1 OPTIMISATION DE LA COLLECTE DES DONNEES Place, principe et intérêt des plans d’expériences Christian J. Ducauze et Thanh X . Bui 1. Introduction : contexte d’une optimisation de la collecte des données Comprendre en quoi consiste une organisation optimale de la collecte des données nécessite de situer cette démarche dans celle de l’analyticien, telle qu’elle est présentée sur la Figure 1. Cette optimisation, qui a pour but de recueillir l’information souhaitée à moindre frais, c’est-à-dire en un minimum d’expériences, va en effet s’appuyer sur l’existence d’un modèle implicite ou explicité. Une modélisation préalable sera donc nécessaire, laquelle revient en fait à passer du problème posé à un problème analytique. Savoir poser le problème puis le modéliser sont certainement les deux opérations les plus délicates : elles conditionnent toute la suite et le succès de l’étude, elles exigent que l’analyticien mette en oeuvre tout son savoir-faire, son intelligence et son bon sens.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
OPTIMISATION DE LA COLLECTE DES DONNEES
Place, principe et intérêt des plans d’expériences
Christian J. Ducauze et Thanh X . Bui
1. Introduction : contexte d’une optimisation de la collecte
des données
Comprendre en quoi consiste une organisation optimale de la collecte des données
nécessite de situer cette démarche dans celle de l’analyticien, telle qu’elle est présentée
sur la Figure 1. Cette optimisation, qui a pour but de recueillir l’ information souhaitée à
moindre frais, c’est-à-dire en un minimum d’expériences, va en effet s’appuyer sur
l’existence d’un modèle implicite ou explicité. Une modélisation préalable sera donc
nécessaire, laquelle revient en fait à passer du problème posé à un problème analytique.
Savoir poser le problème puis le modéliser sont certainement les deux opérations les
plus délicates : elles conditionnent toute la suite et le succès de l’étude, elles exigent que
l’analyticien mette en œuvre tout son savoir-faire, son intelligence et son bon sens.

2
ModèleProblème
3.Echantillonnage
1.Modélisation
6.ValidationPrédiction
5.Structuration des données
4.Analysechimique
2.Organisation de
la collectedes données
Méthodes
LoisDécisions
informationchimique
Figure 1 : Démarche de l’Analyticien : place de l’organisation de la collecte des données
2. Définition du Problème et modélisation
Poser un problème résulte toujours de la confrontation à une obligation de prendre une
voire plusieurs décisions, qu’il s’agisse de décisions visant à améliorer la qualité d’un
produit, la qualité et/ou le rendement d’une production, etc. ou tout simplement
d’énoncer une conclusion sur l’observation d’un phénomène. L’étude à entreprendre
aura un prix ; on attend de la décision qu’elle apporte un bénéfice, qu’il soit
économique ou purement cognitif ; la préoccupation sous-jacente à la démarche de
l’analyticien sera d’obtenir un rapport coût sur bénéfice qui soit le plus petit possible.

3
Bien poser le problème demande :
1. d’expliciter clairement le ou les objectifs poursuivis et d’estimer les bénéfices
escomptés ; dans le cas où plusieurs objectifs seraient visés à la fois, d’établir une
hiérarchie entre eux. Quelle est la priorité ?
2. d’énoncer les décisions à prendre, dont on pense qu’elles devraient permettre
d’atteindre le(s) objectifs ;
3. de s’interroger sur les risques consécutifs à la prise de mauvaises décisions. L’effort
consenti (coût de l’étude) pourra être d’autant plus important que le risque est
grand ;
4. de préciser ensuite les questions auxquelles on doit être en mesure de répondre pour
pouvoir prendre les bonnes décisions ;
5. enfin, de hiérarchiser l’ensemble de ces questions.
L’ensemble des questions hiérarchisées constitue l’énoncé du problème. Il détermine la
ou les études à entreprendre. Dans ce but, on va devoir modéliser le problème, c’est-à-
dire chacune des questions posées, en progressant comme suit :
1. On va se demander tout d’abord – et c’est fondamental – si une information
chimique est capable d’apporter une réponse à la question posée, si le problème va
trouver une solution à travers cette information. Autrement dit : est-il possible de
traduire la question posée en un problème d’analyse ?
2. Si c’est le cas, on va choisir la réponse qu’il faut mesurer et la méthode d’analyse
adaptée. Or cette méthode comporte un bruit de fond ; ceci veut dire que les données
collectées par la répétition d’une même analyse sur le même échantillon auront une
certaine dispersion, qu’on peut caractériser au moyen d’une estimation de l’écart-
type. La prise en compte de ce critère est importante si l’on souhaite pouvoir mettre
en évidence des variations de la réponse, les faire ressortir du bruit de fond de la
méthode.
3. On va ensuite s’interroger sur les facteurs susceptibles d’influencer la réponse,
d’expliquer –même si l’on ne sait pas pourquoi- ses variations mesurées. On va
recenser très largement ces « facteurs explicatifs » : tout facteur, même s’il y a
doute, sera pris en compte dans un premier temps, quitte à l’éliminer très rapidement

4
dans une première opération de criblage. Cette recherche des facteurs explicatifs
demande de rassembler toutes les informations existantes (connaissances théoriques,
données bibliographiques, expériences antérieures dont les résultats auront été
structurés au moyen des méthodes statistiques multidimensionnelles de l’analyse des
données).
4. On va définir le domaine expérimental, domaine dans lequel seront étudiées les
valeurs de la réponse suivant les valeurs affectées à chaque facteur. Ce sont les
bornes inférieure et supérieure de chaque facteur qui fixent l’étendue du domaine
exploré, du domaine d’intérêt. Une question doit être ici immédiatement posée :
est-on en mesure de fixer précisément un facteur à une valeur prédéterminée, à un
niveau choisi ? Si oui, on parlera de facteur contrôlé.
5. Reste alors à choisir une stratégie de collecte des données.
3. Les différentes stratégies de collecte des donné es
Plusieurs stratégies de collecte sont en effet possibles. Elles s’appuient toutes sur
l’existence implicite d’une surface de réponse. Selon la stratégie choisie, on cherchera
ou non à déterminer cette surface de réponse qu’on peut représenter, comme sur la
Figure 2, au moyen de courbes d’isoréponses, courbes pour lesquelles une même
réponse est obtenue lorsqu’on fait varier les facteurs. Quelle stratégie choisir ?
La première, la plus habituelle – mais aussi certainement la plus mauvaise – consiste à
faire varier un facteur à la fois. Pour mieux comprendre, prenons l’exemple simple
d’une réponse R (par exemple : l’altitude) qui dépendrait de 2 facteurs X1 et X2 (par
exemple : la longitude et la latitude). Ce cas est illustré par la Figure 2 où les courbes
d’isoréponses sont, par exemple, les courbes de niveaux qu’on trouve sur une carte
d’état major.

