Novel Speech Recognition Models for Arabic The Arabic Speech Recognition Team JHU Workshop Final Presentations August 21, 2002

Novel Speech Recognition Models for Arabic The Arabic Speech Recognition Team JHU Workshop Final Presentations August 21, 2002.
Dec 29, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Novel Speech Recognition Models for Arabic
The Arabic Speech Recognition TeamJHU Workshop Final Presentations
August 21, 2002

Arabic ASR Workshop Team
Senior Participants Undergraduate Students: Katrin Kirchhoff, UW Melissa Egan, Pomona
College
Jeff Bilmes, UW Feng He, Swarthmore College
John Henderson, MITRE
Mohamed Noamany, BBN Affiliates:
Pat Schone, DoD Dimitra Vergyri, SRI
Rich Schwartz, BBN Daben Liu, BBN
Nicolae Duta, BBN
Graduate Students Ivan Bulyko, UW
Sourin Das, JHU Mari Ostendorf, UW
Gang Ji, UW

“Arabic”
GulfArabic
EgyptianArabic
LevantineArabic
North-AfricanArabic
ModernStandardArabic(MSA)
Dialects used for informal conversation
Cross-regional standard, used for formal communication

Arabic ASR: Previous Work
• dictation: IBM ViaVoice for Arabic• Broadcast News: BBN TIDESOnTap• conversational speech: 1996/1997 NIST
CallHome Evaluations
• little work compared to other languages• few standardized ASR resources

Arabic ASR: State of the Art (before WS02)
• BBN TIDESOnTap: 15.3% WER • BBN CallHome system: 55.8% WER • WER on conversational speech noticeably
higher than for other languages (eg. 30% WER for English CallHome)
focus on recognition of conversational Arabic

Problems for Arabic ASR
• language-external problems: – data sparsity, only 1 (!) standardized corpus
of conversational Arabic available
• language-internal problems: – complex morphology, large number of
possible word forms (similar to Russian, German, Turkish,…) – differences between written and spoken
representation: lack of short vowels and other pronunciation information
(similar to Hebrew, Farsi, Urdu, Pashto,…)

Corpus: LDC ECA CallHome
• phone conversations between family members/friends
• Egyptian Colloquial Arabic (Cairene dialect)• high degree of disfluencies (9%), out-of-vocabulary
words (9.6%), foreign words (1.6%) • noisy channels • training: 80 calls (14 hrs), dev: 20 calls (3.5 hrs),
eval: 20 calls (1.5 hrs)• very small amount of data for language modeling
(150K) !

MSA - ECA differences • Phonology:
– /th/ /s/ or /t/ thalatha - talata (‘three’)– /dh/ /z/ or /d/ dhahab - dahab (‘gold’)– /zh/ /g/ zhadeed - gideed (‘new’) – /ay/ /e:/ Sayf - Seef (‘summer’)– /aw/ /o:/ lawn - loon (‘color’)
• Morphology: – inflections yatakallamu - yitkallim (‘he
speaks’)
• Vocabulary:– different terms TAwila - tarabeeza (`table’)
• Syntax: – word order differences SVO - VSO
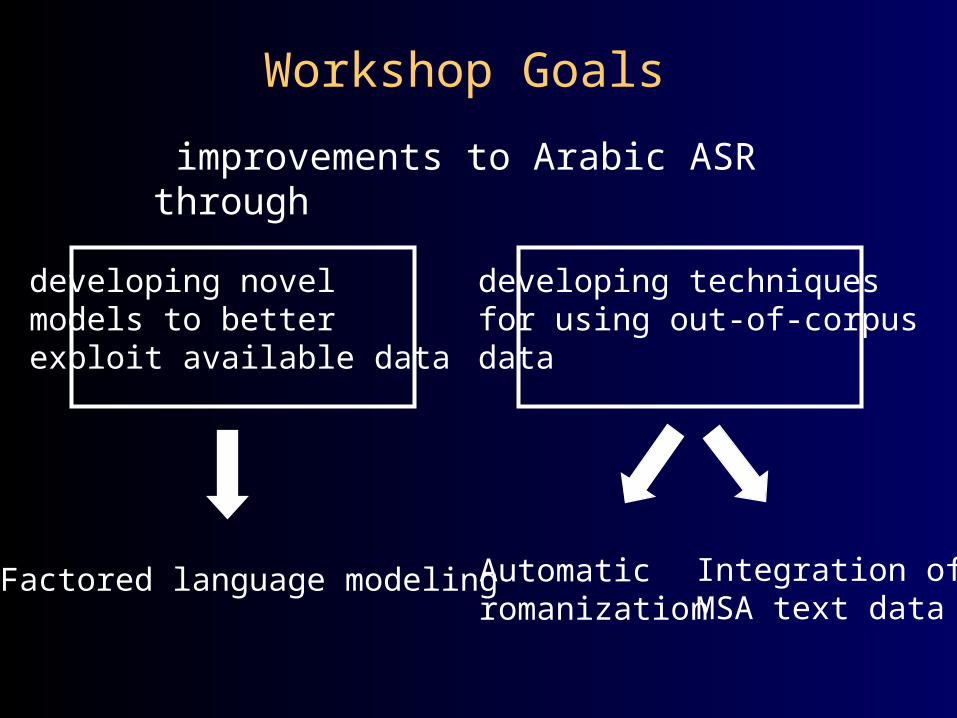
Workshop Goals
improvements to Arabic ASR through
developing novel models to better exploit available data
developing techniques for using out-of-corpusdata
Factored language modeling Automaticromanization
Integration ofMSA text data

Factored Language Models
• complex morphological structure leads to large number of possible word forms
• break up word into separate components
• build statistical n-gram models over individual morphological components rather than complete word forms

Automatic Romanization
• Arabic script lacks short vowels and other pronunciation markers
• comparable English example
• lack of vowels results in lexical ambiguity; affects acoustic and language model training
• try to predict vowelization automatically from data and use result for recognizer training
th fsh stcks f th nrth tlntc hv bn dpletd
the fish stocks of the north atlantic have been depleted

Out-of-corpus text data
• no corpora of transcribed conversational speech available
• large amounts of written (Modern Standard Arabic) data available (e.g. Newspaper text)
• Can MSA text data be used to improve language modeling for conversational speech?
• Try to integrate data from newspapers, transcribed TV broadcasts, etc.

Recognition Infrastructure
• baseline system: BBN recognition system • N-best list rescoring • Language model training: SRI LM toolkit
with significant additions implemented during this workshop
• Note: no work on acoustic modeling, speaker adaptation, noise robustness, etc.
• two different recognition approaches: grapheme-based vs. phoneme-based

Summary of Results (WER)
40
45
50
55
60
65
52
53
54
55
56
57
58
59
AdditionalCallhomedata 55.1%
Languagemodeling 53.8%
Baseline59.0
Automaticromanization57.9%
Grapheme-based reconizer
Phone-based recognizer
Random62.7%
Oracle46%
Base-line55.8%
Trueromanization54.9%

Novel research
• new strategies for language modeling based on morphological features
• new graph-based backoff schemes allowing wider range of smoothing techniques in language modeling
• new techniques for automatic vowel insertion• first investigation of use of automatically
vowelized data for ASR• first attempt at using MSA data for language
modeling for conversational Arabic• morphology induction for Arabic

Key Insights
• Automatic romanization improves grapheme-based Arabic recognition systems
• trend: morphological information helps in language modeling
• needs to be confirmed on larger data set
• Using MSA text data does not help• We need more data!

Resources
• significant add-on to SRILM toolkit for general factored language modeling
• techniques/software for automatic romanization of Arabic script
• part-of-speech tagger for MSA & tagged text

Outline of Presentations• 1:30 - 1:45: Introduction (Katrin Kirchhoff)• 1:45 - 1:55: Baseline system (Rich Schwartz) • 1:55 - 2:20: Automatic romanization (John Henderson, Melissa Egan)• 2:20 - 2:35: Language modeling - overview (Katrin
Kirchhoff)• 2:35 - 2:50: Factored language modeling (Jeff Bilmes)• 2:50 - 3:05: Coffee Break • 3:05 - 3:10: Automatic morphology learning (Pat Schone)• 3:15 - 3:30: Text selection (Feng He)• 3:30 - 4:00: Graduate student proposals (Gang Ji, Sourin
Das)• 4:00 - 4:30: Discussion and Questions

Thank you!• Fred Jelinek, Sanjeev Khudanpur, Laura
Graham• Jacob Laderman + assistants• Workshop sponsors• Mark Liberman, Chris Cieri, Tim Buckwalter• Kareem Darwish, Kathleen Egan• Bill Belfield & colleagues from BBN • Apptek


BBN Baseline System for Arabic
Richard Schwartz, Mohamed Noamany,Daben Liu, Bill Belfield, Nicolae Duta
JHU WorkshopAugust 21, 2002

BBN BYBLOS System
• Rough’n’Ready / OnTAP / OASIS system
• Version of BYBLOS optimized for Broadcast News
• OASIS system fielded in Bangkok and Aman
• Real-Time operation with 1-minute delay
• 10%-20% WER, depending on data

BYBLOS Configuration
• 3-passes of recognition– Forward Fast-match uses PTM models and
approximate bigram search– Backward pass uses SCTM models and
approximate trigram search, creates N-best.– Rescoring pass uses cross-word SCTM
models and trigram LM
• All runs in real time– Minimal difference from running slowly

Use for Arabic Broadcast News
• Transcriptions are in normal Arabic script, omitting short vowels and other diacritics.
• We used each Arabic letter as if it were a phoneme.
• This allowed addition of large text corpora for language modeling.

