Optimizing 27-point Stencil on Multicore Kaushik Datta, Samuel Williams, Vasily Volkov, Jonathan Carter , Leonid Oliker, John Shalf, and Katherine Yelick CRD/NERSC, Berkeley Lab EECS, University of California, Berkeley [email protected] iWAPT 2009 October 1-2 2009

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Optimizing 27-point Stencil on
MulticoreKaushik Datta, Samuel Williams, Vasily Volkov,
Jonathan Carter, Leonid Oliker, John Shalf, and
Katherine Yelick
CRD/NERSC, Berkeley Lab
EECS, University of California, Berkeley
iWAPT 2009
October 1-2 2009
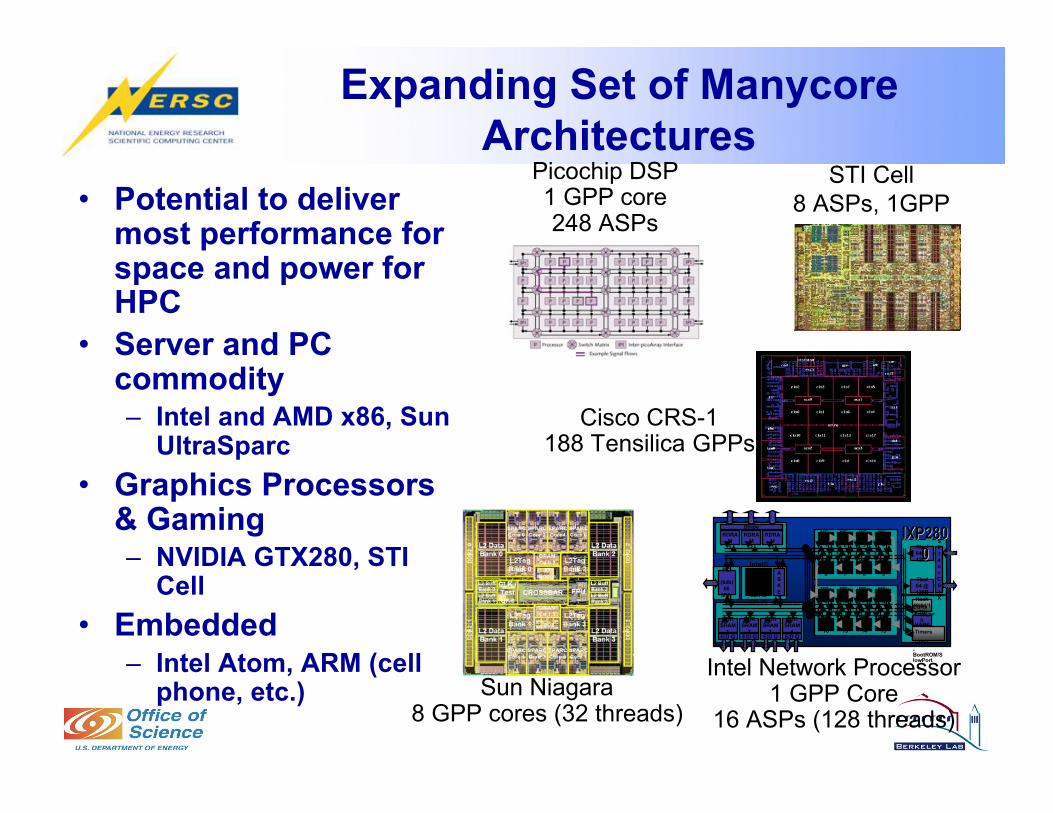
Expanding Set of Manycore
Architectures
• Potential to delivermost performance forspace and power forHPC
• Server and PCcommodity– Intel and AMD x86, Sun
UltraSparc
• Graphics Processors& Gaming– NVIDIA GTX280, STI
Cell
• Embedded– Intel Atom, ARM (cell
phone, etc.)
Picochip DSP1 GPP core248 ASPs
Cisco CRS-1188 Tensilica GPPs
Sun Niagara8 GPP cores (32 threads)
Intel®
XScale
™
Core32K IC
32K DC
MEv2
10
MEv2
11
MEv2
12
MEv
2
15
MEv
2
14
MEv
2
13
Rbuf
64 @
128B
Tbuf
64 @
128B
Hash
48/64/1
28Scratc
h16KB
QDR
SRAM
2
QDR
SRAM
1
RDRA
M1
RDRA
M3
RDRA
M2
G
AS
K
E
T
PCI
(64b)
66
MHz
IXP280IXP280
00 16b16b
16b16b
11
88
11
88
11
88
11
88
11
88
11
88
11
88
64b64b
S
P
I
4o
r
C
S
IX
Stripe
E/D Q E/D Q
QDR
SRAM
3E/D Q11
88
11
88
MEv2
9
MEv
2
16
MEv2
2
MEv2
3
MEv2
4
MEv
27
MEv
26
MEv
25
MEv2
1
MEv
28
CSRs
-Fast_wr
-UART
-Timers
-GPIO
-BootROM/SlowPort
QDR
SRAM
4E/D Q11
88
11
88
Intel Network Processor1 GPP Core
16 ASPs (128 threads)
STI Cell
8 ASPs, 1GPP

