ORNL is managed by UT-Battelle for the US Department of Energy Portable Heterogeneous High-Performance Computing via Domain-Specific Virtualization Dmitry I. Lyakh [email protected] This research used resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under contract No. DE-AC05-00OR22725.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

ORNL is managed by UT-Battelle for the US Department of Energy
Portable HeterogeneousHigh-PerformanceComputing viaDomain-SpecificVirtualization
Dmitry I. [email protected]
This research used resources of the Oak Ridge Leadership Computing Facility at the Oak RidgeNational Laboratory, which is supported by the Office of Science of the U.S. Department of Energyunder contract No. DE-AC05-00OR22725.

2 ExaTensor
Application-Hardware Interface
HPC Application
Hardware/HPC-system
Interface Width
Interface Width ~ O(1): Manageable Performance Portability, regardless ofthe programming model(only O(1) parts of the codeinteract with raw hardware)
Direct Interface
Interface Width ~ O(N): Performance Portability canbecome an issue, even ifusing OpenMP/OpenACC
HPC Application
Runtime + Libraries
Interface Width
Performance Portability effort is shifted towards Runtime and Libraries
Uni-Indirect Interface
Hardware/HPC-system
Interface Width
HPC Application responsibility to be aware of Hardware
HPC Application
Domain-SpecificRuntime + Libraries
Interface Width
Performance Portability effort is shifted towardsdomain-specific Runtime and Libraries
Bi-Indirect Interface
DS Runtime is aware of boththe Application and Hardware
Hardware/HPC-system
Interface Width
Performance portability effort is shifted towards Runtime and Libraries
HPC Application is awareof Runtime, Runtime isresponsible to be awareof Hardware

3 ExaTensor
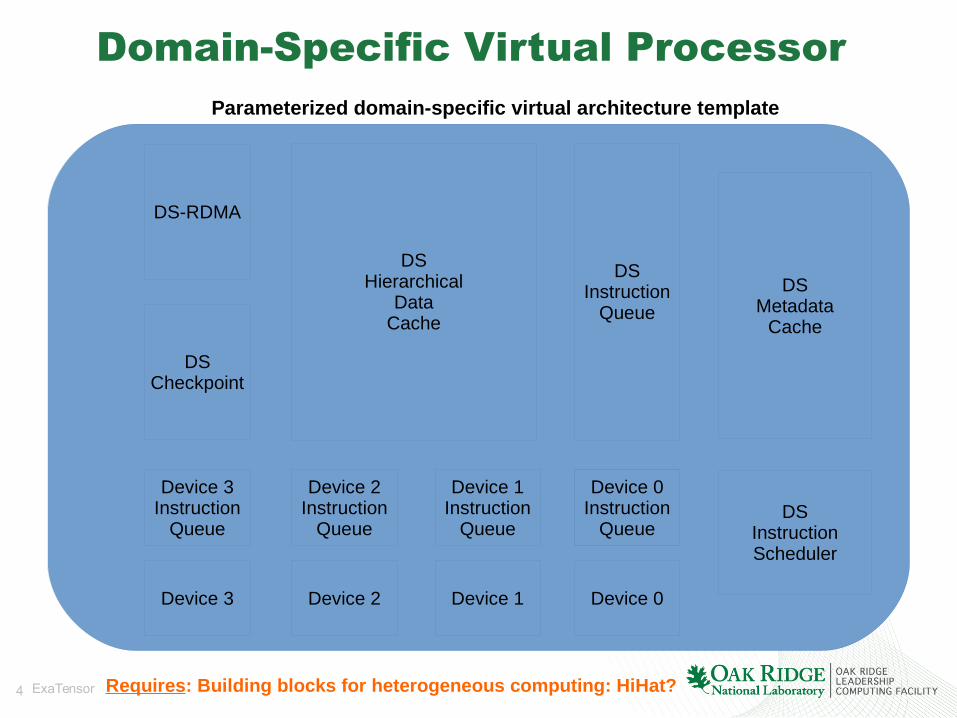
Domain-Specific Virtual Processor
HPC Application
Domain-SpecificVirtual Processor + Libraries
Interface Width
Hardware/HPC-system
Interface Width
A better structured runtime thatformally resembles a processorbut specialized to the domain-specific workloads
Understands the specificityof domain-specific data,operations, and algorithms
Understands the specificityof a class of HPC architecturesvia a parameterized templateof node architectures
➢ The domain HPC applications express their algorithms in a domain-native language (higher-level),either via a standalone or embedded DSL;
➢ The domain algorithms are compiled into instructions for a domain-aware virtual architecture;➢ The virtual architecture is built from virtual units that map reasonably well to the physical hardware;➢ Hardware encapsulation, yet potential for a seemless co-design.
4 ExaTensor
Domain-Specific Virtual Processor
DSInstruction
Queue
DSMetadata
Cache
Device 0Instruction
Queue
Device 0
Device 0Instruction
Queue
Device 1
Device 1Instruction
Queue
Device 2
Device 2Instruction
Queue
Device 3
Device 3Instruction
Queue
DSHierarchical
DataCache
DS-RDMA
DSCheckpoint
Parameterized domain-specific virtual architecture template
DSInstructionScheduler
Requires: Building blocks for heterogeneous computing: HiHat?

