Multiprozessorsysteme SMP DSM Bemerkungen OpenMP Amdahl Parallel Blocking Literatur Page 1 of 41 Praktikum Wissenschaftliches Rechnen Praktikum Wissenschaftliches Rechnen Performance-optimized Programming Scientific Computing in Computer Science Prof. Dr. H.-J. Bungartz Dipl.-Geophys. Markus Brenk, [email protected] Dr. Ralf Mundani [email protected] 15. November 2006 (Foliensatz II)

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 1 of 41
PraktikumWissenschaftliches Rechnen
Praktikum Wissenschaftliches Rechnen
Performance-optimized Programming
Scientific Computing in Computer ScienceProf. Dr. H.-J. Bungartz
Dipl.-Geophys. Markus Brenk,[email protected]. Ralf [email protected]
15. November 2006 (Foliensatz II)

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 2 of 41
PraktikumWissenschaftliches Rechnen
1. Einordnung von Multiprozessorsysteme
• Einteilung nach Adressraum und Speicherkonfiguration
Konfiguration von Multiprozessoren
quick and dirty

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 3 of 41
PraktikumWissenschaftliches Rechnen
• Einteilung nach Zugriffszeit und Übertragungszeit
– Uniform-memory-access-Model (UMA)
– Non-uniform-memory-access-Model (NUMA)
– Uniform-communication-architecture-Model (UCA)
– Non-uniform-communication-architecture-Model (NUCA)

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 4 of 41
PraktikumWissenschaftliches Rechnen
2. „Symmetric Multiprocessor“ SMP
2.1. Bus gekoppelte SMP’s
• Datentransfer in „cache lines“
• Speicherzugriffskonflikte sind sehr wahrscheinlich
• Mehrfachbussystem mit parallel angeordnetem Mehrfachbus

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 5 of 41
PraktikumWissenschaftliches Rechnen
2.2. „Crossbar“ gekoppelte SMP’s
• blockierungsfreie Kommunikation (disjunkte Paare)
• hohe Bandbreite
• hoher Hardwareaufwand (n2)

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 6 of 41
PraktikumWissenschaftliches Rechnen
2.3. Cache-Kohärenz bei SMP’s
Parallele Ausführung eines Programms:
• Das Programm wird in mehrere Threads aufgeteilt.
• Die Threads werden auf unterschiedlichen Prozessoren parallelausgeführt.
Problem:
• Alle Prozessoren greifen auf den gemeinsamen Speicher zuund legen Kopien in ihrem Cache an.
• Wird ein Datum im Cache verändert, so ist das System nichtmehr konsistent.
Durch eine „write-through“ Strategie, bei der eine Änderung im Ca-che zu einer Änderung im Hauptspeicher führt, kann das Systemkonsistent gehalten werden. Ein solch hoher Aufwand führt zu Leis-tungseinbußen!Deutlich weniger Aufwand hat die „write-back“ Strategie, die inkon-sistente Zustände erlaubt.Liefert ein Lesezugriff immer den Wert des zeitlich letzten Schreib-zugriffs auf das entsprechende Datum, so wird das Speichersystemals cache-kohärent bezeichnet.

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 7 of 41
PraktikumWissenschaftliches Rechnen
Das Cache-Kohärenzprotokoll legt den Umfang der Inkonsistenz festund sichert die Kohärenz.Es gibt zwei prinzipielle Ansätze für Cache-Kohärenzprotokolle:
• write-update: Beim Verändern einer Kopie in einem Cache müs-sen alle Kopien in anderen Caches ebenfalls verändert werden.
• write-invalidate: Vor dem Verändern einer Kopie in einem Cachemüssen alle Kopien für ungültig erklärt werden.
Üblicherweise wird bei SMP’s „bus-snooping“ mit Write-invalidate-Cache-Kohärenzprotokoll im Write-back-Verfahren angewandt.Beispiel: MESI-Protokoll
Exclusive modified Die Cache-line wurde geändert und befindet sichausschließlich in diesem Cache.
Exclusive unmodified Die Cache-line wird nur gelesen und befindetsich ausschließlich in diesem Cache.
Shared unmodified Kopien der Cache-line befinden sich für Lesezu-griffe im mehr als einem Cache.
Invalid Die Cache-line ist ungültig.
Nomenklatur: CC-UMA, CC-NUMA

