Parallel garbage collection with a block-structured heap Simon Marlow (Microsoft Research) Simon Peyton Jones (Microsoft Research) Roshan James (U. Indiana) Tim Harris (Microsoft Research)

Parallel garbage collection with a block-structured heap Simon Marlow (Microsoft Research) Simon Peyton Jones (Microsoft Research) Roshan James (U. Indiana)
Dec 28, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Parallel garbage collection with a block-structured
heapSimon Marlow (Microsoft Research)
Simon Peyton Jones (Microsoft Research)Roshan James (U. Indiana)
Tim Harris (Microsoft Research)

Setting the scene…
• We have an existing GC for Haskell– multi-generational– copying by default (optional mark/compact for
the old generation)• GC is a bottleneck for parallel execution: we
want to make the GC run in parallel on a multiprocessor to improve scaling.
• NB. parallel, not concurrent• A parallel GC can speed up even single-
threaded programs on a multiprocessor with no input from the programmer.
• Target: commodity multi-cores
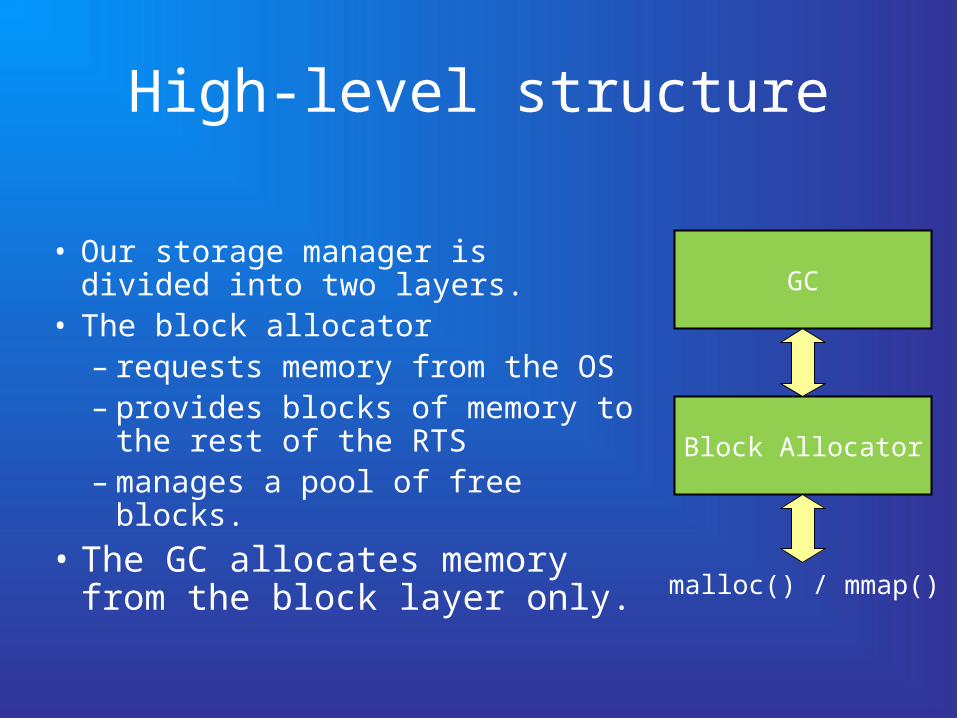
High-level structure
• Our storage manager is divided into two layers.
• The block allocator – requests memory from the OS– provides blocks of memory to
the rest of the RTS– manages a pool of free blocks.
• The GC allocates memory from the block layer only.
GC
Block Allocator
malloc() / mmap()

Blocks of memory
• Memory is managed in units of the fixed block size (currently 4k).
• Blocks can be allocated singly, or in contiguous groups to accomodate larger objects.
• Blocks can be linked together into lists to form areas

Why divide memory into blocks?
• Flexibility, Portability
1.The storage manager needs to track multiple regions (e.g. generations) which may grow and shrink over time. – contiguous memory would be problematic: how much
space do we allocate to each one, so that they don’t grow into each other?
– Address space is limited.– With linked lists of blocks, we can grow or shrink a
region whenever we like by adding/removing blocks.2.managing large objects is easier: each gets its
own block group, and we can link large objects onto lists, so no need to copy the object to move it.– some wastage due to slop (<1%)