5 ExaTensor
Performance Portability Strategy• Abstract computing system template:
– Distributed (weakly-coupled) level: The computing systemis composed of compute nodes interconnected via network interfaces in some topology
– (Semi-)shared (strongly-coupled) level: Each node is composed of multiple compute devices of the same or different kinds, possibly sharing the same (hierarchical) memory
• Algorithms are formulated for this abstract computer
• The hardware specificity is masked by driver libraries that provide a device-unified API interface for a set of necessary domain-specific primitives (DS-ISA)
• New hardware = New driver library

6 ExaTensor
Use Case: Numerical Tensor Algebra
• Quantum many-body theory: Electronic and Nuclear structure, Quantum computing: Wave-function
• Loop quantum gravity: Fine structure of space-time
• Multivariate data analytics: Extracting correlations, features, data compression
• Classical physics
• Any data arranged as a multi-dimensional array is a tensor (in the most general sense)
• Any function of multiple variables discretized over a grid or some functional inner-product space is a tensor

7 ExaTensor
Coupled-Cluster Theory
Electron correlation = Correlationbetween hole-particle excitations
i a
j b
i aj b
kc
i aj b
i aj b

8 ExaTensor
Automated Development Tools and DSL• Automated equation/code generators are unavoidable
• DSLangs and DSLibs can provide a scalable development environment: DiaGen input/output:
Efficient flexible runtime?

9 ExaTensor
Past/Present Experience• 2002-2005: CLUSTER: Automated code generation:
CAS-CCSD method = Millions of generated SLOC
• 2006-2008: CLUSTER moved to a direct interpretation of many-body CC equations: High-level spec → Bytecode
• 2009-2013: ACES III and ACES IV: Domain-specific super-instruction language and runtime (SIAL/SIP):SIAL (med.level) → SIP bytecode → Interpretation by SIP
• 2014+: ExaTENSOR framework: Direct interpretation of generic tensor expressions on heterogeneous HPC architectures with cross-domain applications
• Other efforts: Code generation (TCE), embedded DSL + Tensor Algebra library (Aquarius/Cyclops, TiledArray)

