IT 13 016 Examensarbete 30 hp Mars 2013 Optimizing Total Migration Time in Virtual Machine Live Migration Erik Gustafsson Institutionen för informationsteknologi Department of Information Technology

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

IT 13 016
Examensarbete 30 hpMars 2013
Optimizing Total Migration Time in Virtual Machine Live Migration
Erik Gustafsson
Institutionen för informationsteknologiDepartment of Information Technology


Teknisk- naturvetenskaplig fakultet UTH-enheten Besöksadress: Ångströmlaboratoriet Lägerhyddsvägen 1 Hus 4, Plan 0 Postadress: Box 536 751 21 Uppsala Telefon: 018 – 471 30 03 Telefax: 018 – 471 30 00 Hemsida: http://www.teknat.uu.se/student
Abstract
Optimizing Total Migration Time in Virtual MachineLive Migration
Erik Gustafsson
The ability to migrate a virtual machine (VM) from one physical host to another isimportant in a number of cases such as power management, on-linemaintenance, and load-balancing. The amount of memory used in VMs have beensteadily increasing up to several gigabytes. Consequently, the time to migratemachines, the total migration time, has been increasing. The aim of this thesis is toreduce the total migration time.
Previous work aimed at reducing the amount of time and disk space required forsaving checkpoint images of virtual machines by excluding data from the memory thatis duplicated on the disk of the VM. Other work aimed at reducing the time torestore a VM from a checkpoint by only loading a subset of data before resuming theVM and marking the other memory as invalid. These techniques have been adaptedand applied to virtual machine live migration to reduce the total migration time. Theimplemented technique excludes sending duplicate data that exists on disk andresumes the VM before all memory has been loaded.
The proposed technique has been implemented for fully virtualized guests in Xen 4.1.The results of research conducted with a number of benchmarks demonstrate thatthere is an average 44% reduction of the total migration time.
Tryckt av: Reprocentralen ITCIT 13 016Examinator: Ivan ChristoffÄmnesgranskare: Philipp RümmerHandledare: Bernhard Egger


Acknowledgements
I would sincerely like to thank Professor Bernhard Egger at Seoul National Uni-versity helping to supervise me during this thesis.
I would also like to thank Professor Philipp Ruemmer at Uppsala University forreviewing my thesis.
I would also like to dedicate this thesis to my lovingly special someone, Alek-sandra Oletic.
i

Contents
Acknowledgements i
Contents ii
List of Figures iv
Acronyms v
1 Introduction 11.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Live Migration . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.3 Motivation and Problem Definition . . . . . . . . . . . . . . . . . 21.4 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.5 Outline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Virtual Machine Monitors, Xen, and Memory Management 42.1 Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Paravirtualization . . . . . . . . . . . . . . . . . . . . . . . . . . 52.3 Hardware Assisted Virtualization . . . . . . . . . . . . . . . . . . 52.4 Memory Management and Page Tables . . . . . . . . . . . . . . . 62.5 The Page Cache . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Related Work 73.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.2 Performance Measurements . . . . . . . . . . . . . . . . . . . . . 73.3 Live Migration Methods and Techniques . . . . . . . . . . . . . . 8
3.3.1 Iterative Pre-Copy . . . . . . . . . . . . . . . . . . . . . . 83.3.2 Memory Compression of Pre-Copy . . . . . . . . . . . . . 83.3.3 Post-Copy . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.3.4 System Trace and Replay . . . . . . . . . . . . . . . . . . 93.3.5 SonicMigration with Paravirtualized Guests . . . . . . . . 103.3.6 Discussion of Live Migration Techniques . . . . . . . . . . 10
3.4 Checkpoint Methods and Techniques . . . . . . . . . . . . . . . . 113.4.1 Efficiently Checkpointing a Virtual Machine . . . . . . . . 11
ii

3.4.2 Fast Restore of Checkpointed Memory using Working SetEstimation . . . . . . . . . . . . . . . . . . . . . . . . . . 12
4 Proposed Solution to Optimize Total Migration Time 134.1 Page Cache Elimination . . . . . . . . . . . . . . . . . . . . . . . 134.2 Page Cache Data Loaded at the Destination Host . . . . . . . . . 154.3 Maintaining Consistency . . . . . . . . . . . . . . . . . . . . . . . 17
5 Implementation Details 205.1 Live Migration . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205.2 Pre-fetch Restore . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2.1 The Page Fault Handler . . . . . . . . . . . . . . . . . . . 205.2.2 Intercepting I/O to Maintain Consistency . . . . . . . . . 215.2.3 Optimizations . . . . . . . . . . . . . . . . . . . . . . . . . 22
6 Results 246.1 Experimental Setup . . . . . . . . . . . . . . . . . . . . . . . . . 246.2 Results . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 256.3 Comparison with Other Methods . . . . . . . . . . . . . . . . . . 32
6.3.1 Memory Compression . . . . . . . . . . . . . . . . . . . . 326.3.2 Post-Copy . . . . . . . . . . . . . . . . . . . . . . . . . . . 326.3.3 Trace and Replay . . . . . . . . . . . . . . . . . . . . . . . 326.3.4 SonicMigration with Paravirtualized Guests . . . . . . . . 33
7 Conclusion and Future Work 347.1 Conclusions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 347.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
Bibliography 36
iii

List of Figures
2.1 Structure of Xen . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
4.1 Network Topology . . . . . . . . . . . . . . . . . . . . . . . . . . 134.2 Time-line Overview . . . . . . . . . . . . . . . . . . . . . . . . . . 154.3 Simplified Architecture . . . . . . . . . . . . . . . . . . . . . . . . 164.4 Violation cases . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
5.1 Execution Trace over the Sector Accessed . . . . . . . . . . . . . 23
6.1 Total migration time normalized to unmodified Xen . . . . . . . 266.2 Downtime normalized to unmodified Xen . . . . . . . . . . . . . 266.3 Total data transferred . . . . . . . . . . . . . . . . . . . . . . . . 286.4 Data sent over the network . . . . . . . . . . . . . . . . . . . . . 296.5 Performance degradation normalized to unmodified Xen . . . . . 30
iv

Acronyms
dom0 domain 0.
domU user domain.
EPT Extended Page Tables.
HVM hardware virtual machine.
MFN machine frame number.
MMU memory management unit.
NAS Network Attached Storage.
NPT Nested Page Tables.
PFN page frame number.
PTE page table entry.
SPT shadow page table.
SSD solid-state drive.
VCPU virtual CPU.
VM virtual machine.
v

1 Introduction
1.1 Overview
In recent years, server virtualization has seen a steady increase of attention andpopularity due to a multitude of factors. Virtualization [7] is the principle ofproviding a virtual interface for hardware. A virtual interface can create inde-pendence from the physical hardware by providing a layer of abstraction thataccesses the hardware. A virtual machine [17] is a machine that runs in a vir-tualized environment as opposed to directly on hardware.
Decoupling the OS from the physical machine by virtualization has enabledseveral techniques and methods to be employed such as power managementcapabilities, on-line maintenance, and load balancing which is enabled by theability to move a virtual machine from one physical host to another.
These capabilities can be achieved because the state of the virtual machine, thevirtual CPUs (VCPUs), the memory, and any attached device can be recorded.The state can then be transferred to another physical host which enables thesame virtual interface to the hardware where the virtual machine can be re-sumed. The process of moving the state from a physical host to another iscalled migration.
Running several virtual machines on one physical server allows pooling of re-sources together to provide better power management [14]. Moving a virtualmachine from one physical server to another provides cluster environments todo on-line maintenance [13]. Load balancing can be achieved by dynamicallymoving and allocating virtual machines across a cluster of physical hosts [22].
The use of each of these techniques requires the ability to efficiently move thevirtual machine between physical hosts, and is called virtual machine migration.
1.2 Live Migration
Live migration builds upon the idea of migration and takes it a step further.The ”live” in live migration pertains to the fact that the migration should be
1

transparent to the users. As a consequence, the guest OS should be runningduring the migration. The downtime is the time it takes for the source hostto suspend execution of the virtual machine (VM) until the destination hostresumes it. The VM should not be stopped for a considerable amount of timein order for the it to be usable during the migration and thereby transparent tothe users who ideally are not aware of the migration occurring.
1.3 Motivation and Problem Definition
The aim of this thesis is to further improve upon and to reduce the the totalmigration time of virtual machine live migration. The total migration time isthe time it takes from when the migration is initiated for a VM on the sourcehost until the VM is resumed on the destination host. In order to be able toprovide the capability of live migration, a low downtime is required. Downtimeis the time during which the virtual machine is not responsive. Suspending thestate of the VM includes pausing the VCPUs as well as other connected devices.Extensive work has previously been done to reduce the downtime but less workhas been done focusing on reducing the total migration time.
Total migration time can be very important in data centers since a reductionin total migration time improves load balancing, proactive fault tolerance, andpower management capabilities.
1.4 Contributions
The contributions of this thesis are:
• A technique is presented that reduces the total migration time by sendingonly a critical subset of data through the network. We identify and cor-rectly handle all scenarios that could lead to a corrupt memory image ordisk of the VM during and after the migration.
• The proposed technique has been implemented in Xen 4.1 and variousbenchmarks have been conducted with fully-virtualized Linux guests.
• The results have been analyzed compared to the performance of the orig-inal Xen implementation. The total migration time is reduced by 40.48seconds on average which corresponds to a 44% relative reduction.
1.5 Outline
The thesis is structured as follows. Chapter 1 introduces to the thesis topic.Chapter 2 continues with an introduction to virtualization concepts and toolsused. Chapter 3 presents a discussion of related and previous works. Thereafter,Chapter 4 proposes a solution to the problems discussed. Chapter 5 presents
2

an discussion about implementation details. Chapter 6 provides an in-depthanalysis of the solution. Chapter 7 concludes the thesis and discusses futurework.
3

2 Virtual Machine Monitors, Xen, and
Memory Management
The following sections in this chapter discusses important background informa-tion abut virtualization, tools used, and a brief overview of relevant computerarchitecture. A basic knowledge of computer architecture is assumed and canbe found in [17].
2.1 Overview
Xen is an open source bare metal hypervisor [1]. A hypervisor is a virtualizationlayer on top of the hardware that runs virtual machines. Bare metal pertainsto the fact that the hypervisor is running directly on hardware and not on topof any existing OS such as VirtualBox or VMware WorkStation. Each of thevirtual machines resides in a domain of their own called a user domain (domU).The only domain allowed to access the hardware directly and start new guestmachines is domain 0 (dom0) which is a special management domain in Xen.The hypervisor ensures the separation of the domains so that they cannot affecteach other for reasons of security and correctness. The structure can be seen inFigure 2.1.There are two types of virtualization techniques which Xen provides,hardware virtual machine (HVM) and paravirtualized guests.
Hypervisor
Hardware
Dom0 DomU
Figure 2.1: Structure of Xen
4

