ISSN 0032-9460, Problems of Information Transmission, 2008, Vol. 44, No. 3, pp. 214–225. c Pleiades Publishing, Inc., 2008. Original Russian Text c K.Sh. Zigangirov, A.E. Pusane, D.K. Zigangirov, D.J. Costello, Jr., 2008, published in Problemy Peredachi Informatsii, 2008, Vol. 44, No. 3, pp. 50–62. CODING THEORY On the Error-Correcting Capability of LDPC Codes 1 K. Sh. Zigangirov a , A. E. Pusane b , D. K. Zigangirov a 2 , and D. J. Costello, Jr. b a Institute for Information Transmission Problems, Moscow [email protected] [email protected] b University of Notre Dame, Indiana, USA [email protected] [email protected] Received November 22, 2007; in final form, April 30, 2008 Abstract—We consider the ensemble of low-density parity-check (LDPC) codes introduced by Gallager [1]. The Zyablov–Pinsker majority-logic iterative algorithm [2] for decoding LDPC codes is analyzed on the binary symmetric channel. An analytical lower bound on the error- correcting capability τ max that grows linearly in the code block length is obtained. DOI: 10.1134/S0032946008030046 1. INTRODUCTION Low-density parity-check (LDPC) codes were invented by Gallager [1]. The advantage of these codes is their ability to use relatively low-complexity iterative decoding algorithms. An algorithm proposed by Gallager [1] for symbolwise decoding of LDPC codes, called the sum-product algorithm, has been extensively studied in the literature. Its bit error probability has been analyzed, resulting in a relatively weak upper bound on its performance. As the block length N grows, the bound decreases as exp[−O(N γ )], where γ< 1 (see, for example, [3]). The same bound is also valid for the block error probability. A different approach was taken in the paper by Zyablov and Pinsker [2]. In that paper, a binary symmetric channel (BSC) is considered and a majority-logic iterative decoding algorithm for LDPC codes, different from Gallager’s algorithm [1], is analyzed. (This algorithm is described in Section 3.) Zyablov and Pinsker proved that this algorithm, having complexity O(N log N ), corrects O(N ) channel errors. It immediately follows that, for small enough channel error rates, the block error probability goes to zero exponentially in N , i.e., as exp[−O(N )]. In this paper, we study the same algorithm presented in [2]. For this decoding algorithm, we prove a new analytical bound on the number of correctable errors as a function of the parameters of an LDPC code. To derive the bound, we use a combinatorial approach similar to that used in [4–6] to obtain a lower bound on the minimum distance of LDPC block codes with parity-check matrices constructed from permutation matrices, to obtain a lower bound on the free distance of LDPC convolutional codes, and to analyze the iterative decoding performance of LDPC codes on the binary erasure channel, respectively. 2. BASIC DEFINITIONS AND PROBLEM FORMULATION By definition, a {coder/decoder} pair has an error-correcting capability τ max if the decoder can correct all combinations of τ errors in the received sequence, where τ ≤ τ max . Throughout this 1 This work was partially supported by NSF Grants CCR02-05310 and CCF05-15012, NASA Grants NNG05GH73G and NNX07AK53G, and a Graduate Fellowship from the Center for Applied Mathematics, University of Notre Dame. 2 Supported in part by the State Contract of the Russian Federation 02.514.11.4025 from 1.05.2007. 214

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

ISSN 0032-9460, Problems of Information Transmission, 2008, Vol. 44, No. 3, pp. 214–225. c© Pleiades Publishing, Inc., 2008.Original Russian Text c© K.Sh. Zigangirov, A.E. Pusane, D.K. Zigangirov, D.J. Costello, Jr., 2008, published in Problemy Peredachi Informatsii, 2008,Vol. 44, No. 3, pp. 50–62.
CODING THEORY
On the Error-Correcting Capability of LDPC Codes1
K. Sh. Zigangirova, A. E. Pusaneb, D. K. Zigangirova2, and D. J. Costello, Jr.b
aInstitute for Information Transmission Problems, [email protected] [email protected]
bUniversity of Notre Dame, Indiana, [email protected] [email protected]
Received November 22, 2007; in final form, April 30, 2008
Abstract—We consider the ensemble of low-density parity-check (LDPC) codes introducedby Gallager [1]. The Zyablov–Pinsker majority-logic iterative algorithm [2] for decoding LDPCcodes is analyzed on the binary symmetric channel. An analytical lower bound on the error-correcting capability τmax that grows linearly in the code block length is obtained.
DOI: 10.1134/S0032946008030046
1. INTRODUCTION
Low-density parity-check (LDPC) codes were invented by Gallager [1]. The advantage of thesecodes is their ability to use relatively low-complexity iterative decoding algorithms. An algorithmproposed by Gallager [1] for symbolwise decoding of LDPC codes, called the sum-product algorithm,has been extensively studied in the literature. Its bit error probability has been analyzed, resultingin a relatively weak upper bound on its performance. As the block length N grows, the bounddecreases as exp[−O(Nγ)], where γ < 1 (see, for example, [3]). The same bound is also valid forthe block error probability.
A different approach was taken in the paper by Zyablov and Pinsker [2]. In that paper, abinary symmetric channel (BSC) is considered and a majority-logic iterative decoding algorithmfor LDPC codes, different from Gallager’s algorithm [1], is analyzed. (This algorithm is describedin Section 3.) Zyablov and Pinsker proved that this algorithm, having complexity O(N log N),corrects O(N) channel errors. It immediately follows that, for small enough channel error rates,the block error probability goes to zero exponentially in N , i.e., as exp[−O(N)].
