Optimized K-means (OKM) clustering algorithm for image segmentation F.U. SIDDIQUI * and N.A. MAT ISA School of Electrical & Electronic Engineering, Universiti Sains Malaysia, 14300, Nibong Tebal, Penang, Malaysia This paper presents the optimized K−means (OKM) algorithm that can homogenously segment an image into regions of inter− est with the capability of avoiding the dead centre and trapped centre at local minima phenomena. Despite the fact that the previous improvements of the conventional K−means (KM) algorithm could significantly reduce or avoid the former problem, the latter problem could only be avoided by those algorithms, if an appropriate initial value is assigned to all clusters. In this study the modification on the hard membership concept as employed by the conventional KM algorithm is considered. As the process of a pixel is assigned to its associate cluster, if the pixel has equal distance to two or more adjacent cluster centres, the pixel will be assigned to the cluster with null (e. g., no members) or to the cluster with a lower fitness value. The qualita− tive and quantitative analyses have been performed to investigate the robustness of the proposed algorithm. It is concluded that from the experimental results, the new approach is effective to avoid dead centre and trapped centre at local minima which leads to producing better and more homogenous segmented images. Keywords: K−means based clustering; image segmentation; dead centre problem; trapped centre problem; optimized K−means. 1. Introduction Image segmentation is a process of partitioning an image into homogenous regions of interest. Amongst different algorithms for image segmentation, the unsupervised cen− tre−based clustering algorithms are widely used in computer vision and many other applications [1–10]. In a clustering area, the K−means (KM) algorithm is an iterative conven− tional method which is familiar for its low execution time and easy implementation. The KM algorithm begins with initializing the cluster centres value and is followed by iteratively refining their value until the desired global mi− nima solution is reached. Unfortunately, without proper ini− tialization process, in some cases, the cluster centres are trapped at local minima, leading to them to lose the chance to be updated in the next iteration. The cluster centres will be stuck to its initial value and cannot properly represent any group of data or, in the worst case, the cluster will have no members (e. g., referred as a dead centre). Typically, it only gives better results if the initial centre values are set close to the optimum location. The fuzzy C−means (FCM) algorithm has then been introduced to reduce both problems by partially distributing the pixels to all clusters with diffe− rent degrees of membership and becoming less sensitive to initialization. On the other hand, it becomes sensitive to outliers and could not homogenously segment the images [11]. In other attempts, in order to improve the capability of the conventional KM algorithm, the fitness concept has been introduced in the moving K−means (MKM) algorithm [12]. Obeying to one fitness condition as stated in the MKM algorithm, the cluster with the highest fitness value is forced to share its members to the cluster with the lowest fitness value (e. g., although, those pixels or members should belong to other more appropriate clusters) to ensure all the clusters are active during the updating process. Due to the force transformation of elements to the inappropriate clus− ter, the representation of data will be inappropriate and may also converge to local minima solution. An adaptive version of the MKM algorithm called the adaptive moving K−means (AMKM) algorithm has been put forward to resolve the MKM drawbacks by transferring the members of the high− est fitness cluster to its nearest neighbouring cluster instead of the cluster with the lowest fitness value [13]. The fuzzy concept in the AMKM algorithm is also proposed in Ref. 13. The modified version is called the adaptive fuzzy moving K−means (AFMKM) algorithm. The AMKM and AFMKM algorithms have homogeneously segmented the images. However, they also have to face the same draw− backs as the conventional algorithm; failing to significantly update the lowest fitness cluster during the iteration (which may be trapped at non−active regions) and are also sensitive to initial parameters’ values [14]. These weaknesses are overcome by the latest improved version of the AMKM algorithm named the enhanced moving K−means (EMKM) algorithm. In the EMKM algorithm, the highest fitness clus− ter keeps its members within the range as defined in Ref. 14, 216 Opto−Electron. Rev., 20, no. 3, 2012 OPTO−ELECTRONICS REVIEW 20(3), 216–225 DOI: 10.2478/s11772−012−0028−8 * e−mail: [email protected]

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Optimized K-means (OKM) clustering algorithm for image segmentation
F.U. SIDDIQUI* and N.A. MAT ISA
School of Electrical & Electronic Engineering, Universiti Sains Malaysia, 14300,Nibong Tebal, Penang, Malaysia
This paper presents the optimized K−means (OKM) algorithm that can homogenously segment an image into regions of inter−est with the capability of avoiding the dead centre and trapped centre at local minima phenomena. Despite the fact that theprevious improvements of the conventional K−means (KM) algorithm could significantly reduce or avoid the former problem,the latter problem could only be avoided by those algorithms, if an appropriate initial value is assigned to all clusters. In thisstudy the modification on the hard membership concept as employed by the conventional KM algorithm is considered. As theprocess of a pixel is assigned to its associate cluster, if the pixel has equal distance to two or more adjacent cluster centres,the pixel will be assigned to the cluster with null (e. g., no members) or to the cluster with a lower fitness value. The qualita−tive and quantitative analyses have been performed to investigate the robustness of the proposed algorithm. It is concludedthat from the experimental results, the new approach is effective to avoid dead centre and trapped centre at local minimawhich leads to producing better and more homogenous segmented images.