2.2 Paravirtualization
A paravirtualized guest is aware that is it running virtually as opposed to aHVM guest [4, 17]. In a virtualized environment the hypervisor must executein ring 0, to ensure that the domains are completely separated in order for thedifferent domains not to be able to affect each other. A ring is a protectionmode that is allowed to execute with a certain privilege, where ring 0 has thehighest privilege. The paravirtualized kernel of the guest is thus evicted fromring 0, where it usually resides, to ring 1. Thereby, the kernel cannot executeprivileged instructions. A privileged instruction is an instruction that can onlybe performed in ring 0 and trap otherwise according to Goldberg [16]. In or-der for the kernel to cope with the eviction, the kernel is modified to call thehypervisor via hypercalls, which are similar to the privileged instructions. Thechanges are confined to the kernel, and thus the user applications does not needto be modified [5].
2.3 Hardware Assisted Virtualization
An HVM guest has no knowledge that it is running virtually as opposed todirectly on hardware and thus has a different set of requirements compared to aparavirtualized guest. There are methods to virtualize unmodified guests with-out the using special hardware with techniques such as binary translation [18].However, this approach was not considered in Xen due to the incurred per-formance degradation of this technique [4]. Hardware extensions such as IntelVT [20] or AMD SVM [2] are instead required since there are instructions in thex86 architecture that change the configuration of the system, by changing globalregisters or communicate with devices without being a privileged instruction.Since operations which can have global effects existed prior to these hardwareextensions, certain privileged instructions could be executed without being ableto be trapped by the hypervisor. Support for non-paravirtulized guest couldnot be offered because it violates the isolation of domains. Due to the risingpopularity in virtualization, hardware manufacturers introduced the ability tomitigate these problems. ”Conceptually, they can be thought of as adding a’ring -1’ above ring 0, allowing the OS to stay where it expects to be and catch-ing attempts to access the hardware directly” [5, p. 12]. The hypervisor thusexecutes in this ’ring -1’ above ring 0, thus enabling the use of virtualized guestswithout kernel modifications in the guest itself.
There are performance differences of an HVM and paravirtualized guest. Hard-ware is emulated for an HVM guest and this usually causes them to be slowerthan paravirtualized guests. A hybrid approach can provide the hardware ex-tensions together with the modifications of the OS to reduce the performancedegradation.
5

2.4 Memory Management and Page Tables
Memory management differs from the HVM and the paravirtualized guest. Aparavirtualized guest interacts with the hypervisor directly since the domU isnot allowed to access hardware. It issues a hypercall to the hypervisor whichensures that a mapping between guests page frame number (PFN) has a correctmapping to a machine frame number (MFN). A MFN is a real hardware addressin memory whereas a PFN is a virtual address which the guest can use as a realaddress.
For HVM guests, shadow page tables are page tables containing mappings fromwhat the guest believes are MFNs, which are in fact PFNs, to real hardwareMFNs used by the hypervisor. These shadow page tables are used by the hy-pervisor and hidden from the HVM guest. This is achieved by marking the pagetables of the HVM as read-only by the hypervisor. Therefore, a page fault willbe generated when a guest tries to update its own page table entries. The hy-pervisor intercepts these page faults and keep a mapping between the PFNs andMFNs. These operations can be quite expensive. Modern memory managementunits (MMUs) such as Intel’s Extended Page Tables (EPT) and AMD’s NestedPage Tables (NPT) mitigate this problem by allowing the guests to modify theirown page tables and handle their own page faults. This is achieved by keeping aseparate set of page tables, such as EPT and translating the guests guests pseudoaddresses to real hardware addresses. Shadow page tables are also used duringlive migration for the purpose of tracking which pages are modified [4,5, p. 82].
2.5 The Page Cache
The page cache [17] is a cache kept by the kernel of the OS in main memory tobuffer data that goes to and from the disk. It is used to facilitate quicker accessto disk, since accessing memory is orders of magnitude faster than accessing thedisk. Write requests to disk as well as read requests from disk are cached by theOS in the page cache. Modern operating systems use a majority of the unusedmemory to buffer I/O requests to or from the disk. The page cache can also aidin speeding up write requests to disk by caching the write request in memoryand eventually flushing the page to disk. This speeds up the write because theapplication will think it has already finished writing to disk and can continueeven though it may only be cached and later written to disk.
6

3 Related Work
3.1 Introduction
Live migration is the migration of a VM without stopping the execution ofit for a considerable amount of time. Three phases can be identified in livemigration [6].
• Push - In the push phase, the source virtual machine sends its data to thedestination VM.
• Stop and copy - In the stop and copy phase, the source VM stops executingand transfers control to the destination VM.
• Pull - In the pull phase, the destination VM retrieves data from the sourceVM.
These three phases can be mapped to different methods of achieving live migra-tion. Two commonly used techniques are called pre- and post-copy, respectively.
The naive approach to migrate a virtual machine is to stop the execution at thesource, record its state, then move that state to another machine and finallycontinue executing as described above in the stop and copy phase. The problemthat arises is the availability of the virtual machine. For a virtual machine thathas 512 MB of RAM, this can result in an 8 second downtime or 32 seconddowntime with bandwidths 512 Mbit/sec and 128 Mbit/sec, respectively [6]. Inthe present day, VMs have memory sizes of 4 GB are not uncommon whichclearly exacerbates the problem of long migration times. Recording the stateof a virtual machine includes recording the state of the memory, the VCPUand any attached devices. The majority of the time to migrate a VM is spentrecording and transmitting the memory. This approach of doing a naive stopand copy quickly becomes infeasible since even larger amounts of RAM are usedtoday which increases the downtime and total migration time even more.
3.2 Performance Measurements
There are two useful performance measures in terms of time, total migrationtime and downtime. Downtime refers to the time when the virtual machine
7

is unresponsive. This is when the actual transfer of control is occurring fromthe source host to the destination host, the time during which the VM is notresponsive on the source or the destination host. Total migration time is the timefrom when the process of migration begins from the source machine until thetime when the destination VM has control and the source can be discarded. Inlive migration these two times usually differ greatly. However, in cold migration,the naive version with only the stop and copy, they are equal. Cold migrationdoes not involve any work before or after the transfer of control from one hostto another; it does not involve the push or pull phase.
3.3 Live Migration Methods and Techniques
3.3.1 Iterative Pre-Copy
Pre-copy is the predominant algorithm used today in live migration [6]. It worksby copying the memory of the virtual machine from the source and then trans-ferring it to the destination in a number of iterations without stopping the VMon the source host. In the first iteration, the whole memory is copied from thesource to the destination while the VM is still executing. In the subsequentiterations, the memory pages that have been modified during the previous iter-ation are resent. This process continues until the last iteration when the sourcehalts execution of the VM, the last modified memory pages are transferred tothe destination machine where the virtual machine is thereafter resumed. Thepre-copy technique can be seen as a number of successive iterations of the pushphase which ends with the stop and copy.
The last iteration occurs when one of the three following conditions occurs. Themaximum number of iterations has passed, the maximum amount data has beensent over the network, or the modified memory is sufficiently low. In contrast tothe naive stop-and-copy approach, the pre-copy technique can reduce the down-time by a factor of four with a single push iteration, sending the whole memoryonce and then do a stop-and-copy, for a SPECweb benchmark. However, pre-copy normally performs several iterations and demonstrates the effect of thedowntime compared to the naive approach. In an interactive environment suchas a Quake 3 server; a large downtime can be detrimental to the players. Withthe pre-copy technique, the downtime can be as low as 60 ms with 6 players [6].
The amount of data transferred in the first pre-copy iteration is proportionalto the amount of memory allocated to the guest OS. The other iterations areproportional to how fast the memory pages are modified [3].
3.3.2 Memory Compression of Pre-Copy
The pre-copy algorithm has been improved upon since its conception. Hai Jin etal. [10] developed an adaptive memory compression technique where the mem-
8

ory sent is first compressed at the source and decompressed at the destinationmachine. A 27% reduction in downtime, a 32% reduction in total migrationtime, and a 68% reduction in data transferred was achieved with this approach.
3.3.3 Post-Copy
The post-copy approach begins with the stop and copy phase and continueswith the pull phase. In order for the destination machine to have all the datait requires, it retrieves them from the source continually. Several techniquescan be used in order to retrieve the memory from the source, such as demandpaging, active pushing, and adaptive pre-paging.
Demand paging is a technique in which the page fault occurs at the destinationmachine and as this happens it requests the faulted page from the source. Ac-tive pushing is when the source machine actively pushes data to the destinationwithout waiting for a page fault. These two techniques can be used simultane-ously. Adaptive pre-paging is a concept borrowed from operating systems andworks on the assumption of spatial locality. When a page faults occurs, the like-lihood of a page fault in the same vicinity is increased and thereby pages closeto the first page fault will be sent to the destination along with the page faultitself [9]. Adaptive pre-paging continues to send pages in the nearby proximityuntil another page fault occurs.
Hines et al. [9] also proposes a technique called dynamic self ballooning, wherea driver runs in the guest VM, continuously reclaiming free and unused memoryand giving it back to the hypervisor. This requires the use of a paravirtualizedmachine due to the communication between the guest driver and the hypervisor.Using this technique during migration reduces the amount of memory that is tobe sent of the network since the reclaimed and unused memory is not transferred.
The migration time of post-copy is mostly bounded by the amount of memoryallocated to the VM since the memory is the bottleneck of saving and trans-ferring the state [9]. As opposed pre-copy, post-copy will only transfer eachmemory page once.
3.3.4 System Trace and Replay
Haikun Liu et al. [12] studied a more unorthodox method based upon tracingand replaying events instead of transferring data. This method, called systemtrace and replay, starts by taking checkpoint of the source VM. A checkpoint is arecorded state of the VM usually saved to disk to be resumed later. The systemtrace and replay instead transfers the checkpoint to the destination machine. Si-multaneously, the source machine starts to record, or to trace, non-deterministicevents such as user input and time variables. These events are recorded in a logand subsequently sent to the destination. The log transfer happens in a numberof iterations similar to that of pre-copy. Thereafter, the destination executes,
9

