“None of us is as smart as all of us” Prospective Report Japanese Proverb Network-based Distributed Computing (Metacomputing) by Peter Kacsuk and Ferenc Vajda MTA SZTAKI ERCIM 1999

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

“None of us is as smart as all of us”Prospective Report Japanese Proverb
Network-based Distributed Computing
(Metacomputing)
by
Peter Kacsuk and Ferenc Vajda
MTA SZTAKI
ERCIM
1999

2
Contents
1. Introduction2. From Supercomputers to Metacomputing systems
2.1 From parallel supercomputers to clusters2.2 From clusters to metacomputing systems
3. Programming models3.1 Message passing
3.1.1 PVM3.1.2 MPI3.1.3 PVMPI
3.2 Client-server model (remote computing)3.3 Code shipping3.4 Proxy computing3.5 Intelligent mobile agents
4. Distributed system implementation support4.1 Conventional approaches4.2 Object-oriented approaches
4.2.1 Java-based methods4.2.2 CORBA4.2.3 DCOM4.2.4 Comparison of Java/RMI CORBA and DCOM
5. Architecture issues5.1 Three-tier architectures
5.1.1 TP Monitors5.1.2 Distributed objects5.1.3 Web architectures5.1.4 CORBA based three-tier metacomputing system5.1.5 Java and commodity metacomputing
5.2 Network based caching6. Computational Grids and middleware concepts
6.1 Toolkit approach6.1.1 Globus communication model6.1.2 Globus resource management6.1.3 Globus Metacomputing Directory Service
6.2 Object-oriented design approach6.2.1 Programming model6.2.2 The Legion architecture6.2.3 Parallelism in Legion6.2.4 Resource management in Legion
7. Metacomputing programming environments7.1 Toolkit based integrated environment
7.1.1 The PLUS communication interface7.1.2 Resource management (CCS)7.1.3 Resource and service description (RSD)

3
7.2 Application specific environments7.2.1 SCIRun7.2.2 NetSolve
8. Scheduling in metacomputing systems8.1 High-Performance scheduling8.2 High-Throughput scheduling8.3 Resource scheduling
9. Communication media and protocols9.1 ATM9.2 FDDI9.3 Fast Ethernet9.4 TCP/IP9.5 Intenet29.6 QoS
10. System problems10.1 Security10.2 Distributed file systems
10.2.1 NFS10.2.2 AFS10.2.3 OSF-DSF10.2.4 RFS
11. Applications11.1 Enterprise architectures11.2 Selected application areas11.3 Selected European projects
12. Summary and Conclusions13. Used acronyms14. References

4
1. Introduction
Advances in network and computational technology make it possible to construct large-scale high performance distributed computing environments. At the same time emergingapplications require the ability to exploit diverse, geographically distributed resources.New classes of high performance applications are being developed that requirecapabilities not available in a single computer.
The main motivation for metacomputing with respect to supercomputing was driven bygrand challenge problems and by the recognition that the whole can be greater than thesum of the parts, i.e., by connecting heterogeneous computing resources and particularlysupercomputers we may be able to achieve superlinear speedup in case of sufficientlycomplex applications like the grand challenge problems. The most obvious reason forobtaining such superlinear speedup can be that the metacomputer can have much largermemory than the individual supercomputers.
Another motivation for the appearance of metacomputing was the geographicallyseparated clients and their need to collaborate via the network. Such a collaborative workrequires the connection of software and databases developed by different groups andrunning on different machines. It also includes the collaborative access of remoteexpensive resources that can be shared via the network.
The rapid development of network technology made these wishes become everydayrealm though it also raised many new problems to be solved. The two main technologiesfrom which metacomputing systems were originated are the supercomputing technologyand the advanced network technology. In the current study we try to cover both aspects ofmetacomputing systems and to overview the main achievements of metacomputing. Wealso try to show the open problems and trends for the future of metacomputing withrespect to supercomputing and collaborative work.

5
2. From Supercomputers to Metacomputing systems
Supercomputing is originated from the 60s when the first vectorcomputers appeared onthe market with the aim of significantly speeding up vector and matrix based number-crunching scientific computations. Vector machines were soon followed by other types ofsupercomputers like array processors, shared memory symmetric multiprocessors,distributed memory parallel computers, distributed shared memory systems, etc.[SiFK97]. The real breakthrough of using supercomputers took place in the late eightieswhen they became generally accepted and widely used both in the academic world and inthe companies. Their breakthrough was initiated by two major technological advances:
� The new hardware technology resulted in powerful and cheap microprocessorswith the necessary interconnection technology and hence the supercomputers builtfrom these commodity microprocessors became affordable for a large usercommunity.
� The progress in software technology led portable interprocess communicationlayers like PVM [GEIS94] and MPI [GrLS94], optimizing compilers for highlevel scientific languages like High-Performance Fortran [HPFF93], advancedgraphical parallel programming environments like TRAPPER [Baek97] andGRADE [KDFL98].
However, in the early nineties a big competitor of supercomputers has arisen, calledclusters. Though, supercomputers were already affordable their cost was still quite highfor the academic world and hence scientists were searching for a cheaper alternativesolution of achieving supercomputer performance. These efforts led to the introduction ofclusters of PCs or clusters of workstations which became a very successful andcompetitive alternatives of supercomputers [Pfis95], [Turc96], [Bert98]. Interestingly, thesoftware systems of supercomputers and clusters are very similar and hence advances inone platform can immediately be applied in the other one.
Another motivation for replacing supercomputers with aggregation of PCs andworkstations was the low-level utilization of a large number of PCs and workstations incompanies and universities. Software tools like Codine [www12] have been developedfor better utilization of workstations and PCs through the intranet. This NOW (NetworkOf Workstations) systems typically include heterogeneous workstations and/or PCs. Thesoftware techniques introduced in the NOWs are very similar to the ones applied inmetacomputing systems and hence they represent a major step towards distributedparallel systems.
The need for metacomputing had a different motivation and technically it required someother technological innovations mainly in the field of Internet, distributed computing andweb computing. In the mid-nineties application areas were pointed out for which thesingle supercomputers or clusters were not able to deliver the necessary performance. Inparallel, the speed of Internet reached the threshold which made it possible to use theInternet-connected supercomputers and clusters as a single supercomputer from the pointof view of the user. Tasks of a program can be distributed via the Internet to several
6
supercomputers and clusters that can work together in solving a single problem. Suchtechnique is called metacomputing and it practically means (parallel) distributedprogramming over the Internet. In a metacomputing environment supercomputers and/orclusters play the similar role as microprocessors within supercomputers as shown inTable 2.1.
Table 2.1 Comparison of supercomputers, clusters and Metacomputing systemsSupercomputer Cluster NOW Metacomputing
systemProcessing units(nodes)
Microprocessors PCs,workstations
PCs,workstations
Supercomputers,clusters, PCs,workstations
Number ofnodes
100 - 1000 10 - 100 10 - 100 100 - 10000
Communicationnetwork
Buses, switches LAN LAN Internet
Node OS Homogeneous Typicallyhomogeneous
Typicallyheterogeneous
Heterogeneous
Inter-nodesecurity
Nonexistent Rarelyrequired
Necessary Necessary
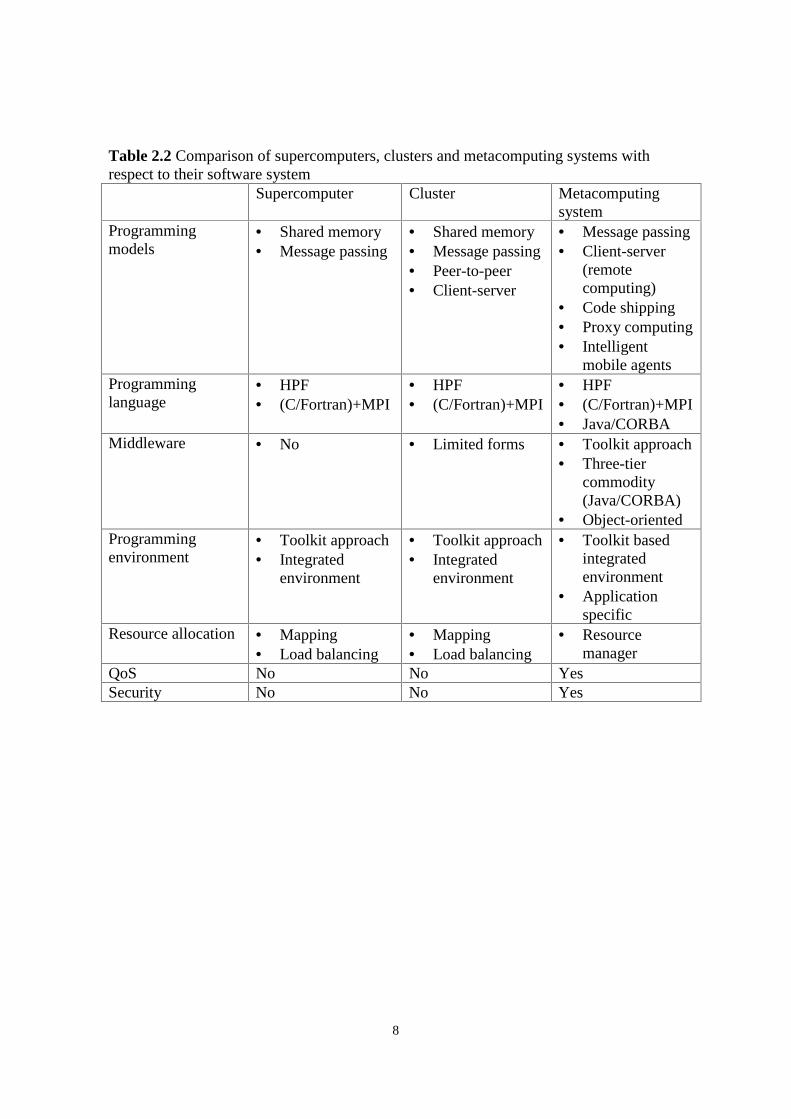
With respect to the software system managing the parallel execution of applicationprograms in supercomputers, clusters and in metacomputing systems there are somesignificant differences shown in Table 2.2 and explained below:
• The programming model of parallel supercomputers is either the shared memory orthe message passing model. Clusters apply the same models and additionally thepeer-to-peer and client-server concepts as described in Section 2.2. In case ofmetacomputing the shared memory model is less used and new computational modelsappeared: code shipping, proxy computing, intelligent mobile agents. These newapproaches opened a new horizon which includes the Web and other new remotecomputational forms.
• According to these models the programming languages of supercomputers are eitherHigh-Performance Fortran (HPF) or C/Fortran together with a message passinglibrary like MPI or PVM. The same holds for clusters, too. In case of metacomputers,on the one hand the conventional approaches (HPF, MPI) can be adapted and used inthe framework of a suitable programming environments. On the other hand newapproaches appeared which should be further developed in the future. One of thesenew directions is the commodity approach which tries to adapt the very successfulJava/CORBA middleware concept for even high-performance distributed systems likemetacomputers.
• Middleware typically appeares in distributed network based systems though in somelimited forms they already existed in clusters and particularly in NOWs, too. Twomain approaches of metacomputing middleware can be distinguished.
1. Toolkit approach which can be considered as a natural extension and furtherdevelopment of the toolkit approach used in clusters.

7
2. Commodity approach which is a natural extension of the three-tiermiddleware concept based on CORBA, Java and the Internet.
3. Object-oriented approach which is somewhere half way between the other twoapproaches. It tries to combine the object-oriented programming style withoutJava and CORBA in a toolkit-like programming environment.
• The programming environments of supercomputers support either the HPF-like or themessage passing programming style. They are typically based on a toolkit approachthough sometimes these tools are integrated into a uniform graphical programmingenvironment. Clusters are not different from supercomputers with respect toprogramming environments. The programming environments of metacomputingpartially follow the toolkit based integrated environment approach of supercomputersand clusters whereby the tools are integrated in a usually graphical programming andsupervising environment. Besides that there is a new direction manifested in theintroduction of application specific environments that restrict the user to a set ofproblem-solving “cliches” which are implemented by specialized strategies in themetacomputing system. These environments try to preserve existing legacy codes andwrap them into a grid-oriented programming style.
• Concerning resource allocation, the critical issues are mapping and load balancingthat influence the performance of supercomputers and clusters in a large extent. Thenodes in a supercomputer and in a cluster are usually dedicated to a parallel programfor the entire run of the program. On the contrary, in a metacomputing environmentthis condition does not hold, supercomputers and clusters of a metacomputing systemhave a privileged owner whose computational needs should be satisfied with highpriority even when tasks initiated from other machines are under execution. Tohandle this issue a sophisticated resource manager software layer should be employedin metacomputing systems.
• Performance monitoring, analysis and visualization are important parts for each of theexamined systems. In the metacomputing environment some special techniquesshould be applied at all levels.
• In a supercomputer and in a cluster the interconnection system among the nodes canbe considered as:
• reliable• providing constant communication throughput.
In a metacomputing environment none of these assumptions are valid and hence aspecial software layer is necessary to tackle these problems. This layer is called QoS(Quality of Service) and plays crucial role in metacomputing systems.
• Messages among nodes of the metacomputing system are transmitted through publicnetwork and hence security issues should be handled in this environment. Nodes ofthe supercomputers are tightly connected while nodes of a cluster are connected byprivate LAN and hence security issues do not appear in those systems.
Clusters and NOWs represent a trade-off between supercomputers and distributedsystems. Clusters and NOWs have many features resembling to supercomputers anddistributed systems as well as features that distinguish them from the other two types ofsystems. In the next sections we compare parallel supercomputers, clusters anddistributed systems.
8
Table 2.2 Comparison of supercomputers, clusters and metacomputing systems withrespect to their software system
Supercomputer Cluster Metacomputingsystem
Programmingmodels
• Shared memory• Message passing
• Shared memory• Message passing• Peer-to-peer• Client-server
• Message passing• Client-server
(remotecomputing)
• Code shipping• Proxy computing• Intelligent
mobile agentsProgramminglanguage
• HPF• (C/Fortran)+MPI
• HPF• (C/Fortran)+MPI
• HPF• (C/Fortran)+MPI• Java/CORBA
Middleware • No • Limited forms • Toolkit approach• Three-tier
commodity(Java/CORBA)
• Object-orientedProgrammingenvironment
• Toolkit approach• Integrated
environment
• Toolkit approach• Integrated
environment
• Toolkit basedintegratedenvironment
• Applicationspecific
Resource allocation • Mapping• Load balancing
• Mapping• Load balancing
• Resourcemanager
QoS No No YesSecurity No No Yes

9
2.1 From parallel supercomputers to clusters
Meanwhile supercomputers have specialized architectures containing usually a largenumber of processors (10-1000), clusters combine ordinary computers typicallyworkstations or PCs. There are two characteristic features of clusters that distinguishthem from parallel supercomputers:
1. A cluster connects complete computers (including processor, memory, I/Ounits).
2. The component computers of a cluster are loosely connected typically by aLAN.
The first property distinguishes clusters from supercomputers since a supercomputer doesnot connect whole computers rather a replicated computer part which is typically theprocessor but in several kinds of supercomputers it could be even memory and cacheunits. Another important distinguishing feature is that the components of a cluster, i.e. theworkstations or PCs are able to work independently of the cluster while replicated partsof a supercomputer cannot be used independently of the supercomputer, they work onlyinside the supercomputer as a structural component of the machine architecture.Supercomputers can be classified according to the replicated parts [SiFK97]. Forexample:
• SIMD (Single Instruction Multiple Data) supercomputers replicate only anarithmetic and logic unit along with some registers and memory.
• UMA (Uniform Memory Access) supercomputers replicate the processors.• NUMA (Non-Uniform Memory Access) machines replicate processor-memory
pairs just like message passing computers.• CC-NUMA (Cache-Coherent Non-Uniform Memory Access) architectures
replicate processor-memory-cache units.• COMA (Cache-Only Memory Access) machines replicate processor-cache pairs.
In fact, if we do not take into consideration the second property of clusters they can beviewed as special case of message passing (distributed memory) supercomputers whereeven the I/O units attached to the processor-memory pairs are replicated. In order todistinguish clusters from this form of message passing supercomputers we need thesecond feature to define clusters. Finally, to make complete the definition of clusters wegive here their third main defining feature:
3. A cluster is utilized as a single, unified computing resource.
This feature does not distinguish clusters from supercomputers on the contrary itexpresses that like supercomputers clusters are also used to solve a single program byparallel techniques.

10
2.2 From clusters to metacomputing systems
The third feature of clusters introduced above can be used to distinguish clusters fromdistributed systems and particularly from metacomputing systems. The workstations of acluster are anonymous to the outside world since the workstations of the cluster together,as a unified computing resource are used to provide requested services. On the otherhand, workstations, supercomputers and other types of host machines as part of adistributed system should be identifiable for the outside world. For example, in ageographically distributed system like a distributed banking system workstations in aparticular branch should be distinguished from workstations operating in an other branch.
Although internal anonymity of cluster components is a distinguishing feature there aremany similarities between clusters and distributed systems. From the point of view ofcommunication, distributed systems have no internal hierarchy they compose a physicallyflat peer-to-peer communication system. However, on top of this flat scheme themachines of a distributed system are organized logically into a two- or three-tierhierarchy according to the client-server concept. We can observe in clusters, too theapplication of both the peer-to-peer and client-server schemes.
In computational intensive clusters a small number of workstations (typically one or two)are dedicated to maintain the file system. In such clusters the distributed file system isrealized according to the client-server principle. The dedicated file server workstationsact as servers and all the other workstations of the cluster request file services as clients.
On the other hand in data-intensive applications such a client-server scheme woulddegrade performance and hence in clusters used for data-intensive applications the peer-to-peer approach is employed. The physical implementation of such a peer-to-peer disksystem could be based on either the shared disk concept or on the shared-nothing conceptwhich is applied in distributed systems, too.
Clusters can work as part of a client-server distributed system in two ways:
1. The cluster plays the role of a high-performance server (compute server or databaseserver depending on the structure of the cluster)
2. In a three-tier architecture the cluster can realize an aggregate of some applicationservers (middle tier) and the data server (third tier) as shown in Figure 2.1.
Clusters and high-performance distributed systems or metacomputers have the same goal:both were created in order to increase performance by connecting whole computers thatwork together to solve a single program. On the other hand they have many differences:

11
1. Clusters are not distributed geographically while metacomputers are.2. Components of a cluster are typically workstations or PCs. Components of a
metacomputing environment can be any kind of computer including supercomputersand even clusters.
3. The cluster is usually homogeneous (though not always), the metacomputing systemis typically heterogeneous (though not always).
4. Components (workstations) of a cluster are anonymous outside of the cluster.Components of a metacomputing system should be individually addressed anddistinguished (just like component workstations in a NOW).
Due to the similarities of clusters and metacomputers many software concepts andtechniques can be inherited from clusters and relatively easily adapted to metacomputers.On the other hand, the differences pointed out above suggest that many new softwareconcepts not applied in clusters should be introduced into the metacomputer systems. Aswe have seen metacomputers are geographically distributed systems and as such theyinherit many approaches from the network based technology of traditional distributedsystems. All these concepts and techniques will be surveyed in the following sections ofthe study.
Client1 Client2 Client3 ClientN
Data server
Cluster
Tier 1
Tier 2
Tier 3
Applicationservers
Figure 2.1. Cluster based three-tier architecture