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 8 of 41
PraktikumWissenschaftliches Rechnen
Erweiterung des MESI-Protokolls: MOESI (z.B. AMD Opteron)

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 9 of 41
PraktikumWissenschaftliches Rechnen
3. Bemerkungen zu Distributed-Shared-Memory (DSM)
• Die Prozessoren besitzen einen gemeinsamem Adressraum aberlokalen Speicher.
• Die Cache-Kohärenz wird über directory tables gesichert. Da-ten: write-back, write-invalidate; Directory: write-through, write-update.
• Leichte Portierbarkeit von SMP’s auf DSM’s.
• Der gemeinsame virtuelle Speicher wird in Seiten aufgeteilt.Diese Seiten können ihren physikalischen Speicherort wech-seln.
• Problem: Programmierer hat kaum Kontrolle über die Kommu-nikation.
• Problem: Das „Wandern“ der Seiten kann zu Seitenflattern (thra-shing) führen.
• Eine Variante ist Software basiertes DSM-System (z. B. Rthreads).

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 10 of 41
PraktikumWissenschaftliches Rechnen
4. Shared-Memory Programmierung mit OpenMP
4.1. OpenMP - Einführung
http://www.openmp.org

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 11 of 41
PraktikumWissenschaftliches Rechnen
4.2. OpenMP - Fine Grained Parallelism
program main...!$OMP PARALLEL DOdo i=1,n
!parallel workend do!$OMP END PARALLEL DO...!$OMP PARALLEL SECTIONS!$OMP SECTION...!$OMP SECTION...!$OMP END PARALLEL SECTIONS...end program main
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 12 of 41
PraktikumWissenschaftliches Rechnen
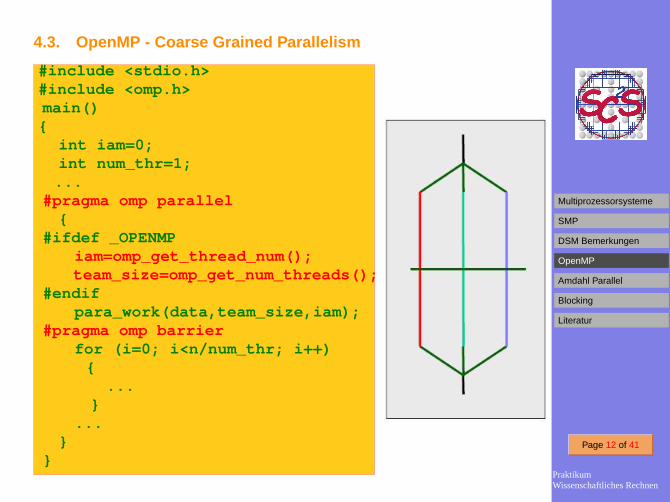
4.3. OpenMP - Coarse Grained Parallelism
#include <stdio.h>#include <omp.h>main()
{int iam=0;int num_thr=1;
...#pragma omp parallel
{#ifdef _OPENMP
iam=omp_get_thread_num();team_size=omp_get_num_threads();
#endifpara_work(data,team_size,iam);
#pragma omp barrierfor (i=0; i<n/num_thr; i++)
{...
}...
}}

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 13 of 41
PraktikumWissenschaftliches Rechnen
4.4. OpenMP - Überblick
• Directives#pragma omp ... bzw. !$OMP ...
• Parallel regions construct#pragma omp parallel
• Work sharing constructs#pragma omp for , #... sections , #... single
• Master and Synchronization constructs#pragma omp master , #... critical , #... barrier ,...
• Variable scoping clauses and directives#pragma omp threadprivat(...) , #... privat(...) ,#... shared(...) , ...
• Runtime libraryomp_get_thread_num() , omp_get_num_threads() , ...
• Environment variablesOMP_NUM_THREADS, ...

