1 Instructions for Conducting One-Way ANOVA in SPSS One way ANOVA is used to examine mean differences between two or more groups. It is a bivariate test with one IV and one DV. The IV must be categorical and the DV must be continuous. In this demonstration we describe how to conduct one way ANOVA, and planned and post hoc comparisons. The instructions also include a check for whether the homogeneity of variance has been met. The DV is a measure of base year standardized reading scores (BY2XRSTD); the IV is an indicator of the geographic region of each school (G8REGON). The IV has four values—northeast (coded as 1), north central (coded as 2), south (coded as 3), and west (coded as 4). This analysis is based on 300 randomly selected cases from the NELS database with no missing observations. Although not used in the actual analysis, the data set also includes one weight variable (F2PNWLWT). Copies of the data set and output are available on the companion website. The data set file is entitled, “ONE WAY ANOVA.sav”. The output file is entitled, “One Way ANOVA results.spv ”.

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1
Instructions for Conducting One-Way ANOVA in SPSS
One way ANOVA is used to examine mean differences between two or more groups. It is
a bivariate test with one IV and one DV. The IV must be categorical and the DV must be
continuous. In this demonstration we describe how to conduct one way ANOVA, and planned
and post hoc comparisons. The instructions also include a check for whether the homogeneity of
variance has been met. The DV is a measure of base year standardized reading scores
(BY2XRSTD); the IV is an indicator of the geographic region of each school (G8REGON). The
IV has four values—northeast (coded as 1), north central (coded as 2), south (coded as 3), and
west (coded as 4). This analysis is based on 300 randomly selected cases from the NELS
database with no missing observations. Although not used in the actual analysis, the data set also
includes one weight variable (F2PNWLWT).
Copies of the data set and output are available on the companion website. The data set
file is entitled, “ONE WAY ANOVA.sav”. The output file is entitled, “One Way ANOVA
results.spv ”.
The following instructions are divided into three sets of steps:
1. Conduct an exploratory analysis to a) examine descriptive statistics, b) check for
outliers, c) check that the normality assumption is met, and d) verify that there are
mean differences between groups to justify ANOVA.
2. Conduct the actual one-way ANOVA to determine whether group means are different
form one another (warranting planned or post hoc comparison tests, as described in
step 3). Also, check that the homogeneity of variance assumption is met.
3. Conduct planned or post hoc comparisons if warranted. For illustration purposes, we
provide instructions for conducting both planned and post hoc comparisons.