More advantages of blocks
3. Portable: all we require from the OS is a way to allocate memory, there are no dependencies on address-space layout.
4. Memory can be recycled quickly: cache-friendly
5. Sometimes we need to allocate when it is inconvenient to GC: we can always grab another block.
6. A “useful granularity”– useful for performing occasional checks during
execution (e.g. context switching)– for dividing up the work when parallelising GC
(later...)
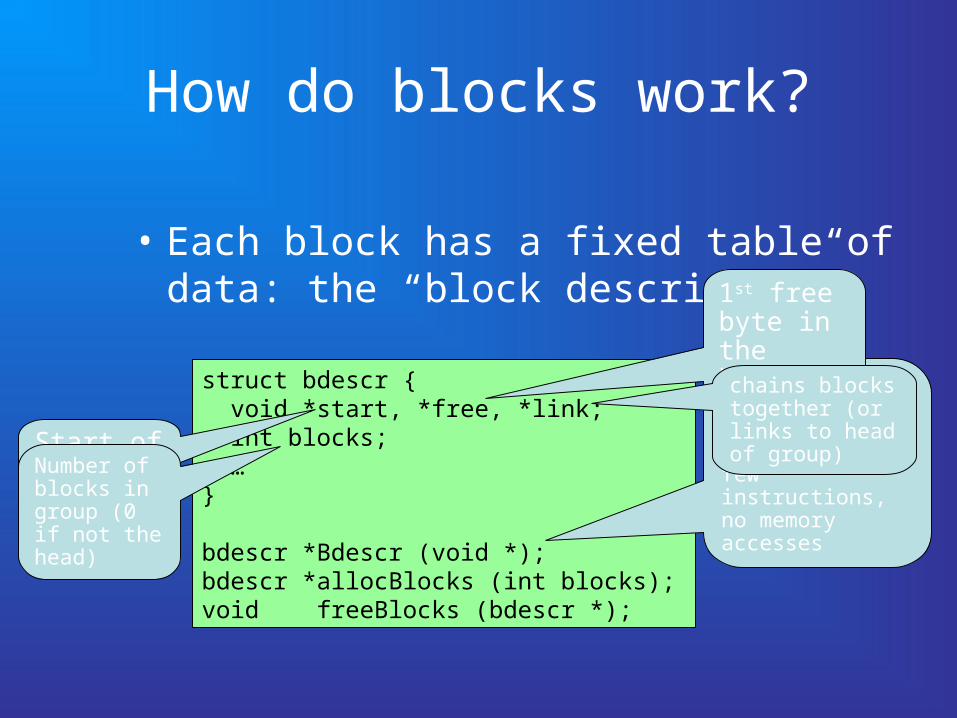
How do blocks work?
• Each block has a fixed table of data: the “block descriptor”.
struct bdescr { void *start, *free, *link; int blocks; …}
bdescr *Bdescr (void *);bdescr *allocBlocks (int blocks);void freeBlocks (bdescr *);
Bdescr() maps address to block descriptor in a few instructions, no memory accesses
Start of the block
1st free byte in the blockchains blocks together (or links to head of group)Number of
blocks in group (0 if not the head)

Where do block descriptors live?
• Choice 1: at the start of a block. Bdescr(p) is one instruction: p & 0xfffff000 Bad for cache & TLB.
• We often traverse block descriptors: if they are scattered all over memory this thrashes the TLB.
Contiguous multi-block groups can only have a descriptor for the first block.
A block contains “4k minus a bit” space for data (awkward)