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 14 of 41
PraktikumWissenschaftliches Rechnen
4.5. OpenMP - Typische Anwendung
Beispiel: Gradient Φ(x, y) = x2 + y; Calculate: ∇Φprogram grad
implicit noneinteger,parameter :: n=500real,dimension(0:n,0:n) :: potentialreal,dimension(1:n,1:n,1:2) :: fieldinteger :: i,j,kdo i=0,n
do j=0,npotential(i,j)=(real(i)/real(n)) ** 2+&
real(j)/real(n)end do
end dodo i=1,n
do j=1,nfield(i,j,1)=(potential(i,j)-&
potential(i-1,j)) * real(n)field(i,j,2)=(potential(i,j)-&
potential(i,j-1)) * real(n)end do
end doend program grad

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 15 of 41
PraktikumWissenschaftliches Rechnen
program grad...head ...!$OMP PARALLEL PRIVATE(i,j)&
!$OMP SHARED(potential,field,n)!$OMP DO
do j=0,ndo i=0,n
potential(i,j)=(real(i)/real(n)) ** 2+&real(j)/real(n)
end doend do
!$OMP END PARALLEL DO!$OMP DO
do j=1,ndo i=1,n
field(i,j,1)=(potential(i,j)-&potential(i-1,j)) * real(n)
field(i,j,2)=(potential(i,j)-&potential(i,j-1)) * real(n)
end doend do
!$OMP END PARALLEL DO!$OMP END PARALLELend program grad
Grundregel: Parallelisiere die äußerste Schleife!

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 16 of 41
PraktikumWissenschaftliches Rechnen
4.6. OpenMP - smooth.c
Beispiel: Smoothing Glätten eines Datensatzes
for (i=1; i<m; i++){
for (j=1; j<n-1; j++){
a[i][j]=(a[i-1][j-1]+a[i-1][j] \+a[i-1][j+1])/3.0;
}}
for (i=1; i<m; i++){
#pragma omp parallel for private(j)for (j=1; j<n-1; j++)
{a[i][j]=(a[i-1][j-1]+a[i-1][j] \
+a[i-1][j+1])/3.0;}
}

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 17 of 41
PraktikumWissenschaftliches Rechnen
4.7. OpenMP - Directive Format
#pragma omp directive [clause[[,]clause]...] newline
4.8. OpenMP - Parallel regions construct
#pragma omp parallel [clause[[,]clause]...] newlinestructured-block
4.9. OpenMP - Work sharing constructs
• for Construct#pragma omp for [clause[[,]clause]...] newlinefor-loop
• Die Iterationen der Loops werden auf die Threads verteilt.• Dabei finden die folgenden Scheduling Strategien Anwendung:
static , dynamic , guided und runtime
• Das for-Statement muss eine „einfache“ Gestalt besitzen.• Der Geltungsbereich der Variablen wird durch private ,
firstprivate , lastprivat und reduction festgelegt.• Die Klausel nowait unterdrückt die Synchronisation am Ende
der Loop.

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 18 of 41
PraktikumWissenschaftliches Rechnen
• sections Construct#pragma omp sections [clause[[,]clause]...] newline
{[ #pragma omp section new-line]
structured-block[ #pragma omp section new-line
structured-block]...}
• workshare Construct (nur Fortran!)!$OMP WORKSHAREblock
!$OMP END WORKSHARE [NOWAIT]z. B. array assignment, intrinsic funktions, where statenent
• Kurzformenz.B. #pragma omp parallel forMöglich, wenn nur eine „paralleles Objekt“ in der parallelen Regionenthalten ist.

