PENERAPAN FUNGSI ASSOCIATION RULE PADA DATA MINING UNTUK MENGOPTIMALKAN TATA LETAK BARANG DI TOSERBA MENGGUNAKAN ALGORITMA FREQUENT PATTERN GROWTH (Studi kasus : Toserba BORMA Cipadung Bandung) Riki Irfan Hidayat #1 , Edi Mulyana *2 , Jumadi *3 Jurusan Teknik Informatika, Universitas Islam Negeri Sunan Gunung Djati Bandung Jalan A.H. Nasution Nomor 105 Cibiru, Bandung 1 [email protected], 2 [email protected], 3 [email protected] Abstrak Terus bertambahnya data transaksi yang dialami oleh Toserba BORMA Cipadung menyebabkan semakin menumpuknya data tersebut, namun pemanfaatannya belum maksimal, hanya digunakan sebagai laporan penjualan saja. Dengan menggunakan Data mining data tersebut dapat lebih dimaksimalkan pemanfaatannya yaitu dengan mencari informasi yang tersembunyi dalam data tersebut, yaitu pola beli konsumen dalam berbelanja berupa kebiasaan suatu produk dibeli bersama dengan produk apa. Informasi ini dapat dijadikan salah satu referensi bagi manajer dalam menentukan tata letak barang yang optimal sebagai salah satu upaya untuk meningkatkan keunggulan dalam persaingan bisnis retail. Teknik Data Mining yang digunakan adalah Association Rule yang mempunyai 2 parameter yaitu support dan confident dengan menerapkan Algoritma Frequent Pattern Growth. Hasil pencarian informasi dalam data transaksi BORMA dari tanggal 8 sampai dengan 9 April 2013 sebanyak 3.242 transaksi diperoleh informasi yaitu jika konsumen membeli Asesoris Komputer, maka akan membeli ATK dengan nilai support 4 % dan confident tertinggi yaitu 93%, dan jika konsumen membeli Mie Instant, maka akan membeli Susu Dalam Kemasan dengan nilai support tertinggi yaitu 30% dan nilai confident 33%. Kata kunci : assosiation rule, confident, data mining, frequent pattern growth, support. 1. Pendahuluan Perkembangan teknologi komputer saat ini sudah semakin pesat, yang mengakibatkan hampir seluruh aktivitas kehidupan manusia menggunakan bantuan komputer, hal ini berdampak pada peningkatan data komputer secara signifikan, jumlah data komputer pada tahun 2008 mencapai 487 milyar Giga Byte (Gantz, 2009 : 1). Jumlah ini terus bertambah hingga sekarang sehingga menimbulkan fenomena data explosion atau ledakan jumlah data. Fenomena ini juga dialami oleh PT. Harja Gautama Lestari – Toserba Borma, Cipadung – Bandung. Sebagai sebuah perusahaan retail yang berdiri sejak tahun 2000, data transaksi Borma mengalami peningkatan secara signifikan, jumlah data dari tanggal 8 s.d. 9 April 2013 sebanyak 3.242

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

PENERAPAN FUNGSI ASSOCIATION RULE PADA DATA MININGUNTUK MENGOPTIMALKAN TATA LETAK BARANG DI TOSERBA
MENGGUNAKAN ALGORITMA FREQUENT PATTERN GROWTH(Studi kasus : Toserba BORMA Cipadung Bandung)
Riki Irfan Hidayat#1, Edi Mulyana*2, Jumadi*3
Jurusan Teknik Informatika, Universitas Islam Negeri Sunan Gunung Djati BandungJalan A.H. Nasution Nomor 105 Cibiru, Bandung
[email protected], [email protected], [email protected]
Abstrak
Terus bertambahnya data transaksi yang dialami oleh Toserba BORMACipadung menyebabkan semakin menumpuknya data tersebut, namunpemanfaatannya belum maksimal, hanya digunakan sebagai laporan penjualansaja.
Dengan menggunakan Data mining data tersebut dapat lebih dimaksimalkanpemanfaatannya yaitu dengan mencari informasi yang tersembunyi dalam datatersebut, yaitu pola beli konsumen dalam berbelanja berupa kebiasaan suatuproduk dibeli bersama dengan produk apa. Informasi ini dapat dijadikansalah satu referensi bagi manajer dalam menentukan tata letak barang yangoptimal sebagai salah satu upaya untuk meningkatkan keunggulan dalampersaingan bisnis retail.
Teknik Data Mining yang digunakan adalah Association Rule yang mempunyai 2parameter yaitu support dan confident dengan menerapkan Algoritma Frequent PatternGrowth. Hasil pencarian informasi dalam data transaksi BORMA dari tanggal 8sampai dengan 9 April 2013 sebanyak 3.242 transaksi diperoleh informasiyaitu jika konsumen membeli Asesoris Komputer, maka akan membeli ATK dengannilai support 4 % dan confident tertinggi yaitu 93%, dan jika konsumen membeliMie Instant, maka akan membeli Susu Dalam Kemasan dengan nilai supporttertinggi yaitu 30% dan nilai confident 33%.
Kata kunci : assosiation rule, confident, data mining, frequent pattern growth, support.
1. Pendahuluan
Perkembangan teknologi komputersaat ini sudah semakin pesat, yangmengakibatkan hampir seluruhaktivitas kehidupan manusiamenggunakan bantuan komputer, halini berdampak pada peningkatandata komputer secara signifikan,jumlah data komputer pada tahun2008 mencapai 487 milyar Giga Byte(Gantz, 2009 : 1). Jumlah ini
terus bertambah hingga sekarangsehingga menimbulkan fenomena dataexplosion atau ledakan jumlah data.
Fenomena ini juga dialami olehPT. Harja Gautama Lestari –Toserba Borma, Cipadung – Bandung.Sebagai sebuah perusahaan retailyang berdiri sejak tahun 2000,data transaksi Borma mengalamipeningkatan secara signifikan,jumlah data dari tanggal 8 s.d. 9April 2013 sebanyak 3.242

transaksi, diperkirakan jumlahseluruhnya mencapai ± 7,5 jutatransaksi.
Namun pemanfaatan data tersebutbelum optimal, karena selama inihanya digunakan sebagai laporanpenjualan saja sehingga dikenaldengan istilah “rich of data but poor ofinformation” (Pramudiono, 2003 : 1).
Dengan menggunakan Data Miningdata tersebut dapat lebihdioptimalkan pemanfaatannya yaitudengan mencari informasi yangtersembunyi dan jarang diketahui.Informasi tersebut dapat digunakanuntuk meningkatkan keunggulandalam persaingan bisnis retail.
Salah satu fungsi Data Miningadalah Association Rule, yaitu fungsiuntuk mencari informasi berupaasosiasi atau hubungan antar itemdalam suatu data transaksi danmenampilkannya dalam bentuk polayang menjelaskan tentang pola belikonsumen dalam berbelanja.Pengetahuan mengenai pola inilahyang nantinya bisa menjadi pedomanuntuk meningkatkan keunggulandalam persaingan bisnis retaildengan cara mengoptimalkan tataletak barang yang sesuai denganpola beli konsumen sehingga dapatmeningkatkan kenyamanan konsumendalam berbelanja. Suatu poladitentukan oleh dua parameter,yaitu Support dan Confidence. Support(nilai penunjang) adalahpersentase kombinasi item tersebutdalam database, sedangkan Confidence(nilai kepastian) adalah kuatnyahubungan antar item dalam aturanasosiasi (Kusrini, 2009:150).