Choice 2
• Block descriptors are grouped together, and can be found by an address calculation. Bdescr(p) is ~6 instructions (next
slide…) We can keep block descriptors
together, better for cache/TLB Contiguous block groups are easier:
all blocks in the group have descriptors.
Blocks contain a full 4k of data
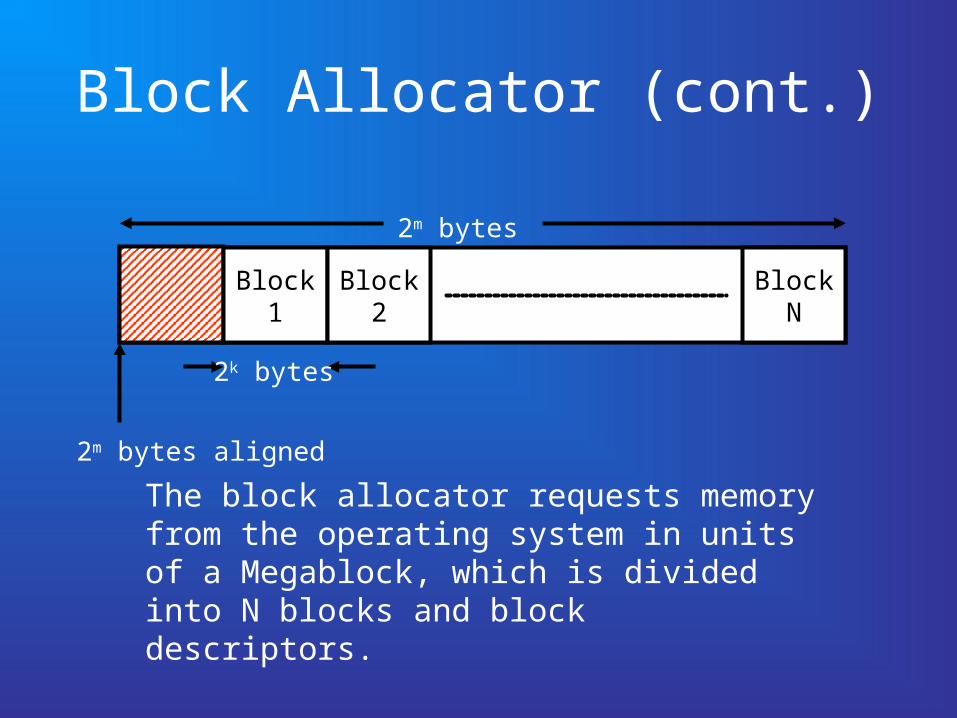
Block Allocator (cont.)
2m bytes aligned
Block1
2k bytes
Block2
BlockN
The block allocator requests memory from the operating system in units of a Megablock, which is divided into N blocks and block descriptors.
2m bytes
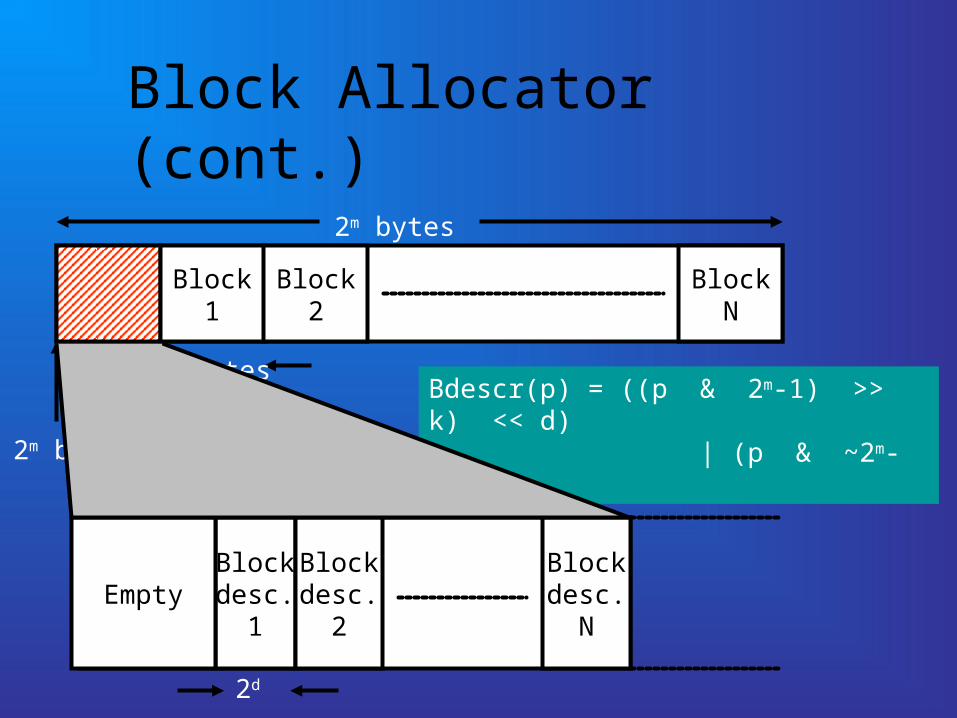
Block Allocator (cont.)
2m bytes aligned
2m bytes
Block1
2k bytes
Block2
BlockN
Blockdesc.
1
Blockdesc.
2
Blockdesc.
NEmpty
Bdescr(p) = ((p & 2m-1) >> k) << d) | (p & ~2m-1)
2d