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 19 of 41
PraktikumWissenschaftliches Rechnen
4.10. OpenMP - schedule Clause
• schedule (static[,chunk])Die Iterationen werden gleichmäßig in Blöcken (chunks) derGröße chunk reihum auf die Threads aufgeteilt. Default-Wertfür chunk ist die Anzahl der Iterationen dividiert durch die An-zahl der Threads.
• schedule (dynamic [,chunk])Die Iterationen werden in Blöcken (chunks) der Größe chunkauf die Threads aufgeteilt. Der Thread, der seinen Block abge-arbeitet hat, bekommt einen neuen zugewiesen. Default-Wertfür chunk ist 1.
• schedule (guided [,chunk])Die Iterationen werden in Blöcken (chunks) auf die Threads auf-geteilt, deren Größe exponentiell abnimmt. Mit chunk wird dieminimale Blockgröße angegeben. Default-Wert für chunk ist 1.
• schedule (runtime)Das Schleifen-Scheduling kann zur Laufzeit durch die Umge-bungsvariable OMP_SCHEDULEfestgelegt werden.
• Die Voreinstellungen sind implementationsabhängig. Meist istschedule (static) voreingestellt

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 20 of 41
PraktikumWissenschaftliches Rechnen
4.11. OpenMP - single /master and Synchronization Constructs
Zuerst zwei Work Sharing Constructs:
• single Construct#pragma omp single [clause[[,]clause]...] newlinestructured-blockSynchronisation am Ende des Blocks!
• master Construct#pragma omp master newlinestructured-blockKeine Synchronisation am Ende des Blocks!
Synchronization Constructs:
• barrier Construct#pragma omp barrier newline
• critical Construct#pragma omp critical (name)] newlinestructured-block
• atomic Construct#pragma omp atomic newlinestructured-stmt
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 21 of 41
PraktikumWissenschaftliches Rechnen
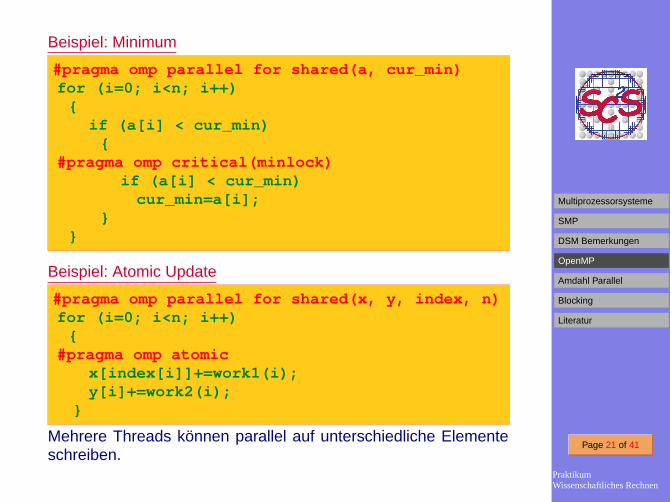
Beispiel: Minimum
#pragma omp parallel for shared(a, cur_min)for (i=0; i<n; i++)
{if (a[i] < cur_min)
{#pragma omp critical(minlock)
if (a[i] < cur_min)cur_min=a[i];
}}
Beispiel: Atomic Update
#pragma omp parallel for shared(x, y, index, n)for (i=0; i<n; i++)
{#pragma omp atomic
x[index[i]]+=work1(i);y[i]+=work2(i);
}
Mehrere Threads können parallel auf unterschiedliche Elementeschreiben.
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 22 of 41
PraktikumWissenschaftliches Rechnen
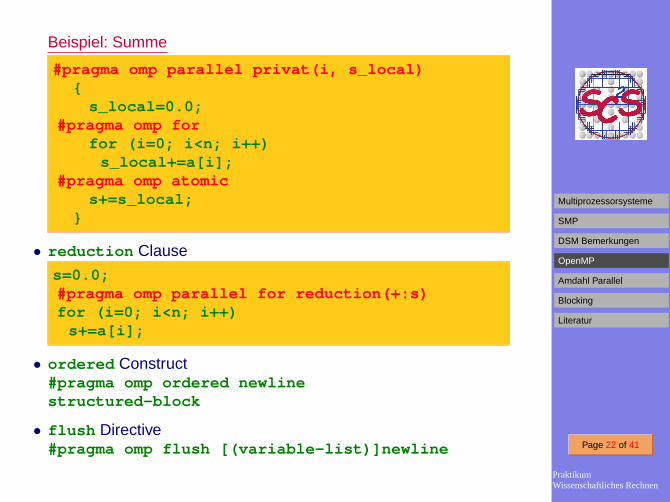
Beispiel: Summe
#pragma omp parallel privat(i, s_local){
s_local=0.0;#pragma omp for
for (i=0; i<n; i++)s_local+=a[i];
#pragma omp atomics+=s_local;
}
• reduction Clause
s=0.0;#pragma omp parallel for reduction(+:s)for (i=0; i<n; i++)
s+=a[i];
• ordered Construct#pragma omp ordered newlinestructured-block
• flush Directive#pragma omp flush [(variable-list)]newline

