a r X i v : 1 2 0 8 . 3 5 2 4 v 1 [ p h y s i c s . d a t a - a n ] 1 7 A u g 2 0 1 2 Submitted to the Annals of Applied Statistics POWER-LA W DISTRIBUTIONS IN BINNED EMPI RICAL DATA By Yogesh Virkar † and Aaron Clauset †,‡,∗ University of Colorado at Boulder † Santa Fe Institute ‡ Many man-made and natural phenomena, including the intensity of earthquakes, population of cities, and size of international wars, are believed to follow power-la w distributions. The accurate identification of power-law patterns has significant consequences for developing an understanding of complex systems. However, statistical evidence for or against the power-law hypothesis is complicated by large fluctua- tions in the empirical distribution’s tail, and these are worsened when information is lost from binning the data. We adapt the statistically principled framework for testing the power-law hypothesis, developed by Clauset, Shalizi and Newman, to the case of binned data. This ap- proach includes maximum-likelihood fitting, a hypothesis test based on the Kolmogorov-Smirnov goodness-of-fit statistic and likelihood ratio tests for comparing against alternative explanations. We evalu- ate the effectiveness of these methods on synthetic binned data with known structure and apply them to twelve real-world binned data sets with heavy-tailed patterns. 1. Int roducti on. Po wer-la w distributions have attracted broad scien- tific interest [36] both for their mathematical properties, which sometimes lead to surprising consequences, and for their appearance in a wide range of natural and man-made phenomena, spanning physics, chemistry, biology, computer