Supported by the NIH grant 1U24 AI117966-01 to UCSD PI , Co-Investigators at: The model annotated with schema.org Susanna-Assunta Sansone, Alejandra Gonzalez-Beltran, Philippe Rocca-Serra Oxford e-Research Centre, University of Oxford, UK

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Supported by the NIH grant 1U24 AI117966-01 to UCSD PI , Co-Investigators at:
The modelannotated with schema.org
Susanna-Assunta Sansone, Alejandra Gonzalez-Beltran, Philippe Rocca-Serra
Oxford e-Research Centre, University of Oxford, UK

The model

What is ?
Like the JATS (Journal Article Tag Suite) is used by PubMed to index literature,
a DATS (DatA Tag Suite) is needed for a scalable way to index data sources in
the DataMed prototype

Where do I find the documentation?
Like the JATS (Journal Article Tag Suite) is used by PubMed to index literature,
a DATS (DatA Tag Suite) is needed for a scalable way to index data sources in
the DataMed prototype

A community-driven effort

A community-driven effort

v Support intended capability of the DataMed prototype to harvest
key metadata (experimental and data) descriptors, such as
² information and relations between authors, datasets, publication and
funding sources, nature of biological signal, nature of perturbation
etc.
What is support to cover and do?

v Support intended capability of the DataMed prototype to harvest
key metadata (experimental and data) descriptors, such as
² information and relations between authors, datasets, publication and
funding sources, nature of biological signal, nature of perturbation
etc.
v Use cases and the competency questions used throughout the
development process
² to define the appropriate boundaries and level of granularity: which
queries will be answered in full, which only partially, and which are
out of scope
What is support to cover and do?
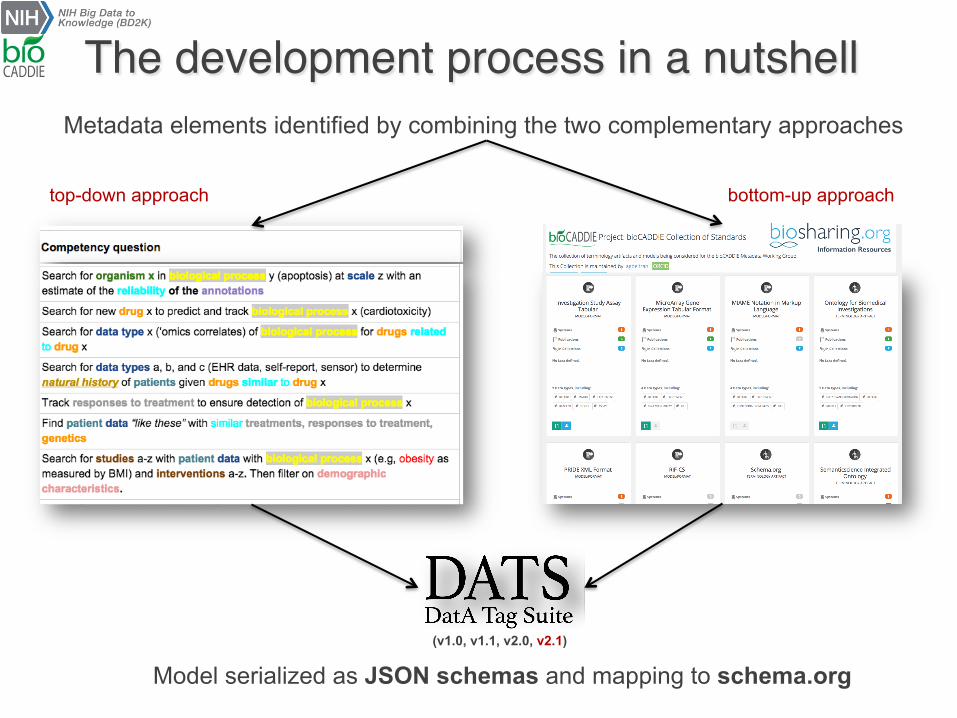
Metadata elements identified by combining the two complementary approaches
top-down approach bottom-up approach
The development process in a nutshell
Model serialized as JSON schemas and mapping to schema.org (v1.0, v1.1, v2.0, v2.1)