Parallel GC
• First we consider how to parallelise 2-space copying GC, and then extend this to generational GC.
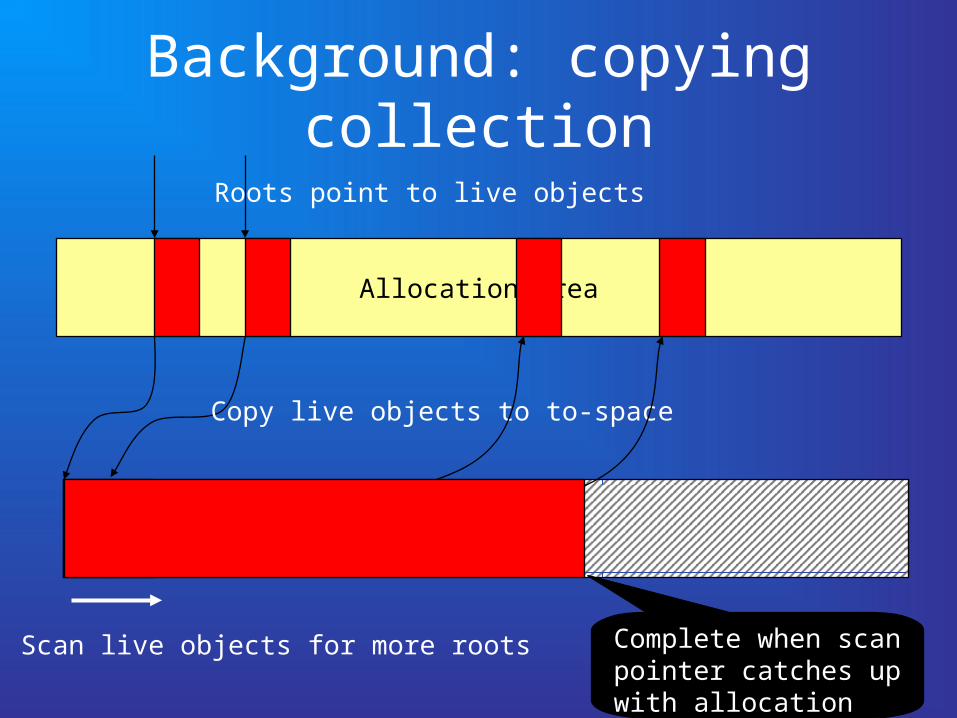
Background: copying collection
Allocation area
To-space
Roots point to live objects
Copy live objects to to-space
Scan live objects for more roots Complete when scan pointer catches up with allocation pointer.

How can we parallelise copying GC?
• Basically, we want each CPU to copy and scan different objects.
• The main problem is finding an effective way to partition the problem, so we can keep all CPUs busy all the time (load balancing).
• Static partitioning (eg. partition the heap by address) is not good:– live data might not be evenly distributed,
leading to poor load balancing– Need synchronisation when pointers cross
partition boundaries

Load balancing• So we need dynamic load-balancing for GC.
– the pending set is the set of objects copied but not yet scanned.
– Each CPU:
– where
– (Need synchronisation to prevent two threads copying the same object – later)
scan(p) { for each object q pointed to by p { if q has not been copied { copy q add q to the pending set } }}
while (pending set non-empty) { remove an object p from the pending set scan(p)}

The Pending Set
– Now the problem is reduced to finding a good representation for the pending set.
– Operations on the pending set are in the inner loop, so heavyweight synchronisation would be very expensive.
– In standard copying GC the pending set is represented implicitly (and cheaply!) by to-space. Hence any explicit representation will incur an overhead compared to single-threaded GC, and eat into any parallel speedup.