Algortima yang digunakan padapenelitian ini adalah Frequent PatternGrowth atau FP-Growth, algortima inimengadopsi teknik Divide and Conguer,langkah pertama, algortima inimemadatkan database yang mewakilifrequent itemset (data yang palingsering muncul) kedalam FrequentPattern Tree atau FP-Tree yang
menyimpan informasi hubungan antartiap itemset. Kemudian membagidatabase yang telah dipadatkankedalam sekumpulan conditionaldatabase, masing-masing conditionaldatabase terhubung dengan satufrequent item dan pencarian informasidilakukan secara terpisah (Han,2006 : 243). Metode Divide and Conguerdigunakan untuk memecahkan masalahmenjadi submasalah yang lebihkecil sehingga mempermudahmenemukan pola (Chandrawati dalamSuprasetyo, 2012:2).
2. Data Mining
Data mining merupakan ekstraksiinformasi yang tersirat dalamsekumpulan data. Data mining jugadapat diartikan sebagaipengekstrakan informasi baru yangdiambil dari bongkahan data besaryang membantu dalam pengambilankeputusan (Prasetyo, 2012:2).
Data mining merupakan salah satutahap dalam proses pencarianpengetahuan atau KDD (KnowledgeDiscovery in Database), dapat dilihatpada Gambar 1
Gambar 1 Knowledge Discovery inDatabase
(Sumber : Han, 2006 : 6)Secara umum proses Knowledge
Discoery in Database dapat dijelaskansebagai berikut :
A. Data cleaning

Sebelum proses data mining dapatdilaksanakan, perlu dilakukanproses cleaning atau pembersihanpada data yang menjadi fokus KDD.Proses cleaning meliputi antara lainmemeriksa data yang tidak lengkapatau missing value dan mengurangikerancuan / noisy.
B. Data integrationMenggabungkan berbagai sumber
data yang dibutuhkan atauintegration, kualitas data yangdimiliki akan sangat menentukankualitas dari hasil data mining.C. Data selection
Pemilihan atau seleksi datayang diperlukan dari sekumpulansumber data sebelum tahappenggalian informasi dalam KDDdimulai. Data hasil seleksi inilahyang akan digunakan untuk prosesdata mining. Disimpan dalam suatuberkas terpisah dari sumber data.
D. TransformationData-data yang telah melalui
proses cleaning, integration, dan selectiontidak bisa langsung digunakan,tahap ini merupakan proses kreatifuntuk merubah bentuk data kedalambentuk yang dapat dieksekusi olehprogram. Bentuk yang dibuat sangattergantung dari informasi apa yangakan dicari dalam data tersebut.
E. Data miningData mining adalah proses mencari
pola atau informasi menarik dalamdata dengan menggunakan teknikatau metode tertentu. Teknik,metode, atau algoritma dalam datamining sangat bervariasi. Pemilihanmetode atau algoritma yang tepatsangat bergantung pada tujuan danproses KDD secara keseluruhan.
F. Interpretaion atau EvaluationPola-pola yang diidentifikasi
oleh program kemudianditerjemahkan ataudiinterpretasikan kedalam bentukyang bisa dimengerti manusia untuk
membantu dalam perencanaanstrategi bisnis.
3. Association Rule
Aturan asosiasi (Association rules)atau analisis afinitas (afinityanalysis) berkenaan dengan studitentang ‘apa bersama apa’. Inibisa berupa studi transaksi disupermarket, misalnya seseorangyang membeli shampoo juga membelisabun mandi. Disini berartishampoo bersama dengan sabunmandi. Karena awalya berasal daristudi tentang database transaksipelanggan untuk menentukankebiasaan suatu produk dibelibersama produk apa, maka aturanasosiasi juga sering dinamakanmarket basket analysis (Santoso,2007:225).
Strategi umum yang diadopsioleh banyak algoritma penggalianaturan asosiasi adalah memecahmasalah kedalam dua pekerjaanutama (Prasetyo 2012 : 5),yaitu :
A. Frequent itemset generationTujuannya adalah mencari semua
itemset yang memenuhi ambang batasatau minimum support. Itemset inidisebut frequent itemset (itemset yangsering muncul). Nilai support inidiperoleh dengan rumus dapatdilihat pada Rumus 1
Support (A )=JumlahTransaksiMengandungATotalTransaksi
Rumus 1 Rumus mencari nilai support (Sumber : Kusrini, 2009 : 150)
Rumus 1 menjelaskan bahwa nilaisupport diperoleh dengan caramembagi jumlah transaksi yangmengandung item A dengan jumlahseluruh transaksi.
B. Rule generation

Tujuannya adalah mencari aturanatau pola dengan confidence tinggidari frequent itemset yang ditemukandalam langkah itemset generation.Aturan ini kemudian disebut aturanyang kuat (strong rule).
Rumus untuk menghitung confidencedapat dilihat pada Rumus 2
Confidence=(A→B)=JumlahTransaksiMengandungAdanBJumlahTransaksiMengandungA
Rumus 2 Rumus mencari nilaiconfidence
(Sumber : Kusrini, 2009 : 151)
Rumus 2 menjelaskan bahwa untukmencari nilai confidence itemsetA,B yaitu dengan membagi jumlahtransaksi yang mengandung item Adan B dengan seluruh transaksiyang mengandung item A.
4. Analisis dan Perancangan Sistem
4.1 Analisis Sistem yang SedangBerjalan
A. Deskripsi Masalah
Berdasarkan analisa danpenelitian yang dilakukan diToserba Borma, Cipadung – Bandung,setiap hari terjadi transaksi jualbeli yang datanya tersimpan dalamdatabase penjualan. Jumlahtransaksi selama 2 hari saja yaitupada bulan April tanggal 8 s.d. 9tahun 2013 mencapai 3.242transaksi, ini merupakan angkayang besar apabila kita mengingatawal mula berdiri Toserba BormaCipadung yaitu pada tahun 2000,tentu data yang terkumpul akansangat besar sekali. Namun selamaini data transaksi tersebut hanyadigunakan sebagai laporanpenjualan saja kepada pihak atasantanpa ada suatu proses untukmendapatkan manfaat lebih dariadanya data tersebut.
B. Pemecahan Masalah
Aplikasi data mining yang akandibangun ini akan memberikansolusi yaitu dengan menggali ataumengekstrak informasi yangtersembunyi dalam data transaksi,guna mendapatkan manfaat lebihdari adanya data tersebut.
Informasi yang dicari yaitupola beli konsumen berupakebiasaan suatu produk dibelibersamaan dengan produk apa,informasi ini bermanfaat untukmenata layout toko yang ideal,misalnya konsumen biasanya membeliroti dengan susu. Maka dalamlayout toko posisi roti idealnyaberdekatan dengan susu.
4.2 Analisis Pencarian Pola
Proses pencarian pola adalahserangkaian proses yang harusdijalani secara bertahap dalammencari pola yang tersembunyidalam sebuah database. Dimulaidari proses pengumpulan data,preprocessing (data cleaning, integration,selection, transformation), data mining danpattern evaluation.
