Journal of Environmental Science and Health Part C, 27:57–90, 2009 Copyright C Taylor & Francis Group, LLC ISSN: 1059-0501 (Print); 1532-4095 (Online) DOI: 10.1080/10590500902885593 Predictive Models for Carcinogenicity and Mutagenicity: Frameworks, State-of-the-Art, and Perspectives E. Benfenati, 1 R. Benigni, 2 D. M. DeMarini, 3 C. Helma, 4 D. Kirkland, 5 T. M. Martin, 6 P . Mazzatorta, 7 G. Ou ´ edraogo-Arras, 8 A. M. Richard, 9 B. Schilter, 7 W. G. E. J. Schoonen, 10 R. D. Snyder, 11 and C. Yang 12 1 Istituto di Ricerche Farmacologiche “Mario Negri,” Milano, Italy 2 Istituto Superiore di Sanit ` a, Environment and Health Department, Rome, Italy 3 Environmental Carcinogenesis Division, US EPA, Research Triangle Park, North Carolina, USA 4 In Silico Toxicology, Basel, Switzerland 5 Covance Laboratories Ltd, Harrogate, United Kingdom 6 Sustainable Technology Division, National Risk Management Research Laboratory, US EPA, Cincinnati, Ohio, USA 7 Nestl´ e Research Center, Quality and Safety Department, Lausanne, Switzerland 8 L’Or´ eal, Safety Research Department, Aulnay-sous-Bois, France 9 National Center for Computational Toxicology, US EPA, Research Triangle Park, North Carolina, USA 10 Schering-Plough Research Institute, Oss, The Netherlands 11 Schering-Plough Research Institute, Summit, New Jersey, USA 12 Center for Food Safety and Applied Nutrition, Food and Drug Administration, College Park, Maryland, USA Mutagenicity and carcinogenicity are endpoints of major environmental and regula- tory concern. These endpoints are also important targets for development of alternative methods for screening and prediction due to the large number of chemicals of potential concern and the tremendous cost (in time, money, animals) of rodent carcinogenicity bioassays. Both mutagenicity and carcinogenicity involve complex, cellular processes that are only partially understood. Advances in technologies and generation of new data Received January 29, 2009; accepted March 9, 2009. Address correspondence to E. Benfenati, Head, Laboratory of Environmental Chem- istry and Toxicology, Istituto di Richerce Farmacologiche “Mario Negri,” Via La Masa 19, Milan 20156, Italy. E-mail [email protected] 57

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Journal of Environmental Science and Health Part C, 27:57–90, 2009Copyright C© Taylor & Francis Group, LLCISSN: 1059-0501 (Print); 1532-4095 (Online)DOI: 10.1080/10590500902885593
Predictive Models forCarcinogenicity andMutagenicity: Frameworks,State-of-the-Art, andPerspectives
E. Benfenati,1 R. Benigni,2 D. M. DeMarini,3 C. Helma,4
D. Kirkland,5 T. M. Martin,6 P. Mazzatorta,7
G. Ouedraogo-Arras,8 A. M. Richard,9 B. Schilter,7
W. G. E. J. Schoonen,10 R. D. Snyder,11 and C. Yang12
1Istituto di Ricerche Farmacologiche “Mario Negri,” Milano, Italy2Istituto Superiore di Sanita, Environment and Health Department, Rome, Italy3Environmental Carcinogenesis Division, US EPA, Research Triangle Park, NorthCarolina, USA4In Silico Toxicology, Basel, Switzerland5Covance Laboratories Ltd, Harrogate, United Kingdom6Sustainable Technology Division, National Risk Management Research Laboratory,US EPA, Cincinnati, Ohio, USA7Nestle Research Center, Quality and Safety Department, Lausanne, Switzerland8L’Oreal, Safety Research Department, Aulnay-sous-Bois, France9National Center for Computational Toxicology, US EPA, Research Triangle Park,North Carolina, USA10Schering-Plough Research Institute, Oss, The Netherlands11Schering-Plough Research Institute, Summit, New Jersey, USA12Center for Food Safety and Applied Nutrition, Food and Drug Administration, CollegePark, Maryland, USA
Mutagenicity and carcinogenicity are endpoints of major environmental and regula-tory concern. These endpoints are also important targets for development of alternativemethods for screening and prediction due to the large number of chemicals of potentialconcern and the tremendous cost (in time, money, animals) of rodent carcinogenicitybioassays. Both mutagenicity and carcinogenicity involve complex, cellular processesthat are only partially understood. Advances in technologies and generation of new data
Received January 29, 2009; accepted March 9, 2009.Address correspondence to E. Benfenati, Head, Laboratory of Environmental Chem-istry and Toxicology, Istituto di Richerce Farmacologiche “Mario Negri,” Via La Masa19, Milan 20156, Italy. E-mail [email protected]
57

58 E. Benfenati et al.
will permit a much deeper understanding. In silico methods for predicting mutagenicityand rodent carcinogenicity based on chemical structural features, along with currentmutagenicity and carcinogenicity data sets, have performed well for local prediction(i.e., within specific chemical classes), but are less successful for global prediction (i.e.,for a broad range of chemicals). The predictivity of in silico methods can be improved byimproving the quality of the data base and endpoints used for modelling. In particular,in vitro assays for clastogenicity need to be improved to reduce false positives (relativeto rodent carcinogenicity) and to detect compounds that do not interact directly withDNA or have epigenetic activities. New assays emerging to complement or replace someof the standard assays include VitotoxTM, GreenScreenGC, and RadarScreen. The needsof industry and regulators to assess thousands of compounds necessitate the develop-ment of high-throughput assays combined with innovative data-mining and in silicomethods. Various initiatives in this regard have begun, including CAESAR, OSIRIS,CHEMOMENTUM, CHEMPREDICT, OpenTox, EPAA, and ToxCastTM. In silico meth-ods can be used for priority setting, mechanistic studies, and to estimate potency. Ulti-mately, such efforts should lead to improvements in application of in silico methods forpredicting carcinogenicity to assist industry and regulators and to enhance protectionof public health.
Key Words: Carcinogenicity; mutagenicity; QSAR; in silico; predictive methods
INTRODUCTION
The EC-funded SCARLET (Structure-activity relationships leading expertsin mutagenicity and carcinogenicity) project was designed to investigate thecurrent status and future application of predictive models for carcinogenicityand mutagenicity. The project organized a Workshop in Milan, Italy, 2–4 April2008. Participants discussed the potentials and the issues of the methods butalso considered societal and industrial needs and the possibilities of interac-tions with and incorporation of a wider body of scientific research dealing withcarcinogenicity and toxicity in general.
Studies on carcinogenicity and mutagenicity span diverse fields such as bi-ology, toxicology, biochemistry, and chemistry. These studies are important notonly from a scientific point of view but also for the societal consequences re-lated to the toxicity of carcinogenic and mutagenic compounds. To explore thedifferent perspectives, different tools may be preferable. In silico tools are thosebased on computer programs and include so-called (quantitative) structure-activity relationships; i.e., (Q)SAR methods. In silico tools offer advantages forseveral scenarios, particularly where test data are unavailable or prohibitivelyexpensive and time consuming to generate. For this reason, it is useful to pro-vide a general overview of the evolving field of carcinogenicity and mutagenic-ity studies toward the goal of enhancing in silico approaches. More details onthe SCARLET project and the workshop can be found on the Internet (1).
It is not feasible or practical to report all the contributions and positionsrelated to the use of in silico methods for predicting mutagenicity and carcino-genicity. Here we will organize the discussion in five areas to assess the utility

Predictive Models for Carcinogenicity and Mutagenicity 59
of in silico tools for different potential scenarios:
1. The scientific framework of carcinogenicity and mutagenicity studies;
2. The needs of industry and regulators;
3. State-of-the art of the methods of in silico prediction for carcinogenicity andmutagenicity;
4. Connecting new and traditional data into a new scenario;
5. Conclusions.
THE SCIENTIFIC FRAMEWORK OF CARCINOGENICITY ANDMUTAGENICITY STUDIES
The meeting opened with a brief overview of the emerging knowledge of mecha-nisms underlying mutagenesis and carcinogenesis. The importance of the “mu-tagenesis paradigm” was emphasized because this is the general step-wise pro-cess by which a cell deals with DNA damage. Most chemical mutagens do notdirectly induce mutations (i.e., a change in nucleotide sequence in the DNA).Instead, mutagens induce DNA damage, which can be, for example, a DNAadduct (a molecule bound covalently to a nucleotide) or a single- or double-strand break. In either case, the primary nucleotide sequence is not changed.A complex array of signalling pathways detects the DNA damage and directsthe cell to do one of three general things: repair the damage, convert the dam-age to a mutation, or signal the cell to die (apoptosis). Thus, mutagenesis isa cellular process involving enzymatic activities and usually DNA replication.Consequently, mutagens make DNA damage and cells make mutations. Mod-elling this complex process directly may be possible in the future as a clearerunderstanding of the underlying signalling pathways emerges.
Carcinogenesis is now clearly understood to proceed in a Darwinianprocess in which cells with a growth advantage are selected in a step-wisefashion, resulting in a tumor. Both mutational and epigenetic (non-mutational)events are involved and are necessary for this process. Epigenetic events arechanges in gene expression and do not involve a change in nucleotide sequence(mutation). Gene expression can be modulated by methylation of DNA ormethylation or acetylation of histones, which are proteins surrounding theDNA. Carcinogenesis can be initiated by either a genetic (mutational) orepigenetic (non-mutational) event. However, both are ultimately necessary forthe formation of a tumor.
More and more studies are directed toward development of alternativetests to animal studies. However, given the high frequency of irrelevantpositives from in vitro mammalian cell tests, unless there is improved accu-racy of these tests to predict in vivo genotoxic or carcinogenic hazard, many

