Pretests for genetic- Pretests for genetic- programming evolved trading programming evolved trading programs : programs : “zero-intelligence” strategies and “zero-intelligence” strategies and lottery trading lottery trading Nicolas NAVET Nicolas NAVET INRIA - AIECON NCCU INRIA - AIECON NCCU http:// http:// www.loria.fr www.loria.fr /~ /~ nnavet nnavet joint work with Shu-Heng joint work with Shu-Heng Chen Chen AIECON NCCU AIECON NCCU http://www.aiecon.org/ ICONIP 2006 – Hong Kong – October 4, 2006

Pretests for genetic-programming evolved trading programs : “zero-intelligence” strategies and lottery trading Nicolas NAVET INRIA - AIECON NCCU nnavet.
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Pretests for genetic-Pretests for genetic-programming evolved programming evolved trading programs :trading programs :
“zero-intelligence” strategies and “zero-intelligence” strategies and
lottery tradinglottery trading Nicolas NAVETNicolas NAVETINRIA - AIECON NCCUINRIA - AIECON NCCU
http://http://www.loria.frwww.loria.fr/~/~nnavetnnavet
joint work with Shu-Heng joint work with Shu-Heng ChenChen
AIECON NCCUAIECON NCCU http://www.aiecon.org/
ICONIP 2006 – Hong Kong – October 4, 2006

2
Conclusions are - most often - Conclusions are - most often - inconclusive regarding the inconclusive regarding the
efficiency of GPefficiency of GP
Is it because market is efficient ? (i.e. nothing to learn on the training data)
Further efforts are meaningless ! Or learning algorithm is inefficient ?
Consider another ML algorithm / improvement of the GP scheme: fitness function, search intensity, high level function sets, overfitting avoidance, better genetic operators, data division scheme, etc, etc, …
Pretesting may provide some evidence !
If results are not very convincing :

3
Genetic programmingGenetic programming : a : a recaprecap
Generate a population of
random programs
Evaluate their quality
(“fitness”)
Create better programs by applying genetic
operators, eg- mutation
- combination (“crossover”)
GP is the process of evolving a population of computer programs, that are candidate solutions, according to
the evolutionary principles (e.g. survival of the fittest)
Solution

4
In GP, programs are In GP, programs are represented represented by trees (1/3)by trees (1/3) Trees are a very general representation
form : E.g. of a trading rule : buy if expression is “true”
functions
terminals

5
GP for financial tradingGP for financial trading Predicting price evolution (not
discussed here) Inducing technical trading rules :Training
intervalValidation interval
Out-of-sample interval
1 ) Creation of the trading rules using GP
2) Selection of the best resulting strategies
Further selection on unseen data
-
One strategy is chosen for
out-of-sample
Performance evaluation

6
Why GP is an appealing Why GP is an appealing technique for financial technique for financial
trading ?trading ? Easy to implement / robust evolutionary
technique Trading rules (TR) should adapt to a
changing environment – GP may simulate this evolution
Solutions are produced under a symbolic form that can be understood and analyzed
GP may serve as a knowledge discovery tool (e.g. evolution of the market)
7
But one may cast doubts on GP But one may cast doubts on GP efficiency ..efficiency ..
Highly heuristic – no theory ! Problems on which GP has been shown not to be significantly better than random search
Few clear-cut successes reported in the financial literature
GP embeds little domain specific knowledge yet .. Doubts on the efficiency of GP to use the available
computing time : code bloat bad at finding numerical constants best solutions are sometimes found very early in the run ..
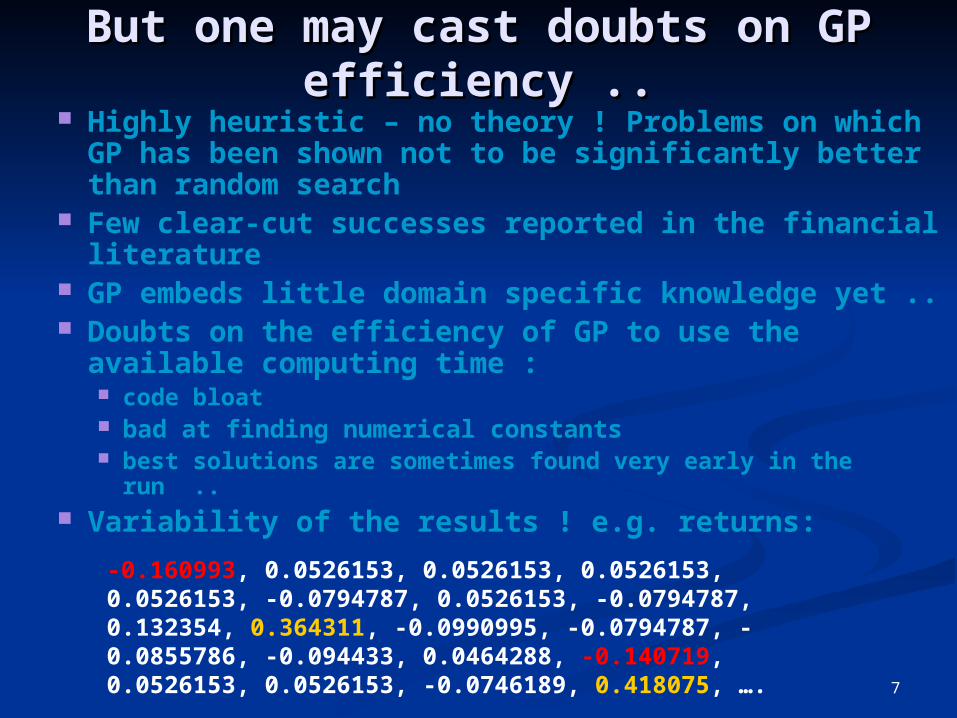
Variability of the results ! e.g. returns:
-0.160993, 0.0526153, 0.0526153, 0.0526153, 0.0526153, -0.0794787, 0.0526153, -0.0794787, 0.132354, 0.364311, -0.0990995, -0.0794787, -0.0855786, -0.094433, 0.0464288, -0.140719, 0.0526153, 0.0526153, -0.0746189, 0.418075, ….

