Modelling the relationship between diatom abundances and physico-chemical parameteres in Lake Prespa Andreja Naumoski 1 , Dragi Kocev 2 , Nataša Atanasova 3 , Kosta Mitreski 1 , Svetislav Krstić 4 , Sašo Džeroski 2 1 Faculty of Electrical Engineering and Information Technology, Skopje, Macedonia [email protected], [email protected] 2 Dept. of Knowledge Technologies, Jožef Stefan Institute, Ljubljana, Slovenia [email protected], [email protected] 3 Inst. of Sanitary Engineering, Faculty of Civil Engineering, University of Ljubljana, Slovenia [email protected] 4 Institute of Biology, Faculty of Natural Sciences and Mathematics, Skopje, Macedonia, [email protected] Abstract: In this work, we address the problem of predicting the relationship between the physico-chemical parameters of water quality from bioindicator data (diatom species abundance data). A chemical situation of the water (or water class) is defined with the values of the measured physico-chemical parameters. Traditional approach to model these data is to learn a separate model for each parameter and then derive a global overview with some kind of summarization over the multiple models. Another approach is to learn single model that describes all parameters (multi target approach). We explore these approaches and apply them on data from Lake Prespa and its tributary rivers. The obtained models revealed interesting connections between the diatom species and the water quality (i.e. the values of the chemical parameters). Some of the models express the existing ecological knowledge about the diatoms, but some of the models reveal new knowledge about the lake. Further investigation is encouraging to continue in several direction using multi-target data mining techniques, such as reconstruction of several aspects of the ecosystem past history, investigate the impact of the climate change or reconstruct the environmental patterns for certain chemical parameters. Keywords: diatoms, Lake Prespa, decision trees, bioindicator, physico-chemical 1. Introduction 1 1 2 3 4 5 6 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 2

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript
PREDICTING CHEMICAL PARAMETERES OF WATER QUALITY FROM DIATOMS ABUDANCE IN LAKE PRESPA AND ITS TRIBUTARIES
Modelling the relationship between diatom abundances and physico-chemical parameteres in Lake Prespa
Andreja Naumoski1, Dragi Kocev2, Nataša Atanasova3, Kosta Mitreski1,
Svetislav Krstić4, Sašo Džeroski2
1 Faculty of Electrical Engineering and Information Technology, Skopje, Macedonia
[email protected], [email protected]
2 Dept. of Knowledge Technologies, Jožef Stefan Institute, Ljubljana, Slovenia
[email protected], [email protected]
3 Inst. of Sanitary Engineering, Faculty of Civil Engineering, University of Ljubljana, Slovenia
4 Institute of Biology, Faculty of Natural Sciences and Mathematics, Skopje, Macedonia, [email protected]
Abstract: In this work, we address the problem of predicting the relationship between the physico-chemical parameters of water quality from bioindicator data (diatom species abundance data). A chemical situation of the water (or water class) is defined with the values of the measured physico-chemical parameters. Traditional approach to model these data is to learn a separate model for each parameter and then derive a global overview with some kind of summarization over the multiple models. Another approach is to learn single model that describes all parameters (multi target approach). We explore these approaches and apply them on data from Lake Prespa and its tributary rivers. The obtained models revealed interesting connections between the diatom species and the water quality (i.e. the values of the chemical parameters). Some of the models express the existing ecological knowledge about the diatoms, but some of the models reveal new knowledge about the lake. Further investigation is encouraging to continue in several direction using multi-target data mining techniques, such as reconstruction of several aspects of the ecosystem past history, investigate the impact of the climate change or reconstruct the environmental patterns for certain chemical parameters.
Keywords: diatoms, Lake Prespa, decision trees, bioindicator, physico-chemical
1. Introduction
High population densities and the multiplicity of industrial and agricultural activities expose most hydrographical basins close to urban centres to heavy and rising environmental impacts. Usual approaches to water quality evaluation are divided in two main categories. One based on physical and chemical methods, and another considering biological community’s evaluation (Salomoni et al, 2006). Physical and chemical monitoring reflects only instantaneous measurements, restraining the knowledge of water conditions to the moment when the measurements were performed. Biotic parameters on the other hand provide better evaluation of environmental changes, because community development integrates a period of time reflecting conditions that might not be anymore present at the time of sampling and analysis.
Typical representatives for biological indicators usually are taxonomic organisms that are influenced by the physico-chemical parameters of the environment (as specified in the guidelines of the water quality standard), such as diatoms (specific algae species) (McCormick and Caims, 1994; Lowe and Pan, 1996; Krstic et al., 2007). Diatoms have many properties, which are required for organisms that can be used as bioindicators for environmental changes in aquatic ecosystems (Gold et al., 2002). Because of this, they are widely studied to discover relationships between diatoms and different ecological states of the ecosystems. Mainly, they are used to search for a correlation between their abundance and the eutrophication levels, as individual species of diatoms are sensitive to changes in nutrient concentrations and supply rates (Tilman, 1977; Tilman et al. 1982; Hall and Smol, 1992; Reavie et al., 1995; Fritz et al., 1993; Bennion, 1994, 1995; Bennion et al., 1996). Also, there are studies to connect the presence of diatoms with presence of metals in the ecosystem (Gold et al., 2002).
The Prespa Park (a transboundary park bordering Macedonia, Albania and Greece) is well known for its great biodiversity, natural beauty and populations of rare water birds. However, the ecological integrity of the region is threatened by the increasing exploitation of the natural resources (inappropriate water management, forest destruction leading to erosion, overgrazing), inappropriate land use practices, ecologically unsound irrigation practices, water and soil contamination from uncontrolled use of pesticides, lake siltation and uncontrolled urban development. Monitoring of the state of Lake Prespa is necessary to prevent major catastrophes in the Prespa ecosystem.
An attempt for intensive monitoring was made within the EU funded project TRABOREMA. The monitoring comprised measurements that reflect the physical, chemical and biological aspects of the lake ecosystem (Levkov et al., 2006; Krstic and Levkov, 2007). These measurements comprise relative abundances of 116 diatom species, and parameters such as temperature, pH, total phosphorus, nitrogen etc (see Table 1). The results of the monitoring revealed great amount of data about the lake ecosystem, but unfortunately, they are limited to the project duration. So, constant monitoring should be performed to keep the system in good ecological state. As this is not the case with Lake Prespa, we focus our research in constructing models (using machine learning techniques) that reveal the relationships between abundance of diatoms and physico-chemical parameters, and consequently the water quality and overall ecosystem’s health. These models can be used for the appropriate decision making process and easier management of the lake.
Typically in this area, classical statistical modelling approaches, such as PCA and CCA (Stroemer and Smol, 2004), are most commonly applied. Although these techniques provide very useful insights in the data, they are limited in terms of interpretability. On the other hand, decision trees (CART) are very easy to interpret, fast to induce and they are non-parametric. They are one of the most widely used machine learning techniques.
