Philip Brisk 2 Paolo Ienne 2 Hadi Parandeh- Afshar 1,2 1: University of Tehran, ECE Department 2: EPFL, School of Computer and Communication Sciences Efficient Synthesis of Compressor Trees on FPGAs

Philip Brisk 2 Paolo Ienne 2 Hadi Parandeh-Afshar 1,2 1: University of Tehran, ECE Department 2: EPFL, School of Computer and Communication Sciences Efficient.
Dec 28, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Philip Brisk2
Paolo Ienne2
Hadi Parandeh-Afshar1,2
1: University of Tehran, ECE Department
2: EPFL, School of Computer and Communication Sciences
Efficient Synthesis of Compressor Trees on FPGAs

January 22, 2008 2
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 3
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 4
FPGA vs. ASIC
Performance
Area Utilization
Power Consumption
Flexibility
Time-to-Market
ASIC FPGA
√
√
√
√
√

January 22, 2008 5
FPGA Arithmetic Features
Poor Performance for Arithmetic Operations Compared to ASIC IP Cores
High Routing Costs Limited Flexibility; 18-bit Adder/Multiplier
Full Adder Implemented in CLB Structure Fast Carry-Chain (Xilinx and Altera)
Reduces Routing Delay
Cannot Use Compressor Trees to Add k>2 Values Wallace/Dadda/3-Greedy

January 22, 2008 6
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 7
Motivation: Compressor Trees
Partial product reduction in parallel multiplication Wallace and Dadda in the 1960s
Multi-input addition occurs in many multimedia and signal processing H.264/AVC Variable Block Size Motion Estimation FIR Filters 3G Wireless Base Station Channel Cards
Flow graph transformations expose opportunities to use compresor trees in high-level synthesis [Verma and Ienne, ICCAD 04]
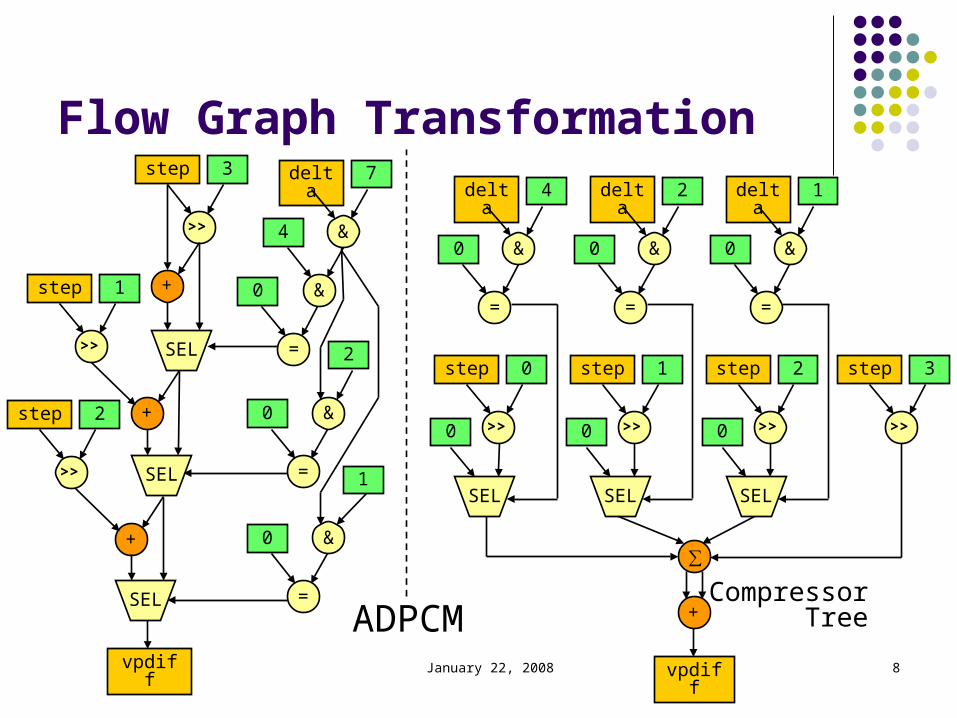
January 22, 2008 8
Flow Graph Transformationstep 3
>>
&
delta
7
&4
SEL =
0+
SEL
+
step 1
>>
&
2
=
0
SEL
+
step 2
>>
&
1
=
0
vpdiff
step 3
>>
=
delta
1
&0
step 2
>>
SEL
0
=
delta
2
&0
step 1
>>
SEL
0
=
delta
4
&0
step 0
>>
SEL
0
vpdiff
∑
+Compressor
TreeADPCM

January 22, 2008 9
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 10
Counters
m
n
m:n counter
n = log2(m+1)
Count #of Input Bits Set to 1
Output # as a Binary Value
Counters You Know
2:2 – Half Adder
3:2 – Full Adder(Carry-Save Adder)
The correct building block for computing sums of k>2 numbers
Counters do not map well onto LUTs or carry chains