10 ExaTensor
Math Framework: Basic Tensor Algebra• Formal tensor: : n-D Array
Full tensor:
Tensor slice:
• Tensor addition:
• Tensor product:
• Tensor contraction:
Compute intensive (potentially)!
Parallelism!
Parallelism!
Few primitive operations:
,...),,,(...... srqpTT pq
rs SsRrQqPpsrqpT ,,,:),,,(
SSsRRr
QQqPPpsrqpT
','
,',':),,,(
pqrs
pqrs
pqrs RLTsrqp :,,,
qs
pr
pqrs RLTsrqp :,,,
qbcdrsai
paibcd
pqrs RLTsrqp :,,,
11 ExaTensor
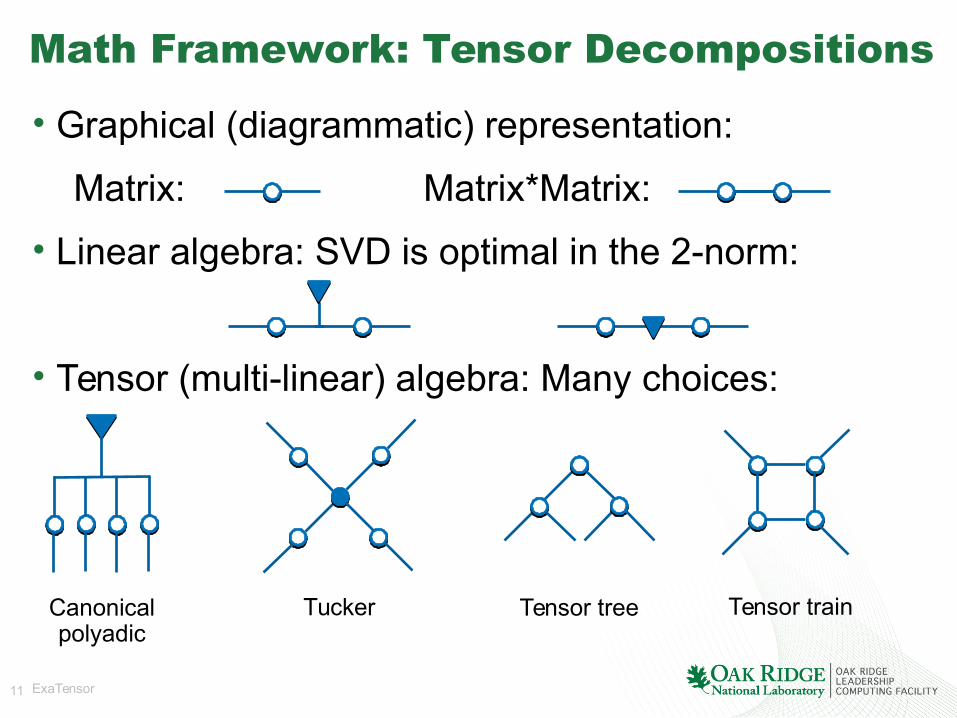
Math Framework: Tensor Decompositions
• Graphical (diagrammatic) representation:
Matrix: Matrix*Matrix:
• Linear algebra: SVD is optimal in the 2-norm:
• Tensor (multi-linear) algebra: Many choices:
Canonicalpolyadic
Tucker Tensor tree Tensor train

12 ExaTensor
Tensor Sparsity• Dense tensors:
• Block-sparse tensors (container of dense slices):
• Regular sparse tensors:– Some regular sparsity pattern other than block sparsity
• Irregular sparse tensors:– Sparsity pattern has no regularity

13 ExaTensor
Adaptive (+Hierarchical) Tensor Algebra
• Large tensor elements can become tensors themselves (higher resolution);
• Weak tensor slices can be compressed by lowering the resolution, up to a single (complex) number;
• Adapt to the calculated electronic state and available HPC resources;
• Should be better than just black-and-white discarding.
D.I.L. Int. J. Quantum Chem. 2014; D.I.L. ArXiv 2017
Extrapolation of H/H2-matrixalgebra to TENSORS

14 ExaTensor
Computational Challenges• Dense tensor algebra:
– Communication bandwidth: Communication avoiding and regularization (similar to the matrix multiplication, e.g.,CARMA by Demmel et al.)
– Memory size: Out-of-core algorithms
• Block-sparse tensor algebra adds:– Irregular data placement and computational workload: Load
balancing → Task-based programming model
• Adaptive hierarchical block-sparse tensor algebra adds:– Dynamic irregular data placement and computational workload:
Load balancing, dynamic data layout → Adaptive task-based programming model
ExaTENSOR: 1. Implementation of the tensor algebra DSVP for heterogeneous computing; 2. Implementation of scalable tensor algebra algorithms for TA-DSVP.

