Chicago ©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved Enterprise Pre-Day

Optimizing Costs and Efficiency of AWS Services
Aug 04, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Chicago
©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved
Enterprise Pre-Day

Do you • Wear green eye-shades? • Work from the console?

You’re using AWS. You like it.

But maybe you are spending more than you planned

Or you’d just like to spend less

What should you do?

How about some
frameworks

Some tools

Some best practices

And some examples from other customers
like you

How are you controlling the provisioning of
resources?

Control who can provision resources

Require tagging

“No tags? No instance” – Large financial services customer in Boston

Best practices: • Control who can provision
resources via IAM • Require tagging
– Inspect – Stop instances without tags

Savings potential
100% if you don’t start instances you don’t need!

Are you identifying and terminating idle
resources?

How do I identify idle resources?

AWS Trusted Advisor runs 100+ configuration
checks and recommends savings

Trusted Advisor Demo

We are using AWS Trusted Advisor to improve cost efficiency and to audit
the configurations of service platforms

Trusted Advisor

How do I handle demand spikes?

Design for elasticity rather than deploy for
peak

Use Auto Scaling or queue-based approaches
to add resources when needed, and turn them
off when not
Amazon SQS Queue
Auto Scaling

Problem: Workloads arrive asynchronously and require isolation
Solution: Amazon
Simple Queue Service and launch/
termination of instances
Amazon SQS

Problem: How to scale up to accommodate sudden traffic
spikes?
Solution: Auto Scaling Auto Scaling

Auto Scaling real world example • Baseline traffic: 300+ thousand pages / hour
130 TB/month outbound traffic • Peak: 2.0+ million pages / hour (~7x baseline)
• Architectural changes: e.g., move from local SSDs to provisioned IOPS needed due to this scale
• Auto Scaling provides 23% savings over three years

Best practices • Identify idle resources using Trusted
Advisor • Turn them off
• Design to scale up and scale down using Auto Scaling or a queue-based approach
• Match your usage and capacity — don’t pay for idle resources!

Are you using the most cost-effective
instances or resources?

Match resources to
workload

How can I tell if there’s a match or mismatch?

Use Amazon CloudWatch to
collect and track metrics
CloudWatch

Amazon CloudWatch monitoring Basic • 7 metrics for Amazon EC2
including: – CPU utilization – Data transfer – Disk usage and more
• 5-minute frequency • Metrics for Amazon EBS,
Amazon DynamoDB, Amazon RDS, etc.
Detailed • 1-minute frequency • Aggregation by instance type and
AMI

Why does this matter?

Different instances cost different amounts

Instance families: Example Instance vCPU Mem
(GiB) Monthly price (3-yr AURI )
Ideal use case
c4.2xlarge 8 15 $125.44 Best price-compute performance
m4.2xlarge 8 32 $137.25 Balanced
r3.2xlarge 8 61 $179.25 Lowest cost per GiB RAM
r3.xlarge 4 30.5 $89.61 Lowest cost per GiB RAM

Do you need continuous compute
or does bursting work for you?

t2.medium • 4 GiB RAM • Baseline performance: 40% • Bursts beyond this based on CPU
credits • Less than $17 per month • Details: http://amzn.to/1sl2bKa • Web servers, dev, small databases
t2

