Presenter MaxAcademy Lecture Series – V1.0, September 2011 Stream Scheduling

Presenter MaxAcademy Lecture Series – V1.0, September 2011 Stream Scheduling.
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

PresenterMaxAcademy Lecture Series – V1.0, September 2011
Stream Scheduling

• Latencies in stream computing• Scheduling algorithms• Stream offsets
2
Overview

• Consider a simple arithmetic pipeline
• Each operation has a latency– Number of cycles from input to output– May be zero– Throughput is still 1 value per cycle, L values can be
in-flight in the pipeline
3
Latencies in Stream Computing
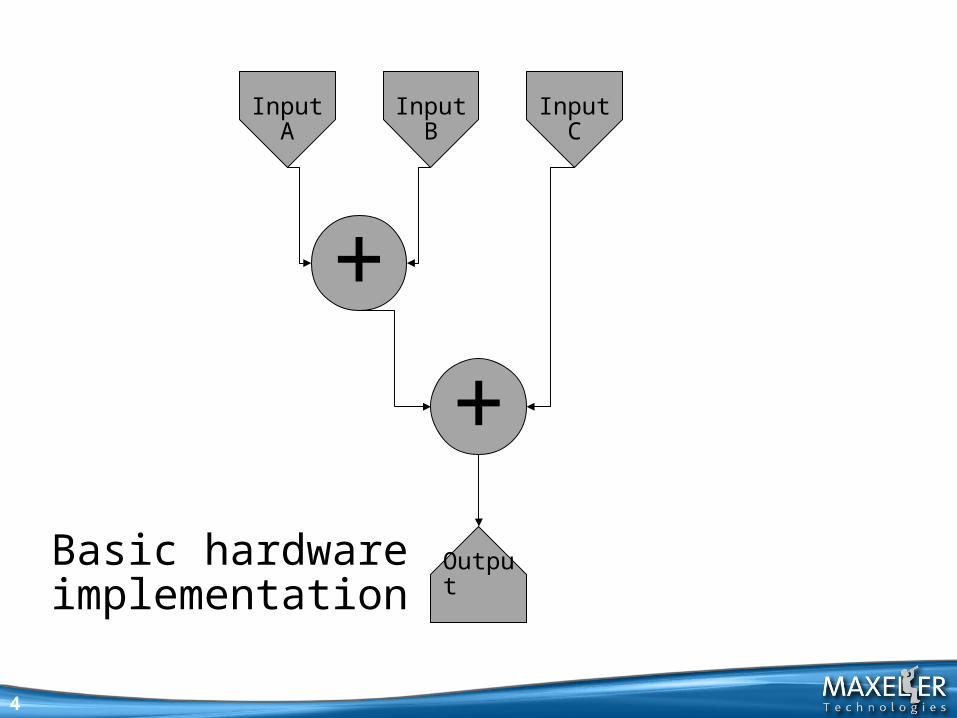
(A + B) + C
4
++
Output
InputA
InputB
InputC
Basic hardware implementation
++
Output
InputA
InputB
InputC
5
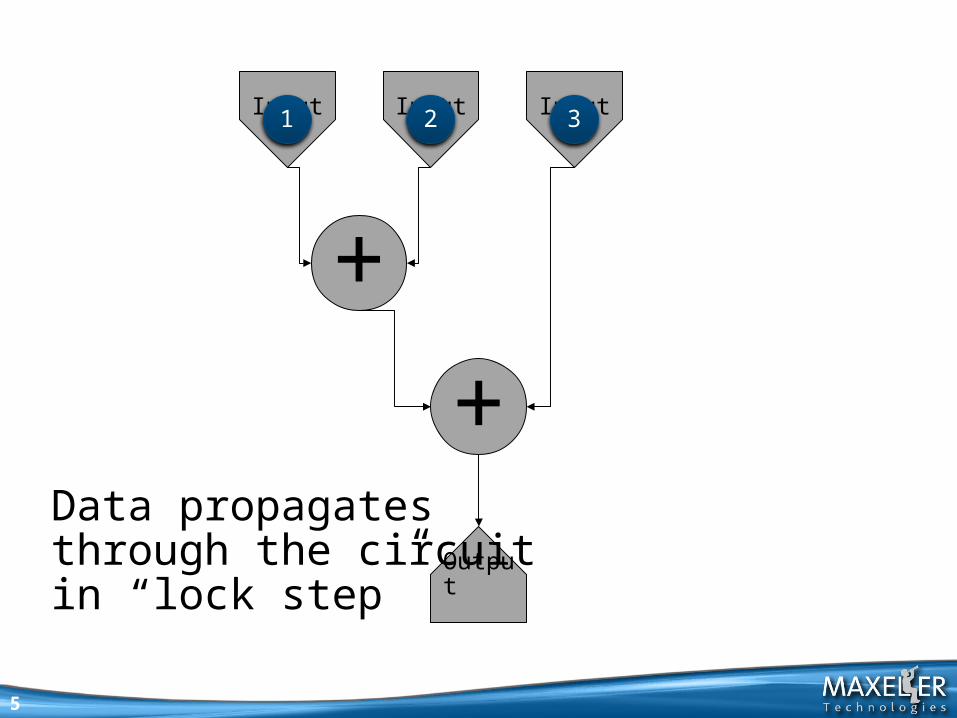
321
Data propagates through the circuit in “lock step”