January 22, 2008 11
Generalized Parallel Counters (GPCs) Sum bits having different ranks
m:n counter: all bits have rank 0, i.e.: 20 = 1 Representation:
(Kn-2, Kn-1, …, K0; S) Ki – number of input bits of rank i S – number of output bits
(0, 4; 3) – typical 4:3 counter (2, 3; 3) – maximum value: 2*21 + 4*20
= 12 Range [0, 12] requires S = 4 output bits
Examples usingdot notation (3, 3; 4) GPC (5, 5; 4) GPC

January 22, 2008 12
GPC Implementation
For ASICs Basic gates, e.g. AND, XOR Built from m:n counters, e.g., just like a
compressor tree FPGA Implementation
K-input GPC maps nicely onto K-LUTs One logic level required
K = 6 for Xilinx Virtex-5 and Altera Stratix II and III Three 6-LUTs for 6-input, 3-output GPC Four 6-LUTs for 6-input, 4-output GPC

January 22, 2008 13
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 14
Definitions
Primitive GPCs: Satisfies given I/O Constraints 12-primitive GPCs for 6 inputs, 3 outputs
Including (1, 3; 3), (2, 3; 3)
Covering GPCs Functionality cannot be implemented by other
GPCs, given the I/O constraints e.g., (2, 3; 3) GPC can implement a (1, 3; 3) GPC
Set a rank-1 input bit to 0

January 22, 2008 15
Definitions
Unreasonable GPCs: Single bit in rank-0 column
(3, 1; 3) GPC rank-0 output bit = rank-0 input bit
No reduction in bits (1, 2; 3) GPC 3 input bits: Output value in range [0, 4] 3 output bits

January 22, 2008 16
Definitions
Compression Ratio (CR): # Input Bits / # Output Bits (3, 3; 4) GPC
CR = 6/4 = 1.5 (2, 3; 3) GPC
CR = 5/3 = 1.67
Using GPCs with large CR tends to reduce the number of bits to sum at the next logic level # logic levels = # LUTs on critical path in an FPGA

January 22, 2008 17
Input: Columns of bits to sum
Example: 3-tap FIR filter Each FIR filter is different, depending on
constants used
0rank

January 22, 2008 18
Mapping Heuristicmap_algorithm(Integer : M, Integer : N ,Array of Integers : columns)
{step1: find_covering_GPCs ;) (step2: find_primitive_GPCs;) (step3: order_primitive_GPCs ;) (
Repeat{ step4: Repeat{
col_indx = find_highest_column ;) ( find_next_GPC (col_indx);
remove_covered_dots;) ( } until all dots are covered or no reasonable GPC is found
step5: connect_GPCs_IOs;) (step6: generate_next_stage_dots;) (
} until three rows of dots remains;}step7: generate_final_cpa( columns )
Virtex-5 and Stratix II & III support ternary addition
Attack the tallest column first (greedy approach)