60 E. Benfenati et al.
substances will be classified inappropriately; i.e., falsely labelled hazardousor even banned. Improvements to basic cell culture are needed to avoidreactions between test substance and culture medium that can result inproduction of clastogenic levels of hydrogen peroxide. A review of the topconcentration (10 mM) for testing non-toxic and freely soluble substancesis urgently needed to see if this concentration is justified. Many differentmeasures of cytotoxicity can be used to determine an appropriately cytotoxictop concentration, but there is now evidence that these do not always selectthe same concentration. If a measure is used that underestimates the toxicity,then higher-than-warranted concentrations may be used and positive artefactsmay occur. Also, the levels of cytotoxicity required in chromosomal aberrationand mouse lymphoma assays are largely based on old published data, andit is not certain that these can be substantiated if more modern protocolsare used (2). These and other factors that may contribute to a high rate ofirrelevant positive results were highlighted by Kirkland et al. (3). A 3-yearresearch program is underway that is funded by the EU cosmetic industryassociation COLIPA and supported by the UK National Institute for the 3Rs,together with ECVAM, to evaluate changes in study design that would reducethe frequency of irrelevant positive results.
Also discussed was the concept of non-covalent DNA interactions. For ex-ample, DNA groove-binding or intercalation, which has not been modelled ad-equately, might also explain many “false positive” findings. Nearly one half ofthe marketed drugs that are not structurally alerting but are still positive inin vitro cytogenetics assays may operate through DNA intercalation and topoi-somerase poisoning (4, 5). This conclusion has been drawn both from cell-basedtesting and 3-D DNA docking evaluations.
Some Examples of Recent In Vitro TechniquesRecently, three different assays were examined for implementation as mu-
tagenicity, genotoxicity, and/or clastogenicity assays; i.e., Vitotox, GreenScreenGC, and RadarScreen. For clastogenicity also, in vivo experiments have to beperformed with rodents.
VitotoxThe Vitotox assay (Thermo Technologies, Finland) is performed in
Salmonella typhimurium strain TA104 (6–8). The assay is based on the ac-tivation of an SOS repair system by genotoxic compounds. In these bacteria, aluciferase gene of the beetle Vibrio frescio is introduced by molecular design,and this gene is under the transcriptional control of the recN promoter. ThisrecN promoter, in turn, is strongly repressed, which prevents the luciferasegene expression under control conditions. In the presence of a DNA-damaginggenotoxic compound, the RecA regulator protein recognizes the resulting
Predictive Models for Carcinogenicity and Mutagenicity 61
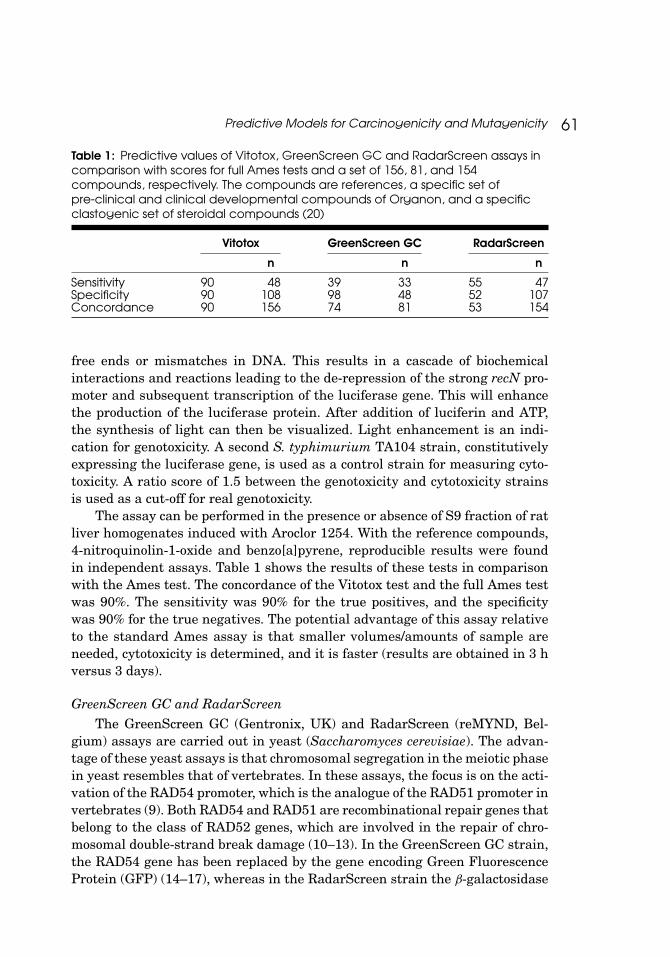
Table 1: Predictive values of Vitotox, GreenScreen GC and RadarScreen assays incomparison with scores for full Ames tests and a set of 156, 81, and 154compounds, respectively. The compounds are references, a specific set ofpre-clinical and clinical developmental compounds of Organon, and a specificclastogenic set of steroidal compounds (20)
Vitotox GreenScreen GC RadarScreen
n n n
Sensitivity 90 48 39 33 55 47Specificity 90 108 98 48 52 107Concordance 90 156 74 81 53 154
free ends or mismatches in DNA. This results in a cascade of biochemicalinteractions and reactions leading to the de-repression of the strong recN pro-moter and subsequent transcription of the luciferase gene. This will enhancethe production of the luciferase protein. After addition of luciferin and ATP,the synthesis of light can then be visualized. Light enhancement is an indi-cation for genotoxicity. A second S. typhimurium TA104 strain, constitutivelyexpressing the luciferase gene, is used as a control strain for measuring cyto-toxicity. A ratio score of 1.5 between the genotoxicity and cytotoxicity strainsis used as a cut-off for real genotoxicity.
The assay can be performed in the presence or absence of S9 fraction of ratliver homogenates induced with Aroclor 1254. With the reference compounds,4-nitroquinolin-1-oxide and benzo[a]pyrene, reproducible results were foundin independent assays. Table 1 shows the results of these tests in comparisonwith the Ames test. The concordance of the Vitotox test and the full Ames testwas 90%. The sensitivity was 90% for the true positives, and the specificitywas 90% for the true negatives. The potential advantage of this assay relativeto the standard Ames assay is that smaller volumes/amounts of sample areneeded, cytotoxicity is determined, and it is faster (results are obtained in 3 hversus 3 days).
GreenScreen GC and RadarScreenThe GreenScreen GC (Gentronix, UK) and RadarScreen (reMYND, Bel-
gium) assays are carried out in yeast (Saccharomyces cerevisiae). The advan-tage of these yeast assays is that chromosomal segregation in the meiotic phasein yeast resembles that of vertebrates. In these assays, the focus is on the acti-vation of the RAD54 promoter, which is the analogue of the RAD51 promoter invertebrates (9). Both RAD54 and RAD51 are recombinational repair genes thatbelong to the class of RAD52 genes, which are involved in the repair of chro-mosomal double-strand break damage (10–13). In the GreenScreen GC strain,the RAD54 gene has been replaced by the gene encoding Green FluorescenceProtein (GFP) (14–17), whereas in the RadarScreen strain the β-galactosidase

62 E. Benfenati et al.
(LacZ) gene was introduced (18, 19). The end-point measurement with GFP isassessed after 24 h and with β-galactosidase after 6 h. The control analysis forcytotoxicity can be carried out in the same sample by adsorption measurementwith a spectrophotometer.
A drawback of the GFP system is that some compounds gave autofluores-cence at the wavelength of GFP. Another issue is that the addition of the S9fraction caused quenching of the GFP signal. With a specific set of 100 candi-date pharmaceuticals, autofluorescence occurred with 15 compounds, whereasfor 15 other compounds activation with the rat-liver S9 fraction was essen-tial. These problems could be overcome with the use of the β-galactosidaseenzyme. This enzyme can cleave 6-O-β-galactopyranosyl-luciferin (Promega,Madison, WI) into free luciferin, which in turn can be quantified with luciferaseof the firefly. At the wavelength of 650 nm, no quenching was found with rat-liver. Due to luminometry, this assay became very sensitive, leading to a betteridentification of clastogenic compounds. With the reference compounds, methylmethanesulphonate and benzo[a]pyrene, reproducible results were found in in-dependent assays.
With both the GreenScreen GC and RadarScreen assays, the predictivitywith the full Ames assay was relatively low compared with the Vitotox eval-uation, leading to sensitivity of 39% and 55% and specificity of 98% and 52%,respectively. Table 2 shows the results of these tests compared with the clasto-genicity test. This new RadarScreen assay should be a good predictor for theidentification of real clastogenic and/or carcinogenic compounds. For example,among 40 steroidal compounds (20) a predictivity score concordance of 82.5%was calculated. With respect to the compounds tested in the full Ames test,12 Ames negative compounds were identified with clastogenic human lym-phoblast or CHO assays. For these 12 compounds, a concordance of 66% wasfound between the RadarScreen and Ames assay. Overall analysis of 132 com-pounds with this RadarScreen assay, compared with the available in vitro clas-togenicity/aneuploidy assays, found that the sensitivity for the positive com-pounds was 80%, the specificity for the negative compounds was 77%, and the
Table 2: Predictive values for Vitotox, GreenScreen GC and RadarScreen assays incomparison with scores for in vitro clastogenicity/aneuploidy for a set of 132, 44,and 130 compounds, respectively. The compounds are references, a specific set ofpre-clinical and clinical developmental compounds of Organon and a specificclastogenic set of steroidal compounds (20)
Vitotox GreenScreen GC RadarScreen
n n n
Sensitivity 29 85 22 23 80 83Specificity 89 47 95 21 77 47Concordance 51 132 57 44 78 130
Predictive Models for Carcinogenicity and Mutagenicity 63
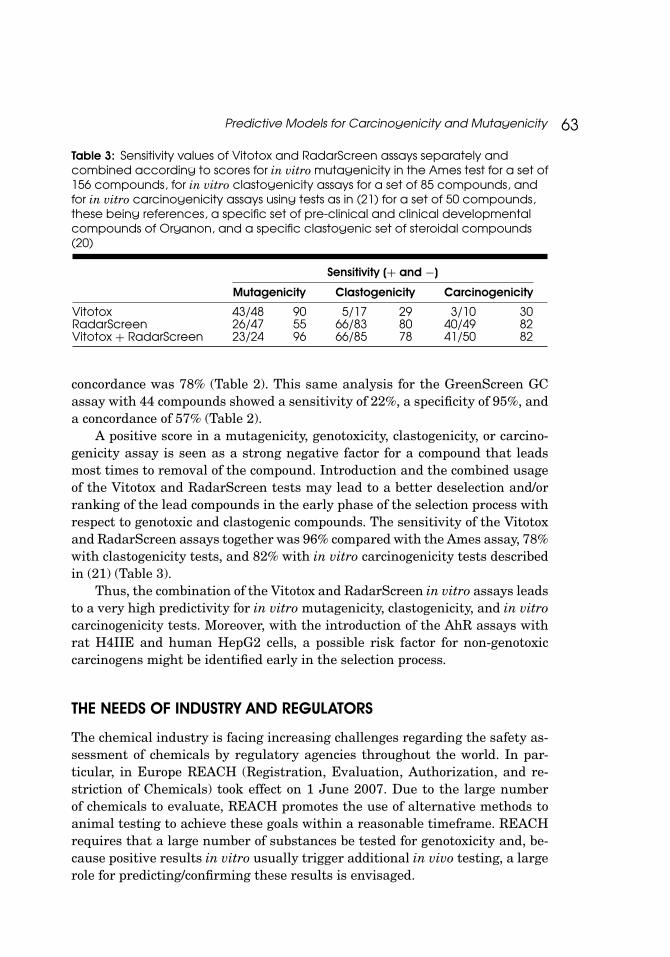
Table 3: Sensitivity values of Vitotox and RadarScreen assays separately andcombined according to scores for in vitro mutagenicity in the Ames test for a set of156 compounds, for in vitro clastogenicity assays for a set of 85 compounds, andfor in vitro carcinogenicity assays using tests as in (21) for a set of 50 compounds,these being references, a specific set of pre-clinical and clinical developmentalcompounds of Organon, and a specific clastogenic set of steroidal compounds(20)
Sensitivity (+ and −)
Mutagenicity Clastogenicity Carcinogenicity
Vitotox 43/48 90 5/17 29 3/10 30RadarScreen 26/47 55 66/83 80 40/49 82Vitotox + RadarScreen 23/24 96 66/85 78 41/50 82
concordance was 78% (Table 2). This same analysis for the GreenScreen GCassay with 44 compounds showed a sensitivity of 22%, a specificity of 95%, anda concordance of 57% (Table 2).
A positive score in a mutagenicity, genotoxicity, clastogenicity, or carcino-genicity assay is seen as a strong negative factor for a compound that leadsmost times to removal of the compound. Introduction and the combined usageof the Vitotox and RadarScreen tests may lead to a better deselection and/orranking of the lead compounds in the early phase of the selection process withrespect to genotoxic and clastogenic compounds. The sensitivity of the Vitotoxand RadarScreen assays together was 96% compared with the Ames assay, 78%with clastogenicity tests, and 82% with in vitro carcinogenicity tests describedin (21) (Table 3).
Thus, the combination of the Vitotox and RadarScreen in vitro assays leadsto a very high predictivity for in vitro mutagenicity, clastogenicity, and in vitrocarcinogenicity tests. Moreover, with the introduction of the AhR assays withrat H4IIE and human HepG2 cells, a possible risk factor for non-genotoxiccarcinogens might be identified early in the selection process.
THE NEEDS OF INDUSTRY AND REGULATORS
The chemical industry is facing increasing challenges regarding the safety as-sessment of chemicals by regulatory agencies throughout the world. In par-ticular, in Europe REACH (Registration, Evaluation, Authorization, and re-striction of Chemicals) took effect on 1 June 2007. Due to the large numberof chemicals to evaluate, REACH promotes the use of alternative methods toanimal testing to achieve these goals within a reasonable timeframe. REACHrequires that a large number of substances be tested for genotoxicity and, be-cause positive results in vitro usually trigger additional in vivo testing, a largerole for predicting/confirming these results is envisaged.