5
100 5075150125 100125150
125
150
175
200
225
Optimum local
Optimum vrai
Optimum trouvé
2ème série
1ère s
érie
10 504020 30
1.0
3.0
2.5
2.0
1.5
Figure 2 : Recherche d’un optimum du domaine expérimental au moyen d’une stratégie
consistant à faire varier un facteur à la fois. Les points expérimentaux indiquent pour
quelles valeurs de X1 et X2 la réponse R a été mesurée
Dans un premier temps (1ère série d’essais), X1 étant fixé, on fait varier X2 et l’on repère
la « meilleure valeur de X2 », celle pour laquelle la valeur mesurée de R est la plus
élevée. C’est à cette valeur, dans un deuxième temps (2ème série d’essais), qu’on va fixer
X2 pour faire varier X1 à son tour. Il se peut – avec beaucoup de chance ! comme ici –
qu’on aboutisse immédiatement pour l’optimum à la valeur de X1 qui avait été
précisément choisie au départ. Mais, en règle générale, on va être obligé de procéder
par itération pour pouvoir atteindre cet optimum. Cela veut dire qu’on n’est pas en
mesure de prévoir le nombre d’essais qu’il faudra réaliser et qu’une telle
expérimentation pourra se révéler coûteuse. Mais là n’est pas le moindre défaut : nous
voyons en effet que cette stratégie ne permet pas forcément d’atteindre un optimum
local et encore moins l’optimum du domaine d’intérêt. En appliquant cette stratégie, on
ne peut en fait trouver l’optimum que si les courbes d’isoréponses sont des droites
parallèles (Figure 3), ce qui correspond à un modèle du type :

6
R = a0 + a1X1 + a2X2 , (1)
modèle dans lequel il n’y a pas d’interaction entre les facteurs X1 et X2.
Au contraire, si cette interaction existe, comme dans le modèle :
R = a0 + a1X1 + a2X2 + a12X1X2 , (2)
la stratégie choisie ne permet pas, comme nous l’avons vu pour un modèle plus
complexe (Figure 2), d’atteindre l’optimum recherché.
Optimum vrai
Optimum trouvé 2ème série
1ère s
érie
10 504020 30
1.0
3.0
2.5
2.0
1.5
Figure 3 : Recherche de l’optimum du domaine expérimental au moyen d’une stratégie
consistant à faire varier un facteur à la fois. Les points expérimentaux (carrés) indiquant
pour quelles valeurs de X1 et X2 la réponse R a été mesurée. On suit le trajet 1 (1ère série) puis
le trajet 2 (2ème série) 22110 XaXaaR ++=
Une deuxième stratégie possible est de mesurer la réponse R en des points
expérimentaux (cercles) disposés – comme indiqué sur la Figure 4– aux nœuds d’un
réseau dont on a préalablement défini la maille et qui couvre tout le domaine
expérimental. Cette stratégie, quoique coûteuse en essais, présente un avantage : elle

7
permet de se faire une idée de l’allure de la surface de réponse si, au départ, on n’a
aucune idée sur ce point. Elle peut être utile si le domaine expérimental est étendu et la
surface de réponse supposée compliquée : elle permet éventuellement de restreindre le
domaine d’intérêt à une zone plus étroite dans laquelle on augmente ses chances de
retrouver le véritable optimum du domaine exploré. Rien n’interdit ensuite, dans ce
domaine restreint, de conduire une autre stratégie. On peut en effet combiner
successivement, dans le cadre d’une même étude, différentes stratégies.
100 5075150125 100125150
125
150
175
200
225
Optimumlocal
Optimum vrai
C
A B
10 504020 30
1.0
3.0
2.5
2.0
1.5
Figure 4 : Organisation des essais en réseau et recherche d’un domaine expérimental
restreint. Le domaine A semble a priori le plus intéressant à explorer pour trouver l’optimum
du domaine expérimental
Il est justement possible, dans un domaine expérimental suffisamment restreint et
judicieusement choisi, de rechercher l’optimum par une méthode de simplex(e) qui fait
partie d’une autre stratégie. En quoi consiste-t-elle ?
On choisit tout d’abord, dans le domaine d’intérêt, un simplex de base qui, si la réponse
mesurée dépend de n facteurs, comporte n + 1 points expérimentaux. Pour prendre

8
l’exemple simple – représenté sur la Figure 5 – d’une réponse R qui est fonction des 2
facteurs X1 et X2, le simplex de base va comporter trois points expérimentaux (1, 2, 3)
où R sera mesurée.
100 5075150125 100125150
125
150
175
200
225
Optimum local
Optimum vrai
Optimum trouvé
Essai interdit
10 504020 30
1.0
3.0
2.5
2.0
1.5 1 2
3
a
bc
4
Figure 5 : Recherche d’un optimum par une méthode de simplex. Incidence du choix du
simplex de base
On recherche alors le point correspondant à la plus mauvaise des réponses pour définir,
en son symétrique par rapport à l’ensemble des autres points, un nouveau point
expérimental où sera réalisée la mesure suivante : c’est par exemple le point (4) de la
Figure 5. Puis on procède par itération ; c’est-à-dire qu’on recherche de nouveau la plus
mauvaise des réponses sur les n points conservés du simplex précédent et le nouveau
point.

