Probabilistic Clustering- Projection Model for Discrete Data Shipeng Yu 1,2 , Kai Yu 2 , Volker Tresp 2 , Hans-Pe ter Kriegel 1 1 Institute for Computer Science, University of Munich 2 Siemens Corporate Technology, Munich, Germa ny October 2005

Probabilistic Clustering-Projection Model for Discrete Data Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, Hans-Peter Kriegel 1 1 Institute for Computer Science,
Dec 17, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Probabilistic Clustering-Projection Model
for Discrete Data
Shipeng Yu1,2, Kai Yu2, Volker Tresp2, Hans-Peter Kriegel1
1Institute for Computer Science, University of Munich2Siemens Corporate Technology, Munich, Germany
October 2005

2
Outline
Motivation Previous Work The PCP Model Learning in PCP Model Experiments Conclusion and Future Work

3
Motivation
We model discrete data in this work Fundamental problem for data mining and machine learning In “bag-of-words” document modelling: document-word pairs In collaborative filtering: item-rating pairs
Properties The data can be described as a big matrix with integer entries The data matrix is normally very sparse (>90% are zeros)
w1 w2 ¢¢¢ wVd1 2 0 ¢¢¢ 1d2 0 1 ¢¢¢ 2...
......
......
dD 1 1 ¢¢¢ 0
Documents
Words
Occurrences

4
Data Clustering
Goal: Group similar documents together For continuous data: Distance-based similarity (k-means)
Iteratively minimize a distance-based cost function Equivalent to a Gaussian mixture model
For discrete data: Occurrence-based similarity
Similar documents should have similar occurrences of words No Gaussianity holds for discrete data
w1 w2 ¢¢¢ wVd1 2 0 ¢¢¢ 1d2 0 1 ¢¢¢ 2...
......
......
dD 1 1 ¢¢¢ 0

5
Data Projection
Goal: Find a low-dimensional feature mapping For continuous data: Principal Component Analysis
Find orthogonal dimensions to explain data covariance For discrete data: Topic detection
Topics explain the co-occurrences of words Topics are not orthogonal, but independent
w1 w2 ¢¢¢ wVd1 2 0 ¢¢¢ 1d2 0 1 ¢¢¢ 2...
......
......
dD 1 1 ¢¢¢ 0
z1 ¢¢¢ zK

6
Projection versus Clustering
They are normally modelled separately But why not jointly?
More informative projection better document clusters
Better clustering structure better projection for words
There should be a stable situation
And how? PCP Model Well-defined generative model for the data Standard ways for learning and inference Generalizable to new data
w1 w2 ¢¢¢ wVd1 2 0 ¢¢¢ 1d2 0 1 ¢¢¢ 2...
......
......
dD 1 1 ¢¢¢ 0
z1 ¢¢¢ zK

7
Two-sided clustering [Hofmann & Puzicha 98]: Same problem as PLSI Discrete-PCA [Buntine & Perttu 03]: Similar to LDA in spirit TTMM [Keller & Bengio 04]: Lack a full Bayesian explanation
Previous Work for Discrete Data
PLSI [Hofmann 99] First topic model Not well-defined generative model
LDA [Blei et al 03] State-of-the-art topic model Generalize PLSI with Dirichlet prior No clustering effect is modelled
NMF [Lee & Seung 99] Factorize the data matrix Can be explained as a cluster
ing model No projection of words is dire
ctly modelled
Projection model Clustering model
w1 w2 ¢¢¢ wVd1 2 0 ¢¢¢ 1d2 0 1 ¢¢¢ 2...
......
......
dD 1 1 ¢¢¢ 0
z1 ¢¢¢ zKµw1 w2 ¢¢¢ wV
d1 2 0 ¢¢¢ 1d2 0 1 ¢¢¢ 2...
......
......
dD 1 1 ¢¢¢ 0
Joint Projection-Clustering model