or replays, from the checkpoint and any non-deterministic event is read fromthe log. The replay mechanism is able perform faster than the original trace ofevents. This is required for the destination to catch up with the source. De-terministic events do not need to be recorded because the destination machinestarts from a checkpoint and thus they will have the same deterministic eventsafterwards. The cycle of tracing and replaying goes on until the destinationmachine has a sufficiently small log; the source stops and copies the last of thelog to the destination where the last of it is replayed and the migration has beencompleted at this point.
A problem may afflict this technique when several virtual machines are runningon the same physical host. In case the source host has several VMs runningwhich require the use of the CPU(s) frequently. Then this method may in factincrease the total migration time. This happens because there is an overheadon the source host for recording the events. If there are other CPU bound VMsrunning simultaneously it can slow down the migration compared to originalXen.
3.3.5 SonicMigration with Paravirtualized Guests
Koto et al. [11] presented a similar technique to this thesis called SonicMigration.They presented a technique where the page cache and the unused memory in aguest is not transferred to the destination. Instead, they invalidated the pagecache and skipped sending those pages. This only works for paravirtualizedguests since a fully virtualized guest has no knowledge that it is running in avirtulized environment. The hypervisor must be able to communicate with theguest kernel directly.
3.3.6 Discussion of Live Migration Techniques
The techniques presented here can all be evaluated by the two metrics of down-time and total migration time as discussed above. The system trace and replaymethod managed to achieve an average of 72.4% reduction in downtime com-pared to the pre-copy technique, which is currently the most frequently usedone [12]. The system trace and replay is one of the most promising techniques interms of reducing downtime, although not total migration time. This techniquehas an 8% application performance overhead because of the tracing capabilitiesenabled during live migration at the source, which can increase the migrationtime. It reduces the total migration time with about 30%. The memory com-pression technique reduces the downtime and total migration time by 27% and32%, respectively, by reducing the bandwidth required to transfer the data. Thepost-copy technique increases the downtime due to implementation difficultieswhich can be improved upon and reduces the total migration time by over 50%in certain cases. SonicMigration is able to reduce the total migration by 68%.
10

In contrast to the pre-copy approach, the post-copy approach suffers from re-duced reliability since the destination host has only one part of the whole state.If the destination machine dies, the source has an inconsistent state since thedestination had the most recent state of the VM. If the source machine dies thenthe destination cannot continue executing the VM with only a subset wholestate. In the same fashion, the migration cannot be cancelled mid-way like pre-copy. Another problem with post-copy is that it performs worse than pre-copyon read intensive programs since numerous page faults will occur. On the otherhand, when it comes to write intensive programs which will modify the memorypages rapidly, post-copy performs better than pre-copy, because post-copy willnot have to fetch much data from the source machine, whereas pre-copy willkeep sending all the modified pages until a termination requirement has beenmet. Another problem with post-copy is that current implementation increasesthe downtime compared to pre-copy [9].
3.4 Checkpoint Methods and Techniques
3.4.1 Efficiently Checkpointing a Virtual Machine
Checkpointing, or taking a snapshot as it is sometimes called, of a virtual ma-chine is to record the state of the running VM and save it to non-volatile storagesuch as disk. The checkpoint can later be used to resume the VM with the stateit had before being checkpointed. The state of the VM includes, but is notlimited to, the memory of the machine. Previous work has been done to reducethe amount of memory saved by up to 81% along with a reduction in 74% oftime spent taking the checkpoint.
The performance enhancements are achieved by realizing that the page cache,a buffer in the OS, keeps data from disk cached in memory to facilitate quickeraccess to it, will contain the same information both on disk as well as in memory.At the time of check pointing a machine, the memory of the VM will be savedto disk and thus there will be replicated data on disk, the data in the memorysnapshot as well as the original data on disk.
The unmodified pages in the page cache, the ones that are the same in memoryas on disk, are discarded from the checkpoint by Park et al. [15] When the VMis later resumed, it will read the pages from the original disk sectors, and notfrom the checkpoint image.
To know which pages have duplicate data on disk, Park et al. track and in-tercept I/O request from the VM to the disk. The PFN involved in the diskrequest is recorded in conjunction with the accessed sector on disk and storedin a map, pfn to sec. The PFNs included in the pfn to sec are marked asread-only in their page table entrys (page table entries). If the VM modifies
11

such a page, by writing to it, a page fault is triggered. The page fault is handledby the hypervisor which deletes the corresponding mapping in the pfn to sec
map and re-grants the PFN write access and resume the VM.
A drawback to this approach of efficient checkpointing is the restoration time.Since the checkpoint image does not contain all data required, the data mustbe loaded from disk. This makes the restoration slower because the data isscattered over the disk. Reading a contiguous checkpoint image file is fasterthan reading scattered data because the disk is forced to introduces a large seektime in the latter case.
3.4.2 Fast Restore of Checkpointed Memory using Work-ing Set Estimation
Zhang et al. [21] worked on improving the restoration time of virtual machines.Restoring a virtual machine includes restoring the state of the VCPUs as wellas the memory and any devices. Zhang et al. load only a subset of all memorybefore resuming the VM because loading the memory is the major part of therestoration time. The subset consists of the working set of memory pages usedbefore saving the memory to a checkpoint image on disk. Restoring withoutthe working set performs poorly since it incurs numerous page faults. It istherefore used to minimize the subsequent degradation. The working set ismeasured by constantly reading and resetting the access bit in the guests pagetable entries. The result is saved in a bitmap for later restoring only the mostrecently used pages. This approach achieves a 89% reduction in restoration forcertain workloads.
12

4 Proposed Solution to Optimize Total
Migration Time
The solution in this paper is briefly described in this paragraph and a longer,more detailed version follows in the next sections. The overall design of thesolution is to discard sending the data in memory which is duplicated on disk.Instead, this data is read at the destination directly from disk after the migrationhas finished. This proposed solution relies upon the fact that the source and thedestination machines are attached to the same secondary storage in the form ofNetwork Attached Storage (NAS), this does not pose a problem since to be ableto do a live migration in Xen some type of network attached storage has to beused [19].Data is not read from disk during the migration to ensure correctness.The data yet to be loaded in memory is marked invalid to preserve correctnessof the VM, once it has resumed on the destination. This a combination ofthe pre-copy algorithm, the algorithm used in Xen, and a modified version ofefficiently restoring virtual machines from checkpoints described in section 3.4.1and section 3.4.2, respectively.
4.1 Page Cache Elimination
The proposed method to handle the increasing migration times with larger mem-ory sizes involves several of the techniques previously mentioned in section 3.4,by exploiting the page cache. The page cache is a cache provided by the OS tofacilitate fast access to the disk. The OS caches recently written pages to diskin memory in addition to data read from the disk in order to reduce the latencyfor a disk access.
The proposed method of reducing total migration time is to use the efficient
Source Destination
NAS
Figure 4.1: Network Topology
13

checkpointing described in section 3.4.1 and apply it to live migration. Theunmodified pages are read from disk at the destination. The modified pages aresent over the network. The topology of the design can be seen in Figure 4.1.This entails a solution where the source machine records the unmodified pagecache pages with the corresponding disk sector in a data structure, called apfn to sec map in order for the restoration process on the destination side toknow what PFN has its corresponding data on disk.
If a PFN is in the pfn to sec map during migration of a VM, the PFN is notincluded with the pages sent over the network. Instead, the pfn to sec map issent over the network. The pfn to sec map stores a mapping between a PFNand a disk sector, hence it is orders of magnitude smaller than the memory.Sending the pfn to sec map in the last iteration might increase the downtimedue to the additional data sent. Therefore, the pfn to sec map is sent itera-tively to the destination in the same fashion as pre-copy does with the memory,in order to keep the downtime as low as possible. In the first iteration, thewhole pfn to sec map is sent. In the subsequent iterations, only the changesto the pfn to sec map are sent.
One possible design is to load pages from disk during the network transfer. Thisintroduces a problem when the page cache is sufficiently large so that loadingthe data from disk takes longer than the network transfer. In that case the VMhave to be paused at the destination until all data has been read from disk.This might drastically increase the downtime which is a substantial problem forinteractive services. Park et al. measured that the the page cache can be over90% of the memory used in a computer in extreme cases [15]. This may in turnresult in unsatisfactory downtimes. To solve the potential problem of increaseddowntime, the guest should be started while pages are loaded in the backgroundfrom disk, called pre-fetch.
Cache Consistency During Live Migration
There are several problems that occur during live migration due to asynchronousI/O or caches for the proposed technique. The source may delay and cache writerequests to disk since writing to disk can be asynchronous. The destination ma-chine may also cache reads from the NAS. These problems can cause race con-ditions to appear. If the source writes from PFN p to sector s and records thatin the pfn to sec map and the write request is delayed, then the destinationmay read invalid data from sector s. This is more of a implementation issues, anissue nonetheless. Additionally, if the destination machine has previously readand cached sector s which is then written to by the source. The destinationwill read the wrong data from its cache instead of reading directly from the diskwhich is more of an inherent problem of this approach.
Caching of reads from the NAS at the destination host should thus be turned off
14