8
Possible pretest : measure of Possible pretest : measure of predictability of the financial predictability of the financial
time-seriestime-series
Serial correlation Kolmogorov complexity Lyapunov exponent Unit root analysis Comparison with results on surrogate
data : “shuffled” series (e.g. Kaboudan statistics)
...
Actual question : how predictable for a given horizon with a given cost function?

9
In practice, some predictability In practice, some predictability does not imply profitability ..does not imply profitability ..
Volatility may not be sufficient to cover round-trip transactions costs!
t Not the right trading instrument at hand .. typically short selling not available
t
Prediction horizon must be large enough!

Part 2 :Part 2 :Pretests for GP Pretests for GP evolved trading evolved trading
strategiesstrategies

11
Pretest methodologyPretest methodology Compare GP with several variants
of Random search algorithms
“Zero-Intelligence Strategies” - ZIS Random trading behaviors
“Lottery trading” - LT
Statistical hypotheses testing Null : GP does not outperform
ZIS Null : GP does not outperform LT
Issue : how to best constraint randomness ?

Pretest 1 :Pretest 1 : GP versus GP versus Zero-Intelligence Zero-Intelligence
strategiesstrategies(=“Equivalent search intensity” (=“Equivalent search intensity”
Random Search (ERS) with Random Search (ERS) with validation stage)validation stage)
-Null hypothesis Null hypothesis HH1,0 : : GP does not GP does not outperform equivalent random outperform equivalent random search search - Alternative hypothesis is - Alternative hypothesis is HH1,1

13
Pretest 1 : GP vs Pretest 1 : GP vs zero-intelligence strategieszero-intelligence strategies
H1,0 cannot be rejected – interpretation : There is nothing to learn or GP is not very
effective
Training interval
Validation interval
Out-of-sample interval
1 ) Creation of the trading rules using GP
2) Selection of the best resulting strategies
Further selection on unseen data
-
One strategy is chosen for
out-of-sample
Performance evaluation
ERS

14
Pretest 4 : GP vs lottery Pretest 4 : GP vs lottery tradingtrading
Lottery trading (LT) = random trading behavior according the outcome of a r.v. (e.g. Bernoulli law)
Issue 1 : if LT tends to hold positions (short, long) for less time that GP, transactions costs may advantage GP ..
Issue 2 : it might be an advantage or an disadvantage for LT to trade much less or much more than GP. ex: downward oriented market with no
short-sell

15
Frequency and intensity Frequency and intensity of a trading strategyof a trading strategy
Frequency : average number of transactions per unit of time
Intensity : proportion of time where a position is held
For pretest 4 : We impose that average frequency and
intensity of LT is equal to the ones of GP Implementation : generate random
trading sequences having the right characteristics0,0,1,1,1,0,0,0,0,0,1,1,1,1,1,1,0,0,1,1,0,1,0,0,0,
0,0,0,1,1,1,1,1,1,…

16
Training interval
Validation interval
Out-of-sample interval
1 ) Creation of the trading rules using GP
2) Selection of the best resulting strategies
Further selection on unseen data
-
One strategy is chosen for
out-of-sample
Performance evaluation
Pretest 4 : implementationPretest 4 : implementation
0,0,1,1,1,0,0,0,0,0,1,…
Lottery trading

Answering question 1 Answering question 1 ::
is there anything to is there anything to learn on the training learn on the training
data at hand ? data at hand ?