Secara umum flowchart prosespencarian pola dapat dilihat padaGambar 2
Gambar 2 Flowchart proses pencarianpola
Tahap Data mining merupakan tahapyang paling utama, pada tahap ini

algoritma Frequent Pattern Growthdigunakan untuk mencari pola-polayang tersembunyi dalam data.Flowchart cara kerja algoritmaFrequent Pattern Growth secara umumdapat dilihat pada Gambar 3
Gambar 3 Flowchart cara kerja FP-Growth
A. Pengumpulan DataSumber data yang digunakan
dalam penelitian ini berasal daridata transaksi di Toserba Borma,Cipadung – Bandung.
B. Data preprocessingSebelum melakukan pencarian
pola, data yang digunakan harusmelalui serangkaian prosesterlebih dahulu (preprocessing)tujuannya selain untukmeningkatkan kualitas data,konsistensi dan hasil mining, jugauntuk meningkatkan efisiensi danmempermudah proses data mining (Han,2006, 47).
Pada tahap ini dilakukan prosesData cleaning, Data integration, Dataselection, dan Data transformation.
1. Data cleaning
Pada tahap ini data yangdigunakan kita coba untuk lengkapikekurangannya (missing values),menghilangkan kerancuan (noisy) danmemperbaiki data yang tidakkonsisten.
1.1 Missing values
Pada data transaksi penjualanselama 2 hari tidak terdapatatribut kategori pada datatersebut, sedangkan dalampenelitian ini justru yang akandigunakan adalah kategori barangbukan nama barang, data transaksitersebut dapat dilihat pada Tabel1
Tabel 1 Tabel data BORMA 8-9 April2013
Tanggal Mid Notrx Code Descript
ionHarga D J
08/04/2013 7:38:42
POS01
114297
002.1013 BEET 9630 0 9630
08/04/2013 7:47:25
POS01
114298
292.2202
AQUA 600ML/24 1650 0 1650
08/04/2013 8:07:27
POS01
114299 024 TELUR
AYAM12730 0 1273
0
08/04/2013 8:07:27
POS01
114299 024 TELUR
AYAM12900 0 1290
0
08/04/2013 8:07:27
POS01
114299 024 TELUR
AYAM13400 0 1340
0
08/04/2013 8:07:27
POS01
114299 024 TELUR
AYAM12815 0 1281
5
08/04/2013 8:07:27
POS01
114299
202.2101
INDOMILKKENTAL MANIS 397
7800 0 31200
Keterangan : selengkapnya dapat dilihat pada file lampiran 1 - tbl_transaksi_borma.xls dalam CD laporan
Kita tambahkan atribut kategoripada setiap barang yang dibeli,dengan cara mengambil 3 digitangka pertama pada kolom codekemudian kita tentukan kategoribarangnya. Misalnya code 251.3401untuk barang DAIA DET BUNGA900G/12 dan code 251.1205 untukbarang RINSO AN 700GR/12 maka kitadapat menentukan code barang 251termasuk kategori DETERJEN, hasiltahap ini dapat dilihat pada Tabel2
Tabel 2 Tabel data transaksisetelah tahap
Missing valuesTanggal Mid Notr
x Code Kategori Description H
08/04/2013 7:38:42
POS01
114297
002.1013
BUAH DANSAYURAN BEET 9630
08/04/2013 7:47:25
POS01
114298
292.2202
MINUMAN DALAM BOTOL
AQUA 600ML/24 1650
08/04/2013
POS01
114299
024 TELUR AYAM
TELUR AYAM
12730
8:07:2708/04/2013 8:07:27
POS01
114299 024 TELUR
AYAMTELUR AYAM
12900
08/04/2013 8:07:27
POS01
114299 024 TELUR
AYAMTELUR AYAM
13400
08/04/2013 8:07:27
POS01
114299 024 TELUR
AYAMTELUR AYAM
12815
08/04/2013 8:07:27
POS01
114299
202.2101
SUSU FULL CREAM
INDOMILKKENTAL MANIS 397
7800
Keterangan : selengkapnya dapat dilihat pada file lampiran 2 - tbl_transaksi_borma_1_missing_ values.xls dalam CD laporan.
1.2 Noisy
Setelah atribut kategoriditambahkan, maka langkahselanjutnya adalah menghilangkankerancuan (noisy) dalam datatersebut teknik yang digunakanadalah binding untuk mengurutkandata berdasarkan notrx agar datamudah dibaca. Data transaksisetelah diurutkan dapat dilihatpada Tabel 3
Tabel 3 Tabel data transaksisetelah tahap noisy
Tanggal Mid Notr
x Code Kategori Description H
08/04/2013 12:09:31
POS18
82.353
501.1526
ASESORIS KOMPUTER
MEDIATECH USB HUB VER.2 STD
16900
08/04/2013 12:09:31
POS18
82.353
501.1868
ASESORIS KOMPUTER
MOUSE VOTER USB
15600
08/04/2013 12:09:31
POS18
82.353
501.0180
ASESORIS KOMPUTER
SUNTIKAN TINTA
1900
08/04/2013 13:32:20
POS18
82.354
031.1461 ATK ISI BOLPEN
PARKER17300
08/04/2013 13:32:58
POS18
82.355
192.2121 KALKULATOR
CITIZEN SDC-812BN 12 DIGIT
39900
08/04/2013 13:35:06
POS18
82.356 065 KERTAS
KADO AKSESORIS 4400
08/04/2013 13:36:27
POS18
82.357 030 MAINAN
ANAK-ANAK SIRKAM 6300
Keterangan : selengkapnya dapat dilihat pada file lampiran 3 - tbl_transaksi_borma_2_noisy.xls dalam CD laporan.
2. Data integration
Pada tahap ini berbagai sumberdata yang menunjang digabungkan(integration), namun karena sumber
data yang digunakan hanya satu,maka tahap ini tidak dilakukan.
3. Data selection
Atribut pada data transaksiyang sesuai dengan kebutuhan untukmencari pola kita pilih (selection).Langkah pertama adalahmenggabungkan beberapa kategoriyang sama yang terdapat dalam satutransaksi menjadi satu kategori,misalnya pada notrx 82.353terdapat 3 kategori yaitu ASESORISKOMPUTER maka kita anggap dalamtransaksi itu hanya satu kategorisaja. Data transaksi setelahdilakukan penggabungan kategoridapat dilihat pada Tabel 4
Tabel 4 Tabel data transaksisetelah penggabungan
kategoriTanggal Mid Notr
x Code Kategori Description H
08/04/2013 12:09:31
POS18
82.353
501.1526
ASESORIS KOMPUTER
MEDIATECHUSB HUB VER.2 STD
16900
08/04/2013 13:32:20
POS18
82.354
031.1461 ATK
ISI BOLPEN PARKER
17300
08/04/2013 13:32:58
POS18
82.355
192.2121 KALKULATOR
CITIZEN SDC-812BN12 DIGIT
39900
08/04/2013 13:35:06
POS18
82.356 065 KERTAS
KADO AKSESORIS 4400
08/04/2013 13:36:27
POS18
82.357 030 MAINAN
ANAK-ANAK SIRKAM 6300
08/04/2013 13:38:39
POS18
82.358
501.1403
ASESORIS KOMPUTER
FLASH DISK VANDISK V50 8GB
53900
08/04/2013 13:42:50
POS18
82.359
501.4571
ASESORIS KOMPUTER
COOLER NBM119
42400
Keterangan : selengkapnya dapat dilihat pada file lampiran 4 - tbl_transaksi_borma_3_data_ selection.xls dalam CD laporan.