Source
Destination Running execution of a VM
NAS
time
DowntimeTotal migration time
Page faults
Figure 4.2: Time-line Overview
once the migration is started and only for the affected background process. Anyother process or domain should not have degraded performance. Direct I/Owhich bypasses any client cache is not used since not all kernels support directI/O, the O DIRECT flag, in conjunction with the distributed file system used.Due to the complicated nature of this problem, instead of turning off cachingin real-time per domain-basis on any level, another solution is better suited,namely avoid simultaneous reads or writes to the disk. This solution impliesthat the destination machine does not start reading data from disk until the VMat the source has shut down. All outstanding writes are flushed to disk whenthe VM is suspended and moved from the source. After this, the destinationmay start reading data from disk so that no pages are read during the networktransfer.
There are other methods that can be used such as using cache coherent dis-tributed file systems or using direct I/O to the network attached storage. Dis-tributed cache coherent file systems are not used due to the over head of connect-ing different machines and the difficulty of measuring the performance degrada-tion.
4.2 Page Cache Data Loaded at the DestinationHost
The aforementioned problem of the potentially increased downtime, when thepage cache is too large, is remedied by resuming the VM once the network trans-fer is completed in a similar fashion to what Zhang et al. accomplished withefficient restoration of checkpoints [21]. Pages are loaded in the backgroundwhile the machine is running. To keep the VM in a consistent state, the pages
15
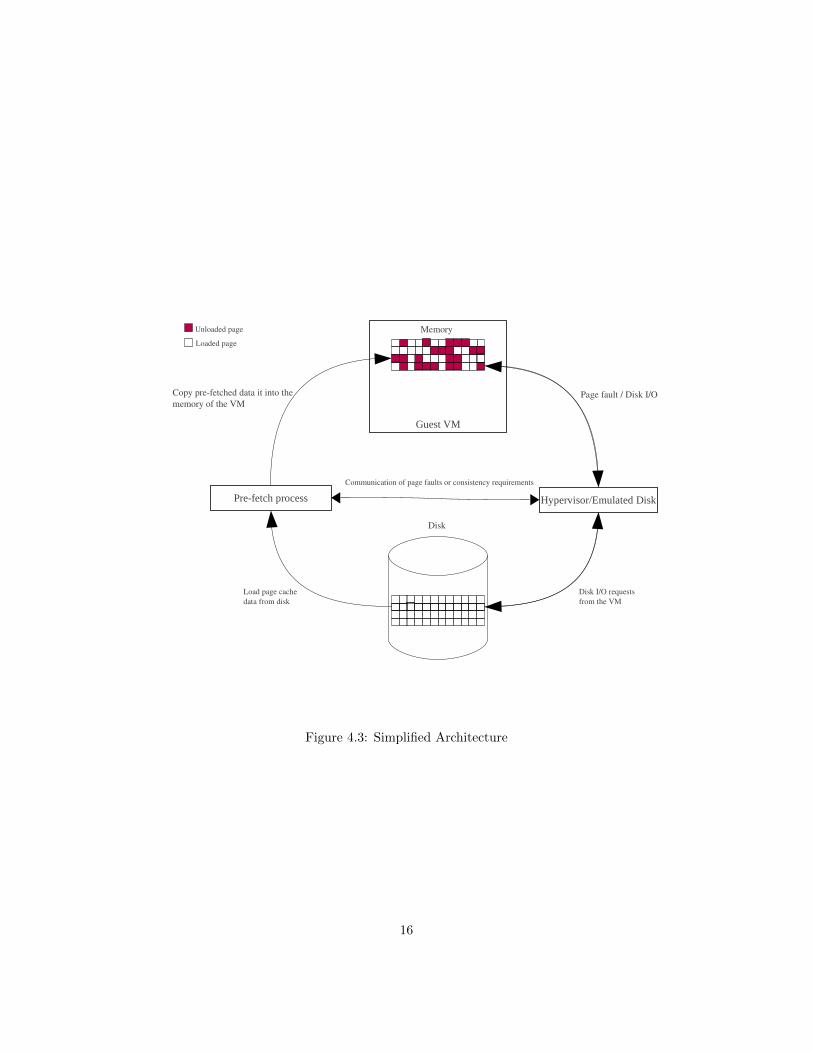
Hypervisor/Emulated Disk
Guest VM
Pre-fetch process
Page fault / Disk I/OCopy prefetched data it into the memory of the VM
MemoryUnloaded page
Loaded page
Disk
Communication of page faults or consistency requirements
Disk I/O requests from the VM
Load page cache data from disk
Figure 4.3: Simplified Architecture
16

that have not been loaded are marked as invalid in their corresponding PTE. Abackground fetch process, called pre-fetch, is initialized with all pages to load,the pages in the pfn to sec map. The running VM may try to access a page yetto be loaded. In this case, a page fault is raised. The page fault handler in thehypervisor intercepts it and forwards a request to the background fetch processto load the page, which immediately loads the data from disk and responds tothe hypervisor. The hypervisor itself cannot load the page since it is requiredto services other guests on the same system and cannot be blocked with an I/Orequest. Figure 4.2 illustrates the design of the the proposed solution. Thetotal migration time and the downtime are also depicted. The architecture ofthe resumed VM is depicted in Figure 4.3. To maintain consistency of the diskand memory of the VM, all disk I/O needs to be intercepted as discussed in thenext section and illustrated in Figure 4.3.
4.3 Maintaining Consistency
The following cases may occur depending on the way the hypervisor virtual-izes the disk. Disk requests do not go directly to the disk in Xen, since thatviolates the isolation of domains constraints; they are rather handled by a em-ulated disk. This emulated disk runs with privileges of a super user on the hostmachine and does not use the same virtualized page tables as the guest. Sincethe guest can simply pass a reference to the memory address from where theI/O request originates, the virtualized disk may access data which is marked asinvalid in the guest. Thus, a page fault is not triggered by the emulated diskand because of these interactions, the following problems may arise. To detectif this may occur, all I/O requests from the guest are intercepted and comparedwith the background process’ queue which contains an up-to-date mapping ofwhich pages are to be loaded. These pages that have not been loaded are theones that can cause corruption of the memory or disk of the VM discussed indetail in this section.
Read/write disk race. This situation occurs when the VM writes data to adisk sector which is to be loaded by the background process. If the write requestis processed and written to disk before the read from the background process,the background process will load modified data on disk into the memory of theVM. The data on disk has been changed behind the process’ back. The solutionto this problem is to delay the write request from the guest until the data ondisk has been loaded by the background process. Case a depicts this scenarioin Figure 4.4.
Read disk race. The disk read race occurs when the VM reads data into apage which has not been loaded by the background process. If the backgroundprocess later loads data into a such a page, it will overwrite the newer data withold data causing the memory to become corrupt. This may occur when mem-
17
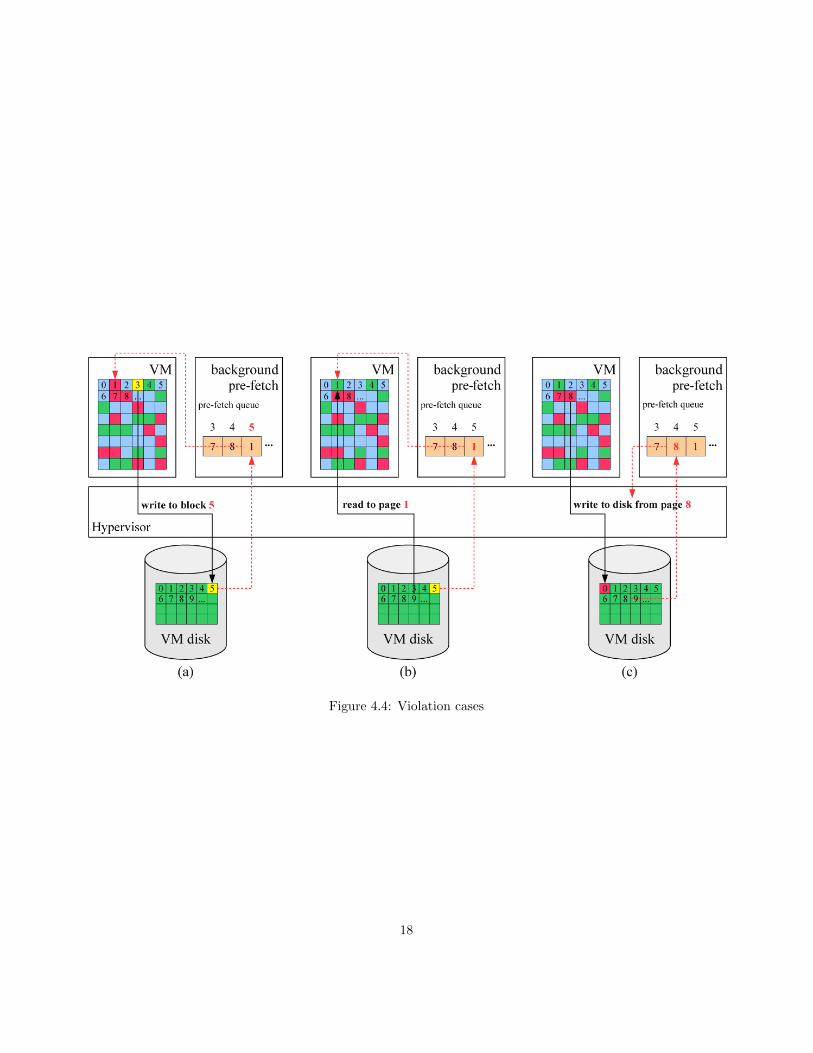
Figure 4.4: Violation cases
18

ory inside the VM is used for several read requests from disk or newly allocatedmemory is not accessed before a read request. Old page cache data may forinstance be overwritten by newer I/O requests. Case b depicts this scenario inFigure 4.4.
In case the read request is the size of the whole memory page, then it can simplybe dropped from the background process queue. If, on the other hand, the readrequests only spans a subset of the page, the read request has to be delayeduntil the original data is loaded by the background process. This is depicted ascase b in Figure 4.4.
Writing data to disk from a page that has not yet been loaded. Incase the VM issues a write request from a page that has not been loaded, itwill write corrupted data to disk, thereby corrupting the disk. If such a writeis about to occur, it has to be intercepted and deferred until the correct data isloaded into memory. Case c depicts this scenario in Figure 4.4.
19

5 Implementation Details
The proposed technique has been implemented in the Xen hypervisor version4.1.2. for HVM guests. This chapter discusses the details of the implementation.
5.1 Live Migration
When a user requests Xen to migrate a guest, a migration process is started.In the original Xen implementation, all pages are sent over the network. In thisimplementation, only the non-duplicated pages are sent. In the first iterationof the pre-copy algorithm the pfn to sec map is transmitted over the network.In the subsequent iterations only the changes in the pfn to sec map are sent.Once the VM resumes at the destination, the pages in the pfn to sec map haveall their access permissions (read, write, and execute) removed from their corre-sponding page table entry (PTE) in the guests virtualized page table, ExtendedPage Tables (EPT) or Nested Page Tables (NPT).
5.2 Pre-fetch Restore
Once the VM is running, the pre-fetch restoration process sets up a commu-nication channel with the hypervisor. An asynchronous ring buffer is used forthe communication from the hypervisor to the pre-fetch restoration process.The hypervisor uses asynchronous communication since it has to be availableto other guest domains. However, the restoration process performs hypercallsto get direct access to the hypervisor. This communication channel is set up todeliver page fault requests to the background restoration process.
5.2.1 The Page Fault Handler
The Xen hypervisor receives page faults that have been triggered by a guestviolating the access permissions of a memory page. The page faults which arecaused by the guest accessing a page which has not yet been loaded are easilydistinguished from other types of page faults. It is achieved by checking if theaccess was removed by the pre-fetch restore process. These page faults cause thehypervisor to pause the VCPU of the affected domain and forward the requestto the background restoration process. The restoration process uses two array
20

based queues, one sorted by PFN and one sorted by disk sector to facilitatequick access to both.
The page faults are indexed by PFN whereas the background process needs aqueue to read sequential sectors, a queue sorted by sector number in ascendingorder. The queue indexed by PFN is updated when a page is loaded from diskto check off which sectors has already been loaded with a flag.
The background restoration process continually loads batches of pages from diskto reduce the number of page faults. After each of these load operations, thering is checked to see if a page fault has occurred. These page fault requestsare processed immediately upon reception. A subsequent hypercall is performedto notify the hypervisor that the page is loaded and to resume the VM. It ispossible that the background restoration process receives page fault requests forpages recently loaded. In such occasions, the hypervisor is notified immediatelywhich resumes the VM.
5.2.2 Intercepting I/O to Maintain Consistency
In order to maintain consistency, all I/O requests from the VM have to be in-tercepted as previously discussed in Section 4.3. All I/O requests issued froman HVM guest pass through ioemu, a modified version of qemu. Ioemu is usedin Xen to emulate hardware for HVM guests. The emulated disk located inioemu has been modified to intercept and properly deal with cases which wouldviolate the consistency and to detect these situations that may lead to a corrup-tion of the memory or disk of the VM. Ioemu needs to have access to the queuemaintained by the restoration process to ensure consistency. A shared memorysegment is used between ioemu and the restoration process to facilitate quicklookups in the queues.
Read/write disk race. To detect a disk read/write race condition from apage PFN to a disk sector s, ioemu checks the restoration process queue forsector s. In case such a sector is found in one entry, it sets a flag in a sharedmemory segment requesting a load of that sector. After loading the data intothe memory, the background process sends a message back to ioemu which thenexecutes the write request.
Read disk race. To detect a disk read/read race condition from a PFN p toa sector s, ioemu searches the pre-fetch queue of the restoration process for anentry with the same PFN p. If such an entry exists, ioemu deletes the entry inthe queue if data read from disk is as large as the size of the memory page. Ifon the other hand, the read from disk only spans a subset of a page in memory,then ioemu signals the restoration process to load the page and once it is loaded,continue with the request.
21