In this paper, we study the same algorithm presented in [2]. For this decoding algorithm, weprove a new analytical bound on the number of correctable errors as a function of the parametersof an LDPC code. To derive the bound, we use a combinatorial approach similar to that usedin [4–6] to obtain a lower bound on the minimum distance of LDPC block codes with parity-checkmatrices constructed from permutation matrices, to obtain a lower bound on the free distance ofLDPC convolutional codes, and to analyze the iterative decoding performance of LDPC codes onthe binary erasure channel, respectively.
2. BASIC DEFINITIONS AND PROBLEM FORMULATION
By definition, a {coder/decoder} pair has an error-correcting capability τmax if the decoder cancorrect all combinations of τ errors in the received sequence, where τ ≤ τmax. Throughout this1 This work was partially supported by NSF Grants CCR02-05310 and CCF05-15012, NASA Grants
NNG05GH73G and NNX07AK53G, and a Graduate Fellowship from the Center for Applied Mathematics,University of Notre Dame.
2 Supported in part by the State Contract of the Russian Federation 02.514.11.4025 from 1.05.2007.
214

ON THE ERROR-CORRECTING CAPABILITY OF LDPC CODES 215
paper, we consider the Gallager ensemble [1] of binary LDPC (J,K)-regular codes with parity-check matrices H of size L × N that have J ones in each column and K ones in each row. Thedimensions L and N are chosen so that N = KM and L = JM , where M > 0 is an integer. Thenthe parity-check matrix H can be expressed as a composition of J submatrices H(j), j = 1, 2, . . . , J :
H =
⎛⎜⎜⎜⎜⎝
H(1)
H(2)
...H(J)
⎞⎟⎟⎟⎟⎠
. (1)
The M × N submatrices H(j), j = 1, 2, . . . , J , have a single one in each column and K ones ineach row. The design rate3 of such a code is R = 1 − J/K. We consider the ensemble C(N,J,K)of codes with parity-check matrices given by (1), where the submatrices H(j), j = 1, 2, . . . , J , arechosen randomly, independently of each other, and so that all values of the submatrix H(j) areequiprobable. We start with a brief analysis of the ensemble.
Lemma 1. Each matrix H(j), j = 1, 2, . . . , J , can take one of(KM)!(K!)M
values.
Proof. There are(
KM
K
)ways to form the first row of H(j). Then the second row can be
chosen in(
K(M − 1)K
)different ways, and so on. We conclude that H(j) can be chosen in
(KM
K
)(K(M − 1)
K
)(K(M − 2)
K
). . .
(K
K
)=
(KM)!(K!)M
(2)
different ways. �By definition, a binary sequence v = (v1, v2, . . . , vN ) is a codeword of a code with parity-check
matrix H if and only if it satisfiesvHT = 0. (3)
If a binary codeword v is transmitted over a BSC, at the output of the channel the receivedsequence r = (r1, r2, . . . , rN ) can be decomposed into a (modulo-2) sum of the transmitted code-word v and an error sequence e; i.e.,
r = v + e, (4)
where e = (e1, e2, . . . , eN ). From (3) and (4), the syndrome can be computed as
s = rHT = eHT, (5)
where s = (s(1), s(2), . . . , s(J)). The M -dimensional vector s(j), j = 1, 2, . . . , J , is a partial syndromecorresponding to the submatrix H(j), and it satisfies the equation
e(H(j)
)T= s(j), j = 1, 2, . . . , J. (6)
We denote the set of check equations in (6) by S(j), j = 1, 2, . . . , J . Let τ be the Hammingweight of the error vector e; w(j), j = 1, 2, . . . , J , be the Hamming weight of the partial syndromevector s(j); and w = w(1)+w(2)+. . .+w(J) (real addition) be the Hamming weight of the syndrome s.Clearly, w(j) equals the number of unsatisfied check equations in S(j), and each of the M equationsin S(j), j = 1, 2, . . . , J , includes K symbols.3 The actual code rate may be slightly greater than the design rate due to the existence of linearly dependent
rows in H .
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

216 ZIGANGIROV et al.
In parallel to each partial syndrome vector s(j), we consider a partial pseudo-syndrome vectors̃(j) = (i(j)1 , i
(j)2 , . . . , i
(j)M ), where i
(j)m ∈ {0, 1, . . . ,K} equals the number of nonzero symbols in e
included in the mth equation of S(j), m = 1, 2, . . . ,M . The vector s̃ = (s̃(1), s̃(2), . . . , s̃(J)) is calleda pseudo-syndrome.
Now let ν(j)i denote the number of parity-check equations in S(j) that include i nonzero (error)
symbols of e. Consider the vector ν(j) = (ν(j)0 , ν
(j)1 , . . . , ν
(j)K ), called the constraint composition
of S(j) (or of the partial pseudo-syndrome s̃(j)). In other words, ν(j)i equals the number of com-
ponents of the partial pseudo-syndrome s̃(j) that have the value i. Below (see (18b)), it is provedthat
τ =K∑
i=0
iν(j)i . (7)
The Hamming weight of the partial syndrome s(j) can be written as
w(j) =∑i odd
ν(j)i , (8)
where the summation is over odd i. The weight of the j-th partial pseudo-syndrome, defined as thenumber of nonzero symbols in e included in unsatisfied parity-check equations of S(j), is given by
w̃(j) =∑i odd
iν(j)i . (9)
Finally, we define the weight of the pseudo-syndrome as
w̃ = w̃(1) + w̃(2) + . . . + w̃(J). (10)
3. ANALYSIS OF THE DECODING ALGORITHM
It follows from the code description in the previous section that each symbol of the receivedsequence r is included in one parity-check equation in each set S(j), j = 1, 2, . . . , J . Thus, in total,each received symbol is included in J check equations. The Zyablov–Pinsker algorithm works asfollows. In the first step of decoding, the decoder observes all symbols of the received sequence and
marks the symbols for which the number of unsatisfied parity-check equations is greater than⌊J
2
⌋.