9
Ainsi, par cette démarche séquentielle, on devrait progresser pas à pas vers un optimum.
Représentera-t-il le véritable optimum du domaine d’intérêt ou seulement un optimum
local ? On l’ignore car une telle stratégie ne permet pas de déterminer la surface de
réponse, bien qu’elle en suppose l’existence. L’optimum atteint dépend du choix du
simplex de base, de sa taille et de son positionnement sur le domaine expérimental :
c’est ce qui est montré sur la Figure 5 où un nouveau simplex de base (a, b, c) a été
choisi.
On voit donc les inconvénients de cette nouvelle stratégie :
- elle ne permet pas de prévoir, avant de commencer l’expérimentation, le nombre
d’essais qu’il faut réaliser ;
- ne permettant pas de déterminer la surface de réponse, elle risque de nous conduire à
un optimum local qui ne correspond pas forcément à la meilleure combinaison
possible des facteurs expérimentaux.
Elle présente cependant un sérieux avantage si l’on souhaite trouver l’optimum d’un
domaine d’intérêt suffisamment restreint : c’est en particulier le cas lorsqu’on se
propose de trouver le réglage optimal des paramètres (= facteurs contrôlés) d’une chaîne
de fabrication, sans avoir pour autant à interrompre la production ; on ne peut en général
consentir que de faibles variations des paramètres, autour de leurs valeurs habituelles,
pour ne pas avoir à rejeter ensuite la majeure partie des produits fabriqués pendant
l’expérimentation.
Enfin, comme cela a déjà été dit, rien n’empêche de combiner cette stratégie avec une
ou plusieurs autres stratégies. Ce qui est important, c’est de savoir choisir la stratégie la
mieux adaptée au problème et d’avoir clairement conscience, à chaque étape de l’étude,
de la stratégie qui est appliquée à la collecte des données.
Une dernière stratégie doit être présentée : elle s’appuie sur la méthode des plans
d’expériences.
4. Plan et principe des plans d’expériences
La réponse à mesurer ayant été choisie, les facteurs expérimentaux ayant été
sélectionnés et, pour chacun d’eux, les limites du domaine de variation ayant été
précisées – c’est ainsi qu’a été défini le domaine d’intérêt –, la méthode des plans
d’expériences va exiger qu’on pose un modèle dès le départ : il s’agit d’un modèle a

10
priori , choisi en fonction de la connaissance qu’on a du phénomène et/ou de l’objectif
poursuivi au moment de la collecte des données.
Si l’on suppose, par exemple, que la réponse doit être linéaire à l’ensemble des facteurs,
on va écrire un modèle de la forme : ∑∑∑⟩
−
==
++=ij
n
ijiij
n
iii XXaXaaR
1
110 (3)
Par contre, si l’on pressent que la réponse aura une forme plus compliquée comme
fonction des facteurs pris en compte, on peut poser d’autres modèles, par exemple :
∑∑ ∑∑⟩
−
= ==
+++=ij
n
i
n
iiiijiij
n
iii XaXXaXaaR
1
1 1
2
10 (4)
Ce dernier modèle peut d’ailleurs être considéré comme une excellente approximation
d’un modèle exponentiel dans un étroit domaine de variation des variables considérées.
Mais le modèle qu’on pose n’est pas à prendre seul en considération : à ce stade de la
collecte, l’objectif poursuivi est tout aussi important. En admettant, par exemple, qu’on
ait initialement retenu un très grand nombre de facteurs susceptibles d’ « expliquer » la
réponse et que l’on veuille établir une discrimination entre eux pour distinguer – c’est-à-
dire trier, cribler – ceux qui ont une influence de ceux qui n’en ont pas, il est évident
qu’il sera plus approprié, dans ce but, de poser un modèle intrinsèquement linéaire du
type (3) plutôt qu’un modèle du deuxième degré. En effet, répondre par « oui » ou par
« non » qu’un facteur a un effet sur la réponse ne demande pas qu’on connaisse l’allure
de cette réponse : quelle que soit sa forme entre les bornes inférieure et supérieure qui
sont assignées aux valeurs du facteur, on ne fait que s’interroger sur le fait qu’il y a eu
ou non variation de la réponse entre ces deux valeurs limites du facteur contrôlé ; on
dira, en d’autres termes, qu’entre deux points, toute courbe peut être assimilée à une
droite et que, si l’objectif est d’affirmer qu’il y a eu ou non variation de la réponse entre
ces deux points, prendre une droite suffit. Elle est en effet déterminée par deux points,
alors qu’il en faut au moins trois pour déterminer une fonction parabolique comme celle
du modèle (4). En conséquence, lorsqu’on se propose d’effectuer un tri parmi les
facteurs pour ne retenir que ceux ayant effectivement une influence sur la réponse –
c’est l’opération de criblage dont il a été précédemment question – un modèle
intrinsèquement linéaire du type (3) sera le plus approprié puisqu’il permet de prendre
une décision en diminuant le nombre des essais.

11
Comme on vient de le voir, poser le modèle au départ est extrêmement important car la
forme de ce modèle implique la façon optimale d’organiser la collecte des données : on
a intuitivement perçu que deux points expérimentaux suffisent pour un modèle
intrinsèquement linéaire, alors qu’il en faut trois pour un modèle parabolique.
En fait le modèle initialement posé implique la manière dont le calcul sera ensuite
conduit, partant des résultats expérimentaux, c’est-à-dire des réponses mesurées, pour
déterminer les coefficients ai et aij du modèle. Ce que l’on veut, connaissant le mode de
calcul des coefficients du modèle posé a priori, c’est minimiser la répercussion de
l’erreur expérimentale – ou aléa expérimental – attachée à chaque essai sur la
détermination de chacun de ces coefficients. Pour cette raison, le modèle posé et, par
voie de conséquence, la méthode de calcul qui s’attache à la détermination de ses
coefficients, va dicter la façon optimale d’organiser les essais, laquelle sera présentée
sous la forme d’un plan d’expérience.
Le modèle étant posé, on va choisir, en un deuxième temps, le plan d’expérience
optimal qui vise à réduire la répercussion des erreurs expérimentales sur la
détermination du modèle. Ce plan propose un certain nombre d’essais qu’il faut
impérativement réaliser : il ne faut pas perdre de vue en effet que pour atteindre le but
énoncé, le plan d’expérience proposé représente un tout et que le but ne pourra être
atteint qu’à la condition de pouvoir réaliser la totalité des essais prévus par le plan.
Le troisième point sera donc de s’interroger sur la faisabilité du plan d’expérience : est-
on en mesure, compte tenu des niveaux fixés à l’avance pour chaque facteur, de réaliser
chacun des essais prévus ? Des contraintes expérimentales et/ou économiques (coût) ne
s’opposent-elles pas à ce qu’on puisse mener jusqu’au bout l’expérimentation prévue ?
Ayant levé cette hypothèque, il n’y aura plus qu’à réaliser l’ensemble des essais prévus,
dans un ordre librement défini pour essayer de s’affranchir de certaines contraintes liées
à l’expérimentation, réduire par exemple le nombre de manipulations ou de réglages,
pallier la dérive d’un instrument de mesure, etc.
La dernière étape consistera à interpréter les résultats expérimentaux en résolvant un
système d’équations plus ou moins complexe pour déterminer l’ensemble des
coefficients du modèle initialement posé. On s’interrogera sur la signification de chacun
des coefficients : est-il significativement différent de zéro ou, autrement dit, l’effet du
facteur ou de l’interaction correspondante doit-il être pris en considération ? On essaiera
enfin, par différentes méthodes statistiques, de valider le modèle et tester son pouvoir