Auto-tuning
• Problem: want to obtain andcompare best potentialperformance of diversearchitectures, avoiding– Non-portable code
– Labor-intensive user optimizations foreach specific architecture
• A Solution: Auto-tuning– Automate search across a
complex optimization space
– Achieve performance far beyondcurrent compilers
– Achieve performance portabilityfor diverse architectures Reference
Best: 4x2
Mflop/s
Mflop/s
For finite element problem (BCSR)
[Im, Yelick, Vuduc, 2005]

Maximizing
Memory Bandwidth
•Exploit NUMA
•Hide memory latency
•Satisfy Little’s Law
?memory
affinity ?SW
prefetch
?DMA
lists
?unit-stride
streams
?TLB
blocking
Optimization Categorization
Minimizing
Memory Traffic
Eliminate:
•Capacity misses
•Conflict misses
•Compulsory misses
•Write allocate behavior
?cache
blocking
?array
padding
?compress
data?streaming
stores
Maximizing
In-core Performance
•Exploit in-core parallelism
(ILP, DLP, etc…)
•Good (enough)
floating-point balance
?unroll &
jam
?explicit
SIMD
?reorder
?eliminate
branches
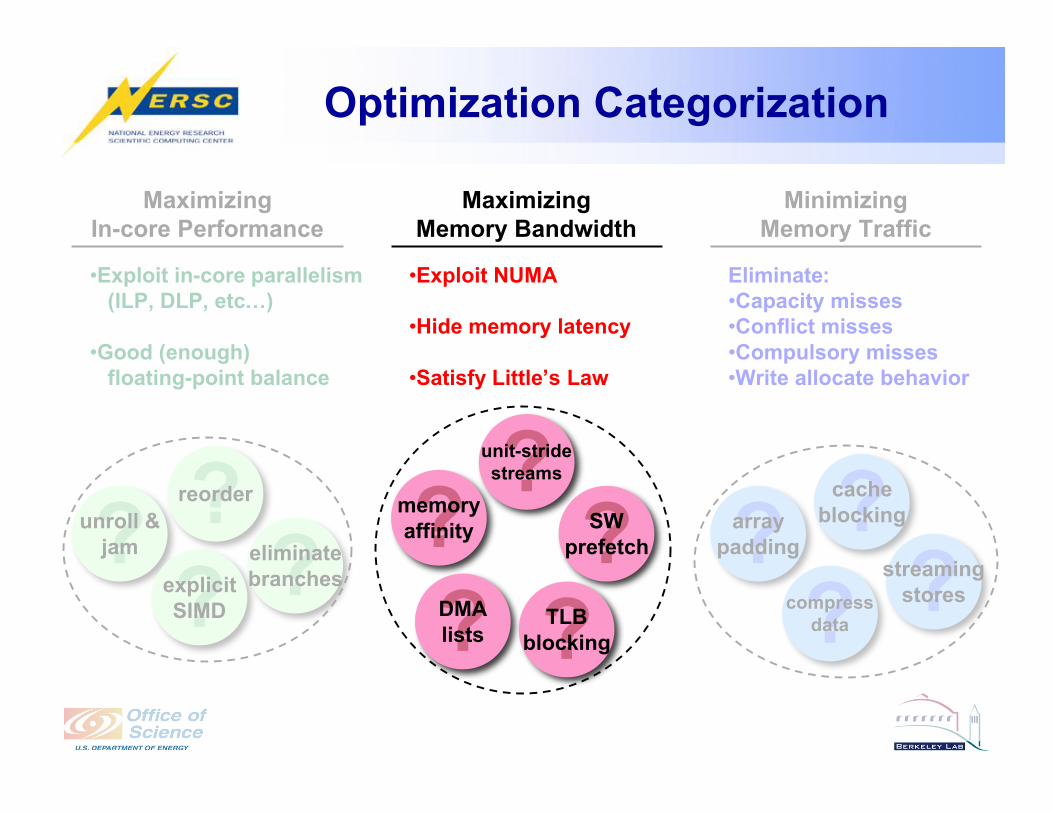
Optimization Categorization
Maximizing
In-core Performance
Minimizing
Memory Traffic
•Exploit in-core parallelism
(ILP, DLP, etc…)
•Good (enough)
floating-point balance
?unroll &
jam
?explicit
SIMD
?reorder
?eliminate
branches
Eliminate:
•Capacity misses
•Conflict misses
•Compulsory misses
•Write allocate behavior
?cache
blocking
?array
padding
?compress
data?streaming
stores
Maximizing
Memory Bandwidth
•Exploit NUMA
•Hide memory latency
•Satisfy Little’s Law
?memory
affinity ?SW
prefetch
?DMA
lists
?unit-stride
streams
?TLB
blocking

