NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011

NVIDIA Fermi Architecture Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011.
Jan 02, 2016
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

NVIDIA Fermi Architecture
Patrick CozziUniversity of PennsylvaniaCIS 565 - Spring 2011

Administrivia
Assignment 4 grades returned Project checkpoint on Monday
Post an update on your blog beforehand Poster session: 04/28
Three weeks from tomorrow

G80, GT200, and Fermi
November 2006: G80 June 2008: GT200 March 2011: Fermi (GF100)
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

New GPU Generation
What are the technical goals for a new GPU generation?

New GPU Generation
What are the technical goals for a new GPU generation? Improve existing application performance. How?

New GPU Generation
What are the technical goals for a new GPU generation? Improve existing application performance. How?Advance programmability. In what ways?

Fermi: What’s More?
More total cores (SPs) – not SMs though More registers: 32K per SM More shared memory: up to 48K per SM More Super Functional Units (SFUs)

Fermi: What’s Faster?
Faster double precision – 8x over GT200 Faster atomic operations. What for?
5-20x Faster context switches
Between applications – 10xBetween graphics and compute, e.g.,
OpenGL and CUDA

Fermi: What’s New?
L1 and L2 caches. For compute or graphics?
Dual warp scheduling Concurrent kernel execution C++ support Full IEEE 754-2008 support in hardware Unified address space Error Correcting Code (ECC) memory support Fixed function tessellation for graphics

G80, GT200, and Fermi
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

G80, GT200, and Fermi
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

GT200 and Fermi
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

Fermi Block Diagram
Image from: http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
GF100 16 SMs Each with 32 cores
512 total cores Each SM hosts up
to 48 warps, or 1,536 threads
In flight, up to 24,576 threads

Fermi SM
Why 32 cores per SM instead of 8?Why not more SMs?
G80 – 8 cores GT200 – 8 cores GF100 – 32 cores

Fermi SM
Image from: http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
Dual warp schedulingWhy?
32K registers 32 cores
Floating point and integer unit per core
16 Load/stores 4 SFUs

Fermi SM
Image from: http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
16 SMs * 32 cores/SM = 512 floating point operations per cycle
Why not in practice?

Fermi SM
Image from: http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
Each SM64KB on-chip memory
48KB shared memory / 16KB L1 cache, or
16KB L1 cache / 48 KB shared memory
Configurable by CUDA developer