12
prédictif : dans ce but, on pourra par exemple essayer d’évaluer la qualité de la
régression ou d’évaluer encore, par la somme des carrés des résidus, l’ajustement aux
réponses expérimentales, mesurées lors de l’exécution du plan, des réponses prédites
par le modèle lorsqu’on assigne aux facteurs les mêmes valeurs que celles choisies pour
chaque essai.
Par la démarche qui vient d’être décrite on aboutit donc à la connaissance de la surface
de réponse qui permettra, dans le domaine d’intérêt et pour lui seul, de prédire les
réponses. Il est à noter cependant qu’assez souvent – si l’on procède en particulier à une
opération de criblage au moyen de plans factoriels complets ou fractionnaires- on n’ira
pas forcément au bout de cette démarche : on pourra se contenter, partant des réponses
mesurées, de mettre en évidence les effets des facteurs et de leurs interactions.
5. Intérêt des plans d’expériences : étude d’un exe mple
L’exemple présenté ici a été décrit par Harold HOTTELING1 en 1944. Il est frappant
car il porte sur une expérimentation très simple qui consiste à déterminer la masse de
plusieurs objets au moyen d’une balance à deux plateaux. Il est étonnant qu’il ait fallu
attendre une date aussi récente pour s’interroger sur la meilleure façon d’opérer !
Quel est le problème ? Il est demandé de « déterminer les masses pj de k objets avec un
maximum d’efficacité ». Mais que veut dire « maximum d’efficacité » ? La question
ainsi posée n’est pas suffisamment explicite et si l’on demande donc plus de précisions,
on va apprendre pour cet exemple que ce qui est réellement souhaité c’est d’avoir à la
fois un nombre de pesées minimal et une évaluation de la masse de chaque objet qui soit
la plus proche possible de sa « vraie valeur ». Mais lequel de ces deux impératifs est
prioritaire sur l’autre ? Admettons que ce soit le premier. Le problème est alors bien
posé : les contraintes ont été hiérarchisées, la priorité définie. Nous savons :
1. qu’il faut faire un minimum de pesées et, s’il nous est demandé par exemple de
peser 3 objets (k = 3), nous aurons au moins N = k + 1 = 4 pesées à effectuer car il
faut au départ faire la tare, c’est-à-dire placer un poids p0 sur l’un des deux plateaux
de la balance pour ramener l’aiguille au zéro ;
1 HOTELLING H. Some problems in weighing and other experimental techniques Am. Math. Sta (1944), 15, 297-306

13
2. qu’il faut ensuite trouver la meilleure stratégie pour que l’erreur de lecture attachée
à chaque pesée se répercute le moins possible sur l’estimation jp de la masse de
chaque objet. Nous ferons l’hypothèse de l’indépendance statistique des essais, ce
qui revient à dire que l’erreur expérimentale, c’est-à-dire l’aléa expérimental attaché
à chaque pesée n’aura aucune répercussion sur les autres pesées et inversement.
Dans ces conditions, si pj représente la masse d’un objet (1 ≤ j ≤ 3), jp son estimation
( jp est l’estimateur de pj), yi le résultat expérimental de la pesée (i) (c’est le poids qu’il
faut placer sur l’un des deux plateaux de la balance pour ramener l’aiguille au zéro) et Yi
le résultat théorique de la pesée (i), on va écrire :
yi = Yi + ei (5)
où ei représente l’aléa expérimental
E (ei) = 0 (6)
var (yi) = var (ei) = σ2 (7)
cov (yi, yi+ 1) = 0 (8)
Ecrire que l’espérance mathématique de ei, E (ei), est nulle exprime que l’erreur de
lecture sur la position de l’aiguille par rapport au zéro a la même probabilité
d’apparaître à gauche qu’à droite. On a posé que la dispersion des ei peut être mesurée à
travers la variance σ et exprimé l’indépendance statistique des essais – ce sont les
pesées – par la nullité de la covariance de deux résultats expérimentaux quelconques yi
et yi+ 1.
Il s’agit maintenant de poser le modèle. Il est simple :
Y = p0 + p1X1 + p2X2 + p3X3 (9)
Dans ce modèle, Xj (1 ≤ j ≤ 3) peut prendre 3 valeurs xij lors de la pesée (i) qui seront,
par convention, –1 lorsque l’objet est placé sur le plateau de gauche de la balance, +1
lorsqu’il est placé sur le plateau de droite et 0 si l’objet n’est placé sur aucun des 2
plateaux. On écrira donc comme suit le résultat expérimental yi de la pesée (i) :
yi = p0 + p1xi1 + p2xi2 + p3xi3 + ei (10)
Partant du modèle (9), on va alors essayer de mettre en œuvre différents plans
d’expériences pour comparer leurs efficacités respectives.

14
Le plan habituel, apparemment le plus simple – celui auquel chacun pense
immédiatement –, consiste après avoir fait la tare, à placer successivement chacun des 3
objets sur le plateau de droite de la balance pour effectuer une pesée. Cette façon
d’organiser les essais est résumée dans le Tableau 1.
valeurs affectées à la
variable X
résultat théorique résultat expérimental
essai X1 X2 X3
1 x11 = 0 x12 = 0 x13 = 0 Y1 = p0 … … … y1 = p0 … … … +e1
2 x21 = +1 x22 = 0 x23 = 0 Y2 = p0 + p1 … … y2 = p0 + p1 … … +e2
3 x31 = 0 x32 = +1 x33 = 0 Y3 = p0 … +p2 … y3 = p0 … +p2 … +e3
4 x41 = 0 x42 = 0 x43 = +1 Y4 = p0 … … +p3 y4 = p0 … … +p3 +e4
Tableau 1 : Plan d’expérience consistant à peser un objet à la fois.
Sans aucune difficulté, on déduit du tableau 1 que :
pj = Yi+1 – Y1
p0 = Y1
11ˆ yyp ij −= +
10ˆ yp =
Il est donc possible, lorsqu’on met en œuvre ce plan d’expérience d’obtenir une
estimation des coefficients p0, p1, p2 et p3 du modèle, c’est-à-dire d’avoir en 4 pesées
une estimation de la masse des 3 objets. Encore faudrait-il que cette estimation soit juste
et que l’intervalle de confiance dejp , calculé à partir de la variance dejp , soit le plus
petit possible.
Dire que l’estimation jp de pj est juste ou, autrement dit, que cette estimation ne
présente pas de biais, revient à écrire qu’il faut que :
jj ppE =)ˆ(