64 E. Benfenati et al.
For the cosmetic industry, the seventh amendment to the European Cos-metic Directive will also phase out the use of animals for testing ingredientsstarting in March 2009. Therefore, the use of non-animal methods is manda-tory for the seventh amendment, whereas it is a recommendation for REACH.Both regulations affect not only companies located in Europe but also thoseexporting chemicals to Europe. There are incentives for seeking alternativemethods (in vitro and in silico methods) in hazard/risk assessment. It shouldbe emphasized that structure-activity concepts are already used, for example,by the U.S. Environmental Protection Agency (EPA).
The EC Research ProjectsTo deal with this new situation and these new regulatory requirements, the
European Union (EU) has promoted a wide range of initiatives to adequatelyprepare for REACH. Several EC-funded projects relate exclusively or partly tothe REACH regulation and in silico models, and others will start soon.
CAESAR (Computer Assisted Evaluation of industrial chemical Sub-stances According to Regulations) is an EC-funded project, coordinated by E.Benfenati (Milan), that is devoted to developing in silico models for REACH forfive endpoints: carcinogenicity, mutagenicity, reproductive toxicity, bioconcen-tration factor, and skin sensitization. All models will be made freely availableat the Web site: http://www.caesar-project.eu.
Because the purpose is related to regulation, careful attention has beengiven to the source of the data to be used for QSAR models, including checkingthe suitability of the experimental procedure according to REACH. Further-more, great care has been given to the data quality from a chemical and toxic-ity point of view. Many mistakes have been found in the data, even when datahave been taken from recent papers. Double checking of all chemical struc-tures found that more than 10% of the chemical structures were incorrect (22).Conversely, some sources, such as the EPA DSSTox database (23), were foundto be of high quality.
OSIRIS (Optimized Strategies for Risk Assessment of Industrial Chem-icals based on Intelligent Combinations of Non-Test and Test Information) isan EC-funded project, coordinated by G. Schuurmann (Leipzig), that is devotedto developing intelligent testing strategies for REACH. In silico, in vitro, andin vivo data will be integrated with exposure scenario. Software will be devel-oped to assist users in determining if the data are sufficient for modelling orif further experiments are needed. Models from CAESAR also will be incorpo-rated within OSIRIS.
Other EC-funded projects are highly relevant to supporting REACHlegislation, even if the project descriptions were not dedicated specificallyto REACH. We already introduced SCARLET, coordinated by E. Benfenati(Milan). The EC-funded project CHEMOMENTUM, coordinated by P. Bala

Predictive Models for Carcinogenicity and Mutagenicity 65
(Warsaw), will produce software for automatic QSAR modelling. The user willhave the capability to build up workflows and extract data from databases andchemical structures from repositories. Chemical descriptors will be calculatedautomatically, including 3D descriptors, and a battery of algorithms will beavailable for modelling. A grid-based approach will allow different parts of thecentralized workflow to be physically present in different locations without af-fecting software performance. This user-friendly scheme will allow simplifiedand seamless modelling, whereas today the user has to switch from the dif-ferent components. CHEMOMENTUM also will incorporate docking tools. Theoutput of the model will also be available in QSAR Model Reporting Format asspecified by requirements of the Organization for Economic Cooperation andDevelopment (OECD). Models for REACH will be available that utilize thedata produced within CAESAR.
CHEMPREDICT is an EC-funded project coordinated by E. Benfenati (Mi-lan). This project is devoted to developing models focused on new simplifiedchemical descriptors that are based on the simplified molecular input line en-try system (SMILES) format. Endpoints for modelling include carcinogenicityand genotoxicity.
OpenTox is a new EC project coordinated by B. Hardy (DouglasConnect)that started in 2008. It is focused on the development of an open-source frame-work providing unified access to toxicity data, (Q)SAR models, and validationprocedures.
The European Chemicals Bureau (ECB), among others, has promoted stud-ies aimed at clarifying the state of the art in the field of (Q)SARs for muta-gens and carcinogens. These studies have been described in official EU reports(24, 25) as well as in scientific publications (26, 27).
Several initiatives have been implemented to help companies fulfill therequirements of legislation. The EPAA (European Platform for AlternativeApproaches to Animal testing) is one such initiative (28) that aims to facili-tate efforts to share knowledge and research to accelerate implementation andacceptance of the 3Rs (Replacement, Reduction, Refinement). The EPAA wasfounded in 2005 from a joint initiative of the European Commission companiesand trade associations. This partnership consists of a steering committee, amirror group that provides critical input to the steering committee, and fiveworking groups. The EPAA will map currently used and ongoing projects inthe area of the 3Rs, implement projects where there are gaps, and promote theacceptance and the use of the 3Rs. The EPAA is seeking to partner not onlywith European stakeholders but with international initiatives as well.
The Situation in the Pharmaceutical IndustryWithin the pharmaceutical industry, the focus of structure-activity mod-
elling is typically on the development of new drugs with a beneficial effect

66 E. Benfenati et al.
on a particular disease at an acceptable low dose level. Treatment should im-prove the well-being of the patient, whereas unwanted side-effects should beabsent or very low. However, if the drug has to be administered at relativelyhigh dose levels, side effects may be induced due to supra-pharmacology or off-target pharmacology. Moreover, at high dosages, the compound itself and/or itsmetabolites may induce adverse side effects, such as genotoxicity, carcinogenic-ity, reprotoxicity, hepatotoxicity, nephrotoxicity, cardiotoxicity, neurotoxicity, orblood or skin toxicity. Within the portfolio of Organon, the toxicity failure ratefrom 1960 to 2000 was due mainly to genotoxicity/carcinogenicity (20%) and re-protoxicity (20%), followed by hepatotoxicity (12%), nephrotoxicity (12%), andcardiotoxicity (12%). This portfolio is completely different from that of Rocheduring the same period of time in which genotoxicity/carcinogenicity reachedonly a level of 6% and reprotoxicity a level of 2%. On the other hand, hepato-toxicity, nephrotoxicity, and cardiotoxicity reached levels of 20%, 4%, and 16%,respectively. These figures can easily be explained by virtue of the focus onreproductive medicine within Organon. One of the main topics in this field ismale and female contraception as well as hormone replacement therapy. Theeffects of estrogens, progestagens, and androgens with respect to these toxicityareas are well known. An overall reduction in the attrition rate of compoundswith 20% to 50% failure rates by means of introducing early toxicity screeningmight lead to a sharp cost reduction in drug development (29–31).
The strategy within a pharmaceutical industry should be to start withearly toxicity screens as early as possible in the discovery process. Possibletoxicity screens could be divided into mutagenicity, genotoxicity, clastogenic-ity, cytotoxicity, cytochrome P450 induction, and nuclear receptor activation.These predictive toxicity assays should be an integral part of the “ranking andselection” process of candidate drugs, should be on a medium to high through-put level, should only use a small amount of compound (1 to 20 mg), and shouldbe carried out with a limited amount of man power. Implementation of in sil-ico procedures with structure-activity relationship (SAR) programs, such asDEREK, TOPKAT, MultiCASE, and Mutalert, can already be initiated at thestage of hit selection. in vitro assays for measuring mutagenicity, genotoxic-ity, clastogenicity, non-genotoxic carcinogenicity, cytotoxicity, nuclear receptoractivation, and cytochrome P450 enzyme activation, as well as competition as-says, can be implemented from the point of lead selection to the final choice ofthe development candidate in the preclinical selection phase.
Genotoxicity Tests within the Pharmaceutical IndustryAccording to the guidelines of the U.S. Food and Drug Administration
(FDA), four different endpoints testing mutagenicity and clastogenicity areconsidered for a new drug approval or food ingredients notifications. Thesetests are:

Predictive Models for Carcinogenicity and Mutagenicity 67
1. An in vitro test for gene mutation in bacteria, i.e., Salmonella reverse mu-tation;
2. An in vitro test with cytogenetic evaluation of chromosomal damage, e.g.,in vitro micronucleus or in vitro chromosome aberration;
3. In vitro mammalian mutation, i.e., in vitro mouse lymphoma Tk+/− assay;and
4. An in vivo test for chromosomal damage using rodent hematopoietic cells,i.e., micronucleus assay.
These in vitro tests are still relatively time-consuming, have a relativelylow throughput, and require a relatively large amount of compound.
Non-genotoxic Carcinogens within the Pharmaceutical IndustryActivation of the AhR with dioxin (TCDD) leads in both rats and humans
to an increased incidence of liver tumors (32–34). TCDD is, therefore, classi-fied as a non-genotoxic carcinogen. The difficulty in using AhR activation asa marker for non-genotoxic carcinogenesis lies in the fact that not all AhR in-ducers are necessarily non-genotoxic carcinogens. For instance, grapes, fruits,and vegetables, which are generally considered very healthy, contain chemicalsthat enhance AhR activity and, thus, affect AhR-driven pathways. The mainquestion is whether these protective mechanisms increase or decrease tumorincidence. Thus, a compound that activates the AhR can either be beneficialor carcinogenic. Because it is difficult to predict in which class an AhR acti-vator will fall, it is advisable to steer away from AhR activation during drugdevelopment, even though good compounds may be thrown out with the bad.
For the identification of at least one specific group of non-genotoxic carcino-gens, it is relevant to measure the activation of the rat and/or human AhR. Forthis, simple cellular assays are available in both rat H4IIE and human HepG2cells, both of which make use of the metabolism of 3-cyano-7-ethoxycoumarin(CEC) by cytochrome P450 enzyme 1A1 and/or 1A2—enzymes that are inducedfollowing AhR activation. For TCDD and 3-methylcholanthrene, the activity issimilar in both cell lines. However, species-specific differences have also beenobserved; e.g., indigo activity is dominant in the rat cell line, whereas indirubinis a much stronger AhR agonist in the human cell line. On the other hand, com-pounds such as menadione activated only the human AhR receptor, whereasflutamide, Org D, PCB156, and PCB157 were specific for the rat receptor (35).This species difference has also been observed for a number of Organon pro-prietary compounds.
As mentioned above, existing in silico models may “miss” prediction ofmany genotoxicity tests, which in turn may be related at least in part to thefact that the existing computational programs cannot detect non-covalent DNA

68 E. Benfenati et al.
interactions. Very few DNA intercalators were employed in the training sets ofthese models; even if they were, most of them were classical fused planar multi-ring compounds such as acridines rather than the atypically structured inter-calators reported recently (4, 5). Because of the complexity of the SARs and theprobable need to account for electrostatic and other (i.e., van der Waals, hydro-gen bonding) effects, it will be difficult to improve programs such as DEREK orMCASE to identify such molecules. As the genotoxicity database grows, how-ever, it may be possible to establish a predictive tool for non-covalent chemi-cal/DNA interactions.
The Food Industry and the Need of In Silico Models forCarcinogenicity and Mutagenicity
In recent years there has been mounting concern about food as a source ofexposure to potentially toxic chemicals. It has been estimated that there areover five million man-made chemicals known, of which 70,000 are in use today.The application of continuously improving analytical methods has revealedthat many of these chemicals can enter the food chain and result in humanexposure.
Food chemical risk assessment is the scientific process used to characterizethe health significance of potentially harmful chemicals in food. Classically, itcomprises four steps: (1) hazard identification; (2) hazard characterization; (3)exposure assessment; and (4) risk characterization. In general, hazard identifi-cation and characterization rely on toxicological data obtained in experimentalanimals, mainly rodents. Because toxicological information is limited or absentfor the majority of the inadvertent food-borne chemicals, the assessment of thehealth significance of such chemicals is difficult or impossible. Nevertheless,the detection of such chemicals in food products may trigger not only heavymanagement action (e.g., public recall) but also public concern resulting in lossof consumer confidence for the food supply. In such situations, the availabilityof reliable tools to establish levels of safety concern without hard toxicologicaldata appears of particular importance to ensure adequate consumer protectionwithout undue overconservatism. This should ultimately allow optimal use ofthe limited resources available.
Solutions to this general issue are not straightforward. Obviously, experi-mental toxicology is not a practical tool to deal with situations requiring fastdecision making. Furthermore, even if sufficient facilities to perform toxicolog-ical testing within a relevant time frame were available, it still can be ques-tioned whether testing a large number of substances would be a rational andpractical approach. In this context, in silico predictive models have obviousadvantages in terms of time, cost, and animal protection.
In silico strategies are already proactively and successfully used for pre-clinical screening in pharmaceutical discovery pipelines in which an early