Langkah selanjutnya adalahdengan memilih top 25 kategoriyang paling sering dibeli olehkonsumen, pada penelitian inihanya digunakan 25 kategoriterbanyak sebagai sampel, terdapat122 kategori yang dibeli olehkonsumen dapat dilihat pada Tabel5
Tabel 5 Tabel kategori yang dibelioleh konsumen
Kode Kategori Jumlah DalamTransaksi
291 SUSU DALAM KEMASAN 436
292 MINUMAN DALAM BOTOL 426
211 MIE INSTANT 416
402 SHAMPOO 357
213 BISKUIT KEMASAN 355
251 DETERJEN 293
214 MAKANAN RINGAN 272
Keterangan : lanjut pada lampiran 5 (kategori yang dibeli oleh konsumen) pada laporan bagian lampiran
Transaksi yang mengandungkategori yang tidak termasuk dalamtop 25 maka akan dihapus. Padatabel top 25 kategori kitatambahkan abjad dari A sampai Y,dapat dilihat pada Tabel 6.
Tabel 6 Tabel top 25 kategoriKode Kategori Jumlah Dalam
Transaksi
Transform keAbjad
291 SUSU DALAM KEMASAN 436 A
292 MINUMAN DALAM BOTOL 426 B
211 MIE INSTANT 416 C
402 SHAMPOO 357 D
213 BISKUIT KEMASAN 355 E
251 DETERJEN 293 F
214 MAKANAN RINGAN 272 G
Keterangan : lanjut pada lampiran 1 (top kategori yang dibeli oleh konsumen) .
Data transaksi setelahdilakukan pemilihan top 25terbanyak dapat dilihat pada Tabel7
Tabel 7 Tabel data transaksi top25 kategori
Tanggal Mid Notrx Code Kategori Descripti
on H
08/04/2013 12:09:31
POS18
82.353
501.1526
ASESORIS KOMPUTER
MEDIATECHUSB HUB VER.2 STD
16900
08/04/2013 13:32:20
POS18
82.354
031.1461 ATK
ISI BOLPEN PARKER
17300
08/04/2013 13:38:39
POS18
82.358
501.1403
ASESORIS KOMPUTER
FLASH DISK VANDISK V50 8GB
53900
08/04/2013 13:42:50
POS18
82.359
501.4571
ASESORIS KOMPUTER
COOLER NBM119
42400
08/04/2013 13:42:5
POS18
82.359
031.2739
ATK KIKY B/NOTE SP
4900
008/04/2013 13:45:42
POS18
82.360
031.1445 ATK
LOOSE LEAF A5 100 KK
5700
08/04/2013 13:50:39
POS18
82.362
501.5784
ASESORIS KOMPUTER
SPEAKER SG TATOO 101
77500
08/04/2013 13:55:23
POS18
82.364 031 ATK ATK/BUKU 1500
08/04/2013 13:57:20
POS18
82.365 031 ATK ATK/BUKU 1600
Keterangan : selengkapnya dapat dilihat pada file lampiran 6 - tbl_transaksi_borma_3_data_ selection_r1.xls dalam CD laporan.
4. Data transformation
Pada tahap ini kita pilihatribut yang akan digunakan yaituhanya notrx dan kategori danmenghapus atribut yang lain ,namun kategori yang digunakanharus sudah berupa abjad sepertiyang telah ditentukan pada tabel6, data transaksi setelah dipilihatributnya dapat dilihat padaTabel 8
Tabel 8 Tabel data transaksipemilihan atribut
Notrx Transform ke Abjad
82.353 Y
82.354 J
82.358 Y
82.359 Y
82.359 J
82.360 J
82.362 Y
Keterangan : selengkapnya dapat dilihat pada file lampiran 7 - tbl_transaksi_borma_3_data_ selection_r2.xls dalam CD laporan.
Karena kita akan mencari polahubungan tiap kategori dalamsebuah transaksi maka minimal ada2 kategori dalam sebuah transaksi,transaksi yang hanya terdapat satukategori kita hapus dapat dilihatpada Tabel 9.
Tabel 9 Tabel data transaksiminimal 2 kategori
tiap transaksiNotrx Transform ke Abjad
82.359 Y
82.359 J
82.399 J
82.399 Y
82.412 Y
82.412 J
82.414 J
Keterangan : selengkapnya dapat dilihat pada file lampiran 8 - tbl_transaksi_borma_3_data_ selection_r3.xls dalam CD laporan.
Kemudian tabel 9 diatas kitarubah dalam bentuk matrik biner
dimana baris menyatakan notrx dankolom menyatakan barang yangdibeli. Data transaksi dalambentuk matrik biner dapat dilihatpada Tabel 10
Tabel 10 Tabel data transaksi dalam bentuk matrik binerNotrx ITEM 1 ITEM 2 ITEM 3 ITEM 4 ITEM 5 ITEM 6 ITEM 7 ITEM 8 ITEM 9 ITEM 10 ITEM 11 ITEM 12
128.247 C H E B A N F P S L D I
124.612 I D Q E C T V B U F O N
128.183 V E A G C H F S L P M D
103.161 V H B C O F Q U M D S I
131.337 U Q V T C W H F I O D S
124.667 F Q U I D P M S V E C H
127.976 N F S O D P L I V T W H
Keterangan : selengkapnya dapat dilihat pada file lampiran 9 - tbl_transaksi_borma_3_data_selection_r4.xls dalam CD laporan.
Pada tahap ini datapreprocessing sudah selesai dandata transaksi sudah siap untuk dimining.
C. Data Mining
Pada tahap ini FP-Treedibangkitkan yang akan digunakanoleh algoritma FP Growth untukmenentukan frequent itemsest. Padapenelitian ini akan diambil contohdata sebanyak 10 transaksi dapatdilihat pada Tabel 11. Batasanminimum support yang diberikan 20%
yaitu 2 atau 210
yaitu 0,2 (rumus
untuk menghitung support dapatdilihat pada Rumus 1) dan batasanconfidence yaitu 75%, dalampembentukan FP-Tree diperlukan 2 kalipenelurusan database.
Tabel 11 Tabel contoh datatransaksi setelah tahap transformation
notrx Item 1 Item 2 Item 3 Item 4 Item 5
127.624 X R A T C
103.173 C G A H
131.326 N H G A
128.214 A C H
124.547 R D A
114.550 G C P
124.650 X J I
127.623 T E L
131.324 G Q K
131.024 O U D
Penelusuran database pertamadigunakan untuk menghitung nilaisupport masing-masing item danmenghapus item yang nilai supportnya kurang dari minimum support yangtelah ditentukan. Hasil daripenelusuran pertama ini adalahdiketahuinya jumlah frequensi
kemunculan setiap item pada datatransaksi dan digunakan untukmengurutkan item berdasarkanfrequensi kemunculan yang palingtinggi dapat dilihat pada Tabel 12
Tabel 12 Tabel frequensi setiap itemItem Frequensi Support
A 5 5/10 = 0,5 atau 50%
C 4 4/10 = 0,4 atau 40%
Lanjutan Tabel 12 Tabel frequensisetiap item
Item Frequensi Support
G 4 4/10 = 0,4 atau 40%
H 3 3/10 = 0,3 atau 30%
X 2 2/10 = 0,2 atau 20%
R 2 2/10 = 0,2 atau 20%
T 2 2/10 = 0,2 atau 20%
D 2 2/10 = 0,2 atau 20%
N 1 1/10 = 0,1 atau 10%
P 1 1/10 = 0,1 atau 10%
J 1 1/10 = 0,1 atau 10%
I 1 1/10 = 0,1 atau 10%
E 1 1/10 = 0,1 atau 10%
L 1 1/10 = 0,1 atau 10%
Q 1 1/10 = 0,1 atau 10%
K 1 1/10 = 0,1 atau 10%
O 1 1/10 = 0,1 atau 10%
U 1 1/10 = 0,1 atau 10%
Dari hasil tersebut diperolehitem yang memiliki frekuensi di atasminimum support > 2 yaituA,C,G,H,X,R,T, dan D yang kemudiandiberi nama Frequent List dapatdilihat pada Tabel 13. Frequent Listinilah yang akan berpengaruh padapembangkitan FP-Tree, sedangkan itemyang nilai support nya < 2 akandihapus yaitu itemN,P,J,I,E,L,Q,K,O, dan U.