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 23 of 41
PraktikumWissenschaftliches Rechnen
Beispiel: spin lock
#include <stdio.h>#include <omp.h>main()
{int me=0;int ticket;
#pragma omp parallel private(me) shared(ticket){
#ifdef _OPENMPme=omp_get_thread_num();
#endif#pragma omp single
{ ticket=0;}do {
#pragma omp flush(ticket)} while (ticket < me);work(me);ticket++;
#pragma omp flush(ticket)fprint("%d \n",me);
}}

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 24 of 41
PraktikumWissenschaftliches Rechnen
4.12. OpenMP - Variable scoping clauses and directives
• Normalerweise sind alle Variablen shared.
• Globale Variablen sind shared (Fortran: Common-Blöcke, Va-riable mit dem save-Attribut, Modul-Variable; C: Variable, derenGeltungsbereich sich auf die ganze Quelldatei erstreckt, Varia-ble mit dem static oder extern Attribut), falls sie nicht als thread-private vereinbart sind.
• Ausnahme: Die Schleifenindizes von parallelisierten Zählschlei-fen sind private.
• threadprivat DirectiveGlobale Variablen werden durch threadprivat privatisiert. Siekönnen durch die copyin Klausel initialisiert werden.
Data-Sharing Attribute Clauses
• privates. Beispiele
• shareds. Beispiele
• reduktions. Beispiele
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 25 of 41
PraktikumWissenschaftliches Rechnen
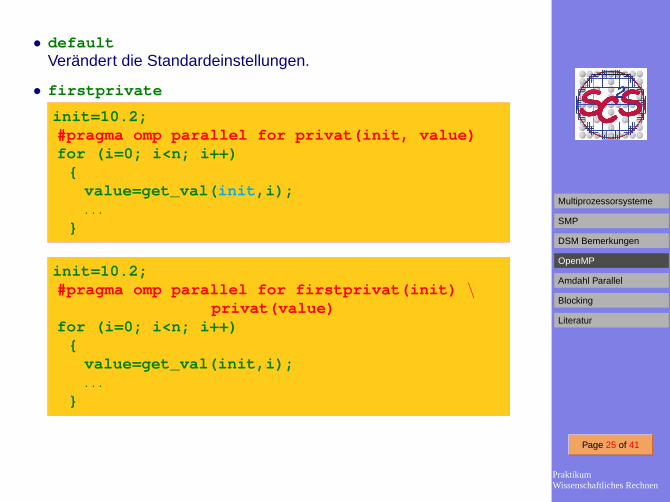
• defaultVerändert die Standardeinstellungen.
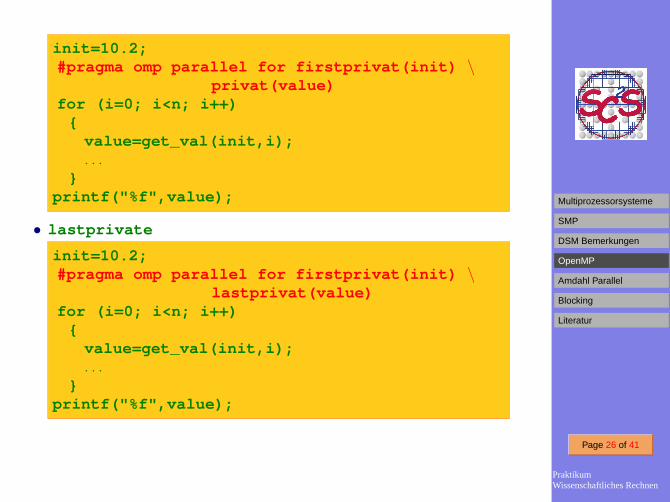
• firstprivate
init=10.2;#pragma omp parallel for privat(init, value)for (i=0; i<n; i++)
{value=get_val( init ,i);. . .
}
init=10.2;#pragma omp parallel for firstprivat(init) \
privat(value)for (i=0; i<n; i++)
{value=get_val(init,i);. . .
}
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 26 of 41
PraktikumWissenschaftliches Rechnen
init=10.2;#pragma omp parallel for firstprivat(init) \
privat(value)for (i=0; i<n; i++)
{value=get_val(init,i);. . .
}printf("%f",value);
• lastprivate
init=10.2;#pragma omp parallel for firstprivat(init) \
lastprivat(value)for (i=0; i<n; i++)
{value=get_val(init,i);. . .
}printf("%f",value);