Predictive Models for Carcinogenicity and Mutagenicity 69
identification of toxicological hazard offers a clear competitive advantage. Suchefforts allow the exclusion of chemicals that could potentially produce unac-ceptable adverse effects in further regulatory toxicology tests. The situationof the food industry is different and requires the development of alternativemodels with the following specific characteristics:
� Risk rather than hazard–based. In the food context, the most likely appli-cation of computational toxicology models would be in the establishmentof the level of safety concern associated with the inadvertent/accidentalpresence of a chemical in products. This requires not only qualitative in-formation on the potential hazardous properties of the chemical (e.g., car-cinogenicity) but also quantitative information (e.g., carcinogenic potency),allowing the derivation of a margin of exposure (MoE) with the estimatedintake. The interpretation of the size of the MoE (e.g., allowing for variousuncertainties such as inter- and intra-species differences) would likely helpto make decisions at the management level.
� Reliable, high sensitivity. Most (Q)SAR predictive models suffer from in-herent poor sensitivity; i.e., the ability to correctly identify true positives(36). Modellers, partially because they are often confronted with non-representative datasets, have focused their attention on identification oftoxicophores that are overly general and, as a result, models tend to havemany false positives. This has made computational toxicology a useful toolfor high-throughput screening (HTS) but different strategies should be op-timized if the target is to have a low number of false negatives or a highconcordance.
� Global. Compounds found in foods and food ingredients present a highstructural diversity and complexity that may be greater than syntheticpharmaceuticals (37) and, therefore, require the development of global insilico models.
Ideally, in silico toxicology strategies should predict adverse effects inthe human population. Because the toxicological training databases currentlyavailable consist mainly of in vitro and animal data with high limitations topredict human situations (38), the development of such models will alwaysconstitute a significant challenge. Their practical application in the food sectorwill depend on their potential to accurately predict endpoints that are cur-rently used to make food safety management decisions. This includes the needto establish confidence limits. The acceptance of these models will be possibleonly if the analysis is fully transparent. Therefore, the promotion of validated,freely available tools based on open-source codes, such as those developed byECB and EPA, is recommended.

70 E. Benfenati et al.
STATE-OF-THE-ART OF IN SILICO METHODS FOR PREDICTION OFCARCINOGENICITY AND MUTAGENICITY
To properly evaluate the utility of current in silico methods, it has to be clari-fied that different purposes are envisioned and, thus, different evaluations arepossible. Also, for this reason, practical applications of in silico programs forprediction of mutagenicity or carcinogenicity have ranged in utility from indis-pensable to useless. Next we list some of the different ways that in silico toolsfor prediction of mutagenicity and carcinogenicity can be employed.
Priority SettingModels are usually used to set priorities among chemicals for further test-
ing. For this use, several (Q)SAR models and databases are commercially (orfreely) available, typically for alert-identification and read-across. Due to thedifferences in the systems (knowledge-based versus artificial intelligence, SARversus QSAR, applicability domains, and extent to which mode-of-action isconsidered in the model development), combining several models appears tobe more sound than relying on a single one. The so-called global and localmodels may be used for the purpose of priority setting. Because regular up-dates of the models are released, care should be taken to re-assess their per-formances on a regular basis. Therefore, active participation of industry isneeded to evaluate and improve existing in silico models so they can meettheir needs. For REACH, although the chemicals to be characterized havebeen chosen on the basis of the amounts produced annually, it may be valu-able to further prioritize them using global SAR. Thus, those chemicals thatpose major concern may be identified and given a higher priority for furtherevaluation.
Mechanistic InvestigationWhen using human knowledge-based systems such as Derek (Lhasa Ltd.)
or OncoLogic (U.S. EPA) or any model based on a mechanistic understanding(as opposed to models based purely on statistics), it is possible to gain insightinto the mechanism underlying the mutagenicity/carcinogenicity.
Quantitative Evaluation of the PotencyIn REACH this evaluation is requested in the case of genotoxic compounds
to assess if the expected exposure level for the scenario of use of the chemicalcompound will produce an unacceptable risk.
Although a particular model may provide results unacceptable for a cer-tain use, for a different purpose the same model can be useful. For instance,a global model with overall prediction accuracy of 65–70%, as can be the case

Predictive Models for Carcinogenicity and Mutagenicity 71
for carcinogenicity models, might be considered unsuitable as a substitute fortraditional testing methods; however, the same model might be useful whencombined with other considerations as a means for prioritization. Further-more, even within the same regulation, such as REACH, in some cases a clas-sifier model can be useful, for instance to identify the presence for a certainmutagenic fragment, whereas for other purposes, such as in support of riskassessment, a quantitative model with less uncertainty is necessary becausethe toxic effect has to be considered along with the exposure level.
There are many publications on the databases, structural alerts, and mod-els, and a number of commercial products are built on these. Publicly availablegenetic toxicity and carcinogenicity data sets include CCRIS (39), EPA Gene-tox (40), NTP (41), IARC (21, 42), EPA IRIS (43), U.S. FDA CRADA database(44), Tokyo-Eiken (45), Mutants (46), CPDB (47, 48), ISSCAN (49), and pri-mary publications. Commercial databases derived from these sources also areavailable from Leadscope (50), Lhasa (51), and MDL (52). These databases pro-vide test results form both regulatory-accepted test protocols as well as otherscreening methods.
Based on these data, commercial prediction models are currently mar-keted in the form of global models, including MultiCASE (53), TOPKAT (54),MDL QSAR (55), and Leadscope FDA Model Applier (56), whereas OncoLogic(57) and LAZAR (58) are freely available for use. Derek from Lhasa offers aknowledge-base classification. Toxtree is a software tool developed by ECB(through IdeaConsult Ltd.) that is able to estimate different types of toxic haz-ards by applying structural rules; it is an open-source, freely available appli-cation that can be downloaded from the ECB Web site (59). The new modulepredicts mutagenicity and carcinogenicity by applying a revised, updated listof Structural Alerts (SA), and, when applicable, three QSARs for congenericclasses (see details in the Toxtree scientific manual) (24, 25). The Leadscopesystem provides data-mining and prediction methods based on both biologi-cal and chemical databases. Currently, researchers at the U.S. FDA and U.S.EPA use Leadscope for chemical and biological read-across based on databasesand to build predictive models. Many of the above prediction methods tend torely heavily on chemical structures and summarized biological endpoint data.Quite often these summarized endpoints are too far removed from the originalexperimental measures and, hence, have lost at least some of their biologicalcontext.
In mutagenicity and carcinogenicity, it is possible to distinguish between(a) coarse-grain methods, relying on the recognition of SAs; (b) fine-tuned ap-proaches, which include Quantitative Structure-Activity Relationships (QSAR)methods for congeneric classes of chemicals (same chemical scaffold, same pre-sumed mechanism of action); and (c) global QSAR models that attempt tocombine elements of the previous two approaches and address more chemicalclasses (60).

72 E. Benfenati et al.
Furthermore, some studies are based on human expertise, which identifiesa series of structural alerts, whereas other tools are based on techniques usedto discover the presence of relationships not yet known; data-mining tools areoften used in the latter case. Examples of models that codify human knowledgeinclude HazardExpert, OncoLogic, Toxtree, and DEREK. MultiCASE, Lead-scope, and LAZAR use software based on the data-driven discovery of geno-toxic or chemical fragments identified by specific automated algorithms. Thereare also mechanistic-based models that rely on prediction of likely chemicalreactions (61).
A comparative analysis of existing lists of SAs derived for the predictionof rodent carcinogenicity has indicated that they have a prediction accuracyof 65% for the rodent carcinogenicity bioassay and an even better predictionaccuracy of 75% for Salmonella mutagenicity results; i.e., surprisingly, rodentcarcinogenicity SAs predict mutagenicity better than they predict rodent car-cinogenicity (26). In addition, these SAs and the Salmonella assay have beenshown to be equally predictive of the rodent carcinogenicity data. Overall, theSAs are a powerful tool for coarse-grain characterization of the chemicals; i.e.,for description of sets of chemicals, preliminary hazard characterization, cate-gory formation for regulatory purposes, or for selecting subsets of chemicals tosubmit to fine-tuned QSAR analyses for priority setting. A previous analysis onthe priority setting criteria adopted by the U.S. National Toxicology Programin selecting chemicals to be bioassayed has shown that the structural criteriaadopted to short-list suspect chemicals were able to enrich the target up toten times. In fact, 70% of the chemicals bioassayed as suspect carcinogens (i.e.,SAs or positive Salmonella data) were carcinogens, whereas only 7% of thechemicals bioassayed based on production/exposure considerations were car-cinogenic (62). This result points to the high reliability of SAs for priority set-ting. On the other hand, the SAs are overly general and are not well suited asa tool for discriminating between positives and negatives of congeners withina chemical class; this is the role of the local, fine-tuned QSARs for congenericclasses (27).
A survey of local QSARs for congeneric classes of chemicals has shown thatthese are classified into (a) models for the gradation of the potency of the pos-itives (mutagens or carcinogens) and (b) those that discriminate between pos-itives and negatives. This is a crucial difference with respect to models suchas those for aquatic toxicity, where it is assumed that all the chemicals can bescaled along one axis of potency, ranging from highly potent to weakly potentchemicals. In mutagenicity and carcinogenicity this does not generally holdtrue; i.e., models for potency most often fail to separate positives from nega-tives. Thus, the models can be applied in two phases: first to separate positivesfrom negatives, and second to assess the potency of the chemicals predicted aspositive in the first phase (63).
The survey on QSARs included (a) a short list of promising models; (b) re-calculation of the statistics; and (c) most importantly, the performance of real

Predictive Models for Carcinogenicity and Mutagenicity 73
external predictivity tests. The latter consisted in selecting from the literaturetest chemicals falling in the same applicability domains of the training sets,but that had never been considered by the authors of the models. The QSARsselected were all scientifically interpretable, had good internal statistics andcross-validation, but varied widely in their external predictivity. The QSARsfor potency had an external prediction ability in the range 30–70% correct(percentage of chemicals whose potency was correctly predicted within 1 logunit). On the other hand, the QSARs for activity (yes/no) had an external pre-diction ability in the range 70–100% correct. This indicates that classificationestimates (e.g., yes/no) generally are much more reliable than estimating datapoints or relative potency rankings. This also confirms the dichotomy betweenQSARs for potency and QSARs for positivity/negativity (64).
Another important result of the survey was that internal validation mea-sures (e.g., cross-validation, other statistics) are not good predictors of externalpredictivity (26, 64). Hence, they should be considered only as a means for bet-ter describing the performances of training sets. It should be emphasized thatthe external predictivity of high quality, local QSARs (70–100%) is in the samerange as the intra-assay agreement of the generally reliable and reproducibleSalmonella mutagenicity assay (80–85%) (65). Hence, the uncertainty inher-ent to the two methods is comparable. In addition, as indicated above, rodentcarcinogenicity SAs correlate with rodent carcinogenicity bioassay results on alarge database to the same extent as the Salmonella assay results.
The OECD guidelines point out that to facilitate the consideration of a(Q)SAR model for regulatory purposes, the model should be associated witha mechanistic interpretation if possible (66). Furthermore, mechanisticallybased (Q)SARs provide (a) a common ground of discussion for modelers, tox-icologists, and regulators; (b) additional tools for minimizing the possibilityof chance correlation; (c) intelligible information to guide synthetic chemistsin preparing safer chemicals; and (d) a rational foundation for developing aQSAR science.
On the other hand, the large amount of legacy data and the anticipated ex-plosion of toxicity-related information expected to be generated over the nextyear (see, for instance, the ToxCastTM program below), call for the applicationof flexible data-mining tools. In the past, for instance, Bursi and coworkers (67)showed results of a global SAR model for mutagenicity with accuracy similarto that of the intra-assay experiments for the Ames test mentioned above. Re-cently, Gini and Ferrari showed similar results obtained within the CAESARproject (68). It should be mentioned that for mutagenicity data, modelling datasets consisting of several thousands of compounds are available and, in thiscase, the role of modern computer techniques are suitable to screen a wide se-ries of possibilities. In this way, it is possible to explore relationships betweenthe presence of a certain fragment and the toxicity and, thus, to mimic theprocess done manually by the human experts. Thus, data-mining tools can beused to explore data in new ways and to identify novel toxicity mechanisms.