science, economics and the social sciences [ 21, 23 , 33, 13 ]. Qua nt iti es that fol lo w a power- law dis tri but ion are someti mes said to exhibit “scal e inv arianc e”, indica ting that common, small even ts are not qualitatively distinct from rare, large events. Identifying this pattern in em- pirical data can indicate the presence of unusual underlying or endogenous processes, e.g., feedback loops, network effects, self-organization or optimiza- tion, although not always [ 29]. Knowing that a quantity does or does not follow a power law provides important theoretical clues about the underlying generative mechanisms we should consider. It can also facilitate statistical extrapolations about the likelihood of very large events [ 7]. ∗ To whom correspondence should be addressed. AMS 2000 subject classifications: Primary 62G32, 62-07; secondary 65C05 Keywords and phrases: power-law distribution, heavy-tailed distributions, model selec- tion, binned data 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 1/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 2/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 3/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 4/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 5/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 6/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 7/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 8/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 9/33
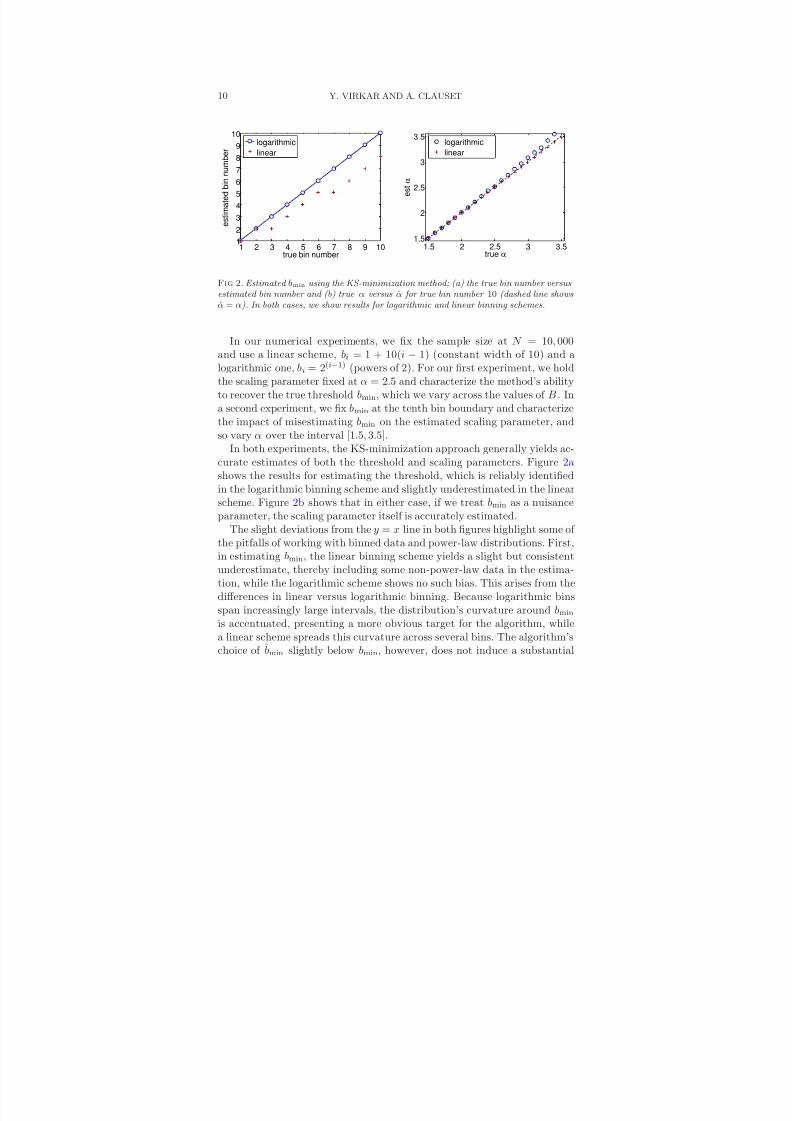
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 10/33
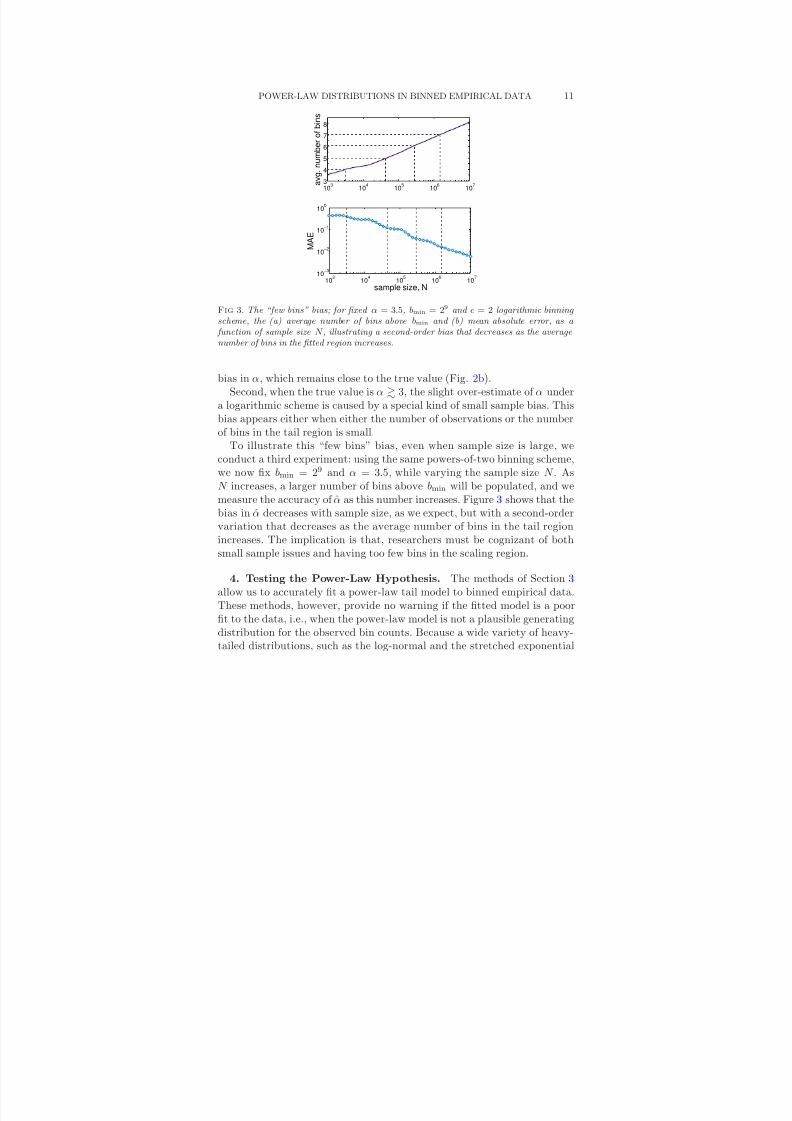