January 22, 2008 19
4
3
1
Example
2
Map to ternary adder

January 22, 2008 20
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 21
Experimental Methodology Altera Stratix-II
90nm CMOS Technology Implementations of multi-input addition
ADD – Ternary adder tree State of the art for FPGAs
3GD – 3-greedy algorithm (3:2 and 2:2 counters) [Stelling et al., TCOMP 98] 2 and 3-input counters do not map well onto 6-LUTs!
GPCs – Heuristic described here
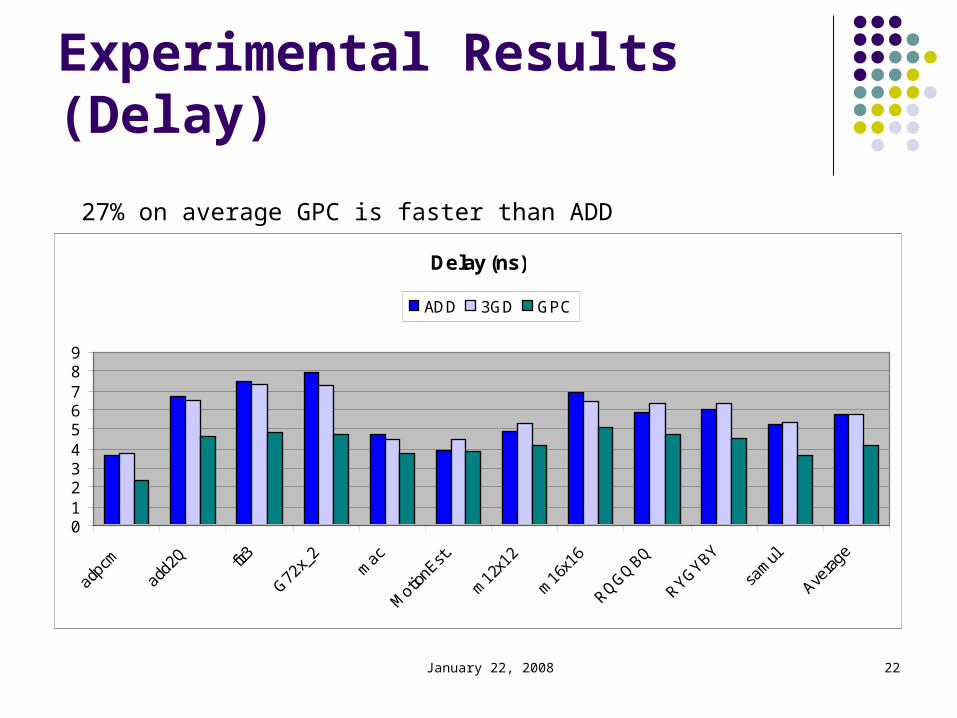
January 22, 2008 22
Experimental Results (Delay)
27% on average GPC is faster than ADD
Delay (ns)
0123456789
adpc
m
add2
Q fir3
G72x_
2m
ac
Mot
ionEst.
m12
x12
m16
x16
RQGQBQ
RYGYBY
sam
ul
Avera
ge
ADD 3GD GPC
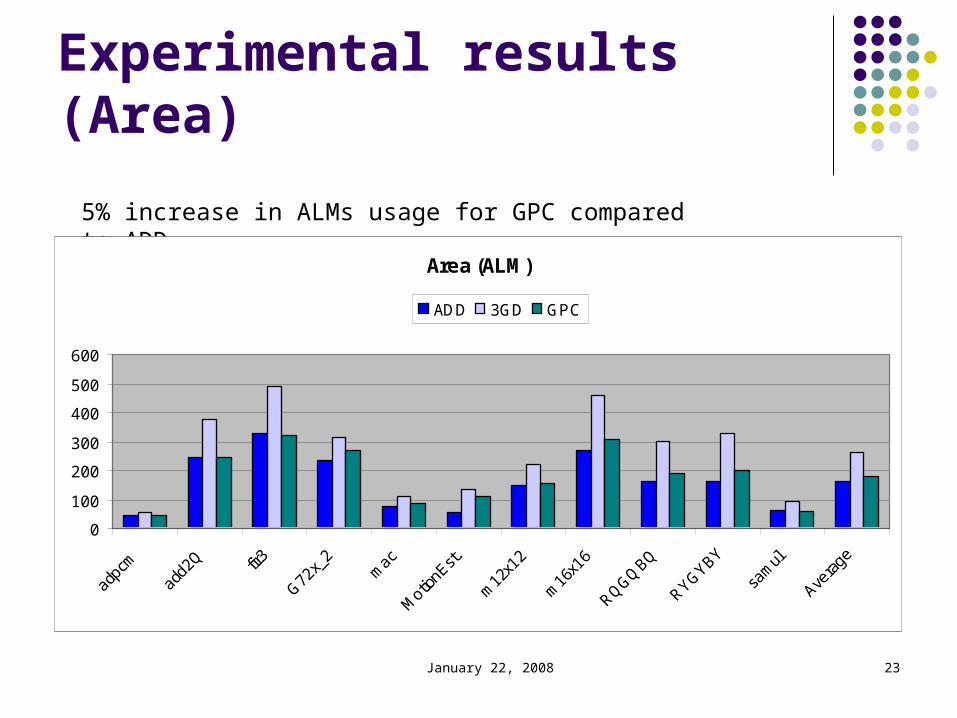
January 22, 2008 23
Experimental results (Area)
5% increase in ALMs usage for GPC compared to ADD
Area (ALM)
0
100
200
300
400
500
600
adpc
m
add2
Q fir3
G72x_
2m
ac
Mot
ionEst.
m12
x12
m16
x16
RQGQBQ
RYGYBY
sam
ul
Avera
ge
ADD 3GD GPC

January 22, 2008 24
Are DSP/MAC Blocks Useful?
Resource Utilization for Adder Trees Using DSPs
0
10
20
30
40
50
60
70
80
DSPs ALMs
No! On average, delay using DSP/MAC blocks was more than 2x worse than 3GD

January 22, 2008 25
Outline
State of the Art: FPGAs
Motivation
Generalized Parallel Counters
Mapping Heuristic
Experimental Results
Conclusion

January 22, 2008 26
Conclusion Conventional wisdom has held that adder trees
outperform compressor trees on FPGAs Ternary adder trees were a major selling point of
the Altera Stratix II architecture This led to their inclusion in Xilinx Virtex-5 devices
Conventional wisdom is wrong! GPCs map nicely onto LUTs
Compressor trees on FPGAs, are faster than adder trees when built from GPCs
Related Documents