Initial BN Baseline
• 37.5 hours of acoustic training• Acoustic training data (230K words)
used for LM training• 64K-word vocabulary (4% OOV)
• Initial word error rate (WER) = 31.2%

Speech Recognition Performance
System (all real-time results) WER (%)
Baseline 31.2
+ 145M word LM (Al Hayat) 26.6
+ System Improvements (MLLR and tuning) 21.0
+ 128k Lexicon (OOV reduced to 2%) 20.4
+ Additional 20 hours acoustic data 19.1
+ 290M word LM + improved lexicon 17.3
+ New scoring (remove hamza from alif) 15.3

Call Home Experiments
• Modified OnTAP system to make it more appropriate for Call Home data.
• Added features from LVCSR research to OnTAP system for Call Home data.
• Experiments:– Acoustic training: 80 conversations (15 hours)
• Transcribed with diacritics
– Acoustic training data (150K words) used for LM
– Real-time
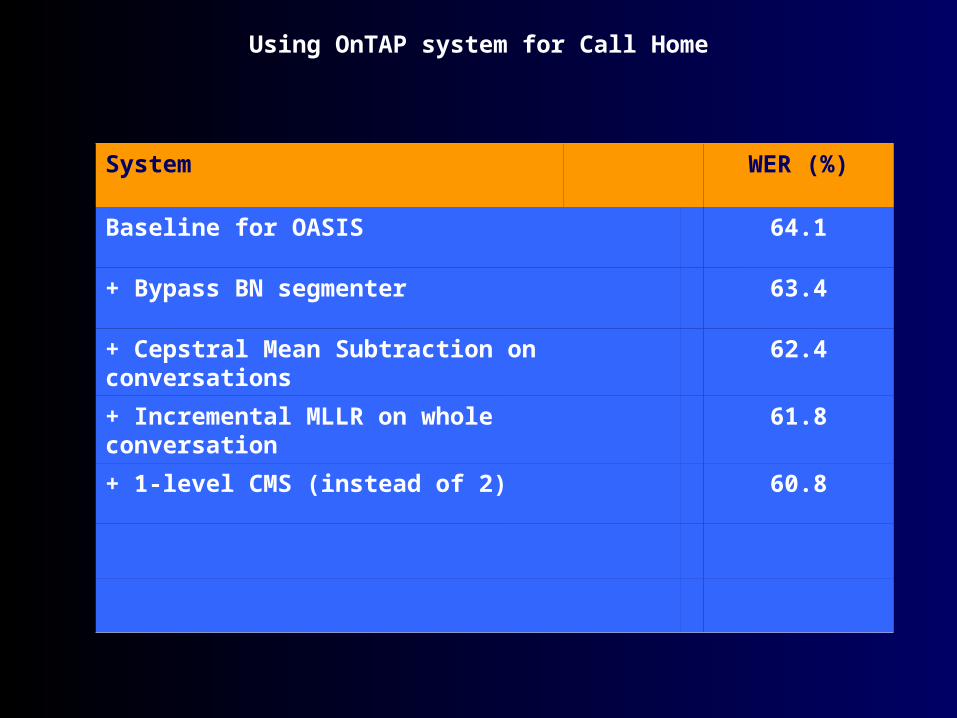
Using OnTAP system for Call Home
System WER (%)
Baseline for OASIS 64.1
+ Bypass BN segmenter 63.4
+ Cepstral Mean Subtraction on conversations 62.4
+ Incremental MLLR on whole conversation 61.8
+ 1-level CMS (instead of 2) 60.8

Additions from LVCSR
System WER (%)
Baseline for OASIS 60.8
+ VTL on training and decoding (unoptimized) 59.0
+ LPC Smoothing with 40 poles 58.7
+ ‘split-init training’ 58.1
+ HLDA (not used for workshop) 56.6
+ Modified backoff (not used for workshop) 56.0

Output Provided for Workshop
• OASIS was run on various sets of training as needed• Systems were run either for Arabic script phonemes
or ‘Romanized’ phonemes – with diacritics.• In addition to workshop participants, others at BBN
provided assistance and worked on workshop problems.
• Output provided for workshop was N-best sentences– with separate scores for HMM, LM, #words, #phones,
#silences– Due to high error rate (56%), the oracle error rate for 100
N-best was about 46%.
• Unigram lattices were also provided, with oracle error rate of 15%

Phoneme HMM Topology Experiment
• The phoneme HMM topology was increased for the Arabic script system from 5 states to 10 states in order to accommodate a consonant and possible vowel.
• The gain was small (0.3% WER)

OOV Problem
• OOV Rate is 10%– 50% is morphological variants of words in
the training set– 10% is Proper names– 40% is other unobserved words
• Tried adding words from BN and from morphological transducer– Added too many words with too small gain

Use BN to Reduce OOV
• Can we add words from BN to reduce OOV?
• BN text contains 1.8M distinct words.• Adding entire 1.8M words reduces OOV
from 10% to 3.9%.• Adding top 15K words reduces OOV to
8.9%• Adding top 25K words reduces OOV to
8.4%.

Use Morphological Transducer
• Use LDC Arabic transducer to expand verbs to all forms– Produces > 1M words
• Reduces OOV to 7%

Language Modeling Experiments
Described in other talks• Searched for available dialect
transcriptions• Combine BN (300M words) with CH
(230K)• Use BN to define word classes• Constrained back-off for BN+CH


Autoromanization of Arabic Script
Melissa Egan and John Henderson

Autoromanization (AR) goal• Expand Arabic script representation to include
short vowels and other pronunciation information.
• Phenomena not typically marked in non-diacritized script include:– Short vowels {a, i, u}– Repeated consonants (shadda)– Extra phonemes for Egyptian Arabic {f/v,j/g} – Grammatical marker that adds an ‘n’ to the
pronunciation (tanween)
• ExampleNon-diacritized form: ktb – write Expansions: kitab – book
aktib – I writekataba – he wrotekattaba – he caused to write

AR motivation
• Romanized text can be used to produce better output from an ASR system.– Acoustic models will be able to better disambiguate
based on extra information in text.– Conditioning events in LM will contain more
information.
• Romanized ASR output can be converted to script for alternative WER measurement.
• Eval96 results (BBN recognizer, 80 conv. train)– script recognizer: 61.1 WERG (grapheme)– romanized recognizer: 55.8 WERR
(roman)

RomanizerTesting
RomanizerTraining
AR data
CallHome Arabic from LDCConversational speech transcripts (ECA) in both script and a roman specification that includes short vowels, repeats, etc.
set conversationswords
asrtrain 80 135Kdev 20
35Keval96(asrtest) 20 15Keval97 20 18Kh5_new 20 18K

Data format• Script without and with diacritics
• CallHome in script and roman forms
Script: AlHmd_llh kwIsB w AntI AzIk
Roman: ilHamdulillA kuwayyisaB~ wi inti izzayyik
our task

Autoromanization (AR) WER baseline
• Train on 32K words in eval97+h5_new• Test on 137K words in ASR_train+h5_new
Status portion error % totalin train in test in test errorunambig. 68.0% 1.8% 6.2%ambig. 15.5 13.9 10.8unknown 16.5 99.8 83.0total 100 19.9 100.0
Biggest potential error reduction would come from predicting romanized forms for unknown words.

AR “knitting” example
unknown: t bqwA
kn.roman: yibqu ops: ciccrd
new roman: tibqu
known: y bqwA
kn.roman: yibqu ops: ciccrd
unknown: tbqwA
known: ybqwA1. Find close known word
2. Record ops required to make roman from known
3. Construct new roman using same ops

Experiment 1 (best match)
Observed patterns in the known short/long pairs:Some characters in the short forms are
consistently found with particular, non-identical characters in the long forms.
Example rule: A a

Experiment 2 (rules)
• Some output forms depend on output context.
• Rule:– ‘u’ occurs only between two non-vowels.– ‘w’ occurs elsewhere.
• Accurate for 99.7% of the instances of ‘u’ and ‘w’ in the training dictionary long forms. Similar rule may be formulated for ‘i’ and ‘y.’
Environments in which ‘w’ occurs in training dictionary long forms:Env FreqC _ V 149V _ # 8# _ V 81C _ # 5V _ V 121V _ C 118
Environments in which ‘u’ occurs in training dictionary long forms:Env FreqC _ C 1179C _ # 301# _ C 29

Experiment 3 (local model)
• Move to more data-driven model– Found some rules manually.– Look for all of them, systematically.
• Use best-scoring candidate for replacement– Environment likelihood score– Character alignment score
Known long: H a n s A h aKnown short: H A n s A h A
input: H A m D y h A
result: H a m D I h a

Experiment 4 (n-best)• Instead of generating romanized form using the
single best short form in the dictionary, generate romanized forms using top n best short forms.
Example (n = 5)

Character error rate (CER)
• Measurement of insertions, deletions, and substitutions in character strings should more closely track phoneme error rate.
• More sensitive than WER– Stronger statistics from same data
• Test set results– Baseline 49.89 character error rate (CER)– Best model 24.58 CER– Oracle 2-best list 17.60 CER suggests more room for gain.

Summary of performance (dev set)
Accuracy CER
Baseline 8.4% 41.4%
Knitting 16.9% 29.5%
Knitting + best match + rules 18.4% 28.6%
Knitting + local model 19.4% 27.0%
Knitting + local model + n-best 30.0% 23.1% (n = 25)

Varying the number of dictionary matches
18
22
26
30
0 50 100 150 200dictionary matches
per
form
ance
accuracy CER

ASR scenarios
1) Have a script recognizer, but want to produce romanized form.
postprocessing ASR output
2) Have a small amount of romanized data and a large amount of script data available for recognizer training.
preprocessing ASR training set

ASR experiments
ScriptTrain
ScriptASR
AR
WERG
WERRRomanResult
ScriptResult
ARRoman
ASR
RomanResult WERR
ScriptResult WERGR2S
Postprocessing
Preprocessing

Experiment: adding script data
Future training set
ASR train100 conv
AR train40
•Script LM training data Script LM training data could be acquired from could be acquired from found text.found text.
•Script transcription is Script transcription is cheaper than roman cheaper than roman transcriptiontranscription
•Simulate a Simulate a preponderance of preponderance of script by training AR script by training AR on a separate set.on a separate set.
•ASR is then trained ASR is then trained on output of AR.on output of AR.