Tabel 13 Tabel Frequent ListItem Frequensi Support
A 5 5/10 = 0,5 atau 50%
C 4 4/10 = 0,4 atau 40%
G 4 4/10 = 0,4 atau 40%
H 3 3/10 = 0,3 atau 30%
X 2 2/10 = 0,2 atau 20%
R 2 2/10 = 0,2 atau 20%
T 2 2/10 = 0,2 atau 20%
D 2 2/10 = 0,2 atau 20%
Setelah diperoleh Frequent List,urutkan item pada data transaksiberdasarkan frequensi paling tinggidapat dilihat pada tabel 14.Tabel 14 Tabel transaksi setelah
diurutkan berdasarkan frequent list
notrx Item 1 Item 2 Item 3 Item 4 Item 5
127.624 A C R T X
103.173 A C G H
131.326 A G H
128.214 A C H
124.547 A R D
114.550 C G
124.650 X
127.623 T
131.324 G
131.024 D
Setelah item dalam datatransaksi disusun ulang berdasarkanfrequent list, penelurusan databaseyang kedua dilakukan untukmembangkitkan FP-Tree yang dimulaidari membaca notrx 127.624 yangakan menghasilkan simpul A,C,R,T,dan X sehingga terbentuk lintasan{NULL} → A → C → R → T → X dengannilai support awal 1, dapat dilihatpada Gambar 4
Gambar 4 Pembangkitan FP-Tree pada pembacaan notrx
127.624
Setelah pembacaan notrx127.624, maka selanjutnya adalahmembaca transaksi selanjutnya yaitu

notrx 103.173 sehingga menghasilkanlintasan {NULL} → A → C → G → H.
Karena node A dan C sudahterbentuk pada pembacaan pertama,maka kita padatkan node tersebutdengan menambahkan nilai supportnyayaitu 2 menandakan bahwa node A danC telah dilewati 2 kali, sedangkannode G dan H kita beri nilaisupport 1, dapat dilihat padaGambar 5
Gambar 5 Pembangkitan FP-Tree padapembacaan
notrx 103.173
Selanjutnya adalah pembacaannotrx 131.326 sehingga menghasilkanlintasan {NULL} → A → G → H. Karenanode A sudah terbentuk maka kitapadatkan kembali dengan menambahnilai support A menjadi 3 sedangkannode G dan H kita beri nilaisupport 1, dapat dilihat padaGambar 6.
Gambar 6 Pembangkitan FP-Tree padapembacaan
notrx 131.326
Selanjutnya adalah pembacaannotrx 128.214 sehingga menghasilkanlintasan {NULL} → A → C → H. Karenanode A dan C sudah terbentuk makakita padatkan dengan menambah nilai
support A menjadi 4 dan C menjadi 3sedangkan node H kita beri nilaiawal 1, dapat dilihat pada Gambar7.
Gambar 7 Pembangkitan FP-Tree padapembacaan
notrx 128.214
Selanjutnya adalah pembacaannotrx 124.547 sehingga menghasilkanlintasan {NULL} → A → R → D. Karenanode A telah terbentuk maka kitapadatkan kembali sehingga nilaisupportnya menjadi 5 dan node R danD kita beri nilai 1, dapat dilihatpada Gambar 8.
Gambar 8 Pembangkitan FP-Tree padapembacaan
notrx 124.547
Selanjutnya adalah pembacaannotrx 114.550 sehingga menghasilkanlintasan {NULL} → C → G. Karenanode C dan G belum terbentuk makakita beri nilai support 1, dapatdilihat pada Gambar 9.

Gambar 9 Pembangkitan FP-Tree pada pembacaan notrx
114.550
Selanjutnya adalah pembacaannotrx 124.650 sehingga menghasilkanlintasan {NULL} → X. Karena node Xbelum terbentuk maka kita berinilai support 1, dapat dilihat padaGambar 10.
Gambar 10 Pembangkitan FP-Tree pada pembacaan notrx
124.650
Selanjutnya adalah pembacaannotrx 127.623 sehingga menghasilkanlintasan {NULL} → T. Karena node Tbelum terbentuk maka kita berinilai support 1. Dapat dilihat padaGambar 11.
Gambar 11 Pembangkitan FP-Tree padapembacaan
notrx 127.623
Selanjutnya adalah pembacaannotrx 131.324 sehingga menghasilkanlintasan {NULL} → G. Karena node Gbelum terbentuk maka kita berinilai support 1, dapat dilihat padaGambar 12.
Gambar 12 Pembangkitan FP-Tree pada pembacaan notrx
131.324
Selanjutnya adalah pembacaantransaksi terakhir yaitu notrx131.024 yang menghasilkan lintasan{NULL} → D. Karena node D belumterbentuk maka kita beri nilaisupport 1. dapat dilihat padaGambar 13.
Gambar 13 Pembangkitan FP-Tree pada pembacaan notrx
131.024
Setelah FP-Tree selesaidibangkitkan, maka langkahselanjutnya adalah mencari frequentitemset dengan menerapkan metodeDivide and Conguer sesuai urutan padaFrequent List (Tabel 13) dimulai dariyang paling kecil hingga palingbesar frequensinya.

1. Kondisi FP-Tree untuk item DLangkah pertama, cari semua
lintasan yang berakhiran D. Setiapnode yang berada pada lintasan Ddiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item D danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 14.
Gambar 14 Kondisi FP-Tree pada item D
Kemudian, naikkan satu persatunode yang melewati lintasan ke Ddan masukan nilai support yangdimiliki D kesetiap node yangmelewati hingga ke node NULL. Item Adan R nilai kemunculan bersamadengan D hanya 1 kali sehingga itemA dan R dibuang. Karena item D hanyaberdiri sendiri maka frequentitemset yang memenuhi minimum supportadalah item D itu sendiri.
2. Kondisi FP-Tree untuk item TLangkah pertama, cari semua
lintasan yang berakhiran T. Setiapnode yang berada pada lintasan Tdiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item T danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 15.
Gambar 15 Kondisi FP-Tree pada item T
Kemudian, naikkan satu persatunode yang melewati lintasan ke Tdan masukan nilai support yangdimiliki T kesetiap node yangmelewati hingga ke node NULL. ItemA,C, dan R nilai kemunculan bersamadengan T hanya 1 kali sehingga itemA,C dan R dibuang. Karena item Thanya berdiri sendiri maka frequentitemset yang memenuhi minimum supportadalah item T itu sendiri.
