Métodos Quantitativos II Mestrado em Economia Aplicada Faculdade de Economia e Administração Prof. Rogério Silva de Mattos ECONOMETRIA CLÁSSICA Notas de Aula

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Métodos Quantitativos II
Mestrado em Economia Aplicada Faculdade de Economia e Administração
Prof. Rogério Silva de Mattos
ECONOMETRIA CLÁSSICA
Notas de Aula

1. INTRODUÇÃO 1.1 OBJETIVOS
• Modelos econométricos • Mensuração • Verificação de teorias • Previsão
1.2 VISÕES DA ECONOMETRIA
• Escola Clássica • Escola Inglesa
1.3 VISÃO ESTATÍSTICA
• Modelo Populacional ↔ Modelo Gerador dos Dados

2. MODELO DE REGRESSÃO MÚLTIPLA 2.1 MODELO LINEAR GAUSSIANO (versão básica)
MGD: ikikii XbXbbY ε+++= L221
• Y → variável dependente; • kXX ,,2 K → variáveis independentes ou explicativas;
• j
ij X
YEb∂∂
=)( ou coeficiente de sensibilidade de Y em relação à Xj;
• kikii XbXbbYE L++= 221)( é a média de Y e representa um hiperplano que corta o espaço euclidiano Rk;
Hipóteses Básicas
1. Y é uma função linear de kXX ,,2 K ; 2. kXX ,,2 K são variáveis não-estocásticas; 3. Cada jX não é uma função linear das demais sX ,
;,,1, , ksjsj L=∀≠ ; 4. 0)( =iE ε ; 5. 2)( σε =iVar e ;0)( =jiE εε ;,1, , njiji L=∀≠ ; 6. ),0(~ 2σε Ni ⇒ )),((~ 2σii YENY .
Observações
• Modelo linear vem da área de planejamento de experimentos, daí a hipótese 2 que diz que cada Xj não é variável aleatória;
• Hipótese 3, implica que cada jX não é combinação linear das demais variáveis explicativas;
• Hipóteses 4, 5, e 6 dizem respeito ao termo de erro aleatório iε , que apresenta as seguintes características:
− média nula (hip. 4); − homocedástico, pois possui variância constante (hip. 5); − não autocorrelacionado com os demais jε (hip. 5); − distribuição normal (hip. 6), logo Yi também é normal com média
)( iYE e variância 2σ ;

2.2 REPRESENTAÇÃO MATRICIAL
• Assumindo n observações para Y, X2,...,Xk
MGD: ε+= XbY onde:
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
×
n
nY
YY M
1
1
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
×
knn
k
knXX
XXX
L
MOMM
L
2
121
1
1
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
×
k
kb
bb M
1
1
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
×
n
nε
εε M
1
1
• XbYE =)( .
Hipóteses Básicas Re-escritas
1. Vetor Y é função linear dos vetores colunas da matriz X; 2. X é uma matriz não-estocástica; 3. X possui posto completo igual a k; 4. 0=)(εE , onde 0 é um vetor n×1 de elementos nulos; 5. IEVar 2)()( σεεε =′= , onde I é uma matriz identidade n×n; 6. ),0(~ 2IMN σε ⇒ ),(~ 2IXbMNY σ ;
Observações
• As hipóteses correspondem às anteriores para a versão não-
matricial; • Hipótese 3 implica que cada coluna de X não é uma combinação
linear exata das k-1 colunas restantes; • Hipóteses 4-6 dizem respeito ao vetor de erros aleatórios ε ; • Hipótese 6 diz que vetor ε segue uma distribuição normal
multivariada com vetor de médias 0 e matriz de variância-covariância I2σ ;
• Hipótese 6 também diz que vetor Y segue uma distribuição normal multivariada com vetor de médias Xb e matriz de variância-covariância I2σ ;

2.3 ESTIMADOR DE MÍNIMOS QUADRADOS ORDINÁRIOS
Conceitos Modelo Amostral: ikikii XbXbbY εˆˆˆ
221 +++= L
Preditor Linear: kikii XbXbbY ˆˆˆˆ221 L++=
Resíduo: kikii
iii
XbXbbY
YYˆˆˆ
ˆˆ
221 −−−−=
−=
L
ε
Representação Matricial
Modelo Amostral: εˆ += bXY
Preditor Linear: bXY ˆˆ =
Resíduo: bXYYY ˆˆˆ −=−=ε
onde: ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=×
n
nY
YY
ˆ
ˆˆ
1
1M
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
=×
k
kb
bb
ˆ
ˆˆ
1
1M
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
×
n
nε
εε
ˆ
ˆˆ
1
1M
Problema: A partir de n observações amostrais, achar estimadores kbb ˆ,,1 K de boa qualidade para kbb ,,1 K ;
Solução: Minimizar a soma dos quadrados dos resíduos ∑=
n
ii
1
ε para b , ou
seja, minimizar εε ˆˆ′ para b . Assim, encontra-se o estimador de mínimos quadrados ordinários (EMQO):
YXXXb ′′= −1)(ˆ

Prova Como se tem de minimizar uma função de b , usa-se as regras de determinação de valores mínimos de funções diferenciáveis de várias variáveis. Ou seja, acha-se as derivadas parciais da função, iguala-se estas a zero e resolve-se o sistema resultante. Os passos são os seguintes:
1. XbXbYXbYY
XbXbYXbYXbYYbXYXbYbXYbXY′′+′′−′=
′′+−′′−′=−′′′−′=−′−=′
2
ˆ)ˆ()ˆ()ˆ()ˆ(ˆˆ εε
2. Condição de 1ª. Ordem: 0ˆ22ˆˆˆ
=′+′−=∂
′∂ bXXYXbεε
3. YXXXb ′′= −1)(ˆ ← EMQO para b.
4. Condição de 2ª. Ordem: 12
2
)(2)ˆ(ˆˆ −
×′=
∂
′∂kkXX
bεε → definida positiva*
* Como X tem posto k, segue que a matriz quadrada X’X de ordem k também apresenta posto k e, logo, é não singular. Sendo não singular, possui inversa. Além disso, X’X é definida positiva ( 0 ,0 ≠∀>′′ zXzXz ; veja-se, por exemplo, JD, 1988: p. 484).
Logo, b é ponto de mínimo absoluto para εε ˆˆ′ .
Exemplo: Vendas trimestrais de automóveis nos EUA (1959.I-1988.I). MGD: ttttt CPIbRbYPbbS ε++++= 4321 onde:
• S = consumo pessoal de automóveis novos em US$ bilhões; • YP = renda pessoal em US$ bilhões; • R = taxa de juros trimestral (de título do Tesouro Americano); • CPI = índice de preços ao consumidor para novos carros (1983=100) Modelo Empírico: tttt CPIRYPS 654,0586,10391,07,35ˆ −++=

2.4 MÉDIA E VARIÂNCIA DOS EMQO
Resultado (R1): εXXXbb ′′=− −1)(ˆ
• Prova:
εε XXXbXbXXXYXXXb ′′+=+′′=′′= −−− 111 )()()()(ˆ . Do que segue que εXXXbb ′′=− −1)(ˆ .
Média
• [ ] 0)()()()ˆ()ˆ( 11 =′′=′′=−= −− εε EXXXXXXEbbEbViés ; • bbE =)ˆ( .
Variância
R2: 12 )()ˆ( −′= XXbVar σ • Prova
12
121
11
11
)()()()()()()(])()[()ˆ(
−
−−
−−
−−
′=
′′′=
′′′′=
′′′′=
XXXXXIXXXXXXEXXX
XXXXXXEbVar
σ
σ
εε
εε

2.5 PROPRIEDADES DOS EMQO Eficiência
• Eficiência Restrita: dadas as hipóteses 1-5, o EMQO é o mais eficiente (não enviesado e com variância mínima) dentro da classe dos estimadores lineares de b; ou seja, o EMQO é o Melhor Estimador Linear Não Enviesado (MELNE) de b.
Nota: Um estimador linear é aquele que pode ser escrito como MYb =
~, onde M é
uma matriz k×n. Prova (Teorema de Gauss Markov):
A prova só usa hipóteses 1-5. Sejam XXXA ′′= −1)( e C matrizes, ambas de ordem n×k. Por R1, εAbb =−ˆ , e por R2, AAbVar ′= 2)ˆ( σ . Seja também YCAb )(~
+= um estimador linear alternativo de b. Então, pode-se escrever εε )()())((~ CAXbCAXbCAb +++=++= . Para b~ ser não enviesado, ele tem de satisfazer:
bbCXICXbbCXbAXbbE =+=+=+= )()~( .
Logo, é preciso que 0=CX . Supondo 0=CX , então ε)()~( CAbb +=− de modo que ])~)(~[()~( ′−−= bbbbEbVar pode ser desenvolvida como:
))(())(()(])'()[()~(
2 ′++=
+′+=+′+=
CACACAECACACAEbVar
σ
εεεε
Mas,
CCXXCCCXXXXXCXXX
CCCAACAACACA
′+′=
′+′′′+′+′=
′+′+′+′=′++
−
−−−
1
111
)()()()(
))((
Pois 0== ''CXCX . Então:
CCbVarCCXXbVar ′+=′+′= − 212 )ˆ(])[()~( σσ
Nota: Resultados de álgebra matricial garantem que CC ′ é semidefinida positiva. Será 0=′CC somente quando C = 0. Mas, neste caso bb ˆ~
= ; logo, não pode haver outro estimador linear, diferente do EMQO, que seja mais eficiente (não-enviesado e com variância mínima).