Optimization Categorization
Maximizing
In-core Performance
Maximizing
Memory Bandwidth
•Exploit in-core parallelism
(ILP, DLP, etc…)
•Good (enough)
floating-point balance
?unroll &
jam
?explicit
SIMD
?reorder
?eliminate
branches
•Exploit NUMA
•Hide memory latency
•Satisfy Little’s Law
?memory
affinity ?SW
prefetch
?DMA
lists
?unit-stride
streams
?TLB
blocking
Minimizing
Memory Traffic
Eliminate:
•Capacity misses
•Conflict misses
•Compulsory misses
•Write allocate behavior
?cache
blocking
?array
padding
?compress
data?streaming
stores

Optimization Categorization
Maximizing
In-core Performance
Minimizing
Memory Traffic
Maximizing
Memory Bandwidth
•Exploit in-core parallelism
(ILP, DLP, etc…)
•Good (enough)
floating-point balance
?unroll &
jam
?explicit
SIMD
?reorder
?eliminate
branches
•Exploit NUMA
•Hide memory latency
•Satisfy Little’s Law
?memory
affinity ?SW
prefetch
?DMA
lists
?unit-stride
streams
?TLB
blocking
Eliminate:
•Capacity misses
•Conflict misses
•Compulsory misses
•Write allocate behavior
?cache
blocking
?array
padding
?compress
data?streaming
stores

Optimization Categorization
Maximizing
In-core Performance
Minimizing
Memory Traffic
Maximizing
Memory Bandwidth
•Exploit in-core parallelism
(ILP, DLP, etc…)
•Good (enough)
floating-point balance
?unroll &
jam
?explicit
SIMD
?reorder
?eliminate
branches
•Exploit NUMA
•Hide memory latency
•Satisfy Little’s Law
?memory
affinity ?SW
prefetch
?DMA
lists
?unit-stride
streams
?TLB
blocking
Eliminate:
•Capacity misses
•Conflict misses
•Compulsory misses
•Write allocate behavior
?cache
blocking
?array
padding
?compress
data?streaming
stores
Each optimization has
a large parameter space
What are the optimal parameters?

Traversing the Parameter Space
Opt. #1 Parameters
Op
t. #
2 P
ara
me
ters
Opt
. #3
Par
amet
ers
• Exhaustive search of these complex layered
optimizations is impossible
• To make problem tractable, we:
• order the optimizations
• applied them consecutively
• Every platform had its own set of best parameters