8
PCP Model: Overview
Probabilistic Clustering-Projection Model A probabilistic model for discrete data A clustering model using projected features A projection model with structural data
Learning in PCP model: Variational EM Exactly equivalent to iteratively performing cluste
ring and projection operations Guaranteed convergence
9
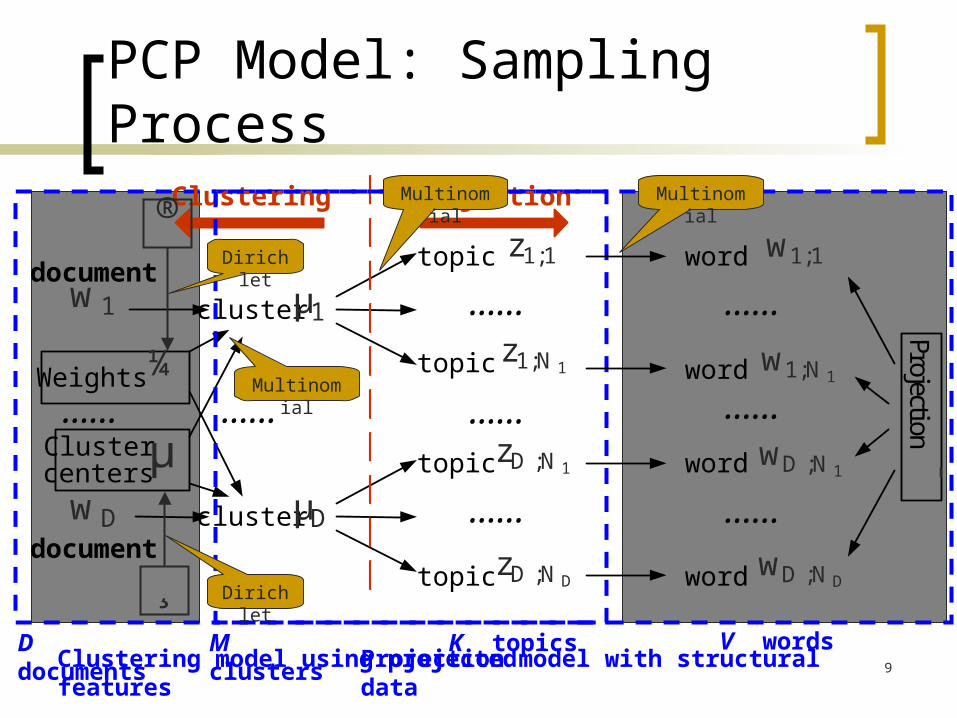
PCP Model: Sampling Process
…... …... …... …...
Clustering Projection
clusterµ1
Weights ¼
Clustercenters
µ
Projection
¯
documentwD
word
…...
word wD ;N D
wD ;N 1
word
…...
word
w1;1
w1;N 1
clusterµD
topic
topic zD ;N D
zD ;N 1
…...
topic
topic
z1;1
z1;N 1
…...
Clustering model using projected featuresProjection model with structural dataD documents M clusters K topics V words
®
¸
Dirichlet
Dirichlet
Multinomial
Multinomial Multinomial
documentw1
10
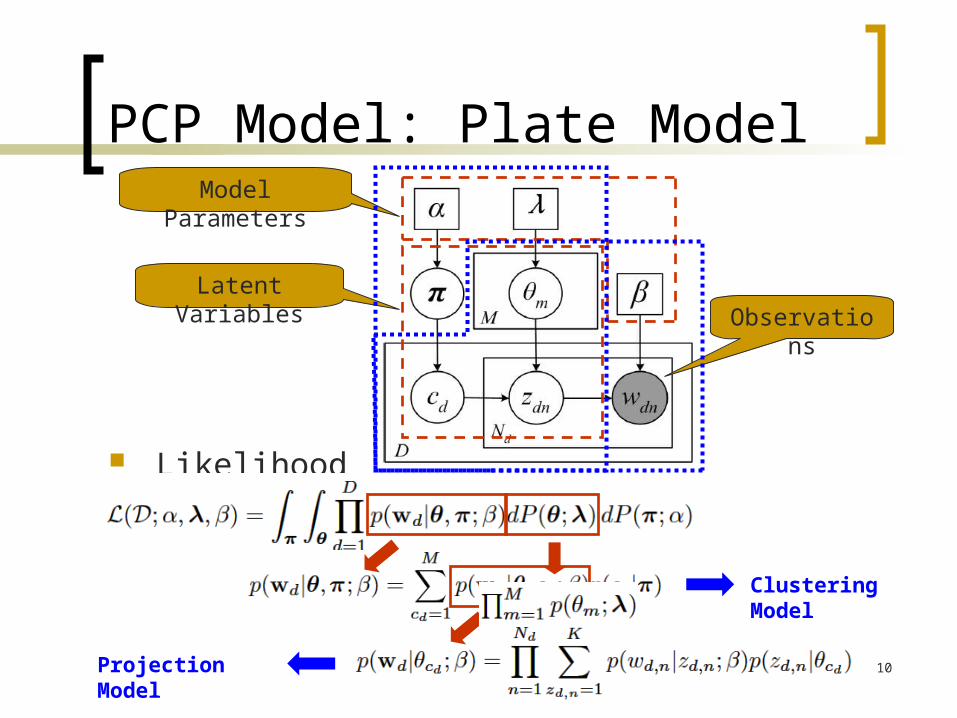
PCP Model: Plate Model
Likelihood
Model Parameters
Latent VariablesObservations
Clustering Model
Projection Model