74 E. Benfenati et al.
A further contribution of global QSAR models (69) was presented by Toropovand coworkers that showed some models to predict potency for carcinogenicityand mutagenicity using simple descriptors based on SMILES format.
Examples of QSAR Methods Based on Data-miningfor Carcinogenicity
We will now present some data-mining studies in more detail. Martinand coworkers developed several different QSAR methodologies for acuteaquatic toxicity in order to model large, noncongeneric data sets (70). Themethodologies include the Hierarchical clustering method, the FDA MDLQSAR method, the single-model method, and the nearest-neighbor method.These methods were shown to yield excellent prediction results (70). Thehierarchical clustering approach uses Ward’s method (71) to divide an ex-perimental toxicity training set into a series of structurally similar clus-ters where each cluster is assumed to represent a common mode-of-action.The structural similarity is defined in terms of 2-D and 3-D descrip-tors. A genetic algorithm-based technique is used to generate statisticallyvalid QSAR models for each cluster. The toxicity for a given query com-pound is estimated using the average of the predictions from the clus-ter models whose chemicals are structurally the most similar to the querycompound.
The FDA MDL QSAR method is a variation of the clustering methodol-ogy of Contrera and coworkers (72). In this method, the prediction for eachtest chemical is made using a unique model that is fit to the chemicals fromthe entire training set that are the most similar to the test compound. In thesingle-model method, a multilinear regression (MLR) model is fit to the entiredata set using molecular descriptors as independent variables. In the nearest-neighbor method, the predicted toxicity is simply the average of the chemicalsin the training set that are most similar to the test chemical.
The predictive ability of the QSAR methods developed by Martin andcoworkers was evaluated using several different carcinogenicity datasets.First, the methods were evaluated using a small congeneric set of aromaticamines. Franke and coworkers reported that they were able to develop excel-lent correlations for this data set using multilinear regression models (73). Itwas shown that cross validation might overestimate the predictive ability ofregression models if it consists of only refitting the model coefficients to thetraining sets for the different cross-validation folds. It is suggested that onecould obtain a conservative estimate of the potential prediction accuracy ofmultilinear regression methods by using a genetic algorithm to fit a new mul-tilinear model to the training set for each cross validation fold. The differentQSAR methods achieved prediction concordances of 60–66% (averaged over thedifferent sex-species sets) for the aromatic amines data sets.

Predictive Models for Carcinogenicity and Mutagenicity 75
Next, the predictive ability of the QSAR methods was evaluated using thelarger data sets contained in the Carcinogenic Potency Database (CPDB) (47).Each sex-species dataset contained ∼600–750 noncongeneric chemicals. Thefraction of carcinogenic compounds for each data set were 47%, 45%, 43%, and44% for the male rat, female rat, male mouse, and female mouse sex-speciesdatasets, respectively. The QSAR methods of Martin and coworkers achievedprediction concordances of about 61–63%, sensitivities of 48–60%, and speci-ficities of 65–73% (averaged over the different sex-species sets) from 5-foldcross-validations. The results achieved for the CPDB were similar to thoseachieved by QSAR-based approaches in the two NTP training exercises (74).
It has been suggested that in order to successfully model large, noncon-generic carcinogenicity data sets, one should develop a series of more focussedQSAR models (75). To test this strategy the predictive ability of class-specificmodels was compared with the predictive ability of the noncongeneric QSARmethods described above. The training set for each of the class-specific modelsconsisted of only the chemicals in that particular class while for the noncon-generic QSAR methods the training data for the different classes were pooledtogether. The comparison was performed using a data set of 280 chemicalstaken from the NTP database (75). Benigni and Richard assigned the chemi-cals in the NTP data set to ten different structural classes (e.g., electrophilicalkylating agents and halogenated aliphatic compounds). The data set wasseparated randomly into training (80%) and prediction sets (20%) 10 times.Sampling was done so that there was an equal number of cancer and non-cancer scores for each chemical class (for both the training and prediction sets).The results for the 10 different prediction sets were pooled together. The class-based models achieved an average prediction concordance of about 58%. Thehierarchical and nearest-neighbor methodologies achieved slightly lower pre-diction concordances of 55% and 57%, respectively. These results indicate thatit may be possible to correlate noncongeneric datasets without manually di-viding the datasets into classes (although one could argue that the results areinconclusive due to the low prediction concordances). The prediction concor-dances were lower for the NTP data set compared with the CPDB and aromaticdata sets because composite cancer scores were modelled.
INCORPORATING NEW AND TRADITIONAL DATA INTO A NEWSCENARIO
Carcinogenicity and Mutagenicity Data: New Initiatives toImprove Access and Utility for Modelling
A number of new initiatives are underway to improve access to exist-ing public carcinogenicity and mutagenicity data for use in modelling, to

76 E. Benfenati et al.
encourage use of less summarized activity classifications, to create linkagesand structure-searchable access to publicly available sources of toxicity data,and to infuse new types of high-throughput biological test data (i.e., biochemi-cal, cell-based, etc.) along with chemical structure considerations into the pre-diction modelling paradigm (76, 77). These various initiatives offer the promiseof moving the current paradigm for toxicity prediction toward one that can beapplied more broadly and confidently to larger swaths of chemical space andto a greater diversity of toxicity endpoints (78).
Current structure-based SAR models for prediction of chemical carcino-genicity and mutagenicity rely on a relatively small number of publicly avail-able data resources in which the data being modelled are typically highlysummarized and aggregated representations of the actual experimental re-sults (i.e., positive and negative calls) (79). The Berkeley Carcinogenic PotencyDatabase (CPDB) (47), which includes bioassay results for more than 1500 sub-stances curated from literature reports, has been commonly employed in thisway for past SAR modelling studies. EPA’s DSSTox Database Network (23)offers elaborated and quality reviewed structure-data file (SD file) represen-tations of public toxicity data sets, such as the CPDB–All Species (CPDBAS)Summary Tables (48) as well as expanded data linkages and coverage of chem-ical space for carcinogenicity and mutagenicity. In particular, the most recentlypublished DSSTox CPDBAS SD file includes a number of new species-specificsummary activity fields, along with a species-specific normalized score for car-cinogenic potency (TD50) and sex/species-specific tumor incidences (80). To fur-ther facilitate use of these summary activity fields and associated data withinthe CPDBAS data file, these chemical structure-associated data have been de-posited in the large, publicly available PubChem database (81) as seven “bioas-says” or PubChem AIDs (PubChem Assay Identifiers); i.e., AIDs for CPDBASMutagenicity, Rat, Mouse, Hamster, Dog Primates, SingleCellCall, and Mul-tiCellCall. Separate indexing of component activity classifications within thePubChem system allows a user to take full advantage of the tools and capa-bilities within PubChem for “read-across” and SAR clustering in bioassay andstructure space; i.e., allowing for comparisons of CPDB compounds across theentire PubChem inventory (millions of compounds, hundreds of assays).
The entire DSSTox published data file inventory (>16,000 records, >8,000unique compounds) has been deposited/updated within PubChem, enabling auser to cross-reference between the two systems. A user can now link directlyfrom PubChem substance and bioassay listings to DSSTox data files, docu-mentation, and Source chemical data pages where available (e.g., to the CPDBor National Toxicology Program online chemical data pages). Having estab-lished this direct correspondence between PubChem and DSSTox CIDs (Com-pound/structure IDs), the DSSTox Structure-Browser (82) now incorporates adirect link from the DSSTox structure-search results page to the correspondingPubChem Compound (CID) summary results page, allowing less experienced

Predictive Models for Carcinogenicity and Mutagenicity 77
users (e.g., toxicologists, risk assessors) to directly access relevant PubChembioassay information, links, and data for similar substances.
The concept of chemical “toxicity profiling” has gained new prominenceand importance in the field of toxicity prediction and recently has been rec-ommended as a long-term goal for toxicity screening and assessment by aprominent advisory committee and U.S. government agencies (83, 84). Tox-icity profiling can occur at two levels: (1) profiles of in vivo responses aremade possible by increasing availability of detailed observational data and ex-perimental measures associated with chronic toxicity studies, and (2) newerin vitro high-throughput screening (HTS) data offer a means for broadly char-acterizing a chemical’s biological profile in terms of target interactions, path-way perturbations, and cellular responses. Several initiatives are currently un-derway to harness legacy toxicity data from diverse domains of study (cancerbioassays, genetic toxicity, developmental and reproductive toxicity, skin sen-sitization, etc.) into hierarchical toxicity data models suitable for building re-lational databases (85, 86). These historical reference data are necessary toanchor and validate new predictive toxicology approaches based on alterna-tive in vitro test methods as well as to eventually move away from current invivo rodent test systems to mechanistic pathway-based test data more directlyrelevant to humans.
The ToxCastTM project within the U.S. EPA’s National Center for Compu-tational Toxicology is a prominent example of a new predictive toxicology ini-tiative that is aggressively harnessing legacy in vivo data as well as employingnew HTS in vitro technologies and toxicity profiling concepts (76, 87). As partof this effort, the ToxRef database has been built to house in vivo toxicity datain standardized data model representations, and it is being populated with ro-dent bioassay study data (chronic, developmental, reproductive) for hundredsof pesticidal active ingredients registered for use in the United States acrossa range of toxicity investigation areas. Public release of various representa-tions of these data, in conjunction with other ToxCastTM data, occurred in late2008, through venues such as DSSTox and PubChem, and the new EPA AC-ToR (Aggregated Computational Toxicology Resource) system (88, 89), whichwill house all ToxCastTM data as well as supporting publicly available data.Phase I of the ToxCastTM effort is generating data in hundreds of HTS bio-chemical and cell-based assays for 320 selected compounds, mostly pesticidalactives (90), for which a rich profile of toxicity data exists within ToxRef orother public sources. The goal is to develop candidate predictive signatures forvarious toxicity endpoints to undergo further testing and validation in PhaseII.
Microarray data (i.e., information on the changes in gene expression ofmany genes) are becoming more available each year, and structure-annotateddata bases containing such information will soon be available for general use.The complex array of genes that are mutated or whose expression is modulated

78 E. Benfenati et al.
is only incompletely understood at this point. However, microarray data, alongwith epigenetic and genetic data, will permit a more precise modelling of thecancer process and improve predictive toxicology in silico.
The generation of large amounts of new HTS and in vitro data, coupledwith enrichment and elaboration of reference in vivo toxicity data in the publicdomain, offer new challenges and opportunities to SAR modellers. AlthoughSAR modelling has had many successes and has been an extremely valuabletool for toxicity screening and prioritization in the absence of biological data,the limitations of a structure-only approach to prediction are well known andenumerated in the literature. In general, chemical class-based approaches thatoffer a greater chance of mechanistic coherence can be applied more confidentlyto prediction, but in a narrow range of chemical space. In contrast, global SARprediction approaches can be applied more broadly, albeit usually with lessconfidence. The concepts of chemical similarity and chemical class can be use-fully employed in the new paradigm to focus investigation on regions of HTSactivity space, exploring differences within the space. By the same token, clus-ters within HTS activity profile space (such as in a heat map representation)can be projected onto chemical space, potentially implicating members of mul-tiple chemical classes and offering new SAR hypotheses for further investiga-tion. HTS, or “fast biology” results can also potentially be employed as “biolog-ical descriptors” in a traditional QSAR paradigm; i.e., coupled with traditionalchemical descriptors for SAR/QSAR model construction (91).
Finally, adding layers of richness to data model representations of legacyin vivo toxicity results, such as in the ToxRef database, yields a great variety ofnew activity profile representations, or “endpoints,” for use in guiding and an-choring SAR and HTS predictive toxicology investigations. A smaller region ofchemical space associated with a more focused activity profile, in turn, is likelyto be offset by the greater potential mechanistic coherence of the data and,therefore, greater potential for modelling and prediction success. The effectiveincorporation of SAR concepts into ToxCastTM and similar toxicity modellingefforts will be crucial for their ultimate success.
Two Case Studies of Data-mining in a New, Broader ScenarioThese case studies describe the approaches investigated within regulatory
agencies to go beyond the traditional QSAR paradigm for predictive toxicologyand to include biology more explicitly into the QSAR process.
Case Study 1: Genetic Toxicity Data-mining with IntegratedDatabase
The predictive data-mining methodology was applied to data from vari-ous regulatory agencies and industry partners. Some findings from this case