Then it flips these symbols. In the second step, the decoder operates with this updated sequenceas with a received sequence; it again marks all symbols for which the number of unsatisfied parity-
check equations is greater than⌊J
2
⌋and flips them. The decoding stops if there are no symbols
for which the number of unsatisfied parity-check equations is greater than⌊J
2
⌋. In this case, the
syndrome weight is either zero (complete decoding) or nonzero (failed decoding).We call the sequence that the decoder currently operates with the current received sequence,
and the current error sequence is the modulo-2 sum of a transmitted codeword and the currentreceived sequence.
Note that the decoder can observe the received sequence r, the syndrome s, and its weight w.At the same time, the error sequence e, its weight τ , the pseudo-syndrome s̃ = (s̃(1), s̃(2), . . . , s̃(J)),and the weight of the pseudo-syndrome w̃ are “unobservable” by the decoder. Although we canobserve how the syndrome weight w changes in the decoding, we cannot estimate the behavior of τ
and w̃. Received symbols that are included in⌊J
2
⌋or less unsatisfied check equations are called
unflipable; otherwise, they are called flipable. Received sequences for which all erroneously receivedsymbols are unflipable are called trapping sets.
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

ON THE ERROR-CORRECTING CAPABILITY OF LDPC CODES 217
The parameter τtrap is called the trapping weight of an LDPC code if there are no trapping setsof weight τ < τtrap and there is at least one trapping set of weight τ = τtrap. As a generalization ofthe definition of the trapping weight, we introduce the trapping weight of order γ. By definition,τtrap(γ) is called the trapping weight of order γ of an LDPC code if, for any τ < τtrap(γ), thenumber of unflipable erroneous symbols in all error sequences is strictly less than (1− γ)τ , and, forτ = τtrap(γ), there exists at least one error sequence with (1 − γ)τ unflipable erroneous symbols.Obviously, τtrap = τtrap(0).
Our analysis of the Zyablov–Pinsker decoding algorithm is based on lower bounding τtrap(γ).We will prove the existence of a code for which the lower bound on τtrap(γ), the trapping weightof order γ, grows linearly with block length N if γ is sufficiently small. Using this bound, we canobtain a lower bound on the error-correcting capability τmax.
It is convenient to consider the normalized error-correcting capability ρmax = τmax/N and thenormalized trapping weight of order γ, ρtrap(γ) = τtrap(γ)/N . Below we formulate two theoremswhich establish lower bounds ρ̂trap(γ) and ρ̂max on ρtrap(γ) and ρmax, respectively.
First, for a given value of γ, we introduce the following function of the variables λ, μ, and ρ:
Gγ(λ, μ, ρ) = g(λ, μ) − μ
(j0
J+
(J − j0)γJ
)ρ − λ
(1 − j0
J− (J − j0)γ
J
)ρ − J − 1
JH(ρ), (11)
where j0 =⌊J
2
⌋, ρ = τ/N , and
g(λ, μ) =1K
ln
[(1 + eμ)K − (1 − eμ)K
2+
(1 + eλ)K + (1 − eλ)K
2
], λ < 0, μ < 0. (12)
Then we defineFγ(ρ) = min
μ<λ<0Gγ(λ, μ, ρ). (13)
Theorem 1. Assume that there exists ρ = ρ̂trap(γ) such that Fγ(ρ̂trap(γ)) < 0. Then, for Nsufficiently large, we have ρtrap(γ) > ρ̂trap(γ) for almost all codes in the ensemble C(N,J,K).
It follows from Theorem 1 that if in a particular decoding step the current error sequence hasweight τ < ρ̂trap(γ)N , then for almost all codes the Zyablov–Pinsker algorithm flips more than afraction γ of erroneous symbols. At the same time, it may also flip some correctly received symbols;i.e., it may introduce errors. If for each decoding step the number of flipable correctly receivedsymbols is strictly less than the number of flipable erroneously received symbols, then the weight ofthe error sequence decreases at each decoding step and the decoder corrects all errors in O(log N)iterations. We will establish the conditions under which, for each decoding step, the number offlipable correct symbols is strictly less than the number of flipable erroneous symbols and therebyobtain a lower bound ρ̂max on ρmax. First, we introduce the following function:
Qγ(ρ) =1 − ρ
JH
( γρ
1 − ρ
)+
γρ
Jln α(ρ), (14)
where
α(ρ) =
(J
j0 + 1
)[(K − 1)ρ/(1 − ρ)]j0+1. (15)
Then we introduceU(ρ) = max
0<γ<1(Fγ(ρ) + Qγ(ρ)), (16)
where Fγ(ρ) is defined in (13).The following theorem establishes a lower bound ρ̂max on the normalized error-correcting capa-
bility ρmax.
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

218 ZIGANGIROV et al.
Theorem 2. Assume that there exists ρ = ρ̂max such that U(ρ̂max) < 0. Then, for N suffi-ciently large, we have ρmax > ρ̂max for almost all codes in the ensemble C(N,J,K).
The following two sections contain lemmas which imply Theorems 1 and 2.
4. PROOF OF THEOREM 1
Lemma 2. If the weight w̃ of a pseudo-syndrome is greater than (j0 + (J − j0)γ)τ , where
j0 =⌊J
2
⌋, then the Zyablov–Pinsker algorithm flips more than a fraction γ of erroneous symbols in
the current error sequence of weight τ .