2
NOTE: There is no way use SPSS to check that the independence assumption has been met. The
independence assumption means that the errors associated with each observation are independent
from one another. For this particular example, it is the assumption that if two students are in the
same region/group, the extent to which the score of one student deviates from the group mean is
not correlated with the extent to which the scores of other students deviate from the group mean.
The independence assumption is met when case selection is random. Thus it is based on the
sampling procedures used to create the sample. Because the NELS study incorporated random
sampling, we assume that the independence assumption has been met. If the independence
assumption is violated, then one-way ANOVA should not be used.
To get started, open the SPSS data file entitled, ONE WAY ANOVA.sav.
STEP 1: Exploratory Analyses
First we calculate descriptive statistics. At the Analyze menu, select Compare Means.
Click on Means. Highlight BY2XRSTD (Reading Standardized Score) and move it to the
Dependent List box. Highlight G8REGON (Composite Geographic Region of School) and move
it to the Independent List box. Click on Options. In the Statistics box, highlight
Variance, Skewness, and Std. Error of Skewness. Click to move them to the Cell
Statistics box. By default Mean, Number of Cases, and Standard Deviation are already in the
Cell Statistics box. If they are not in the Cell Statistics box, move them over now. Click
Continue. Click OK.
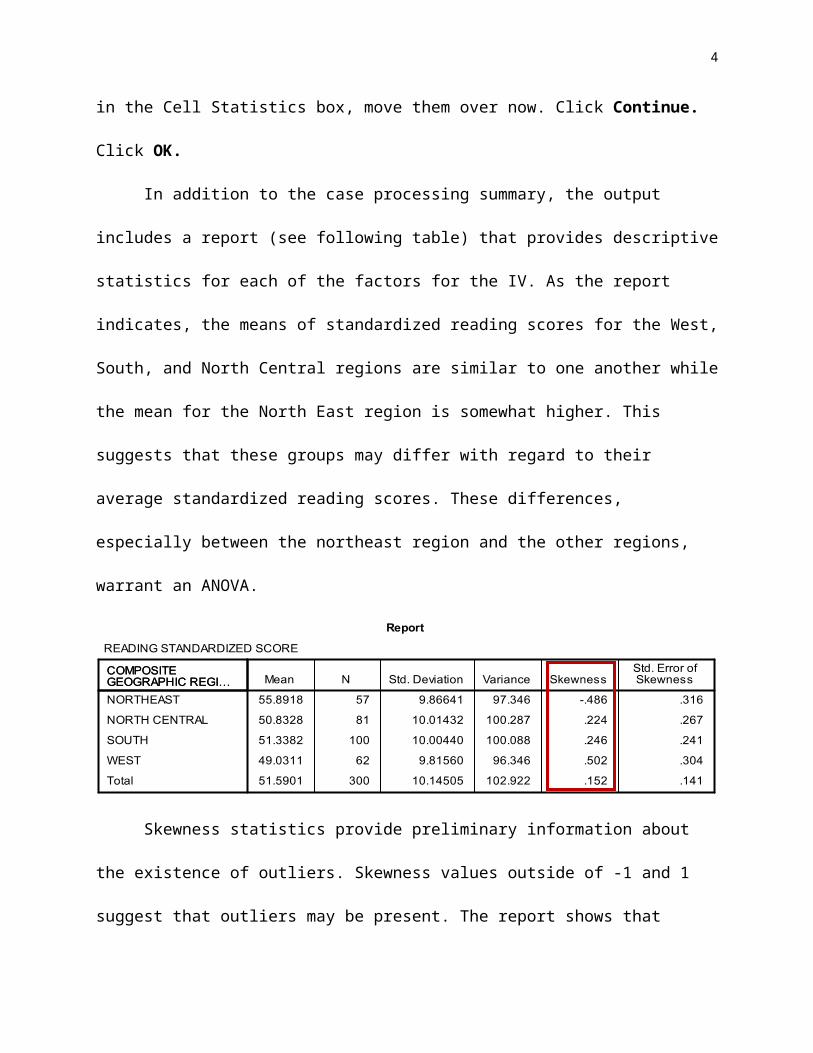
In addition to the case processing summary, the output includes a report (see following
table) that provides descriptive statistics for each of the factors for the IV. As the report
indicates, the means of standardized reading scores for the West, South, and North Central

3
regions are similar to one another while the mean for the North East region is somewhat higher.
This suggests that these groups may differ with regard to their average standardized reading
scores. These differences, especially between the northeast region and the other regions, warrant
an ANOVA.
Skewness statistics provide preliminary information about the existence of outliers.
Skewness values outside of -1 and 1 suggest that outliers may be present. The report shows that
skewness values for all regions fall within -1 to 1 range, suggesting no outliers. We can examine
box plots to confirm this. Select Graphs from the menu, then Legacy Dialogs, then click Box
plot. Click Simple. Within the “Data in Chart Are”, select Summaries for groups of cases.
Click Define. Highlight BY2XRSTD (Reading Standardized Score) and move it to the
Variable box. Highlight G8REGON (Composite Geographic Region of School) and move
it to the Category Axis box. Click OK to create a box plot graph.
The output includes the case processing summary and a graph of the box plots of reading
scores by region. The box plots indicate that none of the regions include outliers.
4
If outliers are present, their cases would be displayed at either end of the respective box
plot, as illustrated in the following example. As you can see, cases 163 and 237 are outliers.
Next, we check whether the normality assumption has been met. The normality
assumption means that the residual errors are assumed to be normally distributed, roughly in the
shape of the normal curve. We check this assumption by examining histograms of each group. At
the Graphs menu, select Legacy Dialogs. Click Histograms. Highlight BY2XRSTD (Reading
Standardized Score) and move it to the Variable box. Highlight G8REGON (Composite
Geographic Region of School) and move it to the Rows box. Check the Display normal curve.
Click OK.