Predictive Models for Carcinogenicity and Mutagenicity 79
study were recently published (92) in which the FDA CRADA SAR (Cooper-ative Research and Development Agreement Structure Activity Relationship)genetic toxicity database (2006 version) was integrated with proprietary indus-try data. The proprietary data were shared by Leadscope structural featuresstatistics without the actual connection tables. The 3220 chemicals in this in-tegrated database were 30% drugs, 22% food ingredients, and 48% industrialchemicals, the latter including agricultural chemicals. Various data sourceswere integrated according to the ToxML criteria (80, 86). For compounds to bescored for assessment (e.g., test calls), ToxML requires the data to be accom-panied by information on test system, including conditions such as controls,dosage regimen, and cytotoxicity (92). The ToxML data model and data entrytool (ToxML Editor) are freely and publicly available (93). The genetic toxic-ity profile of these chemicals was analyzed by structural features across thevarious strains of Salmonella typhimurium reverse mutagenesis (Salmonellamutation), mouse lymphoma mutation, in vitro chromosome aberration (ivtCA), and in vivo micronucleus (micronucleus).
Structural features associated with point mutations—in particular, basesubstitutions or frame shifts—were found. For example, alkyl halides arehighly correlated with mutagenicity in all Salmonella strains, whereas arylhalides are not. Well-known groups such as epoxides, nitro, nitroso, andquinines are highly associated with all four genetic toxicity endpoints. Onthe other hand, structural features such as azo, benzimidazole, and quinolinesare correlated with mutagenicity but not with clastogenicity. Features such asalkenyl ketones, aryl aldehyde, pyrazine (H), and base nucleosides are associ-ated only with clastogenicity. When the four genetic toxicity outcomes are cor-related using the structural features, two mutagenicity tests using Salmonellaand mouse lymphoma correlated well. Salmonella mutagenesis outcome alsocorrelated well with that of in vitro chromosome aberrations. However, in vivomicronucleus did not correlate well with in vitro chromosome aberrations. If achemical is ivt CA negative, it will probably be micronucleus negative. It is im-portant to note that these genetic toxicity screening tests should be used moreas a profile rather than as an individual predictor for carcinogenicity. Thesestructural features can be further refined to form structural alerts grouped bychemical reactivity.
Structural alerts representing positive carcinogenicity/negative genotox-icity were extracted from the data set. Many structural alerts for genotoxiccarcinogens for general industrial chemicals were consistent with literatureresults (94). The landscape of these alerts changed significantly when thestructure space changed from industrial chemicals toward drugs. Several newstructural alerts representing non-genotoxic carcinogens were presented. Oneof the structural alerts included the statin analogs.
To further understand the biology of the statins, various target or-gan lesions from the chronic studies were compared with the SAR-ready

80 E. Benfenati et al.
carcinogenicity database (45). In chronic studies, liver lesions included cen-trilobular necrosis, hypertrophy, and vacuolar degeneration of perilobular hep-atocytes, cellular atypia, fatty change, and bile duct hyperplasia. Liver organweight increases and ALT/AST enzyme level increases were also noticed dur-ing the chronic studies. These statin analogs also showed thyroid lesions, thy-roid organ weight increase, and CPK enzyme increase. In the carcinogenicitydatabase, adenoma, carcinoma, and fibrosarcoma of liver were observed as wellas thyroid follicular cell adenoma. The increased incidence of liver and thyroidtumors is connected by a well-known mechanism of thyroid-stimulating hor-mone instigating the liver microsomal enzymes (95). The same connection wasalso reported previously from data-mining the CPDB database (96). As pre-sented in this case, understanding non-genotoxic carcinogens requires under-standing of biological mechanisms involved in target organ effects. Therefore,a quality database providing in-depth target organ findings in chronic studiesalong with the carcinogenicity and genetic toxicity data can be vitally impor-tant to further our knowledge of carcinogens.
Case Study 2: NTP High throughout Screening andUnderstanding Genotoxicity and Carcinogenicity
One of the questions that can be posed of a database of genetic toxic-ity screening tests is whether the current genetic toxicity tests sufficientlyreflect the different mechanisms involved in carcinogenesis. In this regard,the HTS campaign initiated by the U.S. National Toxicology Program (NTP)is worth discussing. The objectives of that project are to develop methods toscreen and prioritize the nomination of chemicals for rodent bioassays andto look for approaches to gain insights on mode-of-actions for various toxi-city endpoints. Potentially, some of these data and methods can lead to im-provements in predictive toxicology. NTP initially selected 1408 chemicals andtested against 24 bioassays. The chemicals included food ingredients (13%),agricultural chemicals (17%), drugs and hormones (20%), and general indus-trial chemicals (50%). The 24 bioassays included caspase and kinase activi-ties of NCGC cell lines (3T3, BJ, SHSY5, H4IIe, Hek293, HepG2, HUVEC,Jurkat, N2A,,IkB signalling protein, JNK Alpha), and SKNSH, MRC5, Renal,and Mesenchymal assays. The bioassay panel also includes 7 FRED and 13NCGC strains for cell viability (97).
When compounds were clustered against the bioassays and cell viabilities,most of the compounds were not differentiated by activities; however, someblocks of chemicals did separate based on cell viabilities. The differentiationof cell viabilities and activities against compounds increased markedly whenthe observations were based on smaller units of structural features (i.e., frag-ments of molecules) rather than individual compounds. Using cell viabilityto probe for rodent acute toxicity, biological and chemical fingerprints were

Predictive Models for Carcinogenicity and Mutagenicity 81
investigated. The bioassay profile also has been compared with the genotox-icity and carcinogenicity endpoints. Of the 1408 chemicals, 543 had rodentcarcinogenicity data, 1112 had Salmonella data, 344 had mammalian muta-genesis data, 428 had ivt CA data, and 223 had micronucleus data withinthe database sources mentioned above. At the compound level, there were toomany missing values to permit meaningful correlations between the bioassaysand toxicity data (i.e., too few cases where the same compound had all types ofassay data across the data sources).
When the observations were based on structural features and statisticswere recalculated, the trends reported previously among the four genetic tox-icity tests in the first data-mining case study were again observed. Struc-tural features correlating either positively or negatively across the differentendpoints were selected to recalculate the statistics. Based on the 1408 dataset, Salmonella mutagenesis (R = 0.52) and in vitro chromosome aberra-tions (R = 0.39) showed some correlations to rodent carcinogenicity, in whichrodent carcinogenicity was defined as induction of tumors in both rat andmouse.
From this method, structural features positive for both rodent carcino-genicity and genotoxicity included aromatic amines, azo, epoxides, halides,and nitroso/nitrosamine. Pyridine (H) was found to correlate more with non-genotoxic carcinogens. Genotoxic but not carcinogenic features included alkylnitro, benzimidazole, quinoline, and 1,4-diamino benzene features. These re-sults are quite consistent with earlier reports on the classes of rodent carcino-genicity (98, 99). Using the feature analyses, a compound-class–driven cate-gorization of the correlations between bioassays and toxicity endpoints wasconducted by 2-D clustering of correlations between the various toxicity andbioassays. A heat-map generated from these data was used to tease out par-ticular biological assays correlating highly with rodent carcinogenicity for aspecific set of compound classes.
To summarize, a battery of genotoxicity screening tests can be used forprofiling compounds to understand carcinogenicity potential. Structural alertswith genotoxic-carcinogenic outcome probabilities stratified by potency can bedeveloped based on the feature-based methodology. The current NCGC bioas-says from the first NTP HTS campaign may not correlate well with genotoxic-ity and carcinogenicity at a global compound level. However, toxicity of a par-ticular class of chemicals correlates relatively well with some of the biologicalassays. In addition, NTP has expanded their screen to include other cell-basedand activity assays.
The importance of the two case studies presented above is not to emphasizean efficacy of one particular test or assay, but rather to approach the genetictoxicity and carcinogenicity problem in a new way by linking chemical struc-tures to biological effects with the introduction of new molecular-level assaysto yield potential mechanistic insights. In the long run, predictive data-mining

82 E. Benfenati et al.
methods can help in revisiting data, testing strategies, and past presumptionsinvolved in risk assessment.
CONCLUSIONS
In QSAR models for carcinogenicity (mainly) and mutagenicity, there are stilla number of open problems and unresolved issues. Most of these involve thepoint of application (e.g., screening vs. late-stage) and interpretation of soft-ware output. “False positives” generated by programs such as DEREK orMC4PC are greatly reduced by applying expert knowledge that takes into ac-count the chemical context of the alert or biophore, and whether hydrolysis ormetabolism are likely to convert the molecule to a true alert as defined origi-nally and confirmed in the literature. The “false negative” designation, on theother hand, suggests that the learning sets on which the prediction systemswere based initially may lack some essential knowledge. Studies using botha cell-based system and 3-D DNA docking/electrostatic modelling have shownthat many “false negatives” can be explained by non-covalent binding (e.g.,DNA intercalation or groove binding), and that the genotoxicity of such inter-actions is largely the result of topoisomerase II inhibition. This type of chemi-cal/DNA interaction was and still is poorly understood and, consequently, maybe trained inappropriately in the learning sets of the most commonly used insilico programs. Moreover, because most of these putative intercalating agentsdo not possess classical, planar intercalating structures, simple visual inspec-tion does not allow prediction of non-covalent binding to DNA.
In order to significantly improve in silico models for carcinogenicity andmutagenicity, it is crucial to understand and accept that there are still prob-lems with the experimental methods dedicated to study these endpoints. Thus,several of the problems that appear as (Q)SAR problems are actually typicalof the general limitations of the current experimental techniques and state ofthe knowledge. (Q)SAR models, for their part, are more suitable to statisticaltreatment of the data, which highlight their accuracy, sensitivity, specificity,reliability, and predictivity. Different tools are useful, depending on whetherthe model is a classifier (SAR) or a regression model.
In the case of the in vitro models designed to replace in vivo methods, it ismore and more common to have a statistical evaluation for the false positivesand negatives of the method. However, similar objective appraisal is missingin animal models when compared with human toxicity. The extrapolation fromanimal models to humans is not an easy task given the paucity of data on thelatter. In addition, the variability of the in vivo data is poorly described.
These intrinsic scientific problems are complicated by different purposesand intended uses of the models. Models for regulations are strictly linkedto legal specifications that depend on the specific regulation. Even within the

Predictive Models for Carcinogenicity and Mutagenicity 83
same regulation, different possible uses of the modelling tools are possible. Forexample, within the REACH legislation, carcinogenicity has to be described asa category for prioritization and classification and labelling. However, contin-uous quantitative estimates of potency are also needed to estimate the risk ofthe carcinogen within a given scenario of exposure.
There are several possible uses of the in silico models, such as prioritisa-tion, screening, mechanistic studies, and support for risk assessment. Todaythe acceptance of in silico tools and predictive models, some based on incorpo-ration of newer HTS data, for carcinogenicity as alternative methods to in vitroor in vivo testing, is still highly debated, and the varied discussions at theworkshop demonstrated this. One reason for this is the lack of knowledge andexperience produced on the proposed alternative methods. It was mentionedthat even the Ames test, when originally proposed, was severely criticized. De-spite this, after decades, mutagenicity is now a requested endpoint in severalregulations.
It may happen that a scientist strongly supports and advocates for use ofa particular method with which he or she is comfortable. However, the techni-cal, theoretical differences between the different models should have a loweremphasis compared with the advantages for the user and practical utility ofmodels for a certain application. As Galileo said, hypotheses have to be exper-imentally evaluated. In the case of in silico models, they have to be provento work for their intended use. There are at least two possible applications:in silico models can classify potential carcinogens or mutagens or they canpredict a potency from a continuous model, with an estimated confidence in-terval, namely the error range. Depending on the errors in the quantitativepredictions or classifications, the method can be used as a screening tool or asa substitute to in vitro or in vivo testing if the error is acceptable. In the caseof models for regulatory purposes, where conservative measures for ensuringpublic safety is of primary concern, the errors that give rise to false negativesare much more relevant and high specificity is thus critical. The measure ofsensitivity and specificity is much more important than that of concordance.This holds true both for classification and continuous QSAR models. The pre-dicted residuals are more appropriate than just R2.
To cope with the scientific problems of a better understanding and predic-tion of carcinogenicity and mutagenicity, new efforts have to be planned andorganized, integrating different tools, not only in silico. We discussed the newpossibilities of a large screening of chemical substances and some ongoing ini-tiatives. The challenge is to reinforce and expand knowledge on toxicity phe-nomena by introducing and using new experimental data that are more easilygenerated than with the classical in vivo methods. The use of these data ischanging the perspective of toxicity evaluation. The huge amount of data willoffer new ways to explore relationships between data of different origin as acontribution to the understanding of toxicity. In this evolving scenario there