Keywords: K−means based clustering; image segmentation; dead centre problem; trapped centre problem; optimizedK−means.
1. Introduction
Image segmentation is a process of partitioning an imageinto homogenous regions of interest. Amongst differentalgorithms for image segmentation, the unsupervised cen−tre−based clustering algorithms are widely used in computervision and many other applications [1–10]. In a clusteringarea, the K−means (KM) algorithm is an iterative conven−tional method which is familiar for its low execution timeand easy implementation. The KM algorithm begins withinitializing the cluster centres value and is followed byiteratively refining their value until the desired global mi−nima solution is reached. Unfortunately, without proper ini−tialization process, in some cases, the cluster centres aretrapped at local minima, leading to them to lose the chanceto be updated in the next iteration. The cluster centres willbe stuck to its initial value and cannot properly representany group of data or, in the worst case, the cluster will haveno members (e. g., referred as a dead centre). Typically, itonly gives better results if the initial centre values are setclose to the optimum location. The fuzzy C−means (FCM)algorithm has then been introduced to reduce both problemsby partially distributing the pixels to all clusters with diffe−rent degrees of membership and becoming less sensitive toinitialization. On the other hand, it becomes sensitive tooutliers and could not homogenously segment the images[11].
In other attempts, in order to improve the capability ofthe conventional KM algorithm, the fitness concept hasbeen introduced in the moving K−means (MKM) algorithm[12]. Obeying to one fitness condition as stated in the MKMalgorithm, the cluster with the highest fitness value is forcedto share its members to the cluster with the lowest fitnessvalue (e. g., although, those pixels or members shouldbelong to other more appropriate clusters) to ensure all theclusters are active during the updating process. Due to theforce transformation of elements to the inappropriate clus−ter, the representation of data will be inappropriate and mayalso converge to local minima solution. An adaptive versionof the MKM algorithm called the adaptive moving K−means(AMKM) algorithm has been put forward to resolve theMKM drawbacks by transferring the members of the high−est fitness cluster to its nearest neighbouring cluster insteadof the cluster with the lowest fitness value [13]. The fuzzyconcept in the AMKM algorithm is also proposed inRef. 13. The modified version is called the adaptive fuzzymoving K−means (AFMKM) algorithm. The AMKM andAFMKM algorithms have homogeneously segmented theimages. However, they also have to face the same draw−backs as the conventional algorithm; failing to significantlyupdate the lowest fitness cluster during the iteration (whichmay be trapped at non−active regions) and are also sensitiveto initial parameters’ values [14]. These weaknesses areovercome by the latest improved version of the AMKMalgorithm named the enhanced moving K−means (EMKM)algorithm. In the EMKM algorithm, the highest fitness clus−ter keeps its members within the range as defined in Ref. 14,
216 Opto−Electron. Rev., 20, no. 3, 2012
OPTO−ELECTRONICS REVIEW 20(3), 216–225
DOI: 10.2478/s11772−012−0028−8
*e−mail: [email protected]

and the members beyond this range will be assigned to thenearest neighbouring cluster. In addition, the lowest fitnesscluster obtains the members of the nearest neighbouringcluster which lie outside of the range as defined by Ref. 14.The enhanced version could significantly reduce both afo−rementioned problems. Furthermore, the proposed EMKMalgorithm is less sensitive to the initial parameters.
The decisive factor (fitness condition) of the conven−tional MKM and its modified algorithms could not differen−tiate, in common, the dead centre and the cluster with zerointra cluster variance during the process which results in aninadequate distribution of data. Furthermore, in the algo−rithm with hard membership function, the pixel that has theequal distance to two or more adjacent clusters could beassigned to the higher variance cluster and the lower vari−ance cluster will not be trained or updated in the learningprocess. Due to these problems, the algorithms could fail tohomogenously segment an image. In this study, the modi−fied version of the KM algorithm called the optimizedK−means (OKM) is introduced to overcome those weak−nesses and segment an image in uniformity.
The rest of this paper is organized as follows: Section 2describes the limitation of previous algorithms and then fol−lowed by the explanation regarding the proposed OKMalgorithm. Experimental results and comparison are givenin Sect. 3. Finally; the conclusion of this study is providedin Sect. 4.
2. Methodology
2.1. Limitation of previous K-means based clusteringalgorithms
As presented in Sect. 1, the conventional KM algorithmassigns each pixel to the respective cluster on the basis ofthe minimum Euclidean distance. However, poor pixelassignment could occur if the pixel has the same minimumEuclidean distance to two or more adjacent clusters. Thepixel may be assigned to the higher variance cluster and thecluster with lower variance has probably no opportunity tobe trained and could be trapped at local minima which pos−sibly become the dead centre in the next iteration.
Figure 1 visualizes aforementioned problem wherepoints A, B, and C are the centre points of the clusters adja−cent to point D. The Euclidean distance between the point Dto the adjacent clusters A, B, and C is the same. This parti−cular point may be assigned to the higher variance clusterand the lower variance cluster could trap into its presentvalue without updating or could be turned into the dead cen−tre without having a chance to be updated in the forthco−ming iteration.