++
Output
InputA
InputB
InputC
6
3
21

++
Output
InputA
InputB
InputC
7
3
21
X
Data arrives at wrong time due to pipeline latency

8
++
Output
InputA
InputB
InputC
Insert buffering to correct

++
Output
InputA
InputB
InputC
9
1 2 3
Now with buffering

++
Output
InputA
InputB
InputC
10
1 2 3

++
Output
InputA
InputB
InputC
11
3 3

++
Output
InputA
InputB
InputC
12
3 3

++
Output
InputA
InputB
InputC
13
6

++
Output
InputA
InputB
InputC
14
6Success!

15
• A stream scheduling algorithm transforms an abstract dataflow graph into one that produces the correct results given the latencies of the operations
• Can be automatically applied on a large dataflow graph (many thousands of nodes)
• Can try to optimize for various metrics– Latency from inputs to outputs– Amount of buffering inserted generally most interesting– Area (resource sharing)
Stream Scheduling Algorithms

16
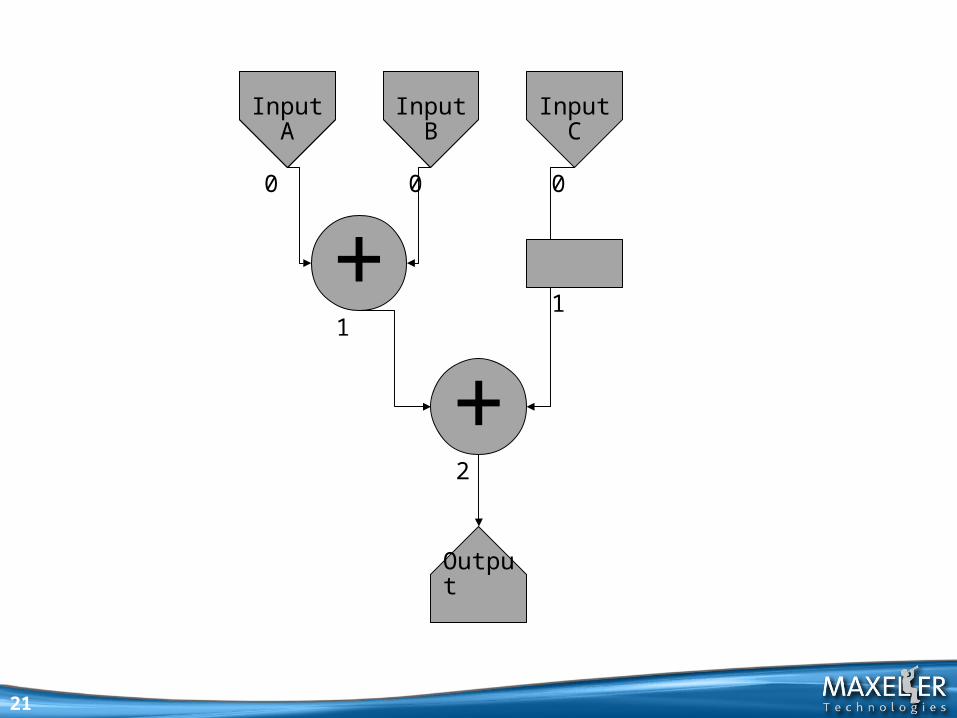
ASAPAs Soon As Possible

17
Input InputInputA
InputA
InputB
InputC
0 00
Build up circuit incrementally
Keeping track of latencies

18
+
Input InputInputA
InputA
InputB
InputC
0 00
1

19
++
Input InputInputA
InputA
InputB
InputC
1
0 00
Input latencies are mismatched