15
Or )()()()ˆ( 1111 yEyEyyEpE iij −=−= ++
= 11 YYi −+
= jj pppp =−+ 00
Il s’agit donc bien d’une estimation non biaisée de pj.
On peut par ailleurs calculer la variance de jp :
),cov(2)var()var()var()ˆvar( 111111 yyyyyyp iiij +++ −+=−=
= σ 2 + σ 2 - 0
= 2 σ 2
et var ( 0p ) = var (y1) = σ 2
En conclusion, ce premier plan d’expérience a permis d’estimer sans biais, en un
nombre minimum de pesées (N = 4), les masses de 3 objets, la variance de jp étant
égale à 2 σ 2, si σ 2 représente la variance du résultat expérimental.
On peut alors se demander si d’autres plans d’expériences ne pourraient pas être mis en
œuvre pour aboutir à de meilleurs résultats ?
Essayons, par exemple, de placer tous les objets sur le plateau de gauche pour la
première pesée puis, pour les 3 pesées suivantes, de placer successivement chaque objet
sur le plateau de droite, les deux autres restant sur le plateau de gauche. C’est le plan
d’expérience présenté sur le Tableau 2.

16
n° de l’essai valeurs données à Xj résultat théorique résultat
expérimental
Pesée n° 1 - 1 - 1 -1 Y1 = p0 - p1 - p2 - p3 y1 = Y1 + e1
Pesée n° 2 + 1 - 1 - 1 Y2 = p0 + p1 – p2 – p3 y2 = Y2 + e2
Pesée n° 3 - 1 + 1 - 1 Y3 = p0 – p1 + p2 - p3 y3 = Y3 + e3
Pesée n° 4 - 1 - 1 + 1 Y4 = p0 – p1 – p2 + p3 y4 = Y4 + e4
Tableau 2 : Plan d’expérience consistant à utiliser les 3 objets pour chaque pesée (tous les
objets sont sur le plateau de gauche pour la première pesée)
On déduit du Tableau 2 que :
0p = (-y1 + y2 + y3 + y4) /2
1p = (y2 – y1) /2
3p = (y3 – y1) /2
4p = (y4 – y1) /2
et, comme précédemment, il est facile de montrer que :
E ( jp ) = pj
var ( jp ) = 4
1 [var (yi+1) + var (y1) – 2 cov (yi+1, y1)] =
2
2σ
Recommençons l’expérimentation mais en plaçant cette fois, pour la première pesée,
tous les objets sur le plateau de droite de la balance, les 3 pesées suivantes restant
identiques à celles effectuées dans le plan précédent. Cette nouvelle expérimentation est
réalisée suivant le nouveau plan d’expérience du Tableau 3.

17
n° de l’essai valeurs données à Xj résultat théorique résultat
expérimental
Pesée n° 1 + 1 + 1 +1 Y1 = p0 + p1 + p2 + p3 y1 = Y1 + e1
Pesée n° 2 + 1 - 1 - 1 Y2 = p0 + p1 – p2 – p3 y2 = Y2 + e2
Pesée n° 3 - 1 + 1 - 1 Y3 = p0 – p1 + p2 - p3 y3 = Y3 + e3
Pesée n° 4 - 1 - 1 + 1 Y4 = p0 – p1 – p2 + p3 y4 = Y4 + e4
Tableau 3: Plan d’expérience consistant à utiliser les 3 objets pour chaque pesée (tous les
objets sont sur le plateau de droite pour la première pesée)
Dans ce cas, la résolution du système linéaire des 4 équations à 4 inconnues (les 4
coefficients du modèle qui représentent la tare et les masses des 3 objets) conduit à
écrire :
4/)(ˆ 43210 yyyyp +++=
4/)(ˆ 43211 yyyyp −−+=
4/)(ˆ 43213 yyyyp −+−=
4/)(ˆ 43214 yyyyp +−−=
Il s’ensuit que : E ( jp ) = pj
var ( jp ) = 16
1 (σ2 +σ2 + σ2
+ σ2) = σ2/4
Ce dernier plan d’expérience permet donc, comme les précédents, d’estimer sans biais
et en 4 pesées, les masses de 3 objets ; mais la variance de jp a été divisée par 2
comparée au plan précédent, par 8 si on la compare à la variance de jp dans le premier
plan. Il peut sembler bizarre, si l’on considère en particulier les deux derniers plans
d’expériences, que le fait de placer, lors de la première pesée, tous les objets sur le
plateau de droite de la balance plutôt que sur le plateau de gauche divise par 2 la
variance jp . En fait, l’explication est simple : il suffit de constater que le mode de
calcul des jp n’est pas le même dans ces deux cas. Dans le dernier plan d’expérience,

18
les essais sont organisés de telle sorte que la façon de calculer jp minimise sa
variance ; c’est le seul plan qui oblige à effectuer une Régression Linéaire Multiple sur
l’ensemble des 4 résultats expérimentaux yi pour estimer chacun des coefficients pj du
modèle.
Effectivement, la théorie associée à ce type de régression montre que, lorsqu’on cherche
à minimiser la variance sur l’estimation des coefficients d’un modèle à partir d’un
système linéaire d’équations, on peut trouver un plan optimal d’organisation des
essais : c’est celui auquel on peut faire correspondre une matrice X telle que le
déterminant (ou norme) XXt de la matrice tXX obtenue en multipliant X à gauche par
sa transposée ait une valeur maximum.
C’est en particulier le cas si la relation suivante est vérifiée :
tXX = NI
où I est la matrice unité et N le nombre d’essais.
C’est le cas idéal des matrices d’Hadamard qui n’existent malheureusement que pour
des valeurs particulières de N :
N = 2 et 4 x l (avec l entier ≥ 1)
Dans ce cas, on démontre en effet que la variance sur l’estimation des coefficients est la
plus petite possible.
Que représente X ? C’est la matrice obtenue en ajoutant à gauche une matrice colonne
d’éléments + 1 au tableau des essais du plan qui fait apparaître, pour chaque essai
(ligne), les valeurs auxquelles ont été fixées chaque variable (colonne). Par exemple, on
va faire correspondre au premier plan d’expérience proposé (Tableau 1) une matrice :
1 0 0 0
1 1 0 0
X = 1 0 1 0
1 0 0 1
Le fait d’ajouter à gauche du tableau des essais une matrice colonne – encore appelée
matrice vecteur - d’éléments 1 n’a rien d’étonnant : ceci correspond au fait que dans le
système d’équations linéaires figurant dans la partie droite du Tableau 1, p0 figure

