1 Luca Benini ARTIST2 / UNU IIST 2007 Part IV - Design technology for MPSoCs System design & Virtual platforms Analysis of non functional properties: power System optimization Allocation and scheduling Communication synthesis Luca Benini – DEIS Università di Bologna [email protected] Luca Benini ARTIST2 / UNU IIST 2007 Methodology Evolution 70’s Silicon Real Estate Time Complex Layouts Transistors Sea of Transistors Gates 80’s RTL Early 90’s RTL Sea of Gates Late 90’s Platform Based Design TA SW HW Blocks + SW 2005+ Sea of Processors HW SW Multiprocessor Systems on Chip (MPSoC) . . . I$ I$ . . . CORE Engine I$ DSP Platform CORE Engine I$ RISC CONTROL BUS External Memory MMU MEMORY BUS CONTROL BUS IP IP Middleware / OS Application Middleware / OS Application

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Luca Benini ARTIST2 / UNU IIST 2007
Part IV - Design technology for MPSoCs
System design & Virtual platformsAnalysis of non functional properties: powerSystem optimization
Allocation and schedulingCommunication synthesis
Luca Benini – DEIS Università di [email protected]
Luca Benini ARTIST2 / UNU IIST 2007
Methodology Evolution
70’s
Silic
on R
eal E
stat
e
Time
Complex Layouts
Transistors
Sea of Transistors
Gates
80’s
RTL
Early 90’s
RTL
Sea of Gates
Late 90’s
Platform BasedDesign
TA SW
HW Blocks + SW
2005+
Sea of Processors
HW SW
Multiprocessor Systems on Chip
(MPSoC)
.
.
.
COREEngine
D$I$
DSP
PlatformIP CORE
EngineD$I$
RISC
CONTROL BUS
Exte
rnal
Mem
ory
MM
U
MEMORY BUS
CONTROL BUS
IP
IP
IP
IP
IP
.
.
.
COREEngine
D$I$
DSP
PlatformIP CORE
EngineD$I$
RISC
CONTROL BUS
Exte
rnal
Mem
ory
MM
U
MEMORY BUS
CONTROL BUS
IP
IP
IP
IP
IP
Middlew
are / OS
Application
Middlew
are / OS
Application

2
Luca Benini ARTIST2 / UNU IIST 2007
Platform based SoC Design Flow
algorithm selectionoptimization
algorithm selectionoptimization
functional modelHW/SW partitioning
behavior mappingarchitecture exploration
HW/SW partitioningbehavior mapping
architecture exploration
architecture modelCPU IP
IP
CPU
MM
S S
INPUT OUTPUT
communication model
implementation model
application requirements
CA selection/explorationprotocol generationtopology synthesis
CA selection/explorationprotocol generationtopology synthesis
interface synthesiscycle scheduling
interface synthesiscycle scheduling
CPU
CPU S
Logic synthesis and physical implementation
M
IP
IP M
S
CPU
CPU S
M
IP
IP M
S
Luca Benini ARTIST2 / UNU IIST 2007
SystemC
Objectives:Model Hw with Sw programming languageAchieve fast simulationProvide support for hw/sw system design
Requirement:Give hw semantics to sw models
Supported by a large consortium of semiconductor and EDA companies

3
Luca Benini ARTIST2 / UNU IIST 2007
SystemC Design Vision
SystemC as a single design language
System Specification(SystemC)
HW(SystemC)
SW(SystemC)
Testbench
0101011110100010111001010010011110000111101010010001100110101011. . .
Ref
ine
Ref
ine
Luca Benini ARTIST2 / UNU IIST 2007
SystemC Model Structure

4
Luca Benini ARTIST2 / UNU IIST 2007
SC_MODULE
SystemC ClassesModules and Ports
Modules (sc_module)Fundamental structural entity Contain processesContain other modules (creating hierarchy)
Ports(sc_in<>,sc_out<>,sc_inout<>)Modules have portsPorts have typesA process can be made sensitive to ports/signals
in1
clk
in2
out1
out2
Luca Benini ARTIST2 / UNU IIST 2007
SC_MODULE
in1
clk
in2
out1
out2
SystemC Classes - ProcessesFunctionality is described in a process
Processes run concurrently
Code inside a process executes sequentially
SystemC has three different types of processesSC_METHOD
SC_THREAD
SC_CTHREADPROCESS
PROCESS

5
Luca Benini ARTIST2 / UNU IIST 2007
Process types
sc_method: method processsensitive to a set of signalsexecuted until it returns
sc_thread: thread processsensitive to a set of signalsexecuted until a wait()
sc_cthread: clocked thread processsensitive only to one edge of clockexecute until a wait() or a wait_until()watching(reset) restarts from top of process body (reset evaluated on active edge)
Combinational
Sequential
Testbench
Luca Benini ARTIST2 / UNU IIST 2007
Execution of processes
Not hierarchical, communicate through signalsExecution and signal updates
request-update semantics1. execute all processes that can be executed2. update the signals written by the processes
other processes to be executed
module ex
port a port binternalsignal
sig
process process

6
Luca Benini ARTIST2 / UNU IIST 2007
Channels
Primitive Hierarchical
Luca Benini ARTIST2 / UNU IIST 2007
Communication semantics
Interface Method Calls (IMC)Process calls an interface method of a channelThe collection of a fixed set of communication Methods is called an Interface (virtual object without data)Channels implement one or more InterfacesModules can be connected via their Ports to those Channels

7
Luca Benini ARTIST2 / UNU IIST 2007
1. Specification model
2. PE*-assembly model3. Bus-arbitration model4. Time-accurate
communication model
5. Cycle-accurate computation model
6. Implementation model
Model types
TLM
* Processing elements
Luca Benini ARTIST2 / UNU IIST 2007
PE-assembly & Bus-arbitration Models
Processing elements (PEs)Message-passing channels
Abstract bus channelsBus arbiter arbitrates bus
conflict