15 ExaTensor
Domain-Specific Virtual Processing • Domain-specific algorithm → Domain-specific virtual processor(s)
→ Physical processor(s):
• Why this way?– Less unneeded detail, more focus
on the domain-specific algorithms (TA);– Better portability;– Better debugability/profileability
of domain-specific algorithms;– Better opportunities for co-design.
Domain-SpecificVirtual Processor
(abstract class)
Domain-SpecificInstruction
(abstract class)
Domain-SpecificOperand
(abstract class)
TensorOperand
TensorInstruction
Tensor AlgebraProcessor
Logic Processor(control, meta-data)
Numeric Processor(numeric tensor ops)
0 1 2 3
0 1 2 3
7
11
654
8 9 10
Heterogeneous DSVPHeterogeneous DSVP(ExaTENSOR)(ExaTENSOR)

16 ExaTensor
Node-Level Virtualization: Hiding HardwareHardware Processors (CPU, GPU, etc.)

17 ExaTensor
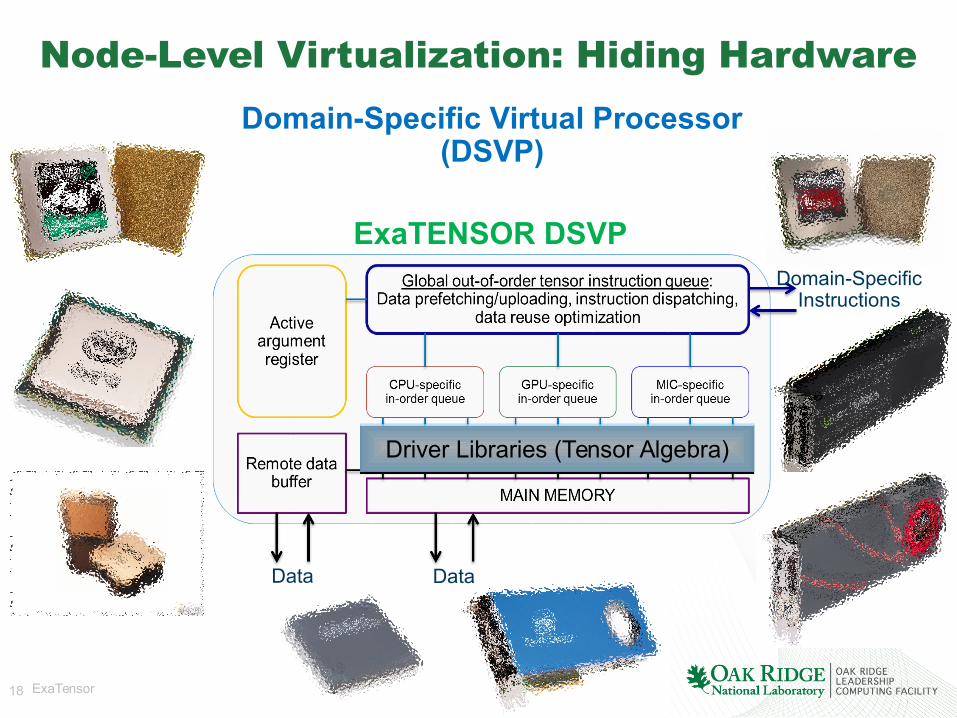
Node-Level Virtualization: Hiding HardwareDomain-Specific Virtual Processor
(DSVP)
ExaTENSOR DSVPDomain-Specific
Instructions
Data Data
18 ExaTensor
Node-Level Virtualization: Hiding HardwareDomain-Specific Virtual Processor
(DSVP)
ExaTENSOR DSVPDomain-Specific
Instructions
Data Data
Driver Libraries (Tensor Algebra)Driver Libraries (Tensor Algebra)