Modern operating systems perform the majority of the disk I/O on page granu-larity. I/O requests on a sub-page granularity is not tracked by Park et al. sinceit adds complexity while providing modest reduction in the checkpoint imagesize. The same approach is followed in this paper. Thus, reads from disk thatspan only a subset of a page will be a special case since a subsequent load bythe restoration process overwrites any data which ioemu loads into the memorypage. The restoration process is notified about such requests and loads the dataimmediately and the requests are delayed until the data is loaded.
Writing data to disk from a page that has not yet been loaded. Inthis case, the VM requests to write data from PFN p to disk sector s. Ioemusearches the restoration process’ queue for an element with PFN p, if it findssuch an element then it notifies the background process which it immediatelyloads from disk. However, ioemu has already copied the data from the memoryof the VM into its own I/O buffers that now contain invalid data. The dataof the requested page is thus sent along with the confirmation message backto ioemu which copies the data into the I/O buffers before executing the writerequest.
5.2.3 Optimizations
Early tests showed that the number of seek operations can drastically affectthe performance of the disk. Data is thus loaded in ascending order on disk tominimize the number of seeks.To achieve good performance during the pre-copyiterations as well as after restarting the VM on the destination, it is importantto minimize the number of page faults as well as the number of disk I/O opera-tions caused by the background process. Tests have shown that the performanceof the VM is substantially better when the restoration process’ queue is sortedby the disk block number. This may be counter-intuitive to the principle ofspatial locality which often is applied to the memory but here the disk. Thereare two reasons for why this performs better. Firstly, it reduces the number ofseek operations on the disk and reduces the number of system calls to the kernel.Secondly, consecutive entries on disk may be loaded with one I/O operation asopposed to as many I/O operations as the number of pages. Thereby, increasingthe throughput of the disk. There are in fact too many consecutive entries inthe queue in certain cases so that a limit has to be placed on the maximumnumber to load at once. Loading too many would impose a large latency forpage faults as well as the disk requests originating from the VM itself would beprolonged. The increased I/O latency in the VM would only be noticeable bythe users of the guest which is difficult to measure, so a trade-off has to be madebetween user satisfaction and the restoration time, the time it takes for all pagesto be loaded. Loading too few would request to many operations to the disk andbecause of latency to disk imposed by it to physically move, this performs poorly.
To further improve performance, an adaptive pre-paging algorithm which aimsat reducing the number of page faults has been implemented. The adaptive
22
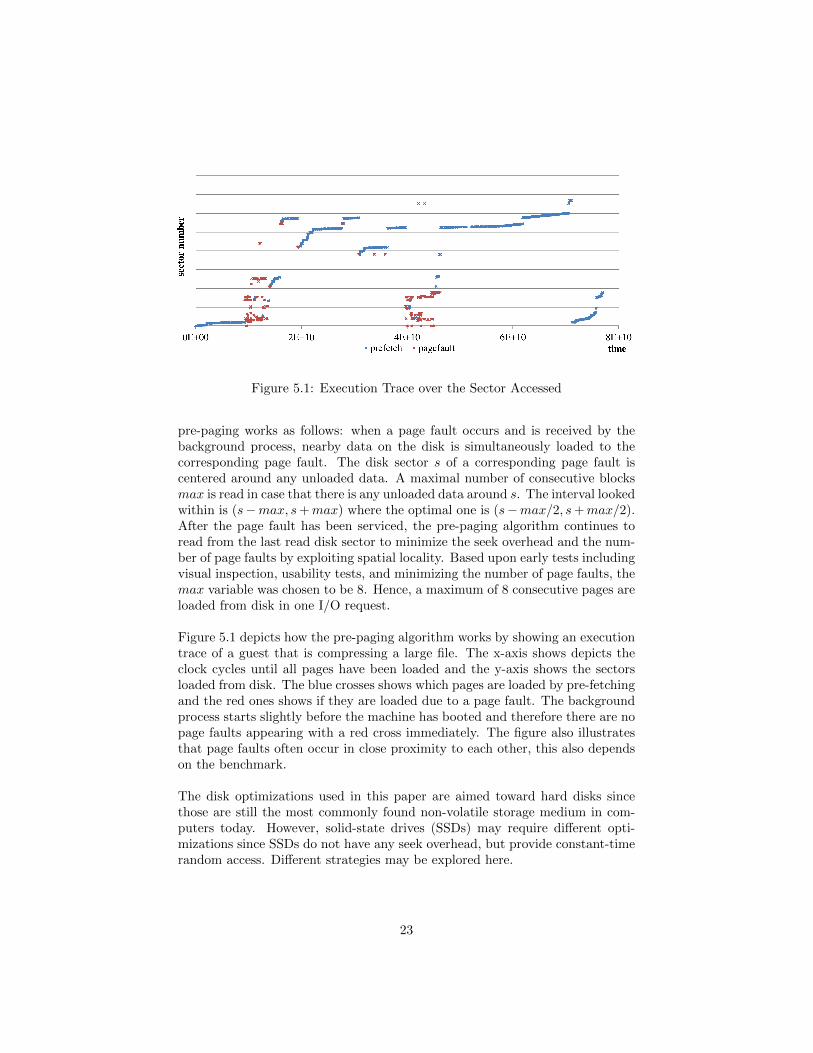
Figure 5.1: Execution Trace over the Sector Accessed
pre-paging works as follows: when a page fault occurs and is received by thebackground process, nearby data on the disk is simultaneously loaded to thecorresponding page fault. The disk sector s of a corresponding page fault iscentered around any unloaded data. A maximal number of consecutive blocksmax is read in case that there is any unloaded data around s. The interval lookedwithin is (s−max, s+max) where the optimal one is (s−max/2, s+max/2).After the page fault has been serviced, the pre-paging algorithm continues toread from the last read disk sector to minimize the seek overhead and the num-ber of page faults by exploiting spatial locality. Based upon early tests includingvisual inspection, usability tests, and minimizing the number of page faults, themax variable was chosen to be 8. Hence, a maximum of 8 consecutive pages areloaded from disk in one I/O request.
Figure 5.1 depicts how the pre-paging algorithm works by showing an executiontrace of a guest that is compressing a large file. The x-axis shows depicts theclock cycles until all pages have been loaded and the y-axis shows the sectorsloaded from disk. The blue crosses shows which pages are loaded by pre-fetchingand the red ones shows if they are loaded due to a page fault. The backgroundprocess starts slightly before the machine has booted and therefore there are nopage faults appearing with a red cross immediately. The figure also illustratesthat page faults often occur in close proximity to each other, this also dependson the benchmark.
The disk optimizations used in this paper are aimed toward hard disks sincethose are still the most commonly found non-volatile storage medium in com-puters today. However, solid-state drives (SSDs) may require different opti-mizations since SSDs do not have any seek overhead, but provide constant-timerandom access. Different strategies may be explored here.
23

6 Results
6.1 Experimental Setup
The proposed technique has been implemented in the Xen hypervisor version4.1.2 on a machine with an Intel(R) Core(TM) i5-2500 CPU @ 3.30GHz, 16 GiBRAM, and a QNAP NAS server. The two hosts, the source and the destination,are connected via Gigabit Ethernet. dom0 runs Ubuntu Server 12.04.1 LTS.The guests have been configured to run Ubuntu 10.04 with 1 GB of RAM and1 VCPU.
A series of experiments have been conducted with varied usage pattern. Eachexperiment has been run with the default adaptive rate-limiting algorithm usedin Xen. The transfer rate starts at 100 Mbits and increases with 50 Mbit aftereach iteration, until a maximum limit of 500 Mbit. This algorithm is used tominimize the congestion of the network between the hosts. The results thathave been achieved are compared to unmodified Xen. There is a number ofinteresting measures for evaluating the performance of the proposed technique.After each experiment, the page cache was also dropped on each of the hosts inorder for them to not have cached anything from a previous run.
• The downtime of the VM
• The total migration time of the VM
• The degradation incurred for the VM once it has started.
Table 6.1 lists the benchmarks used to evaluate this work. The user sessionsbenchmarks include the desktop and movie benchmark which are lacking abenchmark time since there is no time at which they finish. The desktop bench-mark represents a long running user session. The movie benchmark plays a700 MB movie until almost the end, at which point the VM is migrated in or-der to have a relatively large number of pages in the page cache. The moviebenchmark is similar to a desktop session, although the movie is playing andkeeps an active working set whereas a normal user session is more or less idle.Gzip compresses a large file of about 500 MB; this benchmark is both I/O andCPU-intensive. The Make benchmark compiles the Linux 2.6.32.60 kernel andrepresent a CPU-intensive benchmark. Copying a file and running Postmark
24