8
Luca Benini ARTIST2 / UNU IIST 2007
Time-accurate Communication model
Time/cycle accurate communication (time constraint) Approximate timed computationProtocol channel provides functions for all abstraction bus transaction
Luca Benini ARTIST2 / UNU IIST 2007
Cycle-accurate computation model
Modeled at register-transfer level PE are pin accurate and execute cycle-accuratelyWrappers convert data transfer from higher level of abstraction to lower level abstraction

9
Luca Benini ARTIST2 / UNU IIST 2007
Successive refinements
Luca Benini ARTIST2 / UNU IIST 2007
Summary: models
Models Communication time
Computation time
Communication scheme
PE interface
Specification model
no no variable (no PE)
Component-assembly model
no approximate variable channel abstract
Bus-arbitration model
approximate approximate abstract bus channel
abstract
Bus-functional model
time/cycle accurate
approximate protocol bus channel
abstract
Cycle-accurate computation
model
approximate cycle-accurate abstract bus channel
pin-accurate
Implementation model
cycle-accurate cycle-accurate bus (wire) pin-accurate

10
Luca Benini ARTIST2 / UNU IIST 2007
Pure SystemC Flow
Luca Benini ARTIST2 / UNU IIST 2007
SystemC HDL Flow

11
Luca Benini ARTIST2 / UNU IIST 2007
The missing link: SystemC Synthesis
SystemC is not “born” to be a language for HW implementation(like Verilog & VHDL)Someone does not think so (and it would be nice if they wereright)
Basic idea: define synthesizableSystemC subsetMake it another refinement step
But will it succeed? Long story…
[Celoxica 2005]
Luca Benini ARTIST2 / UNU IIST 2007
SystemC contrastedwith other design languages

12
Luca Benini ARTIST2 / UNU IIST 2007
Industry Standard
Architecture
Design vs. Reuse
Co-Design
Implement
Co-Verify
Verify
Implement
Verify
SW Code HW Design
Implement
Verify
DesignReuse
IPCodeReuse
IP
Software
Product
Hardware
Environment
Specify
Conceptto
RTL
RTLto
GDSIIReusable
IPIntegration
Reuse of IP components (HW/SW) is key!
Luca Benini ARTIST2 / UNU IIST 2007
Virtual Platforms
Library of functional models of IP BlocksStandardized channel interfaceMultiple levels of abstractions are allowed

13
Luca Benini ARTIST2 / UNU IIST 2007
Example: ARM Prime Xsys VP
Luca Benini ARTIST2 / UNU IIST 2007
HW AcceleratorsDSP
On-chip Memory
DedicatedPeripherals Logic
Core support
CPU Core
AR
B
Dec
odeComplex system interconnect:
Configurable Bus Matrix
Core subsystem:Select and
Automate Integration
Peripheral IP:Select, Configure and Automate Integration
Build full system:Auto-Validate Build
… we need industry standards for data exchange to enable fast VP construction
Building a virtual platform

14
Luca Benini ARTIST2 / UNU IIST 2007
SPIRIT Meta-data:Machine-interpretable design IP Specifies integration requirementsConsistent across all design views
SPIRIT generators:Point-tool launchIP configuration launchInterface for integration with SPIRIT-enabled tools
HW AcceleratorsDSP
AR
B
Dec
ode
On-chip Memory Logic
DedicatedPeripherals
Integrate
SPIRIT a Standard for IP integration
Import
Configure
Core support
CPU
Luca Benini ARTIST2 / UNU IIST 2007
Why use Design Meta-data?
Relate specification to implementationMachine interpretable coupling of design views e.g., Meta-data describes how Verilog signal list of a design IP describes a bus interface
Broad applicabilityIs applicable to new and legacy IPNo enforced design style or methodology A by-product of IP import into SPIRIT-enabled tools

15
Luca Benini ARTIST2 / UNU IIST 2007
SPIRIT in Design Environments
Design Build
Design Capture
protocolbuswidth
mPsystem_bus
ComponentIP
UART GPIO
addressinterfaceregisters
Design Build
protocolbuswidth
mP
system_bus
ComponentIP
UART GPIO
mPComponentIP
UART GPIO
MEM
addressinterfaceregisters
addressinterfaceregisters
SPIRIT IPImportExport
SPIRIT EnabledIP
ComponentIP
ComponentXML
ComponentIP
ComponentXML
SPIRITMeta-data
SPIRIT EnabledSoC Design Tool
ConfiguredIP
PointTool
SPIRITAPIs
PointTool
GeneratorXML
ConfiguratorXML
SPIRIT EnabledGenerators
SoCDesign IP
XML
SoCDesign IP
DesignXML
Luca Benini ARTIST2 / UNU IIST 2007
Analysis of non functional properties: power

16
Luca Benini ARTIST2 / UNU IIST 2007
Non-functional properties
INTERCONNECTION
Core Core INTERRUPTCONTROLLER
PRI MEM 4 SHARED MEM SEMAPHORES
Core Core
PRI MEM 3PRI MEM 2PRI MEM 1
STbusor AMBA or Xpipes
Cycle accurate VP(~ 24 Kcycles/sec with 4 cores on a 2-proc Pentium III, 1GHz, 512MB)
How to estimate power during SW execution?
Luca Benini ARTIST2 / UNU IIST 2007
Power modeling
Invoked from hardware modules after activation events on a cycle-by-cyclebasisEnergy info is passed to data collectorroutine at each cycle
MEMORY(or CACHE)
MODULE
PowerModelEnergy spent
DataCollector
Memory state1. The module calls the
power model function
Energy spent2. The module sends the
energy consumptioninfo to the data collector routines

17
Luca Benini ARTIST2 / UNU IIST 2007
Power model for processor cores
Power statistics are obtaining bymonitoring traces of core execution(e.g. executed instructions)Need to account for idle power when module is stalled
ARMMODULE
PowerModel
Energy spent
DataCollector
1. The simulator calls the data coll. routine
Core state
2. The data collector routine gets the energyinformationfrom the power model
Luca Benini ARTIST2 / UNU IIST 2007
Core Power Estimation: Instruction-Level
ILPA [TMWL96]Empirical method for characterizing single (or very short sequences of) instructions.Key issues:
Evaluation of power dissipation for single instructions.Choice of representative instructions forcharacterization.
Advantage: Roughly architecture-independent.

