1 p2p, Fall 06 Querying the Internet with PIER (PIER = Peer-to-peer Information Exchange and Retrieval) VLDB 2003 Ryan Huebsch, Joe Hellerstein, Nick Lanham, Boon Thau Loo, Timothy Roscoe, Scott Shenker, Ion Stoica

P2p, Fall 06 1 Querying the Internet with PIER (PIER = Peer-to-peer Information Exchange and Retrieval) VLDB 2003 Ryan Huebsch, Joe Hellerstein, Nick Lanham,
Dec 22, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1p2p, Fall 06
Querying the Internet with PIER(PIER = Peer-to-peer Information Exchange and Retrieval)
VLDB 2003
Ryan Huebsch, Joe Hellerstein, Nick Lanham, Boon Thau Loo, Timothy Roscoe, Scott Shenker, Ion Stoica

2p2p, Fall 06
What is PIER?
A query engine that scales up to thousands of participating nodes
= relational queries + DHT
Built on top of a DHT

3p2p, Fall 06
Motivation, Why?
In situ distributed querying (as opposed to warehousing)
Network monitoring
network intrusion detection: sharing and querying fingerprint information
Fingerprints (sequences of port accesses, port numbers, packet contents etc)
Where: network servers: mail servers, web servers, remote shells) & applications (mail clients, web browsers)
Publish the fingerprint of an attack in PIER for a short time
Query it – similar reports, statistics, intrusions from the same domain, etc

4p2p, Fall 06
Motivation, Why?
Besides security:
network statistics (eg bandwidth utilization, etc)
In-network processing – streams
Text search
Deep web crawling

5p2p, Fall 06
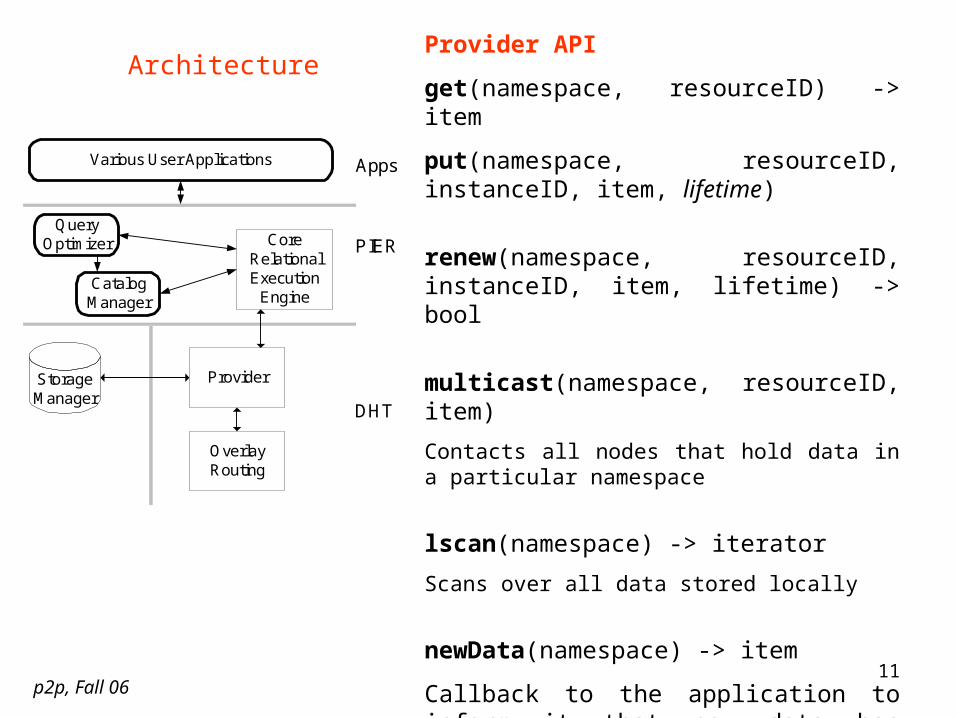
Architecture
DHT is divided into 3 modules: Routing Layer Storage Manager Provider
Goal is to make each simple and replaceable
CoreRelationalExecution
Engine
ProviderStorageManager
OverlayRouting
CatalogManager
QueryOptimizer
Various User Applications
PIER
DHT
Apps
An instance of each DHT and PIER component runs at each participating node
PIER is build on top of a DHT (in the paper, the DHT is CAN with d = 4)
The DHT is used both for indexing and storage

6p2p, Fall 06
Architecture
Routing Layer Maps a key to the IP address of the node currently responsible for it
API
lookup(key) -> ippaddr
join(landmark)
leave()
LocationMapChange()Callback used to notify higher levels asynchronously when a set of keywords mapped locally has changed
CoreRelationalExecution
Engine
ProviderStorageManager
OverlayRouting
CatalogManager
QueryOptimizer
Various User Applications
PIER
DHT
Apps

7p2p, Fall 06
Architecture
Storage Manager
Temporary storage of DHT-based data
Local database at each DHT node
a simple in memory storage-system or a disk-based package like Berkeley DB
In this paper, a main memory storage manager
API
store(key, item)
retrieve(key) -> item
remove(key)
CoreRelationalExecution
Engine
ProviderStorageManager
OverlayRouting
CatalogManager
QueryOptimizer
Various User Applications
PIER
DHT
Apps

8p2p, Fall 06
Architecture
Provider
What PIER sees
What are the data items (relations) handled by PIER?
CoreRelationalExecution
Engine
ProviderStorageManager
OverlayRouting
CatalogManager
QueryOptimizer
Various User Applications
PIER
DHT
Apps

9p2p, Fall 06
Naming Scheme
Each object:
(namespace, resourceID, instanceID)
DHT key: hash on namespace, resourceID
Namespace: group, application the object belongs to
In PIER, the Relation Name
No need to be predefined, can be created implicitly when the first item is put and destroyed when the last item expires
ResourceID: some semantic meaning
In PIER, the value of the primary key for base tuples
InstanceID: an integer randomly assigned by the user application
Used by the storage manager to separate items (when they are not stored based on the primary key)
What are the data items (relations) handled by PIER?