• Eficiência Irrestrita: Quando vale também a hipótese 6 (erros
normalmente distribuídos), o EMQO é o mais eficiente dentre todos os estimadores (lineares e não-lineares). A prova envolve mostrar que no caso de normalidade dos erros o EMQO é equivalente ao Estimador de Máxima Verossimilhança (EMV).
Consistência
• EMQO é consistente para b, ou seja, bbp =)ˆlim( ; Prova: Dadas as hipóteses 1-5 e R1, segue que:
⎟⎠⎞
⎜⎝⎛ ′
⎟⎠⎞
⎜⎝⎛+=
⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ ′
⎟⎠⎞
⎜⎝⎛ ′
+=
′′+=
′′+=
−
−
−
−
nXp
nXXb
nX
nXXpb
XXXpbXXXbpbp
ε
ε
ε
ε
lim'
lim
])lim[())(lim()ˆlim(
1
1
1
1
Dado que X é não estocástica (hip. 2), segue que:
1)()(lim
×=′=′=⎟
⎠⎞
⎜⎝⎛ ′
kEXXE
nXp 0εεε
Logo:
bbp =)ˆlim(
Normalidade Assintótica (Propriedade MUITO IMPORTANTE!)
• Quando n → ∞, )1,0(/)ˆ( ˆ Nbbjbj →− σ ;
• Ou seja, em amostras grandes, podemos aproximar a distribuição de jb como uma normal, isto é: para n grande, ),(~ˆ 2
ˆjbjj bNb σ ; • Logo, se a amostra é grande, não precisamos da hipótese 6.
Qualquer que seja a distribuição de iε , podemos aplicar a teoria da normal para o EMQO e os procedimentos de testes de hipótese;

2.6 QUALIDADE DO AJUSTAMENTO • Como avaliar se o modelo está aderindo bem aos dados ou não? • Estatísticas descritivas: 2R , 2R , Critério de Informação de Akaike (AIC)
e Critério de Schwarz (SC)
2R
• Mede o grau de ajustamento do modelo aos dados;
YYi − = ii YY ˆ− + YYi −ˆ Desvio Total
Desvio Não-explicado
Desvio Explicado
• Elevando ao quadrado e agregando para todas as observações:
∑=
−n
ii YY
1
2)(
= ∑=
−n
iii YY
1
2)ˆ(
+ ∑=
−n
ii YY
1
2)ˆ(
Variação Total
Variação Não-
explicada
Variação Explicada
• Matricialmente: yyyy ˆˆˆˆ ′+′=′ εε
onde: YYy
n−=
×1 YYy
n−=
×
ˆˆ1
YYn
ˆˆ1
−=×ε
• Grau de ajustamento
yyyyR′′
=ˆˆ2 ou
yyR
′′
−=εε12
Propriedades
• ]1,0[2 ∈R ; • Bom ajustamento → 12 ≈R ; Fraco ajustamento → 02 ≈R ; • 2R tende a aumentar sempre com novas variáveis explicativas; • 2R nunca diminui com novas variáveis explicativas

2R ou 2R - ajustado
• Corrige limitação do grau de ajustamento 2R
)()1(ˆ
12
knn
yyR
−−
′′
−=εε
Propriedades
• 22 RR = se k = 1; • 22 RR < se k > 1; • 2R pode diminuir se incluo variáveis pouco explicativas; • 2R pode ser negativo;
Critério de Informação de Akaike – AIC
nk
nAIC 2ˆˆ
log +⎟⎠⎞
⎜⎝⎛ ′
=εε
Propriedades
• ∞<<∞− AIC ; • Quanto menor AIC, melhor o ajustamento; • AIC penaliza bem mais que o 2R a presença de variáveis
irrelevantes; • AIC valoriza mais a parcimônia.
Critério de Schwarz – SC
nnk
nSC logˆˆ
log +⎟⎠⎞
⎜⎝⎛ ′
=εε
Propriedades
• ∞<<∞− SC ; • Quanto menor SC, melhor o ajustamento; • SC penaliza bem mais que o 2R a presença de variáveis irrelevantes; • SC também valoriza mais a parcimônia.

2.7 VARIÂNCIA RESIDUAL DA REGRESSÃO
• )(2
iVar εσ = também é um parâmetro desconhecido do MGD; • Caminho natural de estimá-lo seria:
nn
n
ii εεε
σˆˆ
ˆˆ 1
2
2 ′==
∑=
• Problema: 2σ é um estimador enviesado de 2σ ; • Solução: usa-se um corretor de viés que redunda em:
knknS
n
ii
−′
=−
=∑= εεε
ˆˆˆ
1
2
2
• S 2 é a chamada variância residual e será usada em vários contextos,
por exemplo, o R 2 - ajustado pode ser escrito como:
2
22 1
YSSR −= , onde:
n
YYS
n
ii
Y
∑=
−= 1
2
2)(
• S 2 também é usada para se estimar a matriz de variância-covariância
dos EMQO:
122ˆ )( −′= XXSSb

Exemplo: Consumo Anual Brasil 1960-2004
MGD: ttttt NEbIbGRbYbbCO ε+++++= 54321
Saída (Compactada) do Eviews Dependent Variable: CO Method: Least Squares Date: 06/24/05 Time: 11:01 Sample: 1960 2004 Included observations: 45
Variable Coefficient Std. Error
Constante 23372214 9915664.
Y 0.836903 0.031319 GR -0.789323 0.067470
I -0.737619 0.119547 NE -0.764959 0.105569
R-squared 0.994985 Mean dependent var 8.19E+08 Adjusted R-squared 0.994483 S.D. dependent var 3.28E+08 S.E. of regression 24391210 Akaike info criterion 36.96178 Sum squared resid 2.38E+16 Schwarz criterion 37.16252
Nota: Dados anuais referentes ao Brasil; CO = consumo das famílias; Y = renda disponível das famílias; GR = gastos do governo; I = investimento direto; NE = Exportações líquidas
Observações
• A coluna correspondente a “Std. Error” refere-se a:
( )2ˆ
1ˆ b
kb
Sdiags =×
• O modelo empírico é dado por:
tttt NEIGRYCO 765,0738,0789,0837,0214.372.23 −−−+=∧

2.8 RESULTADOS IMPORTANTES
• Supondo que valem todas as hipóteses, inclusive a 6, de normalidade dos erros ε:
R3. 22 ~/ˆˆ kn−′ χσεε ; R4. 222 ~/)( knSkn −− χσ ; R5. ),0(~)ˆ( 2
jjj VNbb σ− , onde jV é o j-ésimo elemento da diagonal de 1)( −′XX ;
R6. 22 /)( σSkn − e )ˆ( jj bb − são independentes;
R7. De R4-R6, segue que: knj
jj tVSbb
−
−~
)ˆ(
Prova: De R4, segue que )1,0(~/)ˆ( 2 NVbb jjj σ− . Agora computando:
2
2
)()()ˆ(σσ knSkn
Vbb
j
jj
−−−
,
temos uma VA N(0,1) dividida por uma VA 2
kn−χ , ambas independentes, o que resulta numa VA tn-k. Fazendo as simplificações necessárias, obtém-se o resultado R7.

2.9 ESTIMAÇÃO INTERVALAR
• Objetivo: achar intervalos de confiança para bj; • Em geral, usa-se intervalos bilaterais; • Critério: α−=≤≤ 1)ˆˆ( jHjL bbbP ;
Ljb ,
ˆ = limite inferior
Hjb ,ˆ = limite superior α−1 = nível de confiança
• Solução:
jbknjLj stbb ˆ,2/,ˆˆ
−−= α
jbknjHj stbb ˆ,2/,ˆˆ
−+= α
Prova: Defina jbVSs
j=ˆ . Então, usando R7, podemos escrever:
ααα −=⎟⎟
⎠
⎞
⎜⎜
⎝
⎛≤
−≤− −− 1
ˆ,2/
ˆ,2/ kn
b
jjkn t
sbb
tPj
( ) ααα −=≤−≤− −− 1ˆ
ˆ,2/ˆ,2/jj bknjjbkn stbbstP
Multipliando todos os componentes da tripla desigualdade por -1:
( ) ααα −=≤−≤− −− 1ˆˆ,2/ˆ,2/
jj bknjjbkn stbbstP
e somando jb aos três componentes:
( ) ααα −=+≤≤− −− 1ˆˆˆ,2/ˆ,2/
jj bknjjbknj stbbstbP

2.10 TESTES DE SIGNIFICÂNCIA DE PARÂMETROS E VARIÁVEIS
MGD: ikikii XbXbbY ε+++= L221
• Exemplos de hipóteses de interesse:
H0: b1 = 0 (E(Y) atravessa a origem do espaço Rk); H1: b1 ≠ 0 (E(Y) não atravessa a origem do espaço Rk); H0: b2 = 0 (variações em X2 não explicam variações em Y); H1: b2 ≠ 0 (variações em X2 explicam variações em Y); H0: b3 = 1 (variações em X3 produzem variações idênticas em Y); H1: b3 ≠ 1 (variações em X3 não produzem vars. idênticas em Y);
Conceitos e definições • α = nível de significância = P(Erro Tipo I) = P(Rejeitar H0|H0 é V); • β = P(Erro Tipo II) = P(Não Rejeitar H0|H0 é F); • Poder do teste = 1 - β; • Representação Geral H0: bj = b0j ; H1: bj ≠ b0j • Caso típico em econometria: b0j = 0; • Por R7, segue que knbj tSbb
j−− ~)ˆ( ˆ,0 ou knb
tSbj
−~ˆˆ (caso b0j= 0);
Procedimentos do teste t
1. Enunciado das hipóteses H0 e H1; 2. Escolha de α = nível de significância;
3. Cálculo de j
jb
jb S
bt
ˆˆ
ˆ=
4. Aplicação da regra de decisão pelo valor de prova (p-value):
Se α≥≥ ) || ( ˆjb
tTP → Não rejeito H0;
Se α<≥ ) || ( ˆjb
tTP → Rejeito H0;

Exemplo: Consumo Anual Brasil 1960-2004
MGD: ttttt NEbIbGRbYbbCO ε+++++= 54321
Saída (Compactada) do EViews Dependent Variable: CO Method: Least Squares Date: 06/24/05 Time: 11:01 Sample: 1960 2004 Included observations: 45
Variable Coefficient Std. Error t-Statistic Prob.
C 23372214 9915664. 2.357100 0.0234 Y 0.836903 0.031319 26.72190 0.0000
GR -0.789323 0.067470 -11.69886 0.0000 I -0.737619 0.119547 -6.170097 0.0000
NE -0.764959 0.105569 -7.246070 0.0000
R-squared 0.994985 Mean dependent var 8.19E+08 Adjusted R-squared 0.994483 S.D. dependent var 3.28E+08 S.E. of regression 24391210 Akaike info criterion 36.96178 Sum squared resid 2.38E+16 Schwarz criterion 37.16252