12
3. Programming models
While in supercomputers and clusters the shared memory concept played an importantrole, it lost importance in metacomputing systems. It is because the price to maintain theshared memory appearance in a wide-area distributed system causes too muchperformance penalty. The message passing paradigm is a natural programming model formetacomputers and hence it is widely used. Besides the traditional message passingapproach, the object-oriented programming gained large popularity mainly in Java andCORBA systems (see Section 4.2). Completely new forms of programming have alsoappeared like remote computing, code shipping, proxy computing and intelligent mobileagents. All these concepts will be introduced and explained in the next sections.
3.1 Message passing
The message passing programming paradigm gained its theoretical foundation by Hoarein the late seventies and was put in practical use by Transputers [MaTW94] and Occam[Inmo88] by the mid-eighties. The theoretical foundation was called CommunicatingSequential Processes [Hoar85] and the main idea was that independent, sequentialprocesses running in parallel can communicate with one another via messages in order tojointly solve a parallel algorithm. By the mid-eighties many other distributed memoryparallel computers were built that also used some form of the message passing paradigmand as a result the shared memory and message passing computational models becamethe two dominating parallel programming paradigms. Since that time an ever runningdebate goes on which is the more preferable one with respect to programming style andefficiency. For symmetric multiprocessors using shared memory obviously the sharedmemory model is the most adequate format of exploiting parallelism. On the other handfor scalable parallel computers, clusters and metacomputing systems the message passingmodel seems to be more natural and appropriate. Since in the current study we focus onmetacomputing systems where the usage of message passing models overrules the sharedmemory one here we omit the introduction of shared memory model.
By the late eighties it turned out that the message passing systems developed by differentvendors and research communities are not compatible and it prevented parallel programsto be portable from one parallel machine to another. This fact became an obviousobstacle of further development of parallel systems. On the other hand distributedcomputing and particularly cluster based computing started to gain popularity whereagain some form of a standard distributed message passing paradigm became necessary.
As a result of these trends two de facto message passing standards have arisen andbecame generally accepted by the mid-nineties. The PVM (Parallel Virtual Machine)communication library [Geis94] was developed to support distributed computing onheterogeneous workstation and parallel computer clusters. The MPI (Message PassingInterface) communication library [GrLS94] was the result of a joint effort of parallelsupercomputer vendors to make compatible their products with respect to portability ofmessage passing parallel programs. Both communication libraries mean that either PVMor MPI programs developed on one particular (single processor or multiple processor)

13
architecture can be moved to another different architecture, compiled and executedwithout modification of the source code.
However, meanwhile PVM supports interoperability the original version of MPI doesnot. It means that PVM executables can communicate with each other and hence a PVMapplication can be ported heterogeneously to run cooperatively across any set of differentarchitectures. An MPI program can run, as a whole, on any single architecture (parallel ornot) and is portable only in that sense. Due to the lack of interoperability MPIimplementations are more efficient than PVM ones and as a result, recently MPI andespecially MPI-2 seems to be getting more popularity over PVM.
When metacomputing research started, the lack of interoperability in MPI became acrucial issue and focus point of improving MPI. Several projects were initiated in order toextend MPI with the interoperability feature. Among them we have to mention thefollowing four approaches:
1. PVMPI [www31]PVMPI is a current effort to combine the PVM and MPI approaches in a way thatinherits the best properties of both communication libraries. The main goal ofPVMPI is to interface the flexible process and virtual machine control facilities ofPVM with the enhanced communication system of MPI implementations.
2. PACX-MPI [Eick98]PACX-MPI is an extended library of MPI to realize communication between twoMPPs based on the TCP/IP standard protocol. Each MPP has to provide two extranodes for the external communication, one for each direction. While one of thenodes is always waiting for MPI commands from inner nodes to transfer messageto the other MPP, the other node is executing MPI commands received from theother MPP.
3. Local Area Multicomputer MPI (LAM / MPI) [www32]LAM is an MPI program development environment for heterogeneous computernetworks. A cluster or a network system can behave as a single parallel computerby applying the LAM/MPI environment.
4. Interoperable MPI (IMPI) [www33]IMPI is an industrial-led effort to create a standard to enable interoperability ofdifferent implementations of MPI.
Nevertheless, both PVM and MPI became very successful and generally accepted by theinternational user community. Many parallel application programs and packages werewritten on top of PVM and MPI which proved to be more efficient than their equivalentshared memory based packages.
When metacomputing research started in the mid nineties PVM and MPI were well-established standards and hence they were considered as a useful programming

14
communication concept for distributed programming of metacomputers. In the nextsections we briefly overview and compare PVM and MPI and show their combinedversion called PVMPI.
3.1.1 PVM
The central concept of PVM was the notion of a “virtual machine” that enables the usageof a heterogeneous system containing different types of computers includingworkstations, clusters and parallel supercomputers to appear logically to the user as asingle parallel computer. If we compare this idea with the concept of metacomputingsystems the similarity between the two approaches is evident. The aim in both cases is togive the view to the user of working on a single computer.
The other important issue in PVM design was the highest possible level of support forinteroperability both at the programming language level and in the communicationsystem. PVM enables for Fortran and C programs to interoperate by sending messages toeach other. PVM executables can also communicate with each other no matter on whichtype of computer runs them. PVM provides the necessary message format transformationto hide differences in computer architectures. PVM implementations exploit nativecommunication functions for local communications and for remote but homogeneousarchitecture communications. However, when communication is performed betweenvarious types of hosts PVM applies the standard network communication functions. Thisdistinguished implementation of communication requires the continuous checking ofcommunication destinations which entails some performance losses in the PVMimplementations compared to MPI ones.
The PVM implementation is based on daemon processes that maintain the virtualmachine view and provide the interprocess and interhost communication. The daemonprocesses also can be used to create a system-wide unique context tag to provide ageneral context based communication model similar to MPI.
PVM provides a dynamic programming environment where both processes and hosts(computing resources) can be dynamically added or deleted either from the applicationprogram or from a system console. PVM supports naming services so independentlycreated processes can find each other and can communicate. All these dynamic featuresprovide a good framework for efficiently handling load balancing, task migration andfault tolerance.
PVM daemons are responsible among others for providing name services. The basicmechanism of identifying independently created processes under PVM is based onmessages which are created by processes, supplied with an associated key (user definedname) and sent to the name server daemons. These names are stored by the daemonswhich can accept inquiring messages from other tasks that look up a name. Two tasksmay not insert the same name since the second attempt returns with an error.

15
PVM can inform those processes that posted notifies for a given I/O server when the I/Oserver exits the virtual machine. Then the processes can reconfigure themselvesaccording to the remaining resources. The processes are also notified when a new serveris entered in the virtual machine. This scheme has been exploited in several resourcemanager systems like for example Condor [LiLM88].
Fault tolerance is particularly important for a large scale parallel program that runs forhours or even days on a large number of workstations that might be rebooted or crashedduring the program execution. In such cases the system should provide gracefuldegradation or at least an automatic scheme to identify faulty system components. PVMhas some built-in facilities to handle process failures. When a process fails PVM can senda special event message for the processes that expect to receive messages from the failedprocess.
3.1.2 MPI
MPI provides the following main features:
• A large set of point-to-point communication routines for communication betweenprocesses belonging to the same process group.
• A large set of collective communication routines for communication amongprocess groups.
• The communicator concept that ensure safe usage of communication libraries.• The concept of communication topologies.• Creation and communication of derived data types from non-contiguous data.
The fundamental innovation in the MPI communication concept is the introduction of thenotion of communicator which is a binding between a communication context and agroup of processes. It makes application process communication safe and separate fromthe communication of processes in a communication library. In the MPI approach point-to-point process communication is allowed only within a group and for each group thereis a unique communicator allocated by MPI.
The two main advantages of MPI over PVM are the following:
• Since interoperability is not supported by MPI it can completely exploit nativecommunication systems of parallel computers and hence its implementation issignificantly more efficient than the one of PVM.
• It provides a much richer set of library functions for point-to-point and collectivecommunication operations than PVM. It also supports the definition ofcommunication topologies and message formats based on derived data types.
As opposed to PVM, MPI does not support interoperability either among differentlanguages or in the intercommunication layer of various computer architectures. MPIrepresents a static world which lacks of dynamic process creation and allocationfacilities, naming service and fault tolerance support.

16
These drawbacks are partially eliminated by MPI-2 which introduces some forms ofdynamic process handling into the MPI world. For example, the MPI-2 standard enablesdynamic process creation but still has no mechanism to recover from the failure of aprocess. MPI-2 enables independent processes to synchronize and form an inter-communicator among them.
3.1.3 PVMPI
As it was shown both PVM and MPI have their particular advantages and drawbackscomparing them. PVM has many features required for operation on a distributedheterogeneous systems where reliability is more important than optimal performancewhile MPI provides high-performance communication but in the framework of a non-flexible static process model.
The most important problem of MPI is the lack of interoperability which excludesdifferent MPI application programs to communicate by message passing. The only viablealternative of communication is the shared use of other mediums like for example cross-mounted file systems.
The remedy offered by PVMPI for this problem is the combination of MPI and PVMprocess groups in a way that static MPI groups can dynamically join and leave PVMgroups that serve as communication relay stations for the MPI application processgroups.
The PVMPI system shows many important future directions for improving messagepassing based programming of heterogeneous distributed systems including NOWs andmetacomputers. The main advantages of the PVMPI concept are as follows:
� The user is not forced to run the whole application on a single system with asingle implementation as it was the case in MPI. The PVMPI user can createsections of an application from different MPI implementations that matchdifferent hardware architectures. This feature makes PVMPI a good candidate forprogramming metacomputing systems.
� In its simplest operating mode PVMPI requires only two or three additional callsto provide full interoperability between entirely different MPI and PVM systems.
3.2 Client-server model (remote computing)
In the client-server or remote computing model [Orfa96] participants of themetacomputing system are divided into two main classes:
• Clients• Servers

17
Clients initiate computations or more generally information processing to solve aproblem. The servers provide code and databases to solve the problems of the client. Theprocess of solving a client’s problem takes place in three steps:
• The client sends the request with the necessary parameters to one of the servers.(The selection of the server could be determined either by the client or in moreadvanced cases by the metacomputing system according to system parameters likeavailability of servers, current load of the servers, etc.)
• The serves processes the request of the client according to the parameters of therequest.
• The servers sends back the results of the executed request to the client.
This logical level of execution model is built on top of the physically peer-to-peerorganization of the computers composing the metacomputing environment. In fact theclient-server model has the roots back to network based distributed processing andrepresents a major step towards metacomputing. In its original form clients and serverswere physically distinguished in the distributed environment. Server computers wereintroduced to give special services (like file servers, database servers, etc.) to a largenumber of usually smaller client machines (typically workstations and PCs). However,the client-server concept could also be considered as an execution model at the logicallevel which can be built on top of the physically peer-to-peer structures of the computerscomposing the computing environment. Actually it happened to the workstation clustersand this logical view can be applied in metacomputing systems, too wheresupercomputers might play dynamically the role of clients and servers at differentcomputations.
3.3 Code shipping
A further step towards the most general network based computational model, i.e., mobileagents is code shipping. In this model the concept of clients and servers diminishes,instead a peer-to-peer organization appears where all computing sites play a symmetricrole in the metacomputing system. Any computing site can dynamically play the role of acode-requestor or a code-provider. The scheme of problem solving now consists of thefollowing steps:
• The code-requestor requests the necessary code to solve the problem.• The code-provider ships the requested code to the code-requestor.• The code-requestor solves the problem with the shipped code on its local data.
The Java applets represent a well-known form of code shipping where such a model isdirectly supported by a programming language.
Code shipping is beneficial when the local data to be processed is much bigger than theprocessing code. In a client-server system the whole local data should be transmitted tothe server which holds the processing code and executes it on the received data.Obviously in case of large data sets the transmission time of data and results would take

18
much more time than code shipping. On the other hand the processing power of the code-requestor and code-provider should be comparable otherwise in case of a slow code-requestor machine the execution of the shipped code would slow down the wholecomputation. In a metacomputing system such parameters as the processing power ofcomputers, network bandwidth and throughput, data and code size should be taken intoconsideration when the scheduler decides where and how to execute codes.
3.4 Proxy computing
Proxy computing is an extension of code shipping whereby not only code but also thenecessary data can be shipped to a computational server of the metacomputing system.The steps of proxy computing are as follows:
• Code and data are transferred to a computational server. (Code can be local to theinitiator or can be provided by a third party.)
• The computational server executes the code on the received data.• The computational server transfers results to the initiator.
The computational server could be any site of the metacomputer (peer-to-peerorganization) or it could be a selected site like in client-server systems. NetSolve (Section7.2.2) supports a limited form of proxy computing while Globus (Section 6.1) codemanagement services and Legion (Section 6.2) vaults provide a more complete supportfor this computational model.
3.5 Intelligent mobile agents
Traditional RPC (Remote Procedure Call) APIs are static in their nature and as such notwell adapted to the dynamic and changing environment. As opposed to the traditionalclient-server synchronous RPC paradigm, the mobile agent technology opens the way toa new, asynchronous decentralized system approach. Mobile agents are autonomoussoftware entities that are able to move from one physical location to another meanwhileacting on behalf of its creator [BuCL99]. Advanced middleware provide mechanisms tomigrate agents’ codes and execute them on different networked hosts. Intelligence is thesecond major aspect of agent technology. It includes the capability of co-operating withother agents, dealing with exceptional situations, adaptation to changes in the network,and so on. In order to implement these features advanced AI techniques are applied in themobile agent technology.
We can conclude that the ultimate solution for a perfectly symmetric metacomputingsystem is the application of intelligent mobile agents. These agents should decide whereto move the code and data and where to execute the requested code or service. In order tosupport the decision making mechanism of such intelligent mobile agents a databaseshould be maintained on the system and resource parameters of the metacomputer. Basedon this information the agent can decide the optimal execution site for a particular sub-problem and assures the move of code and/or data (if necessary) to the selected site.

19
4. Distributed system implementation support
4.1 Conventional approaches
The conventional approaches try to adapt the well-known parallel programmingparadigms (message passing, shared memory), languages (HPF, C, C++) [Vajd98] andcommunication libraries (PVM, MPI) into the metacomputing environment [www5].They do not introduce any new language from the point of view of the end-users. Instead,it is the task of the metacomputing system developer to provide special tools that enablethe employment of these well-known techniques in the new enhanced environment. Avery characteristic example is the Globus toolkit approach (see Section 6.1) that extendsthe usability of MPI over the Internet in order to adapt existing MPI programs formetacomputing applications. However, a number of compiler and runtime environmentdifficulties may arise when the conventional approaches are tried to use in ametacomputing system:
• Adaptive, irregular decomposition techniques to data structures becomenecessary in the dynamically changing, heterogeneous configuration ofmetacomputers. Conventional programming languages miss these techniques.
• Latency management by the compiler becomes a crucial issue. The compilershould generate code where access operations to remote data are initiatedmuch earlier than access operations to memory on the same node.
• Runtime performance estimation will be necessary in order to support goodload balancing during program execution.
• Support for program decomposition and task assignment to nodes in the targetmetacomputer will be important.
A common framework to solve these problems could be the introduction of very high-level graphical languages like GRAPNEL [KaDF98] where program decomposition,communication primitives (like PVM and MPI calls) and task assignment to networktopologies are intensively supported by graphics. Moreover the language concept can besystematically extended to a graphical programming environment where all the necessarysupport tools like distributed debuggers [Kacs99], performance monitors [Mail95] andvisualization tools [HeEt91] are integrated. An example of such an integratedenvironment is GRADE [KDFL98] which is built on top of GRAPNEL and wasdeveloped for NOWs, clusters and supercomputers but can easily be extended formetacomputers. Its compiler gives efficient support for performance analysis and tuningin two ways:
1. It provides calls to the performance monitoring system at critical points,which can be defined either by the user or automatically by the system.
2. It provides click-back and click-forward facilities which help to mapperformance information back to the source code when it is visualized afterexecution.

20
Similar methods has been established for data parallel HPF programs in [Adve95]. Wecan conclude that the conventional approaches can be used in the new metacomputingsystems if the support tools and environments introduced for supercomputers, clustersand NOWs are generalized and adapted for metacomputers.
4.2 Object-oriented approaches
The basic OO concepts [www4] of data encapsulation, inheritance and polymorphismprovide a solid basis to separate the specification of computation from the way thatcomputation is implemented. Currently, three major systems use object-oriented conceptsfor distributed applications:
- Java-based methods- Common Object Request Broker Architecture (CORBA)- Distributed Common Object Model (DCOM)
4.2.1 Java-based methods
The Java-based distributed computing technology provides many different but relatedtechnologies to solve critical distributed application problems. For example, the Javaprogramming language, the JDK (Java Development Kit) software and the Java RMI(Remote Method Invocation) technology provide a consistent programming platform thatsimplifies distributed application development. Here only very short descriptions of theJava-based components are given.
The Java Virtual Machine (JVM)It is an abstract computer that runs compiled Java programs [www9] It is virtual becauseit is generally implemented in software on top of the host “real” hardware platform andoperating system. The different versions of the Java Development Kits (JDKs) emulatethe Java Virtual Machine on different platforms (e.g. Win32, Solaris, MacOS). Efficientnative code can be generated using a JIT (Just-in-Time) VM.. It is essentially a compilerback end, which reads byte code and generates native code. Combining profiling andcompiling a dynamic compiler (e.g. HotSpot) can further improve the execution speed.JVM may also be implemented in microcode, or directly in silicon. The main features ofthe Java Virtual machine include the basic structure of the virtual hardware (stack,garbage-collected heap and the method area).
BytecodeJava bytecode is the machine language of the JVM, i.e. a platform-independentinstruction set. Bytecode is translated, on the fly, into platform specific machine codeinstructions. Because bytecodes were specifically designed for translation to machinecode, Java programs tend to be significantly faster than other interpreted languages.
Remote Method Invocation (RMI)Java RMI is a mechanism that allows one to invoke a method on an object that exists inanother address space. This could be on the same machine or on a different one. RMI

21
mechanism is basically an object-oriented RPC (Remote Process Call) mechanism. Ituses the “Write once, Run Anywhere” model [www8]. The main advantages are: mobile,safe and secure, easy to write and use.
Applet and ServletApplets are small programs (to be downloaded) that run on the client machine whileServlets are small platform-independent programs [www3] to extend the functionality ofa server.
JavaBean and JavaSpacesJavaBean [www7] [Entr98] is a “prefabricated”, reusable software component (e.g. pushbuttons, scrollbars, text boxes, etc.) that can be visually manipulated in builder tools.JavaSpaces [Java98] architecture helps solving problems related to distributed persistence(providing a mechanism for storing a group of related objects and retrieving them basedon a value-matching lookup) and design of distributed algorithms (based on the "flow ofobjects" approach).
JiniA Jini system [Wald98] is a distributed system based on the idea of federating groups ofusers and resources required by the users. Resources can be implemented as eitherhardware devices, software programs or the combination of the two. A Jini systemconsists of the following parts:
- Infrastructure (set of components)- Programming model (to support distributed services)- Services (Jini federation, that can be used by a person, a program or another
service)
4.2.2 CORBA
CORBA (Common Object Request Broker Architecture) [www1] is an open distributedobject computing infrastructure standardized by OMG (Object Management Group).Figure 4.1 illustrates the primary components in the OMG Reference Model architecture.
• Object Services: Domain independent interfaces to discover for example otheravailable services like- Naming Service: to find objects by name- Trading Service: to find objects by property
• Common Facilities: also horizontally oriented but towards end-user applications(e.g. document processing)
• Domain Interfaces: oriented towards specific domains (e.g. financial,telecommunications, manufacturing, etc.)
• Application Interfaces: not standardized interfaces for specific applications
The primary components of CORBA ORB architecture components are:

22
- Object Implementation: it defines operations that implement a CORBA IDL(Interface Definition Language) interface. They can be written in any objectoriented or not object oriented languages (e.g. Java, C, C++, Ada, Smalltalk,etc.)
- Client: it is a program entity that invokes operations on an object implementation.Remote objects are transparent to the calling client and the client knows onlythe logical structure of the object according to the interface.
- ORB (Object Request Broker): it provides a mechanism for transparentlycommunicating client requests to target object implementations. It simplifiesdistributed programming by decoupling the client from the details of themethod invocations. The client requests may appear to be local procedurecalls.
- OMG IDL (Interface Definition Language): it defines the type of the objects byspecifying their interfaces. It consists of a set of named operations andparameters.
- CORBA IDL stubs and skeletons: they serve as “glue” between ORB and theclients (stub) and servers (skeleton), respectively.
- DII (Dynamic Invocation Interface): it allows the dynamic construction of objectinvocations and to directly access the request mechanism provided by theORB.
- DSI (Dynamic Skeleton Interface): it is the server side’s analogue to the clientside’s DII. It allows an ORB to deliver requests to an object implementationthat does not have compile time knowledge of the type of the object.
- Object Adapter: it is the primary way that an object implementation accessservices provided by the ORB.
- ORB Interface: it is an abstract interface, which is the same for all ORBs.Because most of functionality of ORB is provided through the object adapter,stub, skeleton or dynamic invocation only a few operations are availablethrough this interface, which are useful to both clients and implementations ofobjects.
- Interface Repository: it is a service that provides persistent objects that representthe ideal information in a form available at runtime. This information may beused the ORB to perform requests.
- Implementation Repository: it contains information that allows the ORB tolocate and activate implementations of objects.
Object Request Broker
Object Services
DomainInterfaces
ApplicationInterfaces
CommonFacilities

23
Fig. 4.1 The OMG Reference Model

24
4.2.3 DCOM
DCOM [Dcom96], the distributed extension of the Component Object Model (COM)grew from Microsoft’s work on OLE (Object Linking and Embedding) compounddocument standard. COM components use standardized interfaces and methodologies topass data. Microsoft calls DCOM “COM with a long wire” because it uses the samemethodology to talk across networks that is used to run inter process communication onthe same machine. Here only a number of key features of DCOM are summarized:
- Unlike CORBA objects, which execute in a particular language, COMcomponents use standardized interfaces and methodologies to pass data.
- It supports objects with multiple interfaces. A globally unique identifier(GUID) called the interface ID is assigned to each interface. Similarly aunique class ID is assigned to each objects.
- It is based on RPC (Remote Procedure Call) standards developed for DCE(Distributed Computing Environment) standards. Called Object RPC, it canuse TCP for guaranteed connectivity or UDP (User Datagram Protocol) forconnectionless transfer. The Open Group controls DCE, which is the sameindustry consortium to which Microsoft is guaranteed the right to standardizeCOM and DCOM.
More details could be found in the section “Comparison of Java/RMI, CORBA andDCOM".
4.2.4 Comparison of Java/RMI, CORBA and DCOM.
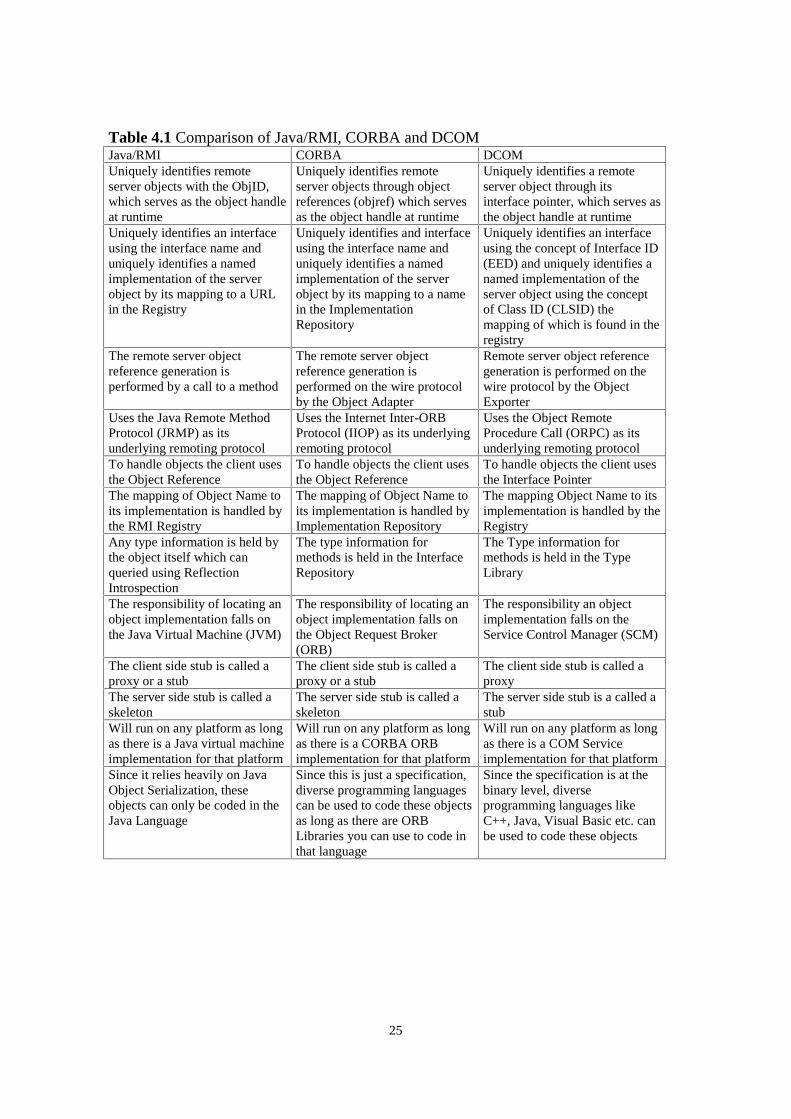
The architectures of Java/RMI, CORBA and DCOM provide mechanism for transparentinvocation and accessing remote distributed objects. Though the mechanisms that theyemploy to achieve remoting may be different, the approach taken by each of them is moreor less similar. (See Table 4.1.)
25
Table 4.1 Comparison of Java/RMI, CORBA and DCOMJava/RMI CORBA DCOMUniquely identifies remoteserver objects with the ObjID,which serves as the object handleat runtime
Uniquely identifies remoteserver objects through objectreferences (objref) which servesas the object handle at runtime
Uniquely identifies a remoteserver object through itsinterface pointer, which serves asthe object handle at runtime
Uniquely identifies an interfaceusing the interface name anduniquely identifies a namedimplementation of the serverobject by its mapping to a URLin the Registry
Uniquely identifies and interfaceusing the interface name anduniquely identifies a namedimplementation of the serverobject by its mapping to a namein the ImplementationRepository
Uniquely identifies an interfaceusing the concept of Interface ID(EED) and uniquely identifies anamed implementation of theserver object using the conceptof Class ID (CLSID) themapping of which is found in theregistry
The remote server objectreference generation isperformed by a call to a method
The remote server objectreference generation isperformed on the wire protocolby the Object Adapter
Remote server object referencegeneration is performed on thewire protocol by the ObjectExporter
Uses the Java Remote MethodProtocol (JRMP) as itsunderlying remoting protocol
Uses the Internet Inter-ORBProtocol (IIOP) as its underlyingremoting protocol
Uses the Object RemoteProcedure Call (ORPC) as itsunderlying remoting protocol
To handle objects the client usesthe Object Reference
To handle objects the client usesthe Object Reference
To handle objects the client usesthe Interface Pointer
The mapping of Object Name toits implementation is handled bythe RMI Registry
The mapping of Object Name toits implementation is handled byImplementation Repository
The mapping Object Name to itsimplementation is handled by theRegistry
Any type information is held bythe object itself which canqueried using ReflectionIntrospection
The type information formethods is held in the InterfaceRepository
The Type information formethods is held in the TypeLibrary
The responsibility of locating anobject implementation falls onthe Java Virtual Machine (JVM)
The responsibility of locating anobject implementation falls onthe Object Request Broker(ORB)
The responsibility an objectimplementation falls on theService Control Manager (SCM)
The client side stub is called aproxy or a stub
The client side stub is called aproxy or a stub
The client side stub is called aproxy
The server side stub is called askeleton
The server side stub is called askeleton
The server side stub is a called astub
Will run on any platform as longas there is a Java virtual machineimplementation for that platform
Will run on any platform as longas there is a CORBA ORBimplementation for that platform
Will run on any platform as longas there is a COM Serviceimplementation for that platform
Since it relies heavily on JavaObject Serialization, theseobjects can only be coded in theJava Language
Since this is just a specification,diverse programming languagescan be used to code these objectsas long as there are ORBLibraries you can use to code inthat language
Since the specification is at thebinary level, diverseprogramming languages likeC++, Java, Visual Basic etc. canbe used to code these objects

26
5. Architecture issues
Metacomputer systems contain supercomputers, workstations, workstation clusters,NOWs, database and other server computers connected by the Internet. Therefore, ametacomputer system is a heterogeneous, parallel distributed system. The mainarchitecture issues are how to organize logically these computers in order to achievehigh-performance system both for computation- and data-intensive applications.
5.1 Three-tier architecture
Client-server systems can be realized either by 2-tire or 3-tier architectures. In 2-tierclient-server systems, the application logic is embedded either in the client or the serverprogram creating either fat client or fat server. Recently a trend to separate theapplication logic both from the clients and servers can be observed. This approach led tothe 3-tier client-server systems where between the client and server tiers a new tierrealizing the application logic has been introduced. This separation of the
� GUI front-end (client)� Application logic� Back-end resource manager (server)
has the positive effect of creating more scalable, robust and flexible distributed systems.Examples of resource managers include SQL databases, hierarchical databases, documentstores, HTML stores, legacy application, etc. Typical examples of the 3-tier client-serversystems are the TP Monitors, distributed objects and the Web.
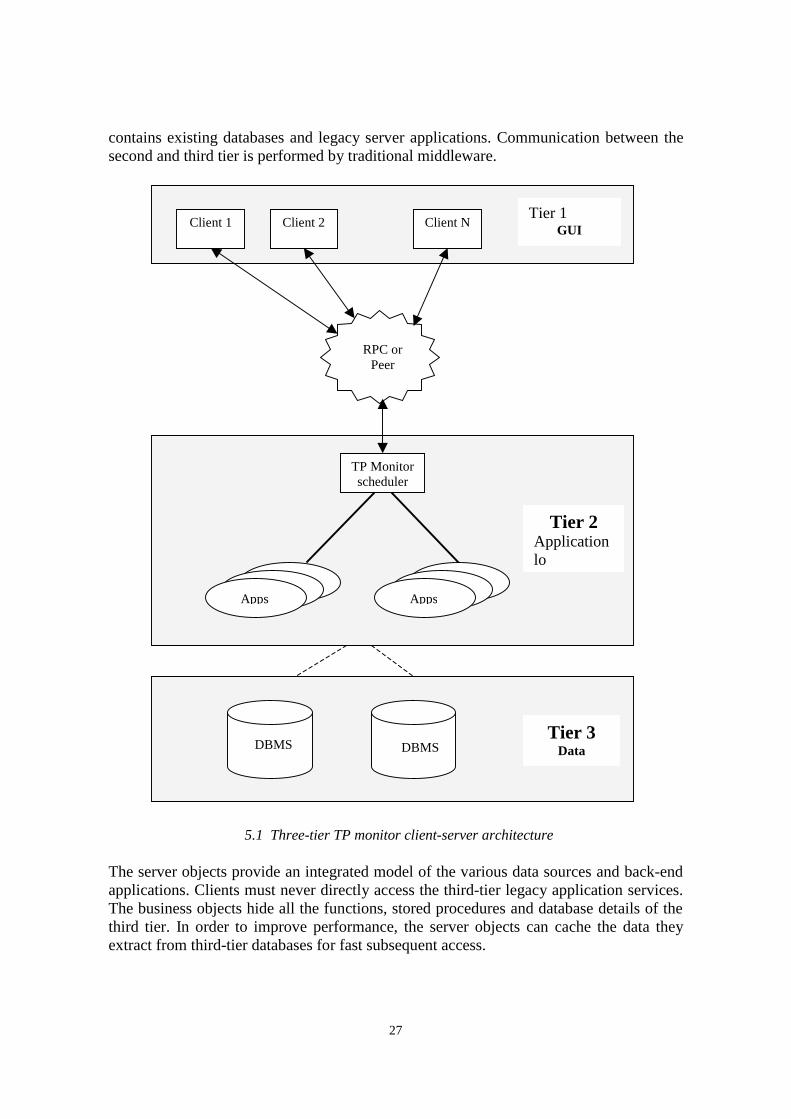
5.1.1 TP Monitors
TP (Transaction Processing) monitors well fit the 3-tier architecture model since they canmanage in the second tier the application processes concurrently and independently fromthe client front-ends (first tier) and the databases (third tier) as it is illustrated in Figure5.1. TP monitors are able to give service for hundreds (or even thousands) of clientsensuring that the transactions are completed accurately. Moreover they provide loadbalancing and can significantly improve the overall system performance. The 3-tier TPmonitor architecture represents a large step towards a distributed heterogeneousinformation system.
5.1.2 Distributed objects
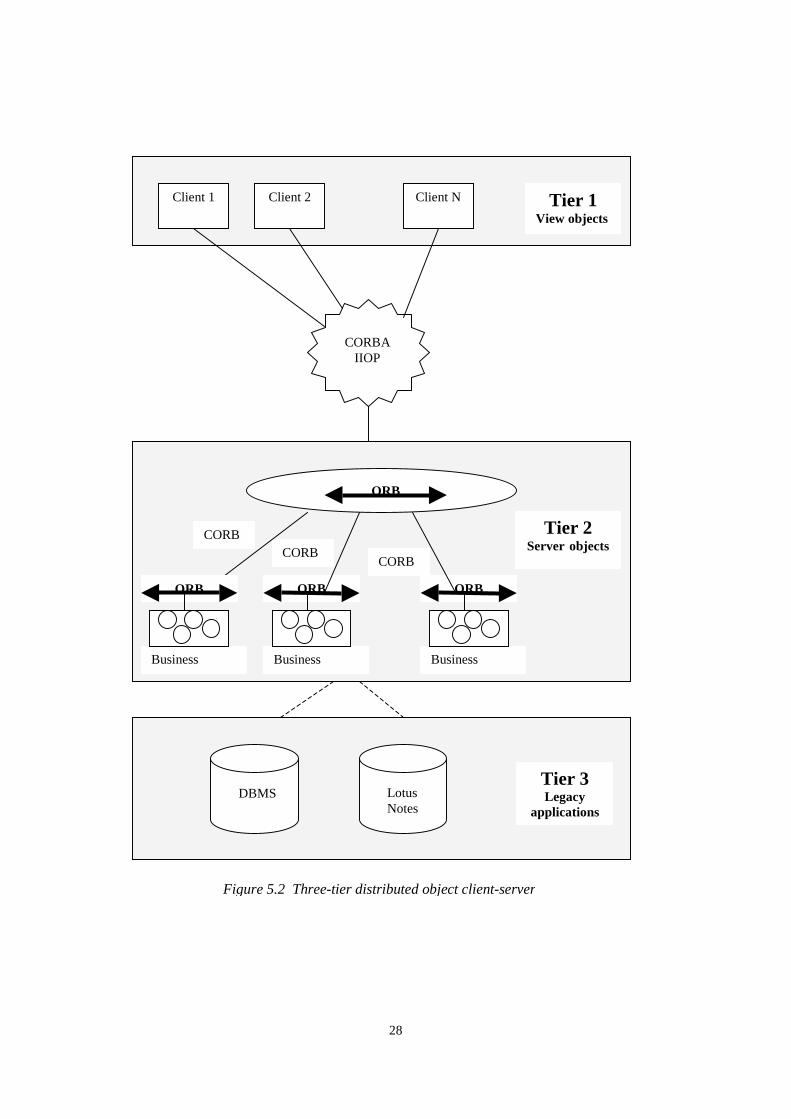
Due to their inherently decomposable feature business objects implemented in CORBA(see Section 5.1.4) are ideal for creating scalable 3-tier client-server architectures asshown in Figure 5.2. The first tier contains the visual objects that typically live on theclients. The middle-tire server objects represent persistent data and the business logicfunctions. These tiers communicate via a CORBA IIOP, while middle-tire objectsinteract with each other via a server ORB (Object Request Broker). The third tier
27
contains existing databases and legacy server applications. Communication between thesecond and third tier is performed by traditional middleware.
The server objects provide an integrated model of the various data sources and back-endapplications. Clients must never directly access the third-tier legacy application services.The business objects hide all the functions, stored procedures and database details of thethird tier. In order to improve performance, the server objects can cache the data theyextract from third-tier databases for fast subsequent access.
5.1 Three-tier TP monitor client-server architecture
Client 1 Client 2 Client NTier 1
GUI
Tier 2Applicationlo
RPC orPeer
DBMS DBMSTier 3
Data
TP Monitorscheduler
Apps Apps
28
Client 1 Client 2 Client N Tier 1View objects
ORB
ORB ORB
Tier 2Server objects
CORBCORB
CORB
ORB
Business Business Business
CORBAIIOP
DBMS LotusNotes
Tier 3Legacy
applications
Figure 5.2 Three-tier distributed object client-server

29
5.1.3 Web architectures
The basic Web architecture is two-tiered and characterized by a Web client that displaysinformation content and a Web server that transfers information to the client. This basicarchitecture is based on three key standards:
1. HTML (Hyper-Text Markup Language) encoding document content (hypertext)2. HTTP (Hyper-Text Transfer Protocol) as an application-level network protocol to
transfer information3. URLs (Uniform Resource Locator) naming remote information objects in a global
namespace.
The basic Web architecture is fast evolving to serve a wider variety of needs beyondstatic document access and browsing. CGI (Common Gateway Interface) is the mostcommon approach to client-initiated programs. It uses a standardized method for passingdata from a client to a server.
APIs (Application Programmer’s Interface)offer a proprietary means to interact with aserver. These programs are designed to run under a given server (and are based on a setof programming commands that can be accessed using a compatible programminglanguage).
JavaScript was the first major technology that brought power to the Web. These scriptsare small programs that interact with the browser and the content of a page. JavaScript ispoised to do for Web publishing what Visual Basic did for Windows programming. (Verymany “prefabricated” scripts are available from different script repositories). A similarsolution is the VBSript (borrowed its initials from Visual Basic).
Applets are small programs downloaded to run on a client machine. Applets are compiledto a platform-independent bytecode and can be safely downloaded and executed by aJVM (Java Virtual Machine - implemented as an interpreter or directly in silicon). Ifperformance is critical, Java applet can be compiled to native machine language on thefly. Such a compiler is called as a JIT (Just In Time ) compiler.
The Web also builds on many additional standards. For example, GIF (GraphicsInterchange Format), JPEG (Joint Photographers Expert Group) image formats, VRML(Virtual Reality Modeling Language) for describing multi-participant interactivesimulations.
Servlets are to the server what applets are to the client – small Java programs compiled tobytecode that can be loaded dynamically to extend the capabilities of the host. Other“prefabricated” software (mostly graphical components) are called JavaBean to becomposed together into applications by the user.
Since 1994 the three-tier Web architecture has been going through a rapid progressconsisting of the following main steps:

30
1. Using graphical Web browsers and hyperlinks2. Introducing forms, tables and CGI3. Appearance of secured transactions including SSL, S-HTTP, firewalls and E-cash4. Combining Java and the Web including applets and mobile components5. Integrating distributed objects and the Web including orblets, compound
documents, ActiveXs, CORBA and Cyberdog
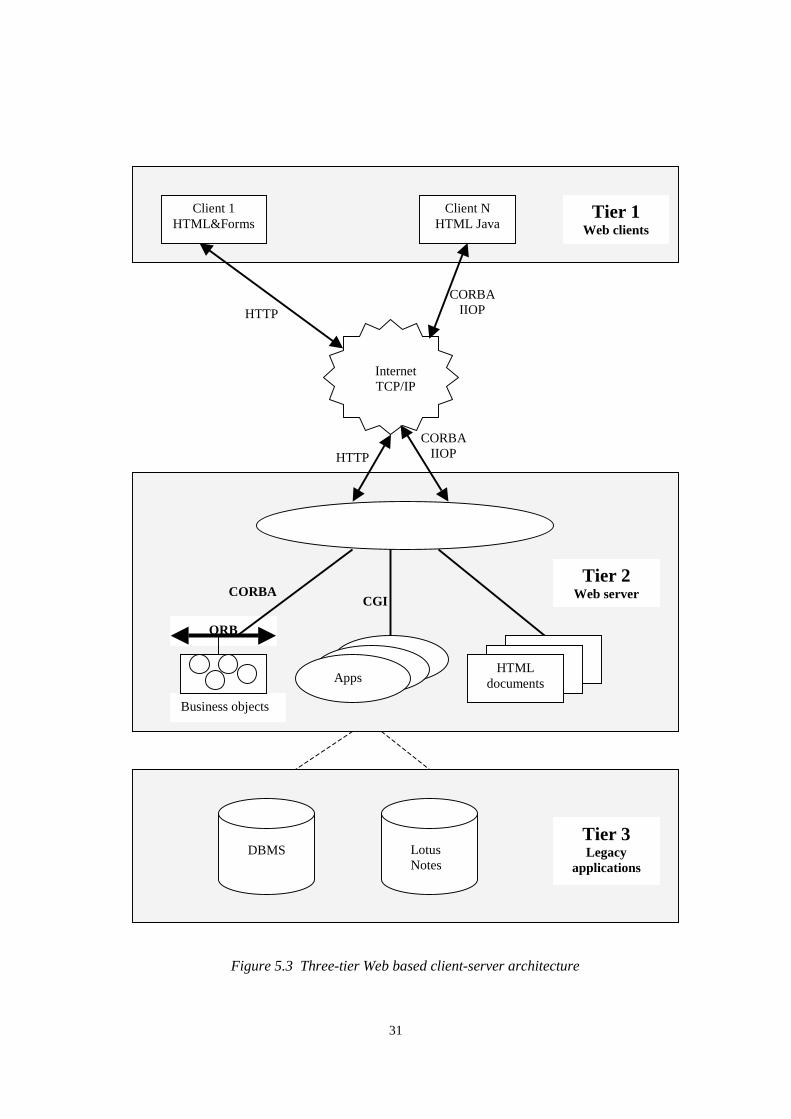
The current state-of-the-art of the three-tier Web architecture integrates CORBA and JavaWeb as it is shown in Figure 5.3. It contains Java clients in the first tier, CORBAbusiness objects in the second tier and additional servers like database, TP monitors andgroupware servers in the third tier. In such an architecture the Java client can directlycommunicate with a CORBA object using the Java ORB and in this way the previousHTTP/CGI middleware is replaced by the more general CORBA system. Thecommunication backbone is the Internet since both HTTP and CORBA IIOP uses theInternet services. HTTP is used to download Web pages, applets and images whileCORBA IIOP is used for Java client-to-server communications. Java clients withoutCORBA cannot communicate across processes. The integrated system shown in Figure5.3 solves this problem, too.
31
CORBAIIOPHTTP
Client 1HTML&Forms
Client NHTML Java
Tier 1Web clients
Tier 2Web server
InternetTCP/IP
DBMS LotusNotes
Tier 3Legacy
applications
Figure 5.3 Three-tier Web based client-server architecture
AppsHTML
documents
HTTP
CGI
CORBAIIOP
ORB
Business objects
CORBA

32
5.1.4 CORBA based three-tier metacomputing system
The commodity approach of creating metacomputer systems assumes that the three-tierclient-server commodity architecture can and should form the basis of high-performancemetacomputing systems [FoFu99]. In this approach the main goal is to create a high-performance computing enhancement in the third tier as a specialized service towardshigh-performance needs. The advantage of this strategy is that it isolates the high-performance computing issues from the control or interface issues in the middle layer. Inthis way, the high-performance metacomputing environment can evolve together with thethree-tier commodity systems without requiring significant reengineering as newcommodity products appear.
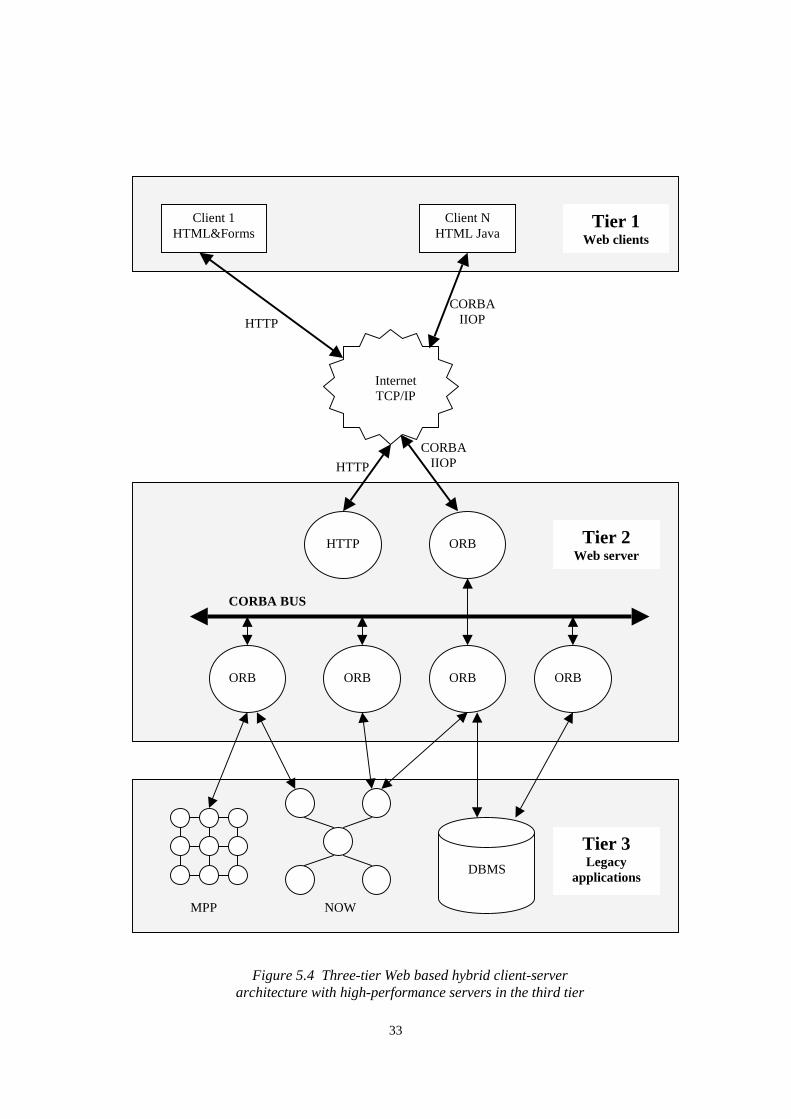
The realization of this concept is shown in Figure 5.4 and it can take place in two steps.As a first step a hybrid three-tier architecture can be constructed where the middle layercan contain multiple instantiations of the same server in order to increase performance.These servers could be CORBA, COM or Java-based Object Web servers. This first stepwill result in a modest-performance, scalable parallel (using multiple servers if necessary)metacomputing environment which includes all commodity services.
The second step increases the performance of the third tier by replacing performance-bottleneck servers with their equivalent high-performance versions like an MPPsupercomputer or a workstation cluster. For example, sequential distributed simulationsare replaced by message-passing implementations on massively parallel supercomputersor a sequential database machine is replaced by a parallel database system. A parallelcomputer server in such an approach will be viewed as a single object and will beaccessed by commodity protocols (IIOP, HTTP, etc.) via its host as shown in Figure 5.4.
CORBA is a realistic long-term candidate to establish a three-tier commodity architecturefor distributed high-performance computing. CORBA supports the server-servercomputational model over the network as shown in Figure 5.4. Any server can invokeany CORBA service available on another site via the CORBA bus implemented on top ofthe Internet. In order to establish a CORBA based metacomputing environment, high-performance computing components should be integrated into the CORBA architecture.
This integration can be done by creating two new facilities:
• The first one should define how CORBA objects interact with one another in ahigh-performance environment.
• The second one should provide user interfaces to scientific computers includinginterfaces for resource managers, performance tools, visualization, etc.
33
CORBAIIOPHTTP
Client 1HTML&Forms
Client NHTML Java
Tier 1Web clients
Tier 2Web server
InternetTCP/IP
DBMS
Tier 3Legacy
applications
Figure 5.4 Three-tier Web based hybrid client-serverarchitecture with high-performance servers in the third tier
HTTP
CORBAIIOP
CORBA BUS
HTTP ORB
ORB ORB ORB ORB
MPP NOW

34
Further down this road there is a vision that the commodity three-tier concept can formthe basis of creating even parallel computers [FoFu99]. In the current stage of technologya parallel computer participating in the CORBA based metacomputing environmentappears as a single entity (CORBA object) for the rest of the CORBA system as shown inFigure 5.4. The parallel computer is accessed by commodity protocols (IIOP, HTTP,etc.) via its host and delivers high-performance computing technology in the third tier ofthe CORBA based metacomputing environment.
Figure 5.5 shows a new view of a parallel computer where the host and other nodes playa symmetric role and all of them can be accessed by commodity protocols. In such aparallel computer approach each node is instantiated as a CORBA object and the parallelcomputer can be considered as a distributed system. Each node of the parallel computercan run a CORBA ORB, a Web server, or any equivalent commodity server. Such anintegration of parallel and distributed computing technology has the advantage that
• commodity protocols can operate both internally and externally to the parallelcomputer
• commodity and high-performance services are uniformly addressed.
However, there is a significant drawback of such an integrated system on the currentstage of communication technology: commodity messaging protocols have unacceptableperformance for parallel computing applications. Fox and Furmanski proposed the
IIOP onInternet
IIOP based internalcommunication networkof a parallel computer
Node1 Node5
Node2
Node3 Host
Node4
Figure 5.5 Parallel computer initiated as a set of CORBA objects [FoFu99]

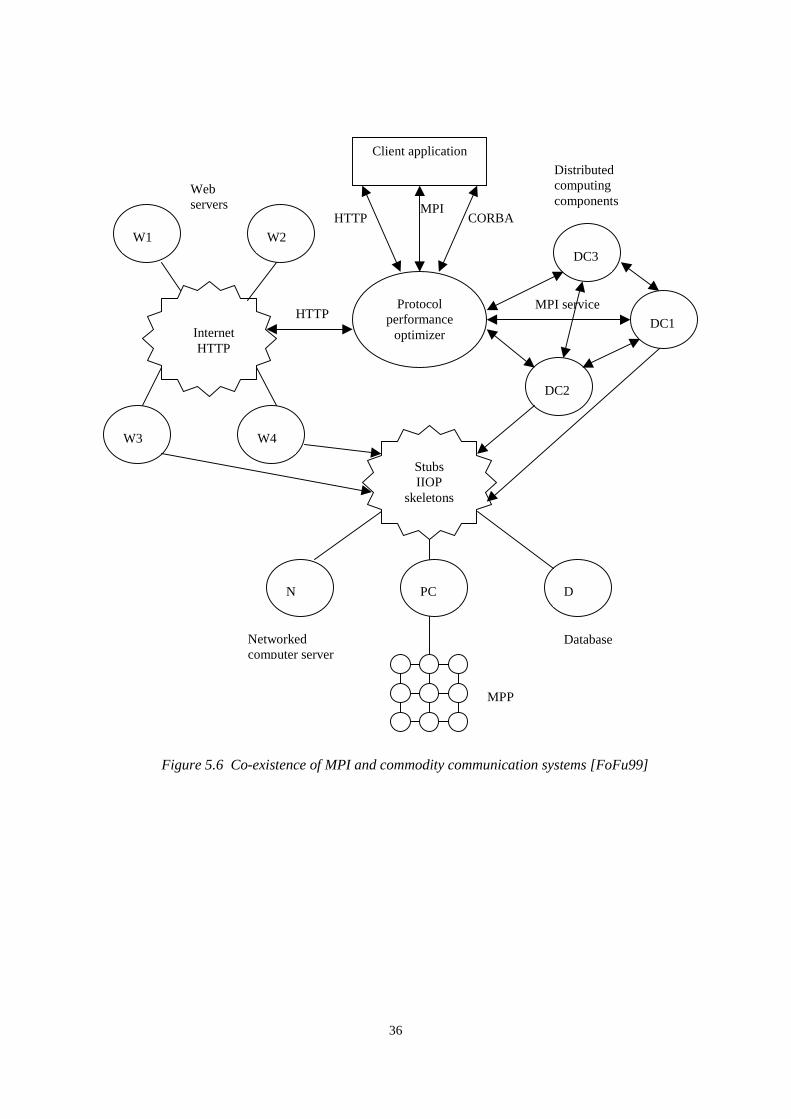
35
introduction of a protocol performance optimizer into the three-tier architecture to solvethe problem [FoFu99]. Their proposed architecture shown in Figure 5.6 can bind MPI orother high-speed communication library to the commodity protocols. In such anarchitecture each service can be accessed by any applicable protocol via the protocolperformance optimizer as Figure 5.6 illustrates it. MPI and CORBA can be linked in twopossible ways:
1. The CORBA invocation can be replaced by an optimized MPI code.2. The MPI call could be realized by calling a CORBA stub.
In any case the proposed solution can open the way to the ultimate unification ofdistributed and parallel computing where the difference between them disappears bothlogically and physically.
5.1.5 Java and commodity metacomputing
The same ideas described for a CORBA based metacomputing environment can beapplied for a Java based metacomputing system, too. However, in additional to theadvantages described there Java can further contribute to high-performance distributedcomputing:
• Java can be easily extended as a high-performance parallel language• Mobile agent technology can be applied on top of Java applets and servlets.
Java already supports functional parallelism at the language level by introducing thethread concept. In order to support data-parallelism for massively parallel scientificprograms new language constructs similar to the constructs of High-Performance Fortanshould be introduced to Java. One of the most important goal of the JavaGrandeconsortium is to enhance Java towards parallel processing so the future of Java seems tobe promising with respect of supporting parallelism.
One of the main current obstacle of using Java as a high-performance computinglanguage is the lack of an efficient implementation on supercomputers. The JavaGrande[www20] project also aims to radically improve Java in this respect. If the JavaGrandeconsortium will be successful we can envisage a very potential and promising approachfor creating commodity metacomputing environments that can incorporate CORBA andJava objects without loss of performance.
36
MPI serviceHTTP
HTTP CORBAMPI
InternetHTTP
Client application
Protocolperformance
optimizer
DC2
DC3
DC1
W2W1
W4W3
N PC D
MPP
StubsIIOP
skeletons
Webservers
Distributedcomputingcomponents
DatabaseNetworkedcomputer server
Figure 5.6 Co-existence of MPI and commodity communication systems [FoFu99]

37
5.2 Network based caching
High-performance, data-intensive applications require a new approach of data handling inorder to ensure high-speed data access and to provide the functionality of a single, verylarge, random-access, block-oriented I/O device [John99]. The solution for this challengeis the introduction of the DPSS (Distributed Parallel Storage System). A DPSS providesseveral important and unique capabilities for the metacomputing system including:
• Application-specific interfaces to extremely large space of logical blocks (16-byteindices).
• Dynamically configurable aggregation of computers and disks (i.e. adding anddeleting servers and storage resources during operation) from all over themetacomputing system.
• Ability to build large, high-performance storage systems from inexpensivecommodity components.
• Ability to increase performance by increasing the number of parallel DPSSservers.
• Replication of data, name translation and disk servers for reliability andperformance.
Fundamentally, DPSS works as a network based application cache for any number ofhigh-speed data sources. The high performance of DPSS is obtained through paralleloperation of independent network based components. The structure of a DPSS systemusing agent-based management is shown in Figure 5.7. Typical DPSS implementationconsists of several low-cost workstations, each with several disk controllers, and severaldisks on each controller. Notice that this system is very similar to the shared-nothingparallel database system architecture applied in workstation clusters. However,meanwhile disk-sharing is a viable alternative to the shared-nothing approach in clusters,there is no alternative approach in metacomputing systems.
Agent based management provides the following advantages in the implementation ofDPSS:
• Structured access to current and historical information of the DPSS components.• Reliability by restarting any crashed components.• Automatic reconfiguration by starting new agents for newly added DPSS
components without affecting existing agents.• Flexible functionality by adding new agent methods to the DPSS at any time.
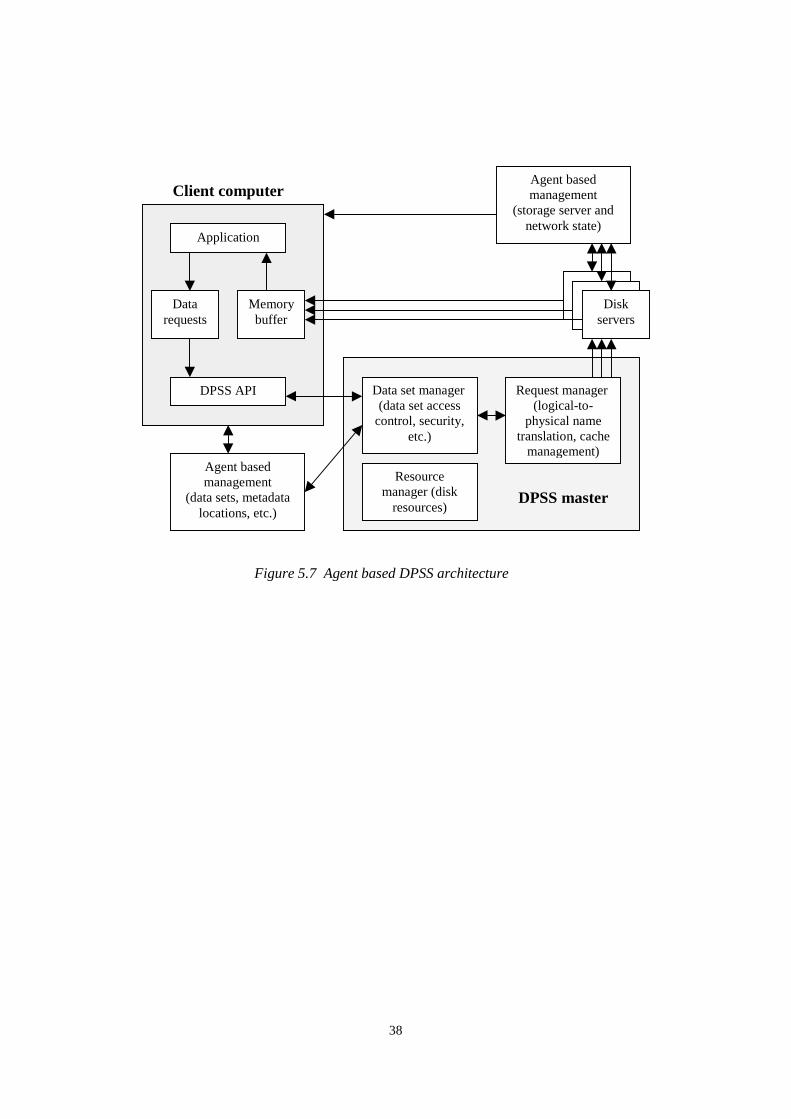
38
Client computer
Application
Datarequests
Memorybuffer
DPSS API
Diskservers
Data set manager(data set access
control, security,etc.)
Agent basedmanagement
(data sets, metadatalocations, etc.)
Request manager(logical-to-
physical nametranslation, cache
management)
Resourcemanager (disk
resources)DPSS master
Agent basedmanagement
(storage server andnetwork state)
Figure 5.7 Agent based DPSS architecture