Furthermore, based on literature review, the MKM andits modified versions (e.g., AMKM, AFMKM and EMKMalgorithms) also fail to allocate the data in a proper cluster.These techniques employ the fitness condition to avoid thedead centre. However, the fitness condition in certain case isnot capable to distinguish between the dead centres or clus−
ters with no member and the zero variance clusters (e.g.,cluster with the similar intensity pixels); because both typesof clusters have the same fitness value (e.g., zero). The pi−xels may be transferred to zero variance clusters and thedead centre (empty cluster) could be left intact without anyupdating process. Thus, these problems could lead to a non−−homogenous segmentation phenomenon.
2.2. Proposed OKM algorithm
Consider the image I with the size N M� to be segmentedinto the k centres or clusters. Similar to the conventionalKM algorithm, the proposed OKM algorithm is introducedas image segmentation by minimizing the following costfunction
OKM p x y cj ki
N M
i j� ���
�
� min ( , ){ ,... }11
2, (1)
where pi(x,y) is the i−th pixel with the coordinate (x,y) to besegmented and cj is the j−th centre or cluster.
In the beginning of the OKM algorithm, all pixels areassigned to the nearest cluster based on the Euclidean dis−tance. For the pixels having the same Euclidean distance totwo or three adjacent clusters (e.g., in this study these pixelsare called conflict pixels), the grey intensity of these pixelswill be sorted in the ascending order according to their dis−tance from the cluster with the highest fitness value (e.g.,this cluster is denoted as cl ) and the sorting array is denotedby Er, where r = 1, 2, 3... (k–1). If the grey level is seg−mented into k number of clusters, the k–1 will be the maxi−mum number of intensity levels for the aforementionedcase. Furthermore, the clusters are also sorted in the ascend−ing order according to their fitness values and denoted as theFq, where q =1, 2, 3...k. The fitness value for each cluster iscalculated according to
f c p x y cj i ji c j
( ) ( , )� ��� 2
. (2)
Opto−Electron. Rev., 20, no. 3, 2012 F.U. Siddiqui 217
Fig. 1. Data point with equal distance to its adjacent clusters.

One of the main problems in the conventional K−mean−−based clustering algorithms is that these algorithms cannotdifferentiate between clusters that have similar intensitypixels (e.g., with reference to zero variance cluster) and theclusters without any members (e.g., referring to dead cen−tres or empty clusters). This is because both types of clustersproduce zero value of Fq. Thus, this study proposes to mea−sure the number of pixels for each cluster as an additionalcondition, in order to differentiate those clusters. In the pro−posed OKM algorithm, if both types of clusters (e.g., emptycluster and zero variance cluster) are found, these clustersare sorted again in the ascending order according to thenumber of pixels in those clusters. This sorting array isdenoted as Hw, where w = 1, 2, 3....z (z is the total number ofempty and zero variance clusters). Then, the Er and Hw
datasets are compared and mapped. The pixels with theintensity value of Eb (starting from b = 1) are then assignedto the cluster with the value of Hb. The process of transfer−ring continues until the value of b in Hb equals to z or thevalue of b in Eb equals to (k–1). On the other hand, for thecase where no dead centre is found, the pixels with the samedistance to two or more adjacent clusters are directlyassigned to the lowest fitness value cluster among thoseadjacent clusters. After completing the assigning process,all the centres are updated by using
cn
p x yjj
ii c j
���1
( , ) , (3)
where, n j is the number of pixels in the j−th cluster.The above mentioned process is repeated until the dif−
ference of the mean square error (MSE) is less than �,where 0 1� �� . The typical value of � to obtain a good seg−mentation performance should be close to 0. The terminat−ing criteria could be defined as
MSEn
p x y ci ji cj
k
j
� �����1 2
1
( , ) , (4)
MSE MSEt l( ) � �1 �, (5)
where, t is the number of iterations and n is the total numberof pixels in an image ( )N M� .
Based on the above mentioned description, the imple−mentation of the OKM clustering algorithm could be out−lined as follows:
1. Initialize the centre value of all clusters and �, and let it−eration t = 0. (Note: � is the constant value in the range0 1� �� , where in this study its value is set to 0.1)
2. Assign all pixels to the nearest cluster based on the Eu−clidean distance, except those pixels that have the sameEuclidean distance to two or more adjacent clusters(e.g., the conflict pixels).
3. Measure the MSE value for each cluster using Eq. (4).(Note: this step is only implemented for iteration t = 0).
4. Calculate the fitness value of all clusters based on Eq.(2) and find the cluster with the highest fitness value cl .
5. For the conflict pixels, sort the grey intensity of thesepixels in the ascending order according to their distancefrom cl and denote the sorting array as Er, where r = 1,2, 3… (k–1).