3. Kondisi FP-Tree untuk item RLangkah pertama, cari semua
lintasan yang berakhiran R. Setiapnode yang berada pada lintasan Rdiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item R danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 16.
Gambar 16 Kondisi FP-Tree pada item R
Kemudian, naikkan satu persatunode yang melewati lintasan ke Rdan masukan nilai support yangdimiliki R kesetiap node yangmelewati hingga ke node NULL. Item A

nilai kemunculan bersama dengan Rsebanyak 2 kali sedangkan item Chanya 1 kali sehingga item Cdibuang. Maka frequent itemset yangmemenuhi minimum support adalah itemA bersama R dan R itu sendiri.
4. Kondisi FP-Tree untuk item XLangkah pertama, cari semua
lintasan yang berakhiran X. Setiapnode yang berada pada lintasan Xdiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item X danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 17.
Gambar 17 Kondisi FP-Tree pada item XKemudian, naikkan satu persatu
node yang melewati lintasan ke Xdan masukan nilai support yangdimiliki X kesetiap node yangmelewati hingga ke node NULL. ItemA,C,R, dan T nilai kemunculanbersama dengan X hanya 1 kalisehingga item A,C,R, dan T dibuang.Karena item X hanya berdiri sendirimaka frequent itemset yang memenuhiminimum support adalah item X itusendiri.
5. Kondisi FP-Tree untuk item HLangkah pertama, cari semua
lintasan yang berakhiran H. Setiapnode yang berada pada lintasan Hdiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item H dan
frequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 18.
Gambar 18 Kondisi FP-Tree pada item H
Kemudian, naikkan satu persatunode yang melewati lintasan ke Hdan masukan nilai support yangdimiliki H kesetiap node yangmelewati hingga ke node NULL. Item Anilai kemunculan bersama dengan Hsebanyak 3 kali sedangkan item Cnilai kemunculan bersama dengan Hsebanyak 2 kali dan item G nilaikemunculan bersama dengan Hsebanyak 2 kali. Maka frequentitemset yang memenuhi minimum supportadalah item A bersama H, C bersamaH, G bersama H, dan H itu sendiri.
6. Kondisi FP-Tree untuk item GLangkah pertama, cari semua
lintasan yang berakhiran G. Setiapnode yang berada pada lintasan Gdiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item G danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 19.
Gambar 19 Kondisi FP-Tree pada item G

Kemudian, naikkan satu persatunode yang melewati lintasan ke Gdan masukan nilai support yangdimiliki G kesetiap node yangmelewati hingga ke node NULL. Item Anilai kemunculan bersama dengan Gsebanyak 2 kali sedangkan item Cnilai kemunculan bersama dengan Gsebanyak 2 kali. Maka frequentitemset yang memenuhi minimum supportadalah item A bersama G, C bersamaG, dan G itu sendiri.7. Kondisi FP-Tree untuk item C
Langkah pertama, cari semualintasan yang berakhiran C. Setiapnode yang berada pada lintasan Cdiberi nilai support awal 0, inidilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item C danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 20.
Gambar 20 Kondisi FP-Tree pada item C
Kemudian, naikkan satu persatunode yang melewati lintasan ke Cdan masukan nilai support yangdimiliki C kesetiap node yangmelewati hingga ke node NULL. Item Anilai kemunculan bersama dengan Csebanyak 3 kali. Maka frequentitemset yang memenuhi minimum supportadalah item A bersama C, dan C itusendiri.
8. Kondisi FP-Tree untuk item ALangkah pertama, cari semua
lintasan yang berakhiran A. Setiapnode yang berada pada lintasan Adiberi nilai support awal 0, ini
dilakukan untuk mengetahuiinformasi berapa kali item dibelibersamaan dengan item A danfrequent itemset mana yang memenuhiminimum support. Hali ini dapatdilihat pada Gambar 21.
Gambar 21 Kondisi FP-Tree pada item A
Kemudian, naikkan satu persatunode yang melewati lintasan ke Adan masukan nilai support yangdimiliki A kesetiap node yangmelewati hingga ke node NULL.Karena item A langsung terhubung kenode NULL maka tidak ada lagi nodeyang melewati item A, frequent itemsetyang memenuhi minimum support adalahitem A itu sendiri.
Setelah memeriksa semua nodeyang ada pada FP-Tree ditemukan 15frequent itemset dapat dilihat padaTabel 15Tabel 15 Tabel frequent itemset dalam
FP-TreeNode item Frequent itemset
D D
T T
R R, AR
X X
H H, GH, CH, AH
G G, CG, AG
C C, AC
A A
Namun tidak semua frequentitemset yang ditemukan kita hitungconfidence-nya sebab dalam associationrule minimal harus terdapat 2 itemdalam frequent itemset maka yangakan kita hitung hanya frequent
itemset AR, GH, CH, AH, CG, AG, danAC.
Selanjutnya adalah pembuatanrule dengan cara menghitung confidencesetiap frequent itemset, hanya ruleyang mempunyai nilai confidence ≥75% atau 0,75 yang akan kita ambilsebagai strong rule atau aturan yangkuat. Rumus untuk menghitungconfidence dapat dilihat pada Rumus2.2. Karena kita akan mengitunghubungan tiap item maka berlakujuga hubungan kebalikannya misaljika A maka R, berlaku juga jika Rmaka A. Hasil perhitungan confidenceuntuk setiap itemset dapat dilihatpada Tabel 16.