18
Question 1 : pretests Question 1 : pretests involvedinvolved
Starting point: if a set of search algorithms do not outperform LT, it gives evidence that there is nothing to learn ..
Pretest 4 : GP vs Lottery TradingNull hypothesis H4,0 : GP does not
outperform LT Pretest 5 : Equivalent Random Search
(ZIS) vs Lottery TradingNull hypothesis H5,0 : ERS does not
outperform LT
19
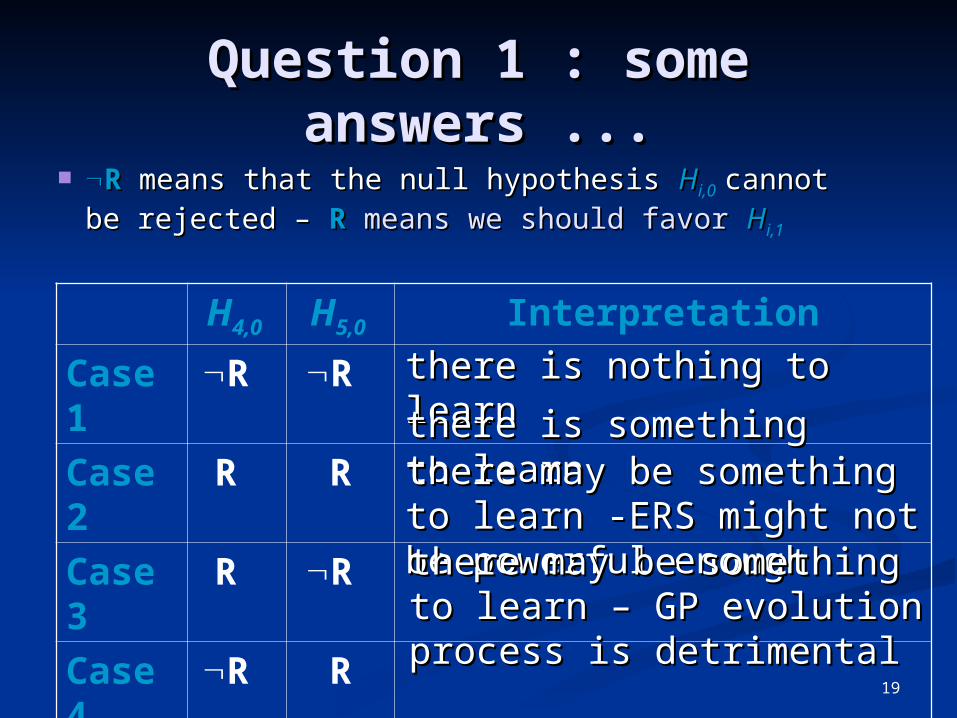
Question 1 : some Question 1 : some answers ...answers ...
RR means that the null hypothesis means that the null hypothesis HHi,0 cannot cannot be rejected – be rejected – R R means we should favormeans we should favor HHi,1
H4,0 H5,0 Interpretation
Case 1
R R
Case 2
R R
Case 3
R R
Case 4
R R
there is nothing to there is nothing to learnlearnthere is something to there is something to learnlearnthere may be something to there may be something to learn -ERS might not be learn -ERS might not be powerful enoughpowerful enoughthere may be something to there may be something to learn – GP evolution process learn – GP evolution process is detrimentalis detrimental
Answering question 2 Answering question 2 ::
is GP effective ? is GP effective ?

21
Question 2 : some Question 2 : some answers ... answers ...
Question 2 cannot be answered if there is nothing to learn (case 1)
Case 4 provides us with a negative answer ..
In case 2 and 3, run pretest 1 : GP vs Equivalent random search Null hypothesis H1,0 : GP does not outperform
ERS If one cannot reject H1,0 GP shows no
evidence of efficiency…

Pretests at work Pretests at work Methodology :Methodology :
Draw conclusions from pretests using Draw conclusions from pretests using our own programs and compare with our own programs and compare with results in the literature results in the literature [ChKuHo06][ChKuHo06]
on the same time series on the same time series