6. Find the empty cluster (e.g., cluster without members).i. If the empty cluster is found,
a. sot all clusters in the ascending order accordingtotheir fitness values and denote the sorting array asFq, where q = 1, 2, 3 …k.
b. for all clusters with zero fitness value as obtainedin step 6(i)(a), sort these clusters in ascending order according to the number of pixels or membersin the clusters and denote the sorting array as Hw,where w = 1, 2, 3….z (z is the total number ofempty and zero variance clusters).
c. assign the pixels with grey intensity of Eb to Hb
(e.g., begin with b = 1) and continue until thevalue of b in Hb equals to z or the value of b in Eb
equals to (k–1).ii. If no empty cluster is found;
a. Assign the pixels with grey intensity Eb to theclusters with the lowest fitness value among theiradjacent clusters, where b = r = 1, 2...k–1.
7. Increase iteration by 1 (e. g., t = t + 1), and update thecentre positions, and measure the MSE value using Eqs.(3) and (4), respectively.
8. Repeat steps 2 to 7 (except step 3) until the condition
MSE MSEt t( ) � �1 � is fulfilled.
The flow chart of the implementation of the proposedOKM algorithm is shown in Fig. 2.
2.3. Estimated time complexity
The conventional KM algorithm is proven to have a shortprocessing time with the time complexity given by Ref. 15
time complexity O ndktKM � ( ), (6)
where n is the number of the pixels in an image, k is thenumber of clusters, t is the number of iteration, and d is thenumber of attributes’ dimensions. For the proposed OKMalgorithm, as a modified version of the conventional KMalgorithm, the time complexity in Eq. (6) needs to be modi−fied as well, which is defined as
time complexity O ndktbOKM � ( ), (7)
where n, d, k, and t are defined as in Eq. (6). The only addi−tional parameter for the proposed OKM algorithm as com−pared to the conventional KM algorithm is b which is thenumber of the intensity values of the conflict pixels that areto be assigned to their respective cluster in step 6. In bothequations, the big notation defines the growth rate of thefunction. Equations (6) and (7) show that the difference ofthe time complexity between the proposed OKM and theconventional KM algorithm is tolerable as the OKM algo−
Optimized K−means (OKM) clustering algorithm for image segmentation
218 Opto−Electron. Rev., 20, no. 3, 2012 © 2012 SEP, Warsaw

Opto−Electron. Rev., 20, no. 3, 2012 F.U. Siddiqui 219
Fig. 2. Flow chart for the implementation of the proposed OKM algorithm.

rithm employs only one extra parameter which is b. In addi−tion, the dependency on parameter b does not significantlyincrease the time complexity (e.g., compared to the conven−tional KM algorithm), as the process which involves param−eter b (e.g., as in step 6) is not implemented to all pixels inthe image but only to the conflict pixels. Hence, the numberof conflict pixels probably decreases with the increment ofthe number of iteration.
3. Experimental setup and system performance
The proposed OKM algorithm has been tested with 103standard images taken from public database. The perfor−mance is tested for different numbers of clusters; e.g., 3, 4,5, and 6 clusters. The empirical results have been analysedqualitatively and quantitatively in order to illustrate the ca−pability of the proposed OKM algorithm to segment homo−geneously the regions of interest and distinguish them fromunwanted background. The conventional KM, MKM, andFCM algorithms and the latest K−means based clusteringalgorithms, namely the AMKM, AFMKM, EMKM−1, andEMKM−2 algorithms are used for comparison. In this paper,4 standard images, namely “Lake”, “Aircraft”, “House” and“Fruit Table” are selected as some examples to visually ana−lyse the performance of the OKM algorithm with 3, 4, 5,and 6 clusters respectively. For the quantitative analysis, allof the 103 tested images will be used. In addition, the execu−tion time for the algorithms is also measured. All experi−mental tests have been executed on MATLAB version7.10.0 (R2010a) using the computer configuration i.e.Intel® Core™ i3 CPU @ 2.93 GHz Processor, 4.00GB ofRAM, and 500GB of disk drive space.
3.1. Qualitative analysis
Qualitative analysis is the widely used procedure to evaluatethe algorithm performance on the basis of human visual per−ception. Using the qualitative analysis the probabilistic des−cription on the segmented results is conducted to demon−strate whether the proposed OKM algorithm uniformly seg−ments the regions of interest over the other comparativealgorithms. The results obtained are presented in Figs. 3 to 6for the images labelled “Lake”, “Aircraft”, “House” and“Fruit Table”, respectively. In each figure the originalimage is shown in image (a), while the segmented resultsproduced by the conventional KM, MKM, FCM, AMKM,AFMKM, EMKM−1, EMKM−2 and the proposed OKMalgorithms are depicted in images (b) to (i), respectively.
The resultant images of “Lake” produced by the pro−posed OKM algorithm and the other conventional algo−rithms with 3 clusters are shown in Fig. 3. In general, theproposed OKM algorithm segments homogeneously thelake and mountain regions which could not be homoge−nously segmented by the conventional KM, MKM, FCM,AMKM, AFMKM, EMKM−1, and EMKM−2 algorithms.Furthermore, the proposed OKM algorithm reasonably seg−ments the wooden bridge and ship into more uniformedregions as compared to that produced by the other con−ventional algorithms.