20
++
Input InputInputA
InputA
InputB
InputC
0 00
11
2
Insert buffering
21
++
Output
Input InputInputA
InputA
InputB
InputC
0 00
11
2

22
ALAPAs Late As Possible

23
Output
0
Start at output

24
+Output
-1
0
-1
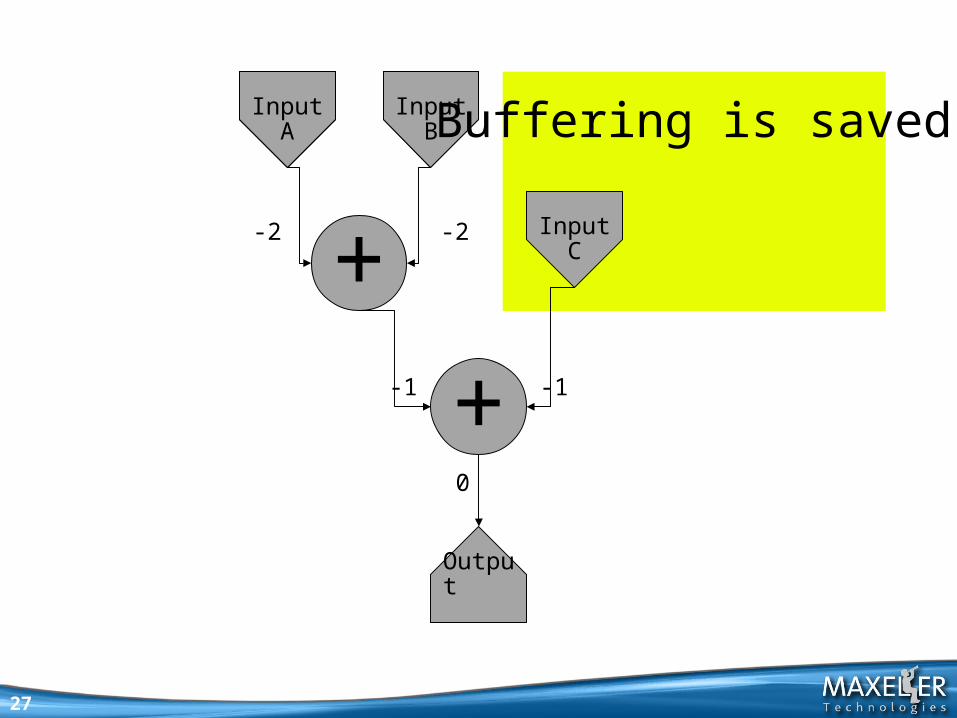
Latencies are negativerelative to end of circuit

25
++
Output
InputC
-2 -2
-1 -1
0

26
++
Output
Input InputInputA
InputA
InputB
InputC
-2 -2
-1 -1
0
27
++
Output
Input InputInputA
InputA
InputB
InputC
-2 -2
-1 -1
0
Buffering is saved

28
++
Output1
Input InputInputA
InputA
InputB
InputC
Output2
Sometimes this is suboptimal
What if we addan extra output?

29
++
Output1
Input InputInputA
InputA
InputB
InputC
-2 -2
-1 -1
0
Output2
Unnecessary bufferingis added
0
Neither ASAP nor ALAPcan schedule this design
optimally

30
• ASAP and ALAP both fix either inputs or outputs in place
• More complex scheduling algorithms may be able to develop a more optimal schedule e.g. using ILP
Optimal Scheduling

• Consider:
• We can see that we might need some explicit buffering to hold more than one data element on-chip
• We could do this explicitly, with buffering elements
31
Buffering data on-chip
a = a + (buffer(a, 1) + buffer(b, 1))
a[i] = a[i] + (a[i - 1] + b[i - 1])

32
++
Output
InputA
InputB
Buffer(1) Buffer(1)
The buffer has zero latency in the schedule

33
++
Output
InputA
InputB
Buffer(1) Buffer(1)
This will schedule thus
Buffering = 3
0 0
00
1
1
2