2.12 TESTE F (SIGNIFICÂNCIA GERAL DA REGRESSÃO)
• H0: 032 ==== kbbb L (nenhuma Xj explica variações em Y); • H1: pelo menos um 0≠jb (pelo menos uma Xj explica variações em
Y); • j = 2...,k-1; • Suponha válidas as hipóteses 1 a 6 e considere H0 verdadeira:
R8. 2
12
****22
12 ~ˆˆˆˆ)ˆ( −=
′′=′=−∑ kn
ibxxbyyYY χσσσ , onde **
)1(* XXx
kn−=
−×
é a matriz X em forma de desvios em relação à média com a primeira coluna (referente à constante) excluída.
Prova: Ver [VA: pp. 59-60];
R9. knkFkn
kyy−−−′
−′,1~
)/(ˆˆ)1/(ˆˆ
εε
Prova
Combinando R3 com R8:
knkFSkyy
knSkn
kyy
−−−′
=−−
−′
,122
2
2 ~)1/(ˆˆ)()(
)1(ˆˆ
σσ
• Estatística de Teste:
)/( )1/(
)/(ˆˆ)1/(ˆˆ
knExplicadaNãoVariaçãokExplicadaVariação
knkyyF
−−
=−′−′
=εε
• Regra de decisão pelo valor de prova:
o Dado uma escolha de α:
Se α≥≥−− )( ,1 FFP knk → Não rejeito H0; Se α<≥−− )( ,1 FFP knk → Rejeito H0;

2.13 MULTICOLINEARIDADE
• Modelo com 1 var. dependente e 2 vars. independentes:
iiii XbXbbY ε+++= 33221
• É fácil verificar que o EMQO neste caso seria:
232
23
22
323232
2 )())(())(()(ˆ
iiii
iiiiiii
xxxxxxyxxyx
bΣ−ΣΣ
ΣΣ−ΣΣ=
232
23
22
322223
3 )())(())(()(ˆ
iiii
iiiiiii
xxxxxxyxxyx
bΣ−ΣΣ
ΣΣ−ΣΣ=
33221ˆˆˆ XbXbYb −−=
Colinearidade Perfeita
• Coeficiente de correlação linear entre X2 e X3:
1123
22
3223 ≤
ΣΣ
Σ=≤−
ii
ii
xx
xxr
• Se 32 XX λ= , com 0≠λ (violação da hipótese 2):
o Os numeradores de 2b e 3b são iguais a 0; o 12
23 =r ⇒ 0)())(( 232
23
22 =Σ−ΣΣ iiii xxxx
• Logo, com 00ˆˆ
32 == bb , é impossível computar os EMQO 321ˆ,ˆ,ˆ bbb .

Alta mas não perfeita colinearidade
• É possível computar EMQO, pois hip. 2 não é violada; • Sejam as variâncias estimadas dos EMQO, (obtidas como os 2
últimos elmentos da diagonal principal de 122ˆ )( −′= XXSSb
):
)1( 2232
22ˆ2 rx
SSi
b −Σ=
)1( 2233
22ˆ3 rx
SSi
b −Σ=
• Seja 12
23 <r , mas considere que:
1223 →r ⇒ ∞→
2bS e ∞→
3bS
• Logo:
1223 →r ⇒ 0
2ˆ →b
t e 03
ˆ →b
t Conseqüências da Multicolinearidade • Estatísticas t podem ficar artificialmente muito baixas; • Inclusive, é possível acontecer 12 ≈R com 0
2ˆ ≈b
t e 03
ˆ ≈b
t , o que é contraditório;
Soluções Alternativas
• Retira-se uma das variáveis do modelo; • Trabalha-se com variáveis em diferenças:
o Exemplo:
Modelo de interesse: tttt WbYbbC ε+++= 321 Se Yt e Wt muito correlacionadas, usa-se: )()()( 113121 −−−− −+−+−=− tttttttt WWbYYbCC εε

2.14 ESTIMAÇÃO POR MÁXIMA VEROSSIMILHANÇA (EMV)
• Pela hipótese 6: )),((~ 2σii YENY ;
• Função densidade:
⎥⎦
⎤⎢⎣
⎡ −−−−= 2
2221
2 2)(
exp2
1)(σπσ
kikiii
XbXbbYYf
K
• Função de verossimilhança:
⎥⎥⎦
⎤
⎢⎢⎣
⎡ −−−−⎟⎠⎞
⎜⎝⎛=
=
∑
∏
=
=
21
22212
2
1
21
2)(
exp2
1
)(),,,(
σπσ
σ
n
i kikii
n
n
iik
XbXbbY
YfbbL
K
K
• Em forma matricial:
⎥⎦⎤
⎢⎣⎡ −′−
⎟⎠⎞
⎜⎝⎛= 2
2
22
2)()(exp
21),(
σπσσ XbYXbYbL
n
• Log-verosssimilhança:
222
2ln
22ln
2),(
σσπσ XbXbYXbYXbYYnnb
′′+−′′−′+−−=l