The selected image namely “Aircraft” has been seg−mented into 4 clusters as shown in Fig. 4. The proposedOKM algorithm shows a relatively good homogeneousresult. Specifically, the bottom of “Aircraft” and cloudregions are more homogeneously segmented by the pro−posed OKM algorithm, which could not be observed in the
Optimized K−means (OKM) clustering algorithm for image segmentation
220 Opto−Electron. Rev., 20, no. 3, 2012 © 2012 SEP, Warsaw
Fig. 3. Segmentation results in 3 clusters for image “Lake” after applying different clustering algorithms: (a) original image, (b) KM,(c) MKM, (d) FCM, (e) AMKM, (f) AFMKM, (g) EMKM−1, (h) EMKM−2, and (i) proposed OKM.

resultant images produced by the conventional algorithms.Furthermore, the OKM algorithm clearly segments the text“F−16”, written on the tail of the aircraft as compared to ot−hers. In general, the conventional KM, MKM, and FCM andthe recently introduced AMKM, AFMKM, EMKM−1, andEMKM−2 algorithms have not managed to segment theaforementioned regions of interest with homogeneous oruniform texture. Furthermore, the AFMKM algorithm showsthe low contrast segmented images. This is due to the inten−sity of a centre to represent a region that is close to that of thecentre representing other regions. Thus, the regions obtainedhave low intensity difference among them which could leadto low contrast of the segmented image. For example, asshown in the resultant image produced by AFMKM, thecloud region is hardly observed due to the intensities of cloudand ice regions that are very close to each other.
The resultant images of the “House” segmented into 5clusters are depicted in Fig. 5. Similar results have beenobserved as in the image segmentation in 3 and 4 clusters.The resultant images clearly illustrate the capability of theproposed OKM algorithm over the other algorithms. TheOKM algorithm homogeneously segment the roof and wallof the house while the other algorithms produce much lesshomogeneous segmented images as can clearly be seen atthe wall of the house. Many unwanted small regions areproduced.
To extend the qualitative analysis, the image “FruitTable” is segmented into 6 clusters and the obtained resultsare presented in Fig. 6. Based on Fig. 6, all algorithms exceptthe proposed OKM algorithm segment non−homogeneouslythe background where a rough texture of shadowed regioncould clearly be observed on the wall. Furthermore, the KM,FCM, MKM, AMKM, AFMKM, EMKM−1, and EMKM−2also fail to segment homogenously the fruits and the winebottle. The proposed OKM algorithm, on the other hand, suc−cessfully segments the fruits (especially the grapes), the winebottle and wall with some homogeneous regions.
3.2. Quantitative analysis
Quantitative analysis numerically computes the perfor−mance of the tested algorithms and is used to verify and sup−port the findings of the qualitative analysis. As compared tothe qualitative analysis which is subjective among obser−vers, the quantitative analysis evaluates the performance ofthe algorithms which are independent on the observer’s orhuman error. In this paper, three quantitative methods areemployed, which are defined as follows:
F(I) proposed by Liu and Yang [16]
F I Re
Ai
ii
R( ) �
��
2
1
. (8)
Opto−Electron. Rev., 20, no. 3, 2012 F.U. Siddiqui 221
Fig. 4. Segmentation results in 4 clusters for image “Aircraft” after applying different clustering algorithms: (a) original image, (b) KM,(c) MKM, (d) FCM, (e) AMKM, (f) AFMKM, (g) EMKM−1, (h) EMKM−2, and (i) the proposed OKM.

Optimized K−means (OKM) clustering algorithm for image segmentation
222 Opto−Electron. Rev., 20, no. 3, 2012 © 2012 SEP, Warsaw
Fig. 5. Segmentation results in 5 clusters for image “House” after applying different clustering algorithms: (a) original image, (b) KM,(c) MKM, (d) FCM, (e) AMKM, (f) AFMKM, (g) EMKM−1, (h) EMKM−2, and (i) the proposed OKM.
Fig. 6. Segmentation results in 6 clusters for image “Fruit Table” after applying different clustering algorithms: (a) original image, (b) KM,(c) MKM, (d) FCM, (e) AMKM, (f) AFMKM, (g) EMKM−1, (h) EMKM−2, and (i) the proposed OKM.

F I( ) proposed by Borsotti et al. [17]
��
�
� �� �F I
N MR A
e
AA
A
i
ii
R( )
( )[ ( )]
max1
10001 1
1
2
1
. (9)
Q(I) further expanded from F I( ) by Borsotti et al. as [17]
Q IN M
Re
A
R A
Ai
i
i
ii
( )( ) log
( )�
�
��
���
�
���
�
���
1
1000 1
2 2
��
1
R.(10)
For the above formulae, I is the image, 1/1000( )N M� isa normalizing factor, N M� is the size of image, R is thenumber of regions found, Ai is the size of region and ei is theaverage intensity error.