Having in mind that there are multiple physico-chemical parameters (in statistical terminology, multiple responses or multiple dependant variables), we investigate two scenarios: (1) induce a regression tree (RT) (Breiman et al, 1984) for each physico-chemical parameter separately and (2) induce a multi-target regression tree (MTRT) (Blockeel et al, 1998; Struyf and Dzeroski, 2006) to predict multiple parameters simultaneously. The advantages of the latter approach are that the obtained MTRT is smaller than the sum of the RTs for each physico-chemical parameter and that the MTRT is able to capture and explicate the dependencies between the observed physico-chemical parameters (Struyf and Dzeroski, 2006).
The remainder of this paper is organized as follows. In Section 2, we describe the machine learning methodology that was used (regression trees and multi-target regression trees). Section 3 describes the data and Section 4 explains the experimental design that was employed to analyse the data at hand. In Section 5, we present the obtained WQ models and discuss them. Section 6 gives the main conclusions.
2. Methodology
2.1 Regression Trees
Regression trees are decision trees that are capable of predicting the value of a numeric target variable (Breiman et al. 1984). They are hierarchical structures, where the internal nodes contain tests on the input attributes. Each branch of an internal test corresponds to an outcome of the test, and the predictions for the values of the target attribute are stored in the leaves. Regression tree leaves contain constant values as predictions for the target variable (they represent piece-wise constant functions).
To obtain the prediction of a regression tree for a new data record, the record is sorted down the tree, starting from the root (the top-most node of the tree). For each internal node that is encountered on the path, the test that is stored in the node is applied, and depending on the outcome of the test, the path continues along the corresponding branch (to the corresponding subtree). The procedure is repeated until we end up in a leaf. The resulting prediction of the tree is taken from this leaf.
The tests in the internal nodes can have more than two outcomes (this is usually the case when the test is on a discrete-valued attribute, where a separate branch/subtree is created for each value). Typically, each test has two outcomes: the test has succeeded or the test has failed. The trees in this case are called binary trees.
2.2. Multiple Targets Regression Trees
Multi-target regression trees are an instantiation of predictive clustering trees (PCTs) (Blockeel et al. 1998), where a tree is viewed as a hierarchy of clusters. The top-node of a PCT corresponds to a cluster that contains all the data. This cluster is then recursively partitioned into smaller clusters while moving down the tree. The leaves represent the clusters at the lowest level of the hierarchy and each leaf is labeled with its prototype.
Multi-target regression trees (Blockeel at al. 1998; Struyf and Džeroski 2006) are a generalization of regression trees, because they can predict the values of several numeric target attributes simultaneously. Instead of storing a single numeric value, the leaves of a multi-target regression tree store a vector. Each component of this vector is a prediction for one of the target attributes. Examples of multi-target regression trees can be found in Sections 5 and 6.
A multi-target regression tree (of which a regression tree is a special case) is usually constructed by a recursive partitioning algorithm from a training set of records. The algorithm is known as TDIDT (top-down induction of decision trees). The records include measured values of the descriptive and the target attributes. The tests in the internal nodes of the tree refer to the descriptive, while the predicted values in the leaves refer to the target attributes.
The TDIDT algorithm starts by selecting a test for the root node. Based on this test, the training set is partitioned into subsets according to the test outcome. In the case of binary trees, the training set is split into two subsets: one containing the records for which the test succeeds (typically the left subtree) and the other contains the records for which the test fails (typically the right subtree). This procedure is recursively repeated to construct the subtrees.
The partitioning process stops if a stopping criterion is satisfied (e.g., the number of records in the induced subsets is smaller than some predefined value; the depth/size of the tree exceeds some predefined value etc). In that case, the prediction vector is calculated and stored in a leaf. The components of the prediction vector are the mean values of the target attributes calculated over the records that are sorted into the leaf.
One of the most important steps in the tree induction algorithm is the test selection procedure. For each node, a test is selected by using a heuristic function computed on the training data. The goal of the heuristic is to guide the algorithm towards small trees with good predictive performance. The multi-target regression trees are implemented in the system CLUS (Blockeel and Struyf 2002) available at http://www.cs.kuleuven.be/~dtai/clus/. The heuristic used in this algorithm for selecting the attribute tests in the internal nodes is intra-cluster variation summed over the subsets induced by the test. Intra-cluster variation is defined as
with N the number of examples in the cluster, T the number of target variables, and Var[yt] the variance of target variable yt in the cluster. Lower intra-subset variance results in predictions that are more accurate. The variance function is standardized so that the relative contribution of the different targets to the heuristic score is equal.
3. Data description
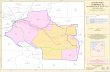
Lake Prespa is located at the border intersection of Macedonia, Albania and Greece (see Figure 1). It covers an area of 301 km2 at 850 m above sea level. The whole region that surrounds the lake was recently proclaimed a transboundary park (Prespa Park). The Prespa Park is well known for its great biodiversity, natural beauty and populations of rare water birds. However, the ecological integrity of the region is threatened by the increasing exploitation of the natural resources (inappropriate water management, forest destruction leading to erosion, overgrazing), inappropriate land-use practices, ecologically unsound irrigation practices, water and soil contamination from uncontrolled use of pesticides, lake siltation and uncontrolled urban development. Monitoring of the state of Lake Prespa is necessary to prevent major catastrophes in the Prespa ecosystem (Krstić 2006).
Monitoring of the state of Lake Prespa was performed during the EU project TRABOREMA. The measurements cover one and a half year period (from March 2005 to September 2006). Samples for analysis were taken from the surface water of the lake at 14 locations. The lake sampling locations are distributed in the three countries (see Figure 1) as follows: 8 in Macedonia, 3 in Albania and 3 in Greece. The selected sampling locations are representative for determining the eutrophication impact (Krstić 2005).
Fig. 1. Position of Lake Prespa (left) and the sampling locations (right)
Through the lake measurements, a total of 218 water samples were collected. On these water samples, both physicochemical and biological analyses were performed. The physicochemical properties of the samples provided the environmental variables for the habitat models, while the biological samples provided information on the relative abundance of the studied diatoms. The following physicochemical properties of the water samples were measured: temperature, dissolved oxygen, Secchi depth, conductivity, alkalinity (pH), nitrogen compounds (NO2, NO3, NH4, inorganic nitrogen), sulphur oxide ions SO4, and Sodium (Na), Potassium (K), Magnesium (Mg), Copper (Cu), Manganese (Mn) and Zinc (Zn). The basic statistics for these variables are given in Table 1.
The biological variables were the relative abundances of 116 different diatom taxa (for a complete list of diatom names and acronyms see Table A1 in the Appendix). Diatom cells were collected with a planktonic net or as attached growth on submerged objects (plants, rocks or sand and mud). This is the usual approach in studies for environmental monitoring and screening of diatom abundance. The sample, afterwards, is preserved and the cell content is cleaned. The sample is examined with a microscope, and the diatom taxa and abundance in the samples are obtained by counting 200 cells per sample. The specific taxon abundance is then given as the percent of the total diatom count per sampling site (Levkov et al. 2006).