18
Luca Benini ARTIST2 / UNU IIST 2007
Instruction-Level Power Characterization
Direct measurement of the currents drawnfrom the power supply while executing the instructions.HDL simulation:
The instructions are simulated on a processor model in some HDL.The processor is plugged into a tester machineand simulation traces are applied. The current ismeasured by the tester.
Use simulation of a gate-level description of the processor.
Luca Benini ARTIST2 / UNU IIST 2007
Instruction-Level Models
A power cost is assigned to each instruction.Two components of the cost:
Static component, called “base-cost”: It is the individual instruction cost without a notion of “state”.Dynamic component, called “circuit state effects”: It accounts for the previous processor state.
Dynamic cost accounts for events dependingon sequences of events (e.g., cache misses, pipeline stalls).

19
Luca Benini ARTIST2 / UNU IIST 2007
Extracting the model
The base cost is computed as follows:An infinite loop containing a total of N copies of the target instruction I is executed.The average current is measured as describedearlier.The power cost is obtained from the values of the current, the supply voltage and the cycle/instruction.
N should not be too small to amortize the loop overhead.
Luca Benini ARTIST2 / UNU IIST 2007
Computing program execution cost
Due to the averaging process, the costs for I1 → I2 and I2 →I1 cannot be distinguished.The cost of a program can be summarized as follows:
Cost(Program) = Σi (B i · N i) + Σi j (O i j ·N i j ) + Σ k E k
where: B i : Base cost of instruction i.N i : # of occurrences of instruction i.O i j : Dynamic cost of sequence →j.N i j : # of occurrences of sequence →j.E k: Other effects, obtained from program profiling.

20
Luca Benini ARTIST2 / UNU IIST 2007
Instruction-Level power model: Example
Example of power cost values (expressed in pJ):
Example of computation:
Total value = 5.87pJ/(3·25ns) = 78.26μW (Tc = 25ns)
LOADDLOADADDMULT
2.37 0.17 1.19 0.920.99 0.26 0.531.19 0.66
InstructionName
BaseCost
Circuit State EffectsLOAD DLOAD ADD MULT
1.98 0.13 0.15 1.19 0.92
Total
EvaluationProgram(initial state is ADD) Base Cost Circuit StateDLOAD A←x, B ←y LOAD C←z ADD A←C, B
2.37 1.191.98 0.150.99 1.193.34 2.53
Luca Benini ARTIST2 / UNU IIST 2007
Micro-architectural Power Model
The processor is viewed as an interconnection of macro blocks
E.g. Execution units, register file, etc.
Power models are built for the macrosE.g. Analytical, look-up tables, etc.
Advantage: allows micro-architecture expl.Disadvantage: no black-box for COTS proc.

21
Luca Benini ARTIST2 / UNU IIST 2007
FPLA : Functional Level Power Analysis
Between ILPA and micro-architecturalLess parameters than ILPA, less info on intenals than micro-acrchitectural
Suitable for complex cores, with limited internal informationAlgorithmic parameters require functional simulation (ISS runor code analysis)
Algorithmic parameters• α: parallelism rate• β: processing rate• γ: ext. IM access rate• ε: DMA activity rate• τ: ext. DM access rate
Architectural parameters• F: clock frequency• MM: internal Mem mode
(mapped,bypass,cache,freeze)
• DD: data mapping• DW: DMA data width
[Laurent03]
(example TI62, TI67 DSPs)
Luca Benini ARTIST2 / UNU IIST 2007
Power profiling: HW view
Waveforms: cycle by cycle consumption
Power estimation----------------
Energy spent:ARM 0
core: 25609147.30 [pJ]cache: 105048808.17 [pJ]
ARM 1core: 25609092.30 [pJ]cache: 105048808.17 [pJ]
ARM 2core: 25609092.30 [pJ]cache: 105048808.17 [pJ]
ARM 3core: 25614207.30 [pJ]cache: 105048808.17 [pJ]
RAM 0: 2825183.87 [pJ]RAM 1: 2825183.87 [pJ]RAM 2: 2825183.87 [pJ]RAM 3: 2824958.26 [pJ]RAM 4: 0.00 [pJ]BUS: 50778876.39 [pJ]
Power spent:ARM 0
core: 51.18 [mW]cache: 209.95 [mW]
ARM 1core: 51.18 [mW]cache: 209.95 [mW]
ARM 2core: 51.18 [mW]cache: 209.95 [mW]
ARM 3core: 51.18 [mW]cache: 209.95 [mW]
RAM 0: 5.65 [mW]RAM 1: 5.65 [mW]RAM 2: 5.65 [mW]RAM 3: 5.65 [mW]RAM 4: 0.00 [mW]BUS: 101.49 [mW]
Output file: totals

22
Luca Benini ARTIST2 / UNU IIST 2007
Using power models in SW
ISS core SWI_METRIC_START
Initialization:...RegisterSWI(SWI_METRIC_START,metric_start_swi_call);...
installs the handleruint32_t metric_start_swi_call(
CArmProc *arm, uint32_t r0, uint32_t r1, uint32_t r2, uint32_t r3)
statobject->startMeasuring(arm->ID);return r0;
......__asm ("swi " SWI_METRIC_STARTstr);......
Program:
handler invocation
The handler can be easily modified to be invoked by a pseudo-hardwaremodule for collection of system power statistics
Luca Benini ARTIST2 / UNU IIST 2007
Power profiling: SW view
Power distributions for send Power distributions for receive
Message size:128 byte
Message size:256 byte

23
Luca Benini ARTIST2 / UNU IIST 2007
System optimizationAllocation and scheduling
Design as optimizationDesign spaceThe set of “all” possible design choicesConstraintsSolutions that we are not willing to
acceptCost functionA property we are interested in
(execution time, power, reliability…)