39
6. Computational Grids and the Middleware concepts
Advances in networking technology and computational infrastructure make it possible toconstruct large-scale, high-performance distributed computing environments. Recently,these advanced environments are called computational grids. Presently, a wide variety ofgroups are experimenting with grid applications and support technology (services calledmiddleware and application toolkits) [FoKe99].
Especially in the US there are multiple national-scale efforts to enable new classes ofapplications based on the coordinated use of geographically distributed resources. A newlaw (NITRD: Networking and Information Technology Research and Development Act)is in preparation which is to double the federal support for information technologyresearch to approximately 4.8 billion dollars over the next five years.
The most important programs are:
• The Advanced Computational Infrastructure (PACI) program founded by theNational Science Foundation (NSF) which consists of two partnerships, i.e.
• National Computational Science Alliance (Alliance) [www2] led by theUniversity of Illinois and NCSA
• National Partnership for Advanced Computational Infrastructure (NPACI) ledby the San Diego Supercomputer Center
• DOE2000 project of the Department of Energy (DOE)• IPG (Information Power Grid of the National Aeronautics and Space
Administration (NASA)
This new technology could be built upon the experiments and results of successfulprojects such as:
• Globus project• Legion project• Condor project• SuperWeb
First we make some general observations regarding goals and principles:• A grid should support a wide area of applications (not just scientific or high-
performance applications)• A grid should enable sharing at multiple levels in infrastructure. It has not to
be a rigid ISO network model like architecture but rather a collection ofinterrelated services that promotes inter-operation (similar to the servicesprovided by IETF: Internet Engineering Task Force for smooth operation ofthe Internet).
• The proven Internet principle “as simple as possible” should follow• Grid should contribute to standards where ever possible

40
Typical grid architecture comprises four general types of components:
1. Grid Fabric provides resource specific implementations of basic mechanismssuch as network QoS (Quality of Service) support in routers and end systems;high-speed network interfaces and specific implementations of networkprotocols; resource management interfaces supporting advance reservation,allocation, monitoring and control of computers and storage systems(coordinated allocation of computers, networks and storage systems), etc.
2. Grid services (middleware) provide resource and application independentservices. They implement basic mechanisms such as authentication,authorization, resource location and allocation, events, accounting, remotedata access, fault detection, etc.
3. Grid application toolkits provide more specialized services and componentsfor various application classes e.g. remote instrumentation, remotevisualization, remote data access, collaboration, distributed computing(metacomputing), etc.These toolkits define common abstractions, application interfaces and specificservices that facilitate application development and component sharing withinspecific disciplines.
4. Grid aware applications which are implemented in terms of the components ofgrid fabric, services and toolkit.
A Computational Grid should be:• Ubiquitous i.e. able to interface to the system at any point and leverage
whatever is available• Resource aware i.e. capable of managing heterogeneity• Adaptive i.e. able to tailor its behavior dynamically (to get maximum
performance)
There are two main approaches to create metacomputing middleware:1. Toolkit approach2. Object-oriented design approach
6.1 Toolkit approach
The toolkit approach is based on two assumptions:1. The metacomputing environment should provide only the basic services
without enforcing any particular programming model.2. The current commodity technology is unable to satisfy the requirements of
grand challenge problems.
According to these assumptions the main focus is on creating a ‘toolkit’ of low-levelservices which includes the following tools:
1. Communication system2. Resource management system

41
3. Process management4. Data access and security
Based on these tools higher level services, programming models and completemetacomputing environments can be built up. For example, a commodity three-tiersystem might be constructed upon the toolkit approach.
One of the well-known toolkit architecture is the Globus system [FoKe99b] that is underdevelopment by the Argonne National Laboratory and the Information Sciences Instituteof the Univ. of Southern California. The main concept of the Globus system is thehourglass principle as it is shown in Figure 6.1. The hourglass principle is exemplified bythe Internet Protocol suite where global services like TCP, HTTP, etc. can be constructedon top of a local services like Ethernet, ATM, etc. The same idea is applied in thecreation of the Nexus protocol that provides MPI, CORBA, etc. high-level globalcommunication services on top of low-level local services like IP, message passing,shared memory, etc. A similar idea is followed in the GRAM protocol to define high-level resource brokers on top of low-level load balancing tools.
A list of tools provided by Globus is shown in Table 6.1 together with their usage andbenefits. The scope of this study is limited to show only the main trends and mostimportant tools and hence, in the following sections we outline only three major tools ofthe Globus toolkit in order to illustrate its basic concept.
The Globus research project compromised activities on the following areas:
• Basic research in grid related technologies• Development of the Globus toolkit (core services for grid-enabled tools and
applications)• Construction of a large-scale, prototype computational grid (GUSTO testbed)• Extensive realistic application experiments on the prototype grid.
Message passing,Shared memory,
IP, etc.
Condor,LSF, NQE,
LoadLeveler, etc.
MPI, CC++,HPC++, CORBA,
etc.
Resource brokers,Resource co-
allocators
TCP, FTP, HTTP,etc.
Internetprotocol
Ethernet, ATM,FDDI, etc.
GRAMprotocol
Nexusprotocol
Figure 6.1 The hourglass concept of Globus [FoKe99b]
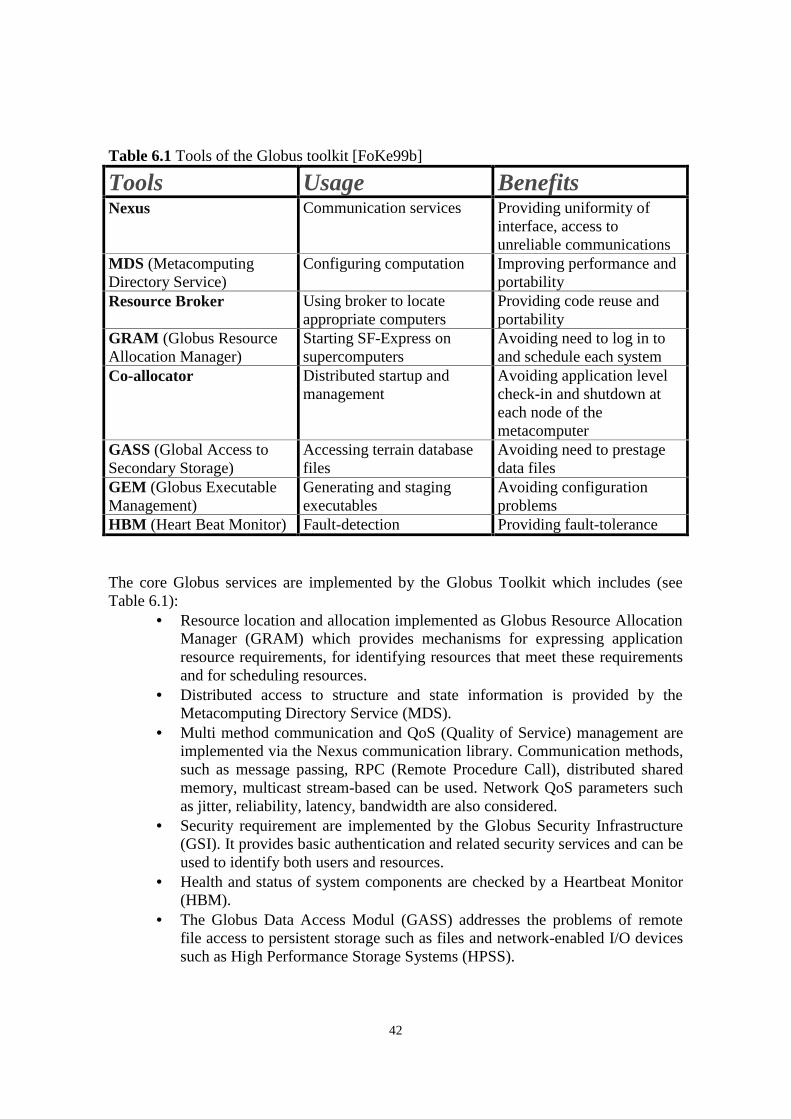
42
Table 6.1 Tools of the Globus toolkit [FoKe99b]
Tools Usage BenefitsNexus Communication services Providing uniformity of
interface, access tounreliable communications
MDS (MetacomputingDirectory Service)
Configuring computation Improving performance andportability
Resource Broker Using broker to locateappropriate computers
Providing code reuse andportability
GRAM (Globus ResourceAllocation Manager)
Starting SF-Express onsupercomputers
Avoiding need to log in toand schedule each system
Co-allocator Distributed startup andmanagement
Avoiding application levelcheck-in and shutdown ateach node of themetacomputer
GASS (Global Access toSecondary Storage)
Accessing terrain databasefiles
Avoiding need to prestagedata files
GEM (Globus ExecutableManagement)
Generating and stagingexecutables
Avoiding configurationproblems
HBM (Heart Beat Monitor) Fault-detection Providing fault-tolerance
The core Globus services are implemented by the Globus Toolkit which includes (seeTable 6.1):
• Resource location and allocation implemented as Globus Resource AllocationManager (GRAM) which provides mechanisms for expressing applicationresource requirements, for identifying resources that meet these requirementsand for scheduling resources.
• Distributed access to structure and state information is provided by theMetacomputing Directory Service (MDS).
• Multi method communication and QoS (Quality of Service) management areimplemented via the Nexus communication library. Communication methods,such as message passing, RPC (Remote Procedure Call), distributed sharedmemory, multicast stream-based can be used. Network QoS parameters suchas jitter, reliability, latency, bandwidth are also considered.
• Security requirement are implemented by the Globus Security Infrastructure(GSI). It provides basic authentication and related security services and can beused to identify both users and resources.
• Health and status of system components are checked by a Heartbeat Monitor(HBM).
• The Globus Data Access Modul (GASS) addresses the problems of remotefile access to persistent storage such as files and network-enabled I/O devicessuch as High Performance Storage Systems (HPSS).

43
• Globus Executable Manager (GEM) is used to initiate computation onresources. This task includes setting up executables, creating an executionenvironment, starting an executable, passing arguments, managingtermination, etc.
The various Globus toolkit modules are defining a metacomputing virtual machine.
6.1.1 Communication model
The communication model of Globus shows many similarities with the Active Messages[Main96] and Fast Messages [PaLC95] communication systems. All of them are based onthe concept of multithreading whereby communication does not only means sending databetween processes but it also involves the invocation of a thread to be executed upon thetransmitted data.
The communication library of Globus is called Nexus [FoKT96] and it combines fivemajor concepts:
1. Nodes (on which the computation is executed)2. Contexts (representing independent address spaces)3. Threads (active components of the computation)4. Communication links (providing a global name space for objects)5. Remote service requests (initiating communication and invoking remote
computation by starting remote threads)
A communication link is represented by a startpoint and an endpoint. Besides point-to-point communications many-point-to-point and point-to-many-point communications areallowed as shown in Figure 6.2. A remote service request (RSR) is defined by giving itsstartpoint, handler identifier and data buffer. Issuing an RSR results in transmitting thedata buffer from the startpoint to its bound endpoint and executing the specified RSRhandler at the endpoint in the form of a thread.
EP
SP EPSP
EP EP SP
Figure 6.2 Communication link topologies in Nexus

44
Startpoints and endpoints can be created dynamically. Another important feature ofNexus is that the startpoint can be mobile, i.e., the creator of the startpoint cancommunicate it to other processes with a handle.
MPICH (an MPI version) has been implemented on top of Nexus. The main idea of theMPICH implementation is the introduction of the Abstract Device Interface (ADI). TheADI provides a fairly high-level abstraction of a communication device that should berealized by the underlying low-level communication library like Nexus. The Nexusimplementation of ADI establishes a full connection among the communication linksused in the MPICH program and the ADI functions are realized as RSR messagehandlers. The implementation of ADI on different machines may apply differentprotocols for transferring data.
6.1.2 Resource management
Globus has a hierarchical resource management concept which is built on three majorcomponents:
• The Resource Specification Language (RSL)• A hierarchical broker architecture• Globus Resource Allocation Managers (GRAMs)
The RSL is used to specify the resource requirements of a particular application. Itcontains expressions like:
• “Run a distributed simulation with 100K entities”• “Perform a parameter study with 10K separate trials”• “Create a shared virtual space with participants X, Y and Z”
Such statements are interpreted and processed by various request brokers like:
• Distributed simulation specific broker• Parameter study specific broker• Collaborative environment specific broker
The brokers collect information on available resources from the so-called InformationService and process the RSL requests according to this information. As a result theytransform the high-level RSL requests into more specific requests until a they identify aspecific set of resources expressed by ground RSL expressions like: “80 nodes ofArgonne SP, 256 nodes on CIT Exemplar, 300 nodes on NCSA 02000”. These groundRSL expressions are sent to a co-allocator which dispatches the ground RSL requests tolocal resource managers called Globus Resource Allocation Managers (GRAMs). A
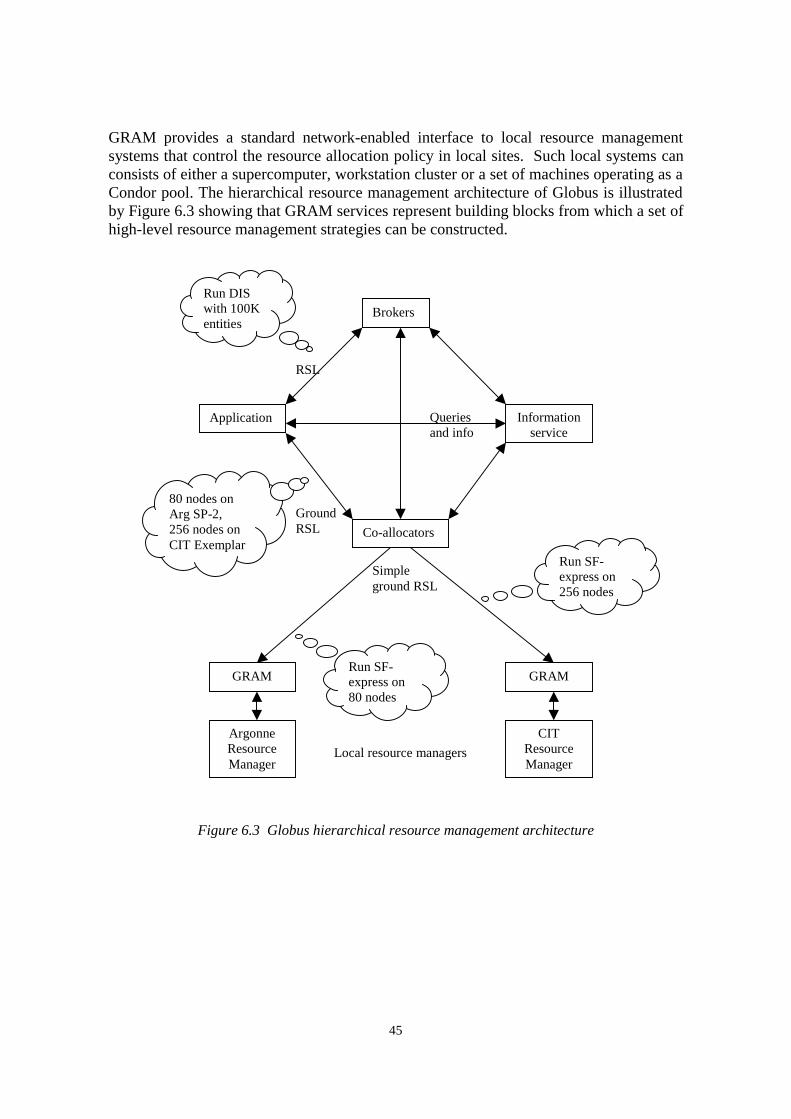
45
GRAM provides a standard network-enabled interface to local resource managementsystems that control the resource allocation policy in local sites. Such local systems canconsists of either a supercomputer, workstation cluster or a set of machines operating as aCondor pool. The hierarchical resource management architecture of Globus is illustratedby Figure 6.3 showing that GRAM services represent building blocks from which a set ofhigh-level resource management strategies can be constructed.
Queriesand info
Simpleground RSL
GroundRSL
RSL
Brokers
Application Informationservice
Co-allocators
Run DISwith 100Kentities
80 nodes onArg SP-2,256 nodes onCIT Exemplar
GRAM
ArgonneResourceManager
GRAM
CITResourceManager
Run SF-express on80 nodes
Run SF-express on256 nodes
Figure 6.3 Globus hierarchical resource management architecture
Local resource managers

46
6.1.3 Globus Metacomputing Directory Service (MDS)
The Globus MDS addresses the requirement of accessing distributed, heterogeneous anddynamic information in the metacomputing system. The MDS information structured as aset of entries (network, computer, organization, person, etc.) is organized in ahierarchical, tree structured name space called Directory Information Tree (DIT). Foreach sub-tree of DIT (e.g. for all machines of a computing center, or a cluster) an MDSserver is allocated which is responsible for its maintenance. Higher-level metacomputingservices like the resource broker of Globus can obtain information from the MDS.
Globus provides a Resource Specification Language (RSL) to describe resources for a jobrequest. The RSL gives parameter specifications and conditions on MDS entries. Forexample, a metacomputing system requiring 64 nodes with a minimum of 256 MB andfour nodes with ATM interface are specified as follows:
+(&(count = 64)(memory >= 256M))(&(count = 4)(network = ATM))
6.2 Object-oriented design approach
6.2.1 Programming model
There is a slight difference between classical object-oriented systems and distributed OOsystems. In the latter an object class instance becomes a component that can be usedremotely from different sites. In order to do it, a component architecture should bedefined which describes the framework for designing and using components. Thearchitecture applies a set of rules that prescribe the required features all components mustobey. Components have control interface through which they can be initialized andintegrated into a distributed application. Besides components the component architectureconsists of containers. A container is an application that runs on the client site and itsmain tasks are to select components, connect them, and respond to event messages. Thecontainer uses the control interface of components to learn their properties, initialize, andintegrate them.
The main features of components are:
• they are objects• they have persistent state• they can communicate with each other by various mechanisms (message
passing, procedure calls, events, method invocation)• they can have visual interfaces• they can be manipulated by container toolkits.
The three most important commodity component architectures are:

47
1. JavaBeans Java Studio2. OMG’s CORBA/OpenDoc3. Microsoft ActiveX
Concerning component integration there are two main approaches:
1. Client-server approach2. Software IC approach
In the client-server model, the application is the client that invokes local or remote servercomponents by calling their public member functions according to their interfaces. Theclient application is realized as a container of components of their proxies.
The software IC approach follows the idea of hardware ICs. Hardware ICs are buildingblocks which have well-defined functions and input/output interfaces. According to theinterface rules hardware ICs can be connected in order to form bigger building blocks.Similarly, a software IC has input ports and output ports. The ports have types which areprotocol interfaces describing the structure of messages that the ports can handle. Thoseinput and output ports that have the same protocol interface can be connected together.The software IC concept represents a macro-dataflow technique that was already used bymessage passing computers and it was particularly popular in the Occam programmingstyle (though it missed the use of OO techniques).
6.2.2 The Legion architecture
A representative example of the OO design approach is the Legion architecture in whichall the hardware and software resources are represented by a Legion object [GaGr99]. ALegion object is an active process that responds to member function invocations. Legiondefines the message formats and high-level protocols for object interaction. Classescreate instances and work as managers since they are responsible for scheduling theirinstances, for activating and deactivating them and for providing information on theircurrent location. Besides the legion classes users can define their own classes which canoverwrite the system-level mechanisms of Legion classes.
Legion can support high-performance computing in two ways:
1. applying parallel processing2. selecting computing sites according to advanced scheduling and resource
management.
6.2.3 Parallelism in Legion
Legion provides tools for implementing the message passing parallel model in four ways:
1. Supporting message passing libraries

48
Legion provides emulation libraries on the top of the Legion runtime library in order tosupport the use of PVM and MPI communication systems. After the recompilation andre-linking of PVM and MPI programs they can run on Legion.
2. Supporting parallel languagesLegion supports parallel program execution in the following three languages:
• MPL (Mentat Programming Language – a parallel C++ language)• Fortran• Java
Legion is written in MPL. The compiler constructs parallel computation graphs from theMPL program and the runtime system execute the methods in parallel on differentprocessors or hosts. For parallel execution of Fortran programs Legion uses BFS (BasicFortran Support) which is a set of pseudo-comments for Fortran. Legion contains apreprocessor that enables the construction of parallel program graphs from BFS andallows parallel execution via remote asynchronous procedure calls. Legion also providesa Java interface which enables Java programs to access Legion objects and to executemember functions asynchronously.
3. Wrapping parallel componentsBesides encapsulating existing sequential legacy code into objects, Legion is able toencapsulate a PVM, HPF or shared-memory threaded application into a Legion object.Such parallel components appear sequential for other Legion objects but they areexecuted in a parallel way.
4. Program graph supportThe Legion runtime library interface is openly available in order to support third-partysoftware development. One particularly important feature of the library interface is thesupport for constructing macro-dataflow graphs. Nodes of the graph are memberfunctions invocations of Legion objects or subgraphs. Arcs represent data dependenciesamong the nodes. Such a graph designs a function which is a first class object of Legion.It can be annotated with arbitrary information such as resource requirements.
6.2.4 Resource management in Legion
The resource allocation (scheduling) policy of Legion is based on a negotiation processbetween resource providers and consumers. Legion provides three types of resources:
• Computational resources (hosts)• Storage resources (vaults)• Network resources
The Legion scheduler system consists of three main components as shown in Figure 6.4:

49
• Collector: its task is to collect information of available resources into aresources state information database. It interacts with resource objects asshown by step 1 in Figure 6.4.
• Scheduler: realizes the actual scheduling policy by matching the availableresources with the required resources (step 2) and computes and send aschedule to the Enactor (step 3).
• Enactor: makes reservation for the individual resources (step 4) and reportsthe result to the Scheduler (step 5). Receiving the approval of the Schedulerthe Enactor places objects on the hosts (step 6).
The Legion provides default scheduling policies from which the user can select or theuser can create and apply his own scheduling policy. This autonomy of the user is crucialto achieve maximum performance. On the other hand Legion respects the autonomy ofresource providers as well. Participating sites in the metacomputing environment areassured that their local scheduling policies will be respected by the global Legionscheduling policies.
Scheduler
Collector(Resource database)
Enactor(Schedule implementor)
Resources
Figure 6.4 The structure of the Legion scheduler system
step 4, step 6
step 2 step 3, step 5
step 1

50
7. Metacomputing programming environments
7.1 Toolkit based integrated environment
An integrated metacomputing environment called CCS (Computing Center Software) hasbeen developed at the Paderborn Centre for Parallel Computing [Brun98]. This systemintegrates the main tools of a possible metacomputing programming approach into agraphical supervising environment. The three main components of the environment are:
• PLUS communication interface• Resource management (CIS/CRM)• Resource and Service Description (RSD)
7.1.1 The PLUS communication interface
PLUS was created with the same purpose as PVMPI, i.e., to enable combining existingPVM and MPI industrial code in the same programming environment. However,meanwhile PVMPI lacks openness towards other models, PLUS realizes an extensible,open, distributed multi-site communication interface between message passing systems.
In order to activate the PLUS communication interface a PLUS master daemon should bestarted by the UNIX command:
startplus<target_machine>
The master daemon will automatically initiate a PLUS daemon for each sub-network ofthe metacomputing environment. The typical location of such daemons as shown forexample in Figure 7.1 are on:
• frontends of a parallel system• powerful workstations• network routers
After the daemons are created, the sub-networks running under different message passingcommunication systems can communicate to one another by using the following PLUScommands:
• plus_init() for signing on the closest PLUS daemon• plus_exit() for logging off• plus_system() for spawning a task on another sub-network• plus_info() for requesting information on the accessible tasks
Figure 7.1 shows a metacomputing environment consisting of a supercomputer runningMPI program and a workstation cluster running a PVM program. In order to combine thetwo sub-networks into a unified metacomputing system both the MPI and PVM programsshould be extended with the plus_init() and plus_exit() commands as shown in the figure.

51
The advantage of the approach that neither the original MPI, nor the PVM calls should bemodified. After the MPI and PVM programs registered into the PLUS environment thetwo PLUS daemons start to exchange process tables and control information. Wheneveran MPI or PVM function is called it will be trapped by the PLUS daemon which checksthe involving processes. If a remote process is involved (its identifier is bigger than themaximal identifier in the local process table), the MPI call is replaced with acorresponding remote PVM call and vice versa the PVM call addressing a remote processis substituted with a remote MPI call.
7.1.2 Resource management (CCS)
The resources in the CCS environment are grouped into so-called islands which havetheir local management system maintained by a number of local daemons as shown inFigure 7.2:
• Island Manager (IM): Provides name services and watchdog functionalitiesfor reliability. It also supervises the other daemons by collecting informationon them, stopping erroneous daemons and restarting crashed ones.
• Access Manager (AM): Manages the user interfaces and is responsible forauthorization and accounting.
network
C+MPI on parallel computer
C+PVM on workstation cluster
PLUS daemon
plus_init()MPI_send()plus_exit()
Frontend
plus_init()pvm_send()plus_exit()
PVM daemon
PLUS daemon
Figure 7.1 Process communication between PVM and MPI via PLUS

52
• Queue Manager (QM): Schedules user requests arriving from the AMaccording to the current scheduling policy. (The system administrator canselect among several fair and deterministic scheduling policies at run time.)
• Machine Manager (MM): manages the parallel system of the island bychecking the mapping constraints derived from the user resourcerequirements. MM decides whether a schedule given by the QM can bemapped onto the hardware at the specified time. The advantage of separatinghardware independent QM services and system-specific MM is that a CCSisland can easily be adapted to new architectures.
The resource management system of the CCS environment is divided into two levels:
• CIS: Center Information System• CRM: Center Resource Manager
The CIS plays the passive part, while CRM the active part of the resource managementsystem. CIS maintains an up-to-date database on the network characteristics, the systemsoftware and the time constraints. This information is provided for external usageincluding mobile agents via a request broker service as shown in Figure 7.2.
CRM is responsible for allocating computing resources to application programsaccording to the service needs specified by the end-users. During the allocation ofresources, CRM takes into account the information provided by CIS on the availablemetacomputing resources. The resource allocation method of CRM is similar to the two-phase-commit protocol of distributed database systems. In the first phase the CRMrequests all the required resources at all the involved islands. If a resource is not availableit either re-schedules the job or rejects the user’s request. Otherwise the user job can bedistributed and executed in the metacomputing system.
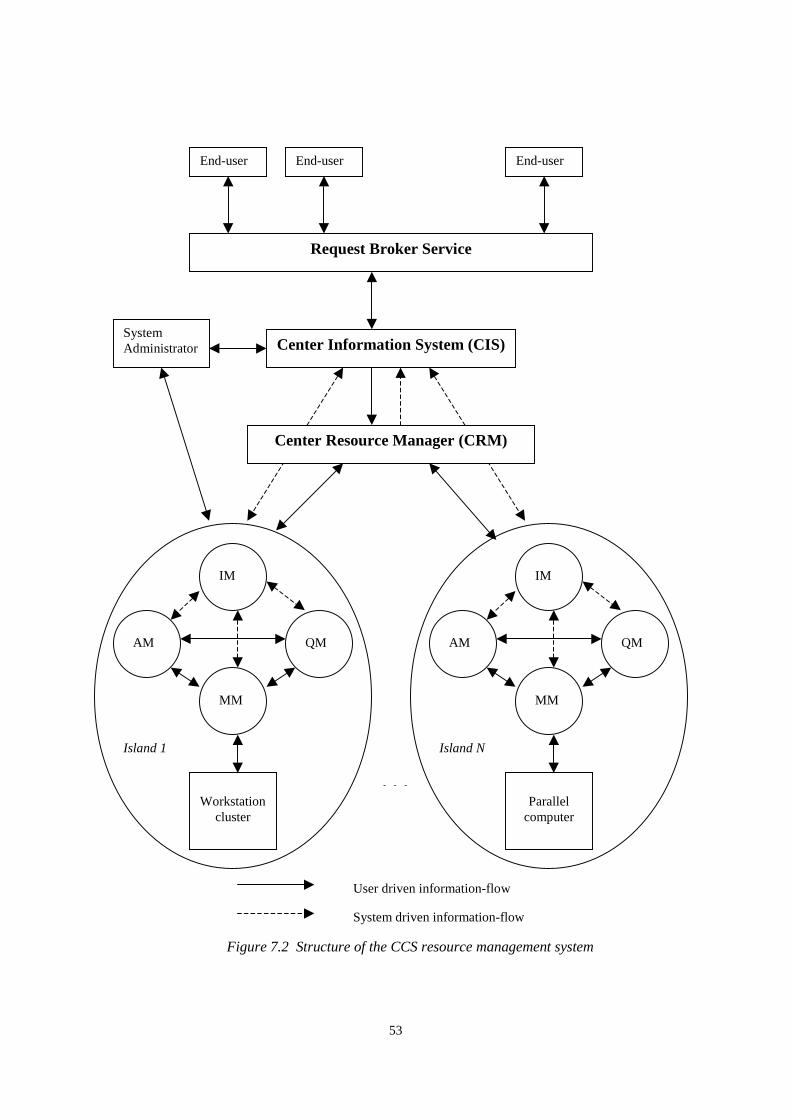
53
MM
IM
AM QM
Workstationcluster
MM
IM
AM QM
Parallelcomputer
Island 1 Island N
. . .
Center Resource Manager (CRM)
Center Information System (CIS)
Request Broker Service
End-user End-user End-user
SystemAdministrator
User driven information-flow
System driven information-flow
Figure 7.2 Structure of the CCS resource management system

54
7.1.3 Resource and Service Description (RSD)
The RSD tool provides a graphical interface and graphical RSD editor for both the end-users and system administrators to describe their resource and service needs of themetacomputing system. The graphical RSD editor is a further development of theWAMM metacomputer manager that was developed at CNUCE-CNER in Pisa [Bara96].At the top level the interconnection network of the metacomputing system should bedefined by intensive use of drag and drop techniques. At the next level the nodes of themetacomputing system can be defined in detail. Clicking on a node the editor pops up awindow showing the detailed information of the machine belonging to the node. The GUIoffers standard machine layouts like Cray T3E, IBM SP2, etc. and in order to define theinternal communication topology of parallel computers, a collection of the most generallyused regular interconnection topologies are predefined and offered for selection. Theadministrator can specify the size of the selected machine and its attributes (like disk size,I/O throughput, etc) in a textual manner. The end-user may either specify the targetmachines in a multi-site application, or can define constraints and let the RMS (ResourceManagement System) choose a suitable part of the metacomputing system.
For system administrators a textual language interface is also provided because thecomplexity of describing a metacomputing system can surpass the possibilities of agraphical interface especially in case of irregular interconnection schemes. Thedescription of a node consists of three parts [Brun98]:
NODE Name {
DEFINITION:Identifier [= (value, …)];
-- identifiers and attributes are introduced
DECLARATION: -- declares all nodes with corresponding attributes-- recursive definition is allowed:
NodeName { DECLARATION: attribute1, …};
CONNETION: -- defines attributed edges between the ports of the nodesEDGE NameOfEdge {NODE x PORT y Ø NODE u PORT v; attribute1, …};
}
In [Brun98] the following example is given to describe a metacomputing system (shownin Figure 7.3) consisting of a parallel supercomputer and an SCI workstation cluster thatare interconnected by a bidirectional 622 Mbps ATM link. The definition of themetacomputer is given in Figure 7.4 and the definition of the SCI workstation cluster inFigure 7.5.
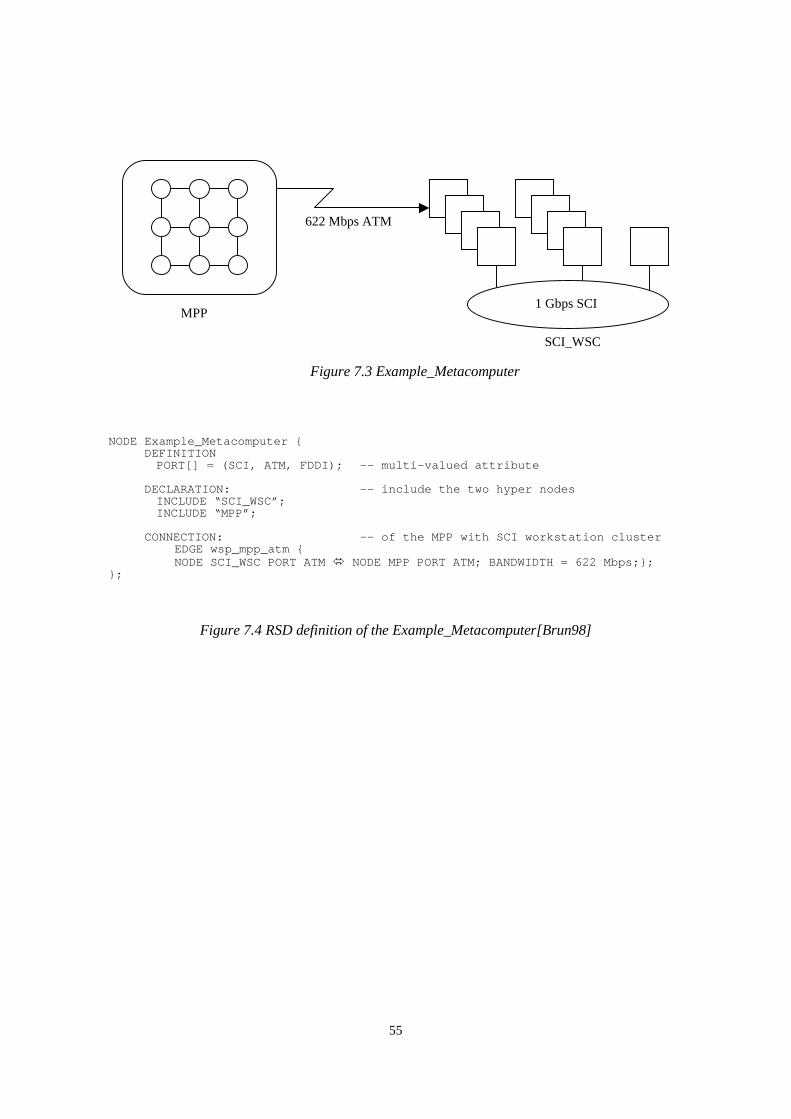
55
NODE Example_Metacomputer {DEFINITIONPORT[] = (SCI, ATM, FDDI); -- multi-valued attribute
DECLARATION: -- include the two hyper nodesINCLUDE “SCI_WSC”;INCLUDE “MPP”;
CONNECTION: -- of the MPP with SCI workstation clusterEDGE wsp_mpp_atm {NODE SCI_WSC PORT ATM Ø NODE MPP PORT ATM; BANDWIDTH = 622 Mbps;};
};
Figure 7.4 RSD definition of the Example_Metacomputer[Brun98]
622 Mbps ATM
MPP
SCI_WSC
Figure 7.3 Example_Metacomputer
1 Gbps SCI

56
NODE SCI_WSC {DEFINITION:CONST N = 3 ; -- number of nodesCPU[] = PENTIUM_II;OS[] = ( SOLARIS, LINUX);SHARED; -- allocate resources for shared use
DECLARATION:-- we have 2 SMP nodes (gateways), each with 4 processors-- each gateway provides one SCI and one ATM portFOR i=0 TO 1 DO
NODE I{ DECLARATION: CPU=PENTIUM_II; MEMORY=512; MULTI_PROC=4;PORT=[SCI, ATM]; };
OD
--the last one is a single processor node with one SCI portNODE 2DECLARATION: CPU=PENTIUM_II; MEMORY=256; OS=SOLARIS;PORT=SCI;
CONNECTION: -- build the 1.0 Gbps unidirectional ringFOR i=0 TO N-1 DO
EDGE edge_$i_to_$((i+1) MOD N){ NODE i PORT SCI => NODE ((i+1 MOD N) PORT SCI;BANDWIDTH = 1.0 Gbps;};
OD
-- establish a special virtual edge from node 0 to the-- port of the hyper node SCI_WSC (=outside world)ASSIGN edge_to_hypernode_port{ NODE 0 PORT ATM Ø PORT ATM;};
};
Figure 7.5 RSD definition of the SCI cluster component of Example_Metacomputer[Brun98]
7.2 Application specific environments
Application specific environments help the end-users to reduce the development time oflarge, complex application-oriented programs by intensive and remote exploitation ofexisting scientific computational libraries. Two main classes of application specificenvironments can be distinguished:
1. Remote service library oriented environments. The main goal in theseenvironments is to exploit remote computing resources without modifying thealready existing application programs. Some typical examples are: NetSolve[CaDo98], Ninf [MaNN96] and RCS [ARGO96].
2. Computational steering environments. They combine interactive simulationand visualization in a metacomputing system. Representative examples are:SCIRun [PaWJ97], CUMULVS [GeKP97] and Magellan [VeSc95].
In the next two sections we show an example for both classes of application specificenvironments.
7.2.1 SCIRun