m3.medium
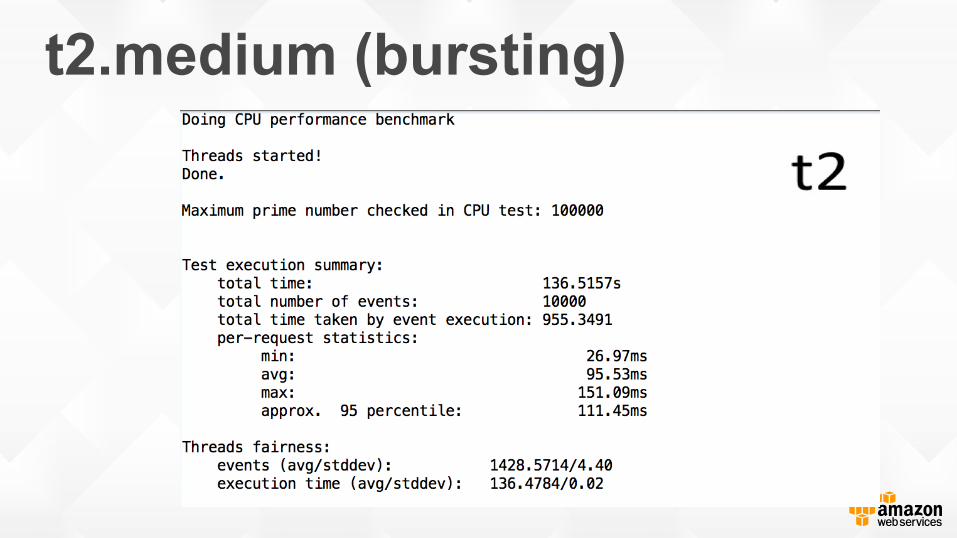
t2.medium (bursting)

Cloudwatch: CPU Utilization

t2 vs m3.medium or c4.large Instance vCPU Mem
(GiB) Monthly price (3-yr AURI )
Ideal use case
m3.medium 1 3.75 $19.08 Always available, balanced
c4.large 2 3.75 $31.36 Always available, compute
t2.medium 2 4 $16.86 Bursty workloads

Consider switching to a t2?

Guidance • Inspect your workloads (use CloudWatch!) • Can your workload run on a t2? • If not, is it memory intensive? àr3 • Is it compute intensive? à c4
• Others to consider: – i2 for storage-optimized – g2 for GPU



Savings potential If t2 works for you • 11%: Switch from m3.medium to t2.medium • 46%: Switch from c3.large to t2.medium Instance optimization • 9%: Switch to c4 for compute-intensive apps
(m4.2xl -> c4.2xl) • 35%: Switch to r3 for memory-intensive apps
(m4.2xl -> r3.xlarge)

Best practices: 1. Monitor instances with CloudWatch 2. Switch to t2 as possible 3. Use compute- and memory-focused instances as needed

Do you need long-term storage?

Amazon Glacier Extremely low-cost cloud
storage service
Amazon Glacier

Are you purchasing in the most cost-
effective way?

Commitment and spot save $

Use Reserved Instances if possible:
Up to 60% savings + capacity reservation

AWS Trusted Advisor identifies savings
attainable via Reserved Instancess

Reserved Instance Marketplace

Use Spot Instances for non-stateful workloads
Pricing starts
at 90% off

Novartis, Cycle Computing & AWS Spot Instances

Goal: Screen 10 million compounds
against a common cancer target in < 1 week

10,600 AWS instances

39 drug design years in 11 hours

3 promising compounds identified

Cost of $4,232

Savings potential • ~40%: 1-Year Reserved
Instances • ~60%: 3-Year Reserved
Instances • Up to 90%: Spot Instances

Could you save by letting AWS do more
work for you?

Focus on what you do best

Let AWS solve other problems for you

AWS’s higher-level services automate your work and save
you money CloudFront
DynamoDB
Amazon RDS
ElastiCache
Amazon Redshift
Amazon EMR
Amazon Kinesis
Amazon WorkSpaces

Are you modeling and monitoring your
spend?