Tabel 16 Tabel frequent itemset dalamFP-Tree
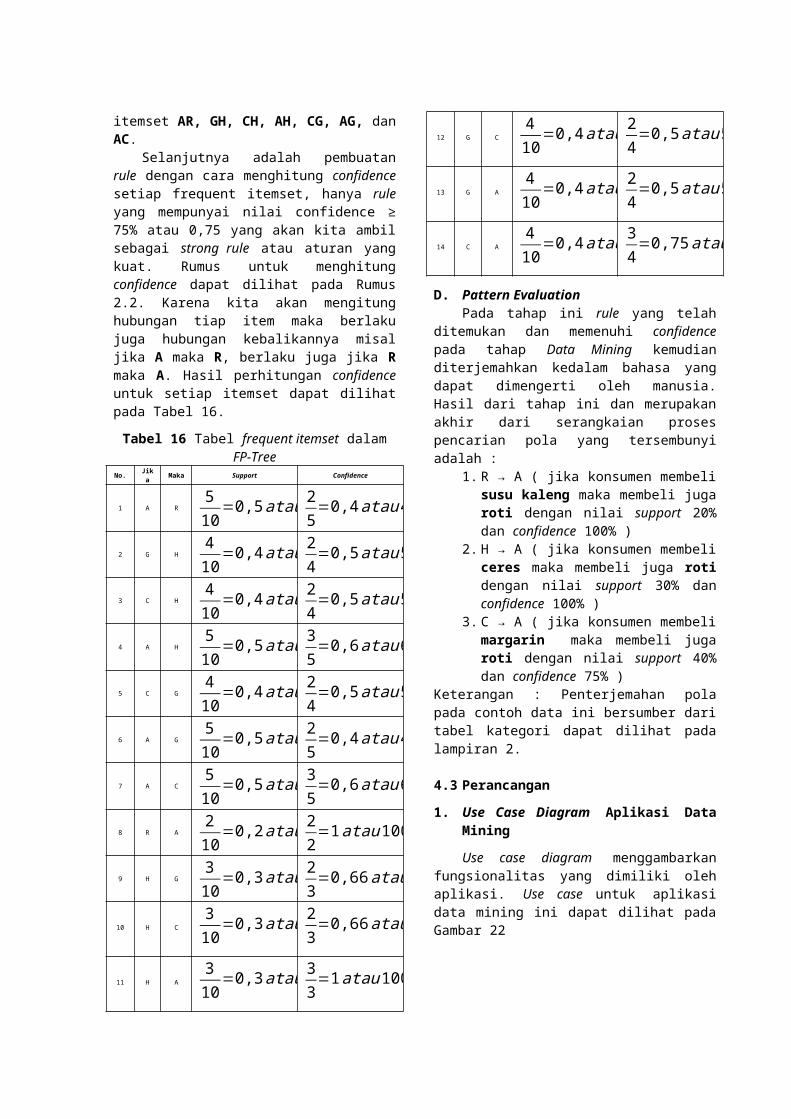
No. Jika Maka Support Confidence
1 A R510
=0,5atau50%25=0,4atau40 %
2 G H410
=0,4atau40%24=0,5atau50%
3 C H410
=0,4atau40%24=0,5atau50 %
4 A H510
=0,5atau50%35=0,6atau60%
5 C G410
=0,4atau40%24=0,5atau50 %
6 A G510
=0,5atau50%25=0,4atau40%
7 A C510
=0,5atau50%35=0,6atau60 %
8 R A210
=0,2atau20%22=1atau100%
9 H G310
=0,3atau30%23=0,66atau66%
10 H C310
=0,3atau30%23=0,66atau66%
11 H A310
=0,3atau30%33=1atau100%
12 G C410
=0,4atau40%24=0,5atau50%
13 G A410
=0,4atau40%24=0,5atau50 %
14 C A410
=0,4atau40%34=0,75atau75%
D. Pattern EvaluationPada tahap ini rule yang telah
ditemukan dan memenuhi confidencepada tahap Data Mining kemudianditerjemahkan kedalam bahasa yangdapat dimengerti oleh manusia.Hasil dari tahap ini dan merupakanakhir dari serangkaian prosespencarian pola yang tersembunyiadalah :
1. R → A ( jika konsumen membelisusu kaleng maka membeli jugaroti dengan nilai support 20%dan confidence 100% )
2. H → A ( jika konsumen membeliceres maka membeli juga rotidengan nilai support 30% danconfidence 100% )
3. C → A ( jika konsumen membelimargarin maka membeli jugaroti dengan nilai support 40%dan confidence 75% )
Keterangan : Penterjemahan polapada contoh data ini bersumber daritabel kategori dapat dilihat padalampiran 2.
4.3 Perancangan
1. Use Case Diagram Aplikasi DataMining
Use case diagram menggambarkanfungsionalitas yang dimiliki olehaplikasi. Use case untuk aplikasidata mining ini dapat dilihat padaGambar 22

System
Operator
Cari pola Bentuk FP-Tree Telusur FP-Tree
Gabungkan pola tiap node di FP-TreeLihat data preprocessing
Lihat statistik pem belian
Lihat About
Lihat profil BORM A
Lihat petunjuk
Lihat inform asi sistem
Keluar
<<include>>
Gambar 22 Use case diagram aplikasidata mining
2. Class Diagram Aplikasi DataMining
Class diagram menggambarkanstruktur dan deskripsi class, packed,dan objek beserta hubungan satusama lain. Class diagram untukaplikasi data mining ini dapatdilihat pada Gambar 23.
penggaliData
+load data()+cari frequent item()+hapus item < minsupport()+urutkan transaksi berdasarkan frequensi item()+bentuk FP-Tree()+cari pola setiap node()+gabungkan setiap pola()+tampilkan pola()
transaksi+notrx = integer+item = string+tambah(notrx, item)
+*+1
pola+itemset = string+support = integer+confident = integer+tambah(itemset, support, confident)
+*
+1
+*
+*
Gambar 23 Class diagram aplikasi datamining
3. Sequence Diagram Aplikasi DataMiningSequence diagram menggambarkan
interaksi antar objek didalamsistem yang disusun dalam suatuurutan waktu. Sequence diagram padaaplikasi data mining ini dapatdilihat pada Gambar 24
aplikasi data miningsd
penggaliData : Agus
: operator
: transaksi : pola
1 : jalankan aplikasi()
2 : load data()
3 : cari frequensi setiap item()
4 : hapus item yang frequensinya < min support()
5 : urutkan transaksi berdasar frequensi item()
6 : bentuk FP-Tree()
7 : cari pola setiap node()
8 : gabungkan setiap pola()
9 : pola dari semua node yang terbentuk dalam FP-Tree()
10 : Menampilkan pola()
Gambar 24 Sequence diagram aplikasidata mining
4. NavigasiStruktur rancangan
navigasi/menu yang dibuat untukaplikasi datamining dapat dilihatpada Gambar 25
Gambar 25 Struktur rancangannavigasi
5. Implementasi
Hasil pengujian pencarian polaterhadap 1.275 data transaksi Bormatanggal 8 sampai dengan 9 April2013 yang telah melewati tahappreprocesssing dapat dilihat padaGambar 26.
Gambar 26 Pengujian sistem dengandata transaksi
Borma

Pada Gambar 5.23 terlihat padatabel data transaksi terdapat 1.275data transaksi yang telah diurutkansesuai dengan frequensi tiap barangpada tabel Frequent Item dengan nilaisupport 1%, hal ini akan sangatsulit dilakukan apabila menggunakanperhitungan manual karena datasangat banyak.
Kemudian Frequent Pattern Treedibangkitkan untuk melihat pola-pola pembelian konsumen yanghasilnya dapat dilihat pada tabelassociation rule. Pola-pola yangditemukan yang memenuhi minimumconfidence yaitu sebesar 20% dapatdilihat pada Tabel 17
Tabel 17 Pola beli konsumen denganminimum
support 1% dan confidence 20%Pola Beli Konsumen Support (%) Confidence
(%)Jika membeli ASESORIS KOMPUTER, maka akan membeli ATK 4 93
Jika membeli ATK, maka akan membeli ASESORIS KOMPUTER 5 64
Jika membeli SABUN MANDI, maka akan membeli SHAMPOO 18 53
Jika membeli PASTA GIGI, maka akanmembeli SHAMPOO 18 50
Jika membeli PELEMBUT PAKAIAN, maka akan membeli DETERJEN 17 50
Jika membeli SABUN CUCI PIRING, maka akan membeli SHAMPOO 15 50
Jika membeli PEMBERSIH WAJAH, makaakan membeli SHAMPOO 17 48
Jika membeli TELUR AYAM, maka akanmembeli MIE INSTANT 16 47
Jika membeli SABUN MANDI, maka akan membeli PASTA GIGI 18 47
Jika membeli PASTA GIGI, maka akanmembeli SABUN MANDI 18 47
Keterangan : selengkapnya dapat dilihat pada file lampiran 10 - pola beli konsumen dengan minimum support 1% dan confidence 20%.xls dalam CD laporan.
6. Kesimpulan
Data transaksi yang tersimpandapat lebih dimanfaatkan denganmenggunakan Aplikasi Data MiningAlgoritma Frequent Pattern Growth yangdapat mencari informasi yangtersembunyi dalam data transaksiyaitu pola beli konsumen. Informasiini dapat dijadikan salah satureferensi bagi manajer dalammenentukan tata letak barang yangoptimal sebagai salah satu upaya
untuk meningkatkan keunggulan dalampersaingan bisnis retail.