Table 1. Basic statistics for the physico-chemical parameters
Minimum
Maximum
Mean Value
Standard Deviation
Temperature (oC)
2.90
26.80
15.56
6.61
Saturated O2 (mg/dm3)
6.60
114.19
83.07
18.76
Secchi Depth (m)
1.80
5.40
3.09
0.71
Conductivity (μS/cm)
142.50
318.00
196.23
27.84
pH
5.50
9.27
8.17
0.64
NO2 (mg/dm3)
0.00
0.44
0.03
0.05
NO3 (mg/dm3)
0.00
13.40
2.07
2.13
NH4 (mg/dm3)
0.01
1.07
0.29
0.18
Total N (mg/dm3)
0.32
9.21
2.53
1.28
Organic N (mg/dm3)
0.02
8.41
1.83
1.10
SO4 (mg/dm3)
2.68
266.10
29.47
22.98
Total P (μg/dm3)
1.15
83.13
18.63
15.31
Na (mg/dm3)
0.75
13.15
4.36
2.10
K (mg/dm3)
0.23
4.80
1.50
0.66
Mg (μg/dm3)
1.11
19.45
5.70
2.84
Cu (μg/dm3)
1.04
23.30
3.97
2.79
Mn (μg/dm3)
0.88
230.00
7.88
16.79
Zn (μg/dm3)
0.27
22.70
5.23
4.42
Namely, out of the 10 top dominant diatoms in Lake Prespa (Table A1 in bold), Cymbopleura juriljii (CJUR) and Navicula prespanensis (NPRE) are newly described taxa with no record for their ecological preferences in the literature. According to latest diatom ecology publications (van Dam et al., 1994) and databases (European Diatom Database - http://craticula.ncl.ac.uk/Eddi/jsp/index.jsp), Amphora pediculus (APED) is an eutrophic taxon tolerant to elevated N concentrations, Cavinula scutelloides (CSCU) is also eutrophic taxon-alkalibiont, Cocconeis placentula (CPLA) is an eutrophic taxon with medium oxygen demand, Cyclotella ocellata (COCE) is a meso to eutrophic taxon, Diploneis mauleri (DMAU), Navicula rotunda (NROT) and Navicula subrotunndata (NSROT) have no records, while Staurosirella pinnata (STPNN) is a hyper-eutrophic (oligo-eutrophic; indifferent) taxon frequently found on moist habitats.
4. Experimental Design
The goal of the experimental setup is to build models for (predicting) the physico-chemical parameters using the diatom abundances. Specifically, we define the following experimental scenarios:
· Inducing models for each measured physico-chemical parameter (single-target regression tree)
· Inducing models for groups of physico-chemical parameters (multi-target regression tree)
For the second experimental scenario, we induce 3 (three) multi-target regression trees (MTRTs). The first MTRT predicts all measured physico-chemical parameters, the second MTRT predicts the parameters that indicate the eutrophication level (phosphorus, nitrogen, Secchi depth) and the third MTRT predicts the metal contamination (Na, K, Mg, Cu, Mn and Zn).
To prevent over-fitting of the models to the training data, we employed ‘F-test pruning’. This pruning method applies the statistical F-test (Lomax 2007) to check whether a given split reduces the variance significantly at a given significance level. The significance level is a user defined parameter: We employ internal 10-fold cross-validation to select an optimal value for this parameter from the following set of values: 0.05, 0.1, 0.125, 0.25, 0.5, 0.75, and 1.0. In addition, to obtain even smaller trees, we set a constraint that does not allow the trees to grow more than 4 levels in depth.
5. Results
In line with the experimental setup we induced 3 multi-target regression trees and 18 single-target regression trees. In this section, we present only the multi-target trees, while the single-target trees are presented in the Appendix.
5.1. Multi-target regression trees for the physico-chemical parameters
In this subsection, we present, describe and discuss the multi-target regression trees that were induced from the data. Figure 2 presents the model for all physico-chemical parameters, Figure 3 the model for the eutrophication parameters and Figure 4 the model for the metals.
Figure 2. Multi-target regression tree for all physico-chemical parameters
The MTRT in Figure 2 has leafs. Each leaf contains predictions for all 18 measured physico-chemical parameters. The predictions are based on the diatom abundances. The internal nodes contain the most abundant diatom species from Lake Prespa – see Table A1 in Appendix). The most important diatom species, appears to be COCE (Cyclotella ocellata), followed by DMAU (Diploneis maulerii), CJUR (Cyclotella juriljii), AMSS (Achnanthes minutissima) and CPLA (Cocconeis placentula).
Let us examine the most obvious relationships revealed by this model. First, note the variation of the temperature. The highest temperature is encountered in the fifth leaf (counting from left to right), where the COCE diatom is present, while DMAU, AMSS, and CPLA are present with low abundances or not present at all. Second, we notice the low saturation of oxygen in the third leaf. This saturation can be indicated by the presence of COCE, low or no presence of DMAU and higher abundances of AMSS. One can further look for descriptions of the relationships in this system, but must be aware of the complexity of the problem: in this case the focus must be on the entire physico-chemical reality, not just a specific parameter. For instance, the second leaf presents a situation where the concentration of NO3 is higher than in the other leafs and the concentration of Zn is lower (as compared to the other leafs).
The NO2 and NO3 components of the lake could be indicated using combination of diatoms, as the model shows that high abundances of the COCE and DMAU, and low abundance of the CJUR diatoms are suitable for nitrogen monitoring. High concentrations of ammonium and organic nitrogen component are suitable environment in which AMSS and COCE can exist in high abundance. In combination with CPLA diatom, these diatoms could indicate lower concentrations of total nitrogen.
The MTRT also can be used to indicate the metal components inside of the lake ecosystem, not just only for one metal parameter, but also a combination of several metals. Low concentrations of K, Cu, Mn, Zn, are suitable environment for the DMAU and COCE diatoms, with low abundance of CJUR. High abundance of the CPLA is adequate for high concentrations of all metals in the dataset except the Mg and Mn.
‘Macrophytes and phytobenthos’ is one of the ecosystem components (termed ‘biological quality elements’ in the WFD) that are required to be analyzed in assessments of ecological status in freshwaters. However, considering all phototrophic organisms simultaneously is problematic because of the wide range of spatial scales and life-histories encompassed within this term. Diatoms have been widely used to support decision-making in freshwater management over the past two decades, with several indices and transfer functions used to provide information on acidification (Battarbee et al., 1999), nutrients (Kelly & Whitton, 1995; Rott et al., 1999; Potapova et al., 2004) and ‘general water quality’ (Descy, 1979; Coste in CEMAGREF, 1982). These approaches, whilst good at determining the intensity of particular types of pollution, are not suitable for assessing ecological status, as required for the WFD, as they do not compare the observed state of a water body with that expected in the absence of anthropogenic disturbance (Kelly et al., 2007).