5
The following shows histograms of the distributions by region. The distribution of the
northeast region is negatively skewed, and the distributions of the other regions (i.e., north
central, south, and west) are positively skewed. However, we should not be too concerned about
this deviation from normality because (a) our sample size is large enough such that, according to
the central limit theorem, the distribution of the sample means should be approximately normal
(b) we found no outliers in any group and (c) the skewness statistic for each group fell within the
-1 to 1 range.

6
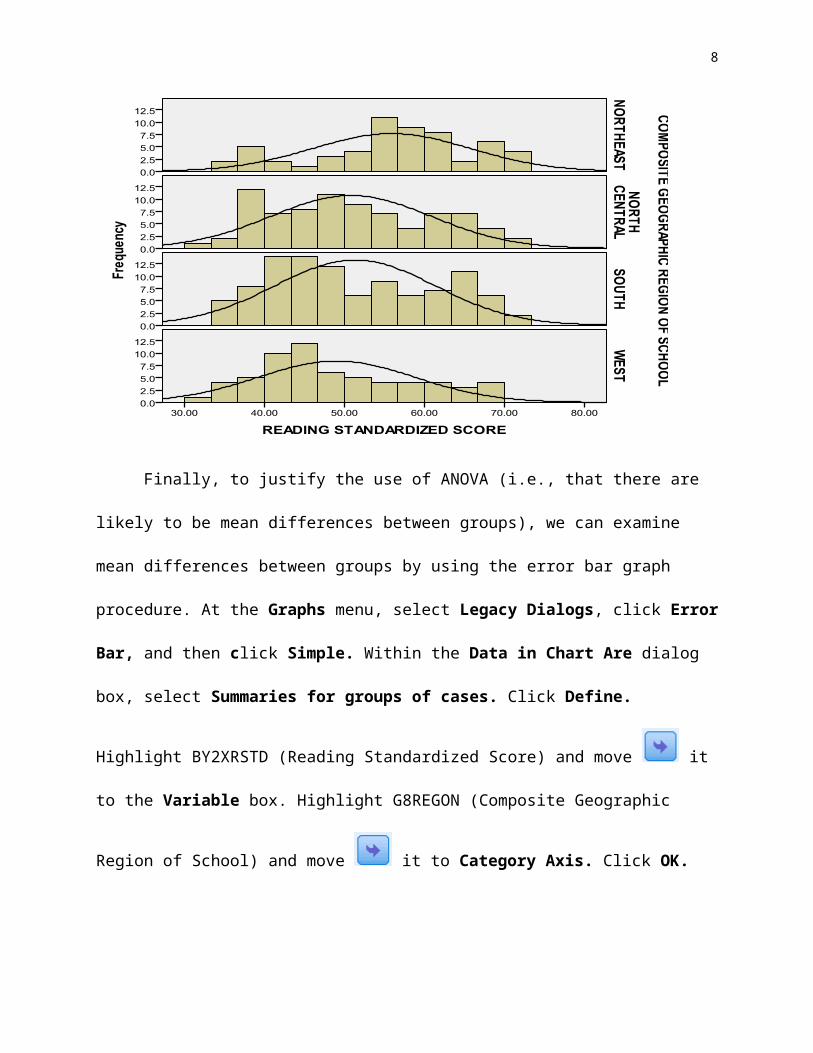
Finally, to justify the use of ANOVA (i.e., that there are likely to be mean differences
between groups), we can examine mean differences between groups by using the error bar graph
procedure. At the Graphs menu, select Legacy Dialogs, click Error Bar, and then click
Simple. Within the Data in Chart Are dialog box, select Summaries for groups of cases. Click
Define. Highlight BY2XRSTD (Reading Standardized Score) and move it to the Variable
box. Highlight G8REGON (Composite Geographic Region of School) and move it to
Category Axis. Click OK.
The output provides an Error Bar graph that displays the 95% confidence interval of the
mean for each group. We can use this graph to examine mean differences between groups (and to
justify the use of ANOVA to analyze these data).
If a horizontal line can be drawn such that it goes through all the bars, this indicates that
the mean differences between groups are likely to be too close to show differences and to justify
ANOVA. Bars that overlap with one another suggest that means for these groups are not
significantly different, and the overall F test for ANOVA will not be significant. If at least one
bar does not overlap with the others, this suggests a significant mean difference, relative to the
other groups, justifying ANOVA.