https://calculator.s3.amazonaws.com/index.html

Detailed billing reports and
cost insights
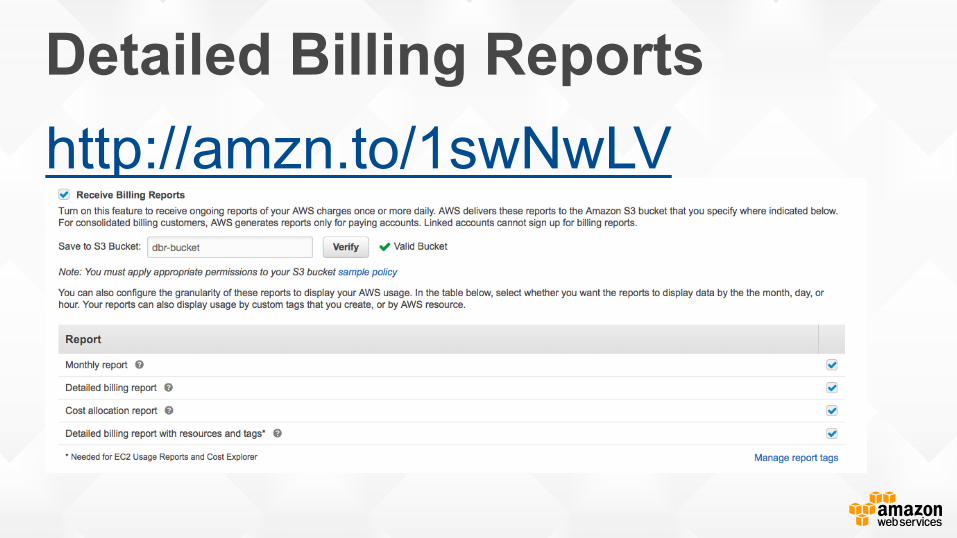
Detailed Billing Reports http://amzn.to/1swNwLV

Cost Explorer http://amzn.to/1zHE2Fj
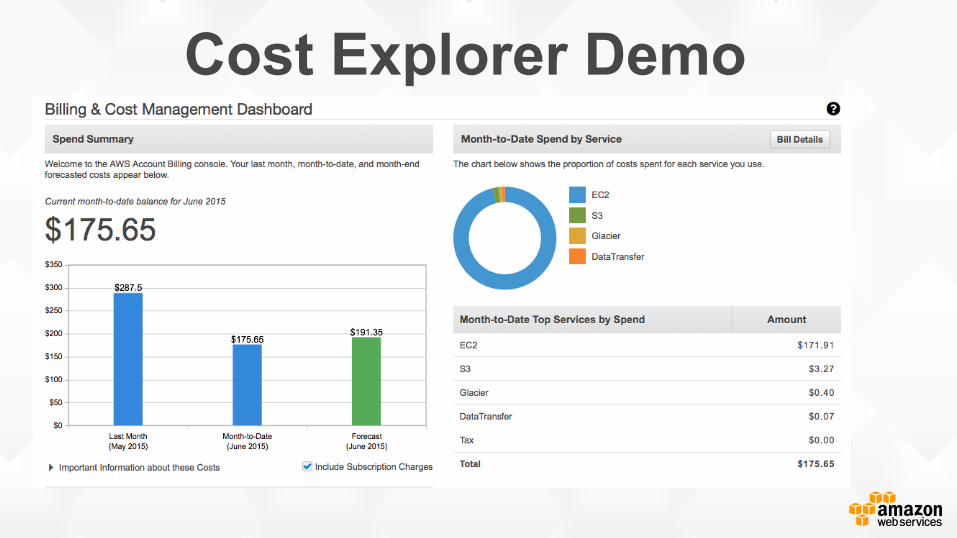
Cost Explorer Demo

Forecasting Demo

Budgeting Demo

Demo
CloudWatch




• Control and verify • Design for elasticity • Match resources and
workload • Purchase for savings • Use application
services • Model and track
Frameworks to remember

Tools to use • IAM, AWS console • Auto Scaling,
Amazon SQS • Amazon CloudWatch • AWS Trusted Advisor • Detailed billing reports
and Cost Explorer • Partners

• Turn off untagged resources • Stop idle instances • Use instances matched to task
and less expensive ones • Baseload with RIs • Use Spot Instances for non-
stateful workloads • Model and track spending
Best practices

Chicago
©2015, Amazon Web Services, Inc. or its affiliates. All rights reserved
Enterprise Pre-Day
Related Documents