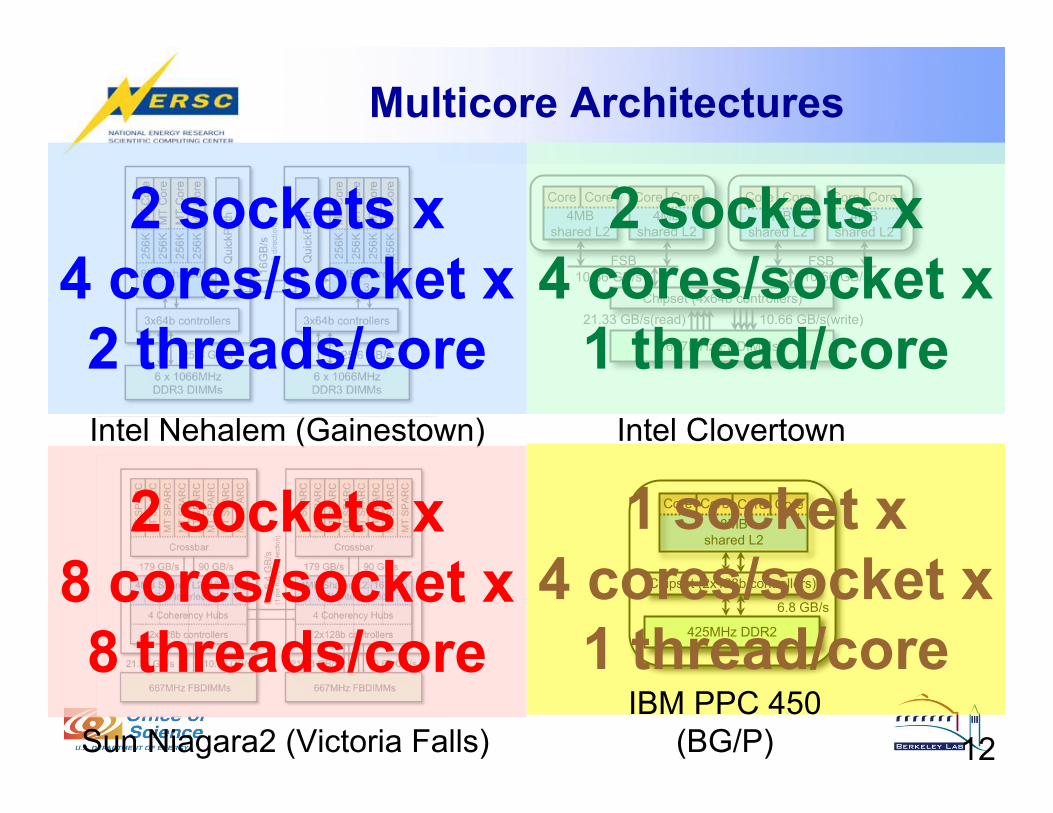
Multicore Architectures
Intel Nehalem (Gainestown) Intel Clovertown
Sun Niagara2 (Victoria Falls) 10
667MHz FBDIMMs
Chipset (4x64b controllers)
10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core
4MB
shared L2
4MB
shared L24MB
shared L2
4MB
shared L2
Core Core
8MB
shared L2
Core Core
425MHz DDR2
Chipset (2x128b controllers)
6.8 GB/s
IBM PPC 450
(BG/P)

Multicore Architectures
Intel Nehalem (Gainestown) Intel Clovertown
Sun Niagara2 (Victoria Falls) 11
667MHz FBDIMMs
Chipset (4x64b controllers)
10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core
4MB
shared L2
4MB
shared L24MB
shared L2
4MB
shared L2
Core Core
8MB
shared L2
Core Core
425MHz DDR2
Chipset (2x128b controllers)
6.8 GB/s
Chip
MultiThreaded
(CMT)
x86
Superscalar
x86
Superscalar/
CMT
PPC
Dual-issue
in-orderIBM PPC 450
(BG/P)
Multicore Architectures
Intel Nehalem (Gainestown) Intel Clovertown
Sun Niagara2 (Victoria Falls) 12
667MHz FBDIMMs
Chipset (4x64b controllers)
10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core
4MB
shared L2
4MB
shared L24MB
shared L2
4MB
shared L2
Core Core
8MB
shared L2
Core Core
425MHz DDR2
Chipset (2x128b controllers)
6.8 GB/s
1 socket x
4 cores/socket x
1 thread/core
2 sockets x
8 cores/socket x
8 threads/core
2 sockets x
4 cores/socket x
1 thread/core
2 sockets x
4 cores/socket x
2 threads/core
IBM PPC 450
(BG/P)

Multicore Architectures
Intel Nehalem (Gainestown) Intel Clovertown
Sun Niagara2 (Victoria Falls) 13
667MHz FBDIMMs
Chipset (4x64b controllers)
10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core
4MB
shared L2
4MB
shared L24MB
shared L2
4MB
shared L2
Core Core
8MB
shared L2
Core Core
425MHz DDR2
Chipset (2x128b controllers)
6.8 GB/s
34 GB/s 7 GB/s
23 GB/s 12 GB/s
IBM PPC 450
(BG/P)

Multicore Architectures
Intel Nehalem (Gainestown) Intel Clovertown
Sun Niagara2 (Victoria Falls) 14
667MHz FBDIMMs
Chipset (4x64b controllers)
10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core
4MB
shared L2
4MB
shared L24MB
shared L2
4MB
shared L2
Core Core
8MB
shared L2
Core Core
425MHz DDR2
Chipset (2x128b controllers)
6.8 GB/s
85 Gflop/s
14 Gflop/s
85 Gflop/s
19 Gflop/s
IBM PPC 450
(BG/P)