24
Hardware synthesisALGORITHM
HIGH-LEVEL SYNTHESIS
S1 S3 S4S2
0.0 200.0 4 00.0 600. 0Freq
-120 .0
-100 .0
-80 .0
-60 .0
-40 .0
-20 .0
Am
pl (
db)
++
++
D
D
++
++
D
D
c1 c2
c3
c4 c5
c6
kIN
+
+
D
D
++
+
D
D
+
++c1
c2 c3
c4
c5
c6 c7
c8
k
dIN OUT
APPLICATION
interconnect
ASICGP signal
MCM
processor
memory
ARCHITECTURE
LOGIC AND PHYSICAL SYNTHESIS
Behavioral synthesisC ontrol/D ataFlow G rap h
(C DFG )Implem en tation
RegReg
M ultiplier
Adder
RegReg2 1 1 ...2 3 2 ...
4 3 2 ...
0 4 7 ...4 7 9 ...

25
Allocation, Assignment, and Scheduling
D
+
-
>>
>>
+
-
>>
+ >>
+
>>
+
Allocation: How Much?2 adders
Assignment: Where?
Schedule: When?
Shifter 1
Time Slot 4
1 shifter24 registers
D
Techniques Well Understood and Mature
Luca Benini ARTIST2 / UNU IIST 2007
Application Mapping
The problem of allocating, scheduling for task graphs on multi-processors in a distributed real-time system is NP-hard.New tool flows for efficient mapping of multi-task applications onto hardware platforms
T1
T2 T3
T4 T5 T6
T7
T8
…Proc. 1 Proc. 2 Proc. N
INTERCONNECT
Private
Mem
Private
Mem
Private
Mem…
T1 T2 T3T4 T5 T6T8 T7
Time
Res
ourc
es
T1 T2
T3
T4
T5 T7
Deadline
T8
Allocation
Schedule

26
Luca Benini ARTIST2 / UNU IIST 2007
When & Why Offline Optimization?
Plenty of design-time knowledgeApplications pre-characterized at design timeDynamic transitions between different pre-characterized scenarios
Aggressive exploitation of system resourcesReduces overdesign (lowers cost)Strong performance guarantees
Applicable for many embedded applications
Luca Benini ARTIST2 / UNU IIST 2007
Scheduling & Voltage Scaling
deadlinet
P
τ1 τ2 τ3
Energy/speed trade-offs:varying the voltages
Vbs
CPUVdd
f1 f2 f3
Different voltages:different frequencies
Mapping and scheduling: given (fastest freq.)
Power
deadlinetτ1 τ2 τ3
SlackVoltage and Frequency scalingmake the problem even harder!
Current off-line approachessolve mapping, scheduling and voltage
selection separately (sequentially)

27
Luca Benini ARTIST2 / UNU IIST 2007
Target architecture Homogeneous computation tiles:
ARM cores (including instruction and data caches);Tightly coupled software-controlled scratch-pad memories (SPM);
AMBA AHB;DMA engine;RTEMS OS;Power models for 0.13μm power models (STM)
Variable Voltage/Frequency cores with discrete (Vdd,f) pairsFrequency dividers scale down the baseline 200 MHz system clockCores use non-cacheable shared memory to communicateSemaphore and interrupt facilities are used for synchronization
Tile TileTile Tile …Sync. Sync. Sync. Sync.
PrivateMem
PrivateMem
PrivateMem
PrivateMem
SharedMem
AMBA AHB INTERCONNECT
PrivateMem..
Prog.REG
CLOCK TREEGENERATOR
SystemC
LOC
K
CLOCK NCLOCK 3
CLOCK 2CLOCK 1
INTSlave
… Int_
CLKTile TileTile Tile …
Sync. Sync. Sync. Sync.
PrivateMem
PrivateMem
PrivateMem
PrivateMem
SharedMem
AMBA AHB INTERCONNECT
PrivateMem..
Prog.REG
CLOCK TREEGENERATOR
SystemC
LOC
K
CLOCK NCLOCK 3
CLOCK 2CLOCK 1
INTSlave
… Int_
CLK
Luca Benini ARTIST2 / UNU IIST 2007
Task graphA group of tasks TTask dependenciesExecution times express in clock cycles: WCN(Ti)Communication time (writes & reads) expressed as: WCN(WTiTj) and WCN(RTiTj)These values can be back-annotated from functional simulation or computed using WCET analysis tools (e.g. AbsINT)Node type
Normal; Fork, And; Branch, Or
Application model
Task1
Task2
Task3
Task4
Task5
Task6
WCN(WT1T2)WCN(RT1T2)WCN(T1)
WCN(WT1T3)WCN(RT1T3)
WCN(T2) WCN(WT2T4)WCN(RT2T4)
WCN(WT3T5)WCN(RT3T5)
WCN(WT4T6)WCN(RT4T6)
WCN(WT5T6)WCN(RT5T6)
WCN(T3)
WCN(T4)
WCN(T5)
WCN(T6)

28
Luca Benini ARTIST2 / UNU IIST 2007
Syst
em B
us
Priv
ate
Mem
Priv
ate
Mem
ARM Core
Int controller
SPM
Semaphores
ARM Core
Int controller
Semaphores
SPM
#2#1
Task memory requirements
Communicating tasks might run:On the same processor → negligible communication costOn different processors → costly message exchange procedure
Task storage can be allocated by Optimizer:On the local SPMOn the remote Private Memory
Each task has three kinds of memory requirements
Program DataInternal StateCommunication queues
Luca Benini ARTIST2 / UNU IIST 2007
Syst
em B
us
Priv
ate
Mem
Priv
ate
Mem
ARM Core
Int controller
SPM
Semaphores
ARM Core
Int controller
Semaphores
SPM
Task memory requirements
Each task has three kinds of memory requirements:
Program Data;Internal State;Communication queues.
#2
#1
Communicating tasks might run:On the same processor → negligible communication costOn different processors → costly message exchange procedure
Task storage can be allocated by Optimizer:On the local SPMOn the remote Private Memory

