Optimization, Learnability, and Games: From the Lens of Smoothed Analysis Shang-Hua Teng Computer Science@Viterbi School of Engineering@USC Joint work with Daniel Spielman (Yale), Heiko Röglin (Maastricht University), Adam Kalai (Microsoft New England Lab), Alex Samorodnitsky (Hebrew University), Xi Chen (USC), Xiaotie Deng (City University of Hong Kong)

Optimization, Learnability, and Games: From the Lens of Smoothed Analysis Shang-Hua Teng Computer Science@Viterbi School of Engineering@USC TexPoint fonts.
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Optimization, Learnability, and Games:From the Lens of Smoothed Analysis
Shang-Hua TengComputer Science@Viterbi School of Engineering@USC
Joint work with Daniel Spielman (Yale), Heiko Röglin (Maastricht University), Adam Kalai (Microsoft New England Lab), Alex Samorodnitsky (Hebrew University), Xi Chen (USC), Xiaotie Deng (City University of Hong Kong)

This Talk
• Part I: Overview of Smoothed Analysis
• Part II: Multiobjective Optimization
• Part III: Machine Learning
• Part VI: Games, Markets and Equilibrium
• Part V: Discussions

Practical Performance of Algorithms “While theoretical work on models of computation and
methods for analyzing algorithms has had enormous payoff, we are not done. In many situations, simple algorithms do well. Take for example the Simplex algorithm for linear programming, or the success of simulated annealing of contain supposedly intractable problems. We don't understand why! It is apparent that worst-case analysis does not provide useful insights on the performance of algorithms and heuristics and our models of computation need to be further developed and refined. Theoreticians are investing increasingly in careful experimental work leading to identification of important new questions in algorithms area. Developing means for predicting the performance of algorithms and heuristics on real data and on real computers is a grand challenge in algorithms.”
-- Challenges for Theory of Computing: Report for an NSF-Sponsored Workshop on Research in Theoretical Computer Science (Condon, Edelsbrunner, Emerson, Fortnow, Haber, Karp, Leivant, Lipton, Lynch, Parberry, Papadimitriou, Rabin, Rosenberg, Royer, Savage,Selman, Smith, Tardos, and Vitter), 1999

Linear Programming & Simplex Method
max s.t.
Worst-Case: exponentialAverage-Case: polynomialWidely used in practice
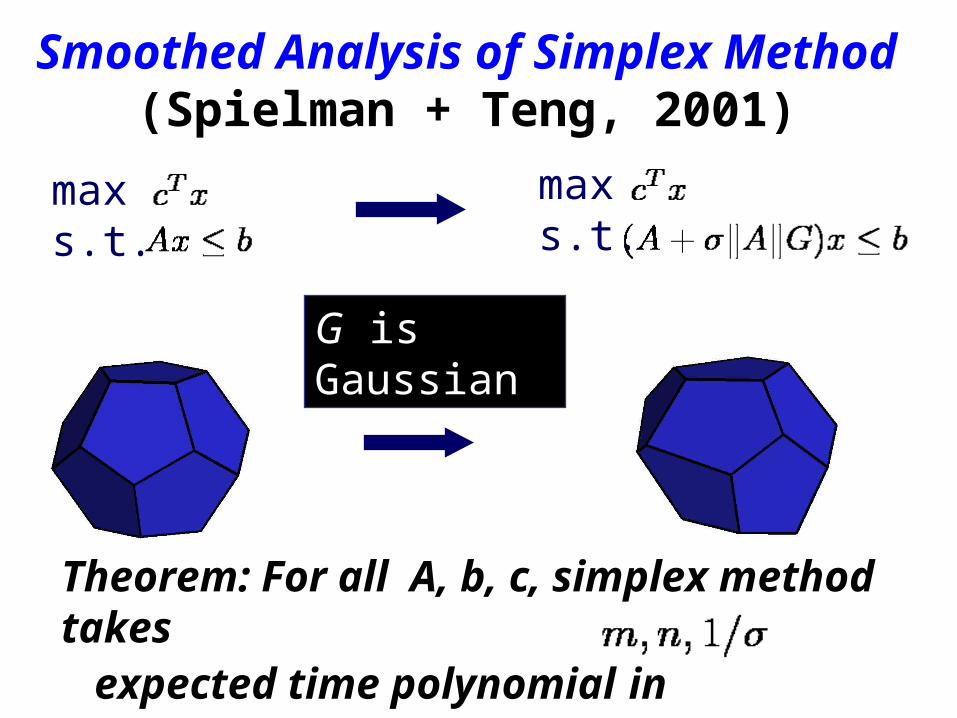
Smoothed Analysis of Simplex Method(Spielman + Teng, 2001)
Theorem: For all A, b, c, simplex method takes expected time polynomial in
max s.t.
maxs.t.
G is Gaussian