On the other hand, using diatoms as biomonitoring organism in process of detection of the ecological status encounters several obstacles (Krstic et al., 2007), related to: i) taxonomical problems - diatom taxonomy is still a problem regarding miss-determination and ‘fitting the species into known species’ pattern; ii) lack of long-term environmental data - to be linked with diatom taxa distribution and abundance, and also the problem of genetical plasticity or evolutionary adaptation patterns to changing environment; and iii) the gap between autecology and taxonomy of taxa - full long term studies on diatom taxonomy and ecology are still lacking, especially when new taxa are described from worldwide habitats. The last obstacle is very clear for Lake Prespa as well, since 70 new taxa were recently described (Levkov et al, 2006) and only one publication presented (Levkov et al., 2007) on the ecology of benthic diatoms.
Figure 3. Multi-target regression tree for the eutrophication parameters
Figure 3 presents a model for the eutrophication parameters. There are 6 leafs, where 3 parameters (Secchi depth, nitrogen and phosphorus) are modelled. All modelled diatoms, including Navicula prespanensis (NPRE) as the first record of this kind, represent a community typical for elevated eutrophication parameters in the ecosystem. The highest eutrophic state of the lake can be found when COCE and UULN diatoms are present: highest phosphorus concentration, lowest Secchi depth and high nitrogen concentrations. Similar situations are described in the third and last leaf (counting from left to right). The remaining 3 leafs (the second, fourth and fifth) describe mesotrophic state of the lake, with lower phosphorus and nitrogen concentrations and higher Secchi depth. Comparing these results to Levkov et al. (2007) who stated: “according to the CCA results, physico-chemical variables are the main factors controlling diatom ecology in Lake Prespa. The main environmental factors controlling species distribution and abundances were ammonium, metallic cations (Cu, Mn, K) and, secondarily, dissolved oxygen and Secchi depth. Except for NH4 concentration, variables related to water trophic status ([P], [N], [Organic Nitrogen]) seem to have a negligible effect on benthic diatom abundances in Prespa Lake”, the obtained multi-target regression tree (Fig.3) offers significantly improved insight of the related diatom species distribution in relation to environmental parameters of the ecosystem.
Figure 4 presents a model for the selected diatom taxa abundance in relation to metal content in the water samples. There are 7 leafs that describe specific metal concentrations that can be encountered in the lake. Generally, when AVEN diatom is low or not abundant, and ACCLB and CELL are abundant (second leaf from left to right) the lowest concentrations of the metals can be found. The AVEN diatom can be used as indicator for high contamination (especially for copper: 13.13 g/dm3 and zinc: 9.24 g/dm3), except for manganese (the lowest encountered manganese concentration – 1.42 g/dm3).
Figure 4. Multi-target regression tree for the metals
Effects of increased levels of heavy metals on epilithic algal communities is studied under laboratory and natural conditions (Levkov and Krstic, 2002). In natural communities effects are investigated at chronic (long term) exposures, what is “more realistic to what algae will experience in nature” (Genter, 1996). They react more completely than filamentous algae or macrophytes (Ivorra et al., 1999). On the other hand, there are very few literature data concerning accumulation of heavy metals in natural diatom communities (Levkov, 2001). Ivorra (2000) shows that there is a large difference in the content of heavy metals in algal communities from unpolluted and polluted sites, and mainly exhibit linear correlation with concentration of adequate heavy metal in the ambient water (Absil and van Scheppingen, 1996). This difference is due to the different species composition in diatom communities (Admiraal et al.1997). Some diatom species have developed tolerance mechanisms against cytotoxic effects of heavy metals (Torres et al., 1995, 1997) to reduce heavy metal toxicity by producing intracellular and extracellular binding components (Ahner et al., 1995; Ahner and Morel, 1995). There are no literature data on sensitivity/tolerance of diatom taxa on ambient metal concentrations or diatom community response to elevated metal impacts.
For the Prespa Lake, Levkov et al. (2007) found that ”strong co-linearity exists within some variable sets (e.g. Cu-K-Mn, Mg-SO4-O2). Concentration of Cu was significantly correlated to the relative abundance of 10 of the 17 diatom taxa analyzed, and also affected species diversity (Shannon’s index, Pearson’s R = 0.2, p = 0.01)”. Developing of the presented regression tree (Fig.3) for Prespa Lake is therefore imperatively significant in determination of hierarchical community response to metal concentrations and establishing of the corresponding monitoring system.
One can also look at the single-target regression trees where each of the physico-chemical parameters is predicted separately. With this approach, we obtain 18 different regression trees (see figure in the Appendix) and they can be interpreted separately. However, these trees are not able to describe the complex physico-chemical situation in the water. The single-target regression trees contain information for only one parameter at a time, while discarding the information for the other parameters.
5.2. Performance of the models
For each of the learned models, we estimate its predictive performance on both the training data and on unseen data (by 10-fold cross-validation). We use two metrics to evaluate the performance: correlation coefficient and root mean squared error (RMSE). In addition, we inspect the selected models in detail and interpret the knowledge contained therein, as described in the previous subsection.
The performance figures for the induced models are listed in Tables 2 and 3. Each of these tables presents the selected significance level for the F-test pruning, the performance (correlation coefficient and RMSE) and the size (total number of nodes, including leaves and internal nodes) of the produced tree. Table 2 presents the performance of the regression trees and Table 3 of the multi-target regression tree.
A quick inspection of the results shows that the prediction problem is very difficult: even on the training data, the performance is low. In order to investigate how much we can improve the predictive performance, we employed ensembles (bagging and random forests) of both regression trees (Breiman 1996, 2001) and multi-target regression trees (Kocev et al. 2007). It is well known that ensemble methods perform better than individual trees and are amongst the top performing methods for predictive modelling (Caruana and Niculescu-Mizil 2006). The results are presented in Tables A.2 and A.3 in the Appendix.
The ensemble models have better predictive performance overall. The best correlation coefficient (on unseen data) is 0.60 (bagging and random forests of regression trees), as compared to 0.38 for the regression trees (the tree for the temperature parameter) and 0.36 for the multi-target regression tree for all parameters (for the total nitrogen parameter). The F-values range from 0.05 to 0.125 for the single target trees, but most of the parameters have 0.05 values while 0.1 for multi target trees for the metal set. The F-values for the regression tree for the SD parameter is 0.1, while for the MTRT we have 0.05.