Eval 96 experiments, 80 conv
Config WERR WERG
script baseline N/A 59.8post processing 61.5 59.8preprocessing 59.9 59.2 (-
0.6)Roman baseline 55.8 55.6 (-
4.2)Bounding experiment• No overlap between ASR train and AR
train.• Poor pronunciations for “made-up” words.
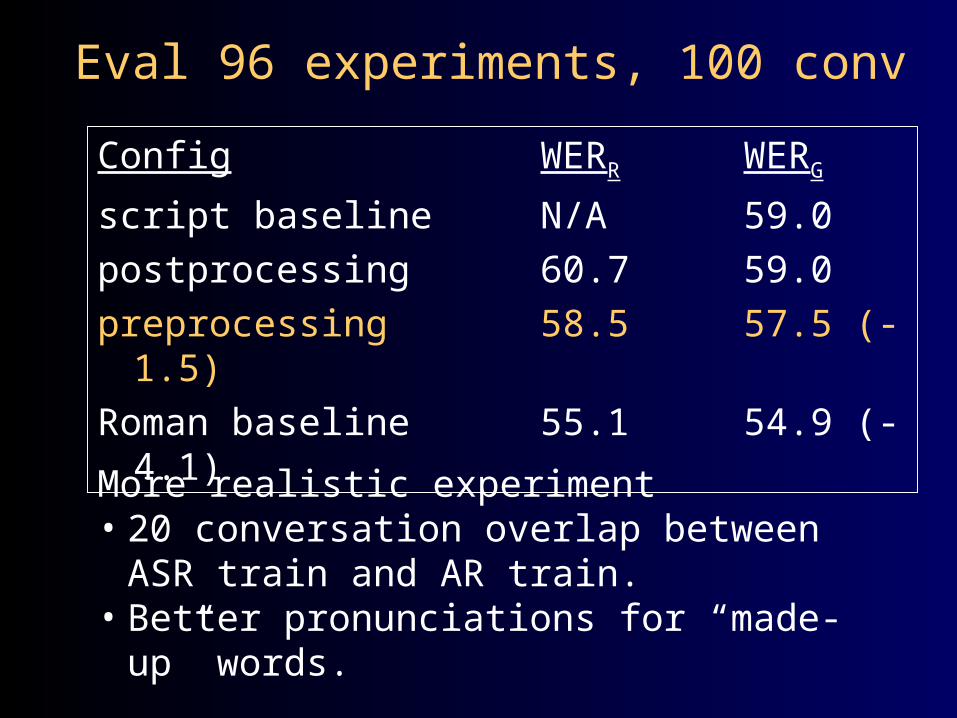
Eval 96 experiments, 100 conv
Config WERR WERG
script baseline N/A 59.0postprocessing 60.7 59.0preprocessing 58.5 57.5 (-
1.5)Roman baseline 55.1 54.9 (-
4.1)More realistic experiment• 20 conversation overlap between ASR
train and AR train.• Better pronunciations for “made-up”
words.

Remaining challenges
• Correct “dangling tails” in short matches
• Merge unaligned characters

Bigram translation model
input s: t b q w A
output r: □ t i b q u □
kn. roman dl: y i b q u
r* arg maxr
p(s,d s )p(r | s,dl )d(ds , dl )
arg maxr
p(s,ds )p(r, s,dl )d(ds ,d l )
p(r, s, dl ) p(ri | ri 1 )p(sj | ri )p(dlk | ri)i
p(sj | ri)
p(ri | ri 1)
p(dlk | ri )

Future work
• Context provides information for disambiguating both known and unknown words– Bigrams for unknown words will also be
unknown, use part of speech tags or morphology.
• Acoustics– Use acoustics to help disambiguate vowels?– Provide n-best output as alternative
pronunciations for ASR training.


Factored Language Modeling
Katrin Kirchhoff, Jeff Bilmes, Dimitra Vergyri,Pat Schone, Gang Ji, Sourin Das

Arabic morphology
• structure of Arabic derived words
s k n
root
a a
pattern
LIVE + past + 1st-sg-past + part: “so I lived”
-tufa- affixesparticles

Arabic morphology• ~5000 roots• several hundred patterns• dozens of affixes large number of possible word
forms problems training robust language
model large number of OOV words

Vocabulary Growth - full word forms
CallHome
0
2000
4000
6000
8000
10000
12000
14000
16000
# word tokens
vocab size EnglishArabic

Vocabulary Growth - stemmed words
CallHome
0
2000
4000
6000
8000
10000
12000
14000
16000
# word tokens
vocab size EN wordsAR wordsEN stemsAR stems

Particle model
• Break words into sequences of stems + affixes:
• Approximate probability of word sequence by probability of particle sequence
MW ,...,, 21
T
ntnttttN PWWWP )|(),...,,( 1,...,2,121

Factored Language Model
• Problem: how can we estimate P(Wt|Wt-1,Wt-
2,...) ?
• Solution: decompose W into its morphological components: affixes, stems, roots, patterns
• words can be viewed as bundles of features Pt
patterns
roots
affixes
stems
words
Rt
At
St
Pt-1
Rt-1
At-1
St-1
Pt-2
Rt-2
At-2
St-2
Wt-2 Wt-1 Wt

Statistical models for factored representations
• Class-based LM:
• Single-stream LM:
),|()|(),|( 2121 tttttttt FFFPFWPWWWP
),|(),...,,|( 21121 tttttt FFFPFFFFP

Full Factored Language Model
assume where w = word, r = root, = pattern, a = affixes
• Goal: find appropriate conditional independence statements to simplify this model.
iiii raw ,,
),,,,,|(
),,,,,,|(
),,,,,,,|(
),,,,,|,,(),|(
222111
222111
222111
22211121
iiiiiii
iiiiiiii
iiiiiiiii
iiiiiiiiiiii
raraP
rararP
rararaP
rararaPwwwP

Experimental Infrastructure
• All language models tested using nbest rescoring
• two baseline word-based LMs: – B1: BBN LM, WER 55.1%– B2: WS02 baseline LM, WER 54.8%
• combination of baselines: 54.5%• new language models were used in
combination with one or both baseline LMs
• log-linear score combination scheme

Log-linear combination
For m information sources, each producing a maximum-likelihood estimate for W:
I: total information available Ii : the i’th information source
ki: weight for the i’th information source
i
i
m
ii
kIWP
IZIWP )|(
)(
1)|(

Discriminative combination
• We optimize the combination weights jointly with the language model and insertion penalty to directly minimize WER of the maximum likelihood hypothesis.
• The normalization factor can be ignored since it is the same for all alternative hypotheses.
• Used the simplex optimization method on the 100-bests provided by BBN (optimization algorithm available in the SRILM toolkit).

Word decomposition
• Linguistic decomposition (expert knowledge)
• automatic morphological decomposition: acquire morphological units from data without using human knowledge
• assign words to classes based not on characteristics of word form but based on distributional properties

(Mostly) Linguistic Decomposition
• Stems/morph class: information from LDC CH lexicon:
• roots: determined by K. Darwish’s morphological analyzer for MSA
• pattern: determined by subtracting root from stem
$atamna <…> $atam:verb+past-1st-plural
stem morph. tag
$atam $tm
$atam CaCaC

Automatic Morphology
• Classes defined by morphological components derived from data
• no expert knowledge• based on statistics of word forms• more details in Pat’s presentation

Data-driven Classes• Word clustering based on distributional statistics• Exchange algorithm (Martin et. al 98)
– initially assign words to individual clusters– move each temporarily word to all other clusters,
compute change in perplexity (class-based trigram)– keep assignment that minimizes perplexity– stop when class assignment no longer changes
• bottom-up clustering (SRI toolkit)– initially assign words to individual clusters– successively merge pairs of clusters with highest
average mutual information– stop at specified number of classes

Results
• Best word error rates obtained with:– particle model: 54.0% (B1 + particle LM)
– class-based models: 53.9% (B1+Morph+Stem)
– automatic morphology: 54.3% (B1+B2+Rule)
– data-driven classes: 54.1% (B1+SRILM, 200 classes)
• combination of best models: 53.8%

Conclusions• Overall improvement in WER gained from
language modeling (1.3%) is significant• individual differences between LMs are not
significant• but: adding morphological class models always
helps language model combination• morphological models get the highest weights
in combination (in addition to word-based LMs)• trend needs to be verified on larger data set application to script-based system?


Factored Language Models and Generalized
Graph Backoff
Jeff Bilmes, Katrin KirchhoffUniversity of Washington, Seattle &
JHU-WS02 ASR Team

Outline• Language Models, Backoff, and Graphical
Models
• Factored Language Models (FLMs) as Graphical Models
• Generalized Graph Backoff algorithm
• New features to SRI Language Model Toolkit (SRILM)

Standard Language Modeling
321( | ) ( | , , )tt t ttt wP w h P w w w
• Example: standard tri-gram
tW1tW 2tW 3tW 4tW

Typical Backoff in LM
1 2 3| , ,t t t tW W W W
1 2| ,t t tW W W
1|t tW W
tW
• In typical LM, there is one natural (temporal) path to back off along.
• Well motivated since information often decreases with word distance.

Factored LM: Proposed Approach
• Decompose words into smaller morphological or class-based units (e.g., morphological classes, stems, roots, patterns, or other automatically derived units).
• Produce probabilistic models over these units to attempt to improve WER.