The above defined functions are used to penalize thesegmentation that forms too many regions or non−homoge−neous regions by providing a larger value. Smaller values ofF(I), F I( ) and Q(I) illustrate a better segmentation perfor−mance produced by the tested algorithm. The results forselected images segmented into 3, 4, 5, and 6 clusters aretabulated in Table 1. In addition, the average results of onehundred and three images are tabulated in Table 2. The bestresults obtained for each analysis are made bold. The resultsobtained clearly show that the proposed OKM algorithmproduces the best segmentation performance for all numberof clusters by producing the smallest values of R, F(I), F I( )and Q(I). One of the interesting findings lies in the numberof regions, R values produced by the proposed OKM algo−rithm for “Lake”, “Aircraft”, “House” and “Fruit Table”which are much smaller as compared to those of the other
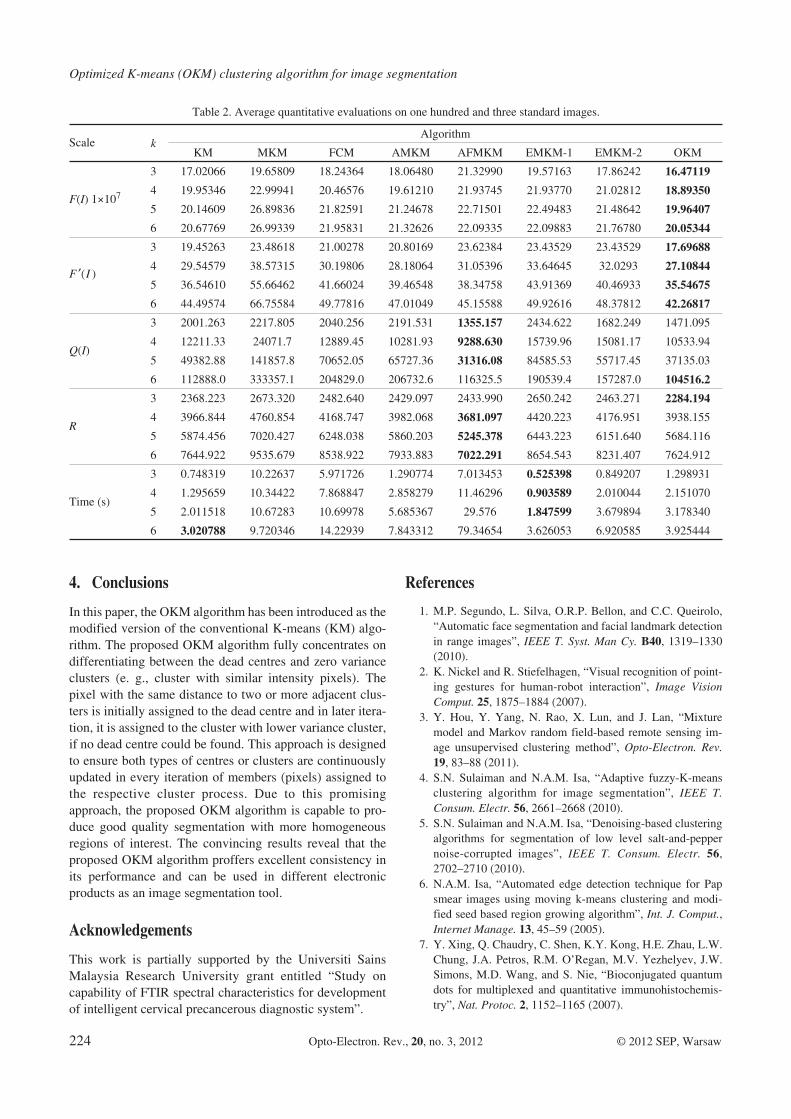
tested algorithms. The results clearly prove the capability ofthe OKM algorithm to reduce the occurrence of the unwan−ted non−homogeneous small regions as suffered by the otheralgorithms (e. g., as shown in Figs. 3 to 6) for images“Lake”, “Aircraft”, “House” and “Fruit Table”, respecti−vely. The findings are further supported by the lowest aver−age values of F(I) and F I( ) for 103 tested images producedby the proposed OKM algorithm for all numbers of clusters.In addition, the average values of Q(I) and R produced bythe proposed OKM algorithm are also the lowest for thenumbers of clusters 6 and 3 respectively as compared toother algorithms. Meanwhile, for the other number of clus−ters, the proposed OKM algorithm is ranked second after theAFMKM algorithm in terms of Q(I) and R analyses. How−ever, as proven in Sect. 3.1, the qualitative analysis favoursthe OKM algorithm compared to the AFMKM algorithm.Thus, it can be concluded that from the results, the proposedOKM algorithm is significantly able to homogenouslysegment the image.
Furthermore, the execution time is also measured toevaluate the efficiency of the proposed OKM algorithmover the other conventional algorithms. The results obtainedare tabulated in Table 1 for the images namely “Lake”,“Aircraft”, “House” and “Fruit Table” with 3, 4, 5, and 6clusters, respectively. Also, the average value of the execu−tion time is tabulated in Table 2. Based on results obtainedin both tables, the proposed OKM algorithm is ranked thirdafter the KM and EMKM−1 algorithms. In general, the pro−posed OKM algorithm has significantly segmented theimages with negligible, high execution time.