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 27 of 41
PraktikumWissenschaftliches Rechnen
4.13. OpenMP - Runtime library
In OpenMPstehen einige Funktionen zur Verfügung, mit denen dieparallele Programmausführung zur Laufzeit gesteuert werden kann.Diese Funktionen werden nicht als Pragma angegeben, daher sollte#ifdef verwendet werden um eine fehlerfreie sequenzielle Über-setzung zu gewährleisten. Beispiele sind:
• omp_set_num_threads(int num_threads )
• omp_get_num_threads()
• . . .
• omp_set_num_dynamic()
• . . .
• Lock FunctionsMutex Operationen zum Steuerung kritischer Abschnitte im Ei-genbau.
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 28 of 41
PraktikumWissenschaftliches Rechnen
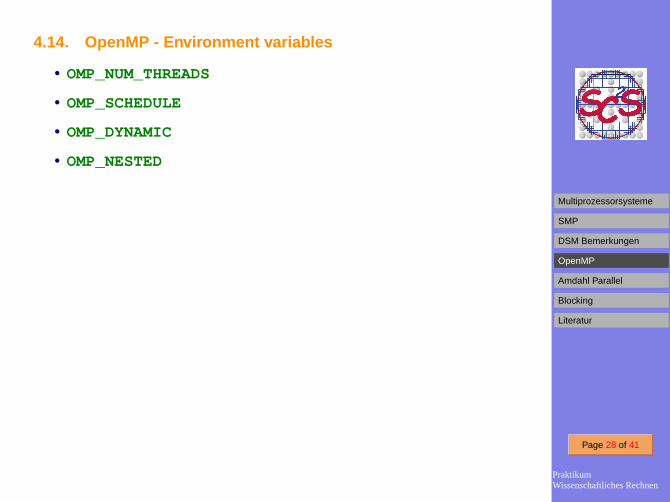
4.14. OpenMP - Environment variables
• OMP_NUM_THREADS
• OMP_SCHEDULE
• OMP_DYNAMIC
• OMP_NESTED

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 29 of 41
PraktikumWissenschaftliches Rechnen
4.15. OpenMP - Links
www http://www.rz.rwth-aachen.de/hpc/talks/SunHPC_2002/OpenMP-Dateien/v3_document.htm
www http://www.compunity.org/
www http://www.openmp.org/drupal/node/view/8
www http://docs.sun.com/
www PortlandGroup Dokumentation

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 30 of 41
PraktikumWissenschaftliches Rechnen
5. Amdahl’sches Gesetz für Parallelisierung
Der Anteil q der m Operationen eines Problems wird auf p Prozes-soren gelöst. Die restlichen Operationen werden sequenziell gelöst.Damit ergibt ich der Speedup nach Amdahl zu
sp(p, q) =t1tp
=mR1
m·qp·R1
+ m(1−q)R1
=1
q 1p
+ (1− q)−−−→p→∞
1
1− q, (1)
wenn t1 die sequenzielle Ausführungszeit, tp parallele Ausführungs-zeit und R1 die Performance des einzelnen Prozessors ist.Was macht Amdahl falsch?
• Parallele Programme besitzen andere Datenstrukturen und Al-gorithmen.
• Es existiert ein paralleler Overhead (Synchronisation, Kommu-nikation, . . . )
• Die Vektorlänge sinkt mit 1/p.
In [1] finden sich dazu ausführliche Betrachtungen.