Example with Words, Stems, and Morphological classes
tS1tS 2tS 3tS
tW1tW 2tW 3tW
tM1tM 2tM 3tM
( | , )t t tP w s m1 2( | , , )t t t tP s m w w 1 2( | , )t t tP m w w

Example with Words, Stems, and Morphological classes
tS1tS 2tS 3tS
tW1tW 2tW 3tW
tM1tM 2tM 3tM
1 2 1 2 1 2( | , , , , , )t t t t t t tP w w w s s m m

In general
2tF
21tF
22tF
23tF
1tF
11tF
12tF
13tF
3tF
31tF
32tF
33tF

• A word is equivalent to collection of factors.
• E.g., if K=3
• Goal: find appropriate conditional independence statements to simplify this sort of model while keeping perplexity and WER low. This is the structure learning problem in graphical models.
General Factored LM
1:{ } { }Kt tw f
1 2 3 1 2 3 1 2 31 2 1 1 1 2 2 2
1 2 3 1 2 3 1 2 31 1 1 2 2 2
2 3 1 2 3 1 2 31 1 1 2 2 2
3 1 2 3 1 21 1 1 2 2
( | , ) ( , , | , , , , , )
( | , , , , , , , )
( | , , , , , , )
( | , , , , ,
t t t t t t t t t t t t
t t t t t t t t t
t t t t t t t t
t t t t t t
P w w w P f f f f f f f f f
P f f f f f f f f f
P f f f f f f f f
P f f f f f f f
32 )t
the kth factorkf

The General Case
2tF
22tF
1tF
11tF
21tF
23tF
12tF
13tF
3tF
31tF
32tF
33tF

The General Case
iF
1AF
2AF
3AF
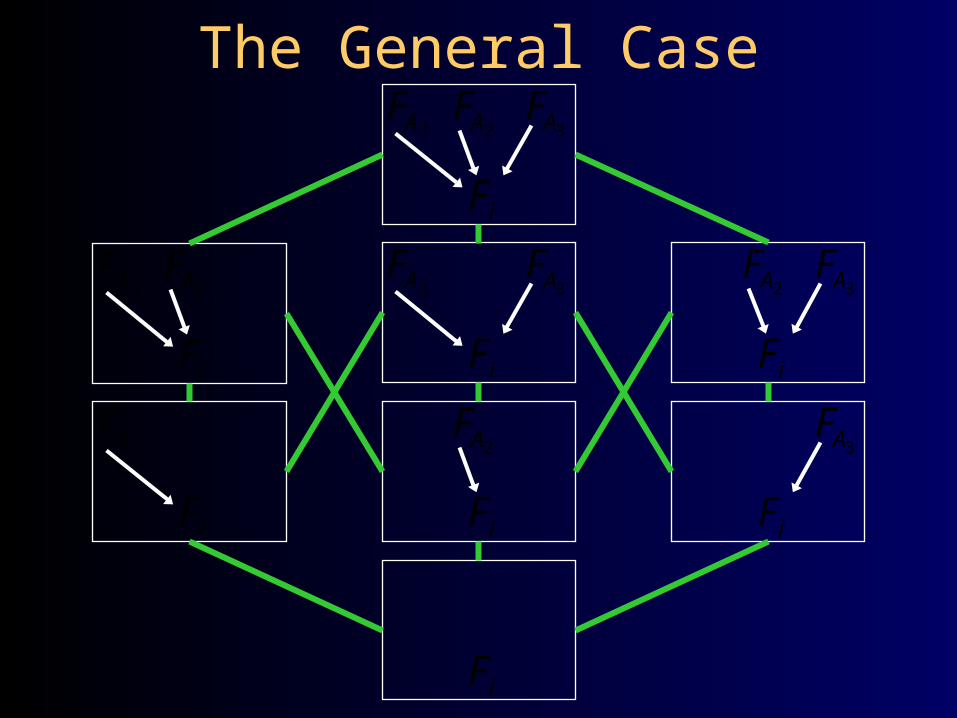
The General Case
iF
1AF
2AF
3AF
iF
1AF
3AF
iF
1AF
iF
iF
1AF
2AF
iF
2AF
3AF
iF
2AF
iF
3AF

1 2 3| , ,i A A AF F F F
1 2| ,i A AF F F 2 3| ,i A AF F F1 3| ,i A AF F F
1|i AF F 2|i AF F 3|i AF F
iF
A Backoff Graph (BG)
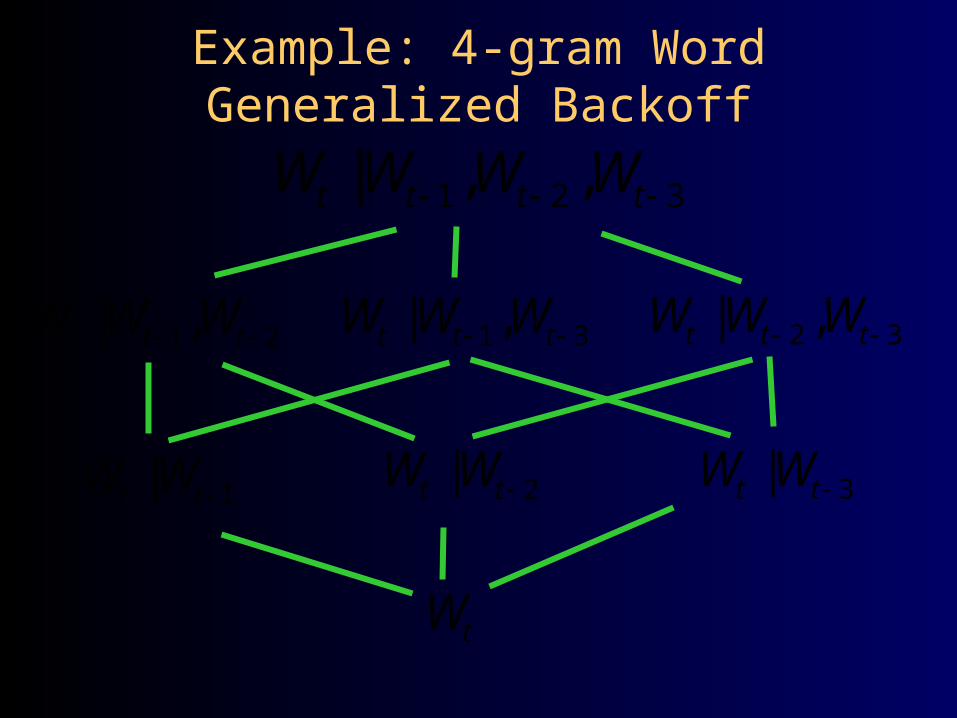
Example: 4-gram Word Generalized Backoff
1 2 3| , ,t t t tW W W W
1 2| ,t t tW W W
1|t tW W
2 3| ,t t tW W W 1 3| ,t t tW W W
2|t tW W 3|t tW W
tW

How to choose backoff path?
Four basic strategies1.Fixed path (based on what
seems reasonable (e.g., temporal constraints))
2.Generalized all-child backoff3.Constrained multi-child backoff4.Child combination rules
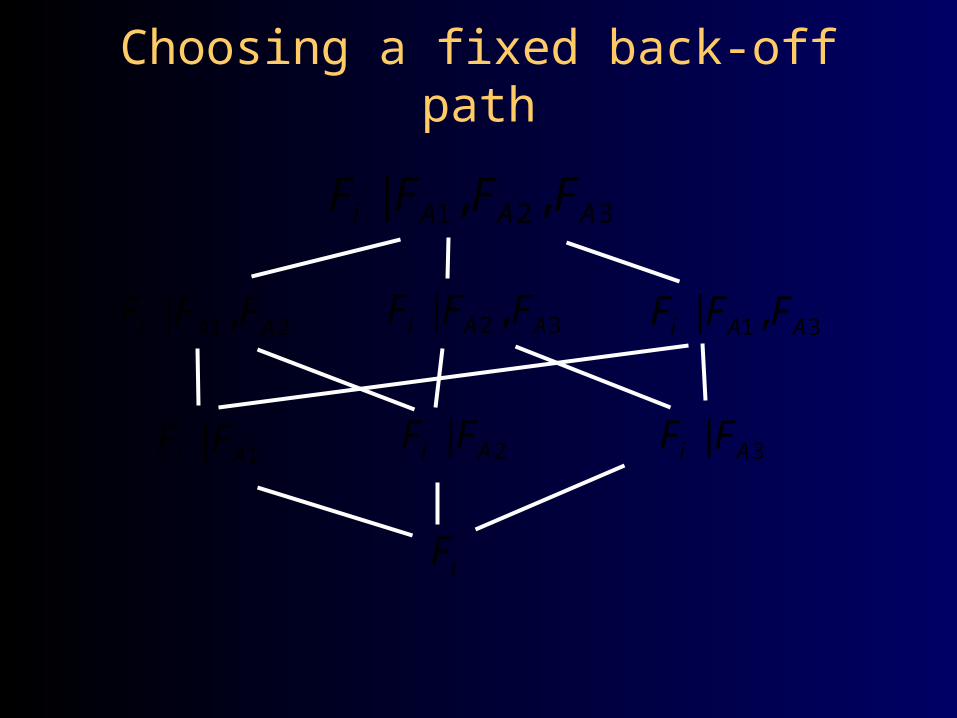
Choosing a fixed back-off path
1 2 3| , ,i A A AF F F F
1 2| ,i A AF F F 2 3| ,i A AF F F
2|i AF F 3|i AF F
iF
1 3| ,i A AF F F
1|i AF F

How to choose backoff path?
Four basic strategies1.Fixed path (based on what
seems reasonable (e.g., temporal constraints))
2.Generalized all-child backoff3.Constrained multi-child backoff4.Child combination rules

Generalized Backoff
1 2
1 2( , , ) 1 2
1 21 2
1 2 1 2
( , , )if ( , , ) 0
( , )( | , )
( , ) ( , , ) otherwise
P P
P PN f f f P P
P PBO P P
P P P P
N f f fd N f f f
N f fP f f f
f f g f f f
• In typical backoff, we drop 2nd parent and use conditional probability.
1 2 1( , , ) ( | )P P BO Pg f f f P f f
• More generally, g() can be any positive function, but need new algorithm for computing backoff weight (BOW).