Proof. The Zyablov–Pinsker algorithm flips γτ symbols of the error sequence if the number ofunsatisfied parity-check equations in these symbols exceeds j0 (but, of course, does not exceed J)and at most j0 parity-check equations are unsatisfied in the remaining (1− γ)τ erroneous symbols.In this case, the weight of the pseudo-syndrome is not greater than
(1 − γ)j0τ + γJτ = j0τ + (J − j0)γτ, (17)
so if w̃ exceeds this value, the Zyablov–Pinsker algorithm must flip more than γτ erroneous sym-bols. �
Lemma 3. Components of a constraint composition vector ν(j) = (ν(j)0 , ν
(j)1 , . . . , ν
(j)K ) satisfy
the equalitiesK∑
i=0
ν(j)i = M, (18a)
K∑i=0
iν(j)i = τ. (18b)
Proof. The set of M parity-check equations S(j) consists of K + 1 subsets such that the ithsubset, i = 0, 1, . . . ,K, consists of ν
(j)i equations and each equation includes i erroneous symbols.
This proves (18a). The sum in (18b) counts the number of erroneous symbols in all check equationsof S(j). Since each symbol enters only one equation in S(j), the sum equals the total number oferroneous symbols in the received sequence. �
Lemma 4. Given a constraint composition ν(j) = (ν(j)0 , ν
(j)1 , . . . , ν
(j)K ), there are
M !
ν(j)0 ! ν(j)
1 ! . . . ν(j)K !
(19)
ways to choose a partial pseudo-syndrome s̃(j).
Proof. The lemma immediately follows from the definitions of the constraint compositionν(j) = (ν(j)
0 , ν(j)1 , . . . , ν
(j)K ) and the partial pseudo-syndrome s̃(j) = (i(j)1 , i
(j)2 , . . . , i
(j)M ), where i
(j)m ∈
{0, 1, . . . ,K}. �Lemma 5. For a given error sequence e of weight τ and a given partial pseudo-syndrome s̃(j)
with constraint composition ν(j) = (ν(j)0 , ν
(j)1 , . . . , ν
(j)K ), the number of ways to choose the parity-
check submatrix H(j) is given byτ ! (N − τ)!
K∏i=0
[i! (K − i)! ]ν(j)i
. (20)
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

ON THE ERROR-CORRECTING CAPABILITY OF LDPC CODES 219
Proof. The proof is similar to that of Lemma 1.
Consider a partial pseudo-syndrome s̃(j) = (i(j)1 , i(j)2 , . . . , i
(j)M ) with constraint composition ν(j).
There are(
τ
i(j)1
)(N − τ
K − i(j)1
)ways to form the first row of H(j). Then the second row can be chosen
in(
τ − i(j)1
i(j)2
)(N − τ − K + i
(j)1
K − i(j)2
)different ways, and so on. We conclude that H(j) can be chosen in
(τ
i(j)1
)(N − τ
K − i(j)1
)(τ − i
(j)1
i(j)2
)(N − τ − K + i
(j)1
K − i(j)2
). . .
(i(j)M
i(j)M
)(K − i
(j)M
K − i(j)M
)
=τ ! (N − τ)!
K∏i=0
[i! (K − i)! ]ν(j)i
(21)
different ways. �Let fτ (ν
(j)0 , ν
(j)1 , . . . , ν
(j)K ) be the probability of choosing the matrix H(j) for a given error vector e
of weight τ and constraint composition ν(j) = (ν(j)0 , ν
(j)1 , . . . , ν
(j)K ). Using Lemmas 1, 4, and 5, we
obtain
fτ (ν(j)0 , ν
(j)1 , . . . , ν
(j)K )
=
M !
ν(j)0 ! ν(j)
1 ! . . . ν(j)K !
τ ! (N − τ)!K∏
i=0
[i! (K − i)! ]ν(j)i
N !(K!)M
=
M !
ν(j)0 , ν
(j)1 . . . ν
(j)K
K∏i=0
(K!
i! (K − i)!
)ν(j)i
N !τ ! (N − τ)!
. (22)
The denominator of the first fraction on the right-hand side of (22) is the number of ways tochoose the matrix H(j) (see Lemma 1). The first term in the numerator is the number of waysto choose the partial pseudo-syndrome s̃(j) with constraint composition ν(j) (see Lemma 4). Thesecond term in the numerator is the number of ways to choose the submatrix H(j) if the errorsequence e of weight τ and the pseudo-syndrome s̃(j) are given (see Lemma 5).
Now consider the code ensemble C(N,J,K) and let Pτ (w̃) be the probability that an errorsequence e of weight τ has pseudo-syndrome weight w̃. Correspondingly, let Pτ (w̃(j)) be theprobability that this error sequence e has the jth partial pseudo-syndrome weight w̃(j). From (10),it follows that
Pτ (w̃) =∑
w̃(1)+w̃(2)+...+w̃(J)
Pτ (w̃(1))Pτ (w̃(2)) . . . Pτ (w̃(J)). (23)
The mathematical expectation Mτ (w̃) of the number of weight-τ error sequences e with pseudo-syndrome weight w̃ is
Mτ (w̃) =
(N
τ
)Pτ (w̃). (24)
The generating function of the mathematical expectation Mτ (w̃) is defined as
Φτ (s) =Jτ∑
w̃=0
estMτ (w̃) =
(N
τ
)Jτ∑
w̃=0
estPτ (w̃) =
(N
τ
)[ϕτ (s)]J ,
where ϕτ (s), the generating function of the probability Pτ (w̃(j)), is given by
ϕτ (s) =τ∑
w̃(j)=0
esw̃(j)Pτ (w̃(j)) (25)
and does not depend on j.