Hasil dari pengolahan datatransaksi 1 minggu dari tanggal 8s.d. 9 April 2013 di BORMACipadung, dengan batasan minimumsupport 1% dan confident sebesar 20%,ditemukan pola beli konsumentertinggi yaitu jika membeliAsesoris Komputer, maka akanmembeli ATK dengan nilai support 4%dan nilai confident tertinggi yaitu93%, dan jika konsumen membeli MieInstant, maka akan membeli SusuDalam Kemasan dengan nilai supporttertinggi yaitu 30% dan confident33%.
7. Saran
Setelah mengevaluasi terhadapproses dan hasil dari aplikasi datamining ini, penulis memilikibeberapa saran untuk pengembanganaplikasi selanjutnya yangberhubungan dengan data mining ini,yaitu :
1. Untuk pencarian polaselanjutnya diharapkan untukmeneliti kembali algoritma yanglebih baik yang bisa diterapkanselain algoritma Frequent PatternGrowth.
2. Informasi yang dicari lebihbervariasi, karena wilayahkajian data mining ini sangatluas.
3. Untuk tampilan aplikasi, dapatlebih disempurnakan denganmenggunakan diagram pada polayang ditemukan agar penggunalebih mudah memahaminya.
8. Daftar Pustaka
Gantz, John., David Reinsel, 2009,As the Economy Contracts, the DigitalUniverse Expands, USA : IDC GMS.
Pramudiono, Iko. 2003, Pengantar DataMining : Menambang PermataPengetahuan di Gunung Data, IlmuKomputer (diakses 23 Juni2013).
Kusrini, Emha Taufiq L. 2009.Algoritma Data Mining, Yogakarta :Penerbit ANDI.
Han, Jiawei., Micheline Kamber,2006, Data Mining Concepts andTechniques Second Edition, SanFransisco : Morgan KaufmannPublisher.
Suprasetyo, Achmad Fendi. 2012,Market Basket Analisis MenggunakanAlgoritma Frequent Pattern Growth padaData Transaksi Penjualan Barang Hariandi Swalayan XYZ, Gorontalo : Fak.Teknik UNG.
Prasetyo, Eko. 2012, Data MiningKonsep dan Aplikasi MenggunakanMATLAB, Yogyakarta : PenerbitANDI.
Santosa, Budi. 2007, Data Mining TeknikPemanfaatan Data untuk KeperluanBisnis, Yogyakarta : Graha Ilmu.
9. Lampiran
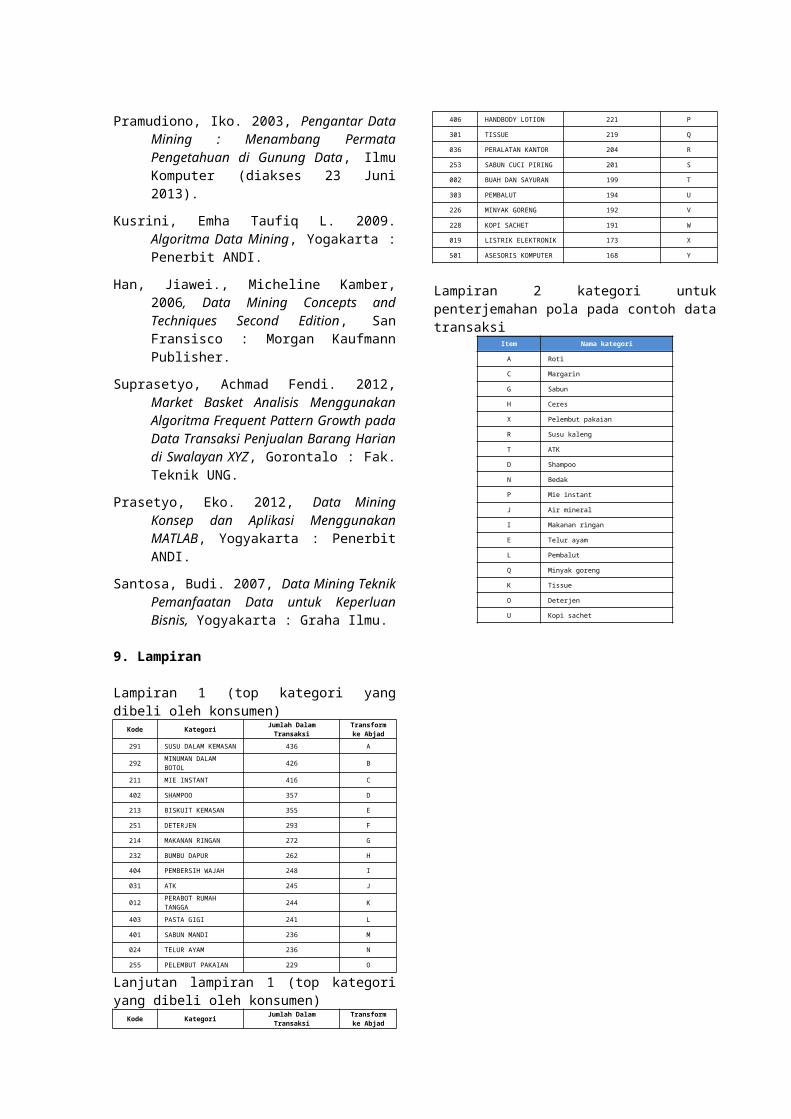
Lampiran 1 (top kategori yangdibeli oleh konsumen)
Kode Kategori Jumlah DalamTransaksi
Transformke Abjad
291 SUSU DALAM KEMASAN 436 A
292 MINUMAN DALAM BOTOL 426 B
211 MIE INSTANT 416 C
402 SHAMPOO 357 D
213 BISKUIT KEMASAN 355 E
251 DETERJEN 293 F
214 MAKANAN RINGAN 272 G
232 BUMBU DAPUR 262 H
404 PEMBERSIH WAJAH 248 I
031 ATK 245 J
012 PERABOT RUMAH TANGGA 244 K
403 PASTA GIGI 241 L
401 SABUN MANDI 236 M
024 TELUR AYAM 236 N
255 PELEMBUT PAKAIAN 229 O
Lanjutan lampiran 1 (top kategoriyang dibeli oleh konsumen)
Kode Kategori Jumlah DalamTransaksi
Transformke Abjad
406 HANDBODY LOTION 221 P
301 TISSUE 219 Q
036 PERALATAN KANTOR 204 R
253 SABUN CUCI PIRING 201 S
002 BUAH DAN SAYURAN 199 T
303 PEMBALUT 194 U
226 MINYAK GORENG 192 V
228 KOPI SACHET 191 W
019 LISTRIK ELEKTRONIK 173 X
501 ASESORIS KOMPUTER 168 Y
Lampiran 2 kategori untukpenterjemahan pola pada contoh datatransaksi
Item Nama kategori
A Roti
C Margarin
G Sabun
H Ceres
X Pelembut pakaian
R Susu kaleng
T ATK
D Shampoo
N Bedak
P Mie instant
J Air mineral
I Makanan ringan
E Telur ayam
L Pembalut
Q Minyak goreng
K Tissue
O Deterjen
U Kopi sachet
Related Documents