Computing BOWs
1 2
1 2
1 2
1 2( , , )
: ( , , ) 0 1 21 2
1 2: ( , , ) 0
( , , )1
( , )( , )
( , , )
P P
P P
P P
P PN f f f
f N f f f P PP P
P Pf N f f f
N f f fd
N f ff f
g f f f
• Many possible choices for g() functions (next few slides)
• Caveat: certain g() functions can make the LM much more computationally costly than standard LMs.

g() functions
• Standard backoff
1 2 1( , , ) ( | )P P BO Pg f f f P f f
• Max counts
1 2 *( , , ) ( | )P P BO Pjg f f f P f f
* argmax ( , )Pjj
j N f f
• Max normalized counts
* ( , )argmax
( )Pj
j Pj
N f fj
N f

More g() functions• Max backoff graph node.
1 2 *( , , ) ( | )P P BO Pjg f f f P f f* argmax ( | )BO Pj
jj P f f
1 2 3| , ,i A A AF F F F
1 1 2| ,A AF F F 1 2 3| ,A AF F F 1 3| ,i A AF F F
1|i AF F 2|i AF F 3|i AF F
iF

More g() functions• Max back off graph node.
1 2 *( , , ) ( | )P P BO Pjg f f f P f f* argmax ( | )BO Pj
jj P f f
1 2 3| , ,i A A AF F F F
1 1 2| ,A AF F F 1 2 3| ,A AF F F 1 3| ,i A AF F F
1|i AF F 2|i AF F 3|i AF F
iF

How to choose backoff path?
Four basic strategies1.Fixed path (based on what seems
reasonable (time))2.Generalized all-child backoff3.Constrained multi-child backoff
• Same as before, but choose a subset of possible paths a-priori
4.Child combination rules• Combine child node via
combination function (mean, weighted avg., etc.)

Significant Additions to Stolcke’s SRILM, the SRI
Language Modeling Toolkit
• New features added to SRILM including– Can specify an arbitrary number of
graphical-model based factorized models to train, compute perplexity, and rescore N-best lists.
– Can specify any (possibly constrained) set of backoff paths from top to bottom level in BG.
– Different smoothing (e.g., Good-Turing, Kneser-Ney, etc.) or interpolation methods may be used at each backoff graph node
– Supports the generalized backoff algorithms with 18 different possible g() functions at each BG node.

Example with Words, Stems, and Morphological classes
tS1tS 2tS 3tS
tW1tW 2tW 3tW
tM1tM 2tM 3tM
( | , )t t tP w s m1 2( | , , )t t t tP s m w w 1 2( | , )t t tP m w w
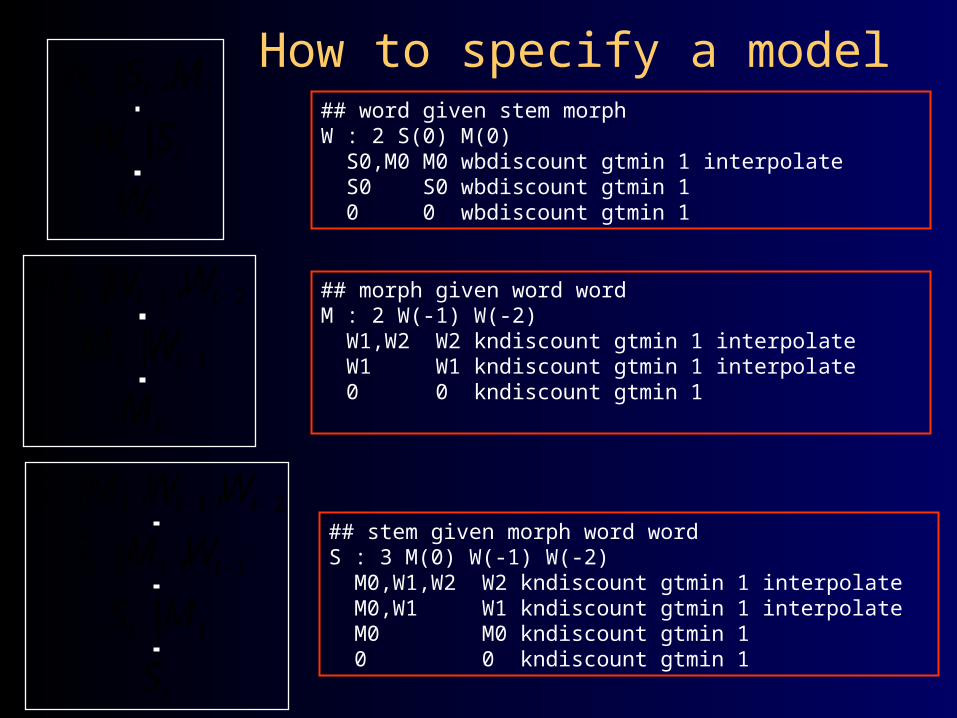
How to specify a model## word given stem morphW : 2 S(0) M(0) S0,M0 M0 wbdiscount gtmin 1 interpolate S0 S0 wbdiscount gtmin 1 0 0 wbdiscount gtmin 1
## stem given morph word word S : 3 M(0) W(-1) W(-2) M0,W1,W2 W2 kndiscount gtmin 1 interpolate M0,W1 W1 kndiscount gtmin 1 interpolate M0 M0 kndiscount gtmin 1 0 0 kndiscount gtmin 1
## morph given word wordM : 2 W(-1) W(-2) W1,W2 W2 kndiscount gtmin 1 interpolate W1 W1 kndiscount gtmin 1 interpolate 0 0 kndiscount gtmin 1
| ,t t tW S M
|t tW S
tW
1 2| ,t t tM W W
1|t tM W
tM
1| ,t t tS M W
|t tS M
1 2| , ,t t t tS M W W
tS

Summary• Language Models, Backoff, and Graphical
Models
• Factored Language Models (FLMs) as Graphical Models
• Generalized Graph Backoff algorithm
• New features to SRI Language Model Toolkit (SRILM)

Coffee Break
Back in 10 minutes

Knowledge-Free Induction of Arabic Morphology
Patrick Schone21 August 2002

Why induce Arabic morphology?
(1) Has not been done before(2) If it can be done, and if it has value in LM, it can generalize across languages without needing an expert

Original Algorithm(Schone & Jurafsky, ‘00/`01)
Looking for word inflections on words w/ Fr>9
Use a character tree to find word pairs with similar beginnings/ endings Ex: car/cars , car/cares, car/caring
Use Latent Semantic Analysis to induce semantic vectors for each word, then compare word-pair semantics
Use frequencies of word stems/rules to improve the initial semantic estimates