Maximizando a log-verossimilhança
• Condição de 1ª. Ordem:
0)~22(2
12 =′+′−=
∂∂ bXXYXb σl ⇒ YXXXb ′′= −1)(~
0~2
~~~2 422 =
′−−=
∂∂
σεε
σσnl ⇒
nεεσ~~~ 2 ′
=
onde: bXY ~~ −=ε
• Condição de 2ª. Ordem: garante que o EVM de b e 2σ é máximo global (ver JD: p. 146).
• Logo, o EMV de b (b~ ) é o mesmo que o EMQO ( b ); e o EMV de 2σ ( 2~σ ) difere do usado antes para 2σ ( 2S ) apenas no denominador;
Propriedades do EMV para pequenas amostras
• b~ é não enviesado para b; • 2~σ é enviesado para 2σ ; • A variância de b~ atinge o limite mínimo de Cramer-Rao, logo b~ é
também eficiente; Propriedades do EMV para grandes amostras
• b~ e 2~σ são consistentes; • b~ apresenta normalidade assintótica;
Conclusão
• Sob hipótese 6 de normalidade dos erros, EMQO e EMV são equivalentes e portanto constituem o melhor estimador de b dentre os estimadores lineares e os não-lineares.

2.15 PREVISÃO
• Objetivo: acertar um valor de Y condicional a valores particulares de kXX ,,2 K ;
Previsão Pontual
• Seja ]1[ 2 kfff XXx L=′ , então:
bxXbXbbY fkfkffˆˆˆˆˆ
221 ′=+++= L
o Previsão dentro da amostra:
nibxYY
XXxx
iif
kiiif,,1 ˆˆˆ
]1[ 2K
L=
⎪⎭
⎪⎬⎫
′==
=′=′
o Previsão fora da amostra:
iobxYY
XXxx
f
kf≠
⎪⎭
⎪⎬⎫
′==
=′=′ ˆˆˆ
]1[
00
0200 L
• Pelo T. Gauss-Markov:
o b é o melhor estimador linear de b; o Logo, fY é um preditor ótimo de Yf;
• Erro de previsão: fff YYe ˆ−= ;
o Note que: )()ˆ()ˆ( ffff YEbxbExYE =′=′= ; o Logo: ;0)ˆ()()ˆ()( =−=−= fffff YEYEYYEeE o Ou seja fY é um previsor não enviesado de fY .

• Variância do erro de previsão: 2)( ffeVar σ=
])(1[
)()ˆ(
])ˆ)(ˆ([))ˆ(()(
))ˆ(()ˆ(
12
1222
2
2
ff
ffff
ffff
fffff
xXXx
xXXxxbVarx
xbbbbxEbbxVarVar
bbxVarYYVar
−
−
′′+=
′′′+=′+=
′−−′+=−′+=
−′−=−=
σ
σσσ
σε
εσ
• Estimação da Variância do erro de previsão:
))(1( 122fff xXXxSS −′′+=
Resultados de interesse • Sejam válidas hips. 1-6. Considere os seguintes resultados:
R10. );1,0(~)ˆ( NeYY fffff σσ −=− R11. 222 ~)( knffSkn −− χσ ; R12. fff YY σ)ˆ( − e 22)( ffSkn σ− são independentes;
R13. knf
ff tS
YY−
−~
ˆ
Prova
Por R10, R11 e R12, segue que a razão:
knf
f
f
f
f
ff tS
YYkn
SknYY−
−=
−
−−~
ˆ
)()(ˆ
2
2
σσ,
Fazendo-se as simplificações necessárias, temos o resultado R13.

Previsão Intervalar
• Objetivo: Achar intervalo de confiança para fY de acordo com o critério α−=≤≤ 1)ˆˆ( fHffL YYYP ;
• Solução:
fknffH
fknffL
StYY
StYY
−
−
+=
−=
,2/
,2/
ˆˆ
ˆˆ
α
α
Prova
Usando R13, verificamos que:
ααα −=≤−
≤− −− 1)ˆ
( ,2/,2/ knf
ffkn t
SYY
tP
De onde é imediato que, após manipulações algébricas simples:
ααα −=+≤≤− −− 1)ˆˆ( ,2/,2/ fknfffknf StYYStYP Isto é:
α−=≤≤ 1)ˆˆ( fHffL YYYP Exemplo: Previsão do Consumo Anual Brasil 2005-2010
Modelo Econométrico:
tttt NEIGRYCO 781,0606,0686,0789,0820.589.29 −−−+=∧
ANO CÔL CÔ CÔH Y G I NE
2005 1046 1087 1128 1848 157 364 94
2006 1073 1114 1155 1907 165 382 97
2007 1095 1136 1177 1958 173 401 99
2008 1114 1156 1197 2008 182 421 101
2009 1132 1174 1215 2055 191 442 102
2010 1148 1190 1233 2102 201 464 102
Nota: Valores em R$ bilhões

3. USOS E EXTENSÕES DO MODELO DE REGRESSÃO MÚLTIPLA 3.1 COEFICIENTES PADRONIZADOS • Os coeficientes do MGD linear não podem ser comparados entre si; • Suas magnitudes dependem da escala de medida das variáveis
explicativas; • Solução: modelo com variáveis normalizadas, isto é:
iX
kkik
X
i
Y
i
kS
XXb
SXX
bS
YYε+
−++
−=
−L
2
222
• Relação entre coeficientes originais e padronizados:
Y
Xjj S
Sbb j=* j = 2,...,k.
• Coeficientes padronizados são a-dimensionais, isto é, não possuem
uma unidade particular de medida; • A comparação entre coeficientes padronizados é possível porque
agora todas as variáveis apresentam a mesma média e variância; 3.2 ELASTICIDADES
• Muito usada em microeconomia, a elasticidade mede a variação relativa na variável dependente dada uma variação relativa numa variável independente (com as demais constantes);
)()()(
j
jij
i
ji
ji
ij YE
Xb
YEX
XYE
E =⋅∂∂
=
• No modelo linear, a elasticidade estimada é obtida como:
i
jijj Y
XbE ˆˆˆ =
• Elasticidades no ponto médio:
YX
bE jjj
ˆˆ ≈
• No caso do modelo log-log (todas as variáveis são medidas em
logaritmos), a elasticidade é constante para todo i = 1,...,n.

• 3.3 MODELOS NÃO-LINEARES
• Modelo Linear: ikikii XbXbbY ε+++= L221 • Modelo Não-Linear: qualquer modelo que não é linear.
),,,( 2 ikiii XXFY εK=
• Modelos não-lineares intrinsecamente lineares (MNLIL):
o São lineares nos parâmetros ou ; o Podem ser transformados em lineares nos parâmetros;
• Modelos não-lineares intrinsecamente não-lineares (MNLINL):
o não podem ser transformados em lineares nos parâmetros. Modelos intrinsecamente lineares
• Modelo polinomial: ikikiii XbXbXbbY ε+++= −12
321 L
• Modelo multiplicativo: *21
2i
bki
bi
kXXbY εK=
• Modelo log-log: ikikii XbXbbY ε+′++′+′= lnlnln 221 L o Note-se que o modelo log-log deriva do modelo
multiplicativo, porque:
11 ln bb =′ 22 bb =′ ⋅ ⋅ ⋅ kk bb =′ *ln ii εε =
• Modelo exponencial: ε)exp( 221 kikii XbXbbY +++= K
• Modelo log-lin: εlnln 221 ++++= kikii XbXbbY K
• Modelo recíproco: ikiki
i XbXbbY
ε++++=
L221
1
o Que pode ser transformado em:
ε++++= kikiI
XbXbbY
K2211
• Modelo lin-log: ikikii XbXbbY ε++++= lnln 221 L
• Modelo interativo: iiiiii XXbXbXbbY ε++++= )( 32433221

3.4 TESTE F PARA SIGNIFICÂNCIA DE BLOCOS DE VARIÁVEIS
• Considere o MGD: iiiiii XbXbXbXbbY ε+++++= 554433221 ;
• Teste de Hipótese: o H0: 054 == bb (X4 e X5 não são significativas);
o H1: 04 ≠b e/ou 05 ≠b (X4 e/ou X5 é/são significativa(s));
• Definições: o Modelo irrestrito (IR): iiiiii XbXbXbXbbY ε+++++= 554433221
o Modelo restrito(R): iiii XbXbbY ε+++= 33221
o SQT = Soma dos Quadrados Totais = ∑ ′=− yyYYi2)( ;
o SQE = Soma dos Quadrados Explicados: ∑ ′=− yyYYi ˆˆ)ˆ( 2 ;
o SQR = Soma dos Quadrados dos Resíduos: ∑ ′= εεε ˆˆˆ 2i ;
• Estatística de Teste:
IRRIR knkkIRIR
RIRRIR FknSQR
kkSQESQEF −−−
−−= ,~
)()/()(
• Regra de decisão pelo valor de prova:
o Dado uma escolha de α:
Se α≥≥−− )( , FFPIRRIR knkk → Não rejeito H0;
Se α<≥−− )( , FFPIRRIR knkk → Rejeito H0;

Exemplo: Modelo consumo vs renda e tendência quadrática
MGD: ε++++= 24321 tbtbYbbC tt
• H0: ;043 == bb (termo de tendência não é significativo)
• H1: 03 ≠b e/ou 04 ≠b (termo de tendência é significativo) Implementação do teste com α = 5%; • Usando-se n = 15 observações anuais, estimou-se:
• Modelo irrestrito: 2
)43,1()59,1()35,6()56,16(32,01,177,01,2ˆ ttYC tt +++=
o 10,965.65=IRSQE ;
o 17,77=IRSQR ;
o 4=IRk ;
• Modelo restrito: tt YC)49,7()31,17(
77,03,2ˆ +=
o 24,898.65=RSQE ;
o 2=Rk
• 765,4)415(17,77
)24/()24,6589810,65965(=
−−−
=F
• 0323,0)765,4( 11,2 =≥FP → Rejeitamos H0 a 5% de significância

Caso Geral do Teste F para bloco de variáveis
MGD: ikikii XbXbbY ε+++= L221
• Divida o conjunto X2,...,Xk em 2 grupos, sendo um deles formado
por q < k−1 variáveis a serem testadas;
• Agrupe as variáveis a serem testadas no final do MGD, re-escrevendo-o como segue:
ikikiqkqkiqkqkii XbXbXbXbbY ε+++++= +−+−−− LL ,11,221
H0: 01 ===+− kqk bb L ( kqk XX ,,1 K+− são não-significativas);
H1: pelo menos um 0≠sb (pelo menos uma Xs, s = k − q + 1,...,k, é significativa);
Escolha um valor para α; Estime os modelos irrestrito e restrito; Compute:
)()/()(
IRIR
RIRRIR
knSQRkkSQESQE
F−
−−= ;
Aplique a regra de decisão:
o Se α≥≥−− )( , FFPIRRIR knkk → Não rejeito H0;
o Se α<≥−− )( , FFPIRRIR knkk → Rejeito H0;
