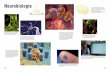
ologie de à l’alcool Lüscher nces fondamentales , Université de Genève La consommation d’alcool peut induire l’addiction L’addiction se distingue de la dépendance Les substances euphorisantes stimulent le système du cerveau responsable de la perception de la récompense peut induire l’addiction L’activation de ce système altère la communication entre cellules nerveuses L’addiction est donc un maladie de l’apprentissage & de la mémoire -10 -5 0 5 10 Appréciation 200 150 100 50 0 Quantité de chocolat (g) ! Small et al., Brain, 2001 Plaisir Ecoeurement Small et al., Brain, 2001 ! Small et al., Brain, 2001 Coronale Sagittale Horizontale Nez Nuque Nez Nuque Small et al., Brain, 2001

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Neurobiologie de obiologie de
l’addiction à l’alcooll’addiction à l’alcool
Christian LüscherChristian Lüscher
Dépt. des Neurosciences fondamentales osciences fondamentales
& Service de Neurologie, Université de Genèveologie, Université de Genève
La consommation d’alcool peut induire l’addiction
L’addiction se distingue de la dépendance
Les substances euphorisantes stimulent le système
du cerveau responsable de la perception de la
récompense peut induire l’addiction
L’activation de ce système altère la communication
entre cellules nerveuses
L’addiction est donc un maladie de l’apprentissage &
de la mémoire
-10
-5
0
5
10
Ap
pré
cia
tio
n
200150100500
Quantité de chocolat (g)
!!
Small et al., Brain, 2001
Plaisir
Ecoeurement
Small et al., Brain, 2001
!
Small et al., Brain, 2001
Coronale
Sagittale
Horizontale
Nez Nuque
Nez Nuque
Small et al., Brain, 2001

Cortex préfrontal
Noyau Accumbens
Le système de
récompense
Noyau Accumbens
Amygdale
Noyau Accumbens
Hippocampe
Dopamine
Les neurones dans la VTA
N. accumbens
Ctx préfrontal
Amygdale
Aire tegmentale ventrale (VTA)
0 1 2s
Schultz et al., Science 1997
Erreur de prédiction
-1 0 1 2s
0 1 2 s
R
0 1 2 s
Image
-1 0 1 2s
Image R
0 1 2 s
1857
In a resting animal, midbrain dopamineneurons show a slow, steady (“tonic”) rateof firing; certain meaningful stimuli pro-voke brief, abrupt (“phasic”) changes indischarge. In previous work, Schultz andco-workers (2, 3) recorded the activity ofsingle dopamine neurons in awake mon-keys with microelectrodes. When themonkey received an unexpected reward,such as a drop of juice, most dopaminecells responded with a burst of firing.However, if the monkey learned that astimulus, such as a particular pattern on acomputer monitor, always preceded deliv-ery of the reward, the dopamine neuronsno longer responded to the reward butfired instead in response to the predictive(“conditioned”) stimulus. Omission of apredicted reward caused slowing or cessa-tion of dopamine firing around the timethat the reward was expected.
The phasic responses of midbraindopamine neurons resemble a key signalin computer models based on animallearning (4–7). Through adjustment ofconnection weights in a neural network(“reinforcement”), these models are ableto predict the achievement of a goal state(“reward”) and result in optimization ofactions. The incremental improvement inpredictions is driven by a “prediction er-ror”: the difference between expected andexperienced rewards. The new findings ofFiorillo et al. both strengthen and chal-lenge the reinforcement-learning notion of
midbrain dopamine neuronal activity whileraising many fascinating new questions.
The novelty of the Fiorillo et al. studylies in their systematic variation of the pro-portion of conditioned stimuli that werefollowed by a reward. The conditionedstimulus associated with each reward prob-ability (0.0, 0.25, 0.50, 0.75, 1.0) consistedof a unique visual pattern displayed on acomputer monitor for 2 seconds (see thefigure). Delivery of the reward, a drop ofsyrup, coincided with the offset of the con-ditioned stimulus. The dopamine neuronsresponded to the conditioned stimuli withphasic increases in firing that correlatedpositively with reward probability. In con-trast, responses to reward delivery showeda strong negative correlation with rewardprobability. On trials when an expected re-ward was omitted, the firing of dopamineneurons tended to decrease at the time ofpotential reward delivery, and the magni-tude of this dip tended to increase with theprobability of a reward. The systematicvariation in the strength of the phasic re-sponses to conditioned stimuli and to re-ward delivery or omission supports and ex-tends previous findings obtained at the twoextreme probabilities (0.0 and 1.0): Thehigher the likelihood of reward, the
stronger the firing to the conditioned stim-ulus, the larger the decrease in firing to re-ward omission, and the weaker the firing toreward delivery.