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 31 of 41
PraktikumWissenschaftliches Rechnen
6. „Cache Bocking“ Algorithmen
6.1. Loop Unrolling
for(i=0;i<n;i++){for(j=0;j<m;j++){
a[i][j]=b[i][j]+c[i][j] * d;}
}for(i=0;i<n;i+=3){
for(j=0;j<m;j++){a[i][j]=b[i][j]+c[i][j] * d;a[i+1][j]=b[i+1][j]+c[i+1][j] * d;a[i+2][j]=b[i+2][j]+c[i+2][j] * d;
}}
PC: Speicherzugriff mit Stride (wenn m klein kein Problem s. u.)
Daumenregeln:
• Unrolling „dicker“ Schleifen zahlt sich nicht aus!
• Kurze Schleifen ⇒ „full unrolling“!
• Lange Schleifen; dünner Körper ⇒ unrolling!

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 32 of 41
PraktikumWissenschaftliches Rechnen
for(j=0;j<n;j++){
for(i=0;i<m;i++){
a[i]+=b[j][i];}
}
for(j=0;j<n;j+=2){
for(i=0;i<m;i++){
a[i]+=b[j][i]+b[j+1][i];}
}
• Grundsätzlich sollte der Compiler die Scheifen optimieren!
• „Handarbeit“ ist nur bei komplexeren Problemen gefragt!

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 33 of 41
PraktikumWissenschaftliches Rechnen
6.2. Speicherzugriff mit „Stride“
for(i=0;i<n;i++){
for(j=0;j<m;j++){
a[i][j]+=b[j][i];}
}
Skizzen der Arrays a und b mit Cache-lines

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 34 of 41
PraktikumWissenschaftliches Rechnen
Skizzen der Arrays a und b - Zugriff auf den Speicher
Wie oft muss b in den Cache geladen werden?for(j=0;j<n;j+=3)
{for(i=0;i<m;i+=3)
{a[i][j]+=b[j][i];a[i+1][j]+=b[j+1][i];a[i+2][j]+=b[j+2][i];a[i][j+1]+=b[j][i+1];. . .
}}

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 35 of 41
PraktikumWissenschaftliches Rechnen
Skizzen der Arrays a und b mit Cache-Blocking
for(j=0;j<n;j+=3){
for(i=0;i<m;i+=3){
a[i][j]+=b[j][i];a[i+1][j]+=b[j+1][i];a[i+2][j]+=b[j+2][i];a[i][j+1]+=b[j][i+1];. . .
}}

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 36 of 41
PraktikumWissenschaftliches Rechnen
6.3. Matrix-Matrix-Multiplikation mit Cache-Blocking
cij =n∑
k=1
aik · bkj , i, j = 1 . . . n.
���������������������������������������������������������������������������������������������������������
���������������������������������������������������������������������������������������������������������
����������������������������
����������������������������
i
k
k
j
A
B
C
Skizze der Matrix-Matrix-Multiplikation -Bearbeitung in Spalten (Fortran)
Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 37 of 41
PraktikumWissenschaftliches Rechnen
����������������������������
����������������������������
������������������������������������������
������������������������������������������
k
k
j
A
B
C
i
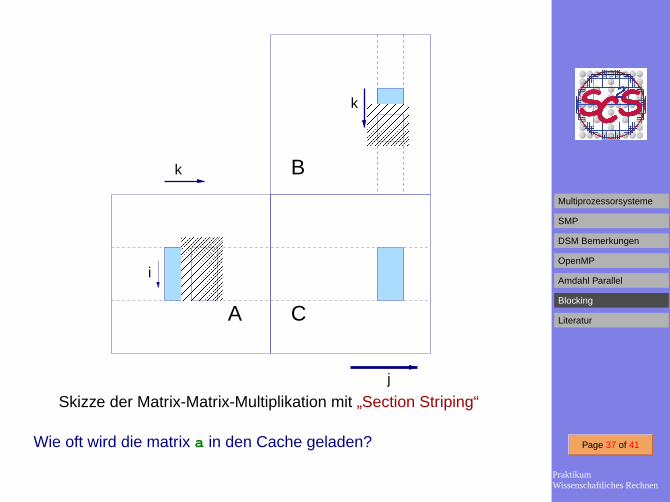
Skizze der Matrix-Matrix-Multiplikation mit „Section Striping“
Wie oft wird die matrix a in den Cache geladen?