Nota: modernos softwares econométricos, como o Eviews, implementam automaticamente esse procedimento, sendo necessário informar apenas o grupo de q variáveis a serem testadas em bloco;

3.5 VARIÁVEIS DUMMY
Variáveis qualitativas: que refletem estado, situação, classe, etc., ou seja, eventos qualitativos que não podem ser medidos numericamente;
Variável dummy: variável binária (assume valor 0 ou 1) usada para representar, num modelo quantitativo/matemático como o MGD, as influências de eventos qualitativos;
Variáveis dummy podem ser usadas no papel de dependente ou independente num modelo econométrico. Veremos por ora só o caso de variáveis dummy independentes;
Regressão com uma variável dummy
MGD: iii DbbY ε++= 21
• Yi é uma variável quantitativa; • Di é uma variável dummy (qualitativa) que assume só valores 0 ou 1;
Exemplo: Estudo americano em escola secundária
n = 20 professores pesquisados; Yi = renda do i−ésimo professor; Di = sexo do i−ésimo professor (1 − homem; 0 − mulher); Interpretação do MGD:
1)0|( bDYE ii == é o salário médio/esperado de uma professora;
21)1|( bbDYE ii +== é o salário médio/esperado de um professor;
Modelo empírico: ii DY)7,2()15.3(
5,12,21ˆ +=
2,21ˆ)0(|ˆ1 === bDY ii ;
7,225,12,21ˆˆ)1(|ˆ21 =+=+== bbDY ii ;
Hipótese de interesse: H0: 02 =b (não há discriminação sexual);

Regressão com duas variáveis dummy
MGD: iRiSii DbDbbY ε+++= 321
Exemplo: Estudo americano em escola secundária (continuação)
n = 20 professores pesquisados; Yi = renda do i−ésimo professor; DSi = sexo do i−ésimo professor (1 − homem; 0 − mulher); DRi = raça do i−ésimo professor (1 − branco(a) ; 0 − negro(a));
Sexo\Raça Branco (B) Negro (N)
Homem (H) DS = DR = 1 DS=1, DR = 0
Mulher(M) DS = 0, DR = 1 DS = DR =0
• Interpretação do MGD: o 1)0|( bDDYE RiSii === : sal. médio/esperado da M.N.; o 21)0,1|( bbDDYE RiSii +=== : sal. médio/esperado do H.N.; o 31)1,0|( bbDDYE RiSii +=== : sal. médio/esperado de uma M.B.; o 321)1|( bbbDDYE RiSii ++=== : sal. médio/esperado do H.B.;
• Modelo empírico: RiSii DDY)01,1()14,3()74,3(
74,003,12,19ˆ ++=
o 2,19)0(|ˆ === RiSii DDY ;
o 23,2003,12,19)0,1(|ˆ =+=== RiSii DDY ;
o 94,1974,02,19)1,0(|ˆ =+=== RiSii DDY ;
o 97,2074,003,12,19)1(|ˆ =++=== RiSii DDY ; Nota: a rigor, não se somaria o coeficiente estimado 74,0ˆ
3 =b porque ele se mostrou diferente de zero a 5% de significância. Apenas para fins ilustrativos é que o incluímos; • Hipóteses de interesse:
o H0: 02 =b (não há discriminação sexual); o H0: 03 =b (não há discriminação racial); o H0: 032 == bb (não há discriminação de qualquer tipo);

Regressão com 1 variável dummy e 1 variável quantitativa
MGD: iiii XbDbbY ε+++= 321
Exemplo: Estudo americano em escola secundária (continuação)
n = 20 professores pesquisados; Yi = renda do i−ésimo professor; Di = sexo do i−ésimo professor (1 − homem; 0 − mulher); Xi = número de anos de serviço do i-ésimo professor. • Interpretação do MGD:
o iiii XbbXDYE 31),0|( +== : salário médio/esperado da professora como função do número de anos de serviço.;
o iiii XbbbXDYE 321 )(),1|( ++== : salário médio/esperado do professor como função do número de anos de serviço;
• Modelo empírico: iii XDY
)15,3()77,2()19,3(53,012,15,19ˆ ++=
o iiii XXDY 53,05,19),0(|ˆ +== ;
o iiii XXDY 53,067,20),1(|ˆ +== ;
• Hipótese de interesse: o H0: 02 =b (não há diferença, entre homens e mulheres, na
relação entre salário recebido e anos de serviço );

Variáveis dummy sazonais
MGD1: ttssttt DbDbDbaY ε+++++= −− ,112211 K
1,...,1 outro
01
−=⎩⎨⎧ =
= sjjt
D jt
• s = comprimento do período sazonal: s = 2 (semestral) s = 6 (bimestral) s = 3 (quadrimestral) s = 12 (mensal) s = 4 (trimestral)
• bj = fator sazonal do j−ésimo mês, bimestre, etc. (j = 1,...,s−1);
• usa−se só s-1 dummies p/evitar colinearidade perfeita c/a constante; Normalização dos fatores sazonais
MGD2: ⎪⎩
⎪⎨⎧
=
+++++=
∑ =0
1
2211
s
j j
tststtt
b
DbDbDbaY εK
• Verifica−se que este modelo pode ser re−escrito como:
MGD2: ttssttt DbDbDbaY ε+++++= −−*
,11*12
*11 K
o Onde: 1,...,1 outro
01
1* −
⎪⎩
⎪⎨
⎧=
⎪⎭
⎪⎬
⎫==
−= sjstjt
D jt
Exemplo: Sazonalidade trimestral (s=4); MGD: ε+= XbY , ]1[ DX n= .
MGD1: tj jtjt DbaY ε++= ∑ =
3
1 MGD2: tj jtjt DbaY ε++= ∑ =
3
1*
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=
0 0 01 0 00 1 00 0 10 0 01 0 00 1 00 0 1
321
MMM
D
DDD
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
−−−
−−−=
MMM
111100010001111
100010001
*3
*2
*1
D
DDD

4. VIOLAÇÃO DE HIPÓTESES BÁSICAS 4.1 AUTOCORRELÃO SERIAL DOS ERROS
• Violação da hipótese 5 ( 0),(),(),( === jijiji CovCorE εεεεεε , i ≠ j);
Caso Geral
MGD: 0),(
221
≠+++=
ji
ikikii
uuCovuXbXbbY L
para algum j ≠ i
Caso de Séries de Tempo
MGD: 0),(),(
221
≠=+++=
−− jttjtt
tktktt
uuEuuCovuXbXbbY L
j = 1, 2, ...
• 0),( ≠− jtt uuCov é chamada autocorrelação serial de j-ésima ordem; Autocorrelação Serial de 1ª. Ordem (ACS1)
MGD: 0),( 1
221
≠+++=
−tt
tktktt
uuCovuXbXbbY L
• Razões para haver ACS1
o Inércia típica das variáveis econômicas; o Variáves explicativas excluídas do MGD considerado:
MGD: tttt XbXbbY ε+++= 33221
MGD considerado: ttt uXbbY ++= 221
o Forma funcional incorreta: MGD: tttt XbXbbY ε+++= 2
321
MGD considerado: ttt uXbbY ++= 21
o Defasagens excluídas: MGD: ttttt YbXbXbbY ε++++= −− 141,23221
MGD considerado: ttt uXbbY ++= 221

Conseqüências da ACS1: • Propriedades do EMQO:
o b continua não enviesado para b; o b (EMQO) não é mais o MELNE para b, logo é ineficiente;
• Variância residual enviesada: o )(ˆ 22 knuS −= ∑ em geral subestima 2σ ;
o Elementos de )(b
Sdiag ficam, em geral, subestimados; o 2R e 2R ficam, em geral, superestimados; o Estatísticas
jj bjbSbt ˆˆ
ˆ= (j = 1,...,k) ficam, em geral, superestimadas;
o Estatística F fica superestimada; o Critérios de informação AIC e SC ficam em geral
subestimados; • Matriz de var-covar dos parâmetros:
o Com ACS1: ),,()()ˆ( ,112 K−
− +′= tt xxCXXbVar ρσ ;
o ),( 1−= tt uuCorρ ; o Computadores tipicamente reportam resultados calculados
com base na ausência de ACS1, isto é: 122ˆ )( −′= XXSSb
; Verificando a presença/ausência de ACS1
• Graficamente:
Termo de Erro com ACS1 Termo de erro Sem ACS1
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49
-0.4
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49
0≠ρ 0=ρ

• Teste de Durbin-Watson
o Assuma que:
o MGD: ⎪⎩
⎪⎨
⎧
===
+=++++=
−
−
21
1
221
)(,0)(;0)( σεεεε
ερ
tttt
ttt
tktktt
VarECor
uuuXbXbbY L
o Onde ttt uu ερ += −1 é chamado processo AR(1) e ),( 1−= tt uuCorρ ;
o H0: 0=ρ ; H1: 0≠ρ ;
o Estatística DW: )ˆ1(2ˆ
)ˆˆ(
1
2
2
21
ρ−≈−
=∞→
=
=−
∑
∑nn
tt
n
ttt
u
uuDW
o Onde 2112 ˆˆˆˆ t
nttt
nt uuu =−= ΣΣ=ρ ;
o Note-se que:
1ˆ =ρ 0≈DW 0ˆ >ρ 20 << DW 0ˆ =ρ 2≈DW 0ˆ <ρ 42 << DW 1ˆ −=ρ 4≈DW
o Regra de decisão
Se Decidir
LdDW <≤0 Rejeitar H0 (há ACS1 +) UL dDWd ≤≤ Não decidir
UU dDWd −<< 4 Não Rejeitar H0
LU dDWd −≤≤− 44 Não decidir 44 ≤<− DWd L Rejeitar H0 (há ACS1 −)
o Onde [dL,dU] = f (n,k’,α);
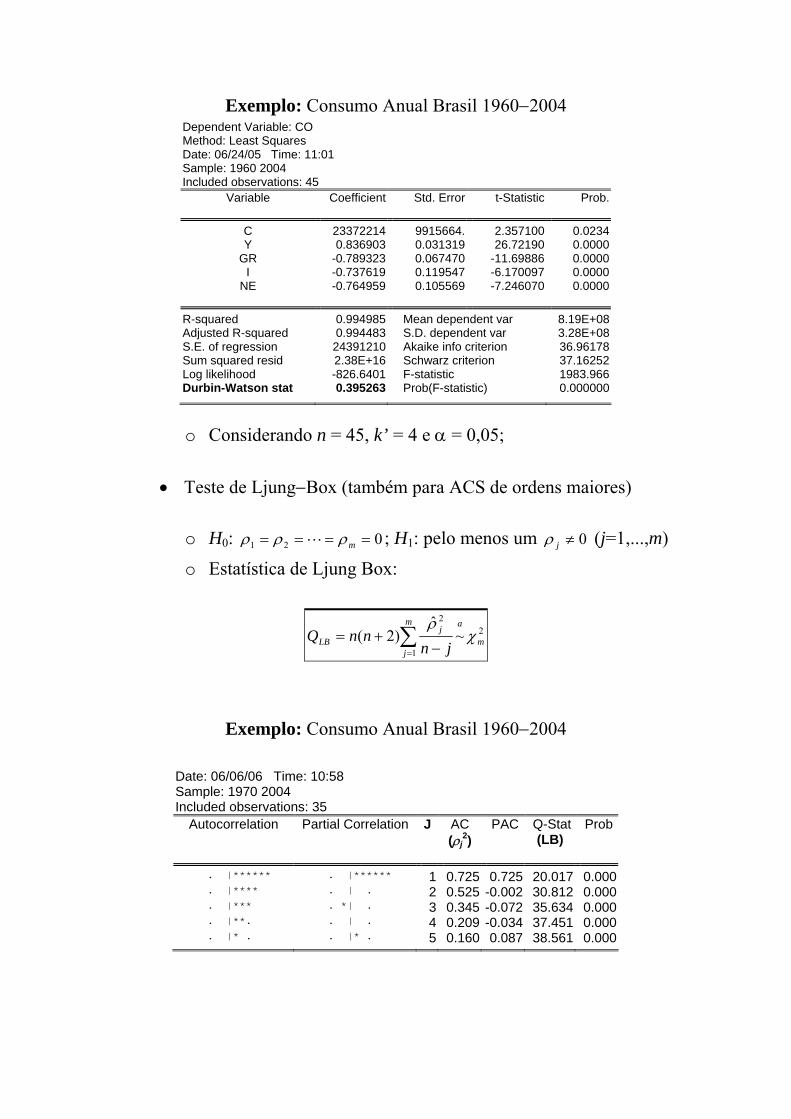
Exemplo: Consumo Anual Brasil 1960−2004 Dependent Variable: CO Method: Least Squares Date: 06/24/05 Time: 11:01 Sample: 1960 2004 Included observations: 45
Variable Coefficient Std. Error t-Statistic Prob.
C 23372214 9915664. 2.357100 0.0234 Y 0.836903 0.031319 26.72190 0.0000
GR -0.789323 0.067470 -11.69886 0.0000 I -0.737619 0.119547 -6.170097 0.0000
NE -0.764959 0.105569 -7.246070 0.0000