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

220 ZIGANGIROV et al.
Lemma 6. For the ensemble C(N,J,K), the mathematical expectation of the number of errorsequences of weight τ having pseudo-syndrome weight w̃ ≤ w̃0 is upper bounded by the followinginequality :
∑
w̃≤w̃0
Mτ (w̃) ≤ e−λJτ−(μ−λ)w̃0+g(λ,μ)JN
(N
τ
)1−J
, (26)
where g(λ, μ) is defined in (12), μ < λ < 0.
Proof. From the definition of the generating function Φτ (s), it follows that
∑
w̃≤w̃0
Mτ (w̃) ≤∑
∀w̃
es(w̃−w̃0)Mτ (w̃) = Φτ (s)e−sw̃0 =
(N
τ
)[ϕτ (s)]
J e−sw̃0, (27)
where s < 0. Then from (22) and (25) we obtain an upper bound on the generating function ϕτ (s):
ϕτ (s) =τ∑
w̃(j)=0
esw̃(j)Pτ (w̃(j)) =
∑K∑
i=0
iν(j)i =τ
es
∑i odd
iν(j)i
fτ (ν(j)0 , ν
(j)1 , . . . , ν
(j)K ) (28)
≤∑
∀ν(j)
es
∑i odd
iν(j)i
eλ
( K∑i=0
iν(j)i −τ
)fτ (ν
(j)0 , ν
(j)1 , . . . , ν
(j)K ) (29)
= e−λτ∑
∀ν(j)
M !
ν(j)0 ! ν(j)
1 ! . . . ν(j)K !
∏i odd
(K! e(s+λ)i
i! (K − i)!
)ν(j)i ∏
i even
(K! eλi
i! (K − i)!
)ν(j)i
N !τ ! (N − τ)!
= e−λτ
(N
τ
)−1 [(1 + es+λ)K − (1 − es+λ)K
2+
(1 + eλ)K + (1 − eλ)K
2
]M
= e−λτ
(N
τ
)−1
eg(λ,μ)N , (30)
where g(λ, μ) is defined in (12), μ = λ + s, and μ < λ < 0. To pass from (28) to (29), we first
multiply the summands by eλ
( K∑i=0
iν(j)i −τ
), which does not change the sum since the summation
is over constraint compositions ν(j) satisfying the conditionK∑
i=0iν
(j)i = τ . Then we replace the
summation over ν(j) satisfying the conditionK∑
i=0iν
(j)i = τ by summation over all ν(j), which can
only increase the sum. Finally, (26) follows from (27)–(30). �The next lemma directly follows from Lemma 6.
Lemma 7. We have the inequality∑
w̃≤w̃0
Mτ (w̃) ≤ exp [MJKGγ(λ, μ, ρ) + o(M)] , (31)
where Gγ(λ, μ, ρ) is defined in (11), μ < λ < 0, ρ = τ/N , w̃0 = (j0 + (J − j0)γ)τ , and j0 =⌊J
2
⌋.
Finally, if we choose λ and μ that minimize Gγ(λ, μ, ρ) and replace Gγ(λ, μ, ρ) by Fγ(ρ) in theexponent on the right-hand side of (31), we obtain the following lemma.
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

ON THE ERROR-CORRECTING CAPABILITY OF LDPC CODES 221
Lemma 8. We have the inequality∑
w̃≤w̃0
Mτ (w̃) ≤ exp [MJKFγ(ρ) + o(M)] , (32)
where Fγ(ρ) is defined in (13), ρ = τ/N , w̃0 = (j0 + (J − j0)γ)τ , and j0 =⌊J
2
⌋.
If Fγ(ρ) < 0, then by choosing N sufficiently large we can make the right-hand side of (32)arbitrarily small; i.e., in the ensemble C(N,J,K), the mathematical expectation of the number oferror sequences of weight τ having pseudo-syndrome weight w̃ ≤ w̃0 goes to zero as N goes toinfinity. This proves Theorem 1.
5. PROOF OF THEOREM 2
Lemma 9. Consider an arbitrary received sequence r and the corresponding error sequence eof weight τ = ρN . Let pτ (k) denote the probability that the number of flipable erroneous symbolsequals k, so that
∑k≤�=γτ
pτ (k) denotes the probability that the number of flipable erroneous symbols
does not exceed = γτ . Then∑
k≤�=γτ
pτ (k) ≤ exp [MJK(Fγ(ρ) − H(ρ)/J) + o(M)] , (33)
where Fγ(ρ) is defined in (13), μ < λ < 0, and ρ = τ/N .
Proof. The proof is analogous to the proof of Lemma 7 and is based on Lemmas 2–5. FromLemma 2 it follows that
∑k≤�=γτ
pτ (k) is upper bounded by the probability that the pseudo-syndrome
weight does not exceed w̃0 = (j0 +(J−j0)γ)τ . In turn, the probability∑
w̃≤w̃0
Pτ (w̃) that the pseudo-
syndrome weight w̃ does not exceed w̃0 is upper bounded by (cf. (26))
∑
w̃≤w̃0
Pτ (w̃) ≤ [ϕτ (s)]J e−sw̃0 ≤ e−Jλτ
(N
τ
)−J
eg(λ,μ)JNe−sw̃0 (34)
= exp [MJK(Gγ(λ, μ, ρ) − H(ρ)/J) + o(M)] . (35)
Choosing λ and μ to minimize Gγ(λ, μ, ρ) and replacing Gγ(λ, μ, ρ) by Fγ(ρ), we obtain (3). �Now fix the received sequence r and consider the corresponding sequence of correctly received
symbols c of length N ′ = N − τ = (1 − ρ)N . The number of flipable symbols in c is denoted
by ; we enumerate this symbols by indices i, i = 1, 2, . . . , . There are(
N ′
)possible sequences
of correctly received symbols with flipable symbols. For the ith flipable symbol in c, there are(J
j0 + 1
)possible collections of j0 + 1 sets of parity-check equations Si = (Si,1,Si,2, . . . ,Si,j0+1),
Si,j ∈ {S(1),S(2), . . . ,S(J)}, j = 1, 2, . . . , j0 + 1, Si,j �= Si,j′ , j �= j′, such that the equationscontained in the sets Si,1,Si,2, . . . ,Si,j0+1 are not all satisfied. Also, for each possible sequence of
correctly received symbols with flipable symbols, there are[(
J
j0 + 1
)]�
such collections of sets S.