Smoothed Complexity
Interpolates between worst and average case
Considers neighborhood of every input
If low, all bad inputs are unstable
Data in practice are not arbitrary but could be generated with noises and imprecision

Optimization: Single Criterion & Multiobjective
min f(x) subject to x ∈ S.
Examples:
• Linear Programming
• Shortest path
• Minimum spanning tree
• TSP
• Set cover

Optimization: Single Criterion & Multiobjective
Real-life logistical problems often involve multiple
objectives
• Travel time, fare, departure time
• Delay, cost, reliability
• Profit and risk

Optimization: Single Criterion & Multiobjective
min f1(x), ..., min fd(x) subject to x ∈ S
There may not be a solution that is simultaneously optimal for all fi
Question: What can we do algorithmically to support a decision maker?

Pareto-Optimal Solutions
x S ∈ dominates y S ∈
iff
∀i : fi(x) ≤ fi(y) and ∃i : fi(x) < fi(y)
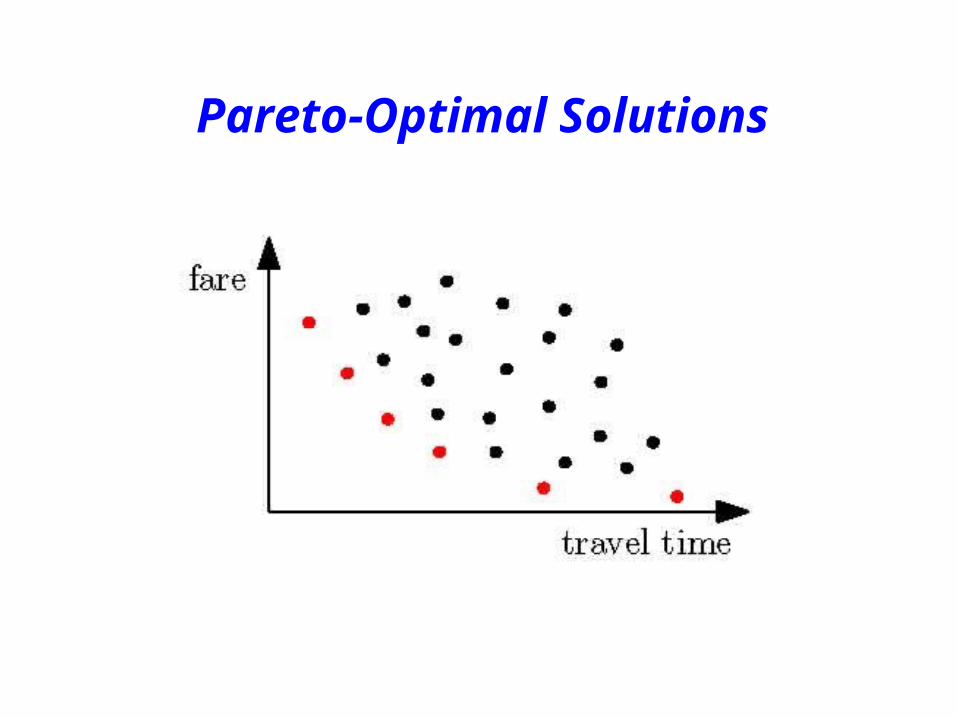
Pareto-Optimal Solutions

Pareto-Optimal Solutions

Pareto Curve

Pareto Surface

Decision Makers only Choose Pareto-Optimal Solutions
Fact: Every monotone function, e.g., 1 f1(x)+ ... +d fd(x)is optimized by a Pareto-optimal solution.
Computational Problem:Return the Pareto curve (surface, set)

Decision Makers only Choose Pareto-Optimal Solutions
Return the Pareto curve (surface, set)
Central Question: How large is the Pareto set?