Table 2. Performance of the single-target regression trees - STRT
F-value
CC
RMSE
Size
Train
Xval
Train
Xval
Temp
0.05
0.74
0.38
4.44
6.48
25
SatO
0.05
0.66
0.37
14.11
17.96
19
SD
0.1
0.64
0.14
0.54
0.76
25
Conduc
0.25
0.67
0.32
20.71
28.37
29
pH
0.5
0.61
0.07
0.50
0.71
23
NO2
0.05
0.65
0.18
0.03
0.05
15
NO3
0.05
0.65
0.27
1.62
2.24
13
NH4
0.05
0.52
0.07
0.15
0.19
11
TotalN
0.05
0.68
0.29
0.93
1.33
21
OrgN
0.5
0.58
0.21
0.90
1.14
25
SO4
0.5
0.67
-0.01
17.10
30.27
13
TotalP
0.05
0.62
-0.01
12.03
18.40
17
Na
0.05
0.56
0.12
1.73
2.25
23
K
0.125
0.53
0.17
0.56
0.71
17
Mg
0.1
0.69
0.22
2.04
3.05
29
Cu
0.05
0.59
0.02
2.25
3.27
15
Mn
0.05
0.28
0.10
16.09
16.75
9
Zn
0.05
0.57
0.15
3.62
4.75
19
Table 3. Performance of the multi-target regression trees - MTRT
F-value
CC
RMSE
Size
Train
Xval
Train
Xval
Temp
0.05
0.43
0.18
5.96
6.82
11
SatO
0.46
0.15
16.63
19.08
SD
0.25
0.12
0.68
0.71
Conduc
0.39
0.27
25.55
26.99
pH
0.36
-0.03
0.59
0.69
NO2
0.46
0.09
0.04
0.05
NO3
0.60
0.21
1.71
2.22
NH4
0.18
0.03
0.17
0.18
TotalN
0.48
0.36
1.12
1.19
OrgN
0.31
0.22
1.05
1.08
SO4
0.09
0.01
22.83
23.09
TotalP
0.23
0.07
14.85
15.50
Na
0.30
0.17
2.00
2.08
K
0.37
0.01
0.61
0.72
Mg
0.21
0.09
2.77
2.87
Cu
0.38
-0.03
2.58
3.32
Mn
0.16
0.05
16.52
16.88
Zn
0.27
0.02
4.25
4.63
F-value
CC
RMSE
Size
Train
Xval
Train
Xval
SD
0.05
0.36
0.10
0.66
0.72
11
TotalN
0.51
0.36
1.09
1.21
TotalP
0.36
0.06
14.22
17.47
F-value
CC
RMSE
Size
Train
Xval
Train
Xval
Na
0.1
0.39
0.10
1.93
2.17
17
K
0.46
0.09
0.59
0.71
Mg
0.47
0.24
2.50
2.81
Cu
0.49
0.01
2.42
3.15
Mn
0.19
0.02
16.43
16.91
Zn
0.33
0.03
4.16
4.65
We can also compare the regression trees and the multi-target regression tree by their size (total number of internal nodes and leafs). The size of the multi-target regression tree is 11, while the size of the regression trees ranges from 9 (for Mn parameter) to 29 (for Conductivity and Mg). The total size of all single-target trees is much larger that the size of the multi-target tree, if we learn a regression tree for each of the 18 physical-chemical parameters. The size of the trees obtain from the eutrophication parameters (SD, Total Nitrogen, Total Phosphorus), is quite different, for regression trees we have total of 63 leafs, but for multi-target trees we have total of 33 leafs all together. The metal set multi target regression trees all together have smaller size than the single target regression trees for each parameter.
Multivariate analyses such as principal components analysis (PCA), canonical correlation analysis and cluster analysis were used to determine the relationship between the distribution of diatom species and gradients in salinity and other physical factors within the estuary in studies by McIntire (1973, 1978) in studies of benthic diatoms in Yaquina Estuary, Oregon. Similar studies include Main and McIntire (1974), Moore and McIntire (1977), and Whiting and McIntire (1985). Descriptive multivariate techniques, including Q-mode cluster analysis and PCA, were employed to analyze the data. Juggins (1992) developed a ‘salinity transfer function’, using weighted-averaging methodology, by analyzing surface sediments and living source communities of diatoms. Although these techniques provide very useful insights in the data, they are limited in terms of interpretability. On the other hand, multi-target regression trees offer models that are readily interpreted. MTRTs are able to identify clusters of samples that are similar in terms of physico-chemical water quality and describe them in terms of diatom species. To summarize, the multi-target regression trees are models that are easily interpretable, with reasonable size and predictive performance.
6. Conclusion (needs more work)
Summary. In this paper, we applied machine learning methodology, in particular multi-target regression trees, to predict the chemical parameters of the environment using the diatom community in Lake Prespa. We managed to express the relationships between the physico-chemical parameters and the diatom abundance. The obtained trees reveal some diatoms as indicators for specific physico-chemical parameters (i.e., for eutrophication or metal contamination). We first assessed the predictive performance of the obtained models, which were then interpreted for content. The interpretation was done by a domain expert, a biologist who has studied the diatoms in Lake Prespa and collected and processed the samples (S. Krstić).
A comparison of the models was then performed along two dimensions. First, we compare the performance of the models both on training data and unseen data. Second, we compare the models by their interpretation in terms of structure and content. Regarding the performance, in our case, MTRTs achieve slightly better correlation coefficients than RTs. The presented methodology of multi-target regression trees has several advantages with respect to the more commonly used approach of single-target regression trees. Namely, the MTRTs provide knowledge about all targets and, in our case, identify the diatom species that are present in the water samples with specific chemical conditions. In contrast to this, using the traditional approach one would have to construct a separate model for each chemical parameter and to summarize over the multiple models, which is not a trivial task.
Predictive power. The predictive power of the models on unseen cases is weak (as estimated with 10-fold cross validation). Since we suspected that over-fitting might play an important role in this, the ‘F-test pruning’ was applied to prevent over-fitting. However, despite this the predictive power remained poor. On the other hand, the performance on the training data and thus the explanatory power is much better; the tests that are in the nodes produce statistically significant reduction in the variance at a given significance level.
To investigate the limits of predictive performance for the data at hand, we also built ensembles of tree-based models. These are well known for their predictive power and are top performers, at the cost of producing models that are not easy to interpret. This yielded predictive performance that was better than that of a single tree, but still not that high (maximum correlation reached was 0.6).
We can thus conclude that the low predictive performance achieved is not a consequence of using an inappropriate methodology, but rather a consequence of the difficulty of the problem addressed. The modelling problem at hand is very difficult, because the lake is a complex ecosystem and the data available was of limited quantity and quality. In order to obtain models with better predictive power, more measurements are needed. These measurements should include additional locations, a longer period of observation and a wider range of measured environmental parameters.
Model interpretation. Multi-target regression trees are a special case of predictive clustering trees, where the tree is viewed as a hierarchy of clusters. In our study, we focus on the clustering part (how the models describe the training data). The developed models clearly reflect and improve the hitherto known ecological preferences of the diatom species in Lake Prespa. The dominant lake diatom flora is composed of species indicative for increased eutrophication levels and their abundance is directly related to specific physico-chemical parameters. Models built to predict all 18 physico-chemical parameters, eutrophication components and metal parameters are used to investigate the diatoms’ ability to reflect the ecological changes.
The developed models clearly reflect the factors that strongly influence the abundance of the dominant species and the entire diatom community in Prespa Lake. Cyclotella ocellata (COCE) is the most abundant diatom species, which can be found in almost all the models, but mostly in the eutrophication ones, which indicates its ability to reflect the environmental changes related to the eutrophication.