7
It appears from Figure 2 that the Northeast region bar does not overlap with the other
bars, suggesting a mean difference between this group and the other groups on standardized
reading scores. Thus, ANOVA appears to be warranted. The error bars also provide a
preliminary impression of whether the homogeneity of variance assumption is satisfied. If the
bars appear to be fairly equal in length, it is likely that the equal variance assumption is satisfied.
However, we’ll still need to conduct a statistical test for homogeneity of variance to be sure.
STEP 2: One-Way ANOVA
To run the one-way ANOVA, at the Analyze menu, select Compare Means. Click One-
Way ANOVA. Highlight BY2XRSTD (Reading Standardized Score) and move it to the
Dependent List box. Highlight G8REGON (Composite Geographic Region of School) and move
it to the Factor box. Click Options in the lower right corner to open the One-Way
ANOVA: Options dialogue box. Check Homogeneity of variance test. Click Continue to return
to the One-Way ANOVA dialogue box. Click OK at the bottom of the One-Way ANOVA
dialogue box to run the one way ANOVA.
The results of the overall F test in the ANOVA summary table can be examined to
determine whether group means are different. As indicated, the overall F test is significant (i.e., p
value < 0.05), indicating that means between groups are not equal. However, in order to
determine which of the group means are different, it is necessary to conduct planned or post hoc
comparison tests.
8
The Test of Homogeneity of Variances table in the output can be examined to check
whether the homogeneity of variance assumption has been met.
Results show that the test for homogeneity of variances is not significant (i.e., p =.733,
which is greater than 0.05). This indicates that the homogeneity of variances assumption is met.
STEP 3: Planned or Post Hoc Comparison Tests (if warranted)
First we describe how to conduct planned comparison tests. This test requires equal
sample sizes between groups. The sample sizes of the groups in this data set are unequal. The
smallest group, with 57 cases, is from the northeast region. In order to conduct a planned
comparison (simply for illustration purposes), we randomly selected 57 students from each of the
other regions to obtain equal sample sizes. In this example, we compare mean reading scores of
students in the northeast region to mean reading scores in the other regions, based on what we
learned from earlier preliminary findings about mean differences between groups. The null
hypothesis is:

9
Planned comparisons require that that coefficients (i.e., weights) must sum to 0 (i.e., balance).
Because there are three groups on the left side of the equation, we put a ‘3’ besides the northeast
for the equation to sum to 0. We can rewrite the equation as:
To conduct the planned comparison test, at the Analyze menu, select Compare Means.
Click One-Way ANOVA. Highlight BY2XRSTD (Reading Standardized Score) and move
it to the Dependent List box. Highlight G8REGON (Composite Geographic Region of
School) and move it to the Factor box. Click Contrasts in the upper right corner to open
the One-Way ANOVA: Contrasts dialogue box. Move your cursor to the Coefficients box. Type
“-3” in the box; click Add; type “1” in the box; click Add; type “1” in the box again and click
Add. Type “1” in the box one more time and click Add. Click Continue to return to the One-
Way ANOVA dialogue box. Click OK at the bottom of the One-Way ANOVA dialogue box to
run the planned comparison tests.

10
As the following table shows, the results of the planned comparison test are not significant. Non-
significance indicates that the means of the standardized reading scores across groups are equal.
The following describes how to conduct a post hoc comparison using the Tukey HSD
test. Click on Analyze in the menu bar. Select Compare Means. Click on One-Way ANOVA to
open the One-way ANOVA dialogue box. Highlight BY2XRSTD (Reading Standardized Score)
and move it to the Dependent List box. Highlight G8REGON (Composite Geographic
Region of School) and move it to the Factor box. Click Post Hoc in the upper right corner
to open the One-Way ANOVA: Post Hoc Multiple Comparisons box. Check Tukey. Click
Continue to return to the One-Way ANOVA dialogue box. Click OK at the bottom of the One-
Way ANOVA dialogue box to run the post hoc comparison test.
As the following table indicates, the mean of the northeast is significantly (p <.05) different from
the means of the other regions, confirming what was observed in the error bar plots.
The default significance level in SPSS is 0.05. If you are using a different significance level then you need to specify it here.

11
The results also indicate that groups can be put into two subsets, based on mean differences. As
the following table indicates, the west, south, and north central regions are grouped together
because their means are similar. The northeast region represents the other group.
Related Documents