84 E. Benfenati et al.
will be a need for powerful data-mining tools that are capable of extractingknowledge from a complex multidimensional space. New initiatives requiringa paradigm shift are increasing, and the hope is that a better understanding oftoxicity phenomena will be achieved for ensuring safer chemicals and stream-lined, yet protective regulatory procedures.
ACKNOWLEDGEMENTS
We acknowledge the financial support of the European Commission, projectSCARLET, contract no. SP5A-CT-2007-044166. This manuscript has been re-viewed by the National Health and Environmental Effects Research Labora-tory and National Center for Computational Toxicology, U.S. EnvironmentalProtection Agency, and is approved for publication. Approval does not signifythat the contents reflect the views of the Agency, nor does mention of tradenames or commercial products constitute endorsement or recommendation foruse.
REFERENCES
1. StruCture-Activity Relationships Leading ExperTs in mutagenicity and carcino-genicity (SCARLET), European Commission Project SPSA-CT-2007-014166. Availableat: http://scarlet-project.eu
2. Moore, MM, Honma, M, Clements, J, Bolcsfoldi, G, Burlinson, B, Cifone, M,Clarke, J, Delongchamp, R, Durward, R, Fellows, M, Gollapudi, B, Hou, S, Jenkinson, P,Lloyd, M, Majeska, J, Myhr, B, O’Donovan, M, Omori, T, Riach, C, San, R, Stankowski,LF Jr, Thakur, A, Van Goethem, F, Wakuri, S, Yoshimura, I. Mouse Lymphoma Thymi-dine Kinase Gene Mutation Assay: Follow-up Meeting of the International Workshopon Genotoxicity Tests-Aberdeen, Scotland, 2003—Assay acceptance criteria, positivecontrols, and data evaluation. Environ Mol Mutagen 2006;47:1–5.
3. Kirkland, D, Pfuhler, S, Tweats, D, Aardema, M, Corvi, R, Darroudi, F,Elhajouji, A, Glatt, H, Hastwell, P, Hayashi, M, Kasper, P, Kirchner, S, Lynch, A,Marzin, D, Maurici, D, Meunier, J-R, Muller, L, Nohynek, G, Parry, J, Parry, E, Thybaud,V, Tice, R, van Benthem, J, Vanparys, P, White, P. How to reduce false positive resultswhen undertaking in vitro genotoxicity testing and thus avoid unnecessary follow-upanimal tests: Report of an ECVAM Workshop. Mutation Research 2007;628:31–55.
4. Snyder, RD, Ewing, DE, Hendry, LB. Evaluation of DNA intercalation potentialof pharmaceuticals and other chemicals by cell-based and three-dimensional computa-tional approaches. Environ Mol Mutagen 2004;44:163–173.
5. Snyder, RD, Ewing, D, Hendry, L. DNA intercalative potential of marketed drugstesting positive in in vitro cytogenetics assays. Mutation Res 2006;609:47–59.
6. van der Lelie, D, Regniers, L, Borremans, B, Provoost, A, Verschaeve, L. TheVITOTOX©R test, an SOS bioluminescence Salmonella typhimurium test to measuregenotoxicity kinetics. Mutagenesis 1997;20:449–454.
7. Verschaeve, L, Van Gompel, J, Thilemans, L, Regniers, L, Vanparys, P, van derLelie, D. VITOTOX©R bacterial genotoxicity and toxicity test for the rapid screening ofchemicals. Environ Mol Mutagen 1999;33:240–248.

Predictive Models for Carcinogenicity and Mutagenicity 85
8. Van Gompel, J, Woestenborghs, F, Beerens, D, Mackie, C, Cahill, PA, Knight,AW, Billinton, N, Tweats, DJ, Walmsley, RM. An assessment of the utility of the yeastGreenScreen assay in pharmaceutical screening. Mutagenesis 2005;20:449–454.
9. Pastink, A, Eeken, JCJ, Lohman, PHM. Genomic integrity and the repair ofdouble-strand DNA breaks. Mut Res 2001;480-481:37–50.
10. Clever, B, Interthal, H, Schmuckli-Maurer, J, King, J, Sigrist, M, Heyer, W-F. Re-combinational repair in yeast: functional interactions between Rad51 and Rad54 pro-teins. EMBO J 1997;16:2535–2544.
11. Sonoda, E, Sasaki, MS, Buerstedde, J-M, Bezzubova, O, Shinohara, A, Ogawa, H,Takata, M, Yamaguchi-Iwai, Y, Takeda, S. Rad51-deficient vertebrate cells accumulatechromosomal breaks prior to cell death. EMBO J 1998;17:598–608.
12. Arbel, A, Zenvirth, D, Simchen, G. Sister chromatid-based DNA repair is medi-ated by RAD54, not by DMC1 or TID1. EMBO J 1999;18:2648–2658.
13. Dronkert, MLG, Beverloo, HB, Johnson, RD, Hoeijmakers, JHJ, Jasin, M,Kanaar, R. Mouse RAD54 affects DNA Double-strand break repair and sister chromatidexchange. Mol Cell Biol 2000;20:3147–3156.
14. Van Gompel, J, Woestenborghs, F, Beerens, D, Mackie, C, Cahill, PA, Knight,AW, Billinton, N, Tweats, DJ, Walmsley, RM. An assessment of the utility of theyeast GreenScreen assay in pharmaceutical screening. Mutagenesis 2005;20:449–454.
15. Billinton, N, Barker, MG, Michel, CE, Knight, AW, Heyer, W-D, Goddard, NJ,Fielden, PR, Walmsley, RM. Development of a green fluorescent protein reporter for ayeast genotoxicity biosensor. Biosensores Bioelectronics 1998;13:831–838.
16. Cahill, PA, Knight, AW, Billington, N, Barker, MG, Walsh, L, Keenan, PO,Williams, CV, Tweats, DJ, Walmsley, RM. The GreenScreen©R genotoxicity assays: ascreening validation programme. Mutagenesis 2004;19:105–119.
17. Knight, AW, Billinton, N, Cahill, PA, Scott, A, Harvey, JS, Roberts, KJ, Tweats,DJ, Keenan, PO, Walmsley, RM. An analysis of results from 305 compounds tested withthe yeast RAD54-GFP genotoxicity assay (GreenScreen GC)—including relative predic-tivity of regulatory tests and rodent carcinogenesis and performance with autofluores-cent and coloured compounds. Mutagenesis 2007;22:409–416.
18. Cole, GM, Schild, D, Lovett, ST, Mortimer, RK. Regulation of RAD54- andRAD52-lacZ gene fusions in Saccharomyces cerevisiae in response to DNA damage.Mol Cell Biol 1987;7:1078–1084.
19. Averbeck, D, Averbeck, S. Induction of the genes RAD54 and RNR2 by variousdamaging agents in Saccharomyces cerevisiae. Mut Res 1994;315:123–138.
20. Joosten, HFP, Acker, FAA, Dobbelsteen van den DJ, Horbach GJMJ, Krajnc, EI.Genotoxicity of hormonal steroids. Toxicol Lett 2004;151:113–134.
21. International Agency for Research on Cancer (IARC). Available at: http://www.iarc.fr/ENG/Databases/index.php.
22. Zhao, C, Boriani, E, Chana, A, Roncaglkioni, A, Benfenati, E. A new hybridsystem of QSAR models for predicting bioconcentration factor (BCF). Chemosphere2008:73:1701–1707.
23. EPA DSSTox. U.S. Environmental Protection Agency’s Distributed Structure-Searchable Toxicity (DSSTox) Database Network. 2009. Available at: http://www.epa.gov/ncct/dsstox/
24. Benigni, R, Bossa, C, Jeliazkova, NG, Netzeva, TI, Worth, AP. The Benigni/Bossarulebase for mutagenicity and carcinogenicity—a module of Toxtree. Report EUR 23241

86 E. Benfenati et al.
EN. 2008. Luxembourg, Office for the Official Publications of the European Communi-ties. EUR—Scientific and Technical Report Series.
25. Benigni, R, Bossa, C, Netzeva, TI, Worth, AP. Collection and evaluation of(Q)SAR models for mutagenicity and carcinogenicity. EUR 22772 EN. Luxembourg, Of-fice for the Official Publications of the European Communities. EUR—Scientific andTechnical Research Series; 2007.
26. Benigni, R, Bossa, C. Predictivity and reliability of QSAR models: the case ofmutagens and carcinogens. Toxicol Mechanisms Meth 2008;18:137–47.
27. Benigni, R, Netzeva, TI, Benfenati, E, Bossa, C, Rainer, R, Helma, C, Hulzebos, E,Marchant, C, Richard, A, Woo, Y-T, Yang, C. The expanding role of predictive toxicology:an update on the (Q)SAR models for mutagens and carcinogens. J Environ Sci HealthC Environ Carcinog Ecotoxicol Revs 2007;25:53–97.
28. European Partnership for Alternative Approaches to animal testing (EPAA).Available at: http://ec.europa.eu/enterprise/epaa/brochure.htm
29. Brown, D, Superti-Furga, G. Rediscovering the sweet spot in drug discovery. DrugDiscovery Today 2003;8:1067–1077.
30. DiMasi, JA. Risks in new drug development: Approval success rates for investi-gational drugs. Clin Pharmacol Ther 2001;69:297–307.
31. Kola, I, Landis, J. Can the pharmaceutical industry reduce attrition rates? Na-ture Reviews Drug Discovery 2004;3:711–715.
32. Fingerhut, MA, Halperin, WE, Marlow, DA, Piacitelli, LA, Honchar, PA, Sweeney,MH, Greife, AL, Dill, PA, Steenland, K, Suruda, AJ. Cancer mortality in work-ers exposed to 2,3,7,8-tetrachlorodibenzo-p-dioxin. N Engl J Med 1991;324:212–218.
33. Manz, A, Berger, J, Dwyer, JH, Flesch-Janys, D, Nagel, S, Waltsgott, H. Can-cer mortality among workers in chemical plant contaminated with dioxin. Lancet1991;338:959–964.
34. Zober, A, Messerer, P, Huber, P. Thirty-four-year mortality follow-up of BASFemployees exposed to 2,3,7,8-TCDD after the 1953 accident. Int Arch Occup EnvironHealth 1990; 62:139–157.
35. Westerink, WMA, Stevenson, JCR, Schoonen, WGEJ. Pharmacologic profiling ofhuman and rat cytochrome P450 1A1 and 1A2 induction and competition. Arch Toxicol2008;82:909–921. Doi 10.1007/S00204-008-0317-7.
36. Snyder, RD, Smith, MD. Computational prediction of genotoxicity: room for im-provement. Drug Discovery Today 2005;10:1119–1124.
37. Ertl, P, Roggo, S, Schuffenhauer, A. Natural Product-likeness score and its appli-cation for prioritization of compound libraries. J Chem Inf Model 2008;48:68–74.
38. Contrera, JF, Jacobs, AC, DeGeorge, JJ. Carcinogenicity testing and the eval-uation of regulatory requirements for pharmaceuticals. Regul Toxicol Pharmacol1997;25:130–145.
39. CCRIS (Chemical Carcinogenesis Research Information System), developed andmaintained by National Cancer Institute. Available at: http://toxnet.nlm.nih.gov/cgi-bin/sis/htmlgen?CCRIS
40. Gene-Tox: Created by US, EPA. Available at: http://toxnet.nlm.nih.gov/cgi-bin/sis/htmlgen?GENETOX
41. National Toxicology Program (NTP). Available at: http://ntp.niehs.nih.gov