Multicore Architectures
Intel Nehalem (Gainestown) Intel Clovertown
Sun Niagara2 (Victoria Falls) 15
667MHz FBDIMMs
Chipset (4x64b controllers)
10.66 GB/s(write)21.33 GB/s(read)
10.66 GB/s
Core
FSB
Core Core Core
10.66 GB/s
Core
FSB
Core Core Core
4MB
shared L2
4MB
shared L24MB
shared L2
4MB
shared L2
Core Core
8MB
shared L2
Core Core
425MHz DDR2
Chipset (2x128b controllers)
6.8 GB/s
530 W
31 W
375 W
610 W
IBM PPC 450
(BG/P)

Stencil Code Overview
• For a given point, a stencil is afixed subset of nearestneighbors
• A stencil code updates everypoint in a regular grid by“applying a stencil”
• Used in iterative PDE solvers likeJacobi, Multigrid, and AMR
• Focus on a out-of-place 3D 27-point stencil sweeping over a2563 grid
– Problem size > Cache size
• Stencil codes characteristics
– Long unit-stride memoryaccesses
– Some reuse of each grid point
– 30 flops per grid point
– Arithmetic Intensity 0.75-1.88Adaptive Mesh Refinement (AMR)

Naïve Stencil Code
• We wish to exploit multicore resources
• Simple parallel stencil code:
– Use pthreads
– Parallelize in least contiguous grid dimension
– Thread affinity for scaling: multithreading, then multicore,
then multisocket
x
y
z (unit-stride)
2563 regular grid
Thread 0
Thread 1
Thread n
…
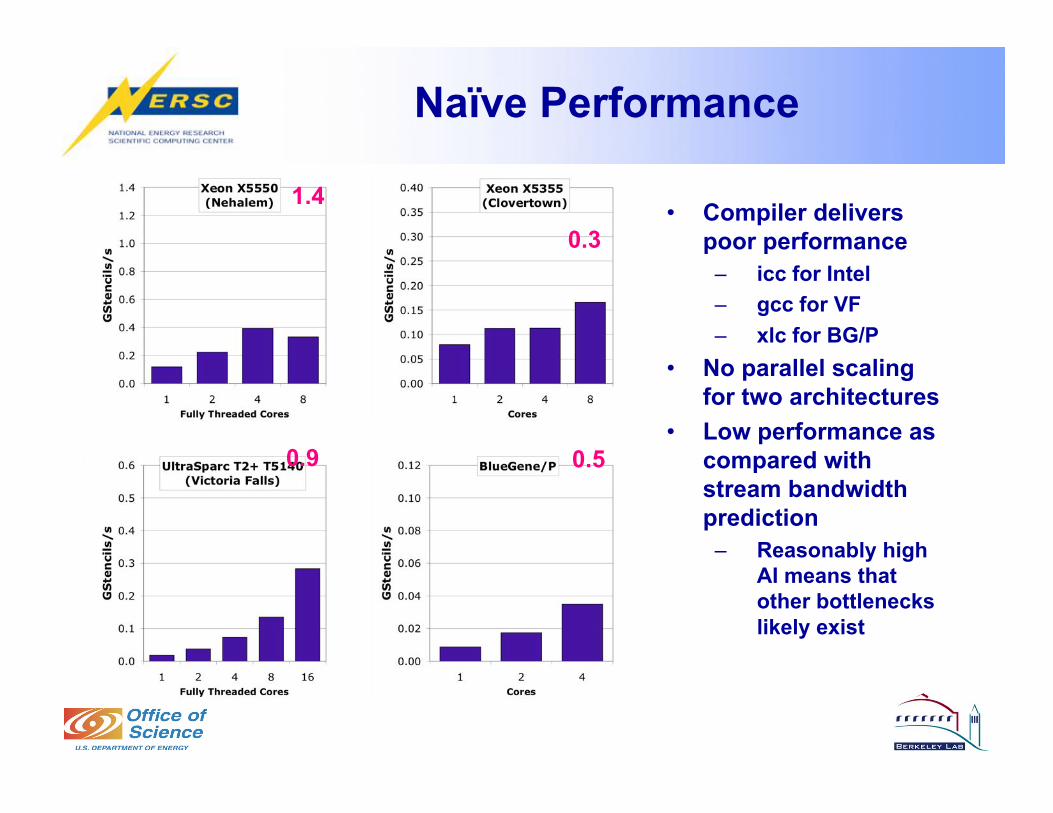
Naïve Performance
1.4
0.3
0.9 0.5
• Compiler delivers
poor performance
– icc for Intel
– gcc for VF
– xlc for BG/P
• No parallel scaling
for two architectures
• Low performance as
compared with
stream bandwidth
prediction
– Reasonably high
AI means that
other bottlenecks
likely exist