Their most provocative results concernthe activity of the dopamine cells beforethe time of potential reward delivery. Inprevious work carried out at the two ex-treme probabilities, the firing rate was sta-ble. By exploring intermediate probabili-ties, Fiorillo et al. reveal a striking new pat-tern: The activity of dopamine neurons in-creased before the potential delivery of anuncertain reward. In contrast to the briefupswings in firing triggered by reward-predicting stimuli and unexpected re-wards, the population firing rate rosesteadily throughout most of the 2-secondpresentation of the conditioned stimuluswhen the probability of reward was 0.5, at-taining a higher rate than when the rewardprobability was 0.25 or 0.75.
The authors propose that the sustainedfiring preceding the time of potential re-ward delivery tracked the uncertainty ofthe reward. The onset of the conditionedstimuli signaling probabilities of either 0.0or 1.0 provided the monkey with definitiveinformation as to whether the rewardwould be delivered; if the meaning of thestimuli had been fully learned, then uncer-tainty about reward occurrence followingstimulus onset would be zero. In contrast, areward was equally likely to be delivered oromitted when the probability was 0.5, andthe monkey should have been maximallyuncertain about reward occurrence. Whenthe reward probability was 0.25 or 0.75,uncertainty was intermediate; if the mon-key had bet on the occurrence of the rewardfollowing stimulus onset, it could havewon, on average, three trials out of everyfour.
Regarding reinforcement learning mod-els, the phasic response of the dopamineneurons encodes a prediction error that isused as a “teaching signal” to improve fu-ture predictions. The incremental adjust-ment of the weights causes the teachingsignal to move backward in time toward theonset of the earliest stimulus that reliablypredicts the occurrence of a reward (and/orits potential time of delivery). How the sus-tained response preceding potential rewarddelivery could be incorporated into suchmodels is hard to see. If the dopamine sig-nal serves as the teacher, and the sustainedcomponent is not filtered out, how couldthe sustained component remain stationaryin time and amplitude over many trials?This problem is a knotty one because thesustained and phasic signals do not appearto be carried by independent populations ofneurons. Thus, postsynaptic elements arelikely to register the combined impact of
CS
Reward
P U
1.0
0.5
0.0
0.0
1.0
0.0
Anticipating a reward. Electrophysiological re-sponses of single midbrain dopamine neurons(yellow) were recorded while monkeys viewed acomputer monitor. Unique visual stimuli wereassociated with different probabilities of a re-ward (a drop of syrup). Rewards were presentedwith different probabilities (P) when the condi-tioned stimulus was switched off (CS offset).Theuncertainty (U) of the reward varied as an in-verted U-shaped function of probability. When P= 0 or P = 1, the monkey is certain that rewarddelivery will or will not accompany CS offset. Incontrast, when P = 0.5, the onset of the CS pro-vides no information about whether reward willor will not occur, but it does predict the potentialtime of reward delivery. The interval betweensuccessive CSs varied unpredictably (not shown),and thus the onset of the CS is the earliest reli-able predictor of the occurrence and/or the po-tential time of reward delivery. Once the mean-ing of the stimuli has been learned, the popula-tion of dopamine neurons responds to CS onsetwith a brief increase in activity when P = 1.0, butreceipt of the expected reward does not provokea strong change in firing. When P = 0, CS onsetproduced little response; if, however, the investi-gator violated expectation by delivering a re-ward, the dopamine cells responded with a brief,vigorous increase in firing.When P = 0.5 (and un-certainty about reward occurrence is maximal), aslow, steady increase in firing is seen prior to thetime of potential reward delivery.C
RED
IT:K
ATH
ARI
NE
SUTL
IFF/
SCIE
NC
E
www.sciencemag.org SCIENCE VOL 299 21 MARCH 2003
P E R S P E C T I V E S
R
–R
S R
+R
Schultz et al., Science, 1997
Koepp et al., Nature,1998 Reuter et al., Nature Neurosceience, 2005
Jeux vidéo Gain monétaire
Noyau accumbens
S +R (p=0.5)
+R (p=0.8)
+R (p=1.0)
Fiorillo et al., Science, 2003