23
Setup : GP control parameters Setup : GP control parameters - same as in - same as in [ChKuHo06][ChKuHo06]

24
Setup : statistics, data, Setup : statistics, data, trading scheme trading scheme
Hypothesis testing with student t-test with a Hypothesis testing with student t-test with a 95% confidence level95% confidence level
Pretests with samples made of 50 GP runs, 50 Pretests with samples made of 50 GP runs, 50 ERS runs and 100 LT runsERS runs and 100 LT runs
Data : indexes of 3 stock exchanges Canada, Data : indexes of 3 stock exchanges Canada, Taiwan and JapanTaiwan and Japan
Daily trading with short sellingDaily trading with short selling Training of 3 years – Validation of 2 yearsTraining of 3 years – Validation of 2 years Out-of-sample periods: 1999-2000, 2001-2002, Out-of-sample periods: 1999-2000, 2001-2002,
2003-20042003-2004 Data normalized with a 250 days moving Data normalized with a 250 days moving
averageaverage

25
Results on actual data (1/2)Results on actual data (1/2)
Evidence that there is something to learn : 4 markets out of 9 (C3,J2,T1,T3) Experiments in [ChKuHo06], with another
GP implementation, show that GP performs very well on these 4 markets
Evidence that there is nothing to learn : 3 (C1,J3,T2) In [ChKuHo06], there is only one (C1) where
GP has positive return (but less than B&H)

26
Results on actual data (2/2)Results on actual data (2/2)
GP effective : 3 markets out of 6 In these 3 markets, GP outperforms Buy and
Hold – same outcome as in [ChKuHo06] Preliminary conclusion : one can rely on
pretests .. When there is nothing to learn, no GP
implementation did good (except in one case) When there is something to learn, at least one
implementation did good (always) When our GP is effective, GP in [ChKuHo06] is
effective too (always)

27
Further conclusionFurther conclusion Our GP implementation is
1. is more efficient than random search : no case where ERS outperform LT and GP did not
2. But only slightly more efficient … one would expect much more cases where GP does better than LT and not ERS
Our GP is actually able to take advantage of regularities in data … but only of “simple” ones
Ongoing work : study the correlation between predictability measures and GP performances

28
ReferencesReferences [ChKuHo06][ChKuHo06] S.-H. Chen and T.-W. S.-H. Chen and T.-W.
Kuo and K.-M. Hoi, “Genetic Kuo and K.-M. Hoi, “Genetic Programming and Financial Trading: Programming and Financial Trading: How Much about What We Know”. How Much about What We Know”. Handbook of Financial Engineering, Handbook of Financial Engineering, Kluwers, 2006.Kluwers, 2006.
[Kab00][Kab00] M. Kaboudan, “Genetic M. Kaboudan, “Genetic Programming Prediction of Stock Programming Prediction of Stock Prices”, Computational Economics, Prices”, Computational Economics, vol16, 2000.vol16, 2000.

29
?

30
Conclusions are - most often - Conclusions are - most often - inconclusive regarding the inconclusive regarding the
efficiency of GPefficiency of GP “Annual returns with the GP
induced technical trading rules is x%” If negative, market is efficient or GP
ineffective ?? If positive, mere luck or GP is effective ?? Good/bad wrt to other search techniques ?? Worth to further improve/ optimize GP ??
Pretests provide some evidence whether
1.There is something to be learned from the data
2.GP is effective at this task

31
Equivalent search intensity Equivalent search intensity
Starting point : 2 search algorithms have similar search intensity if they create the same number of solutions over the course of their execution
Problem : same solutions tends to be rediscovered over time and are not re-evaluated – rate of discovery strongly depends on the search technique / implementation
Refined definition : similar search intensity if same number of “truly” different solutions – here truly means syntactically different

32
Other zero-intelligence (but less Other zero-intelligence (but less meaningful) strategies one can meaningful) strategies one can
think ofthink of Pretest 2 : GP versus equivalent
random search without validationMay give some insight into effectiveness of
validation to fight overfitting .. but little overfitting with random search thus usefulness is dubious ..
Pretest 3 : GP versus equivalent random search without training and validation : random trees applied directly out-of-sample Bias in randomness induced by the GP
language ..

33
Pretest 1 : GP vs zero-Pretest 1 : GP vs zero-intelligence strategiesintelligence strategies
Implementation : Execute multiple GP runs – record average
number of syntactically different individuals Random search is implemented with the initial
population of GP – adjust size of population to obtain “equivalent search intensity”
H1,0 cannot be rejected – interpretation : There is nothing to learn or GP is not effective
H1,1 should be rejected – interpretation :There may be something to learn and GP may
be effective ..

34
Empty slideEmpty slide
XXX
Related Documents

 ultimate forex trading secrets](https://static.cupdf.com/doc/110x72/5479df21b4795995098b4855/fx365groupinfotrading-ultimate-forex-trading-secrets.jpg)