Trie-based approach could be a problem for Arabic: Templates => $aGlaB: { $aGlaB il$AGil $aGlu $AGil } Result: 3576 words in CallHome lexicon w/ 50+ relationships!
Algorithmic ExpansionsIR-Based Minimum Edit Distance
∙ $ A G i l
∙ 0 1 2 3 4 5
$ 1 0 1 2 3 4
a 2 1 2 3 4 5
G 3 2 3 2 3 4
l 4 3 4 3 4 3
a 5 4 5 4 5 4
B 6 5 6 5 6 5
Use Minimum Edit Distance to find the relationships (can be weighted)
Use information-retrieval based approach to faciliate search for MED candidates
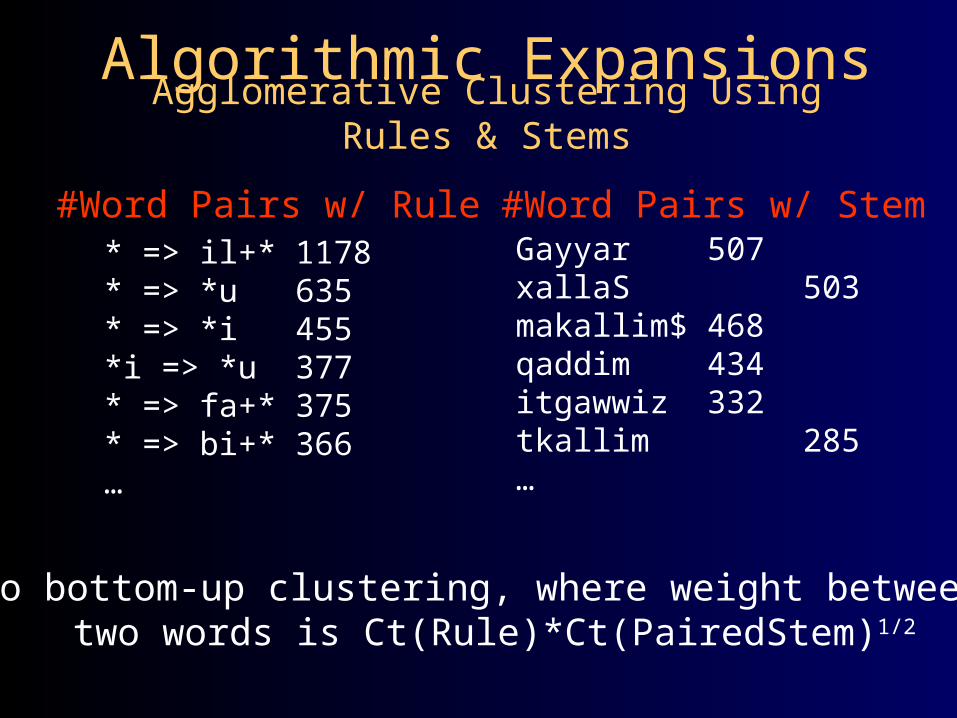
Algorithmic ExpansionsAgglomerative Clustering Using Rules &
Stems
#Word Pairs w/ Rule* => il+* 1178* => *u 635* => *i 455*i => *u 377* => fa+* 375* => bi+* 366…
Gayyar 507xallaS 503makallim$ 468qaddim 434itgawwiz 332tkallim 285…
#Word Pairs w/ Stem
Do bottom-up clustering, where weight betweentwo words is Ct(Rule)*Ct(PairedStem)1/2
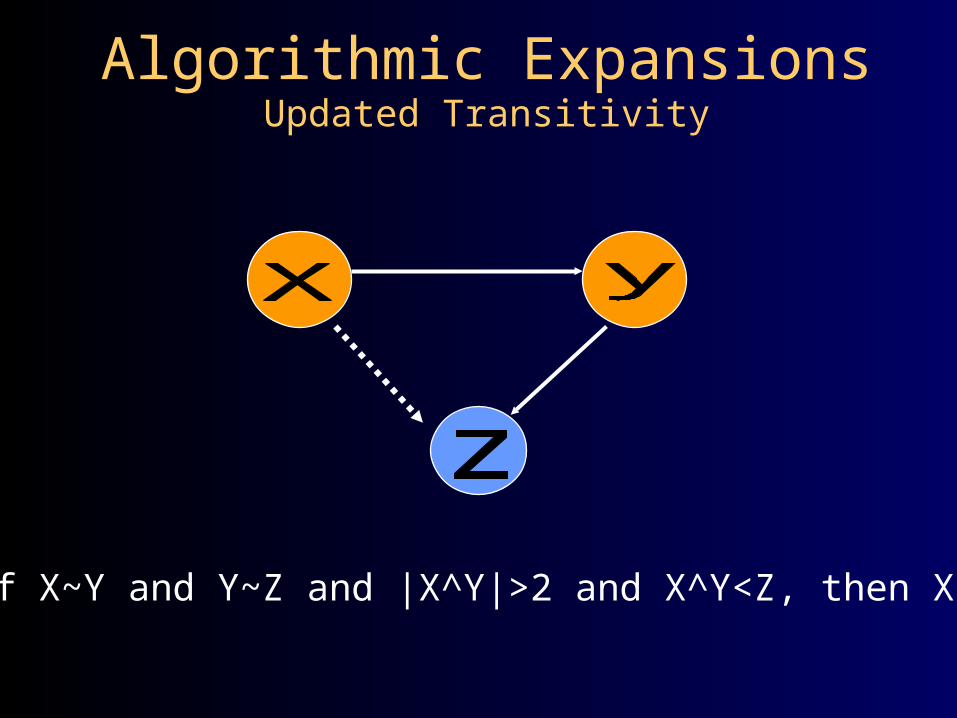
Algorithmic ExpansionsUpdated Transitivity
If X~Y and Y~Z and |X^Y|>2 and X^Y<Z, then X~Z
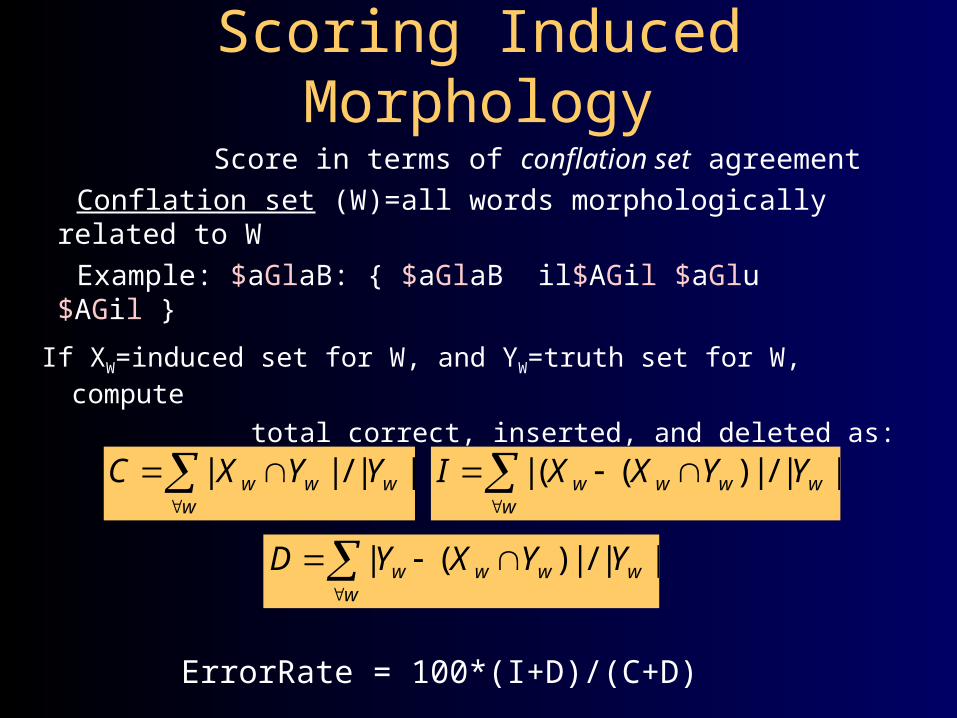
Scoring Induced Morphology
Score in terms of conflation set agreement Conflation set (W)=all words morphologically
related to W Example: $aGlaB: { $aGlaB il$AGil $aGlu $AGil }
||/|| ww
ww YYXC
||/|)((| ww
www YYXXI
||/|)(| ww
www YYXYD
ErrorRate = 100*(I+D)/(C+D)
If XW=induced set for W, and YW=truth set for W, compute
total correct, inserted, and deleted as:
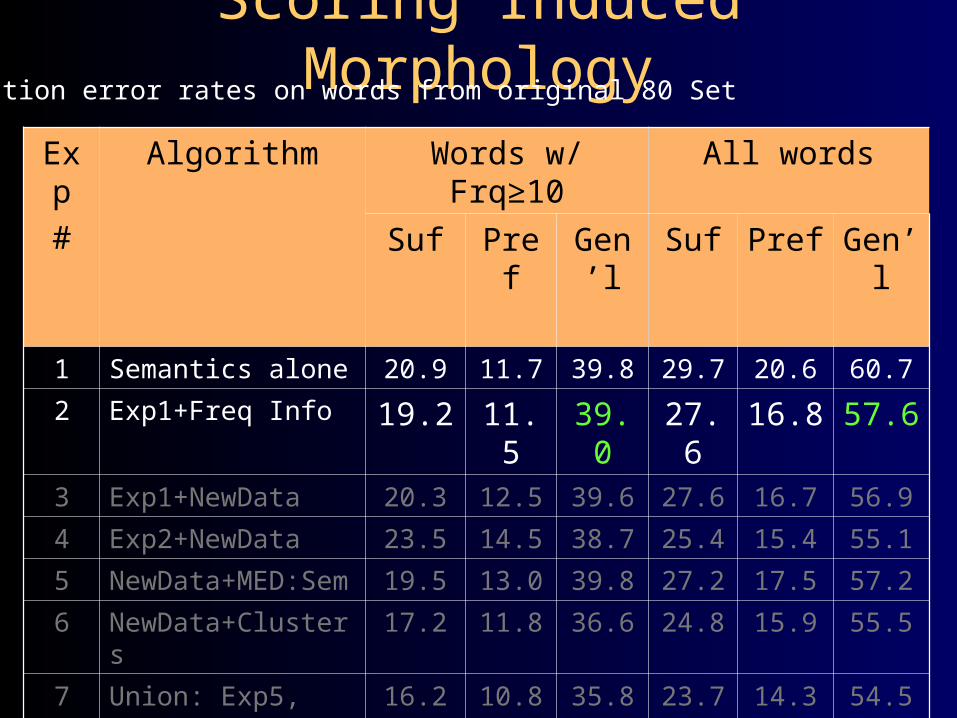
Scoring Induced Morphology
Exp#
Algorithm Words w/ Frq≥10
All words
Suf Pref Gen’l
Suf Pref Gen’l
1 Semantics alone 20.9 11.7 39.8 29.7 20.6 60.7
2 Exp1+Freq Info 19.2 11.5 39.0 27.6
16.8 57.6
3 Exp1+NewData 20.3 12.5 39.6 27.6 16.7 56.9
4 Exp2+NewData 23.5 14.5 38.7 25.4 15.4 55.1
5 NewData+MED:Sem
19.5 13.0 39.8 27.2 17.5 57.2
6 NewData+Clusters
17.2 11.8 36.6 24.8 15.9 55.5
7 Union: Exp5, Exp6 16.2 10.8 35.8 23.7 14.3 54.5
8 Union: Exp3, Exp6 17.5 10.6 35.9 24.2 13.9 54.2
9 Exp7 + NewTrans 14.9 8.4 33.9 22.4 12.3 53.1
10 Exp8 + NewTrans 16.4 8.4 33.6 23.3
12.3 52.7
Induction error rates on words from original 80 Set

Using Morphology for LM Rescoring
System Word Error Rate
Baseline: L1+L2 only 54.5%
Baseline + Root 54.3%
Baseline + Stem 54.6%
Baseline + Class 54.4%
Baseline + Root+Class 54.4%
For each word W, use induced morphology to generate
• Stem =smallest word, z, from XW where z< w
• Root =character intersection across XW
• Rule =map of word-to-stem• Pattern=map of stem-to-root• Class = map of word-to-root

Other Potential Benefits of Morphology:
Morphology-driven Word Generation• Generate probability-weighted “words” using
morphologically-derived rules (like Null => il+NULL)• Generate only if initial and final n-characters of
stem have been seen before.
Numberpropose
d
Coverage Observed
as words
Rule only 993398 41.3% 0.1%
Rule+1-char stem agree
98864 25.0% 1.1%
Rule+2-char stem agree
35092 14.9% 1.8%


Text Selection for Conversational Arabic
Feng HeASR (Arabic Speech Recognition) Team
JHU Workshop

Motivation• Group goal: Conversational Arabic
Speech Recognition.• One of the Problems: not enough
training data to build a Language Model – most available text is in MSA (Modern Standard Arabic) or a mixture of MSA and conversational Arabic.
• One Solution: Select from mixed text segments that are conversational, and use them in training.

– Use POS-based language models because it has been shown to better indicate differences in styles, such as formal vs conversational.
– Method:1.Training POS (part of speech) tagger on
available data2.Train POS-based language models on
formal vs conversational data3.Tag new data4.Select segments from new data that are
closest to conversational model by using scores from POS-based language models.
Task: Text Selection

• For building the Tagger and Language Models– Arabic Treebank: 130K words of hand-
tagged Newspaper text in MSA.– Arabic CallHome: 150K words of
transcribed phone conversations. Tags are only in the Lexicon.
• For Text Selection– Al Jazeera: 9M words of transcribed TV
broadcasts. We want to select segments that are closer to conversational Arabic, such as talk-shows and interviews.
Data

Implementation
• Model (bigram):
)(
)()|(maxarg)|(maxarg*
WP
TPTWPWTPT
TT
1it it
iw
iiiii
iiiii
ttPtwP
ttPtwPTPTWP
)|()|(
)|()|()()|(
1
1:0

• These are words that are not seen in training data, but appear in test data.
• Assume unknown words behave like singletons (words that appear only once in training data).
• This is done by duplicating training data with singletons replaced by special token. Then train tagger on both the original and duplicate.
About unknown words:

Tools:GMTK (Graphical Model Toolkit)
Algorithms:Training: EM training – set parameters so that joint probability of hidden states and observations is maximized.
Decoding (tagging): Viterbi – find hidden state sequence that maximizes joint probability of hidden state and observations.