29
Luca Benini ARTIST2 / UNU IIST 2007
Application Development Flow
CTGCharacterization
Phase
Simulator
OptimizationPhase
Optimizer
ApplicationProfiles
Optimal SWApplication
ImplementationAllo
catio
n
Sched
uling
ApplicationDevelopment
Support
PlatformExecution
Luca Benini ARTIST2 / UNU IIST 2007
Optimization frameworkDeterministic & stochastic task graphsConstraints
Resources: computation, communication, storageTiming: task deadlines, makespan
Objective functionsPerformance (e.g. Makespan)Power (energy)Bus utilization
General modeling framework highly unstructured optimization problems
No black-box/generic optimizer can solve them efficientlyWe developed a flexible algorithmic frameworkwich is tuned on specific problems

30
Luca Benini ARTIST2 / UNU IIST 2007
Logic Based Benders DecompositionObj. Function:Communication cost
& energy consumption
Validallocation
Allocation& Freq. Assign.:
INTEGER PROGRAMMING
Scheduling:CONSTRAINT PROGRAMMING
No good: linearconstraint
Memory constraints
Timingconstraint
Decomposes the problem into 2 sub-problems:Allocation & Assignment (& freq. setting) → IP
Objective Function: E.g.: minimizing energy consumption during execution and communication of tasks
Scheduling → CPObjective Function: E.g.: minimizing energy consumption during frequency switching
Luca Benini ARTIST2 / UNU IIST 2007
Computational scalability
Simplified CP and IP formulationsHybrid approach clearly outperforms pure CP and IP techniquesSearch time bounded to 1000 sec.
CP and IP can found a solution only in 50%- of the instancesHybrid approach always found a solution
Deterministic task graphs, mapping & scheduling
16 25 36 49 64 81 100 1 2 3 4 5 6 7

31
Luca Benini ARTIST2 / UNU IIST 2007
Computational Scalability
Hundreds of of decision variablesMuch beyond ILP solver or CP solver capability
Deterministic task graphs, mapping & scheduling & v,f selectionStochastic task graphs, mapping & scheduling & min bus usage
Luca Benini ARTIST2 / UNU IIST 2007
Optimality gapComparison with heuristic 2-phase solution (GA)
“timing barrier”
gap significant when constraints are tight

32
Luca Benini ARTIST2 / UNU IIST 2007
Optimization Development
The abstraction gap between high level optimization tools and standard application programming models can introduce unpredictable and undesired behaviours.Programmers must be conscious about simplified assumptions taken into account in optimization tools.
Platform Modelling
Optimization Analysis
Optimal Solution
Starting Implementation
Platform Execution
Abstractiongap
(. .
Final Implementation
Challenge: the Abstraction Gap
Luca Benini ARTIST2 / UNU IIST 2007
MAX error lower than 10%AVG error equal to 4.51%, with standard deviation of 1.94All deadlines are met
Optimizer
Optimal Allocation & Schedule
Virtual Platform validation -0.05
0
0.05
0.1
0.15
0.2
0.25
-5% -4% -3% -2% -1% 0% 1% 2% 3% 4% 5% 6% 7% 8% 9% 10% 11%
250 instances
Validation of optimizer solutions Throughput
Prob
abili
ty (%
)
Throughput difference (%)

33
Luca Benini ARTIST2 / UNU IIST 2007
MAX error lower than 10%;AVG error equal to 4.80%, with standard deviation of 1.71;
Optimizer
Optimal Allocation & Schedule
Virtual Platform validation
250 instances
Validation of optimizer solutions Power
-0.05
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
-5% -4% -3% -2% -1% 0% 1% 2% 3% 4% 5% 6% 7% 8% 9% 10% 11%
250 instances
Prob
abili
ty (%
)Energy consumption difference (%)
Luca Benini ARTIST2 / UNU IIST 2007
GSM Encoder
Throughput required: 1 frame/10ms.With 2 processors and 4 possible frequency & voltage settings:
Task Graph:10 computational tasks;15 communication tasks.
Without optimizations:50.9μJ
With optimizations:17.1 μJ - 66,4%

34
Luca Benini ARTIST2 / UNU IIST 2007
Challenge: programming environment
A software development toolkit to help programmers in software implementation:
a generic customizable application template OFFLINE SUPPORT;a set of high-level APIs ONLINE SUPPORT in RT-OS (RTEMS)
The main goals are:predictable application execution after the optimization step;guarantees on high performance and constraint satisfaction.
Starting from a high level task and data flow graph, software developers can easily and quickly build their application infrastructure.Programmers can intuitively translate high level representation into C-code using our facilities and library
Luca Benini ARTIST2 / UNU IIST 2007
//Node Behaviour: 0 AND ; 1 OR; 2 FORK; 3 BRANCHuint node_behaviour[TASK_NUMBER] = 2,3,3,..;
#define N_CPU 2uint task_on_core[TASK_NUMBER] = 1,1,2,1;int schedule_on_core[N_CPU][TASK_NUMBER] = 1,2,4,8..;
uint queue_consumer [..] [..] = 0,1,1,0,..,0,0,0,1,1,.,0,0,0,0,0,1,1..,0,0,0,0,....;
//Node Type: 0 NORMAL; 1 BRANCH ; 2 STOCHASTICuint node_type[TASK_NUMBER] = 1,2,2,1,..;
ExampleNumber of nodes (e.g 12)Graph of activitiesNode type
Normal, Branch, Conditional, Terminator
Node behaviourOr, And, Fork, Branch
Number of CPUs : 2Task AllocationTask SchedulingArc priorities
Time
Res
ourc
es
N1 B2
B3
C4
C7
Deadline
N8
T2 T3
T4 T5 T6 T7
T8 T9 T10
T11
T12
T1N1
B2 B3
C4 C5 C6 C7
N8 N9 N10
N11
T12
fork
or
or
and
branch branch
P1P2
N11
N10
T12
a1a2
a3 a4 a5 a6
a7 a8 a9 a10
a11 a12
B3 C7 N10
T12
a13
a14
#define TASK_NUMBER 12