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 11/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 12/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 13/33
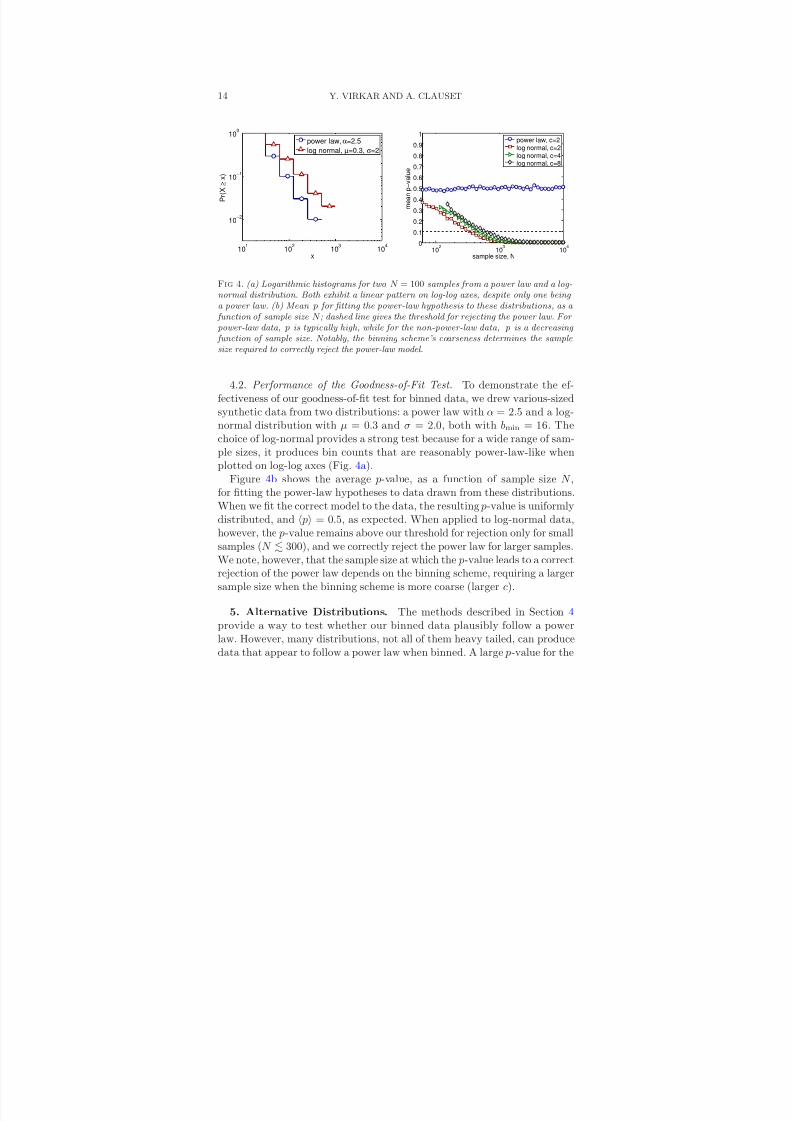
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 14/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 15/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 16/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 17/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 18/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 19/33
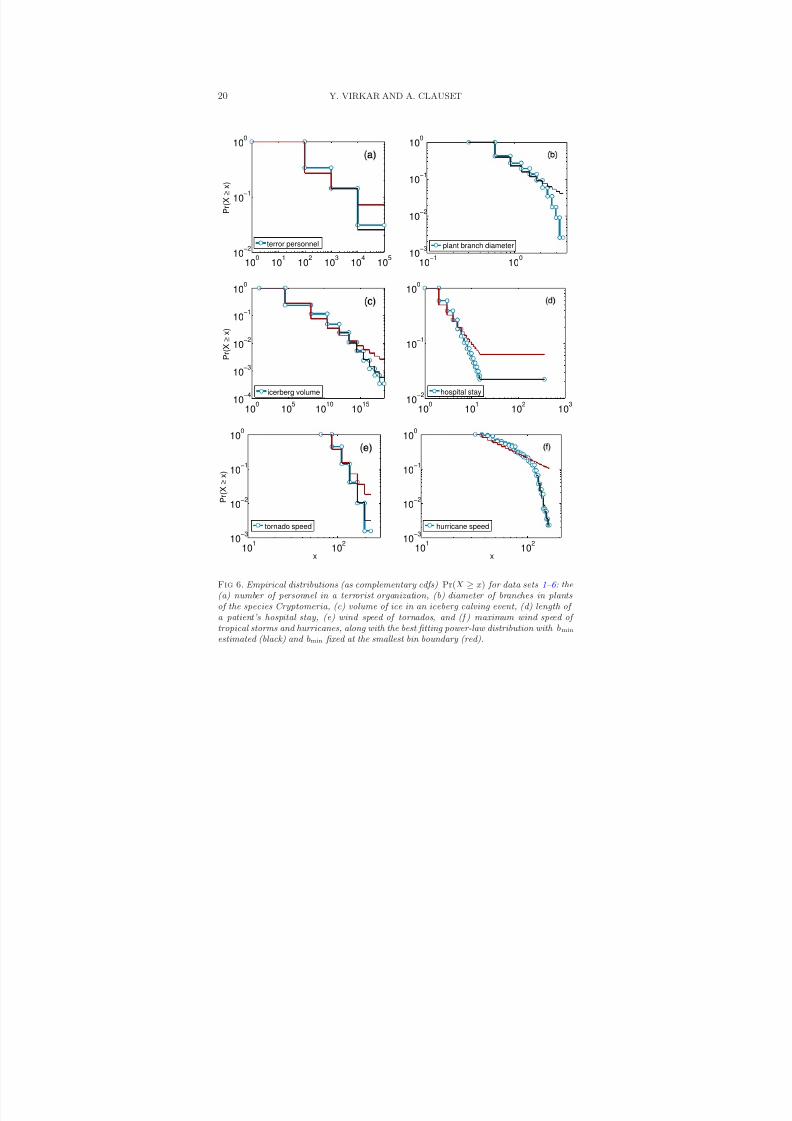
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 20/33
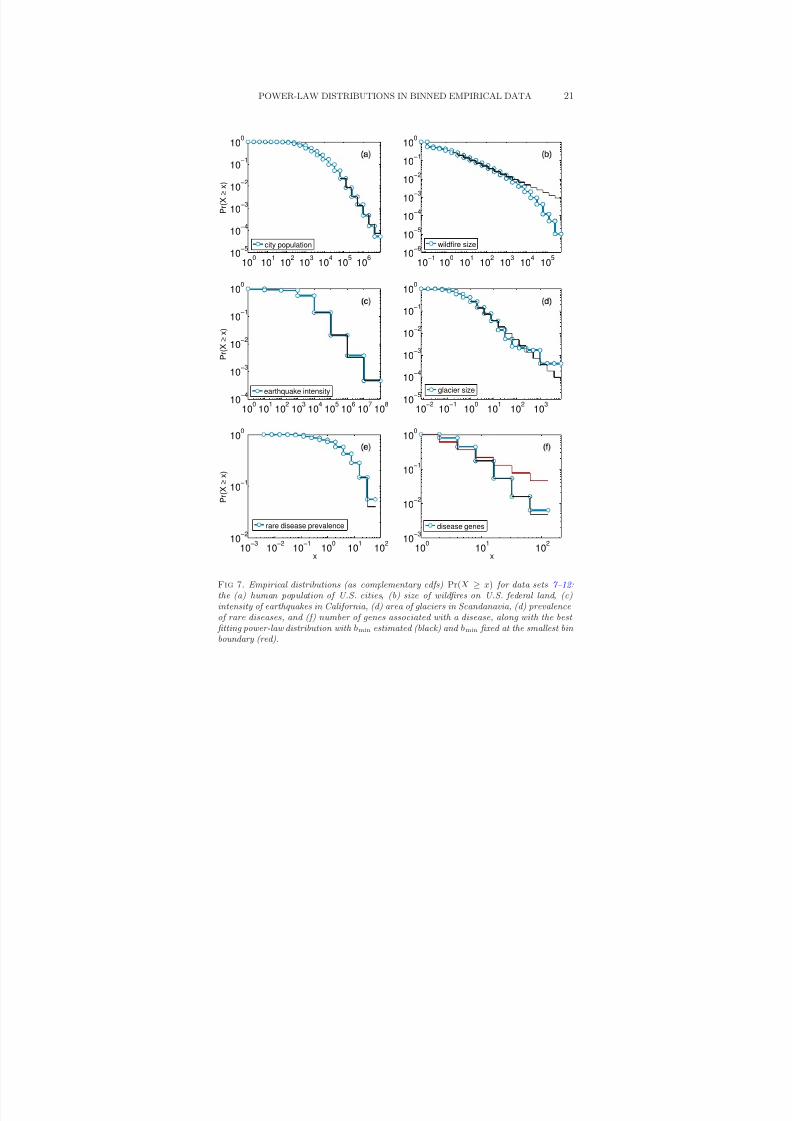
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 21/33
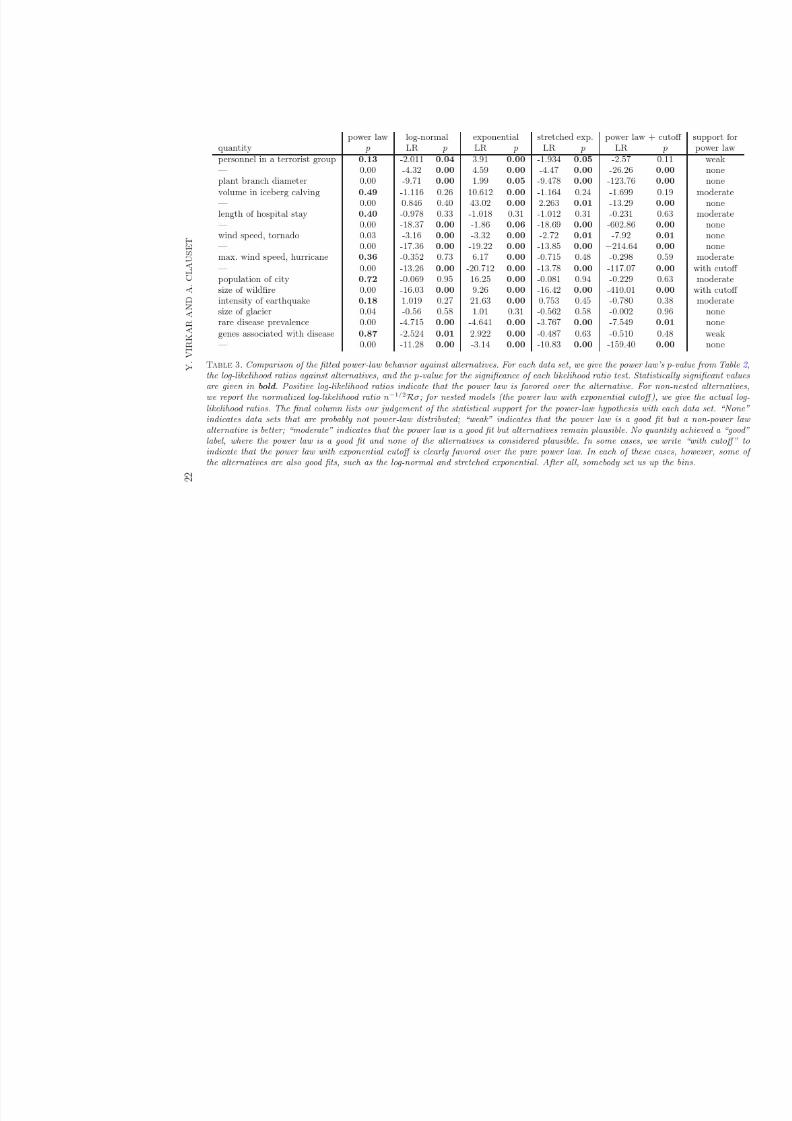