A Concrete Model
S : can encode arbitrary combinatorial structure.
Examples: all paths from s to t, all Hamiltonian cycles, all spanning trees, . . .

How Large can a Pareto Set be?
• Worst Case: Exponential
• In Practice: Usually smaller
– Müller-Hannemann, Weihe (2001)
Train Connection
travel time, fare, number of train changes

Smoothed Models
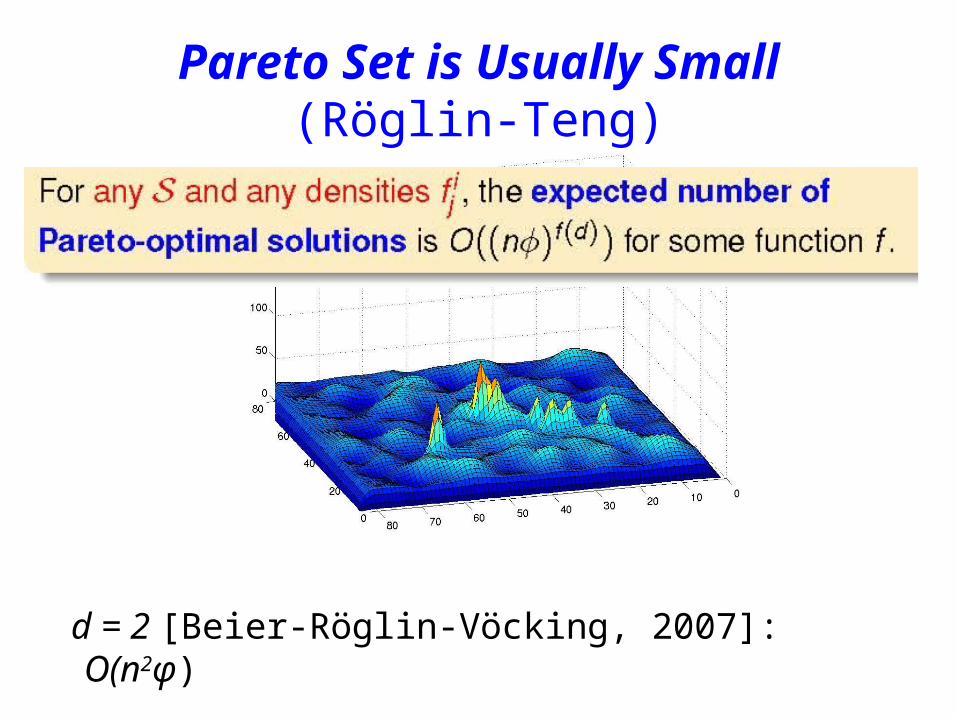
Pareto Set is Usually Small(Röglin-Teng)
d = 2 [Beier-Röglin-Vöcking, 2007]: O(n2φ)