Experiments
Exp 1: Data: first 100K of English Penn Treebank. Trigram model. Sanity check.
Exp 2: Data: Arabic Treebank. Trigram model.Exp 3: Data: Arabic Treebank and CallHome. Trigram
model.The above three experiments all used 10 fold cross
validation, and are unsupervised.
Exp 4: Data: Arabic Treebank. Supervised trigram model.
Exp 5: Data: Arabic Treebank and Callhome. Partially supervised training using Treebank’s tagged data. Test on portion of treebank not used in training. Trigram model.

Results
Experiment Accuracy Accuracy of OOV
Baseline
1 – tri, en 92.7 37.9 79.3 – 95.5
2 – tri, ar, tb 79.5 19.3 75.9
3 – tri, ar, tb+ch
74.6 17.6 75.9
4 – tri, ar, tb, sup
90.9 56.5 90.0
5 – repeat 3 with partial supervision
83.4 43.6 90.0

Building Language Models and Text Selection
• Use existing scripts to build formal and conversational language models from tagged Arabic Treebank and CallHome data.
• Text selection: use log likelihood ratio
)()|(
)()|(log)( /1
/1
FPFSP
CPCSPSScore
i
i
Ni
Ni
i
Si: the ith sentence in data setC: coversational language modelF: formal language modelNi : length of Si

log
cou
nt
log likelihood ratio
perc
enta
ge
log likelihood ratio
Score Distribution

Assessment
• A subset of Al Jazeera equal in size to Arabic CallHome (150K words) is selected, and added to training data for speech recognition language model.
• No reduction in perplexity. • Possible reasons: Al Jazeera has no
conversational Arabic, or has only conversational Arabic of a very different style.

Text Selection Work Done at BBN
Rich SchwartzMohamed Noamany
Daben LiuNicolae Duta

Search for Dialect Text
• We have an insufficient amount of CH text for estimating a LM.
• Can we find additional data?• Many words are unique to dialect text.• Searched Internet for 20 common
dialect words.• Most of the data found were jokes or
chat rooms – very little data.

Search BN Text for Dialect Data
• Search BN text for the same 20 dialect words.
• Found less than CH data• Each occurrence was typically an
isolated lapse by the speaker into dialect, followed quickly by a recovery to MSA for the rest of the sentence.

Combine MSA text with CallHome
• Estimate separate models for MSA text (300M words) and CH text (150K words).
• Use SRI toolkit to determine single optimal weight for the combination, using deleted interpolation (EM)– Optimal weight for MSA text was 0.03
• Insignificant reduction in perplexity and WER

Classes from BN
Hypothesis:• Even if MSA ngrams are different, perhaps the
classes are the same.Experiment:• Determine classes (using SRI toolkit) from
BN+CH data.• Use CH data to estimate ngrams of classes
and / or p(w | class)• Combine resulting model with CH word trigramResult:• No gain

Hypothesis Test Constrained Back-Off
Hypothesis:• In combining BN and CH, if a probability is
different, could be for 2 reasons:– CH has insufficient training– BN and CH truly have different probabilities (likely)
Algorithm:• Interpolate BN and CH, but limit the probability
change to be as much as would be likely due to insufficient training.
• Ngram count cannot change by more than its sqrt
Result:• No gain


Learning & Using Factored Language
ModelsGang Ji
Speech, Signal, and Language InterpretationUniversity of Washington
August 21, 2002

Outline
• Factored Language Models (FLMs) overview
• Part I: automatically finding FLM structure
• Part II: first-pass decoding in ASR with FLMs using graphical models

Factored Language Models
• Along with words, consider factors as components of the language model
• Factors can be words, stems, morphs, patterns, roots, which might contain complementary information about language
• FLMs also provide a new possibilities for designing LMs (e.g., multiple back-off paths)
• Problem: We don’t know the best model, and space is huge!!!

Factored Language Models
• How to learn FLMs– Solution 1: do it by hand using
expert linguistic knowledge– Solution 2: data driven; let the
data help to decide the model– Solution 3: combine both linguistic
and data driven techniques

Factored Language Models
• A Proposed Solution:– Learn FLMs using evolution-inspired
search algorithm
• Idea: Survival of the fittest– A collection (generation) of models– In each generation, only good ones
survive– The survivors produce the next
generation

Evolution-Inspired Search
• Selection: choose the good LMs• Combination: retain useful characteristics• Mutation: some small change in next generation

Evolution-Inspired Search
• Advantages– Can quickly find a good model– Retain goodness of the previous generation
while covering significant portion of the search space
– Can run in parallel
• How to judge the quality of each model?– Perplexity on a development set– Rescore WER on development set– Complexity-penalized perplexity

Evolution-Inspired Search
• Three steps form new models.– Selection (based on perplexity, etc)
• E.g. Stochastic universal sampling: models are selected in proportion to their “fitness”
– Combination– Mutation

Moving from One Generation to Next
• Combination Strategies– Inherit structures horizontally– Inherit structures vertically– Random selection
• Mutation– Add/remove edges randomly– Change back-off/smoothing strategies

Combination according to Frames
t1t 2t t1t 2t t1t 2t
t1t 2t
1F
2F
3F
1F
2F
3F

Combination according to Factors
t1t 2t t1t 2t t1t 2t
1F
2F
3F
t1t 2t
1F
2F
3F

Outline
• Factored Language Models (FLMs) overview
• Part I: automatically finding FLM structure
• Part II: first-pass decoding with FLMs

Problem• May be difficult to improve WER just by
rescoring n-best lists• More gains can be expected from using
better models in first-pass decoding• Solution:
1. do first-pass decoding using FLMs2. Since FLMs can be viewed as graphical models,
use GMTK (most existing tools don’t support general graph-based models)
3. To speed up inference, use generalized graphical-model-based lattices.
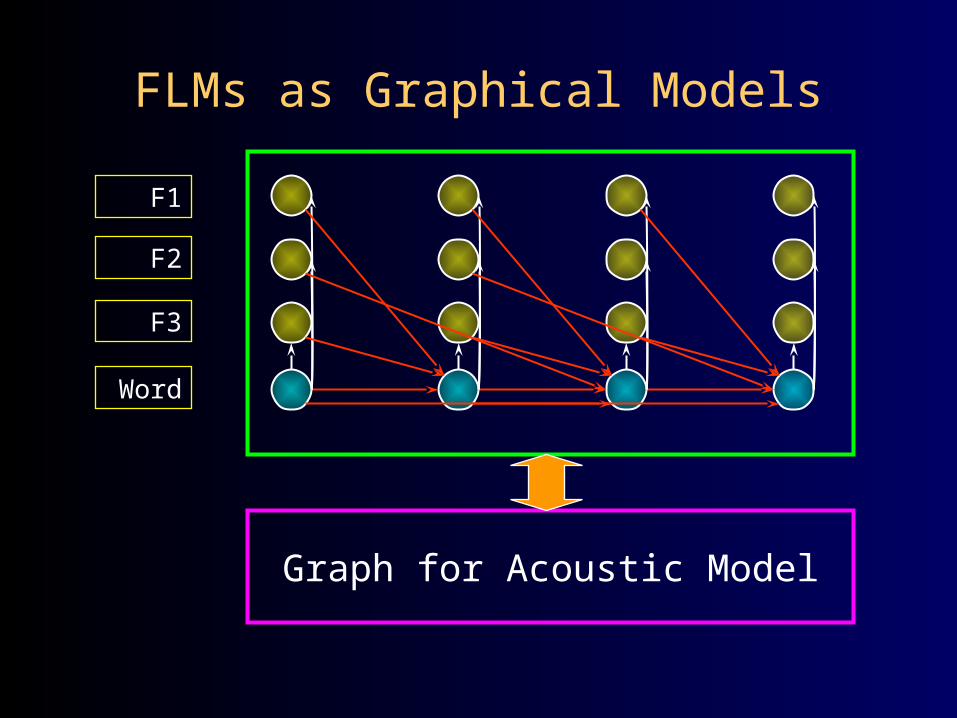
F1
F2
F3
Word
Graph for Acoustic Model
FLMs as Graphical Models