10p2p, Fall 06
Soft State
Each object associated with a lifetime: how long should the DHT store the object
To extend it, must use periodical RENEW calls
11p2p, Fall 06
Architecture
CoreRelationalExecution
Engine
ProviderStorageManager
OverlayRouting
CatalogManager
QueryOptimizer
Various User Applications
PIER
DHT
Apps
Provider API
get(namespace, resourceID) -> item
put(namespace, resourceID, instanceID, item, lifetime)
renew(namespace, resourceID, instanceID, item, lifetime) -> bool
multicast(namespace, resourceID, item)
Contacts all nodes that hold data in a particular namespace
lscan(namespace) -> iterator
Scans over all data stored locally
newData(namespace) -> item
Callback to the application to inform it that new data has arrived in a particular namespace

12p2p, Fall 06
Architecture
PIER currently only one primary module: the relational execution engine
Executes a pre-optimized query plan
Traditional DBs use an optimizer + catalog to take SQL and generate the query plan, those are “just” add-ons to PIER
CoreRelationalExecution
Engine
ProviderStorageManager
OverlayRouting
CatalogManager
QueryOptimizer
Various User Applications
PIER
DHT
Apps

13p2p, Fall 06
Architecture
Query plan is a box-and-arrow description of how to connect basic operators together
selection, projection, join, group-by/aggregation, and some DHT specific operators such as rehash
No iterator model
Instead, operators produced results as quickly as possible and enqueue the data for the next operator

14p2p, Fall 06
Joins: The Core of Query Processing
R Join S, relations R and S stored in separate namespaces NR and NS
How:– Get tuples that have the same value for a particular attribute(s) (the join
attribute(s)) to the same site, then append tuples together
Why Joins? A relational join can be used to calculate:
– The intersection of two sets– Correlate information– Find matching data
• Algorithms come from existing database literature, minor adaptations to use DHT.

15p2p, Fall 06
Symmetric Hash Join (SHJ)
• Algorithm for each site– (Scan – Retrieve local data) Use two lscan calls to retrieve all
data stored locally from the source tables
– (Rehash based on the join attribute) put a copy of each eligible tuple with the hash key based on the value of the join attribute (new unique namespace NQ)
– (Listen) use newData and get to NQ to see the rehashed tuples
– (Compute) Run standard one-site join algorithm on the tuples as they arrive
• Scan/Rehash steps must be run on all sites that store source data• Listen/Compute steps can be run on fewer nodes by choosing the
hash key differently

16p2p, Fall 06
Fetch Matches (FM)
• Algorithm for each site– (Scan) Use lscan to retrieve all data from ONE table
NR
– (Get) Based on the value for the join attribute, for each R tuple issue a get for the possible matching tuples from the S table
• Big picture:– SHJ is put based– FM is get based
When one of the tables, say S is already hashed on the join attribute

17p2p, Fall 06
Joins: Additional Strategies
• Symmetric Semi-Join– Locally at each site, run a SHJ on the source data projected to only
have the hash key and join attributes.– Use the results of this mini-join as source for two FM joins to retrieve
the other attributes for tuples that are likely to be in the answer set• Bloom Filters
– Create Bloom filters for each local R and S data and publish them at a temporary DHT, OR all local R and multicast to nodes hosting S – use lscan but rehash only those that match
• Big Picture:– Tradeoff bandwidth (extra rehashing) for latency (time to exchange
filters)

18p2p, Fall 06
Naïve Group-By/Aggregation
• A group-by/aggregation can be used to calculate:
– Split data into groups based on value – Max, Min, Sum, Count, etc.
• Goal:– Get tuples that have the same value for a particular
attribute(s) (group-by attribute(s)) at the same site, then summarize data (aggregation).

19p2p, Fall 06
Naïve Group-By/Aggregation
• At each site– (Scan) lscan the source table
• Determine group tuple belongs in• Add tuple’s data to that group’s partial summary
– (Rehash) for each group represented at the site, rehash the summary tuple with hash key based on group-by attribute
– (Combine) use newData to get partial summaries, combine and produce final result after specified time, number of partial results, or rate of input
• Hierarchical Aggregation: Can add multiple layers of rehash/combine to reduce fan-in.– Subdivide groups in subgroups by randomly appending a
number to the group’s key

20p2p, Fall 06
Naïve Group-By/Aggregation
Sources
Root
Application Overlay
Sources
Root
…
Each message may take multiple hops
Each levelfewer nodes participate

21p2p, Fall 06
Codebase
• Approximately 17,600 lines of NCSS Java Code
• Same code (overlay components/pier) run on the simulator or over a real network without changes
• Runs simple simulations with up to 10k nodes– Limiting factor: 2GB addressable memory for the JVM (in Linux)
• Runs on Millennium and Planet Lab up to 64 nodes– Limiting factor: Available/working nodes & setup time
• Code:– Basic implementations of Chord and CAN– Selection, projection, joins (4 methods), and naïve aggregation.– Non-continuous queries

22p2p, Fall 06
Seems to scaleSimulations of 1 SHJ Join
Warehousing
Full Parallelization

23p2p, Fall 06
Some real-world results1 SHJ Join on Millennium Cluster

24p2p, Fall 06
Other applications
Recursive queries on network graphsset of nodes reachable within k hops of each node
Hierarchical aggregation
Range Predicateslocality-preserving hash functions
Related Documents