Now we denote by qτ ( |k) the conditional probability that the number of flipable correct symbolsin the sequence c equals given that the number of flipable erroneous symbols in the sequence eis k. This conditional probability depends only on the weight of a sequence e and does not dependon the configuration of e and c.
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

222 ZIGANGIROV et al.
Lemma 10. The conditional probability qτ ( |k) is upper bounded by
qτ ( |k) ≤(
N ′
)[α(ρ)]�, (36)
where the right-hand side does not depend on k, and α(ρ) is defined in (15).
Proof. First, we choose a set of positions corresponding to flipable correctly received symbols.
This can be done in(
N ′
)ways. For each flipable correctly received symbol, say the ith, we then
choose one of the(
J
j0 + 1
)collections of j0 + 1 sets of parity-check equations Si. For the ensemble
C(N,J,K), we then bound the fraction of codes for which the flipable correctly received symbolsin the chosen positions are included in unsatisfied parity-check equations corresponding to thechosen collections of sets {Si, i = 1, 2, . . . , }. By (j), j = 1, 2, . . . , J , we denote the number offlipable correctly received symbols included in unsatisfied parity-check equations of the sets S(j),j = 1, 2, . . . , J . Clearly, we have
(1) + (2) + . . . + (J) = (j0 + 1). (37)
Next, consider an arbitrary set of parity-check equations S(j), j = 1, 2, . . . , J . The number ofunsatisfied parity-check equations in this set does not exceed τ , the number of correctly receivedsymbols that are included in unsatisfied parity-check equations does not exceed L = (K − 1)τ , andthe total number of positions occupied by correctly received symbols equals N ′. Then, indepen-dently of the number of flipable erroneously received symbols k, the probability that (j) flipablecorrectly received symbols is included in unsatisfied parity-check equations of the set S(j) is upperbounded by
L(L − 1) . . . (L − (j) + 1)N ′(N ′ − 1) . . . (N ′ − (j) + 1)
< [(K − 1)ρ/(1 − ρ)]�(j)
. (38)
Now it follows from (37) and (38) that the probability that all flipable correctly received symbolsare included in unsatisfied parity-check equations of the corresponding sets S(j), j = 1, 2, . . . , J , isupper bounded by
[(K − 1)ρ/(1 − ρ)]�(j0+1). (39)
Since a set of flipable correctly received symbols can be chosen among the N ′ correctly received
symbols in(
N ′
)ways and a collection of j0 + 1 sets of unsatisfied parity-check equations can be
chosen among the J sets of parity-check equations in(
J
j0 + 1
)ways, we can upper bound the
probability qτ ( |k) by (N ′
)(J
j0 + 1
)�
[(K − 1)ρ/(1 − ρ)]�(j0+1). (40)
Finally, (36) follows from (40). �Inequality (36) implies
qτ ( |k) ≤ exp [MJKQγ(ρ) + o(M)], (41)
where γ = /τ .
Lemma 11. For an arbitrary received sequence r of length N with τ = ρN erroneous symbols,the probability
∑0<�≤N ′
∑k≤�
qτ ( |k)pτ (k) that the number of flipable erroneously received symbols does
not exceed the number of flipable correctly received symbols is upper bounded by∑0<�≤N ′
∑k≤�
qτ ( |k)pτ (k) ≤ exp [MJK(U(ρ) − H(ρ)/J) + o(M)] , (42)
where U(ρ) is defined in (16).
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

ON THE ERROR-CORRECTING CAPABILITY OF LDPC CODES 223
Proof. From (33), (41), and (42), it follows that∑
0<�≤N ′
∑k≤�
qτ ( |k)pτ (k) ≤∑
0<�≤N ′
[max
kqτ ( |k)
] ∑k≤�
pτ (k)
≤ exp[MJK
(max
γ(Fγ(ρ) + Qγ(ρ)) − H(ρ)/J
)+ o(M)
]. (43)
Then we obtain (42) by using (16) and (43). �Lemma 12. In the ensemble C(N,J,K), the mathematical expectation of the number of received
sequences with τ erroneous symbols for which the number of flipable erroneously received symbolsdoes not exceed the number of flipable correctly received symbols is upper bounded by
exp [MJKU(ρ) + o(M)] , (44)
where U(ρ) is defined in (16).