Previous solutions• per-CPU work-stealing queues (Flood et.
al. (2001)).– good work partitioning, but– some administrative overhead (quantity
unknown)– needs clever lock-free data structures– some strategy for overflow (GC can’t use
arbitrary extra memory!)• Dividing the pending set into chunks
(Imai/Tick (1993), others).– coarser granularity reduces synchronisation
overhead– less effective load-balancing, especially if
the chunk size is too high.

How blocks help
• Since to-space is already a list of blocks, it is a natural representation for a chunked pending set!– No need for a separate pending set
representation, no extra admin overhead relative to single threaed GC.
– Larger blocks => lower synchronisation overhead
– Smaller blocks => better load balancing

But what if…
• … the pending set isn’t large enough to fill a block? E.g. If the heap consists of a single linked list of integers, then the scan pointer will always be close to the allocation pointer, we will never generate a full block of work.
• There may be little available parallelism in the heap structure anyway.
• But with e.g. 2 linked lists, we would still not be able to parallelise on two cores, because the scan pointer will only be 2 words behind the allocation pointer.
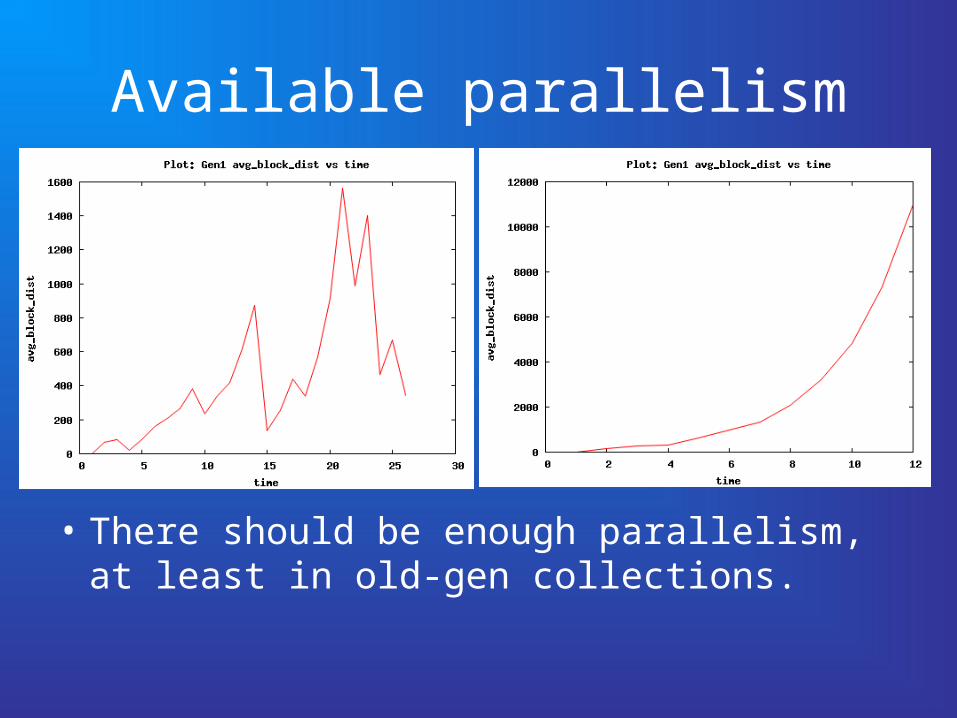
Available parallelism
• There should be enough parallelism, at least in old-gen collections.
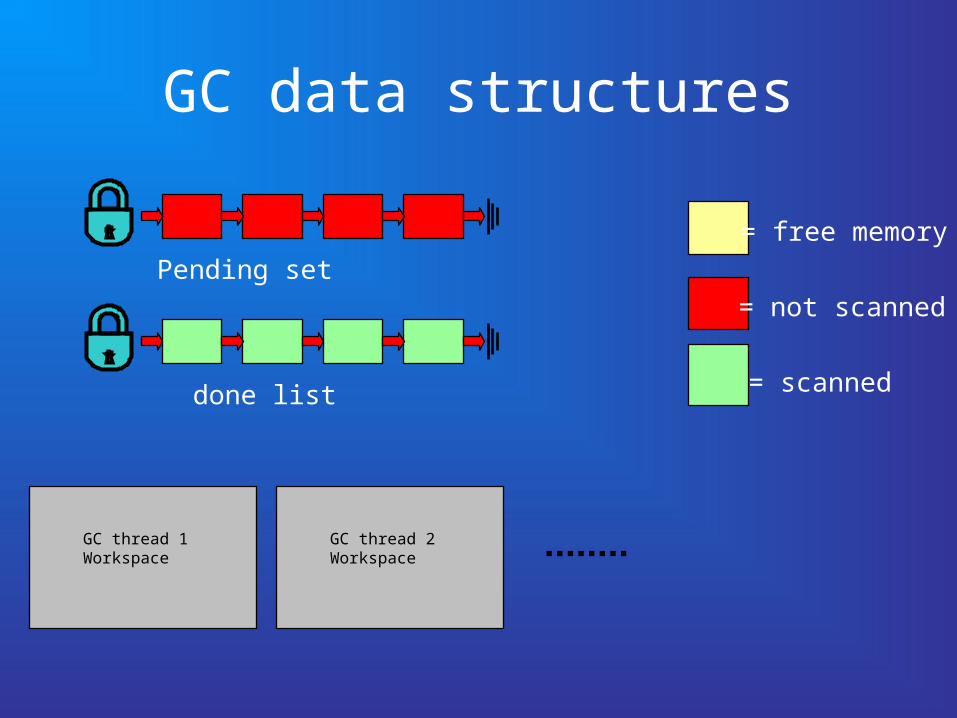
GC data structures
Pending set
done list
= free memory
= not scanned
= scanned
GC thread 1Workspace
GC thread 2Workspace