Extracting requirements from use casesv Selected competency questions
² representative set collected from: use cases workshop, white paper, submitted by the community and from NIH and Phil Bourne’s ADDS office
² key metadata elements processed: abstracted, color-coded and terms binned binned as Material, Process, Information, Properties; relation identified
top-down approach

bottom-up approach
Mapping existing metadata schemas
v schema.orgv DataCitev RIF-CSv W3C HCLS dataset descriptions (mapping of many models including DCAT, PROV, VOID, Dublin
Core)v Project Open Metadata (used by HealthData.gov is being added in this new iteration)
v ISAv BioProjectv BioSample
v MiNIMLv PRIDE-mlv MAGE-tabv GA4GH metadata schemav SRA xmlv CDISC SDM / element of BRIDGE model

v Metadata is either too much or too little
² many databases won’t have all these metadata elements
² conversely, domain-specific databases (e.g. focusing on a type of study, organism or technology) have more detailed metadata
We know that one size does not fit all

v Metadata is either too much or too little
² many databases won’t have all these metadata elements
² conversely, domain-specific databases (e.g. focusing on a type of study, organism or technology) have more detailed metadata
v Our goal is NOT to develop the perfect model
² we have had several iterations testing the model
² we have aimed to have maximum coverage of use cases with minimal number of data elements
² we do foresee that not all questions can be answered in full
We know that one size does not fit all

v The descriptors for each metadata element (Entity), include
² Property (describing the Entity), Definition (of each Entity and Property),
Value(s) (allowed for each Property)
Key features of

v The descriptors for each metadata element (Entity), include
² Property (describing the Entity), Definition (of each Entity and Property),
Value(s) (allowed for each Property)
v We have defined a set of core and extended entities ² Core elements are generic and applicable to any type of datasets, like the
JATS can describe any type of publication.
² Extended elements includes an additional elements, some of which are specific for life, environmental and biomedical science domains
² this set can be further extended as needed
Key features of

v The descriptors for each metadata element (Entity), include
² Property (describing the Entity), Definition (of each Entity and Property),
Value(s) (allowed for each Property)
v We have defined a set of core and extended entities ² Core elements are generic and applicable to any type of datasets, like the
JATS can describe any type of publication.
² Extended elements includes an additional elements, some of which are specific for life, environmental and biomedical science domains
² this set can be further extended as needed
v Entities are not mandatory, in both core and extended set
² An entity is used only when applicable to the dataset to be described
² in that case only few of its properties are defined as mandatory
Key features of

v Model is designed around the Dataset, an entity that intends to cater for any unit of information stored by repositories:
² archived experimental datasets, which do not change after deposition to the repository => examples available for dbGAP, GEO, ClinicalTrials.org
² datasets in reference knowledge bases, describing dynamic concepts, such as “genes”, whose definition morphs over time => examples available for
UniProt
v The Dataset entity is also linked to other digital research objects part of the NIH Commons, such as Software and Data Standard, which are the focus on other
discovery indexes and therefore are not described in detail in this model
General design of the

v Model is designed around the Dataset, an entity that intends to cater for any unit of information stored by repositories:
² archived experimental datasets, which do not change after deposition to the repository => examples available for dbGAP, GEO, ClinicalTrials.org
² datasets in reference knowledge bases, describing dynamic concepts, such as “genes”, whose definition morphs over time => examples available for
UniProt
General design of the

core and extended elements
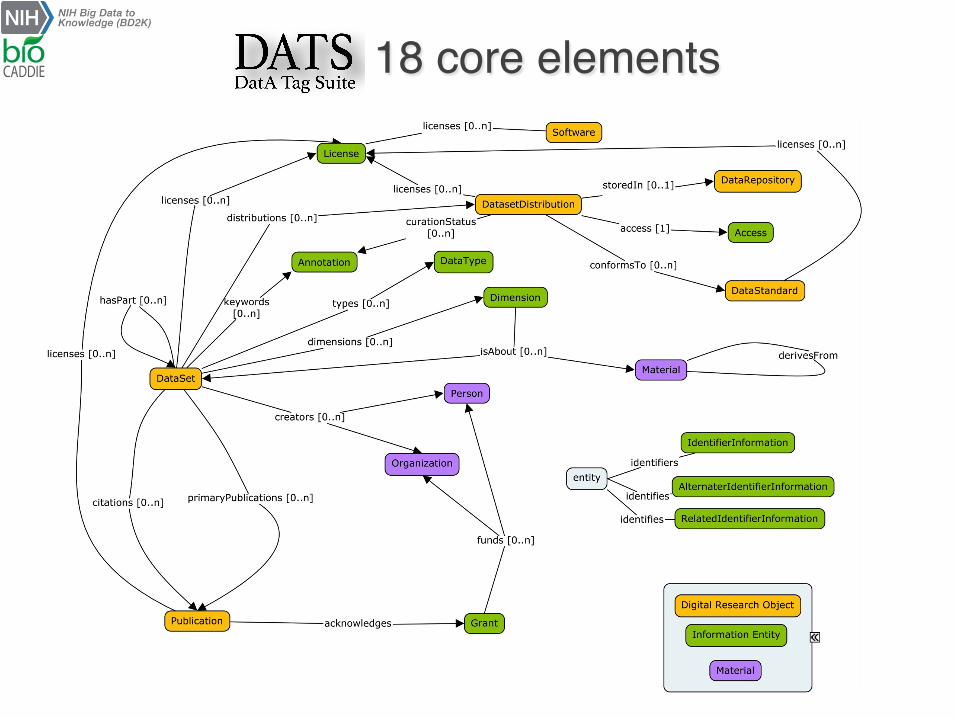
18 core elements

