Overcoming Chance Agreement in Classification Tree Modeling: Predictor Variables, Training Data, and Spatial Autocorrelation Considerations Southwest Regional GAP Project Arizona, Colorado, Nevada, New Mexico, Utah 2004, Las Vegas, Nevada: Transdisciplinary Challenges in Landscape Eric Waller Colorado Division of Wildlife

Overcoming Chance Agreement in Classification Tree Modeling: Predictor Variables, Training Data, and Spatial Autocorrelation Considerations Southwest Regional.
Dec 14, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Overcoming Chance Agreement in Classification Tree Modeling: Predictor Variables, Training Data, and
Spatial Autocorrelation Considerations
Southwest Regional GAP ProjectArizona, Colorado, Nevada, New Mexico, Utah
US-IALE 2004, Las Vegas, Nevada: Transdisciplinary Challenges in Landscape Ecology
Eric Waller
Colorado Division of Wildlife

SWReGAP Approach• Land Cover Mapping:
Classification Trees
– Satellite Image Classification?
– Ecological Modeling?
– Hybrid? (Be wary of ancillary variables!)
Hybrid Implementation
– Iterative: Ecological modeling within spectral (NLCD) strata?
– Single Model: “Kitchen Sink” approach?• Captures nuances / avoids error in spectral strata

Classification Trees
“Need piles of data”

Pseudoreplication • Pseudoreplication (multiple sampling within a polygon)
- Recommended by EROS Data Center (EDC)

Pseudoreplication: Pros and Cons
Exacerbates overfitting?
– Classification tree strategies• Boosting, Cross-validation / pruning
– Rely on independent data– Pseudoreplication = Non-independent data
Benefits of additional data?
- Swamp anomalous data

Autocorrelation
• Satellite imagery?
• Related to land cover?
• DEM-derived variables?
• When combined with pseudoreplication, the explanatory power of those predictor variables is inflated.– Even advanced classification tree techniques will be fooled.

Chance Agreement
Autocorrelation in predictor variables that lack strong explanatory power, when combined with pseudoreplication and a lack of sampling of the range of classes for a given value or combination of those predictor variables, leads to repeated chance agreement between the "bad" predictor variables and the land cover that fools the classification tree model.

Sampling- Only one class for a given slope/aspect combination?
• Need to sample the range of classes (e.g. ponderosa pine, mountain mahogany, etc.) that occur for any particular combination of predictor variables
• Limit predictor variables used in modeling (for those not strongly correlated with land cover)
Slope
Aspect
Mountain mahogany
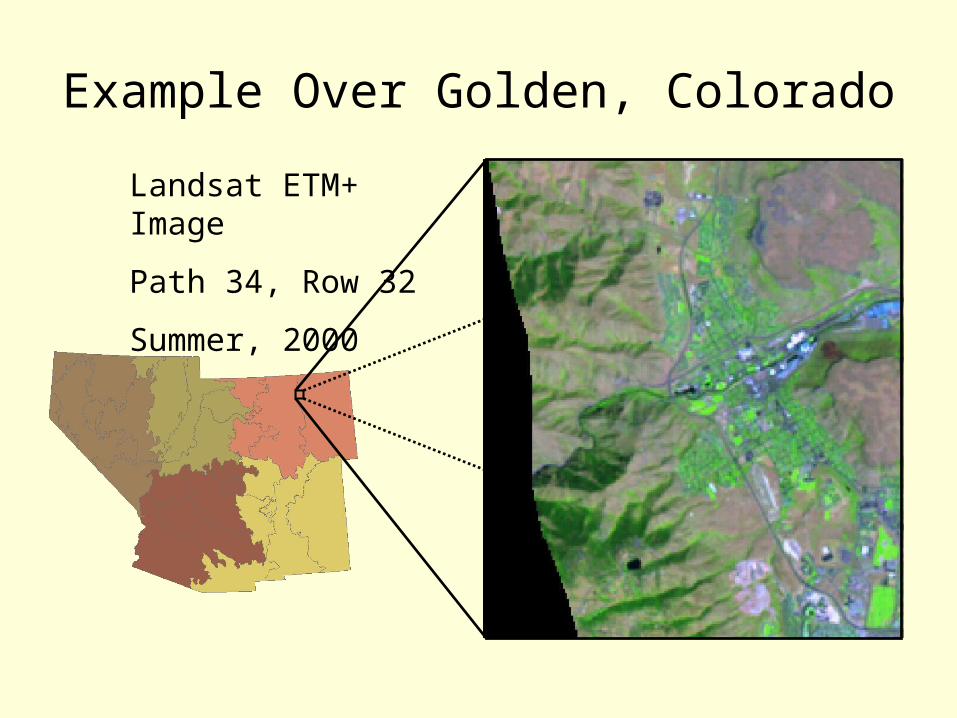
Example Over Golden, Colorado
Landsat ETM+ Image
Path 34, Row 32
Summer, 2000

DEM and DEM-Derived Variables
Elevation
autocorrelated
Slope
autocorrelated
Aspect
autocorrelated
Landform
autocorrelated

Classification Comparison
Water
Mining
Urban
Agriculture
Residential
Wooded Riparian
Mixed Conifer
Ponderosa Pine
Foothill Shrub
Foothill Grass
Invasive Grass
Classification With DEM-Derived Variables
Classification Without DEM-Derived Variables

Matrix Overlay – Aerial Photography
- A matrix can be used to highlight areas of disagreement.
- Air photos can be used to resolve discrepancies.

Conclusions
• This presentation demonstrated a method for dealing with problems associated with using DEM-derived variables in classification tree modeling.
• The approach does not guarantee improvement upon a more spectrally derived land cover product.
• Future efforts may want to establish a sampling strategy that ensures, a priori, that training data represent the range of classes across landscape variability, especially if DEM-derived variables are to be used.
Related Documents