Opto−Electron. Rev., 20, no. 3, 2012 F.U. Siddiqui 223
Table 1. Quantitative evaluations on the segmentation of selected standard images.
Scale k ImagesAlgorithm
KM MKM FCM AMKM AFMKM EMKM−1 EMKM−2 OKM
F(I)1×107
3 Lake 11.6903 10.0834 11.1502 10.7623 9.783464 10.76231 9.671125 7.58954
4 Aircraft 11.5666 17.1180 11.9352 13.4192 17.02955 11.69937 10.69586 9.34801
5 House 1.43806 1.79357 1.32393 1.59661 1.732242 1.863270 1.512374 1.06457
6 Fruit Table 41.4031 74.6201 47.9129 45.8633 47.73871 41.65946 44.25768 49.8415
F I( )
3 Lake 15.7400 13.3268 14.4646 14.0111 13.05546 15.072 10.85116 6.44496
4 Aircraft 8.49447 15.4109 9.02981 10.1404 12.55953 8.775235 7.204465 5.49857
5 House 3.45540 4.84840 2.97197 3.75252 4.390962 3.63426 2.5568 1.40743
6 Fruit Table 108.581 202.279 117.121 111.334 117.6387 107.5785 109.4121 110.297
Q(I)
3 Lake 380.753 336.299 322.773 322.144 382.4093 318.2371 123.679 21.8067
4 Aircraft 257.308 729.899 290.053 264.964 249.2061 264.7348 162.0537 81.1182
5 House 85.6403 321.379 56.5068 83.5496 128.5104 87.25317 30.26328 3.63928
6 Fruit Table 268717 279000 212961 202532 178694.7 270174.9 220799 112826
R
3 Lake 2538 2444 2466 2449 2567 2504 1884 1142
4 Aircraft 3054 3792 3103 2970 2977 3007 2755 2378
5 House 1195 1932 1074 1218 1350 1628 1190 554
6 Fruit Table 14694 14263 14509 14293 13153 15071 14529 12247
Time (s)
3 Lake 0.32202 3.19643 4.54733 0.33373 0.167051 0.283182 0.783353 0.54703
4 Aircraft 1.84909 13.6884 11.6450 1.46950 55.36616 1.214838 2.162578 3.95710
5 House 0.86415 0.24638 3.44602 0.34743 0.841543 0.787365 2.926806 0.47008
6 Fruit Table 0.37935 7.84358 14.8985 5.50225 56.3277 0.773636 12.54757 3.10816
4. Conclusions
In this paper, the OKM algorithm has been introduced as themodified version of the conventional K−means (KM) algo−rithm. The proposed OKM algorithm fully concentrates ondifferentiating between the dead centres and zero varianceclusters (e. g., cluster with similar intensity pixels). Thepixel with the same distance to two or more adjacent clus−ters is initially assigned to the dead centre and in later itera−tion, it is assigned to the cluster with lower variance cluster,if no dead centre could be found. This approach is designedto ensure both types of centres or clusters are continuouslyupdated in every iteration of members (pixels) assigned tothe respective cluster process. Due to this promisingapproach, the proposed OKM algorithm is capable to pro−duce good quality segmentation with more homogeneousregions of interest. The convincing results reveal that theproposed OKM algorithm proffers excellent consistency inits performance and can be used in different electronicproducts as an image segmentation tool.
Acknowledgements
This work is partially supported by the Universiti SainsMalaysia Research University grant entitled “Study oncapability of FTIR spectral characteristics for developmentof intelligent cervical precancerous diagnostic system”.
References
1. M.P. Segundo, L. Silva, O.R.P. Bellon, and C.C. Queirolo,“Automatic face segmentation and facial landmark detectionin range images”, IEEE T. Syst. Man Cy. B40, 1319–1330(2010).
2. K. Nickel and R. Stiefelhagen, “Visual recognition of point−ing gestures for human−robot interaction”, Image VisionComput. 25, 1875–1884 (2007).
3. Y. Hou, Y. Yang, N. Rao, X. Lun, and J. Lan, “Mixturemodel and Markov random field−based remote sensing im−age unsupervised clustering method”, Opto−Electron. Rev.19, 83–88 (2011).
4. S.N. Sulaiman and N.A.M. Isa, “Adaptive fuzzy−K−meansclustering algorithm for image segmentation”, IEEE T.Consum. Electr. 56, 2661–2668 (2010).
5. S.N. Sulaiman and N.A.M. Isa, “Denoising−based clusteringalgorithms for segmentation of low level salt−and−peppernoise−corrupted images”, IEEE T. Consum. Electr. 56,2702–2710 (2010).
6. N.A.M. Isa, “Automated edge detection technique for Papsmear images using moving k−means clustering and modi−fied seed based region growing algorithm”, Int. J. Comput.,Internet Manage. 13, 45–59 (2005).
7. Y. Xing, Q. Chaudry, C. Shen, K.Y. Kong, H.E. Zhau, L.W.Chung, J.A. Petros, R.M. O’Regan, M.V. Yezhelyev, J.W.Simons, M.D. Wang, and S. Nie, “Bioconjugated quantumdots for multiplexed and quantitative immunohistochemis−try”, Nat. Protoc. 2, 1152–1165 (2007).