R-squared 0.994985 Mean dependent var 8.19E+08 Adjusted R-squared 0.994483 S.D. dependent var 3.28E+08 S.E. of regression 24391210 Akaike info criterion 36.96178 Sum squared resid 2.38E+16 Schwarz criterion 37.16252 Log likelihood -826.6401 F-statistic 1983.966 Durbin-Watson stat 0.395263 Prob(F-statistic) 0.000000
o Considerando n = 45, k’ = 4 e α = 0,05;
• Teste de Ljung−Box (também para ACS de ordens maiores)
o H0: 021 ==== mρρρ L ; H1: pelo menos um 0≠jρ (j=1,...,m)
o Estatística de Ljung Box:
2
1
2
~ˆ
)2( m
am
j
jLB jn
nnQ χρ
∑= −
+=
Exemplo: Consumo Anual Brasil 1960−2004
Date: 06/06/06 Time: 10:58 Sample: 1970 2004 Included observations: 35
Autocorrelation Partial Correlation J AC (ρj
2) PAC Q-Stat
(LB) Prob
. |****** . |****** 1 0.725 0.725 20.017 0.000 . |**** . | . 2 0.525 -0.002 30.812 0.000 . |*** . *| . 3 0.345 -0.072 35.634 0.000 . |**. . | . 4 0.209 -0.034 37.451 0.000 . |* . . |* . 5 0.160 0.087 38.561 0.000

Estimador de Mínimos Quadrados Generalizados (EMQG)
MGD: ⎪⎩
⎪⎨
⎧
===
+=++++=
−
−
21
1
221
)(,0)(;0)( εσεεεε
ερ
tttt
ttt
tktktt
VarECor
uuuXbXbbY L
• Equação de diferenças generalizadas (EDG):
tktktt XbXbbY ε++++= **22
*1
* L
o Onde 1*
−−= ttt YYY ρ , 1,*
−−= tjjtjt XXX ρ e 1−−= ttt uu ρε ;
• Então, estima−se a EDG por MQO, obtendo−se )ˆ,,ˆ,ˆ(ˆ2
*1
* ′= kbbbb K ;
o )1(ˆˆ *11 ρ−= bb ;
o Primeira observação: 21
*1 1 ρ−= YY , 2
1*1 1 ρ−= jj XX
Representação matricial
MGD: uXbY += ,
• Note que Ω=′= 2)()( σuuEuVar , porque há ACS1;
o Onde
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=Ω
−−−
−
−
−
×
1
11
1
331
32
2
12
L
MOMMM
L
L
L
nnn
n
n
n
nn
ρρρ
ρρρρρρρρρ
;
• Agora, seja a seguinte matriz:
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
−−
−−
=×
21000
0100010001
ρρ
ρρ
L
OMMM
L
L
L
nnH
o Pré−multiplicando o MGD por essa matriz: HuHXbHY += ;
o Então, minimizando−se uHHui ˆˆˆˆˆ 2 ′′=′=Σ εεε , tém−se o EMQG:
YXXXb 111 ) (~ −−− Ω′Ω′=
o Note−se que HH ′=Ω−1 ;
o b~ é eficiente, consistente e normalmente distribuído assintóticamente;

• Estimação de ρ (Método de Cochrane Orcutt ou CORC): 1. Estima−se o MGD por MQO e obtém−se )1(ˆtu ;
2. Estima−se: ttt vuu ),1(1),1(),1( ˆˆˆˆ += −ρ ;
3. Usa−se ρ para estimar EDG: tktktt XbXbbY εˆˆˆ **22
*1
* ++++= L ;
4. Computa−se: ktkttt XbXbbYu ˆˆˆˆ 221),2( −−−−= L ;
5. Repete−se passos 2, 3 e 4 iterativamente até que: 0|| 1 ≈<− − γρρ ll (onde l indica iteração);
Exemplo: Consumo Anual Brasil 1960−2004
Dependent Variable: CO Sample (adjusted): 1971 2004 Included observations: 34 after adjustments Convergence achieved after 22 iterations
Variable Coefficient Std. Error t-Statistic Prob.
C 1.22E+08 54126485 2.257963 0.0319 Y 0.769876 0.043924 17.52743 0.0000
GR -0.679646 0.062333 -10.90354 0.0000 I -0.828333 0.074674 -11.09262 0.0000
NE -0.932487 0.087990 -10.59761 0.0000 AR(1) 0.865912 0.070015 12.36746 0.0000
R-squared 0.997571 Mean dependent var 7.49E+08 Adjusted R-squared 0.997138 S.D. dependent var 1.75E+08 S.E. of regression 9368116. Akaike info criterion 35.10231 Sum squared resid 2.46E+15 Schwarz criterion 35.37167 Log likelihood -590.7392 F-statistic 2300.268 Durbin-Watson stat 2.156901 Prob(F-statistic) 0.000000
Estatística Q de Ljung−Box
Date: 06/07/06 Time: 15:20 Sample: 1971 2004
Autocorrelation Partial Correlation J AC PAC Q-Stat Prob
. *| . . *| . 1 -0.094 -0.094 0.3309 . |* . . |* . 2 0.087 0.079 0.6192 0.431 . *| . . *| . 3 -0.110 -0.097 1.0987 0.577 . | . . | . 4 -0.016 -0.041 1.1097 0.775 . |* . . |* . 5 0.112 0.127 1.6421 0.801

4.2 HETEROCEDASTICIDADE
• Violação da hipótese 5 ( 2)( σε =iVar , i ≠ j; ou IEVar 2)()( σεεε =′= );
Caso Geral
MGD: 2221
)( ii
ikikii
uVar
uXbXbbY
σ=
++++= L
Caso de Séries de Tempo
MGD: 2
221
)( tt
tktktt
uVar
uXbXbbY
σ=
++++= L
Exemplo Gráfico: Caso de 1 variável explicativa X
• Atualmente, heterocedasticidade ocorre em dados temporais e de
seção cruzada (cross−section);

Consequências da Heterocedasticidade
• Propriedades do EMQO: o b continua não enviesado para b; o b (EMQO) não é mais o MELNE para b, logo é ineficiente;
• Variância residual enviesada: o )(ˆ 22 knuS −= ∑ é um estimador enviesado de 2σ ;
o Elementos de )(b
Sdiag ficam enviesados;
o 2R e 2R ficam enviesados; o Estatísticas
jj bjbSbt ˆˆ
ˆ= (j = 1,...,k) ficam enviesadas;
o Estatística F fica enviesada; o Critérios de informação AIC e SC ficam enviesados;
• Matriz de var-covar dos parâmetros: o Sob heterocedasticidade: Μ= 2)ˆ( σbVar , onde 1)( −′≠Μ XX ; o Computadores tipicamente reportam resultados calculados
com base na ausência de heterocedasticidade, isto é: 122
ˆ )( −′= XXSSb
;
Mínimos Quadrados Ponderados (MQP)
• É um caso particular do EMQG;
MGD: 2
221
)( ii
ikikii
uVar
uXbXbbY
σ=
++++= L
• Supondo 2σ conhecida, transforma−se o MGD segundo:
i
i
i
kik
i
i
ii
i uXb
Xbb
Yσσσσσ
++++= L221
1
o Isto é: ikikiii XbXbWbY ε++++= **221
* L ;
o No novo modelo, o termo iii u σε = é homocedástico;
Prova: ( ) 11)( 2
2
2 ===⎟⎟⎠
⎞⎜⎜⎝
⎛=
i
ii
ii
ii uVar
uVarVar
σσ
σσε
• Estima−se o modelo transformado por EMQO.

Representação Matricial do EMQP
MGD: uXbY += ,
• Note que Ω=′= 2)()( σuuEuVar , onde :
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
=Ω×
2
23
22
21
2
000
000000000
n
nn
σ
σσ
σ
σ
L
MOMMM
L
L
L
;
• Agora, seja a seguinte matriz:
⎥⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
=×
n
nnH
σ
σ
σ
100
010
001
2
1
L
MOMM
L
L
;
o Pré−multiplicando o MGD por essa matriz: HuHXbHY += ;
o Então, minimizando−se uHHui ˆˆˆˆˆ 2 ′′=′=Σ εεε , tém−se o EMQG:
YXXXb 111 ) (~ −−− Ω′Ω′=
o Note−se que HH ′=Ω−1 ;
o b~ é eficiente, consistente e normalmente distribuído assintóticamente;
Quando 2
iσ é desconhecida
• Assume−se que é uma função das variáveis do modelo:
),,,()( 12
kiiiiii XXYcZcZuVar K=== σ
• Onde c é uma constante não nula.

• Transforma−se o MGD conforme:
i
i
i
kik
i
i
ii
i
Zu
ZX
bZ
Xb
Zb
ZY
++++= L221
1
• É fácil verificar que:
( ) cZcZ
uVarZZ
uVar
i
ii
ii
i ===⎟⎟⎠
⎞⎜⎜⎝
⎛ 1
• Logo, no MGD transformado o termo de erro é homocedástico. • Exemplos de funções Zi que podem ser usadas:
o ii YZ = ; o jii XZ = ;
o 2jii XZ = ;
o kikiii XcXcXcZ +++= L2211 ;
Exemplo: Consumo Anual Brasil 1970−2004 Mínimos Quadrados Ponderados: Assumindo que Var(εi)=c.Y
Dependent Variable: CO/SQR(Y) Method: Least Squares Date: 06/12/06 Time: 15:01 Sample (adjusted): 1970 2004 Included observations: 35 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
1/SQR(Y) 42489845 11564215 3.674252 0.0009 SQR(Y) 0.794932 0.032469 24.48296 0.0000
GR/SQR(Y) -0.664485 0.076533 -8.682316 0.0000 I/SQR(Y) -0.690385 0.115316 -5.986888 0.0000
NE/SQR(Y) -0.705055 0.110605 -6.374556 0.0000
R-squared 0.956610 Mean dependent var 21405.12 Adjusted R-squared 0.950824 S.D. dependent var 2459.812 S.E. of regression 545.4779 Akaike info criterion 15.57277 Sum squared resid 8926386. Schwarz criterion 15.79496 Log likelihood -267.5234 Durbin-Watson stat 0.336312

Verificando a Presença de Heterocedasticidade
Graficamente • Plotar ii X 2×ε , ii X 3×ε , ..., kii X×ε ;
• Plotar ii X 22 ×ε , ii X 3
2 ×ε , ..., kii X×2ε ;
• Plotar tt ×ε ou tt ×2ε .
Teste de White • H0: não há heterocedasticidade;
• Estatística de teste: 22 ~ q
anR χ , onde 1]2)1([ −+= kkq ;
o O cômputo dessa estatística de teste envolve regredir os quadrados dos resíduos de um MGD estimado por MQO contra um conjunto V de variáveis formado por:
Todas as variáveis explicativas não−redundantes; Os quadrados dessas variáveis; Os produtos cruzados entre si dessas variáveis;
• Regra de Decisão
o Se αχ >≥ )( 22 nRP q → Não Rejeite H0;
o Se αχ ≤≥ )( 22 nRP q → Rejeite H0.

• Ilustração do teste de White:
o MGD: iiii XbXbbY ε+++= 33221 ;
o Estime por MQO e compute: iiii XbXbbY 33221ˆˆˆˆ −−−=ε ;
o Estime por MQO a regressão:
iiiiiiii wXXcXcXcXaXaa ++++++= )(ˆ 324233
22233221
2ε ;
o Compute )ˆˆˆˆ(12 εε ′′−= wwR para essa regressão;
o Compute a estatística de teste 2nR
o Escolha α e aplique a regra de decisão.
Exemplo: Consumo Anual Brasil 1960−2004
Dependent Variable: CO Method: Least Squares Date: 06/24/05 Time: 11:01 Sample: 1960 2004 Included observations: 45
Variable Coefficient Std. Error t-Statistic Prob.
C 23372214 9915664. 2.357100 0.0234 Y 0.836903 0.031319 26.72190 0.0000
GR -0.789323 0.067470 -11.69886 0.0000 I -0.737619 0.119547 -6.170097 0.0000
NE -0.764959 0.105569 -7.246070 0.0000
R-squared 0.994985 Mean dependent var 8.19E+08 Adjusted R-squared 0.994483 S.D. dependent var 3.28E+08 S.E. of regression 24391210 Akaike info criterion 36.96178 Sum squared resid 2.38E+16 Schwarz criterion 37.16252 Log likelihood -826.6401 F-statistic 1983.966 Durbin-Watson stat 0.395263 Prob(F-statistic) 0.000000
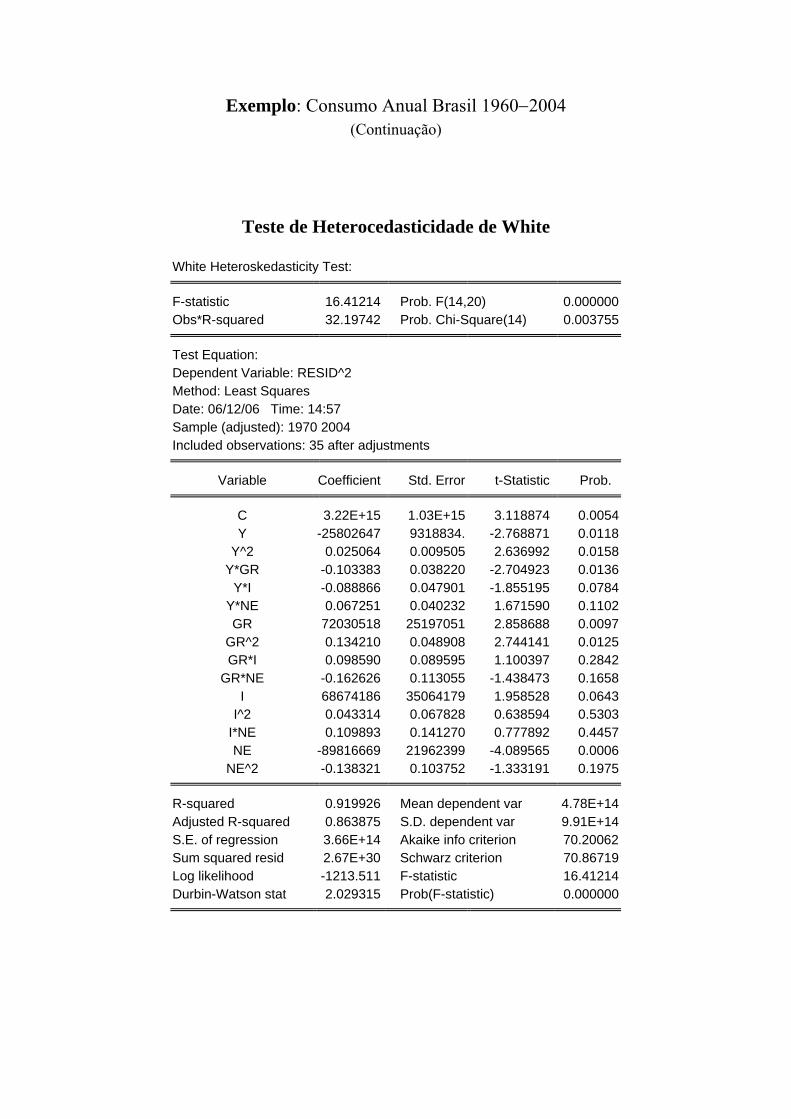
Exemplo: Consumo Anual Brasil 1960−2004 (Continuação)
Teste de Heterocedasticidade de White
White Heteroskedasticity Test:
F-statistic 16.41214 Prob. F(14,20) 0.000000 Obs*R-squared 32.19742 Prob. Chi-Square(14) 0.003755
Test Equation: Dependent Variable: RESID^2 Method: Least Squares Date: 06/12/06 Time: 14:57 Sample (adjusted): 1970 2004 Included observations: 35 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 3.22E+15 1.03E+15 3.118874 0.0054 Y -25802647 9318834. -2.768871 0.0118
Y^2 0.025064 0.009505 2.636992 0.0158 Y*GR -0.103383 0.038220 -2.704923 0.0136
Y*I -0.088866 0.047901 -1.855195 0.0784 Y*NE 0.067251 0.040232 1.671590 0.1102 GR 72030518 25197051 2.858688 0.0097
GR^2 0.134210 0.048908 2.744141 0.0125 GR*I 0.098590 0.089595 1.100397 0.2842
GR*NE -0.162626 0.113055 -1.438473 0.1658 I 68674186 35064179 1.958528 0.0643
I^2 0.043314 0.067828 0.638594 0.5303 I*NE 0.109893 0.141270 0.777892 0.4457 NE -89816669 21962399 -4.089565 0.0006
NE^2 -0.138321 0.103752 -1.333191 0.1975
R-squared 0.919926 Mean dependent var 4.78E+14 Adjusted R-squared 0.863875 S.D. dependent var 9.91E+14 S.E. of regression 3.66E+14 Akaike info criterion 70.20062 Sum squared resid 2.67E+30 Schwarz criterion 70.86719 Log likelihood -1213.511 F-statistic 16.41214 Durbin-Watson stat 2.029315 Prob(F-statistic) 0.000000

4.3 VARIÁVEIS INDEPENDENTES ESTOCÁSTICAS
• Estudaremos este assunto com base na regressão simples:
MGD: iii bXaY ε++=
• Violação da hipótese 2, isto é: iX é estocástica (é uma V.A.);
• Situações em que X é uma V.A.: o Erro de medida nas variáveis independentes; o Variáveis independentes também dependem da dependente; o Variável dependente defasada entre as independentes;
• Nesses casos, é possível que 0),( , ≠= εσε XiiXCov e, se isso ocorre, EMQO é enviesado e inconsistente:
• Prova
o Seja a seguinte “forma em desvios”do MGD: iii ebxy += ; onde YYy ii −= , XXx ii −= e εε −= iie . Neste caso, o EMQO
para b é dado por:
∑∑
∑∑
∑∑ +==
+== 222
)(ˆi
ii
i
iii
i
ii
xex
bx
ebxxxyx
b L
o Computando o E(,) em ambos os lados: ⎥⎥⎦
⎤
⎢⎢⎣
⎡+=
∑∑
2)ˆ(i
ii
xex
EbbE
o Nada garante que bbE =)ˆ( porque ][][][ 22
iiiiii xEyxExyxE ΣΣ≠ΣΣ . No entanto, aplicando o operador plim(,) em ambos os lados:
[ ][ ] 2
,22 lim
limlim)lim()ˆlim(
X
eX
i
ii
i
ii bnxpnexp
bxex
pbpbpσσ
+=+=⎥⎥⎦
⎤
⎢⎢⎣
⎡+=
∑∑
∑∑
o Fica claro que tudo depende de eXii eXCov ,),( σ= :
Se 0, =eXσ , então b é consistente para b (embora não se possa determinar se é enviesado ou não);
Se 0, ≠eXσ , isto significa que b é inconsistente para b (e, em decorrência, também enviesado para b);

Mínimos Quadrados de Variáveis Instrumentais (MQVI)
• Seja X não estocástica e 0),( , ≠= eXii eXCov σ . Como estimar b já que MQO é inconsistente neste caso?
• Definição de instrumento: Seja Z uma V.A. tal que:
o 0lim , ≠=∑ZX
ii
nzx
p σ ;
o 0lim , ==∑eZ
ii
nez
p σ ;
o onde XXx ii −= e ZZz ii −= .
• Então, o estimador MQVI dado por:∑∑=
ii
ii
zxyz
b~ é consistente para b;
• Prova o Novamente, seja o MGD em forma de desvio: iii ebxy += .
Então, o EMQVI pode ser desenvolvido como:
o ( )∑∑
∑∑∑
∑∑
∑∑
∑∑
+=+
=
+=
+==
ii
ii
ii
iiii
ii
iiii
ii
iii
ii
ii
zxez
bzx
ezzxb
zxezzbx
zxebxz
zxyz
b)()(~
o Aplicando plim(,) a ambos os lados:
o ( )( ) bb
nzxpnzp
bpbpZX
eZ
ii
ii =+=+=∑∑
,
,
limlim
)lim()~lim(σσε
Caso Geral MGD: ikikii XbXbbY ε++++= L221
• X2i,...,Xki são todas estocásticas; • Cada Xji (j = 2,...,k) é correlacionada com o termo de erro εi; • Aplicar o MQVI neste caso envolve usar um instrumento para cada
variável independente; ii XZ 22 → ,..., kiki XZ → .
• E usar o estimador geral de MQVI:
YZXZb ′′= −1)(~ • Onde Z é a matrix n×k de instrumentos para a matriz X;

5. INTRODUÇÃO A SISTEMAS DE EQUAÇÕES SIMULTÂNEAS
• Objetivo: introduzir mais variáveis dependentes no MGD;
MGD: iiiii
iiiii
XXYbbYXXYbbY
2222121121202
1212111212101
εγγεγγ++++=++++=
• Terminologia: o Y − variáveis endógenas; o X − variáveis exógenas; o b − coeficientes das endógenas; o γ − coeficientes das exógenas o Variáveis pré−determinadas:
Exógenas; Endógenas defasadas;
• Média: iiii
iiii
XXYbbYEXXYbbYE
222121121202
212111212101
)()(
γγγγ
+++=+++=
• Modelo Amostral: iiiii
iiiii
XXYbbY
XXYbbY
2222121121202
1212111212101
ˆˆˆˆˆˆˆˆˆˆ
εγγ
εγγ
++++=
++++=
• Preditor linear: iiii
iiii
XXYbbY
XXYbbY
222121121202
212111212101
ˆˆˆˆˆˆˆˆˆˆ
γγ
γγ
+++=
+++=
Forma Estrutural x Forma Reduzida
• Forma Estrutural: endógenas como função de endógenas e pré−determinadas;
MGD(FE): iiii
iiii
XYbbYXYbbY
2121121202
1111212101
εγεγ
+++=+++=
• Forma Reduzida: endógenas como função de pré−determinadas;
MGD(FR): iii
iii
XYXY
2121202
1111101
εππεππ++=++=

• Relação entre parâmetros da FE e da FR;
2112
21212
2112
12121
2112
21112121
2112
10212020
2112
11211211
2112
20121010
1
1
11
11
bbb
w
bbb
w
bbb
bbbbb
bbb
bbbbb
iii
iii
−+
=
−+
=
−+
=−+
=
−+
=−+
=
εε
εε
γγππ
γγππ
Problema da Identificação
• Definição: Em um SES uma equação está identificada quando é possível obter−se estimativas numéricas dos parâmetros estruturais a partir de estimativas dos parâmetros da forma reduzida;
• Status de identificação: o Equação não identificada: não é possível; o Equação identificada extamente: obtém−se uma única
estimativa dos parâmetros estruturais; o Equação sobre−identificada: obtém−se mais de uma
estimativa dos parâmetros estruturais; • Sistema Identificado: quando todas as equações do SES estão
identificadas (extamente ou sobreidentificadas); Condição de Ordem (necessária) para identificação
• Regra: Em um SES com M equações simultâneas, uma equação estará identificada se o número de varáveis pré−determinadas excluídas da equação (K−k) for maior ou igual ao número de endógenas incluídas na equação (m) menos um ( 1−≥− mkK );
• Exemplo: MGD: (3) (2) (1)
3131303
2222121121202
1212212101
iii
iiiii
iiii
YbbYXXYbbY
XYbbY
εεγγ
εγ
++=++++=
+++=
Equação M = 3 K = 2 Status
(1) m = 2 k = 1 K−k = 1 = m −1 = 1: identificada exatamente
(2) m = 2 k = 2 K−k = 0 < m −1 = 1: não identificada