Benchmark DescriptionMovie Played a movie of about 700 MB.Desktop Four Libre Office Writer documents, each having file size of
about 10 MB. Firefox opened with 4 tabs. Music streamed.Essentially, long running VM user session.
Gzip Gzip a file of 512 MB random data.Make Linux 2.6.32.60 kernel compile with few modules and drivers.Copy Copied 1 GB of arbitrary data.Postmark Simulates and email server which performs numerous file op-
erations. The base number of files was 500 with 5,000,000transactions. Files ranged in size between 500 bytes and9.77 kilobytes.
Table 6.1: Benchmark Scenarios
are I/O-intensive loads. The copy benchmark copies a large file, and Postmarkis configured to create and use 500 files ranging from 500 bytes to 9.77 kilobytes,5,000,000 transactions performed with 512 bytes read or written. The bench-marks have been run five times and the average of these run has been averagedto reduce statistical anomalies.
6.2 Results
Migration Results
Figure 6.1 shows the total migration time in comparison to unmodified Xen.All results are normalized to unmodified Xen. The proposed technique clearlyoutperforms unmodified Xen in all benchmarks. The total migration time isreduced by 44% on average over these benchmarks. In general, there is also amodest increase in downtime, which can be easily explained by the extra syn-chronization step performed at the destination. The destination machine hasto remove access to all pages that should be loaded from disk, thereby makinga hypercall to the hypervisor. Additionally, a background process has to bestarted to load the pages in the background.
The user session benchmarks, desktop and movie reduce the total migrationtime by over 40% while keeping the downtime low as can be seen in Figure 6.1and Figure 6.2, respectively.
The comparison of the Copy 1024 benchmark to Copy 2048 illustrates an inter-esting phenomenon. The Copy 2048 benchmark seems to perform better thanthe Copy 1024. Table 6.1 shows that the Copy 1024 benchmark takes 100.45 onaverage and a total migration time of 100.67. This occurs because the bench-mark finishes before the migration is done. At the moment the benchmark
25
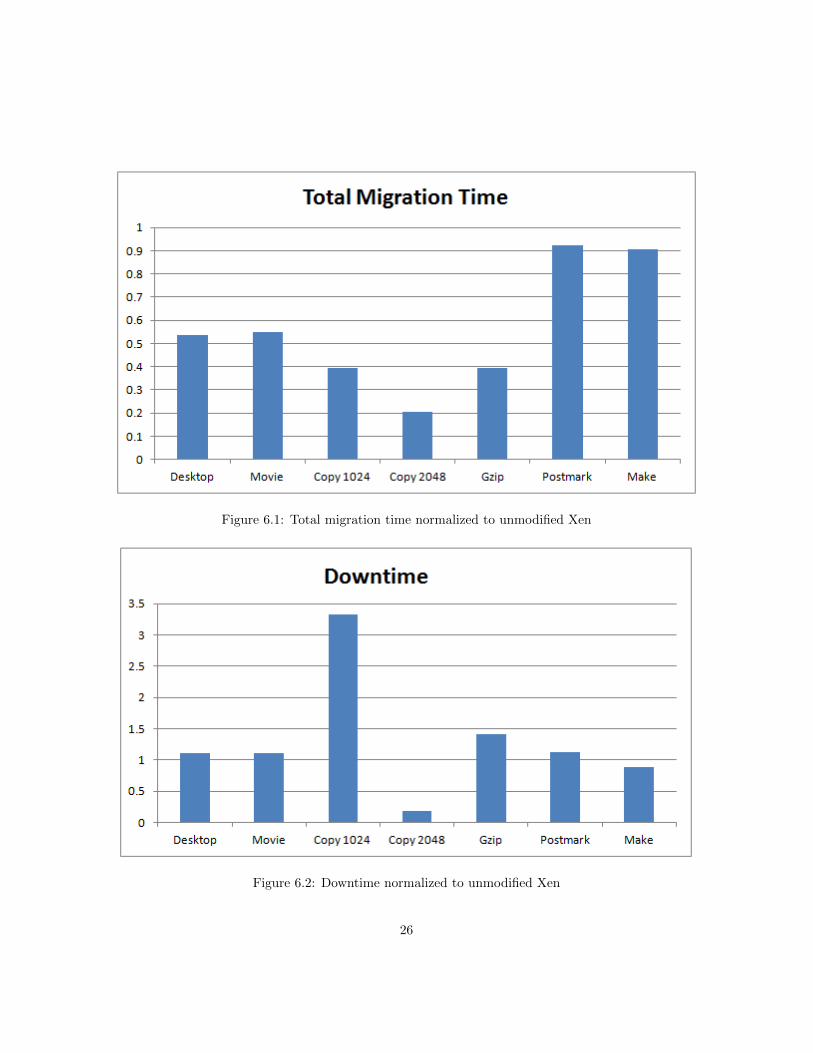
Figure 6.1: Total migration time normalized to unmodified Xen
Figure 6.2: Downtime normalized to unmodified Xen
26

completes, the working set is small enough to be immediately transferred tothe destination. The Copy 2048 demonstrates a bad case for unmodified Xenbecause it is a write intensive benchmark that does not finish during migration.Instead, write intensive applications like this show that pre-copy might neverfinish because in each iteration, enough pages are modified so that the workingset is not decreased. It finishes after a pre-defined number of iterations hasoccurred or if enough data has been sent over the network. Pre-copy simplysuspends the VCPU and transfers all pages, which is shown in the increaseddowntime compared to Copy 1024. However, the proposed solution reduces theworking set by not sending these pages over the network and quickly transferscontrol to the destination, shown by the decreased migration time. The down-time for the Copy 1024 benchmark increases for the proposed solution becauseit reduces the working set to a small enough size. When the working set is smallenough, the pre-copy algorithm issues a call to suspend the VM. During thetime until the VM is actually suspended, the VM modifies pages which are notincluded in the pfn to sec map. Thus, the number of pages that has to be sentover the network are increased compared to original Xen. This does not occurfor original Xen because the benchmark has already finished and the VM is idle.
For Gzip, the total migration time is reduced by about 60%. It increases thedowntime slightly more. This is explained by the same reasoning as why Copy1024 has a large increase in downtime compared to original Xen.
Postmark illustrates a benchmark where the proposed migration technique per-forms poorly due to that there is a small number of pages in the pfn to sec
map. There are a small number of pages in there because I/O is currently onlytracked on a page level granularity. The Postmark benchmark simulates anemail server which performs all I/O operations on small files with a sub-pagegranularity. These I/O requests which are smaller than the memory page sizeare currently not tracked and illustrates a weakness in this approach. Eventhough there a large page cache may exist in the VM, the hypervisor does nottrack I/O operations on this level.
Make has few pages in the page cache when the migration is started since themigration is started as soon as the kernel is compiling. It is also notable thatthe downtime decreases compared to original Xen. Like the Copy 2048 bench-mark this is due to the decreased working set that has to be transferred overthe network. On the other hand, this decreased downtime is just transferred tothe performance degradation once the machine has started.
Interesting to note from Figure 6.3 is that the proposed solution transmit lessdata compared to original Xen in certain cases. Original Xen (Org) is denotedas Org in the diagram, followed by the benchmark name. Similarly for the pro-posed solution (PS). The red portion proposed solution is the amount of dataread from disk and the blue the amount of pages sent over the network. Thediscrepancy between the original version and the proposed solution is explained
27