19
toujours multiplié par + 1 ; c’est en effet la tare et il suffit de se souvenir du modèle (9)
qui avait été posé.
De même, on va associer au dernier plan d’expérience (Tableau 3) une matrice :
1 1 1 1
X = 1 1 -1 -1
1 -1 1 -1
1 -1 -1 1
X correspond au meilleur plan possible car c’est une matrice d’Hadamard.
1 1 1 1 1 1 1 1 4 0 0 0 1 0 0 0 tXX = 1 1 -1 -1 1 1 -1 -1 = 0 4 0 0 = 4 0 1 0 0
1 -1 1 -1 1 -1 1 -1 0 0 4 0 0 0 1 0
1 -1 -1 1 1 -1 -1 1 0 0 0 4 0 0 0 1
La relation tXX = N I est bien vérifiée
Et ici : XXt = 44 est le maximum qu’on puisse avoir pour 4 essais.
Dans ces conditions, la variance sur l’estimation des coefficients du modèle est la plus
petite qu’on puisse atteindre en 4 essais, soit 4
22 σ=σN
Remarque : Pour présenter ce plan optimal sous une forme plus simple, on peut utiliser
les signes + (au lieu de + 1) et – (au lieu de - 1) pour désigner respectivement les
niveaux supérieur et inférieur de chaque variable. Le plan optimal est alors donné par le
tableau :

20
X1 X2 X3
Essai n° 1 + + +
Essai n° 2 + - -
Essai n° 3 - + -
Essai n° 4 - - +
C’est la forme standard de présentation des plans d’expériences.
6. Ordre des essais dans un plan d’expériences opti mal.
Le problème posé est analogue au précédent : il est demandé de déterminer les masses pj
de 3 objets. Mais les contraintes sont maintenant légèrement différentes. On veut :
1. Avoir, en un minimum de pesées, une estimation non biaisée jp de la masse pj de
chaque objet avec une variance de ;8
ˆ2σ=jp
2. Réaliser l’ensemble des pesées en un temps minimum, ce qui veut dire réaliser un
minimum d’opérations entre deux expériences consécutives.
Pour traiter ce problème on va conserver les mêmes notations que celles introduites
dans l’exemple précédent.
Dire qu’on veut avoir pour jp une variance égale à 8
2σ impose de réaliser un minimum
de 8 essais et d’organiser ces 8 expériences sous la forme d’un plan correspondant à une
matrice d’Hadamard, ce qui est possible puisque N = 8. Ecrit sous sa forme standard, ce
plan est donné dans le Tableau 4.

21
Plan des essais
N° de l’essai X1 X2 X3
Nombre d’opérations
à réaliser
1 (1) - - - 3
2 (2) + - - 1
3 (3) - + - 2
4 (4) + + - 1
5 (5) - - + 3
6 (6) + - + 1
7 (7) - + + 2
8 (8) + + + 1
TOTAL = 14
Tableau 4 : Plan d’expérience optimal présenté sous sa forme standard (une opération
correspond au fait de déplacer un objet)
Il est à remarquer que la forme sous laquelle est présentée ce plan d’expérience optimal
– qui est un plan factoriel complet 23 – facilite beaucoup sa construction : il suffit
d’avoir retenu l’alternance des signes + et – dans chacune des colonnes. On aura donc à
effectuer les 8 essais prévus, ce qui implique un total de 14 opérations si les essais sont
effectués dans l’ordre prévu. Cependant rien n’oblige à faire les essais dans cet ordre :
modifier l’ordre ne changera pas en effet le système d’équations qu’il faudra résoudre
ensuite. On a donc toute liberté pour décider d’un ordre qui convient mieux, pour
essayer de satisfaire à la deuxième contrainte qui est de diminuer le nombre des
opérations élémentaires à exécuter. On va choisir l’ordre donné dans le Tableau 5: il
permet de réduire le nombre des opérations de 14 à 10.

22
PLAN D’EXPERIENCE
N° de l’essai X1 X2 X3
Nombre d’opérations
à réaliser
1 (1) - - - 3
2 (2) + - - 1
4 (3) + + - 1
3 (4) - + - 1
7 (5) - + + 1
8 (6) + + + 1
6 (7) + - + 1
5 (8) - - + 1
TOTAL = 10
Tableau 5 : Plan d’expérience optimal. L’ordre des essais a été modifié pour réduire le
nombre d’opérations élémentaires
7. Application de la méthode des plans d’expérienc es dans
le cas où certains facteurs expérimentaux sont des
variables continues.
Dans les exemples précédents, les variables contrôlées X1, X2 et X3 ne pouvaient
prendre que des valeurs discrètes (-1, 0, et +1). Or dans le cadre plus général d’une
expérimentation quelconque, on a souvent affaire à un mélange de facteurs
expérimentaux représentant pour certains des variables discrètes (par exemple, la
présence ou l’absence d’un catalyseur), pour d’autres des variables continues (par
exemple, la température ou la pression). On va alors traiter l’ensemble des facteurs de la
même façon en affectant à chacun d’eux des valeurs discrètes (2 valeurs si l’on fait
appel, comme cela a été le cas jusqu’à présent, à des plans factoriels ; davantage si le
modèle, plus compliqué, impose de choisir d’autres plans d’expériences).
Dans le cas le plus simple mais le plus fréquent où l’on a recours à un plan factoriel, le
modèle étant intrinsèquement linéaire, on ne va attribuer à chaque facteur que deux
niveaux possibles : si le facteur contrôlé est une variable continue, on décide qu’on

23
affecte un niveau + (correspondant à la valeur codée +1 de la variable) à la borne
supérieure de son domaine de variation et un niveau – (valeur codée –1) à la borne
inférieure.
Pour construire le plan d’expériences on est alors ramené aux exemples décrits
précédemment et l’on raisonnera de façon identique sur les valeurs codées de la
variable. Toutefois on ne devra pas perdre de vue, au moment de l’interprétation des
résultats, qu’il faut porter une attention toute particulière au passage des valeurs codées
vers les valeurs réelles que peut prendre chaque facteur.
L’exemple simple de la détermination, dans le domaine de linéarité d’une méthode, de
la pente de la droite d’étalonnage, qui représente la sensibilité de la méthode, va illustrer
ce propos.
Considérons le modèle simple de la droite :
Y = a0 + a1X1
On veut déterminer les coefficients a0 et a1 de ce modèle avec la meilleure « précision »
possible, c’est-à-dire minimiser la variance sur l’estimation de ces deux coefficients.
Dans ce but, on va devoir organiser les essais selon un plan factoriel complet 21 pour
lequel : tXX = 2I. Cette condition est vérifiée en réalisant 2 essais, le facteur contrôlé
X1 – c’est par exemple la concentration – étant successivement fixé à des valeurs codées
–1 et +1. Le plan d’expériences est alors :
Essai n° 1 X1 = -1
Essai n° 2 X1 = +1
Dans ces conditions :
+ 1 + 1 + 1 - 1 2 0 1 0
tXX = - 1 + 1 + 1 + 1 = 0 2 = 2 0 1
Mais, pour conduire les 2 expériences que prévoit le plan, il faut traduire les valeurs
codées de la variable X1 en valeurs réelles.