57
SCIRun is a visual environment to support computational intensive simulation especiallyin the fields of computational medicine and geophysics. It contains the followingcomponents as tools:
• A visual programming language which is based on the macro dataflow graphconcept. The computation is described by a macro dataflow graph whosenodes are already existing modules that realize application specific algorithmstypically written in Fortran and C/C++. The inputs and outputs of thesemodules are connected by data pipes according to the arcs of the dataflowgraph.
• A general class library which includes scientific computing datatypes, datamanipulation types and methods, geometry classes and multitasking classes.
• Domain-specific component libraries for constructing scientific simulations.• Three-dimensional interactive visualization widgets in order to support
interactive, run-time visualization during the simulation process.
7.2.2 NetSolve
The NetSolve problem-specific environment was developed for the integrated use ofexisting numerical program packages like FFTPACK, BLAS, etc. over a metacomputingsystem in order to exploit the available computing resources for solving large scientificproblems. NetSolve is based on a combination of the client-server and proxy computingmodels. It consists of three main components:
• Client APIs serve for the remote call of functions of numerical libraries byusing the NetSolve language which enables a special metacomputing versionof the function invocation. For example
Z = netsolve(‘matmul’, X, Y)
is the NetSolve code for performing the
Z = X * Y
MATLAB code in the metacomputing system. As a result of the netsolve call,a request is sent to the closest NetSolve agent.
• Agents realize resource management in the NetSolve environment. They keeptrack the availability of software resources on the various hardware resources.Upon receiving a request from a client, the agent selects the most suitableserver and passes the call to the chosen server.
• Servers provide the computational resources to execute the remotelyaccessible numerical libraries and perform the requested numericalcomputation. The results are directly sent back to the requestor client withoutthe assistance of agents as shown in Figure 7.6.
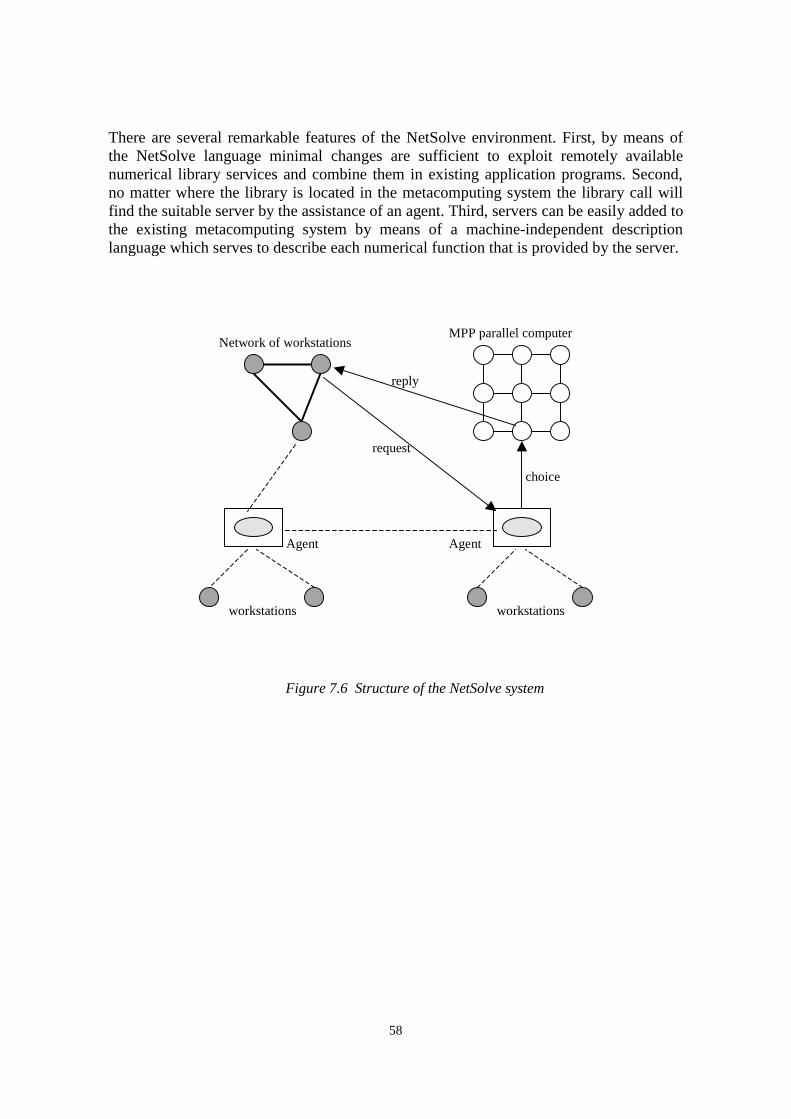
58
There are several remarkable features of the NetSolve environment. First, by means ofthe NetSolve language minimal changes are sufficient to exploit remotely availablenumerical library services and combine them in existing application programs. Second,no matter where the library is located in the metacomputing system the library call willfind the suitable server by the assistance of an agent. Third, servers can be easily added tothe existing metacomputing system by means of a machine-independent descriptionlanguage which serves to describe each numerical function that is provided by the server.
workstationsworkstations
reply
request
choice
Agent
MPP parallel computerNetwork of workstations
Agent
Figure 7.6 Structure of the NetSolve system

59
8. Scheduling in metacomputing systems
Scheduling in metacomputing systems is related with three different aspects ofperformance including the minimization of the average response time, maximization ofthe throughput of the system and ensuring quality of accessing resources. According tothese three aspects schedulers can be divided into three main classes:
1. High-Performance schedulers2. High-Throughput schedulers3. Resource schedulers (QoS)
High-Performance schedulers (or application schedulers) are employed in order toimprove the performance of individual applications by minimizing execution time andincreasing speedup. High-Throughput schedulers (or job schedulers) are applied tooptimize throughput, i.e., the number of jobs executed by the metacomputing system.Resource schedulers are introduced in order to coordinate multiple requests for access toa given resource by providing fairness criteria (ensuring that all request are satisfied)and/or optimizing resource utilization. In the next sections we give a short summary ofthe most important features of all types of scheduling applied in metacomputing systems.
8.1 High-Performance scheduling
Metacomputing high-performance scheduling models require predictive information for aparticular timeframe since the workload of computational resources and the bandwidthsof communication systems dynamically change in time. The accuracy, lifetime and othercharacteristics of performance parameters represent dynamic metainformation that shouldbe extracted from the metacomputing infrastructure. Based on the metainformationvarious compositional scheduling models can be constructed and these are used in currenthigh-performance schedulers like:
• Apples [BeWo97]• Dome [Arab95]• IOS [BuRS97]• I-SOFT [Fost98]• MARS [BuRS97]• SEA [SiMa97]• SPP(X) [Au96]• VDCE [Topc97]
The classification of these high-performance schedulers is shown in Figure 8.1 and theirmost important features are summarized in Table 8.1.
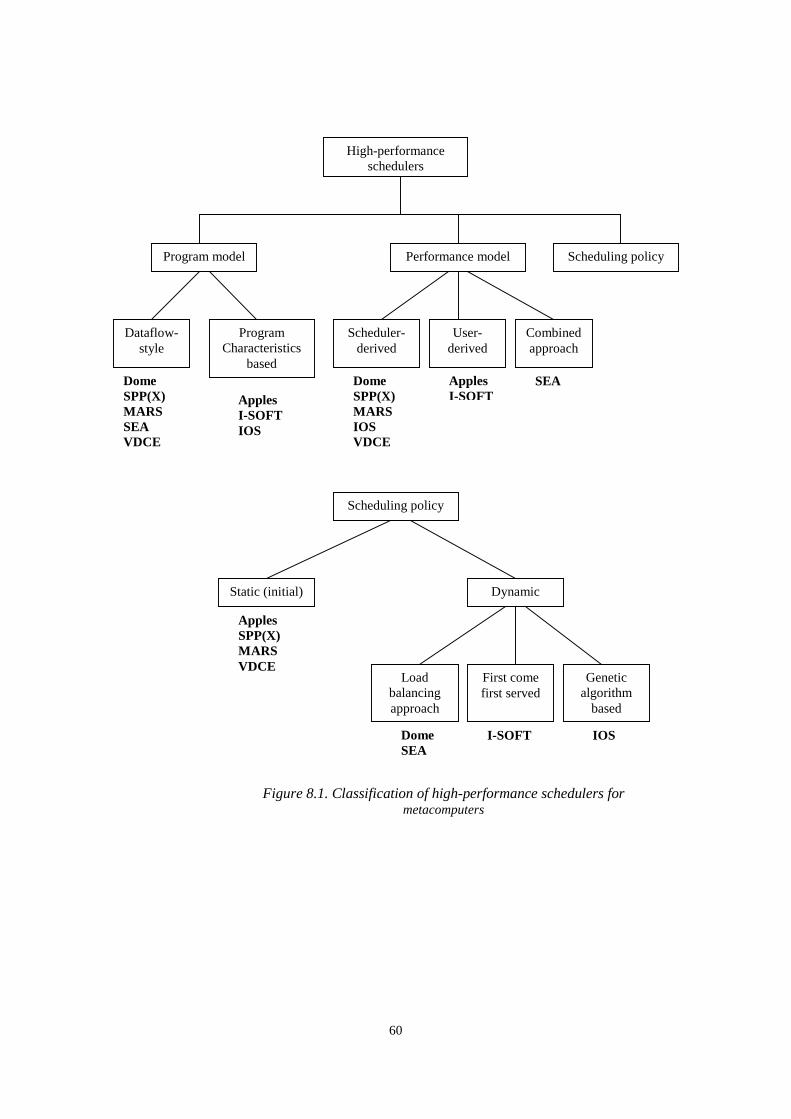
60
IOSI-SOFTDomeSEA
ApplesSPP(X)MARSVDCE
SEAApplesI-SOFT
DomeSPP(X)MARSIOSVDCE
DomeSPP(X)MARSSEAVDCE
High-performanceschedulers
Program model Performance model Scheduling policy
Dataflow-style
ProgramCharacteristics
based
Scheduler-derived
User-derived
Combinedapproach
Scheduling policy
Static (initial) Dynamic
Loadbalancingapproach
First comefirst served
Geneticalgorithm
based
ApplesI-SOFTIOS
Figure 8.1. Classification of high-performance schedulers formetacomputers
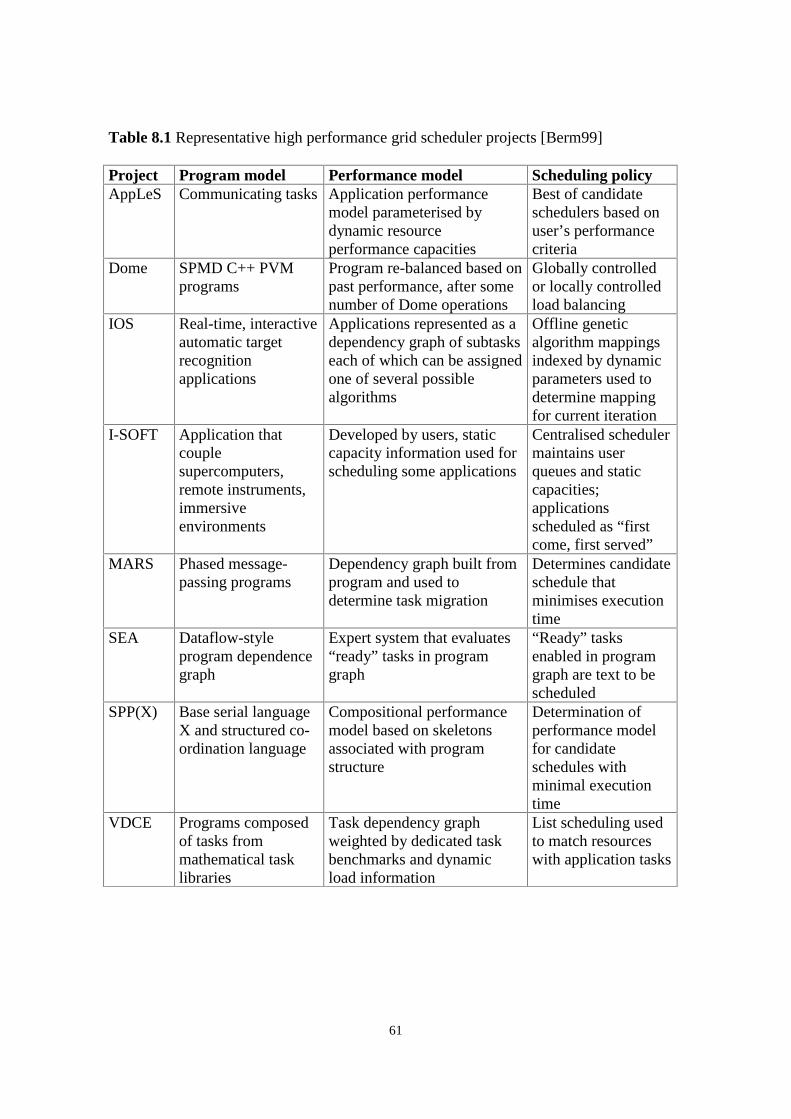
61
Table 8.1 Representative high performance grid scheduler projects [Berm99]
Project Program model Performance model Scheduling policyAppLeS Communicating tasks Application performance
model parameterised bydynamic resourceperformance capacities
Best of candidateschedulers based onuser’s performancecriteria
Dome SPMD C++ PVMprograms
Program re-balanced based onpast performance, after somenumber of Dome operations
Globally controlledor locally controlledload balancing
IOS Real-time, interactiveautomatic targetrecognitionapplications
Applications represented as adependency graph of subtaskseach of which can be assignedone of several possiblealgorithms
Offline geneticalgorithm mappingsindexed by dynamicparameters used todetermine mappingfor current iteration
I-SOFT Application thatcouplesupercomputers,remote instruments,immersiveenvironments
Developed by users, staticcapacity information used forscheduling some applications
Centralised schedulermaintains userqueues and staticcapacities;applicationsscheduled as “firstcome, first served”
MARS Phased message-passing programs
Dependency graph built fromprogram and used todetermine task migration
Determines candidateschedule thatminimises executiontime
SEA Dataflow-styleprogram dependencegraph
Expert system that evaluates“ready” tasks in programgraph
“Ready” tasksenabled in programgraph are text to bescheduled
SPP(X) Base serial languageX and structured co-ordination language
Compositional performancemodel based on skeletonsassociated with programstructure
Determination ofperformance modelfor candidateschedules withminimal executiontime
VDCE Programs composedof tasks frommathematical tasklibraries
Task dependency graphweighted by dedicated taskbenchmarks and dynamicload information
List scheduling usedto match resourceswith application tasks

62
8.2 High-Throughput scheduling
In metacomputing environments a growing community of users are concerned about thethroughput of their applications besides or instead of average response time. To satisfythese users high-throughput computing (HTC) and high-throughput scheduling became acrucial issue. In an HTC environment four groups of people should be taken intoconsideration [LiRa99]:
• Owners• System administrators• Application writers• Customers
The interest of these groups should be reflected by the structure of the ResourceManagement System (RMS) and hence the typical RMS structure is based on a layeredconcept. Such a layered RMS consists of the following layers:
• Local RM layer: This is the lowest layer of the RMS that provides localservices on the resources of the metacomputing system.
• Owner layer: This layer realizes the owner interests by enforcing the owner’spolicy in making public resources to the metacomputing system.
• System layer: It realizes the global resource allocation policy by applyingvarious matchmaking strategies to meet the resource requests and resourceoffers.
• Customer layer: This layer realizes the customer’s (user’s) interests bymaintaining a queue of resource requests and applying various priorityschemes and other RM strategies on requests in the queue. It has also the taskto claim matched resources and hand them off to the application RM layer.
• Application RM layer: This layer is responsible for establishing the runtimeenvironment for the whole application by integrating per task RM services.
The key techniques used in the layered RM architecture are matchmaking and claimingwhich are two consecutive phases of resource allocation. In the first phase, the entitiesthat require matchmaking services send classified advertisements (or shortly classads) toa matchmaker. Owners of resources can advertise their resources for customers andcustomers can advertise their resource needs for resource providers. Upon receiving ads,the matchmaker matches them and notifies the advertisers in case of a successful match.
In the second phase, entities that receive notification of a match should activate aclaiming protocol that validates the match with regard to their mutual authentication andconstraint satisfaction. If the authentication procedure is failed or the constraints imposedby the two parties are not satisfied, the match is rejected by the claiming protocol.Otherwise, the match is validated and the resource allocation can take place according tothe match.

63
This classad-based matchmaking framework has five logically independent components:
1. The evaluation mechanism: It defines the semantics of resource describingexpressions. The evaluation of expressions is usually performed by thematchmaker when matching two classads.
2. The claiming protocol: Claiming is the process by which the resource providerand the consumer agree to use the services of each other. The claimingprotocol provides mutual authentication and verification with respect ofconstraint satisfaction.
3. The advertising protocol: The advertising protocol describes the contents ofads and the means by which these ads can be obtained.
4. The matchmaking protocol: It is a communication protocol through which thematchmaker notifies the advertiser entities on the outcome of thematchmaking process.
5. The matchmaking algorithm: It semantically relates the contents of classads tothe matchmaking process.
There are several significant advantages of the classads framework. First, the paradigmdoes not imply any architecture for the implementation of the matchmaker. Thus, thematchmaking service can be parallelized and distributed for better performance andreliability. Second, the paradigm is very flexible since, the responsibility of thematchmaker ends after identifying the match and it is the full responsibility of theadvertising entities to provide correct advertising, claiming and resource management.
8.3 Resource scheduling
Modern applications as multimedia, video, tele-immersion [www27] etc. have aninsatiable demand for resources. Currently most of the communication structures and alsooperating systems schedule their resources corresponding to the best effort principle, i.e.the scheduler tries its best, but provides no guarantees for deadlines. This is principallyunsuitable when dealing with QoS resources, where guarantees of availability are basicrequirement. Mainly two strategies are applied to cope with this problem:
- Adaptation principle: the system components have to aware of changingparameters and have to adapt to new situation. Adaptation can be done and theoperating-and communication system, the application or at the user domain. Thegoal of this approach is to widen the accepted resource space for a given userQoS. The use of the proper adaptation algorithm will influence the overall systemperformance.
- Reservation principle: resources are assigned to applications. The strategy is usualin operating respectively communication systems supporting real time scheduling.
Considering the Internet2 [www10] requirements QoS is essential. The best effortInternet is inherently unable to guarantee with any reliability the performance necessaryto run advanced network applications envisioned today.

64
QoS is a zero-sum game. QoS does not create bandwidth since, bandwidth allocated tosomeone is bandwidth not available to others. With other words QoS requiresdifferentiated services for the Internet. Almost all Internet traffic crosses manyadministrative boundaries. To achieve a meaningful end-to-end service, all administrativedomains along a QoS flow’s path must agree to treat its traffic especial. Meeting thisrequirement includes many technical and administrative problems (e.g. separatingforwarding from routing, see Fig. 8.2).
"Back-ground"
"Per-packet"
Fig.8.2 Gateway architecture
A “virtual leased line” service model may be implemented with priority queuing andstrict policing. Active networks could contribute in solving these problems. Adaptiveapplications can adjust to their environments to offer their users the best level of servicepossible in any give situation. Although when adaptation is used without network QoScontrol the user level performance of adaptive applications can swing through a widerange from excellent to unacceptable.
Forwarding Table Behavior Table
QoSAgent
RoutingAgent
ForwardingEngine
Link Driver

65
9. Communication media and protocols
Networks are integrated - and often determinative – components of distributed systems.Therefore, a brief overview of the most important advanced communication media(protocols and standards) is provided considering mostly their advantages and limitations.
9.1 Asynchronous Transfer Mode (ATM)
ATM [Boud92] has several significant benefits over such standards as Ethernet or TokenRing. Namely,
• It is a point-to-point switched based network.• It transmits data in fixed-sized cells suitable for transporting voice, data and
video. (ATM represents a fixed size packet switching technology, the packetis relatively short, containing a 48-byte information field and a five-byteheader.) The relatively short cell length is facilitating the integration of voiceand data.
Additional benefits:• Scalability (changing network type, size, operating rates)• Transparency (for applications)• Traffic classification (five traffic classes are supported including one constant,
three variable bit rates and a user definable class).
9.2 Fiber Distributed Data Interface (FDDI)
The original FDDI standard [Held97] defined specifications for fiber optic media, opticaltransmitters and receivers, frame formats, protocols and media access. (The recentdevelopment in the use of twisted-pair expanded it to operate over that transmissionmedium known as CDDI with C referring to copper).
The major advantages are:• Operating rate (high speed channels serving as a backbone net)• Reliability (dual filter optic, self checking and correction)• Optical media (immunity to electrical interference, security - impossible to
tap)
9.3 Fast Ethernet
Fast Ethernet standards retain the original medium access method of the Ethernet i.e.CSMA/CD (Carrier Sense Multiple Access/Collision Detection, which can be describedas a "listen-before-acting" method) but speed up from 10 Mbps to 100 Mbps. (There aredifferent versions of the standards defining different media as unshielded, shieldedtwisted-pair and optical fiber cables.)