Inside a workspace…
• Objects are copied into the Alloc block (per-thread allocation!)
• Loop:– Grab a block to be scanned from the pending set– Scan it– Push it back to the “done” list– When an Alloc block becomes full, move it to the
pending set, grab an empty block
Alloc blockScan block
Scan pointer Alloc pointer
= free memory
= not scanned
= scanned

Inside a workspace…
• When the pending set is empty– Make the Scan block = the Alloc block– Scan until complete– Look for more full blocks…– Note that we may now have scanned part of
the Alloc block, so we need to remember what portion has been scanned. (full details of the algorithm are in the paper).
Alloc blockScan block
Scan pointer Alloc pointer
= free memory
= not scanned
= scanned

Termination
• Keep a global counter of running threads• When a thread finds no work to do, it
decrements the count of running threads• If it finds the count = 0, all the work is
done; stop.• Poll for work: if there is work to do,
increment the counter and continue (don’t remove the work from the queue yet).

When work is scarce
• We found that often the pending set is small or empty (despite earlier measurements), leading to low parallelism.
• The only solution is to export smaller chunks of work to the pending set.
• We use a dynamic chunk size: when the pending set is low, we export smaller chunks.
• smaller chunks leads to a fragmentation problem: we want to fill up the rest of the block later, so we have to keep track of these partially-full blocks in per-thread lists.
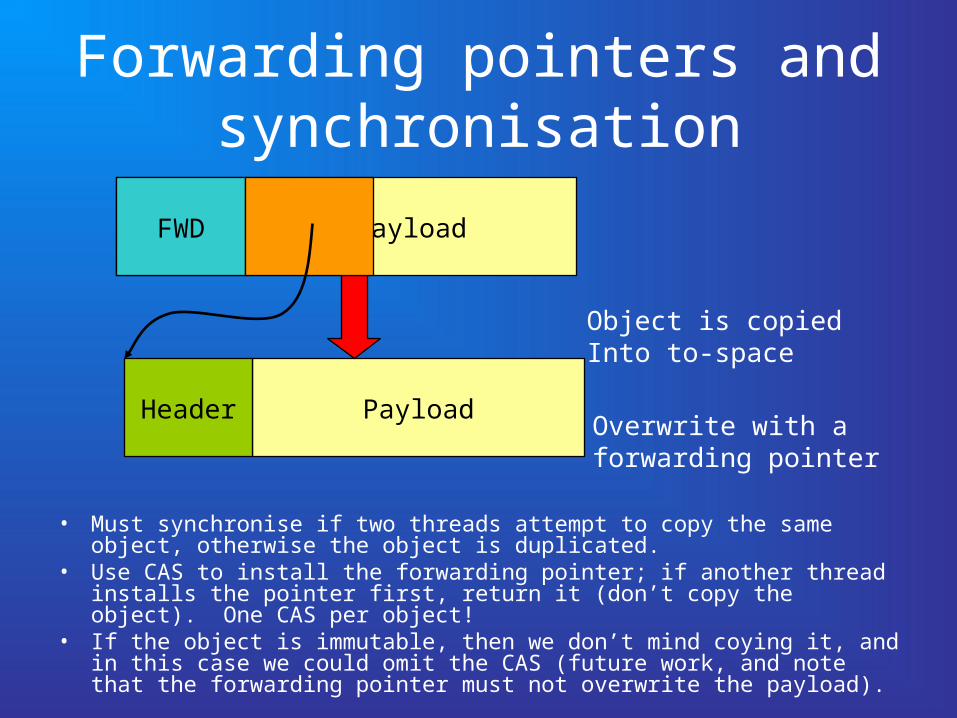
Forwarding pointers and synchronisation
• Must synchronise if two threads attempt to copy the same object, otherwise the object is duplicated.
• Use CAS to install the forwarding pointer; if another thread installs the pointer first, return it (don’t copy the object). One CAS per object!
• If the object is immutable, then we don’t mind coying it, and in this case we could omit the CAS (future work, and note that the forwarding pointer must not overwrite the payload).
PayloadHeader
PayloadHeader
Object is copied Into to-space
FWD
Overwrite with aforwarding pointer