18 core elements and few mandatory properties

v What is the dataset about? ² Material
v How was the dataset produced ? Which information does it hold?
² Dataset / Data Type with its Information, Method, Platform, Instrument
v Where can a dataset be found?
² Dataset, Distribution, Access objects (links to License) v When was the datasets produced, released etc.?
² Dates to specify the nature of an event {create, modify, start, end...} and its timestamp
v Who did the work, funded the research, hosts the resources etc.?
² Person, Organization and their roles, Grant
Core elements provide the basic info

Standards

Standards
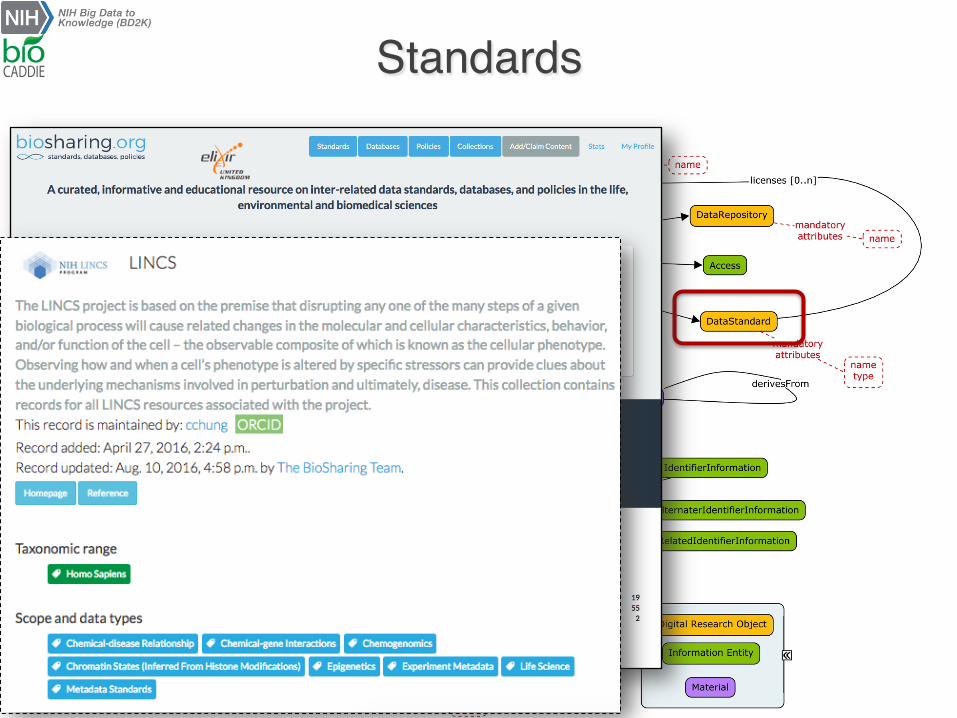
Standards

Software

Software
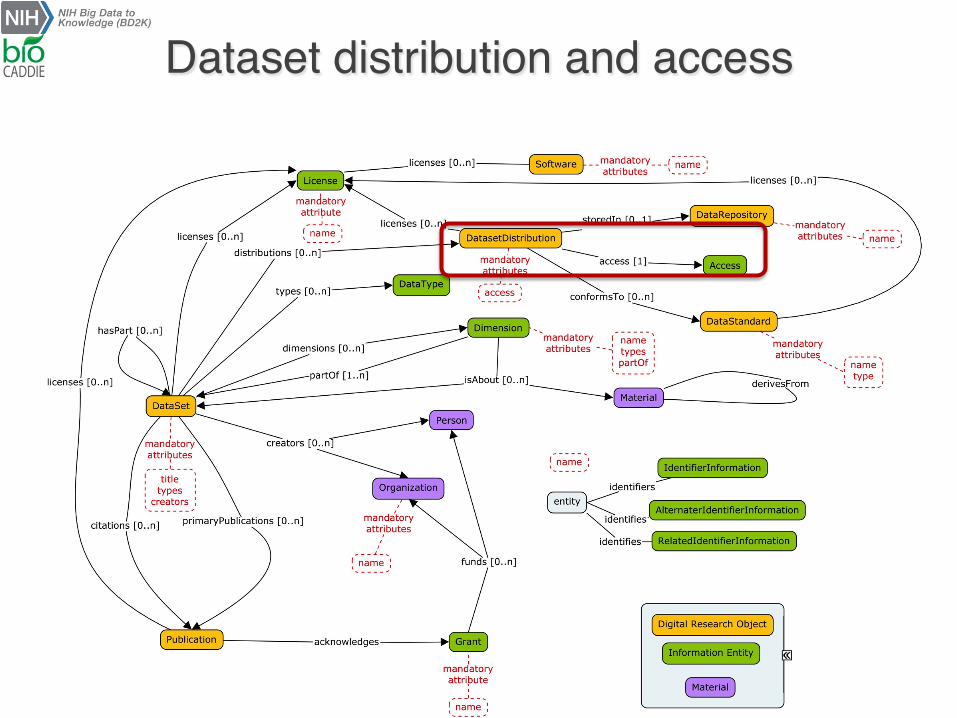
Dataset distribution and access

also follows the W3C Data on the Web Best Practices
DATS follows these, which also recommend DatasetDistribution
https://www.w3.org/TR/dwbp

Serializationsv DATS model in JSON schema, serialized as:
² JSON* format, and
² JSON-LD** with vocabulary from schema.org
v …serializations in other formats can also be done, as / if needed
* JavaScript Object Notation ** JavaScript Object Notation for Linked Data
Context (mapping) file also
available, meaning that other
vocabularies can be used
Discussion also ongoing with:

Schema.org value-added tov Why using schema.org to annotate the DATS?
² Developed/used by search engine consortium (google, yandex, yahoo etc.)
² The NIH Commons is discussing its use
v What benefits do DataMed get by implementing a schema.org-based DATS? Especially: ² increased visibility (by both popular search engines and DataMed), accessibility (via
common query interfaces) and possibly improve ranking