Figure 6.3: Total data transferred
by the fact that reading from disk only starts once the migration process hasended and a shorter migration time. Thereby, pages on disk that would havebeen sent several times are only read one time from disk after the VM hasresumed executing on the destination. The shorter total migration time also af-fects the amount of data sent across the network. This can be beneficial in datacenters since the congestion of the network decreases and less duplicate data istransferred. The reduction in data transferred does not linearly translate to anequal reduction in total migration time due to the adaptive rate limiting, thefirst iterations sends at a slower pace than the latter ones.
Figure ?? illustrates a test-run of Copy 2048. It depicts the number of pagessent across the network. The original version clearly continues far beyond theproposed solution and sends more pages as can be seen in Figure 6.3. It canbe inferred that one iteration is faster for the proposed solution since less datais sent in every iteration. Furthermore, since the proposed solution finisheseach iteration faster, there are less changes to be sent in subsequent iterationscompared to original Xen. Finally, there are small enough changes to migratethe machine which does not happen in the case of original Xen. Original Xensimply does a stops the VM and transfers its state to the destination sinceenough iterations has passed.
28
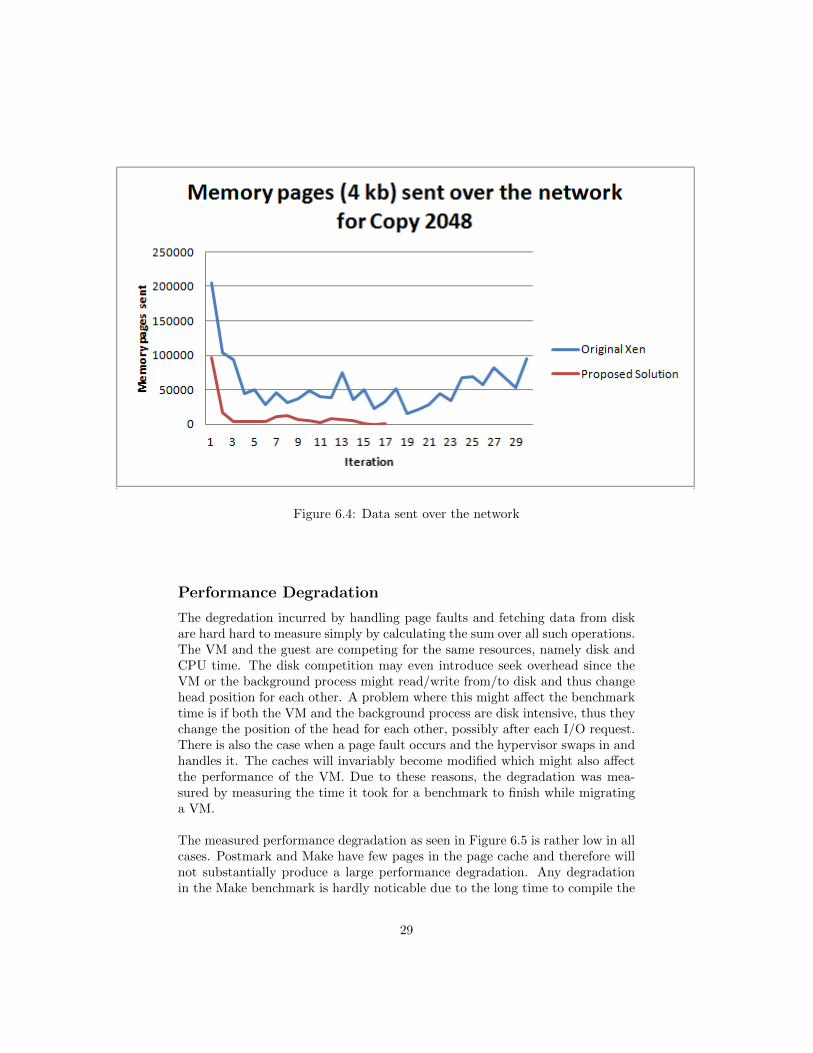
Figure 6.4: Data sent over the network
Performance Degradation
The degredation incurred by handling page faults and fetching data from diskare hard hard to measure simply by calculating the sum over all such operations.The VM and the guest are competing for the same resources, namely disk andCPU time. The disk competition may even introduce seek overhead since theVM or the background process might read/write from/to disk and thus changehead position for each other. A problem where this might affect the benchmarktime is if both the VM and the background process are disk intensive, thus theychange the position of the head for each other, possibly after each I/O request.There is also the case when a page fault occurs and the hypervisor swaps in andhandles it. The caches will invariably become modified which might also affectthe performance of the VM. Due to these reasons, the degradation was mea-sured by measuring the time it took for a benchmark to finish while migratinga VM.
The measured performance degradation as seen in Figure 6.5 is rather low in allcases. Postmark and Make have few pages in the page cache and therefore willnot substantially produce a large performance degradation. Any degradationin the Make benchmark is hardly noticable due to the long time to compile the
29
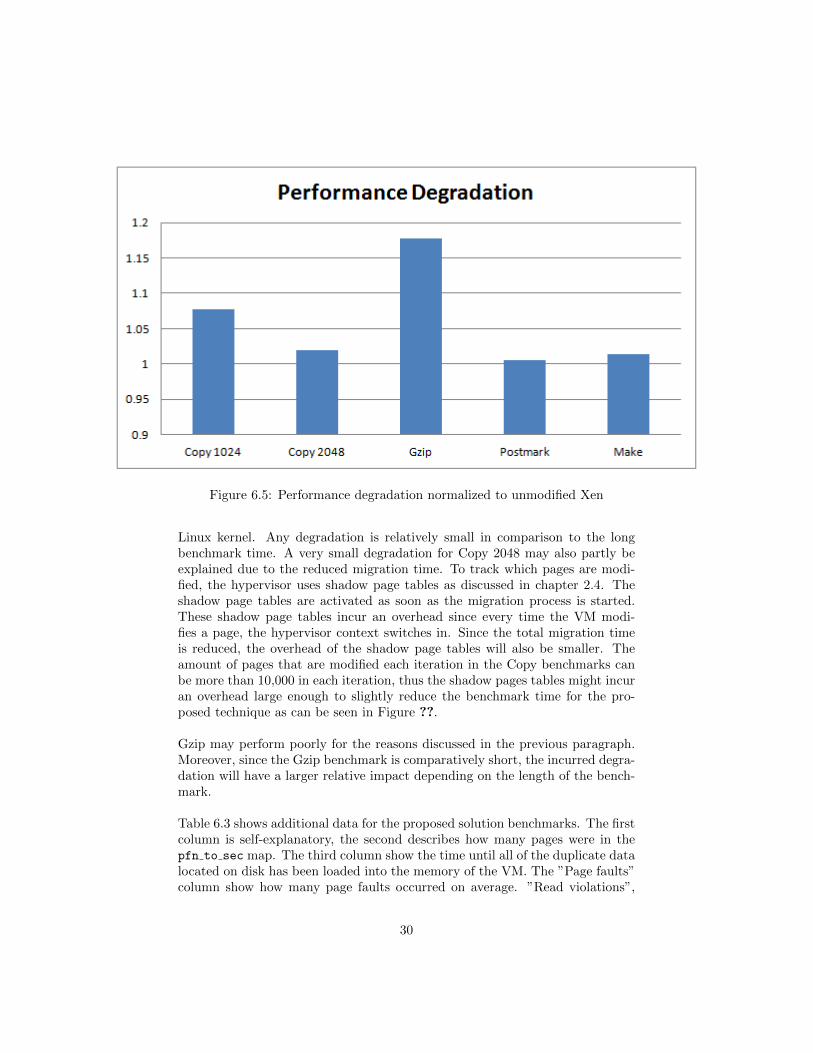
Figure 6.5: Performance degradation normalized to unmodified Xen
Linux kernel. Any degradation is relatively small in comparison to the longbenchmark time. A very small degradation for Copy 2048 may also partly beexplained due to the reduced migration time. To track which pages are modi-fied, the hypervisor uses shadow page tables as discussed in chapter 2.4. Theshadow page tables are activated as soon as the migration process is started.These shadow page tables incur an overhead since every time the VM modi-fies a page, the hypervisor context switches in. Since the total migration timeis reduced, the overhead of the shadow page tables will also be smaller. Theamount of pages that are modified each iteration in the Copy benchmarks canbe more than 10,000 in each iteration, thus the shadow pages tables might incuran overhead large enough to slightly reduce the benchmark time for the pro-posed technique as can be seen in Figure ??.
Gzip may perform poorly for the reasons discussed in the previous paragraph.Moreover, since the Gzip benchmark is comparatively short, the incurred degra-dation will have a larger relative impact depending on the length of the bench-mark.
Table 6.3 shows additional data for the proposed solution benchmarks. The firstcolumn is self-explanatory, the second describes how many pages were in thepfn to sec map. The third column show the time until all of the duplicate datalocated on disk has been loaded into the memory of the VM. The ”Page faults”column show how many page faults occurred on average. ”Read violations”,
30
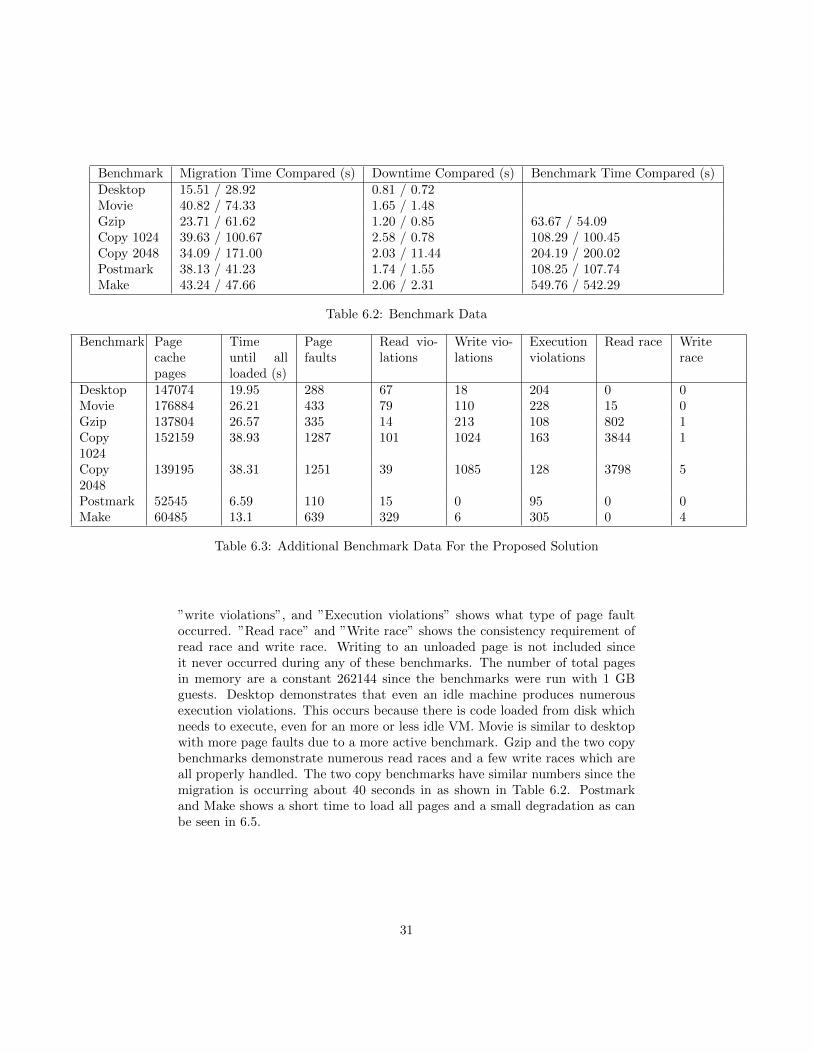
Benchmark Migration Time Compared (s) Downtime Compared (s) Benchmark Time Compared (s)Desktop 15.51 / 28.92 0.81 / 0.72Movie 40.82 / 74.33 1.65 / 1.48Gzip 23.71 / 61.62 1.20 / 0.85 63.67 / 54.09Copy 1024 39.63 / 100.67 2.58 / 0.78 108.29 / 100.45Copy 2048 34.09 / 171.00 2.03 / 11.44 204.19 / 200.02Postmark 38.13 / 41.23 1.74 / 1.55 108.25 / 107.74Make 43.24 / 47.66 2.06 / 2.31 549.76 / 542.29
Table 6.2: Benchmark Data
Benchmark Pagecachepages
Timeuntil allloaded (s)
Pagefaults
Read vio-lations
Write vio-lations
Executionviolations
Read race Writerace
Desktop 147074 19.95 288 67 18 204 0 0Movie 176884 26.21 433 79 110 228 15 0Gzip 137804 26.57 335 14 213 108 802 1Copy1024
152159 38.93 1287 101 1024 163 3844 1
Copy2048
139195 38.31 1251 39 1085 128 3798 5
Postmark 52545 6.59 110 15 0 95 0 0Make 60485 13.1 639 329 6 305 0 4
Table 6.3: Additional Benchmark Data For the Proposed Solution
”write violations”, and ”Execution violations” shows what type of page faultoccurred. ”Read race” and ”Write race” shows the consistency requirement ofread race and write race. Writing to an unloaded page is not included sinceit never occurred during any of these benchmarks. The number of total pagesin memory are a constant 262144 since the benchmarks were run with 1 GBguests. Desktop demonstrates that even an idle machine produces numerousexecution violations. This occurs because there is code loaded from disk whichneeds to execute, even for an more or less idle VM. Movie is similar to desktopwith more page faults due to a more active benchmark. Gzip and the two copybenchmarks demonstrate numerous read races and a few write races which areall properly handled. The two copy benchmarks have similar numbers since themigration is occurring about 40 seconds in as shown in Table 6.2. Postmarkand Make shows a short time to load all pages and a small degradation as canbe seen in 6.5.
31