19 ExaTensor
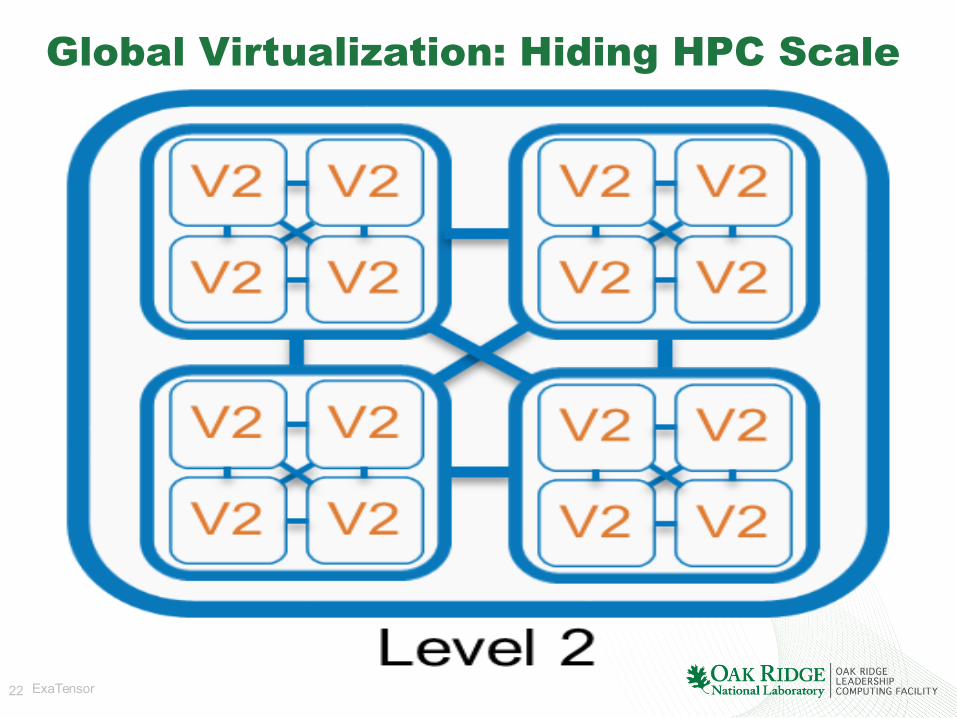
Global Virtualization: Hiding HPC Scale

20 ExaTensor
Global Virtualization: Hiding HPC Scale

21 ExaTensor
Global Virtualization: Hiding HPC Scale
22 ExaTensor
Global Virtualization: Hiding HPC Scale

23 ExaTensor
Global Virtualization: Hiding HPC Scale
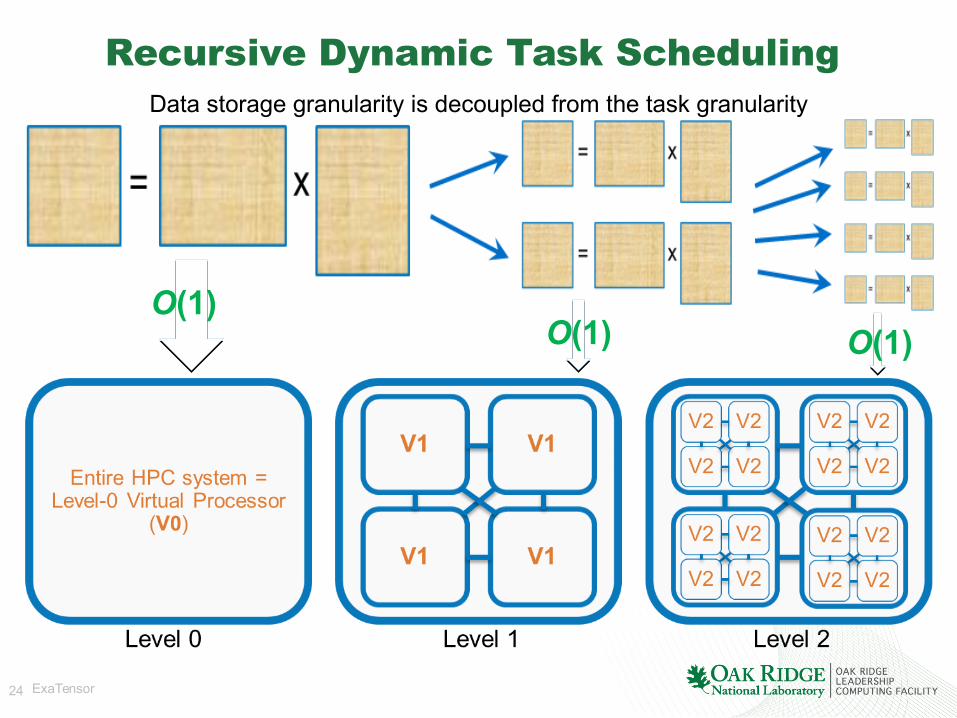
24 ExaTensor
Recursive Dynamic Task Scheduling
O(1)O(1) O(1)
Data storage granularity is decoupled from the task granularity