How Many Pareto Points in an -interval

The Winner

The Losers and their Gaps

A Non-Concentration Lemma
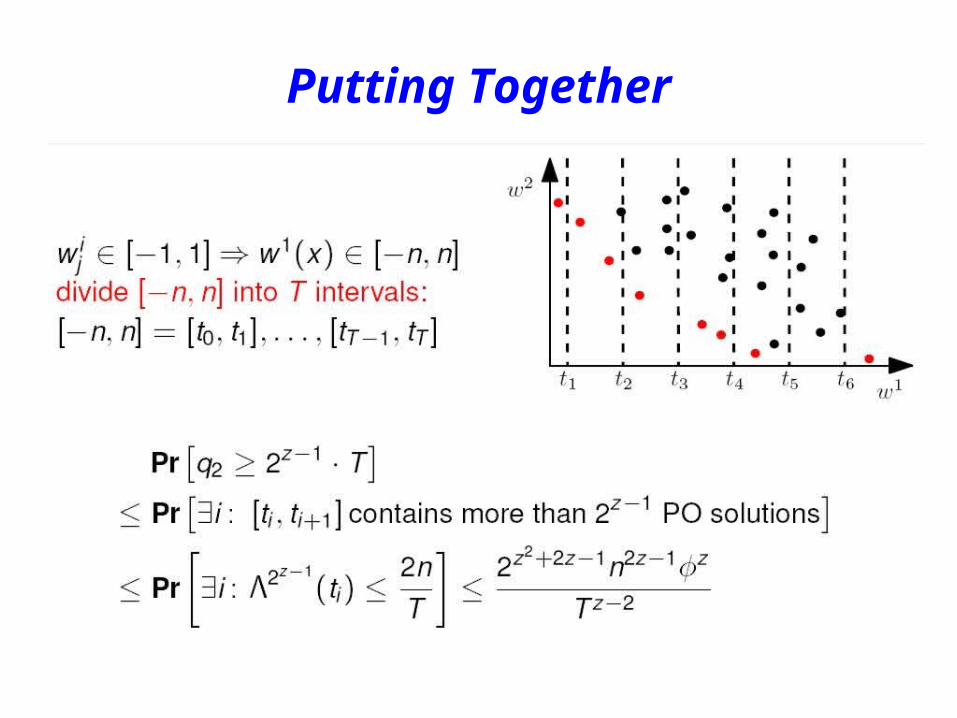
Putting Together

Nearly Tight Smoothed Bounds for 2D: Many Moments

Three or More Objectives
Not So Tight Yet: But Polynomial Smoothed Bound for Fixed Dimensions

This Talk
• Part I: Overview of Smoothed Analysis
• Part II: Multi-objective Optimization
• Part III: Machine Learning
• Part VI: Games, Markets and Equilibrium
• Part V: Discussions

P.A.C. Learning!?
X = {0,1}ⁿ f: X → {–1,+1}
PAC assumption: target is from a particular concept class
(for example, an AND, e.g. f(x) = “Bank” & “Adam” & “Free”)
Input: training data (xj from D, f(xj)) j≤mNoiseless
NIGERIA BANK VIAGRA ADAM LASER SALE FREE IN f(x)
x1 YES YES YES NO NO YES NO YES SPAM
x2 YES NO NO YES YES YES YES YES LEGIT
x3 NO YES YES YES YES YES YES YES LEGIT
x4 YES YES YES NO NO NO NO YES SPAM
x5 YES YES YES YES YES NO YES YES SPAM
[Valiant84]

P.A.C Learning
Poly-time learning algorithm– Succeed with prob. ≥ 1- (e.g. 0.99)
– m = # examples = poly(n/ε)
Output: h: X → {–1,+1} with
err(h) = Prx←D[ h(x)≠f(x) ] ≤
OPTIONAL: “Proper” learning: the class from which h is.

Agnostic P.A.C. Learning!?
X = {0,1}ⁿ f: X → {–1,+1}
Without PAC assumption: target is from a particular concept class
Input: training data (xj from D, f(xj)) j≤m
Poly-time learning algorithm
– Succeed with prob. ≥ 1- (e.g. 0.99)
– m = # examples = poly(n/ε)
Output: h: X → {–1,+1} with
err(h) = Prx←D[ h(x) ≠ f(x) ] ≤ + ming from the class err(g)
[Kearns Schapire Sellie 92]

• Computation is limiting resource– “Easy” ignoring computation
– YET: Children learn many things computers can’t
– Worst-case poly-time algorithms?• PAC-learn DNF, Decision trees, juntas
• Learning parity with noise
Computational Learning Theory

Some Smoothed Results in Learning(Kalai-Samorodnitsky-Teng)
• PAC learn decision trees over smoothed (constant-bounded) product distributions
• PAC learn DNFs over smoothed (constant-bounded) product distribution
• Agnostically learn decision trees over smoothed (constant-bounded) product distributions