24
Où va-t-on choisir dans le domaine d’intérêt – le domaine de linéarité de la méthode –
les niveaux – et + de X1 ? Si α et β représentent les valeurs réelles et ei l’aléa
expérimental de l’essai (i)
N°de l’essai X1 ei yi yi = Yi + ei
1 α e1 a0 + a1α + e1 11010 ˆˆ eaaaa +α+=α+
2 β
e2 a0 + a1β + e2 21010 ˆˆ eaaaa +β+=β+
En résolvant ce système d’équations, on trouve :
β−α
β−α+= 12
00ˆee
aa
β−α
−+= 21
11ˆee
aa
Il apparaît ainsi clairement que â1 → a1 si α - β → ∞
On a donc intérêt à choisir des valeurs de X1 aussi éloignées que possible. Cela revient
à dire que la réponse yi devra être mesurée aux bornes du domaine de linéarité, en deux
points – pour deux concentrations par exemple – aussi éloignés que possible l’un de
l’autre.
Remarque : Cependant, cela ne veut pas dire qu’il ne faut réaliser que deux mesures. On
sait en effet qu’en multipliant les mesures en un même point, l’erreur sur la réponse
expérimentale mesurée en ce point peut être diminuée. On fera donc autant de mesures
que l’on veut mais en deux points seulement.
En règle générale et dans la même optique, on a très souvent intérêt, lorsqu’on met en
œuvre une méthode de plans d’expériences, à choisir pour chaque variable contrôlée un
domaine de variation aussi étendu que possible, donc à choisir un domaine
expérimental aussi large que possible et placer les points expérimentaux aux
bornes de ce domaine.

25
8. Réflexion sur la méthode des plans d’expériences et
conclusion
Notre réflexion va s’appuyer sur l’étude d’un exemple construit par simulation qui a fait
l’objet d’une publication2. Dans cet exemple, les auteurs se proposent de déterminer les
coefficients du modèle :
Y = 10 + 2X1 + 3 X2 + 5 X3
A cette fin, les essais ont été organisés selon 3 plans d’expériences différents : le plan 1
(Tableau 6), le plan 2 (Tableau 7) et le plan 3 (Tableau 8). Les tableaux 6, 7 et 8
donnent les valeurs expérimentales, réelles, qui sont attribuées pour chacun des 10
essais de chaque plan aux variables X1, X2 et X3.
X1 X2 X3 ei yi
1,1 1,1 1,2 0,8 22,3
1,2 1,4 1,2 -0,5 22,1
1,3 1,2 1,6 0,4 24,6
1,5 1,4 1,5 -0,5 24,2
1,6 1,8 1,6 0,2 26,8
1,9 1,7 1,9 1,9 30,3
1,9 2,0 2,2 1,9 32,7
2,3 2,2 2,1 0,6 32,3
2,4 2,5 2,4 -1,5 32,8
2,5 2,2 2,5 - 0,5 32,6
Tableau 6 : Résultats du plan 1
2 SERGENT M., MATHIEU D., PHAN-TAN-LUU R., DRAVA G. Correct and incorrect use of miltilinear regression
Chem. And Intel. Laboratory Systems (1995), 27, 153-162

26
X1 X2 X3 ei yi
1,1 1,1 1,2 0,8 22,3
1,4 1,5 1,1 -0,5 22,3
1,7 1,8 2,0 0,4 29,2
1,7 1,7 1,8 -0,5 27,0
1,8 1,9 1,8 0,2 28,5
1,8 1,8 1,9 1,9 30,4
1,9 1,8 2,0 1,9 31,1
2,0 2,1 2,1 0,6 31,4
2,3 2,4 2,5 -1,5 32,8
2,5 2,5 2,4 - 0,5 34,0
Tableau 7 : Résultats du plan 2
X1 X2 X3 ei yi
1,1 1,1 1,7 0,8 24,8
2,5 1,1 1,7 -0,5 26,3
1,8 2,5 1,7 0,4 30,0
1,8 1,4 1,5 -0,5 29,8
1,1 1,1 1,9 0,2 25,2
2,5 1,1 1,9 1,9 29,7
1,8 2,5 1,9 1,9 32,5
1,8 1,4 1,1 0,6 23,9
1,8 1,4 1,8 -1,5 25,3
1,8 1,4 1,8 -0,5 26,3
Tableau 8 : Résultats du plan 3
Sont également données dans chaque tableau les réponses « expérimentales » yi de
chaque essai, sachant qu’une réponse « expérimentale » yi peut être obtenue par