Optimized K−means (OKM) clustering algorithm for image segmentation
224 Opto−Electron. Rev., 20, no. 3, 2012 © 2012 SEP, Warsaw
Table 2. Average quantitative evaluations on one hundred and three standard images.
Scale kAlgorithm
KM MKM FCM AMKM AFMKM EMKM−1 EMKM−2 OKM
F(I) 1×107
3 17.02066 19.65809 18.24364 18.06480 21.32990 19.57163 17.86242 16.47119
4 19.95346 22.99941 20.46576 19.61210 21.93745 21.93770 21.02812 18.89350
5 20.14609 26.89836 21.82591 21.24678 22.71501 22.49483 21.48642 19.96407
6 20.67769 26.99339 21.95831 21.32626 22.09335 22.09883 21.76780 20.05344
F I( )
3 19.45263 23.48618 21.00278 20.80169 23.62384 23.43529 23.43529 17.69688
4 29.54579 38.57315 30.19806 28.18064 31.05396 33.64645 32.0293 27.10844
5 36.54610 55.66462 41.66024 39.46548 38.34758 43.91369 40.46933 35.54675
6 44.49574 66.75584 49.77816 47.01049 45.15588 49.92616 48.37812 42.26817
Q(I)
3 2001.263 2217.805 2040.256 2191.531 1355.157 2434.622 1682.249 1471.095
4 12211.33 24071.7 12889.45 10281.93 9288.630 15739.96 15081.17 10533.94
5 49382.88 141857.8 70652.05 65727.36 31316.08 84585.53 55717.45 37135.03
6 112888.0 333357.1 204829.0 206732.6 116325.5 190539.4 157287.0 104516.2
R
3 2368.223 2673.320 2482.640 2429.097 2433.990 2650.242 2463.271 2284.194
4 3966.844 4760.854 4168.747 3982.068 3681.097 4420.223 4176.951 3938.155
5 5874.456 7020.427 6248.038 5860.203 5245.378 6443.223 6151.640 5684.116
6 7644.922 9535.679 8538.922 7933.883 7022.291 8654.543 8231.407 7624.912
Time (s)
3 0.748319 10.22637 5.971726 1.290774 7.013453 0.525398 0.849207 1.298931
4 1.295659 10.34422 7.868847 2.858279 11.46296 0.903589 2.010044 2.151070
5 2.011518 10.67283 10.69978 5.685367 29.576 1.847599 3.679894 3.178340
6 3.020788 9.720346 14.22939 7.843312 79.34654 3.626053 6.920585 3.925444

8. J.−W Jeong, D.C. Shin, S.H. Do, and V.Z. Marmarelis, “Seg−mentation methodology for automated classification and dif−ferentiation of soft tissues in multiband images of high−reso−lution ultrasonic transmission tomography”, IEEE T. Med.Imaging 25, 1068–1078 (2006).
9. N.A.M. Isa, M.Y. Mashor, and N.H. Othman, “An automatedcervical pre−cancerous diagnostic system”, Artif. Intell. Med.42, 1–11 (2008).
10. R. Nagarajan, “Intensity−based segmentation of microarrayimages”, IEEE T. Med. Imaging 22, 882–889 (2003).
11. R.J. Hathaway, J.C. Bezdek, and Y. Hu, “Generalized fuzzyc−means clustering strategies using Lp norm distances”,IEEE T. Fuzzy Syst. 8, 576–582 (2002).
12. M. Mashor, “Hybrid training algorithm for RBF network”,Int. J. Comput., Internet Manage. 8, 50–65 (2000).
13. N.A.M. Isa, S.A. Salamah, and U.K. Ngah, “Adaptive fuzzymoving K−means clustering algorithm for image segmenta−tion”, IEEE T. Consum. Electr. 55, 2145–2153 (2010).
14. F.U. Siddiqui and N.A.M. Isa, “Enhanced moving K−means(EMKM) algorithm for image segmentation”, IEEE T.Consum. Electr. 57, 833–841 (2011).
15. B. Leibe, K. Mikolajczyk, and B. Schiele, “Efficient cluster−ing and matching for object class recognition”, Proc. BMVC,789–798 (2006).
16. L. Jianqing and Y. Yee−Hong, “Multiresolution colour imagesegmentation”, IEEE T. Pattern Anal. 16, 689–700 (1994).
17. M. Borsotti, P. Campadelli, and R. Schettini, “Quantitativeevaluation of colour image segmentation results1”, PatternRecogn. Lett. 19, 741–747 (1998).
Opto−Electron. Rev., 20, no. 3, 2012 F.U. Siddiqui 225
Related Documents


![Optimized combinatorial clustering for stochastic processes · budget allocation and Bayesian decision-theoretic methods used an average case analysis [5,8,33]. All three procedures](https://static.cupdf.com/doc/110x72/5f41984f0c68ba7f5c6e576a/optimized-combinatorial-clustering-for-stochastic-processes-budget-allocation-and.jpg)