Predictive Models for Carcinogenicity and Mutagenicity 87
42. International Programme on Chemical Safety (IPCS). INCHEM, a product co-operation between the International Programme on Chemical Safety (IPCS) andthe Canadian Centre for Occupational Health and Safety (CCOHS). Available at:http://www.inchem.org/
43. IRIS EPA. Integrated risk information system for carcinogen classification, orig-inally prepared in US EPA. Available at: http://www.epa.gov/iris/index.htm
44. FDA Cooperative Research and Development Agreemen) database. Leadscope.Available at: http://www.leadscope.com/fda databases/
45. Tokyo-Eiken, Tokyo Metropolitan Institute of Public Health providing primarymutagenicity of food additives for about 300 chemicals. Available at: http://www.tokyo-eiken.go.jp/henigen/
46. The Mutants, a database of mutagenicity/genetic toxicity database spon-sored by Dr. Motoi Ishidate. Available at: http://members.jcom.home.ne.jp/mo-ishidate/index.html
47. CPDB Summary Tables. Summary Table of Chemicals in the Carcinogenic Po-tency Database: Results for Positivity, Potency (TD50), and Target Sites. 2007. Avail-able at: http://potency.berkeley.edu/chemicalsummary.html
48. Gold, LS, Slone, TH, Williams, CR, Burch, JM, Stewart, TW, Swank, AE, Bei-dler, J, Richard, AM. DSSTox Carcinogenic Potency Database Summary Tables—AllSpecies, SDF Files and Documentation, CPDBAS v5c 1547 20NOV2008. 2008. Avail-able at: http://www.epa.gov/ncct/dsstox/sdf cpdbas.html
49. Benigni, R, Bossa, C, Richard, AM, Yang, C. A novel approach: chemical rela-tional databases, and the role of the ISSCAN database on assessing chemical carcino-genicity. Ann Ist Super Sanita 2008; 44:48–56.
50. Leadscope Inc., Ohio, USA. http://www.leadscope.com
51. Lhasa Limited, Leeds, UK. http://www.lhasalimited.org/
52. RTECS, Registry of toxic effects of chemical substances, created by NIOSH,maintained and marketed by MDL Symix. Available at: http://mdl.com/products/predictive/rtecs/index.jsp
53. MultiCASE MC4PC. Available at: http://www.multicase.com/products/prod01.htm
54. TOPKAT. Available at: http://accelrys.com/products/discovery-studio/toxicology/
55. MDL QSAR. Available at: http://www.mdl.com/products/predictive/qsar/index.jsp
56. Leadscope FDA Model Applier. Available at: http://www.leadscope.com/productinfo.php?products id=66
57. OncoLogic. A computer system to evaluate the carcinogenic potential of chemi-cals. Available at: http://www.epa.gov/oppt/newchems/tools/oncologic.htm
58. LAZAR (Lazy Structure Activity Relationship). Available at: http://www.predictive-toxicology.org/lazar/
59. Toxtree. Available at: http://ecb.jrc.it/qsar/
60. Benigni, R. Structure-activity relationship studies of chemical mutagens andcarcinogens: mechanistic investigations and prediction approaches. Chem Revs2005;105:1767–1800.
61. Sello, G, Sala, L, Benfenati, E. Predicting toxicity: A mechanism of actionmodel of chemical mutagenicity. Mutat Res Fundam Mol Mech Mutag 2001;479:141–171.

88 E. Benfenati et al.
62. Fung, VA, Huff, J, Weisburger, EK, Hoel, DG. Predictive strategies for select-ing 379 NCI/NTP chemicals evaluated for carcinogenic potential: scientific and publichealth impact. Fund Appl Toxicol 1993;20:413–36.
63. Benigni, R. Structure-activity relationship studies of chemical mutagens andcarcinogens: mechanistic investigations and prediction approaches. Chem Revs2005;105:1767–800.
64. Benigni, R, Bossa, C. Predictivity of QSAR. J Chem Inf Model. 2008;48:971–980.
65. Piegorsch, WW, Zeiger, E. Measuring intra-assay agreement for the AmesSalmonella assay. In: Rienhoff, O, Lindberg DAB (Eds.), Lecture Notes in Medical In-formation (Statistical Methods in Toxicology), Springer-Verlag, Berlin; 1991: 35–41.
66. OECD. The Report from the Expert Group on (Quantitative) Structure ActivityRelationship ([Q]SARs) on the Principles for the Validation of (Q)SARs. 49Paris, OECD.OECD Series on Testing and Assessment; 2004.
67. Katzius, J, McGuire, R, Bursi, R. Derivation and validation of toxicophores formutagenicity prediction. J Med Chem 2005;48:312–320.
68. Ferrari, T, Gini, G. A new Predictive Model of Mutagenicity, with statisti-cal analysis and validation using data-mining tools in WEKA. Poster presented atSCARLET workshop, April 2–4, 2008, Milan, Italy. Available at: http://www.scarlet-project.eu/posters/Ferrari T-scarlet.pdf
69. Toropov, AA, Toropova, AP, Benfenati, E. QSAR modelling of carcinogenicityand mutagenic potentials by optimal SMILES-based descriptors. Poster presented atSCARLET workshop, April 2–4, 2008, Milan, Italy. Available at: http://www.scarlet-project.eu/posters/Toropov A-scarlet.pdf
70. Martin, TM, Harten, P, Venkatapathy, R, Das, S, Young, DM. A hierarchical clus-tering methodology for the estimation of toxicity. Toxicol Mech Method 2008;18:251–266.
71. Romesburg, HC. Cluster Analysis for Researchers. Belmont, CA: Lifetime Learn-ing Publications; 1984.
72. Contrera, JF, Matthews, EJ, Benz, RD. Predicting the carcinogenic potential ofpharmaceuticals in rodents using molecular structural similarity and E-state indices.Regulat Toxicol Pharmacol 2003;38:243–259.
73. Franke, R, Gruska, A, Giuliani, A, Benigni, R. Prediction of rodent carcinogenic-ity of aromatic amines: a quantitative structure-activity relationships model. Carcino-genesis 2001;22 (9):1561–1571.
74. Bristol, DW, Wachsman, JT, Greenwell, A. The NIEHS Predictive-ToxicologyEvaluation Project. Environ Health Persp 1996;104(Supplement 5):1001–1010.
75. Benigni, R, Richard, AM. QSARS of mutagens and carcinogens: Two case studiesillustrating problems in the construction of models for noncongeneric chemicals. MutatRes 1996;371:29–46.
76. Dix, DJ, Houck, KA, Martin, TM, Richard, AM, Setzer, W, Kavlock, RJ. TheToxCastTM program for prioritizing toxicity testing of environmental chemicals. ToxSci 2007;95:5–12.
77. Richard, AM, Yang, C, Judson, R. Toxicity Data Informatics: Supporting a NewParadigm for Toxicity Prediction. Tox Mech Meth 2008;18:103–118.
78. Richard, AM. Future of Predictive Toxicology: An Expanded View of “Chem-ical Toxicity”—Future of Toxicology Perspective. Chem Res Toxicol 2006;19:1257–1262.

Predictive Models for Carcinogenicity and Mutagenicity 89
79. Richard, AM, Williams, CR. Public sources of mutagenicity and carcinogenicitydata: Use in structure-activity relationship models. In: Benigni R (Ed.), QSARs of Mu-tagens and Carcinogens. New York: CRC Press; 2002:145–173.
80. Richard, AM, Yang, C, Judson, R. Toxicity Data Informatics: Supporting a NewParadigm for Toxicity Prediction. Tox Mech Method 2008;18:103–118.
81. NCBI PubChem. National Institutes of Health, National Library of Medicine,National Center for Biotechnology Information, PubChem Project. 2007. Available at:http://pubchem.ncbi.nlm.nih.gov/
82. Transue, T, Richard, AM. U.S. Environmental Protection AgencyDSSTox Structure-Browser v2.0. 2008. Available at: http://www.epa.gov/dsstoxstructurebrowser/
83. National Research Council (NRC). Toxicity Testing in the 21st Century: A Visionand a Strategy. Washington, DC: National Academies Press; 2007.
84. Collins, FS, Gray, GM, Bucher, JR. Transforming Environmental Health Protec-tion. Science 2008;319: 906–907.
85. Martin, TM, Houck, KA, McLaurin, K, Richard, AM, Dix, DJ. Linking Regu-latory Toxicological Information on Environmental Chemicals with High-ThroughputScreening (HTS) and Genomic Data. The Toxicologist CD. J Soc Toxicol 2007;96:219–220.
86. Yang, C, Benz, RD, Cheeseman, MA. Landscape of current toxicity databases anddatabase standards. Curr Opin Drug Discovery Develop 2006;9:124–133.
87. Houck, K, Dix, D, Judson, R, Martin, M, Wolf, M, Kavlock, R, Richard, AM.DSSTox EPA ToxCast High Throughput Screening Testing Chemicals Structure-IndexFile: SDF File and Documentation: TOXCST v3a 320 12FEB2009. 2008. Available at :http://www.epa.gov/ncct/dsstox/sdf toxcst.html.
88. Judson, R, Richard, AM, Dix, D, Elloumi, F, Martin, M, Cathey, T, Transue, T,Spencer, R, Wolf, M. ACToR—Aggregated Computational Toxicology Resource. ToxicolAppl Pharmacol 2008;233:7–13.
89. ACToR. Aggregated Computational Toxicology Resource. Available at: http://actor.epa.gov/actor/
90. EPA ToxCast. U.S. Environmental Protection Agency’s National Center for Com-putational Toxicology ToxCastTM Program. 2009. Available at: http://www.epa.gov/comptox/toxcast/
91. Zhu, H, Rusyn, I, Richard, AM, Tropsha, A. The Use of Cell Viability AssayData Improves the Prediction Accuracy of Conventional Quantitative Structure Activ-ity Relationship Models of Animal Carcinogenicity. Enviro Health Persp 2008;116:506–513.
92. Yang, C, Arnby, CH, Arvidson, K, Aveston, S, Benigni, R, Benz, RD, Boyer, S,Contrera, J, Dierkes, P, Han, X, Jaworska, J, Kemper, RA, Kruhlak, NL, Matthews, EJ,Rathman, JF, Richard, AM. Understanding Genetic Toxicity through Data-mining: TheProcess of Building Knowledge by Integrating Multiple Genetic Toxicity Databases. ToxMech Method 2008;18:277–295.
93. Leadscope Inc. ToxML editor. Ohio, USA. http://www.leadscope.com/toxml editor.
94. Ashby, J. Fundamental structural alerts to potential carcinogenicity or non-carcinogenicity. Environ Mutagen 1985;7:919–921.
95. Klassen, CD. Casarett & Doull’s Toxicology: The basic science of poisons. NewYork: McGraw-Hill; 1996.

90 E. Benfenati et al.
96. Yang, C, Richard, AM, Cross, KP. The Art of Data-mining the Minefields of Toxic-ity Databases to Link Chemistry to Biology. Curr Comp-Aided Drug Design 2006;2,135–150.
97. Xia, M, Huang, R, Witt, KL, Southall, N, Fostel, J, Choi, MH, Jadhav, A, Smith,CS, Inglese, J, Portier, CJ, Tice, RR, Austin, CP. Compound Cytotoxicity Profiling Us-ing Quantitative High-Throughput Screening, Environ Health Persp 2008;116-284-291.Available at: http://www.ehponline.org.
98. Gold, LS, Bernstein, L, MaGaw, R, Slone, TH. Interspecies extrapolation in car-cinogenesis: Prediction between rats and mice. Environ Health Persp 1989;81:211–219.
99. Benigni, R, Giuliani, A, Franke, R, Gruska, A. Quantitative structure-activity relationships of mutagenic and carcinogenic aromatic amines. Chem Revs2000;100:3697–3714.
Related Documents