34
• Accessing previous values with buffers is looking backwards in the stream
• This is equivalent to having a wire with negative latency– Can not be implemented directly, but can affect the
schedule
Buffers and Latency

35
++
Output
InputA
InputB
0 0
-1-1
0
1
Offset wires can have negative latency
Offset(-1) Offset(-1)
-1-1
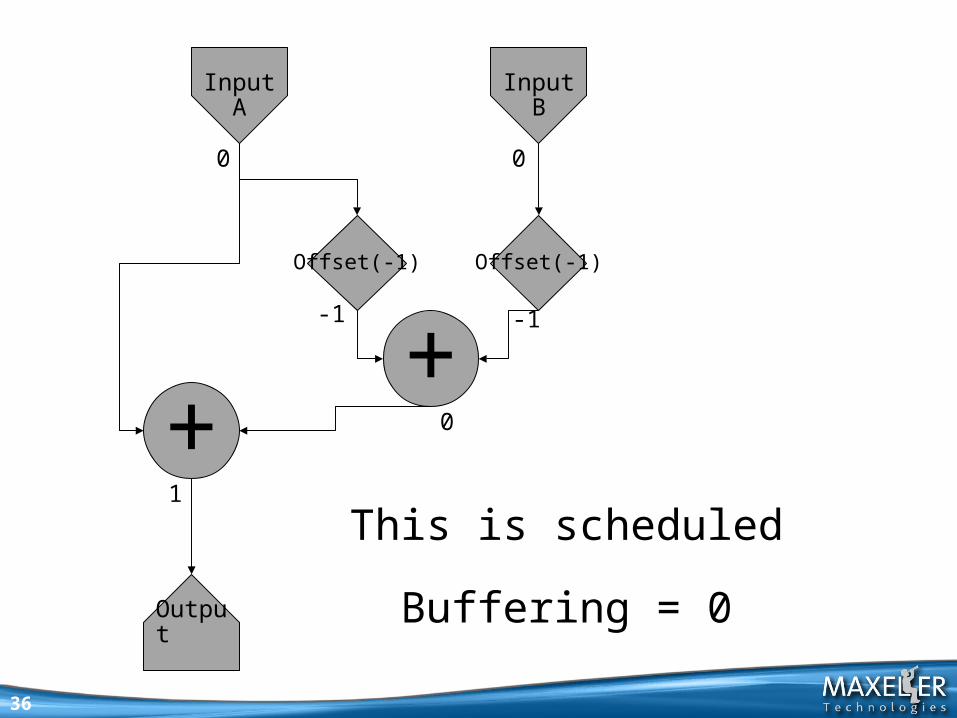
36
++
Output
InputA
InputB
0 0
-1-1
0
1
This is scheduled
Buffering = 0
Offset(-1) Offset(-1)
-1-1

• A stream offset is just a wire with a positive or negative latency• Negative latencies look backwards in the stream• Positive latencies look forwards in the stream
• The entire dataflow graph will re-schedule to make sure the right data value is present when needed
• Buffering could be placed anywhere, or pushed into inputs or outputs more optimal than manual instantiation
37
Stream Offsets

38
+Output
InputA
0
Offset(1)
a = a + stream.offset(a, +1)
a[i] = a + a[i + 1]

39
+Output
InputA
Scheduling produces a circuitwith 1 buffer
0
Offset(1)
11
2

40
For the questions below, assume that the latency of an addition operation is 10 cycles, and a multiply takes 5 cycles, while inputs/outputs take 0 cycles.
1. Write pseudo-code algorithms for ASAP and ALAP scheduling of a dataflow graph
2. Consider a MaxCompiler kernel with inputs a1, a2, a3, a4 and an output c. Draw the dataflow graph and draw the buffering introduced by ASAP scheduling to:
a) c = ( (a1 + a2) + a3) + a4b) c = (a1 + a2) + (a3 + a4)
3. Consider a MaxCompiler kernel with inputs a1, a2, a3, a4 and an output c. Draw the dataflow graph and write out the inequalities that must be satisfied to schedule:
a) c = ((a1 * a2) + (a3 * a4)) + a1b) c = stream.offset(a1, -10)*a2 + stream.offset(a1, -5)*a3 + stream.offset(a1, +15)*a4
How many values of stream a1 will be buffered on-chip for (b)?
Exercises
Related Documents