6.3 Comparison with Other Methods
Lacking a standard benchmark suite for live migration, comparing results torelated work is difficult, especially since the migration time in this paper dependson the pages in the page cache. Based on the results other authors have achieved,this work is compared with the overall result of each of the following techniques.
6.3.1 Memory Compression
Jin et al. describes a technique which both reduces downtime and total migra-tion time by using an adaptive compression algorithm to decrease the amountof data sent over the network. They achieved an average reduction of 27% indowntime and 32% in migration time [10]. In terms of downtime, this tech-nique outperforms the page cache reduction technique described in this paper;however, not in the case of total migration time. These two techniques are or-thogonal to each other, meaning that they can be combined to facilitate evenlarger decreases in migration time. The slight increase in downtime can also bemitigated by using this compression method.
6.3.2 Post-Copy
Post-copy and the proposed technique share several characteristics. Both tech-niques invalidates a portion of the memory on the destination host when theguest starts. Additionally, both use a adaptive pre-paging algorithm to try tominimize the number of page faults; post-copy applies its algorithm to memorywhereas the page cache reduction technique applies a similar algorithm to thedisk. The post-copy technique achieves a 50% reduction in migration in somecases which is similar to the proposed and implemented technique in this paper.As in the case of the compression technique, the post-copy and page cache re-duction techniques can be combined to facilitate larger decreases in migrationtime.
6.3.3 Trace and Replay
Trace and replay introduced by [12] et al. reduces the total migration time upto 32% and downtime with 72%. This technique clearly outperforms the pagecache technique reduction technique when it comes to downtime but the reverseis true for total migration time. Unlike the other methods, this introduces anoverhead of 8% during the migration on the source machine in order to logall the events, and might increase the total migration time in certain cases asdiscussed in 3.3.4. The overhead incurred is similar to the page cache reductiontechnique on the source machine as opposed to on the destination. The traceand replay can also be combined with the technique develop in this thesis. Thetrace and replay algorithm begins by taking a checkpoint of the VM on thesource host which is transferred to the destination host. Only after will it begin
32

recording and replaying. This checkpoint can combined with the page cachereduction technique to further reduce the total migration time.
6.3.4 SonicMigration with Paravirtualized Guests
Koto et al. [11] managed to reduce the total migration time up to 68%. Thelarger reduction in migration time compared to this thesis can be explained bythat the ability of the kernel to communicate with the hypervisor, indicatingwhat memory pages are unused or free in the guest VM. This information isnot known in a fully virtualized environment since any allocation or dealloca-tion of memory within the guest cannot be known by the hypervisor. It ismentioned that a degradation occurs but it is not reported in any quantifiableway. However, since the page cache is invalidated, it is safe to assume that thedegradation is larger than the page cache reduction technique presented heresince this algorithm has to read all the page cache data from disk again.
33

7 Conclusion and Future Work
7.1 Conclusions
In this work, a solution has been proposed and implemented to efficiently mi-grate virtual machines. This method uses techniques from work on optimizedcheckpoints and efficient restoration of virtual machines applied to live migra-tion. An efficient migration time is achieved only by sending a critical set ofmemory pages over the network which are not present on disk. The discardedpages are loaded in the background while the VM is resumed on the new host.Accesses to pages that are not yet loaded are intercepted by the hypervisor witha page fault mechanism. The technique presented decreases the total migrationtime by 44% on average. There are still issues that require to be solved with thisapproach, and they are discussed in the next section. This reduction in totalmigration time can assist data centers to more efficiently utilize power man-agement, proactive fault tolerance, and load balancing capabilities of virtualmachine live migration.
7.2 Future Work
Future work includes exploring various strategies to improve upon this work.Reading from disk simultaneously at the destination, while the migration isoccurring can implemented to reduce the degradation once the guest resumes.This requires that write-after-read hazards be handled properly. Currently, thepfn to sec map records a mapping between the PFN and disk sector beforethe write request has been written to disk. This may create write-after-readrace conditions during the live migration. Consider the following scenario. Thesource host receives a request to write to sector x which is recorded in thepfn to sec map. This pfn to sec map is transmitted to the destination whichreads sector x from disk before the source has written write request data. Thiswill cause the destination to read invalid data. Thus, to solve this, the mappingin the pfn to sec map should only be recorded after the write has been com-mitted to disk. Asynchronous I/O presents a problem with caching on any levelin the source or the destination. An appropriate solution would be to flush alloutstanding writes when the migration begins and then only track read requeststo avoid the destination from reading inconsistent data.
34

The issue of increased downtime compared to original Xen should also be han-dled. This can be achieved by compressing data sent over the network sinceJin et al. managed to reduce the downtime with an adaptive compression algo-rithm. Before the VM is resumed, there is a synchronization step in which theaccess to unloaded pages is removed and a background process which shouldload the pages is started. This synchronization step can be reduced by startingthe background process during the migration. The downtime can also be re-duced by revoking access to pages in pfn to sec map continuously during themigration.
There is also the issue of improving the degradation. Different strategies withthe background process can be explored, such as prioritizing certain pages.Loading the most frequently used pages, or loading executable pages which con-tain code, as this may also decrease the degradation since there are numerouspage faults trying to execute from a page immediately after the VM is resumed,which currently even degrades an idle machine. Additionally, loading the mostrecently used pages in the MMU before any other pages may be superior to thetwo aforementioned solutions.
Other issues include tracking I/O requests on sub-page granularity to speed upapplications like email servers. This is why the Postmark benchmark performsrather poorly.
It is also worth investigating how much this approach helps with migrating sev-eral VMs at once, gang virtual machine live migration as in the case of [8]. Sinceless data is transmitted, the congestion of the network decreases which impliesthat more machines may be migrated simultaneously.
In essence, this technique has produced good results and can be further improvedupon, incorporated with other techniques, and explored in a variety of situations.
35

Bibliography
[1] Xen Hypervisor. http://www.xen.org. [Online; accessed 27-February-2013].
[2] AMD64 Virtualization Codenamed Pacifica Technology Secure Virtual Ma-chine Architecture Reference Manual, May 2005.
[3] Sherif Akoush, Ripduman Sohan, Andrew Rice, Andrew W. Moore, andAndy Hopper. Predicting the performance of virtual machine migration.In Proceedings of the 2010 IEEE International Symposium on Modeling,Analysis and Simulation of Computer and Telecommunication Systems,MASCOTS ’10, pages 37–46, Washington, DC, USA, 2010. IEEE Com-puter Society.
[4] Paul Barham, Boris Dragovic, Keir Fraser, Steven H, Tim Harris, Alex Ho,Rolf Neugebauer, Ian Pratt, and Andrew Warfield. Xen and the art ofvirtualization. In In SOSP (2003), pages 164–177, 2003.
[5] David Chisnall. The definitive guide to the xen hypervisor. Prentice HallPress, Upper Saddle River, NJ, USA, first edition, 2007.
[6] Christopher Clark, Keir Fraser, Steven H, Jacob Gorm Hansen, Eric Jul,Christian Limpach, Ian Pratt, and Andrew Warfield. Live migration ofvirtual machines. In In Proceedings of the 2nd ACM/USENIX Symposiumon Networked Systems Design and Implementation (NSDI, pages 273–286,2005.
[7] I.D. Craig. Virtual Machines. Springer-Verlag London, 2006.
[8] Umesh Deshpande, Xiaoshuang Wang, and Kartik Gopalan. Live gangmigration of virtual machines. In Proceedings of the 20th internationalsymposium on High performance distributed computing, HPDC ’11, pages135–146, New York, NY, USA, 2011. ACM.
[9] Michael R. Hines and Kartik Gopalan. Post-copy based live virtual ma-chine migration using adaptive pre-paging and dynamic self-ballooning. InProceedings of the 2009 ACM SIGPLAN/SIGOPS international conferenceon Virtual execution environments, VEE ’09, pages 51–60, New York, NY,USA, 2009. ACM.
36

[10] Hai Jin, Li Deng, Song Wu, Xuanhua Shi, and Xiaodong Pan. Live virtualmachine migration with adaptive, memory compression. In CLUSTER’09,pages 1–10, 2009.
[11] Akane Koto, Hiroshi Yamada, Kei Ohmura, and Kenji Kono. Towards un-obtrusive vm live migration for cloud computing platforms. In Proceedingsof the Third ACM SIGOPS Asia-Pacific conference on Systems, APSys’12,pages 7–7, Berkeley, CA, USA, 2012. USENIX Association.
[12] Haikun Liu, Hai Jin, Xiaofei Liao, Liting Hu, and Chen Yu. Live migrationof virtual machine based on full system trace and replay. In Proceedingsof the 18th ACM international symposium on High performance distributedcomputing, HPDC ’09, pages 101–110, New York, NY, USA, 2009. ACM.
[13] Arun Babu Nagarajan, Frank Mueller, Christian Engelmann, andStephen L. Scott. Proactive fault tolerance for hpc with xen virtualization.In Proceedings of the 21st annual international conference on Supercom-puting, ICS ’07, pages 23–32, New York, NY, USA, 2007. ACM.
[14] Ripal Nathuji and Karsten Schwan. Virtualpower: coordinated powermanagement in virtualized enterprise systems. SIGOPS Oper. Syst. Rev.,41(6):265–278, October 2007.
[15] Eunbyung Park, Bernhard Egger, and Jaejin Lee. Fast and space-efficientvirtual machine checkpointing. In Proceedings of the 7th ACM SIG-PLAN/SIGOPS international conference on Virtual execution environ-ments, VEE ’11, pages 75–86, New York, NY, USA, 2011. ACM.
[16] Gerald J. Popek and Robert P. Goldberg. Formal requirements for virtual-izable third generation architectures. Commun. ACM, 17(7):412–421, July1974.
[17] A. Silberschatz, G. Gagne, and P.B. Galvin. Operating System Concepts.Wiley, 2011.
[18] Richard L. Sites, Anton Chernoff, Matthew B. Kirk, Maurice P. Marks,and Scott G. Robinson. Binary translation. Communication of the ACM,1993.
[19] C. Takemura and L.S. Crawford. The Book of Xen: A Practical Guide forthe System Administrator. No Starch Press Series. No Starch Press, 2009.
[20] Rich Uhlig, Gil Neiger, Dion Rodgers, Amy L. Santoni, Fernando C. M.Martins, Andrew V. Anderson, Steven M. Bennett, Alain Kagi, Felix H. Le-ung, and Larry Smith. Intel virtualization technology. Computer, 38(5):48–56, May 2005.
[21] Irene Zhang, Alex Garthwaite, Yury Baskakov, and Kenneth C. Barr. Fastrestore of checkpointed memory using working set estimation. SIGPLANNot., 46(7):87–98, March 2011.
37

[22] Yi Zhao and Wenlong Huang. Adaptive distributed load balancing algo-rithm based on live migration of virtual machines in cloud. In Proceedingsof the 2009 Fifth International Joint Conference on INC, IMS and IDC,NCM ’09, pages 170–175, Washington, DC, USA, 2009. IEEE ComputerSociety.
38
Related Documents