Proof. The total number of error sequences of weight τ is(
N
τ
). For each of these error
sequences, the probability that the number of flipable erroneously received symbols does not ex-ceed the number of flipable correctly received symbols is upper bounded by (42). This provesLemma 12. �
Finally, Theorem 2 follows from Lemma 12.We have proved that under the conditions of Theorem 2, the Zyablov–Pinsker decoder corrects
at least one error. Hence, the total number of decoding steps does not exceed τ , i.e., growsno faster than linearly with N . In fact, and this is proved in [2], in each decoding step thealgorithm corrects a number of errors that grows linearly with N . Thus, the number of decodingsteps grows no faster than O(log N), and the total complexity of the algorithm does not exceedO(N log N). To prove a similar result, we have to modify Lemmas 11 and 12 and upper bound themathematical expectation of the number of received sequences having at most ′ flipable erroneouslyreceived symbols and exactly flipable correctly received symbols, where ′ − = εN . Here ε isan arbitrarily small positive number. Then the formulation of Theorem 2 does not change sincethe condition U(ρ̂max) < 0 assumes the existence of a positive number ε such that U(ρ̂max) < −ε,and therefore we can choose the parameters γ for the functions Fγ(ρ) and Qγ(ρ) in equation (16),which defines U(ρ), so that they differ by a small quantity ε.
The table gives values for ρ̂trap and ρ̂max as functions of J and K for 6 ≤ J ≤ 11 and 7 ≤ K ≤ 20.For J < 6, both bounds are zero. It is interesting to the compare the values of ρmax given in thetable with those computed by Zyablov–Pinsker formulas [2]. The values of ρ̂max given in the tableare sometimes greater than those obtained using the more complicated Zyablov–Pinsker formula,and sometimes smaller. In particular, for J = 9 and K = 10, the table value is ρ̂max = 1.29× 10−3,whereas the Zyablov–Pinsker formula gives ρ̂max = 8.5 × 10−3. On the other hand, for J = 10 andK = 20, the value of ρ̂max in the table (5.7 × 10−4) is greater than the value (2 × 10−4) computedby the Zyablov–Pinsker formula.
Note that, from Theorem 2, it follows that, if J ≥ 6 and the number of error symbols in thereceived sequence is not large, then there exists an LDPC code such that the Zyablov–Pinskeralgorithm corrects a number of channel errors that grows linearly with N .
6. DISCUSSION AND CONCLUSIONS
In this paper, we derived a lower bound on the error-correcting capability of Gallager’s regularLDPC codes used with majority-logic iterative decoding on a BSC. In the analysis, we used acombinatorial technique analogous to Gallager’s probabilistic technique for lower bounding the