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 38 of 41
PraktikumWissenschaftliches Rechnen
• a muß für jede Spalte von c neu geladen werden
⇒ lade einen Teil von a und benutze ihn für alle Spalten von c
������������������������������������������
������������������������������������������
������������������������������������������������������������������
������������������������������������������������������
����������������������������
����������������������������
��������������������������������������������
����������������
�����������������������������������������������������������������������������������������
A
B
C
i
j
k
k
Skizze der Matrix-Matrix-Multiplikation mit „Cache Blocking“
⇒ c muß nun für jeden „Cache-fill“ geladen werden

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 39 of 41
PraktikumWissenschaftliches Rechnen
Einschub Cache-Organisation:
• Direct-Mapped-Cache
– Hauptspeicher ist in Blöcke von der Größe des Caches auf-geteilt.
– Die Reihenfolge der Cache-lines im Cache entspricht derim HS.
– Damit ist die Position einer Cache-line durch die Blocknum-mer gegeben.
• full-associative-Cache
– Jede Cache-line kann beliebig im Cache abgelegt werden.
– Um eine Cache-line zu finden, müssen gleichzeitig alle Po-sitionen (voll assoziative) in einem Takt verglichen werden.
• n-way-associative-Cache
– n-facher Direct-Mapped-Cache.
Wie muss ein Cache-Blockling-Algorithmus bei einem Direct-Mapped-Cache bzw. einem n-way-associative-Cache verändertwerden?
Details zur Cache-Optimierung finden sich in [2] und [1].

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 40 of 41
PraktikumWissenschaftliches Rechnen
Literatur
[1] SCHÖNAUER, W.: Scientific Supercomputing. Karlsruhe : Schö-nauer, 2000. – Bem: Anwendungs bezogenes Vorlesungsskript,das lange Zeit handschriftlich (?!) im Web zufinden war. Sehrempfehlenswert! . – ISBN 3–00–005484–7
[2] DOWD, Kevin ; SEVERANCE, Charles: High Performance Compu-ting. O’Reilly, 1998. – Bem: Ein Buch für Praktiker! OptimierterSpeicherzugriff, Schleifen-Optimierung und Benchmarking sindnur einige Themen aus dem breiten Vorrat, den dieses Buch be-reit hällt. – ISBN 3–931216–76–4
[3] CHANDRA, R. ; DAGUM, L. ; KOHR, D. ; MAYDAN, D. ; MCDONALD,J. ; R.MENON: Parallel Programming in OpenMP. Morgan Kauf-mann Publishers, 2001. – Bem: Einziges Lehrbuch und überallerwähntes Standardwerk.. – ISBN 1–55860–671–8
[4] UNGERER, Th.: Parallelrechner und parallele Programmierung.Berlin : Spektrum, 1997. – Bem: Das Buch gibt einen weitreich-nenden Überblick. Es schliest die Lücke zwischen theoretischenKonzepten einerseits und einer Handware bezogenen Betrach-tung andererseits hin zur praktischen Anwendung. Es handeltsich um ein klassisches Lehrbuch. – ISBN 3–8274–0231–X

Multiprozessorsysteme
SMP
DSM Bemerkungen
OpenMP
Amdahl Parallel
Blocking
Literatur
Page 41 of 41
PraktikumWissenschaftliches Rechnen
[5] MÄRTIN, Ch.: Rechnerachitekturen. Leibzig : Fachbuchverlag,2001. – Bem: Wer über die Inhalte des Praktikums hinaus anRechnerarchitektur interresiert ist, findet hier ein Lehrbuch, dassich auch sehr gut als Nachschlagewerk eignet. – ISBN 3–446–21475–5
Related Documents