Conclusion. Using multi-target machine learning techniques methods for prediction, we learn models that contribute to our ecological knowledge about the physico-chemical conditions in the lake using diatoms abundance as bioindicators. The predictive power of the learned models is not high, but they provide useful explanation related to the existing ecological knowledge. It is obvious that several of the diatoms are indicators of important processes and this is confirmed by the biological expert and the known literature. Multi-target decision trees are nice illustration how several parameters at once influence the diatom community.
Multi-target regression trees have been used so far to investigate terrestrial communities, e.g., soil insects (Demšar et al. 2006); to predict chemical parameters of river water quality from bioindicator data (Blockeel et al. 1999) and to predict the condition/quality of indigenous vegetation (Kocev et al. 2009). However, to our knowledge, this is the first use of multi-target regression trees to predict the environmental variables from the composition of diatom communities in a lake ecosystem.
Future work. In the future, we plan to investigate several research scenarios. One of these is to use the diatom community to reconstruct past ecological changes in the lake history, by exploiting bioindicators’ abundance ability to reveal the past physico-chemical conditions. This could lead to understanding the effect of the human population on the lake, as well as understanding the impact on climate change and etc. In other studies the diatoms as bioindicators are widely used to reconstruct certain pattern regarding pH, Total Phosphorus and salinity indicative stages. Another possibility is to represent the diatom community together with its taxonomic structure. The taxonomic structure of the community could then be predicted with hierarchical multi-label classification (Vens et al. 2008) approaches.
References
Absil M.C.P. and Van Scheppingen Y. 1996. Concentration of Selected Heavy Metals in Bentic Diatoms and Sediment in the Westershelde Estuary. Bulletin of Environmental Contamination and Toxicology, 56: 1008-1015.
Admiraal W., Ivorra N., Jonker M., Bremer S., Barranguet C. and Guasch H., 1997. Distribution of diatom species in metal polluted Belgian-Dutch river: An experimental analysis. p.240-244. In: Use of algae for monitoring rivers III, edited by Prygiel J, Whitton BA, Bukowska.
Ahner B.A., Kong S. and Morell F.M.M., 1995. Phytochelatin production in marine algae. 1. An interspecies comparison. Limnology and Oceanography, 40(4): 649-657.
Ahner B.A. and Morell F.M.M. 1995. Phytochelatin production in marine algae. 2. Induction by various metals. Limnology and Oceanography, 40 (4): 658-665.
Battarbee R.W., Charles D.F., Dixit S.S. & Renberg I. (1999) Diatoms as indicators of surface water acidity. In: The Diatoms: Applications for the Environmental and Earth Sciences (Eds E.F. Stoermer & J.P. Smol), pp. 85–127. Cambridge University Press, Cambridge.
Blockeel, H., L. De Raedt, and J. Ramon (1998). Top-down induction of clustering trees. In Proc. Fifteenth International Conference on Machine Learning, p. 55–63. San Mateo, CA, Morgan Kaufmann.
Blockeel, H., and J. Struyf (2002). Efficient algorithms for decision tree cross-validation. Journal of Machine Learning Research 3:621–650.
Breiman, L., J.H. Friedman, R.A. Olshen, C.J. Stone (1984). Classification and Regression Trees. Wadsworth.
CEMAGREF (1982) Etude de Me´thodes Biologiques Quantitatives d’Appreciation de la Qualite´ des Eaux. Rapport Q.E. Lyon-A.F.B. Rhoˆne-Mediterranne´e-Corse. 218 pp.
[14] Davis, R.B., Norton, S.A. “Paleolimnological studies of human impact on lakes in the United States, with emphasis on recent research in New England.”, Journal of Polskie Archiwum Hydrobiologii; Vol.15 (1/2), pp 99-115, 1978
Descy J-P. (1979) A new approach to water quality estimation using diatoms. Nova Hedwigia, 64, 305–323.
Garofalakis, M., D. Hyun, R. Rastogi, and K. Shim (2003). Building decision trees with constraints. Data Mining and Knowledge Discovery 7(2):187–214.
Genter R.B., 1996. Ecotoxicology of Inorganic Chemical Stress to Algae. p.403-468. In: Algal Ecology, edited by Stevenson R.J., Bothwell M.L. 1and Lowe R.L., Academic Press.
Ivorra N, Hettelaar J., Tubbing G.M.J., Kraak M.H.S., Sabater S. and Admiraal W. (1999). Translocation of Microbenthic Algal Assemblages Used for In Situ Analysis of Metal Pollution in Rivers. Archive of Environmental Contamination and Toxicology, 37: 19-28.
Ivorra N.C., 2000. Metal induced succesion in bentic diatom consortia. Doctor Disertation.Faculty of Sciences, University of Amsterdam, The Netherlands. 161p.
Kelly M.G. (2006) A Comparison of Diatoms with other Phytobenthos as Indicators of Ecological Status in Streams in Northern England. Proceedings of the 18th International Diatom Symposium, pp. 139–151. Poland, September 2004. Biopress, Bristol.
Kelly M.G. & Whitton B.A. (1995) The trophic diatom index: a new index for monitoring eutrophication in rivers. Journal of Applied Phycology, 7, 433–444.
Kelly M.G., Juggins S., Bennion H., Burgess A., Yallop M., Hirst H., King L., Jamieson J., Guthrie R. & Rippey B. (2006) Use of Diatoms for Evaluating Ecological Status in UK Freshwaters. Draft final report to Environment Agency. Bristol. 170 pp.
Kelly M.G., Juggins S., Guthrie R., Pritchard S., Jamison J., Rippey B., Hirst H. and Yallop M. (2008) Assesment of ecological status in UK rivers using diatoms. Freshwater Biology, 53, 403-422.
Krstic S. and Levkov Z. (2007): Saprobiological and trophic models for Lake Prespa (saprographs) for use in similar regions and its application for evaluation of Ecological Quality Ratios (indicators). EC-FP6 project "TRABOREMA", EC-Project Contract No. INCO-CT-2004-509177, Deliverable 3.3., 98 pp.
Krstic S., Svircev Z., Levkov Z. and Nakov T. (2007): Selecting appropriate bioindicator regarding the WFD guidelines for freshwaters - a Macedonian experience. International Journal on Algae 9(1), 41-63.
Levkov Z. and Krstic S. (2002): Use of algae for monitoring of heavy metals in the River Vardar, Macedonia. Mediterranean Marine Science, 3/1, 99-112.
Levkov Z., Krstić S., Metzeltin D. and Nakov T. (2006). Diatoms of Lakes Prespa and Ohrid (Macedonia). Iconographia Diatomologica 16: 603.
Levkov, Z., Saul, B., Krstic, S., Nakov, T. and Ector, L. (2007): Ecology of benthic diatoms from Lake Prespa, Macedonia. Archiv für Hydrobiologie: Supplement/ Algological Studies 124: 71-83.