35
Luca Benini ARTIST2 / UNU IIST 2007
Relationship with RT techniques
We can handle periodic task graphsMultiple rates can be analyzed by unrolling and periodic extension
Cannot deal with aperiodic/sporadic tasks unknown at design time
They would require unbounded unrollingCurrently assumes non-preemptive scheduling
Luca Benini ARTIST2 / UNU IIST 2007
Looking forward
Toward a mature SDKMature programmer support (Eclipse toolkit, OpenMAX support)Extend semantics (multi-rate SDF)Ports on real platforms (Cell BC underway, Nomadik is under discussion)
Optimization engine enhancementsDealing with multiple use casesVariable execution timesAggressive communication scheduling on NoCsAddress preemption and sporadic tasks

36
Luca Benini ARTIST2 / UNU IIST 2007
System optimizationAllocation and schedulingCommunication synthesis
Luca Benini ARTIST2 / UNU IIST 2007
Data Communication vs. Processing
I/O Bus
Main Bus
Core NµP
Core 2
µP Sub systemµP
Mem Bus
Core 1 SoCs
Circa 2004
SoCs Circa 2007
Critical Decision Was uP Choice
Critical Decision Is Interconnect Choice
Communication Architecture Design and Verification becoming Highest Priority in Contemporary SoC Design!
DRAMC
Exploding core counts requiring more advanced InterconnectsEDA cannot solve this architectural problem easilyComplexity too high to hand craft (and verify!)
Source: SONICS Inc.

37
Luca Benini ARTIST2 / UNU IIST 2007
Communication Architectures in today’s complex systems significantly affect performance, power, cost and time- to- market!
Communication Architectures in today’s complex systems significantly affect performance, power, cost and time- to- market!
communication architecture consumes upto 50% of total
on-chip power!
communication is THE most critical aspect affecting system performance
communication architecture design, customization,
exploration, verification and implementation takes up the
largest chunk of a design cycle
ever increasing number of wires, repeaters, bus components
(arbiters, bridges, decoders etc.) increases system cost
Need for Communication-centric Design Flow
Luca Benini ARTIST2 / UNU IIST 2007
Typical Industrial SoC Design Flow
algorithm selection
optimization
algorithm selection
optimizationfunctional model
HW/SW partitioningbehavior mapping
architecture exploration
HW/SW partitioningbehavior mapping
architecture exploration architecture model
communication model
implementation model
application requirements
CA selection/explorationprotocol generationtopology synthesis
CA selection/explorationprotocol generationtopology synthesis
interface synthesis
cycle scheduling
interface synthesis
cycle scheduling
Logic synthesis and physical implementation
ad-hoc partitioning and mapping; “on-paper” exploration
manual communication architecture selection
manual bus<->IP interface synthesis
very limited RTL exploration (~weeks)verification (~months)
physical implementation (~months)
no algorithm optimization
38
Luca Benini ARTIST2 / UNU IIST 2007
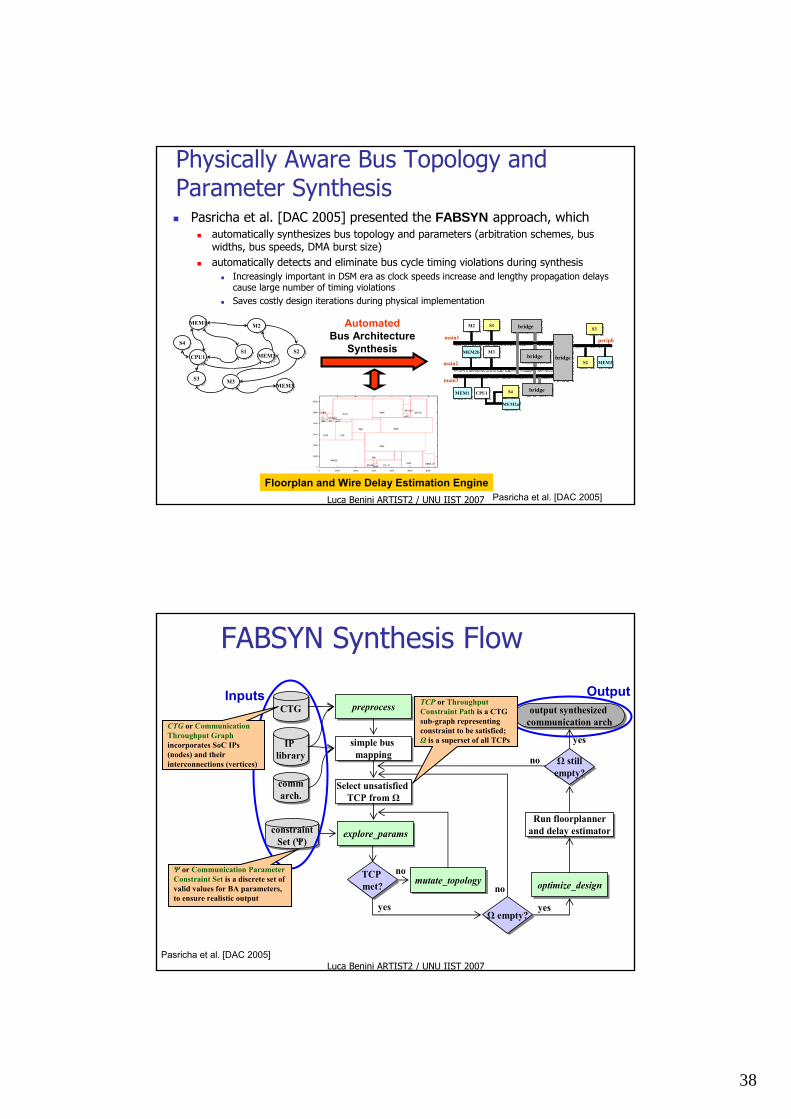
Physically Aware Bus Topology and Parameter Synthesis
Pasricha et al. [DAC 2005] presented the FABSYN approach, whichautomatically synthesizes bus topology and parameters (arbitration schemes, bus widths, bus speeds, DMA burst size)automatically detects and eliminate bus cycle timing violations during synthesis
Increasingly important in DSM era as clock speeds increase and lengthy propagation delays cause large number of timing violationsSaves costly design iterations during physical implementation
S1S1
S3S3
S2S2
MEM3MEM3M3M3
MEM2MEM2
M2M2
CPU1CPU1
MEM1MEM1
S4S4
M2M2
CPU1CPU1
S1S1
MEM3MEM3
MEM2aMEM2a
S3S3
S2S2
periphmain1
bridgebridge
MEM1MEM1 S4S4
MEM2bMEM2b
main2
M3M3
bridge bridge
bridge bridge
main3
bridgebridge
AutomatedBus Architecture
Synthesis
Floorplan and Wire Delay Estimation EnginePasricha et al. [DAC 2005]
Luca Benini ARTIST2 / UNU IIST 2007
FABSYN Synthesis Flow
CTGCTG
commarch.
commarch.
constraintSet (Ψ)
constraintSet (Ψ)
preprocesspreprocess
simple bus mapping
simple bus mapping
explore_paramsexplore_params
TCP met?
TCP met? mutate_topologymutate_topology
optimize_designoptimize_design
output synthesized communication archoutput synthesized
communication arch
IP library
IP library
Select unsatisfied TCP from Ω
Select unsatisfied TCP from Ω
Ω empty?Ω empty?
Run floorplannerand delay estimatorRun floorplanner
and delay estimator
Ω stillempty?Ω still
empty?
no
yes
no
yes
no
yes
Inputs Output
CTG or Communication Throughput Graphincorporates SoC IPs (nodes) and their interconnections (vertices)
TCP or Throughput Constraint Path is a CTG sub-graph representing constraint to be satisfied;Ω is a superset of all TCPs
Ψ or Communication Parameter Constraint Set is a discrete set of valid values for BA parameters, to ensure realistic output
Pasricha et al. [DAC 2005]