11
Learning in PCP Model
We are interested in the posterior distribution
The integral is intractable Variational EM learning
Approximate the posterior with a variational distribution
Minimize the KL-divergence Variational E-step: Minimize w.r.t. variational parameters Variational M-step: Minimize w.r.t. model parameters
Iterate until convergence
DK L (qjjp̂)
Variational Parameters
Dirichlet Dirichlet Multinomial Multinomial

12
Update Equations
Equations can be separated to clustering updates and projection updates
Variational EM learning corresponds to iteratively performing clustering and projection until convergence
Clustering Updates
Projection Updates

13
Clustering UpdatesUpdate soft cluster assignments, P (cd =m)
Update cluster centers Update cluster weights
Prior term
Likelihood term
Prior termLikelihood term
Sufficient Projection term

14
Projection UpdatesUpdate word projection, P (zd;n = k)
Update projection matrix Empirical estimate
Sufficient Clustering term

15
PCP Learning Algorithm
Clustering Updates
Projection Updates
Sufficient Clustering term
Sufficient Projection term

16
Experiments
Methodology Document Modelling: Compare model generalization Word Projection: Evaluate topic space Document Clustering: Evaluate clustering results
Data sets 5 categories in Reuters-21578: 3948 docs, 7665 words 4 categories in 20Newsgroup: 3888 docs, 8396 words
Preprocessing Stemming and stop-word removing Pick up words that occur at least in 5 documents

17
Case Study Run on a 4-group subset of 20Newsgroup data
Car
Bike
Baseball
Hockey

18
Exp1: Document Modelling
Goal: Evaluate generalization performance Methods to compare
PLSI: A “pseudo” form for generalization LDA: State-of-the-art method
Metric: Perplexity
90% for training and 10% for testing
Perp(Dtest) = exp(¡P
d lnp(wd)=P
d jwdj)

19
Exp2: Word Projection
Goal: Evaluate the projection matrix Methods to compare: PLSI, LDA We train SVMs on the 10-dimensional space after projection Test classification accuracy on leave-out data
¯
Reuters Newsgroup

20
Exp3: Document Clustering
Goal: Evaluate clustering for documents Methods to compare
NMF: Do factorization for clustering LDA+k-means: Do clustering on the projected space
Metric: normalized mutual information

21
Conclusion
PCP is a well-defined generative model PCP models clustering and projection jointly Learning in PCP corresponds to an iterative
process of clustering and projection PCP learning guarantees convergence Future work
Large scale experiments Build a probabilistic model with more factors

Thank you!
Questions?
Related Documents