Fermi Dual Warping Scheduling
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf
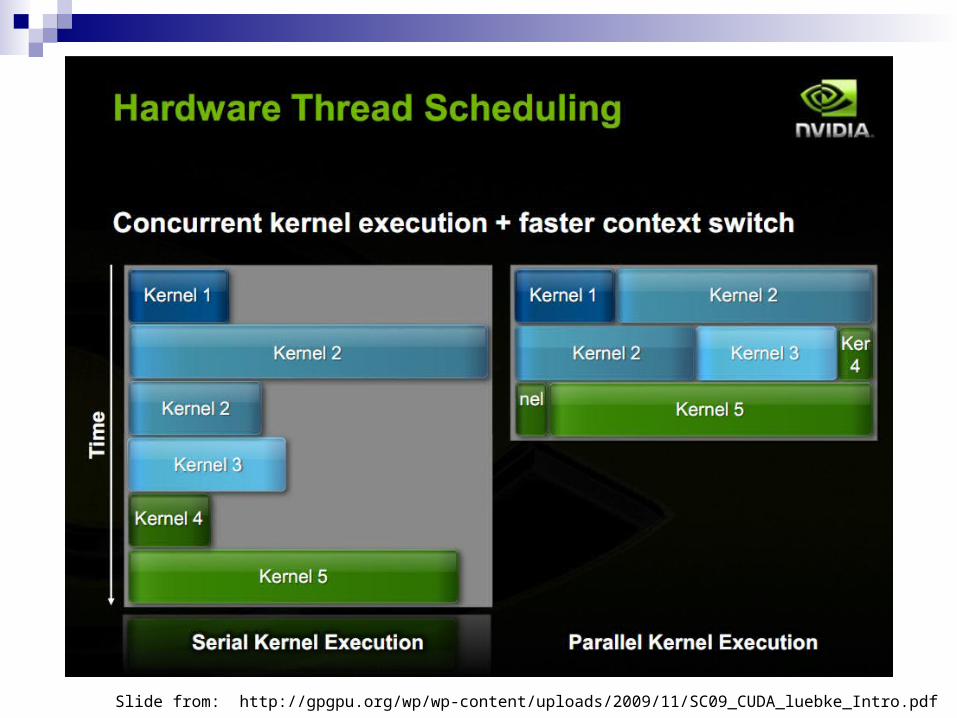
Slide from: http://gpgpu.org/wp/wp-content/uploads/2009/11/SC09_CUDA_luebke_Intro.pdf
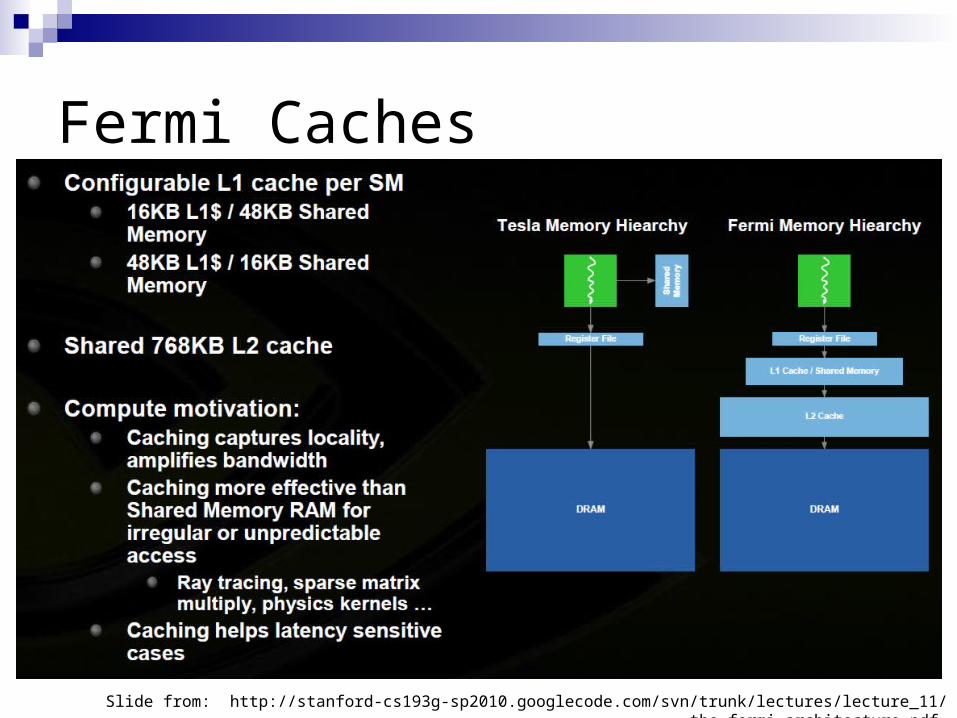
Fermi Caches
Slide from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

Fermi Caches
Slide from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

Image from: http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
Fermi: Unified Address Space

Fermi: Unified Address Space
64-bit virtual addresses 40-bit physical addresses (currently) CUDA 4: Shared address space with CPU.
Why?

Fermi: Unified Address Space
64-bit virtual addresses 40-bit physical addresses (currently) CUDA 4: Shared address space with CPU.
Why?No explicit CPU/GPU copiesDirect GPU-GPU copiesDirect I/O device to GPU copies

Fermi ECC
ECC ProtectedRegister file, L1, L2, DRAM
Uses redundancy to ensure data integrity against cosmic rays flipping bitsFor example, 64 bits is stored as 72 bits
Fix single bit errors, detect multiple bit errors What are the applications?

Fermi Tessellation
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

Fermi Tessellation
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf

Fermi Tessellation
Image from: http://stanford-cs193g-sp2010.googlecode.com/svn/trunk/lectures/lecture_11/the_fermi_architecture.pdf
Fixed function hardware on each SM for graphicsTexture filteringTexture cacheTessellationVertex Fetch / Attribute SetupStream OutputViewport Transform. Why?

Observations
Becoming easier to port CPU code to the GPURecursion, fast atomics, L1/L2 caches, faster
global memory In fact…

Observations
Becoming easier to port CPU code to the GPURecursion, fast atomics, L1/L2 caches, faster
global memory In fact… GPUs are starting to look like CPUs
Beefier SMs, L1 and L2 caches, dual warp scheduling, double precision, fast atomics
Related Documents