A Formal Statement of the First Result
For μ ϵ [0,1]ⁿ, let πμ be the product distribution where entries of μ define the mean of Boolean variables
Theorem 1: Concept Function: decision tree f: {0,1}ⁿ → {–1,+1} of size s Distribution: πμ defined by μ ϵ ν+[–.01,.01]ⁿ where ν ϵ [.02,.98]ⁿ Data: m=poly(ns/ε) training examples (xj, f(xj)) j≤m: xj iid from πμ, Learning Algorithm: a polynomial-time algorithm Output: a function h Quality: Prx←πμ
[ sgn(h(x))≠f(x) ] ≤ ε.

Fourier over Product Distributions
• x ϵ {0,1}ⁿ, μ ϵ [0,1]ⁿ,
1
22
2
(1 )
[ ] (also called ( , ))
ˆ ˆ( ) ( ) ( ) E [ ( ) ]
ˆ ˆ ( ) (Pars
for any
, where
1 eval)
ˆ ˆ ( )
i ii
i i
S i Si S
S SS
S
S
x
n x
f x f S f
x
x x S
x S f x
f f
x
S
f f S
E [ ]i ix

Non-Concentration Bound on Fourier Structures
For any f:{0,1}ⁿ→{–1,1}, α,β > 0, and d ≥ 1,
Continuous generalization of Schwartz-Zippel theoremLet p:Rⁿ→R be a degree-d multi-linear polynomial with leading
coefficient of 1. Then, for any ό>0,
25[.49,.51]
ˆ ˆPr s.t. ( ) ( ) 200n
dS T f S f T T d
[ 1,1]Pr ( ) 2
n
d
xp x
ò ò
e.g., p(x)=x1x2x9+.3x7–0.2

Some Related Work
• Decision Trees:
• P.A.C. Membership Queries:
• Uniform Distributions
[Kushilevitz-Mansour’91; Goldreich-Levin’89]
• [Bshouty’94]
• Agnostic Membership Queries: Uniform D
[Gopalan-Kalai-Klivans’08]• DNF: P.A.C. Membership Queries + Uniform D [Jackson’94]

Some Smoothed Results in Learning(Kalai-Samorodnitsky-Teng)
• PAC learn decision trees over smoothed (constant-bounded) product distributions
• PAC learn DNFs over smoothed (constant-bounded) product distribution
• Agnostically learn decision trees over smoothed (constant-bounded) product distributions

Games and Optimization

Optimization
President UUSA(xUSA,xCA,xMA,…)
Global optimum Local optimumApproximation

Multi-Objective Optimization
President UUSA(xUSA,xCA,xMA,…)
Pareto optimum [Approximation]
UCA(xUSA,xCA,xMA …) UMA(xUSA,xCA,xMA,…)
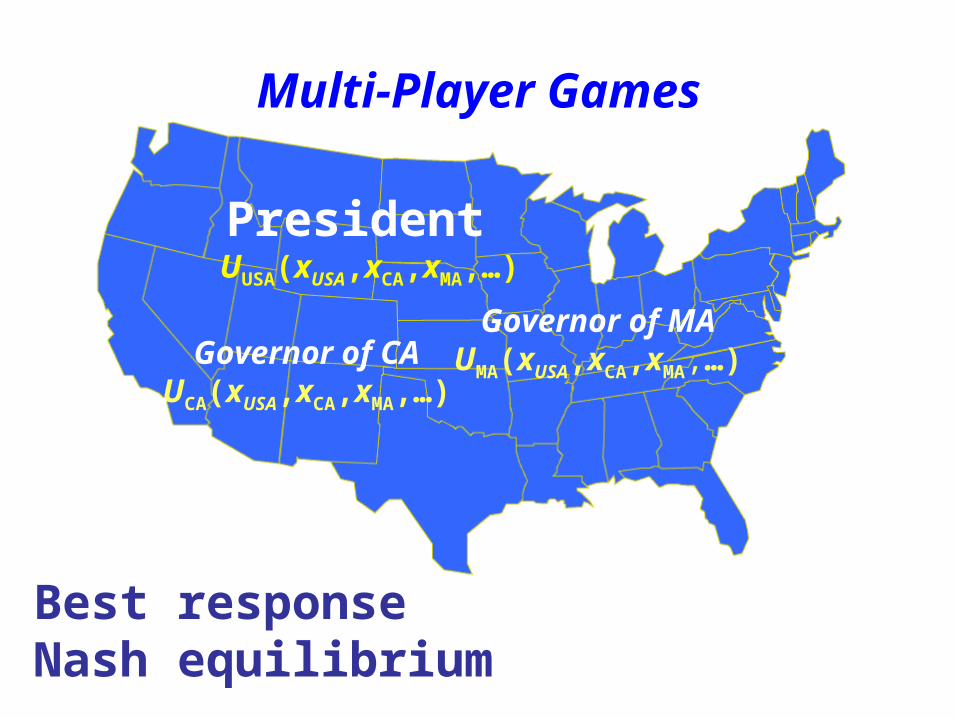
Multi-Player Games
President UUSA(xUSA,xCA,xMA,…)
Best response Nash equilibrium
Governor of CAUCA(xUSA,xCA,xMA,…)
Governor of MAUMA(xUSA,xCA,xMA,…)