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 22/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 23/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 24/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 25/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 26/33
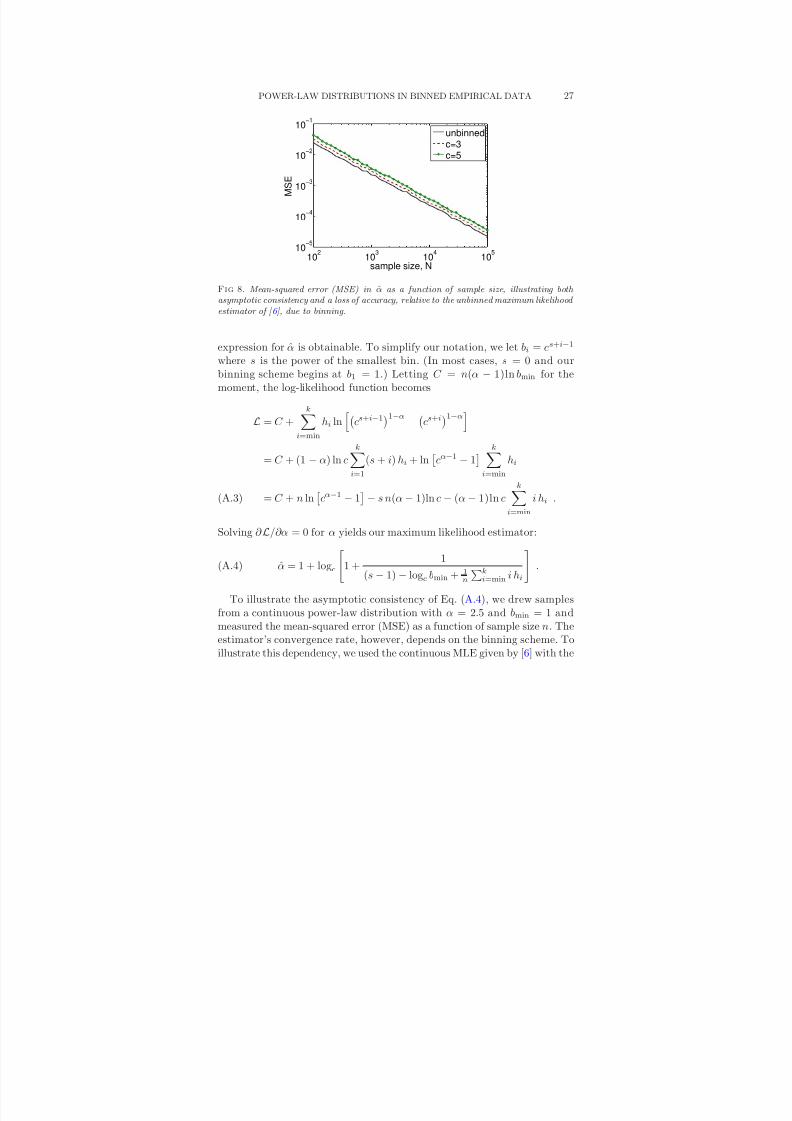
8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 27/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 28/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 29/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 30/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 31/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 32/33

8/13/2019 Power-law Distributions in Binned Empirica_data
http://slidepdf.com/reader/full/power-law-distributions-in-binned-empiricadata 33/33
Related Documents