25 ExaTensor
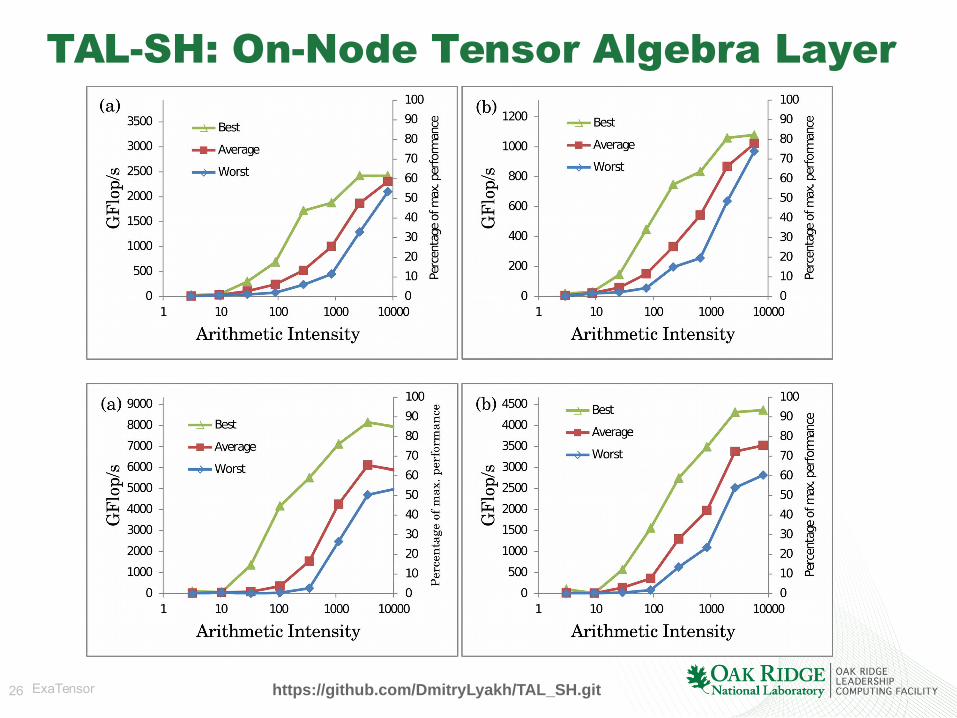
TAL-SH: On-Node Tensor Algebra Layer• Basic tensor algebra operations: Tensor contraction, tensor
product, tensor addition, tensor norm, etc.
• Supports multicore CPU and (multiple) NVIDIA GPU
• Asynchronous task-based execution on accelerators
• Automatic memory and data transfer management,data transfer pipelining
• User-controlled data presence management (images)
• Tensor contractions:
– Up to 1.1 TFlop/s double precision on NVIDIA Kepler K20x for arithmetic intensities > 1000
– Up to 4.2 TFlop/s double precision on NVIDIA Pascal P100 for arithmetic intensities > 1000
26 ExaTensor
TAL-SH: On-Node Tensor Algebra Layer
https://github.com/DmitryLyakh/TAL_SH.git
27 ExaTensor
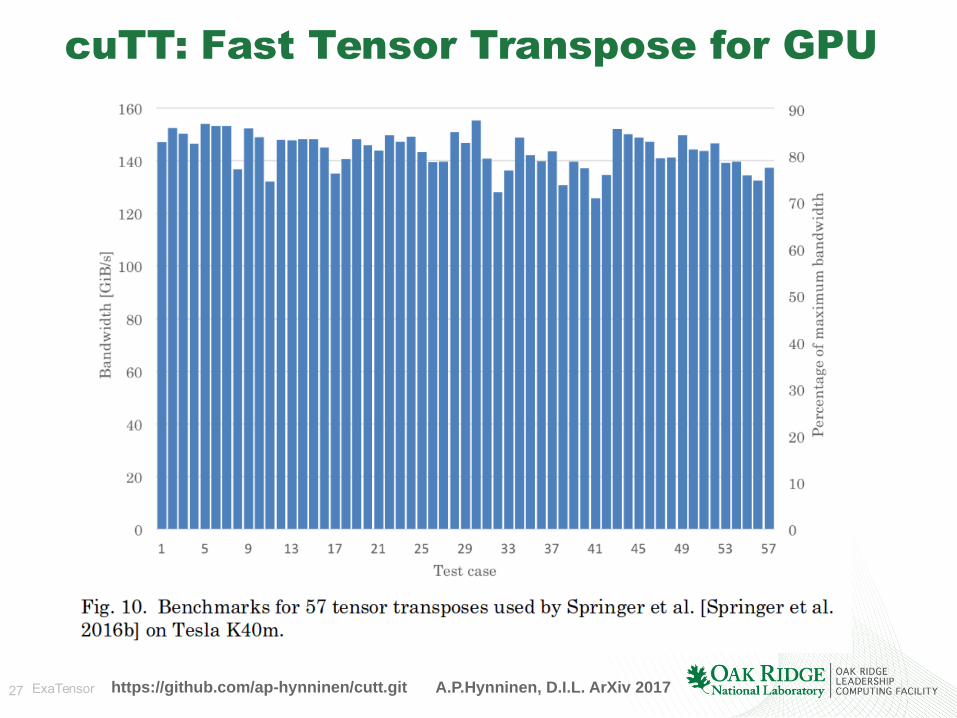
cuTT: Fast Tensor Transpose for GPU
https://github.com/ap-hynninen/cutt.git A.P.Hynninen, D.I.L. ArXiv 2017