39
Luca Benini ARTIST2 / UNU IIST 2007
FABSYN Synthesis Flow Illustration
Pasricha et al. [DAC 2005]
Luca Benini ARTIST2 / UNU IIST 2007
Addressing Interconnect ScalabilityHigh-end industrial solutions:
Evolutionary path from shared busses
AMBA AXI
Protocol evolutionsAMBA AHB
AMBA AHB ML
Topology evolutions
ChallengesComplexity (e.g. 4-SHB + 2XBar, 75 actors): how to analyze and verify “spaghetti interconnects”?Scalability: bus is bandwidth-limited, Xbar is size-limitedPredictability: how to tie interconnects with floorplanning
AHB
AHB
AHB

40
Luca Benini ARTIST2 / UNU IIST 2007
The Network-on-Chip Paradigm
DSPNI
NIDRAM
switch
DMANI
CPU NI
NIAccelNI MPEG
switch
switch
switch
NoC
switch
switch
The “power of NoCs”:Clean separation at session layer
Cores issue end-to-end transactionsNetwork deals with transport, network, link, physical
Modularity at HW level: only2 building blocks
Network interfaceSwitch (router)
Physical design aware (floorplanglobal routing)
Scalability is supported from the ground up!
Luca Benini ARTIST2 / UNU IIST 2007
NoC Synthesis Project
SunFloor
TopologySynthesis
includes:FloorplannerNoC Router RTL
ArchitecturalSimulation
PlatformGeneration
Constraint graphComm graph
NoCArea models
Systemspecs
SystemCcode
NoCcomponent
libraryFPGA
Emulation
To fab
PlatformGeneration
(xpipes-Compiler)
Synthesis
Userobjectives:
power,hop delay
NoCPower models
Constraints:area, power,hop delay,wire length
IP Coremodels
Placement&Routing
Codesign,
Simulation
Application
Input trafficmodel
Area, power characterization
Started in 2002UNIBO, UNICA, Stanford, EPFLObjective: develop a complete EDA flow for NoC synthesis from application to P&R
Backend flow
Floorplanning specifications

41
Luca Benini ARTIST2 / UNU IIST 2007
The xpipes NoC
Packeting/unpacketingOCP 2.0 protocol to connect to IP coresSource routingDual Clock 2 Stage Pipeline
OCP OCP
OCP clkxpipes clk
OCP clk
packeting unpacketing
packetingunpacketing
initiator NI target NI
LUT
LUTpackets
request
response
Crossbar
AllocatorArbiter
Routing & Flow Control
Wormhole switchingRound-robin & fixed priority allocatorSupports ACK/NACK & STALL/GO flow control
ACK/NACK: Output buffered, 2 stagesSTALL/GO: Input buffered, 1 stage
Link pipelining fully supported
A soft macro library:
switch
xpipes switch(5x5 switch, 32b flit, 4-FIFO, 130nm)
909 MHz20 FO4 delay12.7 kgates (NAND2)0.087 mm2
35.2 uW/MHz (32mW@909MHz)
xpipes NI0.8 switch area
Luca Benini ARTIST2 / UNU IIST 2007
Backend Design Flow for Xpipes
xpipeslibrary
fabric instantiationxpipesCompiler
topologySystemC
trafficlogs
verification,power modelingMentor ModelSim
Synopsys PrimePower
powerfigures
trafficgenerators
architectural simulationcycle-accurate simulation platform
architecturalstatistics
performancefigures
areafigures
topologyspecs
fabric synthesisSynopsys Design Compiler
techlibrary
topologynetlist
place&routeCadence SoC Encounter &
Synopsys Astro
topologyfloorplan
HDL translationSystemC to Verilog
topologyHDL
Topologydesign
UnifiedSystemCfrontend