Lomax, R. G. (2007). Statistical Concepts: A Second Course, Routledge, ISBN 0-8058-5850-4
Lowe RL, Pan Y. Benthic algal communities as biological monitors. In: Stevenson RJ, Bothwell ML, Lowe RL, editors. Algal ecology of freshwater benthic ecosystems, aquatic ecology series. Boston: Academic Press, 1996. p. 705–39.
Main, S.P.,& McIntire, C.D. (1974).The distribution of epiphytic diatoms in Yaquina Estuary, Oregon (U.S.A.).Botanica Marina, 17, 88–99.
McCormick PV, Cairns Jr J. Algae as indicators of environmental change. J Appl Phycol 1994;6:509–26.
Moore,W.W.,& McIntire, C.D. (1977). Spatial and seasonal distribution of littoral diatoms in Yaquina Estuary, Oregon (U.S.A.).Botanica Marina,20, 99–109.
Patrick, R., Reimer, C.W.” The diatoms of the United States, exclusive of Alaska and Hawaii. Volume I: Fragilariaceae, Eunotiaceae, Achnanthaceae, Naviculaceae”, Journal of Academy of Natural Sciences of Philadelphia, Monograph No. 13, pp 688, 1966
Potapova M.G., Charles D.F., Ponader K.C. & Winter D.M. (2004) Quantifying species indicator values for trophic diatom indices: a comparison of approaches. Hydrobiologia, 517, 25–41.
Rott E., Pipp E., Pfister P., van Dam H., Ortler K., Binder N. & Pall K. (1999) Indikationslisten fur Aufwuchsalgen in Osterreichischen Fliessgewassern. Teil 2: Trophieindikation. Bundesministerium fuer Land- und Forstwirtschaft, Wien. 248 pp.
Stroemer, E.F., and J. P. Smol (2004). The diatoms: Applications for the Environmental and Earth Sciences, Cambridge University Press.
Salomoni, S., O. Rocha, V. Callegaro and E. Lobo (2006). Epilithic diatoms as indicators of water quality in the Gravataí River, Rio Grande do Sul, Brasil. Hydrobiologia 559: 233-246.
Struyf, J., and S. Džeroski (2006). Constraint based induction of multi-objective regression trees. In Proc. Fourth International Workshop on Knowledge Discovery in Inductive Databases, Revised, Selected and Invited Papers, LNCS 3933: 222–233.
TRABOREMA Project WP3, EC FP6-INCO project no. INCO-CT-2004-509177, 2005-2007
Water Framework Directive (WFD), Water Quality - Sampling - Part 2: Guidance on sampling techniques (ISO 5667-2:1991), 1993.
Whiting,M. C., & McIntire, C.D. (1985).An investigation of distributional patterns in the diatom flora of Netarts Bay, Oregon, by correspondence analysis. Journal of Phycology, 21, 655–61.
APPENDIX
Table A1. The names and acronyms of the 116 diatoms whose abundances were used in the data analysis. The top 10 most abundant are given in boldface.
Diatom
Acronym
Diatom
Acronym
Amphora aequalis
AAEQ
Gomphonema minutum
GMIN
Achnanthes sp.
ACH
Gomphonema olivaceum
GOLIV
Achnanthidium clevei var. balcanica
ACCLB
Gomphonema parvulum
GPRV
Achnanthidium clevei
ACCL
Gomphonema pumilum
GPUM
Amphora copulata
ACOP
Gomphonema olivaceoides
GQDR
Amphora fogediana
AFOG
Gomphonema sarcophagus
GSRC
Achnanthes lacunarum
ALAC
Gomphonema tergestinum
GTRG
Amphora inariensis
AMIN
Gyrosigma macedonicum
GYMAC
Achnanthidium minutissimum
AMSS
Hannea arcus
HARC
Amphora ovalis
AOVAL
Hantzschia amphioxys
HAYX
Amphora pediculus
APED
Hippodonta rostrata
HROS
Amphora thumensis
ATHUM
Luticola mutica
LMUT
Aulacoseira granulata
AUGR
Meridion circulare var. constrictum
MCCC
Amphora veneta
AVEN
Meridion circulare
MCRC
Caloneis schumaniana
CSCH
Martyana martyi
MMRT
Cavinula scutelloides
CSCU
Melosira varians
MVAR
Cocconeis disculus
CDIS
Nitzschia alpina
NALP
Cocconeis placentula
CPLA
Navicula antonii
NANT
Cocconeis placentula var. euglypta
CPLE
Navicula capitatoradiata
NCPR
Cocconeis placentula var. lineata
CPLL
Navicula cryptocephala
NCRPH
Cocconeis neothumensis
CNTHUM
Nitzschia dissipata
NDISS
Cyclotella ocellata
COCE
Neidium dubium
NDUB
Cyclotella meneghiniana
CMHGN
Navicula gregaria
NGRG
Cymatopleura elliptica
CELL
Navicula hasta
NHAS
Cymbopleura juriljii
CJUR
Navicula krsticii
NKRS
Cymbella affiniformis
CAFF
Navicula lanceolata
NLAN
Cymbella lanceolata
CLAN
Nupela lapidosa
NLAP
Cymbella neocistula
CYNC
Nitzschia linearis
NLIN
Diatoma angusticostata
DANG
Navicula praetarita
NPRA
Denticula tenuis
DCNT
Navicula prespanensis
NPRE
Diadesmis gallica var. perpusilla
DGLPS
Navicula protracta
NPTR
Diploneis mauleri
DMAU
Nitzschia recta
NREC
Diatoma mesodon
DMES
Navicula reinhardtii
NRERH
Diploneis modica
DMOD
Navicula rotunda
NROT
Diploneis ovalis
DOVAL
Navicula subhastatula
NSHA
Epithemia adnata
EADN
Navicula subrotundata
NSROT
Encyonema caespitosum
ECAES
Nitzschia subacicularis
NSUA
Encyonema minutum
EMIN
Navicula tripunctata
NTPT
Encyonopsis microcephala
ENCYM
Navicula viridulacalcis
NVCAL
Encyonema silesiacum
ESLS
Navicula viridula
NVIR
Epithemia sorex
ESOR
Orthoseira roseana
OROS
Fragilaria capucina var. vaucheriae
FCAPV
Placoneis balcanica
PBAL
Fragilaria capucina
FCAPV
Pinnularia borealis
PBOR
Fallacia ochridana
FOCH
Placoneis minor
PCLM
Fragilaria parasitica
FPAR
Placoneis elginensis
PELG
Frustulia vulgaris
FVUL
Planothidium lanceolatum
PLLA
Gomphonema clavatum
GCLA
Planothidium rostratum
PLLR
Geissleria decussis
GDEC
Placoneis neoexigua
PNEO
Gomphonema italicum
GITA
Pseudostaurosira brevistriata
PSBR
Table A1 (ctd). Diatom names and acronyms. The top 10 most abundant are given in boldface.