Overhead due to atomic evacuation

Parallel Generational-copying GC
• Fairly straightforward generalisation of parallel copying GC
• Three complications:– maintaining the remembered sets– deciding which pending set to take work
from– tenuring policy
• see paper for the details
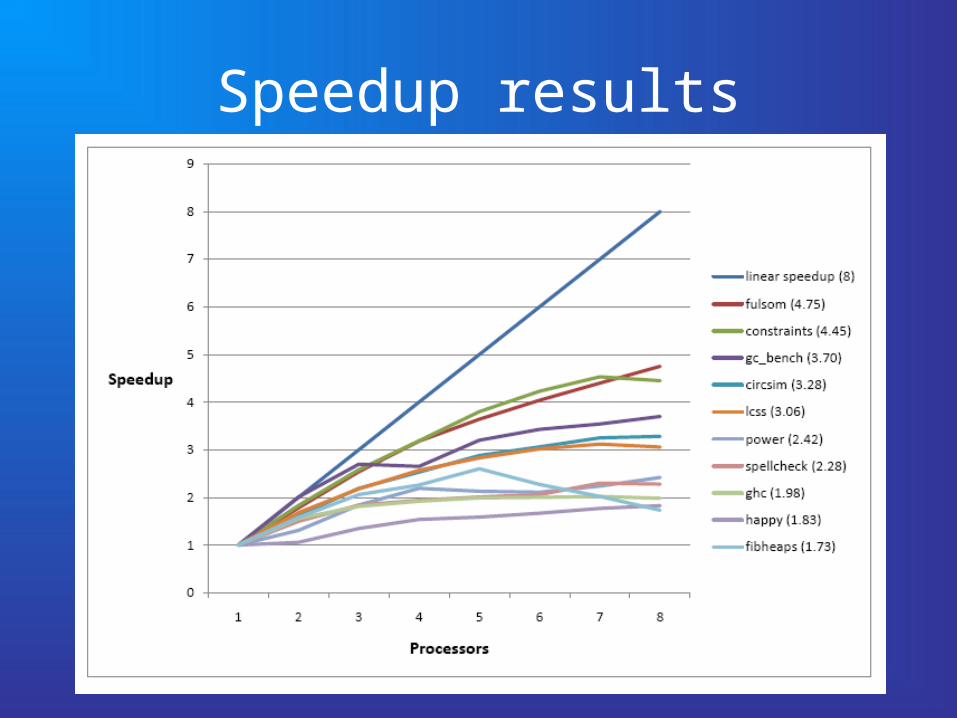
Speedup results