42
Luca Benini ARTIST2 / UNU IIST 2007
“High-level” Design Flow
a. Mesh b. Torus
Or, do I want a custom topology?
Automatically find topology, architectureMinimize area, power, latencySatisfying design constraints
Luca Benini ARTIST2 / UNU IIST 2007
SUNFLOOR & Xpipes Flow
SunFloor
TopologySynthesis
includes:FloorplannerNoC Router RTL
ArchitecturalSimulation
PlatformGeneration
Constraint graphComm graph
NoCArea models
Systemspecs
SystemCcode
NoCcomponent
libraryFPGA
Emulation
To fab
PlatformGeneration
(xpipes-Compiler)
Synthesis
Userobjectives:
power,hop delay
NoCPower models
Constraints:area, power,hop delay,wire length
IP Coremodels
Placement&Routing
Codesign,
Simulation
Application
Input trafficmodel
Area, power characterization
Floorplanning specifications
High-level design flow

43
Luca Benini ARTIST2 / UNU IIST 2007
Custom Topology & Mapping
ObjectivesDesign fully application-specific custom topologiesGenerate deadlock-free networks: both routing and message-level deadlocks are removedOptimize architectural parameters of the NoC (frequency, flit size), tuning based upon application requirements
Leverage accurate analytical models for area and power, back-annotated from layoutsIntegrated floorplanner to achieve design closurewhile also considering wiring complexity
Physical design awareness
Luca Benini ARTIST2 / UNU IIST 2007
Vary NoCarchitecturalparameters
frequency, data-width
Bandwidth, power consumption varies
SUNFLOOR Steps
Vary numberof switches
Which is better ? – Do not know !!

44
Luca Benini ARTIST2 / UNU IIST 2007
NP-Hard problem (single path multi-commodity flow)
Use fast & efficient heuristics
Vary numberof switches
Vary NoCarchitecturalparameters
frequency, data-width
SUNFLOOR Steps
Synthesize best topology
Luca Benini ARTIST2 / UNU IIST 2007
SUNFLOOR Steps
Vary NoCarchitecturalparameters
frequency, data-width
Synthesize best topology
Perform floorplan of design Calculate timing characteristics
If design constraintsmet, save solution
Choose most efficientsolution satisfying
all design constraints
Vary numberof switches

45
Luca Benini ARTIST2 / UNU IIST 2007
vld rld iqn
vprpad
smm
70
27
357
362
49
313
94500
353
300
16
Core graph
isn ups
313
idctarm
a-d
vpm
Synthesis Algorithm
Obtain min-cut partitions of core-graph
Cores in a partition share a switch
Find lower bound on switch sizes, switch power
Establish switch connectivity by routing flows
Account for constraints on # hops, deadlock avoidance, switch sizeMinimize power
Refer to Murali et al. ICCAD06 for full details
Luca Benini ARTIST2 / UNU IIST 2007
Processor-memory cluster
Case Study 1: Comparison AgainstHand-Mapped Topology
P-processors, M-private memories,
T-traffic generators, S-shared slaves
Hand-mapped topology SUNFLOOR custom topology
Bi-directional links
Bi-directional links
Uni-directional links
On our 30-core multimedia benchmark

46
Luca Benini ARTIST2 / UNU IIST 2007
Case Study 1: Results vs Hand-Mapped
Hand-mapped design:
• Topology: 5x3 mesh(15 switches)• Operating frequency:793 MHz (post-layout)• Power consumption:368 mW• Floorplan area:35.4 mm2
• Design time: weeks•0.13 μm technology
Hand-mapped design:
• Topology: 5x3 mesh(15 switches)• Operating frequency:793 MHz (post-layout)• Power consumption:368 mW• Floorplan area:35.4 mm2
• Design time: weeks•0.13 μm technology
SunFloor:
• Topology: custom(8 switches)• Operating frequency:793 MHz (post-layout)• Power consumption:277 mW (-25%)• Cell area:37 mm2 (+4%)• Design time: 4 hours design to layout•0.13 μm technology
SunFloor:
• Topology: custom(8 switches)• Operating frequency:793 MHz (post-layout)• Power consumption:277 mW (-25%)• Cell area:37 mm2 (+4%)• Design time: 4 hours design to layout•0.13 μm technology
Benchmark execution time comply with application requirements and are even 10% better on SunFloor topology.
constraint
Luca Benini ARTIST2 / UNU IIST 2007
1.152.002.00
20.5390.1738.60
CustomMesh
Opt-mesh
MWD(12 cores)
1.332.002.00
30.0095.9446.48
CustomMesh
Opt-mesh
VOPD(12 cores)
1.502.172.17
27.2496.8260.97
CustomMesh
Opt-mesh
MPEG4(12 cores)
1.672.582.58
79.64301.8136.1
CustomMesh
Opt-mesh
VPROC(42 cores)
Avg. nr. hopsPower(mW)TopologyApplication
Case Study 2: SUNFLOOR Vs Regular Topologies
On average, SunFloor custom topologies:
2.75x less power consumption
1.55x less hop delay
Despite large design space, maximum run time of 1 hour for VPROC

47
Luca Benini ARTIST2 / UNU IIST 2007
Looking Forward
Quality of service guarantees for critical trafficRun-time configurabilityRobustness w.r.t. to static/dynamic variations, errorsNetwork interfaces: interoperability, performance
Luca Benini ARTIST2 / UNU IIST 2007
Summary
MPSoC design technology is in fast evolutionSupport for functional design is reaching industrialmaturity
Virtual platformsIP reuse standardization
Support for analysis of non-functional properties isimmature
Even functional analysis is only simulation-basedSystem optimization is at research stage
Related Documents










![Ad Hoc Networks - user.it.uu.seuser.it.uu.se/~eding810/paper/Adhoc10.pdf · tocols are proposed for wireless ad hoc networks [7–10], but they are impractical for largescaledynamic](https://static.cupdf.com/doc/110x72/6053fa48c39fa31a246743ed/ad-hoc-networks-userituu-eding810paperadhoc10pdf-tocols-are-proposed-for.jpg)