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008
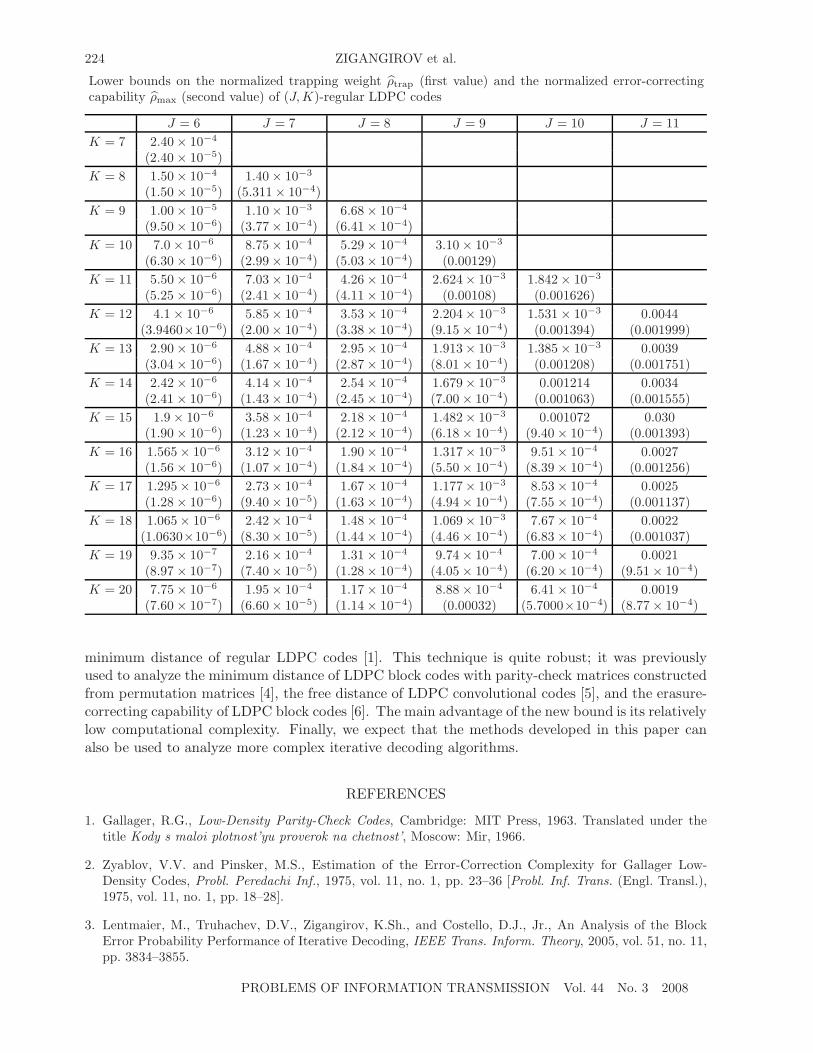
224 ZIGANGIROV et al.
Lower bounds on the normalized trapping weight ρ̂trap (first value) and the normalized error-correctingcapability ρ̂max (second value) of (J, K)-regular LDPC codes
J = 6 J = 7 J = 8 J = 9 J = 10 J = 11K = 7 2.40 × 10−4
(2.40 × 10−5)K = 8 1.50 × 10−4 1.40 × 10−3
(1.50 × 10−5) (5.311 × 10−4)K = 9 1.00 × 10−5 1.10 × 10−3 6.68 × 10−4
(9.50 × 10−6) (3.77 × 10−4) (6.41 × 10−4)K = 10 7.0 × 10−6 8.75 × 10−4 5.29 × 10−4 3.10 × 10−3
(6.30 × 10−6) (2.99 × 10−4) (5.03 × 10−4) (0.00129)K = 11 5.50 × 10−6 7.03 × 10−4 4.26 × 10−4 2.624× 10−3 1.842 × 10−3
(5.25 × 10−6) (2.41 × 10−4) (4.11 × 10−4) (0.00108) (0.001626)K = 12 4.1 × 10−6 5.85 × 10−4 3.53 × 10−4 2.204× 10−3 1.531 × 10−3 0.0044
(3.9460×10−6) (2.00 × 10−4) (3.38 × 10−4) (9.15 × 10−4) (0.001394) (0.001999)K = 13 2.90 × 10−6 4.88 × 10−4 2.95 × 10−4 1.913× 10−3 1.385 × 10−3 0.0039
(3.04 × 10−6) (1.67 × 10−4) (2.87 × 10−4) (8.01 × 10−4) (0.001208) (0.001751)K = 14 2.42 × 10−6 4.14 × 10−4 2.54 × 10−4 1.679× 10−3 0.001214 0.0034
(2.41 × 10−6) (1.43 × 10−4) (2.45 × 10−4) (7.00 × 10−4) (0.001063) (0.001555)K = 15 1.9 × 10−6 3.58 × 10−4 2.18 × 10−4 1.482× 10−3 0.001072 0.030
(1.90 × 10−6) (1.23 × 10−4) (2.12 × 10−4) (6.18 × 10−4) (9.40 × 10−4) (0.001393)K = 16 1.565× 10−6 3.12 × 10−4 1.90 × 10−4 1.317× 10−3 9.51 × 10−4 0.0027
(1.56 × 10−6) (1.07 × 10−4) (1.84 × 10−4) (5.50 × 10−4) (8.39 × 10−4) (0.001256)K = 17 1.295× 10−6 2.73 × 10−4 1.67 × 10−4 1.177× 10−3 8.53 × 10−4 0.0025
(1.28 × 10−6) (9.40 × 10−5) (1.63 × 10−4) (4.94 × 10−4) (7.55 × 10−4) (0.001137)K = 18 1.065× 10−6 2.42 × 10−4 1.48 × 10−4 1.069× 10−3 7.67 × 10−4 0.0022
(1.0630×10−6) (8.30 × 10−5) (1.44 × 10−4) (4.46 × 10−4) (6.83 × 10−4) (0.001037)K = 19 9.35 × 10−7 2.16 × 10−4 1.31 × 10−4 9.74 × 10−4 7.00 × 10−4 0.0021
(8.97 × 10−7) (7.40 × 10−5) (1.28 × 10−4) (4.05 × 10−4) (6.20 × 10−4) (9.51 × 10−4)K = 20 7.75 × 10−6 1.95 × 10−4 1.17 × 10−4 8.88 × 10−4 6.41 × 10−4 0.0019
(7.60 × 10−7) (6.60 × 10−5) (1.14 × 10−4) (0.00032) (5.7000×10−4) (8.77 × 10−4)
minimum distance of regular LDPC codes [1]. This technique is quite robust; it was previouslyused to analyze the minimum distance of LDPC block codes with parity-check matrices constructedfrom permutation matrices [4], the free distance of LDPC convolutional codes [5], and the erasure-correcting capability of LDPC block codes [6]. The main advantage of the new bound is its relativelylow computational complexity. Finally, we expect that the methods developed in this paper canalso be used to analyze more complex iterative decoding algorithms.
REFERENCES
1. Gallager, R.G., Low-Density Parity-Check Codes, Cambridge: MIT Press, 1963. Translated under thetitle Kody s maloi plotnost’yu proverok na chetnost’, Moscow: Mir, 1966.
2. Zyablov, V.V. and Pinsker, M.S., Estimation of the Error-Correction Complexity for Gallager Low-Density Codes, Probl. Peredachi Inf., 1975, vol. 11, no. 1, pp. 23–36 [Probl. Inf. Trans. (Engl. Transl.),1975, vol. 11, no. 1, pp. 18–28].
3. Lentmaier, M., Truhachev, D.V., Zigangirov, K.Sh., and Costello, D.J., Jr., An Analysis of the BlockError Probability Performance of Iterative Decoding, IEEE Trans. Inform. Theory, 2005, vol. 51, no. 11,pp. 3834–3855.
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008

ON THE ERROR-CORRECTING CAPABILITY OF LDPC CODES 225
4. Sridharan, A., Lentmaier, M., Truhachev, D.V., Costello, D.J., Jr., and Zigangirov, K.Sh., On the Mini-mum Distance of Low-Density Parity-Check Codes with Parity-Check Matrices Constructed from Permu-tation Matrices, Probl. Peredachi Inf., 2005, vol. 41, no. 1, pp. 39–52 [Probl. Inf. Trans. (Engl. Transl.),2005, vol. 41, no. 1, pp. 33–44].
5. Sridharan, A., Truhachev, D., Lentmaier, M., Costello, D.J., Jr., and Zigangirov, K.Sh., Distance Boundsfor an Ensemble of LDPC Convolutional Codes, IEEE Trans. Inform. Theory, 2007, vol. 53, no. 12,pp. 4537–4555.
6. Zigangirov, D.K. and Zigangirov, K.Sh., Decoding of Low-Density Codes with Parity-Check MatricesComposed of Permutation Matrices in an Erasure Channel Probl. Peredachi Inf., 2006, vol. 42, no. 2,pp. 44–52 [Probl. Inf. Trans. (Engl. Transl.), 2006, vol. 42, no. 2, pp. 106–113].
PROBLEMS OF INFORMATION TRANSMISSION Vol. 44 No. 3 2008
Related Documents