(3) m = 2 k = 0 K−k = 2 > m −1 = 1: sobre−identificada

Condição de Posto (suficiente) para identificação
• Regra: Em um SES com M equações em M variáveis endógenas, uma equação é identificada se e somente se no mínimo um determinante não nulo de ordem (M−1)×(M−1) puder ser construído a partir dos coeficientes das variáveis (endógenas e pré−determinadas) excluídas daquela equação particular mas incluídas em outras equações do modelo;
Ilustração
iiiii
iiiii
iiiii
iiii
XYbYbbYXXYbbYXXYbbY
XYbbY
4343242141404
3232131131303
2222121323202
1111212101
εγεγγεγγεγ
=−−−−=−−−−=−−−−=−−−
• Pela condição de ordem verifica−se que: Equação M = 4 K = 3 Status
(1) m = 3 k = 1 K−k = 2 = m −1 = 2: identificada exatamente
(2) m = 2 k = 2 K−k = 1 = m −1 = 1: identificada exatamente
(3) m = 2 k = 2 K−k = 1 = m −1 = 1: identificada exatamente
(4) m = 3 k = 1 K−k = 2 = m −1 = 2: identificada exatamente • Tabela de Coeficientes do Sistema
Eq. 1 Y1 Y2 Y3 Y4 X1 X2 X3 (1) −b10 1 −b12 −b13 0 −γ11 0 0
(2) −b20 0 1 −b23 0 −γ21 −γ22 0
(3) −b30 −b31 0 1 0 −γ31 −γ32 0
(4) −b40 −b41 −b42 0 1 0 0 −γ43

• Pela condição de Posto:
• Equação (1): ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−
=
43
32
22
010000
γγγ
A
o Det(A) ≠ 0, logo eq. (1) não está identificada;
• Equação (2): ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−=
4341
31
100001
γbbA
o Det(A) ≠ 0, logo eq. (2) não está identificada;
• Equação (3): ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−
−=
4342
12
100100
γb
bA
o Det(A) ≠ 0, logo eq. (3) não está identificada;
• Equação (4): ⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
−−−−−
−−=
3231
222123
1113
1
0
γγγγ
γbb
A
o Det(A) ≠ 0, logo eq. (4) está identificada; Procedimentos para aplicar a condição de posto
• Passo 1: re−escrever o SES com todas as variáveis e parâmetros do lado esquerdo e só os erros aleatórios do lado direito;
• Passo 2: montar a tabela de coeficientes do sistema; • Passo 3: construir para cada equação a matriz A respectiva (a partir
dos coeficientes nulos da linha correspondente à equação em análise);
Regra Geral de Identificação
K − k > m − 1 Posto de A = M−1 Eq. Sobre−identificada
K − k ≥ m − 1 Posto de A < M − 1 Eq. Sub−identificada
K − k = m − 1 Posto de A = M − 1 Eq. Exatam. identificiada
K − k < m − 1 Eq. Não identificada (Posto de A < M − 1)

Problema da simultaneidade
MGD: iiiii
iiiii
XXYbbYXXYbbY
2222121121202
1212111212101
εγγεγγ++++=++++=
• Simultaneidade: quando há causalidade bidirecional entre
endógenas; • Problema: correlação da endógena do lado direito com o termo de
erro; • No MGD acima: 0),( 12 ≠iiYCor ε e 0),( 21 ≠iiYCor ε , logo:
o EMQO é inconsistente para estimar parâmetros das duas equações;
• Quando não há simultaneidade, é possível usar EMQO, desde que as hipóteses básicas do SES sejam satisfeitas;
Estimação de SES
MGD:
gikigkigigggigggi
ikikigigii
ikikigigii
XXYbYbbY
XXYbYbbY
XXYbYbbY
εγγ
εγγ
εγγ
+++++++=
+++++++=
++++++=
−− LL
MMMM
LL
LL
11,11,110
221212121202
111111212101
• Hipóteses Básicas:
o Relação linear entre as variáveis; o Xjis são não estocásticas, j = 1,...,k; o 0)( =riE ε , 2)( rriVar σε = , 0),( =rjriCov εε para r = 1,...,g e i ≠ j;
o 0),( =siriCov εε para r ≠ s; r = 1,...,g; s = 1,...,g;
o ),0(~ 2rri N σε ⇒ )),((~ 2
rriri YENY σ , r = 1,...,g.

• Antes da estimação, verificar:
o Identificação; o Simultaneidade;
• Métodos de Informação Limitada: considera restrições relacionadas apenas à equação de interesse;
o EMQO; o Estimador de Mínimos Quadrados Indiretos (EMQI); o Estimador de Mínimos Quadrados de 2 Estágios (EMQ2E);
• Métodos de Informação Completa: considera restrições entre equações;
o Estimador de Mínimos Quadrados de 3 Estágios (EMQ3E); o Estimador de Máxima Verossimilhança com Informação
Completa (EMVIC); • Tipologia de SES:
o Equações não relacionadas
0),( 21
2222202
1111101
=++=++=
ii
iii
iii
CovXbY
XbY
εεεγεγ
o Equações aparentemente não relacionadas (SURE)
0),( 21
2222202
1111101
≠++=++=
ii
iii
iii
CovXbY
XbY
εεεγεγ
Nota: neste caso, estima−se por algum método sistêmico, o mais usual sendo o MQ3E;
o Sistemas Recursivos
0),( 21
2222121121202
1212111101
=++++=
+++=
ii
iiiii
iiii
CovXXYbbY
XXbY
εεεγγ
εγγ
Nota: observe que iii YEY 111 )( ε+= ; substituindo na 2ª. equação implica que ;0),( 21 =iiYCov ε

o Sistemas Bloco−Recursivos
0),(),(),( 322121
3232131232131303
2222121121202
1212111212101
===+++++=
++++=++++=
iiiiii
iiiiii
iiiii
iiiii
CovCovCovXXYbYbbY
XXYbbYXXYbbY
εεεεεεεγγ
εγγεγγ
o Sistemas Simultâneos:
iiiii
iiiii
XXYbbYXXYbbY
2222121121202
1212111212101
εγγεγγ++++=++++=
Nota: estima−se por MQI ou MQ2E;
Mínimos Quadrados de 2 Estágios
• Caso particular do EMQVI;
• Serve para estimar equações exatamente ou sobre−identificadas;
• Seja o seguinte:
MGD: ttt
ttttt
YbbYXXYbbY
2121202
1212111212101
εεγγ
++=++++=
• É fácil verificar (pelas condições de ordem e de posto) que: o 1ª. equação não está identificada;
o 2ª. equação está sobre−identificada; o Logo, só é possível estimar a 2ª. equação;
• É fácil verificar também que devido à causalidade bidirecional (simultaneidade) entre tY1 e tY2 , ocorre:
0),( 21 ≠ttYCov ε ;

• Estimação da 2ª. equação por MQ2E:
o 1º. Estágio: construção de instrumento para tY1 via forma reduzida;
Forma Reduzida (FR): tttt
tttt
wXXYwXXY
2221121202
1212111101
+++=+++=
ππππππ
Estima−se por MQO: ttt XXY 212111101 ˆˆˆˆ πππ ++=
o 2º. Estágio: usa−se tY1 no lugar de tY1 para estimar a 1ª. equação da FE por MQVI;
*112120
212112120
21121202
ˆˆˆ)ˆˆ(
tt
ttt
tttt
Ybb
wbYbb
wYbbY
ε
ε
ε
++=
+++=
+++=
o Estima−se usando as fórmulas de MQVI:
∑∑=
tt
tt
yyyy
b11
1221 ˆ
ˆˆ 121220ˆˆ YbYb −=
Nota: é possível mostrar que a formula acima para 21b é equivalente ao estimador de MQO (ver PR pg. 402)
• Observe−se que tY1 é de fato um instrumento para tY1 :
o 0ˆ
lim11ˆ
11 ≠=∑YY
tt
nyy
p σ ;
o 0)),((ˆ
lim *1
*11 ==∑
tttt YECov
ny
p εε
• Logo, EMQE é um estimador consistente para os parâmetros estruturais de equações exatamente ou sobre−identificadas.

Exemplo: Consumo Anual Brasil 1970−2004
Estimação por EMQ2E (Opção TSLS do Eviews em Quick\Estimate Equation)
Dependent Variable: CO Method: Two-Stage Least Squares Date: 06/20/06 Time: 11:05 Sample (adjusted): 1970 2004 Included observations: 35 after adjustments Instrument list: GR NE
Variable Coefficient Std. Error t-Statistic Prob.
C 1.83E+08 28288823 6.469929 0.0000 Y 0.470996 0.023360 20.16266 0.0000
R-squared 0.954299 Mean dependent var 7.36E+08 Adjusted R-squared 0.952914 S.D. dependent var 1.87E+08 S.E. of regression 40600140 Sum squared resid 5.44E+16 Durbin-Watson stat 0.449011 Second-stage SSR 5.20E+17
Estimação da Forma Reduzida no 1º. Estágio Dependent Variable: Y Method: Least Squares Date: 06/20/06 Time: 11:08 Sample (adjusted): 1970 2004 Included observations: 35 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.
C 8.49E+08 51210803 16.57725 0.0000 GR 3.370831 0.449911 7.492219 0.0000 NE 1.672787 1.082381 1.545469 0.1321
R-squared 0.696523 Mean dependent var 1.17E+09 Adjusted R-squared 0.677556 S.D. dependent var 3.57E+08 S.E. of regression 2.03E+08 Akaike info criterion 41.17520 Sum squared resid 1.32E+18 Schwarz criterion 41.30852 Log likelihood -717.5660 F-statistic 36.72227 Durbin-Watson stat 0.593245 Prob(F-statistic) 0.000000
Related Documents