Diatom
Acronym
Diatom
Acronym
Pinnularia subcapitata
PSCP
Surirella angusta
SANG
Rhoicosphenia abbreviata
RABB
Surirella minuta
SMIN
Rhopalodia gibba
RHGB
Sellaphora perbacilloides
SPBA
Reimeria sinuata
RSIN
Sellaphora pupula
SPUP
Surirella angusta
SANG
Stauroneis gracilis
SRGR
Surirella minuta
SMIN
Staurosira construens var. binodis
STCB
Sellaphora perbacilloides
SPBA
Staurosira construens
STCO
Sellaphora pupula
SPUP
Staurosira construens var. venter
STCV
Placoneis neoexigua
PNEO
Stauroneis phoenicenteron
STPHN
Pseudostaurosira brevistriata
PSBR
Staurosirella pinnata
STPNN
Pinnularia subcapitata
PSCP
Stauroneis smithii
STSM
Rhoicosphenia abbreviata
RABB
Tryblionella angustata
TANG
Rhopalodia gibba
RHGB
Tabellaria flocculosa
TFLOC
Reimeria sinuata
RSIN
Ulnaria ulna
UULN
Table A2. Performance (Correlation coefficient and RMSE) of the ensembles of regression trees (Bagging and Random Forest) on training data and estimated with 10-fold cross validation. - STRT
Bagging
Random Forest
CC
RMSE
CC
RMSE
Train
Xval
Train
Xval
Train
Xval
Train
Xval
Temp
0.91
0.60
3.01
5.28
0.90
0.36
2.81
7.15
SatO
0.78
0.41
12.07
17.29
0.80
0.33
11.33
19.53
SD
0.92
0.21
0.35
0.69
0.91
0.18
0.29
0.89
Conduc
0.84
0.42
15.71
25.41
0.85
0.31
14.45
31.53
pH
0.84
0.06
0.38
0.67
0.86
-0.03
0.33
0.83
NO2
0.87
0.24
0.03
0.05
0.79
0.21
0.03
0.05
NO3
0.87
0.50
1.13
1.85
0.88
0.22
0.99
2.49
NH4
0.82
0.25
0.11
0.17
0.82
0.18
0.10
0.21
TotalN
0.85
0.40
0.71
1.18
0.86
0.20
0.65
1.53
OrgN
0.81
0.24
0.69
1.09
0.81
0.13
0.65
1.30
SO4
0.89
0.02
13.33
26.10
0.77
0.10
14.72
29.56
TotalP
0.87
0.17
8.52
15.68
0.86
-0.04
7.81
20.97
Na
0.84
0.35
1.25
1.96
0.83
0.17
1.18
2.51
K
0.88
0.21
0.36
0.66
0.83
0.16
0.36
0.82
Mg
0.89
0.43
1.45
2.55
0.91
0.23
1.19
3.33
Cu
0.78
0.25
1.83
2.75
0.77
0.06
1.78
3.47
Mn
0.38
0.08
15.54
17.05
0.37
0.12
15.54
17.06
Zn
0.82
0.23
2.75
4.34
0.84
0.16
2.42
5.31
Table A3. Performance (Correlation coefficient and RMSE) of the ensembles of multi-target regression trees (Bagging and Random Forest) on training data and estimated with 10-fold cross validation for all parameters.
Bagging
Random Forest
CC
RMSE
CC
RMSE
Train
Xval
Train
Xval
Train
Xval
Train
Xval
Temp
0.90
0.58
3.25
5.37
0.88
0.36
3.18
6.94
SatO
0.77
0.36
12.70
17.51
0.69
0.21
13.47
20.50
SD
0.90
0.12
0.42
0.70
0.76
0.13
0.46
0.81
Conduc
0.82
0.42
17.09
25.21
0.79
0.26
17.14
30.16
pH
0.82
0.07
0.42
0.66
0.76
0.04
0.41
0.81
NO2
0.88
0.25
0.03
0.04
0.78
0.12
0.03
0.05
NO3
0.87
0.50
1.17
1.85
0.84
0.31
1.16
2.29
NH4
0.82
0.18
0.12
0.17
0.70
0.07
0.13
0.21
TotalN
0.84
0.42
0.75
1.16
0.78
0.29
0.80
1.38
OrgN
0.80
0.28
0.72
1.07
0.71
0.14
0.78
1.28
SO4
0.91
0.01
12.96
24.75
0.81
0.07
13.45
31.43
TotalP
0.88
0.21
9.01
15.05
0.79
0.09
9.32
18.62
Na
0.82
0.36
1.34
1.96
0.78
0.26
1.32
2.27
K
0.87
0.22
0.40
0.65
0.77
0.09
0.42
0.79
Mg
0.88
0.45
1.58
2.55
0.81
0.29
1.66
3.11
Cu
0.78
0.20
1.89
2.77
0.75
0.02
1.86
3.39
Mn
0.39
0.08
15.57
16.97
0.34
0.06
15.73
17.48
Zn
0.80
0.20
2.95
4.36
0.74
0.12
2.98
5.23
Table A4. Performance (Correlation coefficient and RMSE) of the ensembles of multi-target regression trees (Bagging and Random Forest) on training data and estimated with 10-fold cross validation for eutrophication parameters.
Bagging
Random Forest
CC
RMSE
CC
RMSE
Train
Xval
Train
Xval
Train
Xval
Train
Xval
SD
0.92
0.15
0.37
0.70
0.88
0.04
0.34
0.93
TotalN
0.85
0.43
0.73
1.16
0.83
0.35
0.72
1.34
TotalP
0.88
0.22
8.69
15.16
0.83
0.05
8.46
20.18
Table A5. Performance (Correlation coefficient and RMSE) of the ensembles of multi-target regression trees (Bagging and Random Forest) on training data and estimated with 10-fold cross validation for metals.
Bagging
Random Forest
CC
RMSE
CC
RMSE
Train
Xval
Train
Xval
Train
Xval
Train
Xval
Na
0.83
0.37
1.30
1.95
0.79
0.28
1.27
2.30
K
0.88
0.22
0.39
0.65
0.81
0.07
0.38
0.86
Mg
0.89
0.45
1.52
2.54
0.87
0.27
1.40
3.18
Cu
0.77
0.21
1.90
2.76
0.71
0.06
1.95
3.38
Mn
0.39
0.07
15.55
17.03
0.33
0.08
15.80
17.23
Zn
0.81
0.21
2.88
4.35
0.76
0.02
2.87
5.64
Single Target Regression Tree for the Temperature
STRT for the Saturated Oxygen
STRT for Secchi Disk
STRT for Conductivity
STRT for pH
STRT for NO2
STRT for NO3
STRT for Total Nitrogen
STRT for OrgN
STRT for SO4
STRT for Total Phosphorus
STRT for Na
STRT for K
STRT for Mg
STRT for Cu
STRT for Mn
STRT for Zn
[
]
å
=
×
T
t
t
y
Var
N
1
_1295876976.unknown
Related Documents