28 ExaTensor
Conclusions• Domain-Specific Virtual Processor pros:
– Domain algorithm friendly (higher-level):Application-Runtime codesign, customizable virtual architecture;
– Hardware agnostic by design:Only requires new driver libraries with domain-specific primitives;
– HPC scale agnostic by design (via a recursive HPC system view);
– Better fault-tolerance (autonomous virtual nodes can be turned on/off);
– Good model for Hardware-Runtime codesign;
– Better debugging (in terms of higher-level operations);
– Better profiling (in terms of higher-level operations).
• Domain-Specific Virtual Processor cons:– Level of effort;
– Runtime overhead (like any virtual machine).

29 ExaTensor
Potential Programming Models• Direct non-task static: Algorithm → Target code (MPI+X or
PGAS+X) → Hardware
• Direct task static: Algorithm → Parameterized static DAG → Task-based runtime → Hardware
• Direct task dynamic: Algorithm → Dynamic DAG → Task-based runtime → Hardware
• Indirect non-task static: Algorithm → DSL → Domain-specific bytecode → Runtime interpretation → Hardware
• Indirect task static: Algorithm → DSL → Parameterized static DAG → Task-based runtime → Hardware
• Indirect task dynamic: Algorithm → DSL → Dynamic DAG → Task-based runtime → Hardware
Related Documents