Schema.org value-added tov Why using schema.org to annotate the DATS?
² Developed/used by search engine consortium (google, yandex, yahoo etc.)
² The NIH Commons is discussing its use
v What benefits do DataMed get by implementing a schema.org-based DATS? Especially: ² increased visibility (by both popular search engines and DataMed), accessibility (via
common query interfaces) and possibly improve ranking
v Discussion and collaboration with schema.org is ongoing ² missing elements (needed by DATS) submitted to the tracker; Roughly 80 % of DATS
entities and properties can be mapped but alignment is not perfect/less precise), the remaining 20% constitute major gaps
² schema.org and its related Health and Life Science extension evolve (the latter focuses on clinical studies)
² coordination also via the ELIXIR-supported bioschemas.org initiative
² discussion also ongoing under the NIH Commons WGs

Mapping to schema.org

elements in CEDAR template
v Datasets not yet in a formal
repositories
² CEDAR metadata authoring
tool can be used to provide
DATS-compliant metadata to
be later indexed by DataMed

and omicsDI models - Mapping
v Overlap with DATS core
elements
² In red some DATS
extended elements

and DCIP supplement - Mapping
Citation metadata for repositories’ landing page

https://github.com/datacite/spinone/issues/3
exported by DataCite
v An API endpoint that returns DataCite
metadata in DATS format is work in
progress: http://api.datacite.org/dats
v DataCite Metadata Schema allows for
a RelatedIdentifier with the
HasMetadata relation type
² this allows linking to the DATS
metadata from a DataCite
metadata record
Related Documents