Measuring load balancing
• Ctot is the total copied by all threads
• Cmax is the maximum copied by any thread
• Work balance factor
• Perfect balance = N, perfect imbalance = 1.• balance factor = maximum possible
speedup given the distribution of work across CPUs (speedup might be lower for other reasons).
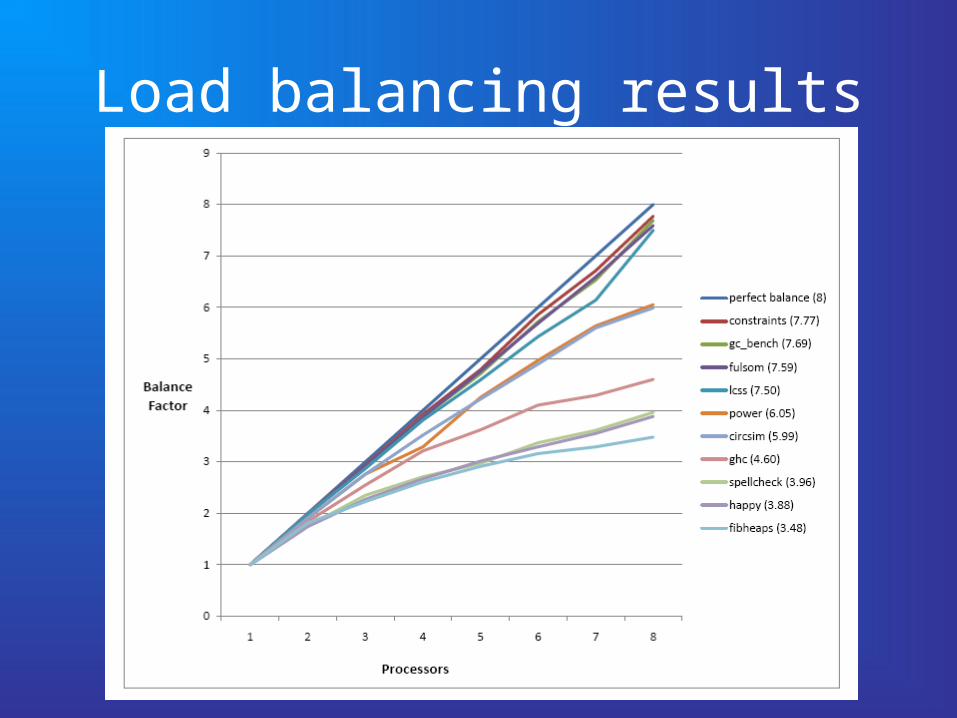
Load balancing results

Status
• Will be available in GHC 6.10 (autumn 2008)
• Multi-threaded GC will usually be a win on 2+ cores, although requires increasing the heap size to get the most benefit: parallelising small GCs doesn’t work so well.

Further work• Investigate/improve load-balancing• Avoid locking for immutable objects
– Contention is very low– We might get a tiny amount of duplication per GC
• Independent minor GCs.– Hard to parallelise minor GC: too quick, not enough
parallelism– Stopping the world for minor GC is a severe bottleneck in a
program running on multiple CPUs.– So do per-CPU independent minor GCs.– Main techincal problem: either track or prevent inter-minor-
generation pointers. (eg. Doligez/Leroy(1993) for ML, Steensgaard(2001)).
• Concurrent marking, with simple sweep: blocks with no live objects can be freed immediately, compact or copy occasionally to recover fragmentation.
• Parallelise mark/compact too– Blocks make parallelising compaction easier: just statically
partition the list of marked heap blocks and compact each segment, concatenate the result.

Optimisations…
• There is a long list of tweaks and optimisations that we tried, some of which helped, some didn’t.– Move block descriptors to the beginning of the
block: bad cache/TLB effects.– Prefetching: no joy, too fragile, and recent
CPUs do automatic prefetching– Should the pending block set be FIFO or LIFO?
or something else?– Some objects don’t need to be scanned, copy
them to a separate non-scanned area (not worthwhile)

A war story…• This GC was first implemented by Roshan
James, in the summer of 2006.– measurements showed negative speedup
• I re-implemented it in 2007, the new implementation also showed negative speedup, despite having good load-balancing.
• The cause of the bottleneck: – after copying an object, a pointer in the block
descriptor was updated. Adjacent block descriptors sometimes share a cache line, so multiple threads were writing to the same cache line => bad.
– It took multiple man-weeks and 3 profiling tools to find the problem.
– Solution: cache the pointer in thread-local storage.
Related Documents