“Is the smoothed complexity of (another classic algorithm,)Lemke-Howson (algorithm) for two-player games,
polynomial?”
0
0
1
-1
-1
1
-1
1
0
0
1
-1
1
-1
-1
1
0
0
BIMATRIX Games
Mixed Strategies

Mixed equilibrium always exists:
Search Problem: Find an equilibrium
Nash Equilibria in Two-Player Games

Exchange Economies
• Traders
• Goods
• Initial Endowments:
• Utilities:

Arrow-Debreu Equilibrium Price
A price vector
Distributed Exchange
• Every Trader:– Sells the initial endowment to “market”: (to get a budget)
– Buys from the “market” to optimize her individual utilities
• Market Clearing Price

Smoothed Model

Complexity of Nash Equilibria
[Daskalakis-Goldberg-Papadimitriou, 2005]• For any constant k ≥ 3, NASH is PPAD-hard.
[Chen-Deng, 2005]• 2-player NASH is PPAD-complete.
[Chen-Deng-Teng, 2006]• If PPAD is not in P, then 2-player NASH does not have a fully
polynomial-time approximation scheme

Smoothed Complexity of Equilibria
[Chen-Deng-Teng, 2006]
• NO Smoothed Polynomial-Time Complexity for Lemke-Howson or any BIMATRIX algorithm, unless computation of game and market equilibria and Brouwer fixed points is in randomized P!
[Huang-Teng, 2006]
• Computation of Arrow-Debreu equilibria in Leontief Exchange Economies is not in Smoothed P, unless …

PSPACE
NP
PLS PPAD
Complexity Classes and Complete Problems
P

Tale of Two Types of Equilibria
Local Search
(Potential Games)• Linear Programming
– P
• Simplex Method– Smoothed P
• PLS– FPTAS
• Intuitive
Fixed-Point Computation
(Matrix Games)• 2-Player Nash equilibrium
– Unknown
• Lemke-Howson Algorithm– If in P, then NASH in RP
• PPAD– FPTAS, then NASH in RP
• Intuitive to some

A Basic Question
Is fixed point computation fundamentally harder than local search?

Random Separation of Local Search and Fixed Point Computation
Aldous (1983): • Randomization helps local search
Chen & Teng (2007):• Randomization doesn’t help Fixed-Point-
Computation!!!
… in the black-box query model

Open Questions
• How hard is PPAD?
• Non-concentration of multi-linear polynomials
• Optimal smoothed bound for Pareto Sets

Non-Concentration of Multi-linear Polynomials
Continuous Schwartz-Zippel Conjecture:Let p:Rⁿ→R be a degree-d multi-linear polynomial with constant
coefficient of 1. Then, for any ό>0,
[ 1,1]Pr ( ) 2
n
d
xp x
ò ò
Related Documents