1857
In a resting animal, midbrain dopamineneurons show a slow, steady (“tonic”) rateof firing; certain meaningful stimuli pro-voke brief, abrupt (“phasic”) changes indischarge. In previous work, Schultz andco-workers (2, 3) recorded the activity ofsingle dopamine neurons in awake mon-keys with microelectrodes. When themonkey received an unexpected reward,such as a drop of juice, most dopaminecells responded with a burst of firing.However, if the monkey learned that astimulus, such as a particular pattern on acomputer monitor, always preceded deliv-ery of the reward, the dopamine neuronsno longer responded to the reward butfired instead in response to the predictive(“conditioned”) stimulus. Omission of apredicted reward caused slowing or cessa-tion of dopamine firing around the timethat the reward was expected.
The phasic responses of midbraindopamine neurons resemble a key signalin computer models based on animallearning (4–7). Through adjustment ofconnection weights in a neural network(“reinforcement”), these models are ableto predict the achievement of a goal state(“reward”) and result in optimization ofactions. The incremental improvement inpredictions is driven by a “prediction er-ror”: the difference between expected andexperienced rewards. The new findings ofFiorillo et al. both strengthen and chal-lenge the reinforcement-learning notion of
midbrain dopamine neuronal activity whileraising many fascinating new questions.
The novelty of the Fiorillo et al. studylies in their systematic variation of the pro-portion of conditioned stimuli that werefollowed by a reward. The conditionedstimulus associated with each reward prob-ability (0.0, 0.25, 0.50, 0.75, 1.0) consistedof a unique visual pattern displayed on acomputer monitor for 2 seconds (see thefigure). Delivery of the reward, a drop ofsyrup, coincided with the offset of the con-ditioned stimulus. The dopamine neuronsresponded to the conditioned stimuli withphasic increases in firing that correlatedpositively with reward probability. In con-trast, responses to reward delivery showeda strong negative correlation with rewardprobability. On trials when an expected re-ward was omitted, the firing of dopamineneurons tended to decrease at the time ofpotential reward delivery, and the magni-tude of this dip tended to increase with theprobability of a reward. The systematicvariation in the strength of the phasic re-sponses to conditioned stimuli and to re-ward delivery or omission supports and ex-tends previous findings obtained at the twoextreme probabilities (0.0 and 1.0): Thehigher the likelihood of reward, the
stronger the firing to the conditioned stim-ulus, the larger the decrease in firing to re-ward omission, and the weaker the firing toreward delivery.
Their most provocative results concernthe activity of the dopamine cells beforethe time of potential reward delivery. Inprevious work carried out at the two ex-treme probabilities, the firing rate was sta-ble. By exploring intermediate probabili-ties, Fiorillo et al. reveal a striking new pat-tern: The activity of dopamine neurons in-creased before the potential delivery of anuncertain reward. In contrast to the briefupswings in firing triggered by reward-predicting stimuli and unexpected re-wards, the population firing rate rosesteadily throughout most of the 2-secondpresentation of the conditioned stimuluswhen the probability of reward was 0.5, at-taining a higher rate than when the rewardprobability was 0.25 or 0.75.
The authors propose that the sustainedfiring preceding the time of potential re-ward delivery tracked the uncertainty ofthe reward. The onset of the conditionedstimuli signaling probabilities of either 0.0or 1.0 provided the monkey with definitiveinformation as to whether the rewardwould be delivered; if the meaning of thestimuli had been fully learned, then uncer-tainty about reward occurrence followingstimulus onset would be zero. In contrast, areward was equally likely to be delivered oromitted when the probability was 0.5, andthe monkey should have been maximallyuncertain about reward occurrence. Whenthe reward probability was 0.25 or 0.75,uncertainty was intermediate; if the mon-key had bet on the occurrence of the rewardfollowing stimulus onset, it could havewon, on average, three trials out of everyfour.