FLMs as Graphical Models
• Problem: decoding can be expensive!• Solution: multi-pass graphical lattice
refinement– In first-pass, generate graphical lattices
using a simple model (i.e., more independencies)
– Rescore the lattices using a more complicated model (fewer independencies) but on much smaller search space
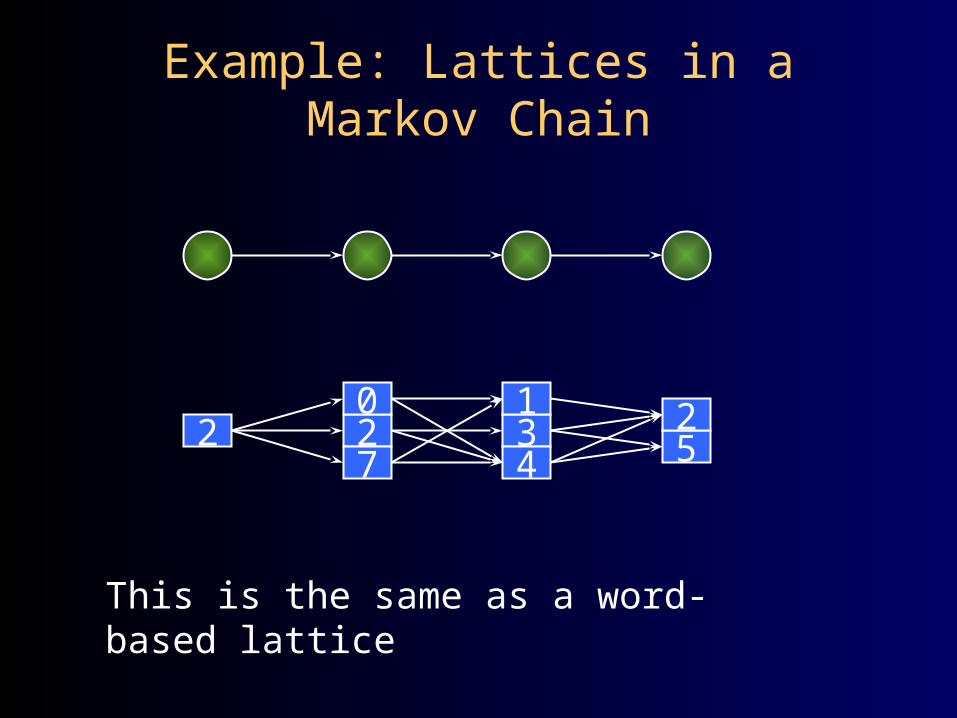
Example: Lattices in a Markov Chain
227
034
152
This is the same as a word-based lattice
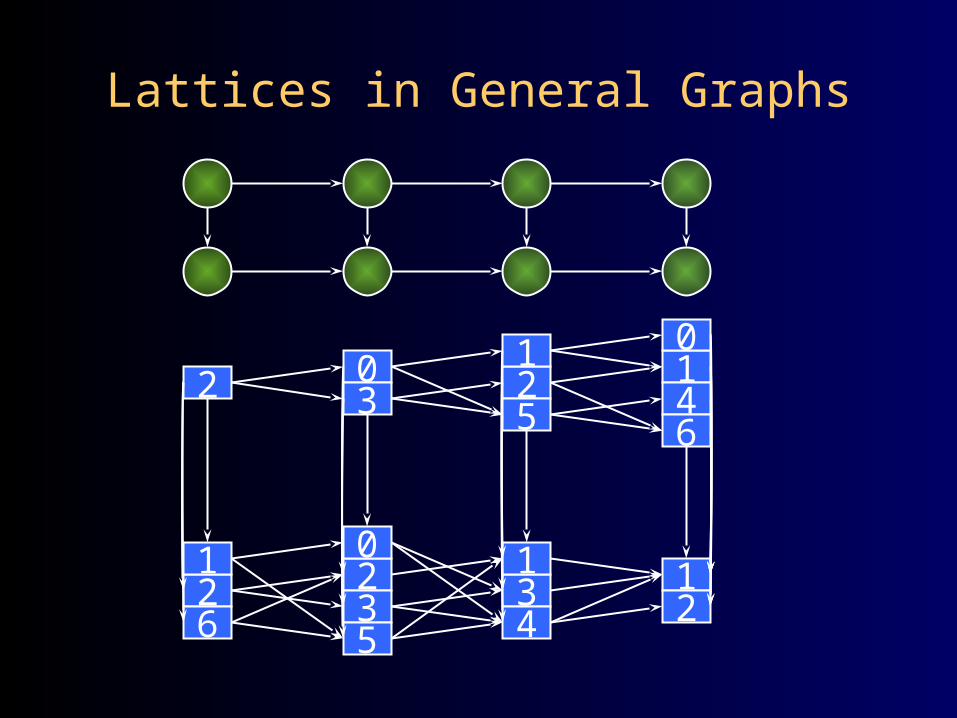
Lattices in General Graphs
2 03
26
1 23
0
5
25
1
34
1
14
0
6
12

Research Plan• Data
– Arabic CallHome data• Tools
– Tools for evolution-inspired search• most part already developed during workshop
– Training/Rescoring FLMs• Modified SRI LM toolkit: developed during this
workshop
– Multi-pass decoding• Graphical models toolkit (GMTK): developed in
last workshop

Summary
• Factored Language Models (FLMs) overview
• Part I: automatically finding FLM structure
• Part II: first-pass decoding of FLMs using GMTK and graphical lattices


Minimum Divergence Adaptation of a MSA-Based
Language Model to Egyptian Arabic
A proposal bySourin Das
JHU Workshop Final PresentationAugust 21, 2002

Motivation for LM Adaptation
• Transcripts of spoken Arabic are expensive to obtain; MSA text is relatively inexpensive (AFP newswire, ELRA arabic data, Al jazeera …)– MSA text ought to help; after all it is Arabic
• However there are considerable dialectal differences– Inferences drawn from Callhome knowledge or data ought
to overrule those from MSA whenever the inferences drawn from them disagree: e.g. estimates of N-gram probabilities
– Cannot interpolate models or merge data naïvely– Need to instead fall back to MSA knowledge only when the
Callhome model or data is “agnostic” about an inference

Motivation for LM Adaptation
• The minimum K-L divergence framework provides a mechanism to achieve this effect– First estimate a language model Q* from MSA text
only– Then find a model P* which matches all major
Callhome statistics and is close to Q*.
• Anecdotal evidence: MDI methods successfully used to adapt models based on NABN text to SWBD: a 2% WER reduction in LM95 from a 50% baseline WER.

An Information Geometric View
Models satisfyingMSA-text marginals
Models satisfyingCallhome marginals
The Uniform Distribution
MaxEnt Callhome LM
Min Divergence Callhome LMMaxEnt MSA-text LM
The Space of all Language Models

A Parametric View of MaxEnt Models
• The MSA-text based MaxEnt LM is the ML estimate among exponential models of the form
Q(x) = Z-1(,) exp[ i fi(x) + j gj(x)]
• The Callhome based MaxEnt LM is the ML estimate among exponential models of the form
P(x) = Z-1(,) exp[ j gj(x) + k hk(x)]
• Think of the Callhome LM as being from the familyP(x) = Z-1(,) exp[ i fi(x) + j gj(x) + k hk(x)]
where we set =0 based on the MaxEnt principle.
• One could also be agnostic about the values of i’s, since no examples with fi(x)>0 are seen in Callhome– Features (e.g. N-grams) from MSA-text which are not seen in Callhome
always have fi(x)=0 in Callhome training data

A Pictorial “Interpretation” of the Minimum Divergence Model
All exponential models of the formP(x)=Z-1(,,) exp[ i fi(x) + j gj(x) + k hk(x)]
Subset of all exponential models with =0Q(x)=Z-1(,) exp[ i fi(x) + j gj(x)]
The ML model for MSA textQ*(x)=Z-1(,) exp[ i*fi(x) + j*gj(x)]
The ML model for Callhome, with =* instead of =0.P*(x)=Z-1(,,) exp[ i*fi(x) + j**gj(x) + k*hk(x)]
Subset of all exponential models with =*P(x)=Z-1(,,) exp[ i*fi(x) + j gj(x) + k hk(x)]

Details of Proposed Research (1):
A Factored LM for MSA text• Notation W=romanized word, =script, S=stem, R=root, M=tag
Q(i|i-1,i-2) = Q(i|i-1,i-2,Si-1,Si-2,Mi-1,Mi-2,Ri-1,Ri-2)
• Examine all 8C2 = 28 all trigram “templates” of two variables
from the history with i.
– Set observations w/counts above a threshold as features
• Examine all 8C1 = 8 all bigram “templates” of one variable from
the history with i.
– Set observations w/counts above a threshold as features
• Build a MaxEnt model (Use Jun Wu’s toolkit)Q(i|i-1,i-2)=Z-1(,) exp[ 1f1(i,i-1,Si-2)+2f2(i,Mi-1,Mi-2) …
+ifi(i,i-1)+…+jgj(i,Ri-1)+…+JgJ(i)]
• Build the Romanized language modelQ(Wi|Wi-1,Wi-2) = U(Wi|i) Q(i|i-1,i-2)

A Pictorial “Interpretation” of the Minimum Divergence Model
All exponential models of the formP(x)=Z-1(,,) exp[ i fi(x) + j gj(x) + k hk(x)]
The ML model for MSA textQ*(x)=Z-1(,) exp[ i*fi(x) + j*gj(x)]
The ML model for Callhome, with =* instead of =0.P*(x)=Z-1(,,) exp[ i*fi(x) + j**gj(x) + k*hk(x)]

Details of Proposed Research (2):
Additional Factors in Callhome LMP(Wi|Wi-1,Wi-2) = P(Wi,i| Wi-1,Wi-2,i-1,i-2,Si-1,Si-2,Mi-1,Mi-2,Ri-1,Ri-2)
• Examine all 10C2 = 45 all trigram “templates” of two variables from the history with W or .– Set observations w/counts above a threshold as features
• Examine all 10C1 = 10 all bigram “templates” of one variable from the history with W or .– Set observations w/counts above a threshold as features
• Compute a Min Divergence model of the form
P(Wi|Wi-1,Wi-2)=Z-1(,, ) exp[ 1f1(i,i-1,Si-2)+2f2(i,Mi-1,Mi-2)+…
+ifi(i,i-1 )+…+jgj(i,Ri-1)+…
+JgJ(i)]
exp[1h1(Wi,Wi-1,Si-2)+ 2h2(i,Wi-1,Si-2) +…
+ khi(i,i-1)+…+ KhK(Wi)]

Research Plan and Conclusion
• Use baseline Callhome results from WS02– Investigate treating romanized forms of a script
form as alternate pronunciations
• Build the MSA-text MaxEnt model– Feature selection is not critical; use high cutoffs
• Choose features for the Callhome model• Build and test the minimum divergence
model– Plug in induced structure – Experiment with subsets of MSA text

A Pictorial “Interpretation” of the Minimum Divergence Model
All exponential models of the formP(x)=Z-1(,,) exp[ i fi(x) + j gj(x) + k hk(x)]
The ML model for MSA textQ*(x)=Z-1(,) exp[ i*fi(x) + j*gj(x)]
The ML model for Callhome, with =* instead of =0.P*(x)=Z-1(,,) exp[ i*fi(x) + j**gj(x) + k*hk(x)]

Related Documents








![Recognition of Handwritten Arabic Literal Amounts Using a ... · used in speech recognition techniques, have been suc-cessfully used for the recognition of handwritten words [2, 3].](https://static.cupdf.com/doc/110x72/5f71963d7e63fb10a012743e/recognition-of-handwritten-arabic-literal-amounts-using-a-used-in-speech-recognition.jpg)