NUMA Optimization
20
! All DRAMs are highlighted in red
! Co-located data on same socket as
thread processing it

Array Padding Optimization
• Conflict misses may occur on low-associativity
caches
• Each array was padded by a tuned amount to
minimize conflicts
x
y
z (unit-stride)
2563 regular grid
Thread 0
Thread 1
Thread n
…
padding

Performance
+ Array Padding
+ NUMA
Naive

Problem Decomposition
+Y
+Z
Decomposition of the Grid
into a Chunk of Core Blocks
+X
(unit stride)NYN
Z
NX
• Large chunks enable
efficient NUMA Allocation
• Small chunks exploit LLC
shared caches
Decomposition into
Thread Blocks
CY
CZ
CX
TYTX
• Exploit caches shared
among threads within a
core
Decomposition into
Register Blocks
RY
TY
CZ
TX
RXRZ
• Make DLP/ILP explicit
• Make register reuse
explicit
• This decomposition is universal across all examined architectures
• Decomposition does not change data structure
• Need to choose best block sizes for each hierarchy level

Performance
+ Thread Blocking
+ Register Blocking
+ Core Blocking
+ Array Padding
+ NUMA
Naive
1.4
0.3
0.9 0.5

ISA Specific Optimizations
• Software prefetch
• Explicit SIMD– PPC SIMD loads do
not improveperformance due tounaligned data
• Cache Bypass– Initial values in write
array not used
– Eliminate write arraycache fills withintrinsics
– Reduces memorytraffic from 24 B/pointto 16 B/point
Write
Array
DRAM
Read
ArrayChip
8 B/point read
8 B/point write
8 B/point read

Performance
+ Cache Bypass
+ SIMD
+ Thread Blocking
+ Software Prefetch
+ Register Blocking
+ Core Blocking
+ Array Padding
+ NUMA
Naive
• Optimizations effect
architectures in different
ways

Common Subexpression
Elimination Optimization
• Common computation exists between
different stencil updates
• Compiler does not recognize this
• Reduce number of flops from 30 to 18

CSE Version Performance
+ Cache Bypass
+ SIMD
+ Thread Blocking
+ Software Prefetch
+ Register Blocking
+ Core Blocking
+ Array Padding
+ NUMA
Naive
+ CSE

Is Performance Acceptable?
• A model (e.g. Roofline) could be used to
predict best performance
• Use a two-pass greedy algorithm

Second Pass Performance
+ Cache Bypass
+ SIMD
+ Thread Blocking
+ Software Prefetch
+ Register Blocking
+ Core Blocking
+ Array Padding
+ NUMA
Naive
+ CSE
+ Second Pass

Tuning Speedup
3.6x 1.9x
2.9x1.8x
• Speedup at maximum
concurrency

Parallel Speedup
8.1x 2.7x
4.0x13.1x
• Speedup going from a single
core to maximum
concurrency
• All architectures now scale

Effect of compilers
• icc is consistently
better than gcc
• For single socket gcc +
register blocking has
equivalent performance
to icc
• Core blocking improves
icc performance, but
not gcc
– Inferior code
generation hides
memory bottleneck?

Performance Comparison
• Intel Nehalem best
in absolute
performance
• Normalize for low
power, BG/P
solution is much
more attractive

Conclusions
• Compiler alone achieves poor performance
– Low fraction possible performance
– Often no parallel scaling
• Autotuning is essential to achieving good
performance
– 1.8x-3.6x speedups across diverse architectures
– Automatic tuning is necessary for scalability
– Most optimization with the same code base
• Clovertown required SIMD (hampers productivity) for
best performance
• When power consumption is taken into account,
BG/P performs well

Acknowledgements
• UC Berkeley
– RADLab Cluster (Nehalem)
– PSI cluster(Clovertown)
• Sun Microsystems
– Niagara2 donations
• ASCR Office in the DOE Office of Science
– contract DE-AC02-05CH11231
Related Documents