Regarding reinforcement learning mod-els, the phasic response of the dopamineneurons encodes a prediction error that isused as a “teaching signal” to improve fu-ture predictions. The incremental adjust-ment of the weights causes the teachingsignal to move backward in time toward theonset of the earliest stimulus that reliablypredicts the occurrence of a reward (and/orits potential time of delivery). How the sus-tained response preceding potential rewarddelivery could be incorporated into suchmodels is hard to see. If the dopamine sig-nal serves as the teacher, and the sustainedcomponent is not filtered out, how couldthe sustained component remain stationaryin time and amplitude over many trials?This problem is a knotty one because thesustained and phasic signals do not appearto be carried by independent populations ofneurons. Thus, postsynaptic elements arelikely to register the combined impact of
CS
Reward
P U
1.0
0.5
0.0
0.0
1.0
0.0
Anticipating a reward. Electrophysiological re-sponses of single midbrain dopamine neurons(yellow) were recorded while monkeys viewed acomputer monitor. Unique visual stimuli wereassociated with different probabilities of a re-ward (a drop of syrup). Rewards were presentedwith different probabilities (P) when the condi-tioned stimulus was switched off (CS offset).Theuncertainty (U) of the reward varied as an in-verted U-shaped function of probability. When P= 0 or P = 1, the monkey is certain that rewarddelivery will or will not accompany CS offset. Incontrast, when P = 0.5, the onset of the CS pro-vides no information about whether reward willor will not occur, but it does predict the potentialtime of reward delivery. The interval betweensuccessive CSs varied unpredictably (not shown),and thus the onset of the CS is the earliest reli-able predictor of the occurrence and/or the po-tential time of reward delivery. Once the mean-ing of the stimuli has been learned, the popula-tion of dopamine neurons responds to CS onsetwith a brief increase in activity when P = 1.0, butreceipt of the expected reward does not provokea strong change in firing. When P = 0, CS onsetproduced little response; if, however, the investi-gator violated expectation by delivering a re-ward, the dopamine cells responded with a brief,vigorous increase in firing.When P = 0.5 (and un-certainty about reward occurrence is maximal), aslow, steady increase in firing is seen prior to thetime of potential reward delivery.C
RED
IT:K
ATH
ARI
NE
SUTL
IFF/
SCIE
NC
E
www.sciencemag.org SCIENCE VOL 299 21 MARCH 2003
P E R S P E C T I V E S
1 s

Apprentissage
0.5
0.8
1.0
Casino
0.5
0.5
0.5
Addiction0.5%
La dopamine est un signal d’apprentissage
Amphétamines Alcool Nourriture
Leyton et al., 2002 Boileau et al., 2003 Small et al., 2003
20% 0.5% ??%
L’activation excessive induit
l’addiction chez certaines personnes
DA
GABA
NAcVTA
i
DA
GABA
Class III
(cocaine, amphetamine, ecstacy)
Class II (benzodiazepines, nicotine, ethanol)
NAcVTA
i
i
T
Increased dopamine
Class I (morphine, THC, GHB)
G
G
DA
GABA
NAcVTA
i
Increased dopamine
(all addictive drugs)
Class I (morphine, THC, GHB)
G
G
Class II (benzodiazepines, nicotine, ethanol)
ii
Class III
(cocaine, amphetamine, ecstacy)
TT
DA
GABAGABA
NAcVTAVTAVT
iiiiiii
IncrIncrIncreased dopamineeased dopamineeased dopamine
(all addictive drugs)
Class I (morphine, THC, GHB)Class I (morphine, THC, GHB)Class I (morphine, THC, GHB)Class I (morphine, THC, GHB)
GG
G
DA
GABA
Class II (benzodiazepines, nicotine, ethanol)
NAcVTA
i
i
Increased dopamine
(all addictive drugs)