27
simulation, en ajoutant au modèle calculé, un aléa gaussien qui représente l’aléa
expérimental, puisqu’on peut écrire qu’à l’essai (i) la réponse mesurée est :
iiiii exxxy ++++= 321 53210
sachant que :
iii eYy +=
Les aléas gaussiens ei ont été tirés au hasard parmi l’ensemble des valeurs possibles
d’une variable de loi Normale )2;(o
mais, pour pouvoir comparer entre eux les résultats des différents plans, on a admis
qu’à l’essai (i) serait toujours associé le même ei quel que soit le plan envisagé.
Partant des réponses ainsi obtenues, on peut alors calculer par Régression Linéaire
Multiple une estimation des coefficients du modèle à laquelle conduit chacun des plans :
les résultats sont présentés dans le Tableau 9 qui fait clairement apparaître que le plan 3
conduit à la meilleure estimation de a0, a1, a2 et a3 alors que le plan 2 est le plus
mauvais.
Plan 1 Plan 2 Plan 3 à comparer avec
0a 10,24 12,11 9,93 10
1a 0,67 8,26 2,14 2
2a 0,93 -5,52 3,57 3
3a 8,15 6,39 4,58 5
Tableau 9 : Calcul des coefficients estimateurs de aj
Or, si l’on cherchait à valider le modèle à travers des paramètres aussi classiques que le
coefficient de régression multiple au carré R2 (Tableau 10) ou la somme des carrés des
résidus (Tableau 11), que constaterait-on ? En se basant sur ces 2 critères, on serait
amené à penser que le plan 2 est le meilleur et le plan 3 le plus mauvais, conclusion
totalement fausse si l’on se rapporte au (Tableau 9).
28
Plan 1 Plan 2 Plan 3
R2 0,958 0,959 0,872
Tableau 10 : Coefficients de régression multiple au carré R2
Plan 1 Plan 2 Plan 3
7,99 5,90 9,54
Tableau 11 : Somme des carrés des résidus
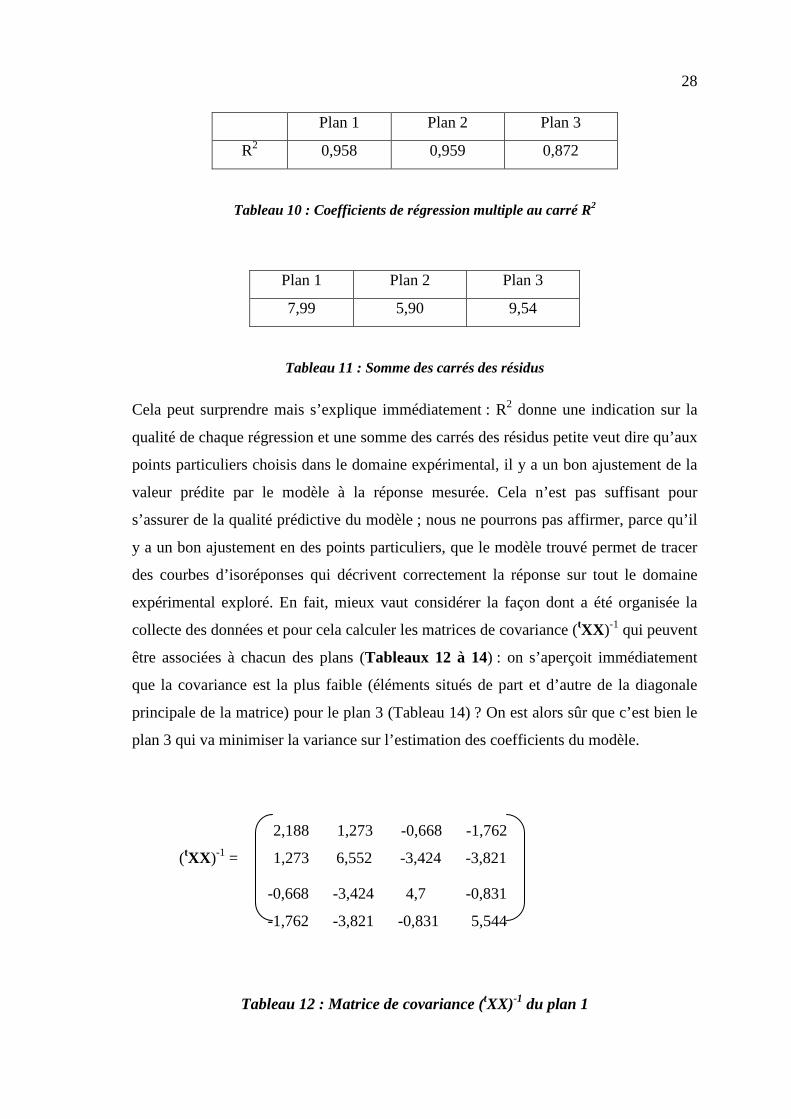
Cela peut surprendre mais s’explique immédiatement : R2 donne une indication sur la
qualité de chaque régression et une somme des carrés des résidus petite veut dire qu’aux
points particuliers choisis dans le domaine expérimental, il y a un bon ajustement de la
valeur prédite par le modèle à la réponse mesurée. Cela n’est pas suffisant pour
s’assurer de la qualité prédictive du modèle ; nous ne pourrons pas affirmer, parce qu’il
y a un bon ajustement en des points particuliers, que le modèle trouvé permet de tracer
des courbes d’isoréponses qui décrivent correctement la réponse sur tout le domaine
expérimental exploré. En fait, mieux vaut considérer la façon dont a été organisée la
collecte des données et pour cela calculer les matrices de covariance (tXX )-1 qui peuvent
être associées à chacun des plans (Tableaux 12 à 14) : on s’aperçoit immédiatement
que la covariance est la plus faible (éléments situés de part et d’autre de la diagonale
principale de la matrice) pour le plan 3 (Tableau 14) ? On est alors sûr que c’est bien le
plan 3 qui va minimiser la variance sur l’estimation des coefficients du modèle.
2,188 1,273 -0,668 -1,762
(tXX )-1 = 1,273 6,552 -3,424 -3,821
-0,668 -3,424 4,7 -0,831
-1,762 -3,821 -0,831 5,544
Tableau 12 : Matrice de covariance (tXX)-1 du plan 1

29
2,407 -0,439 -0,849 0,037
(tXX )-1 = -0,439 28,794 -23,194 -4,694
-0,849 -23,194 22,763 0,384
0,037 -4,694 0,384 4,144
Tableau 13 : Matrice de covariance (tXX)-1 du plan 2
5,708 -0,918 -0,560 -1,731
(tXX )-1 = -0,918 0,510 0 0
-0,560 0 0,373 0
-1,731 0 0 0,962
Tableau 14 : Matrice de covariance (tXX)-1 du plan 3
Ce dernier exemple nous amène à énoncer une conclusion très importante :
Ce ne sont pas les calculs, les traitements statistiques, appliqués a posteriori aux
données qui améliorent la qualité de l’information recherchée. En clair, la façon
dont on organise la collecte des données doit avoir aux yeux de l’expérimentateur
une importance plus grande que les données elles-mêmes.

30
9. Quelques références bibliographiques utiles
COCHRAN W.G, COX G., Experimental design
John Wiley and Sons, New-York, 1969
BOX G.E., HUNTER W.G., HUNTER J.S., Statistics for Experimenters
John Wiley and Sons, New-York, 1971
DEMING S.N., MORGAN S.L., Experimental design : a chemometric approach
Elsevier, Amsterdam, 1987
GOUPY J., La méthode des plans d’expériences
Dunod, Paris, 1996
Related Documents