Class I (morphine, THC, GHB)
G
G
Récepteurs métabotropes
Récepteurs ionotropes
Transporteurs de la dopamine
Lüscher and Ungless, PLoS Med, 2006
Dopamine
Class I: Drugs that activate G protein coupled receptors
Name Main molecular target Pharmacology Effect on dopamine neurons RR
Opioids µ-OR (Gio) agonist disinhibition 4
Cannabinoids CB1R (Gio) agonist disinhibition 2
!-hydroxy butyric acid (GHB) GABABR (Gio) weak agonist disinhibition NA
LSD, Mescaline, Psilocybin 5-HT2AR (Gq) partial agonist - 1
Class II: Drugs that bind to ionotropic receptors and ion channels
Name Main molecular target Pharmacology Effect on dopamine neurons RR
Nicotine nAChR ("4#2) agonist excitation, disinhibition, modulates release 4
Alcohol GABAAR, 5-HT3R, nAChR, ,
NMDAR, Kir3 channels
excitation 3
Benzodiazepines GABAAR positive modulator disinhibition 3
Phencyclidine, Ketamine NMDAR antagonist disinhibition (?) 1
Class III: Drugs that bind to transporters of biogenic amines
Name Main molecular target Pharmacology Effect on dopamine neurons RR
Cocaine DAT, SERT and NET inhibitor blocks DA uptake 5
Amphetamine DAT, NET and SERT, VMAT reverses transport blocks DA uptake, synaptic depletion,
excitation
5
Ecstasy SERT > DAT, NET reverses transport blocks DA uptake, synaptic depletion NA
Table Legend: The mechanistic classification of addictive drugs. Drugs fall into one of three categories that target either G
protein coupled receptors, ionotropic receptors / ion channels or biogenic amine transporters. RR: Relative risk of addiction
(Science 249:1513-21, 1990); LSD: d-lysergic acid diethylamide; µ-OR: µ-opioid receptor, 5-HTxR: serotonin receptor, nAChR:
nicotinic acetylcholine receptor, GlyR:, NMDAR: N-methyl-D-aspartate receptor, Kir3 channels: G protein inwardly rectifying
potassium channels, DAT: dopamine transporter, NET: norepinephrine transporter, SERT: serotonin transporter, VMAT: vesicular
monoamine transporter
Lüscher and Ungless, PLoS Med, 2006
Classification mécanistique
Récompense
anticipéeAlcool
Addiction
S R S R
1
RenforcementEuphorie/Récompense
Augmentation de la
dopamine
Trois étapes2
DépendanceTolérance
Sevrage
Adaptation
100%
Pre
mie
r co
ntac
t
Jour
s
Moi
s ou
plu
s
3
AddictionContexte
Craving
Rechute
Plasticité synaptique
fraction

• Hallucinogènes (LSD) 1
• Cannabis (THC) 2
• Benzodiazépines (BDZ) 2
• Alcool 3
• Nicotine 3
• Opiacés (Morphine, Héroïne) 4
• Amphétamines 5
• Cocaïne 5
Risque relatif d’addictionGoldstein & Kalant, Science 1990
• Alcool 3
Hérédité versus risque d’addiction
Go
ldm
an e
t al,
Nat
Rev
Genet.
20
05
Plasticité synaptique
mGluR1 GluR1 GluR2 GluR3
Cocaine LTD
Nicotine
Apprentissage maladif
Consommation compulsive
Désir sans plaisir
Cocaïne Jeu Chocolat
Communication neuronale
Libération inappropriée de dopamine
Stephen E. Hyman, Am J Psychiatry. 2005
“Addiction: a disease of learning & memory”
Maladies du cerveau en Europe
Cas
en millions
Coût
en Mia!
Dépression 21 104
Addiction (sans nicotine) 9 57
Démence 5 55
Troubles anxieux 41 41
Schizophrénie 3.5 35
Accident vasculaires 1 22
Epilepsie 3 15
Parkinson 1.2 11
Addiction: une maladie du cerveau
• Nouvelles possibilités thérapeutiques
• contrôler et anticiper les propriétés addictives de molécules pharmacologiques
• inhiber l’activation excessive du système dopaminergique
• corriger la plasticité synaptique pathologique
• Stigmatisation sociale (déculpabilisation,
responsabilité personnelle)
• Prise en charge (accès aux soins)
• Politique de la drogue (législation, répression)
Related Documents