66
Another approach creates an entirely new medium access control mechanism. It is basedon hubs and uses a "demand priority" mechanism. This access control system transportsstandard Ethernet frames.
9.4 Internet protocol: TCP/IP
The TCP (Transmission Control Protocol) and IP (Internet Protocol) provide thestandard Internet services. They have several features that are restricting the up-to-dateapplications as a consequence of the size of the system and the new requirements.
9.5 Internet2
A new Internet Protocol (called Abilene [wwww6]) is being developed by UCAID(University Corporation for Advanced Internet Development). This network immenselyexpands support for applications such as virtual laboratories, digital libraries, distance-independent education, voice and video, tele-immersion, etc. (See section onapplications). The advance network (Qbone [www2]) provides support for advancedInternet applications with end-to-end Quality of Service (QoS) technology.
The American national backbone will be capable of operating at OC48 (Optical CarrierLevel 48 = 2.488 Gbps) among the regional networking aggregation points (or gigaPoPs,where PoP means Point of Presence) with OC12 (Optical Carrier Level 12 = 622.08Mbps) to individual institutions gigaPoPs. To increase the backbone capacity to OC192(~10 Gbps) has been decided.
Other important projects are the NSF (National Science Foundation and MCI) BackboneNetwork Service (vBNS) and the basic Internet2 project.
9.6 Quality of Services (QoS)
From the beginning, quality of service (QoS) has been an essential feature to Internet2.Internet today is inherently unable to guarantee any reliability and the performancenecessary to run advanced network application envisions today (e.g. immersion, datamining, etc).
Such applications need to be able to request and receive assurances from the network ofcertain end-to-end transmission parameters. These parameters include bandwidth, delay,maximum pocket loss rate, delay, jitter, etc.

67
10. System problems
10.1 Security
Network and Internet security are critical issues at distributed (network) computing[WhFP]. The problem of network security is hard because of the complex and opennature of the networks themselves.
The three fundamental objectives of computer security are:• Confidentiality (info just for authorized individuals)• Integrity (no modification or deletion)• Availability (concept of denial of service)
At least five security services are usually required:• Authentication (verification of the origin of users, servers, data)• Authorization (access to particular resource is allowed)• Assurance (service provider’s validating)• Auditing (recording system’s operations)• Accounting (tracking the consumption of resources)
To provide these security services, many technologies have been developed andimplemented. For distributed systems the most basic one is file and E-mail encryptiontechnique. For example, PGP 5.0 freeware (PGP = Pretty Good Privacy).
Firewalls are increasingly popular defense mechanism. The primary types of firewalls arepacket filters, application gateways and circuit relays.
Other current technologies include• Kerberos by MIT• SSL (Secure Socket Layer) by Netscape
A typical metacomputing environment, the Legion project’s security architecture andpolicy examples could demonstrate that there are specific security problems that are notaddressed adequately in client-server computing (e.g. group communication mechanismat creating N-way security context, very large and diverse user and resource set, localpolicy heterogeneity, etc.).
10.2 Distributed File Systems
The purpose of a distributed file system [Sing99] is to allow users to share data andstorage resources, despite their dispersed structure and the decentralization of both dataand control, by using a common system. Network based distributed file systems giveusers transparent access to server file systems on global networks.
Some of the most important principles are summarized here:

68
• Probability which means that the file system is platform (machine) and operatingsystem independent.
• Network protocol independence i.e. it can run on multiple transport protocols.• Access transparency. The user and applications can access remote files as if they
were local ones.• Security. The file system architecture enables the utilization of multiple security
mechanism.
Major distributed file systems are:
10.2.1 Network File System (NFS)
NFS uses Remote Procedure Call (RPC) and allows users to access files on remote hostsin exactly the same way as local files. The NFS is a common network file system runningon a large number of different systems. NFS is a stateless service i.e. each accessmessage is self contained (There is no open and close mechanism). References to thelocal file are translated into references to remote file based on the remote file systemdirectories mounted into the local file system.
Since NFS was originally designed as a Local Area Network (LAN) system it hasproblems in the area of data security, data protocols and system administration when it isused as an inter-networked file system.
10.2.2 Andrew File System (AFS)
An AFS uses a local cache to reduce the workload and to increase the performance of adistributed computing environment. It is a true distributed file system, which providesfull file system semantics, transparency across an Internetwork. Its security is based onindividual users rather than on the system. The AFS data protocols use Internet Protocol(IP) therefore, its packets can be routed directly over Internetworks. It provides – withmany other favorable features – file oriented transfers with variable block data sizes. AFScan easily scale to a few hundred thousand users. By using the Kerberos securitytechnology AFS operates in a relatively insecure network environment withoutcompromising data.
10.2.3 Open Software Foundation (OSF) Distributed File System (OSF–DFS)
OSF–DFS is based on AFS with a few added extensions. The primary improvement is theuse of the standardized distributed computing services. It supports caching of data anduses a token mechanism to synchronize concurrent file access by multiple users. Thesecapabilities enable high performance and data integrity and allow the system tointeroperate with other servers on the network.
OSF–DFS also has improved security providing fine grain security, cross-cellauthentication and data encryption.

69
10.2.4 Remote File System (RFS)
RFS is a distributed file system provided with most UNIX systems. It provides an exactcopy of a UNIX file system.
Although, many different technologies can be used to create wide-area networked filesystems, to build a true distributed file system is very difficult. Probably, over the comingyears the distributed file system technologies will advance the quality and usability ofdistributed multiprocessing systems.

70
11. Applications
11.1 Enterprise architectures
Almost all of the major computer companies (IBM, Sun, Oracle, Microsoft, Hewlett-Packard, etc.) offer distributed, component-based architectures. This kind of system playsimportant role in almost all the activities of major large, geographically distributedenterprises and changes both internal and company-customers’ relationships. Here wediscuss corporate architectures, which are relatively abstract, stable and general.
Some companies have created their own component models but increasingly rely onstandard component models to take advantages of existing services, reuse andinterapplication compatibility.
The most popular models are:• Sun’s JavaBeans model with its Enterprise JavaBeans variations, JavaVirtual
Machine (JVM) and Java Development Kit (JDK)• The Object Management Group’s (OMG) CORBA model• Microsoft’s (Distributed) Component Object Model ((D)COM) with its
significant element incorporated directly in the Windows/NT operating system
To demonstrate the main trends of the development of enterprise architectures weselected the corporate architecture development policy of IBM [Gott99].
Although, we have used architecture as a single term, it is important to consider here thatthe term System Architecture – which is a set of abstractions, services, components andcomponent relationship – can be decomposed and simplified into three distinct setsynergistic domains:
• Hardware and software products are required to implement the problemdefined by the Technical Architecture. It describes technology andinfrastructure that are the foundation of the solution.
• Integration Architecture is defined by the service interfaces to the technologyproducts external system integration services and common frameworks (e.g.business object servers design) that will be used to implement the services.The integration architecture describes the shared technical service interfacesprovided by an enterprise’s computing and communication infrastructure.
• Modeling the information, activities and processes of the business defines theInformation Architecture. It describes the content, behavior and interaction ofthe problem domain independent of any technology solution.
• Application scenarios and how the components of the system architecture areused and positioned define the Application Architecture. It identifies thetechniques, tools, interfaces provided by the integration and informationarchitecture to produce applications within the context of an applicationarchitecture model.

71
In the process of recent IBM distributed enterprise application-oriented architecturedevelopment first the Open Blueprint Architecture [Intr97] has to be mentioned. It servesas a reference framework that defines the services required by application in aheterogeneous (i.e. multi-vendor) network environment. In accordance with the previousdiscussion the Open Blueprint can be viewed as an architecture, as a set of technologiesand a basis for specific products. Open Blueprint provides:
• Network services• Distributed system services• Application enabling services
The Open Blueprint components can be combined in different ways. Open Blueprint is areference model that defines the functions necessary for heterogeneous, networkedcomputing. It defines components that can provide either procedural or object-orientedinterfaces. On the top of the basic level there are various building blocks that provideinfrastructure. The infrastructure building blocks can be combined into variouscomputing “styles”. For example, client/server, N-tier, network computing based systemscan be implemented. Recently, IBM introduced an updated version of Open Blueprinttailored for the Internet and e-commerce, called the Network Computing Architecture(NCA).
The Network Computing Framework (NCF) represents IBM’s approach to provide Java-oriented services and capabilities [Gott99]. NCF provides a set of IBM software serverscentered on Java Application Programmer’s Interfaces (APIs) and JavaBeans (includingEnterprise JavaBeans).
Another recent IBM initiation is the San Francisco project [Bohr99]. The main objectiveof the project is to provide business process components that can form the basis ofrapidly developed distributed solutions for (mission-critical) business applications usingintranet, extranet or the Internet. The idea is that IBM collaborates with IndependentSoftware Vendors (ISVs) by defining and building a set of distributed object frameworksspecifically for targeted application domains. They are called Technical ReferenceArchitectures and include both functional and operational aspects of informationtechnology system. The functional aspect is concerned with the functionality ofcollaborating software components while the operational aspect is concerned with thedistribution of components across the organization’s geography Architecture supports
Typical technical reference architectures [LoGa99] are as follows:
• Thin-client transactional (it addresses the need of enterprise-scaleadministrative business as customer sales and services, order processing, etc.)
• Collaboration (working together, communication, use of commoninformation)
• Business intelligence (applications include executive information and decisionsupport systems, data mining, etc.)
• Call center (customer relationship management)

72
• Mobile computing (operation within a mobile environment)
In addition to the reference architectures a new common architecture descriptionlanguage has been developed. Three levels of abstraction are used, called elaborationpoints. (These points can be used as potential entry points for reuse.)
• Initial is used to describe the architecture with minimal constrains• Logical for the set of design including network topology, differentiation of
clients and servers, etc.• Physical for defining hardware architecture, operating system, etc.
The technical reference architectures are linked to a context, which describes the purposeand requirements. Together with the context information there are a number of informalcontextual views representing different aspects of existing and to-be systems (e.g. accesspoints).
11.2 Selected application areas
Metacomputing, computational grids provide a prospect of innovative new uses ofcomputers. It means new application areas as well. The grid application can be classifiedinto the following categories:
- Distributed supercomputing: very large problems needing lots of CPUs,memories, etc. Typical application example: DIS (Distributed InteractiveSimulation).
- On-demand computing: remote resources integrated with local computation.Typical application example: medical instrumentation.
- High-throughput computing: solving of large number of loosely coupled orindependent tasks with unused (idle) processor cycles. Typical examples:cryptography.
- Collaborative computing: supports communication and collaborative workamong multiple participants. Typical example: collaborative design.
- Data-intensive computing: synthesis of new information from many or largedata sources. Typical example: meteorological forecasting.
A few specific representative application areas are introduced to show theinterrelationship between the new technologies and applications.
Tele-Immersion
The term tele-immersion [www27] refers to the use of immersive virtual reality systemsover the network. High-end tele-immersive, collaborative environments represent themost technologically advanced human-computer interface under development today.Requirements for such environments include delivery of many channels of real-timeaudio and video into visual/audio display environment, scalable interconnections of manyusers and worlds, close coupling of the virtual worlds to the distributed networks of

73
large-scale simulations, data bases and real-time interactions. The main types of virtualreality devices are projection-based, monitor-based and head-mounted systems. A virtualenvironment generator includes additional components as graphic display, speechrecognizer for commands, head/eye/hand tracking electronics, haptic/tactile kinestheticsystem, audio synthetizer and localizer, etc., all very high-tech devices.
Typical tele-immersion applications are: interactive scientific visualization, virtualprototyping industrial design, scene acquisition, rendering, telepresence. In the US thereare tool-oriented and real-life application plans in the frame of the National Tele-Immersion Initiative.
Tele-Manufacturing
The goal of tele-manufacturing [www28] is creating an automated rapid prototypingcapability on the Internet. It should be viable for engineers and scientists to use over longdistance. It should provide facilities for the different phases of the engineering process asactual design, visualization, analysis, manufacturing, assembly, testing.
Virtual Laboratory
A virtual laboratory [www29] is a set of general purpose and/or specialized instrumentsinterfaced to a set of computer systems connected to the Internet. It is able to configureinstruments and data logging, analysis and processing remotely. The supporting computerhardware/software system can be built up on a bottom-up layered functional structurewhere layer1 is a high-end distributed computing and networking layer which provides ahigh bandwidth, low latency communication platform. Layer2 could be a datawarehousing cooperative information management facility, which provides variant levelsof information handling data manipulation and archiving services. Layer3 could enablethe communication with devices connected with the laboratory as well as communicationand collaboration among users. Layer4 could present an environment where all typesinteractive calculating context sensitive simulation, geometric probing, etc. are supported.Layer5 provides an interface facility for the virtual laboratory. Users of the virtuallaboratory can access it via this interface to do their scientific-engineering experiments.Domain specific tool for example for physics-computing, system engineering, bio-informatics could be found in this layer as well.
Distributed Data Mining
Data mining [www30] is emerging as key technology for a variety of scientific,engineering, medical and business applications. The goal of data mining [Intr98] is toprovide information from data by the automatic discovery of patterns, changesassociations and anomalies in large data sets. Data mining finds these patterns andrelationships by building models. The main kinds of models are predictive anddescriptive models. In data mining technique classification, regression and time seriesmodels are referred to as supervised learning while clustering, association and sequencediscovery are referred to as unsupervised learning. There are many open problems to

74
developing data mining algorithms, applications and systems for mining large distributeddata sets that are logically and physically distributed. Organizations that aregeographically distributed need a decentralized approach to decision support.
A major challenge for data mining is not only to develop data mining applications butalso to integrate them effectively with other applications, systems and business processesthroughout a large-scale enterprise.
11.3 Selected European projects
Network-based distributed processing is based on many research fields and informationtechnology areas. It includes the different network technology and applicationdevelopments ‘traditional’ distributed, parallel, cluster computing, languages, tools, etc.Therefore it is impossible to show a full picture of the related European research anddevelopment activities. The selection introduced here very briefly should be considered arandom, ad hoc sample of former and current European projects.
The central objective of the METODIS (Metacomputing TOols for DIStributed) project[www16] (HLRS: High Performing Computing Center, Stuttgart) is to develop tools thathelp to exploit the metacomputing capabilities available in Europe as a result ofestablishing high speed networks and supercomputing centers. A metacomputing MPIlibrary implemented both on TCP/IP and on ATM serves as application programmingmodel.
The used building blocks include the PACX-MPI (Parallel Computer eXtension to MPI)[www17]. It concentrates on expanding MPI for environments that couple differentplatforms. With this library the communication inside each system component relies ontuned MPI versions of different vendors while communication between two systemcomponents is based on the TCP/IP standard protocol. For the data exchange each sidehas to provide two extra nodes for communication, one for each direction. While onenode is always waiting for MPI commands from inner nodes to transfer to the other side,the other node is executing commands received from the other system component andhands data over to its own inner nodes.
Since September 1996 PACX-MPI is part of G-WAAT (Global Wide Area ApplicationTestbed) [www15]. The G-WAAT project partners – HLRS (High PerformanceComputing Center, Stuttgart), PCS (Pittsburgh Supercomputing Center) and SNL (SandiaNational Laboratories) demonstrated different supercomputing applications usingmachines connected by a transatlantic ATM link that ensures high speed connectivity.
Visualization and performance analysis plays important role in metacomputingapplications. In the METODIS architecture [www16] the Vampir visualization andanalysis program (Pallas product) [www13] was used. It provides a way to graphicallyanalyze runtime event traces produced by MPI applications by different time line viewsand parallelism displays and communication and execution statistics.

75
In the framework of the G-WAAT COVISE (Collaborative Visualization and SimulationEnvironment) [www14] was used. It was designed by HLRS for distributed collaborativeworking on a network infrastructure and integrates simulation, post-processing andvisualization functionalities.
Paderborn Center for Parallel Computing developed RSD (Resource and ServiceDescription) for specifying hardware and software components of metacomputingenvironments (see Section 7.1). The graphical interface of RSD [Brun98] was developedby CNUCE-CNR in Pisa and allows metacomputer users to specify their resourcerequirements. On the other side the service provider can specify the topology andproperties of the available system and software resources. An additional internal object-oriented representation is used to link different resource management systems and servicetools.
GENIAS Software GmbH plays and important role [www26] in European parallel anddistributed software development. Here only a single product, CODINE [www12] isintroduced briefly. It is Resource Management System to optimize utilization of allsoftware and hardware resources in a heterogeneous networked environment. TheCODINE system encompasses four types of daemons and a variety of tools. The masterdaemon acts as a clearinghouse for jobs and maintains a database. The scheduler daemonis responsible for the mapping of jobs to the most suitable queues submitted by themaster daemon together with a list of requested resources. There is an execution daemonon every machine where jobs can be executed and reports periodically the status ofresources to the master daemon. One or more communication daemons have to run inevery system component and are responsible for the asynchronous communicationbetween the other daemons. It controls the communication via standard TCP ports.
The Kensington software architecture by the Imperial College Parallel Computing Centrehas been designed to address the demands of enterprise data mining [Chat98]. Databasesanywhere on the Internet can be accessed via a JDBC (Java Database Connectivity)connection. The architecture is a three-tier client/server architecture. The client handlesinteractive creation of data mining tasks, visualization, models and sampling of data. Theapplication server authenticates users, provides persistent storage and access control forobjects and controls task execution and data management. The third-tier servers provideboth database and data mining services. Distributed data mining was demonstrated atSupercomputing’98.
The NWIRE project of the Computer Engineering Institute, University of Dortmund hasdeveloped architecture to link various computing resources to a metacomputing system[ScYa98]. It includes many independent and geographically separated components andusers. While the architecture has similar features to the Globus architecture in generalthere are also several differences e.g. in scheduling, resource allocation and informationmanagement. It realizes variable scheduling objectives and makes possible the existenceof additional independent schedulers. It supports resource reservation and providesguarantees, reservation and multiside applications.

76
The institutes of GMD (German National Research Center for Information Technology)[www21] [www23] have been and still are very active in different fields of parallel,distributed cluster, meta and supercomputing. GMD SCAI (Institute for Algorithms andScientific Computing) [www22] [www24] took part with different institutions (amongothers MTA SZTAKI) in the WINPAR Esprit project for developing a programmingenvironment for windows-based parallel computing. The TRAPPER system [AhBa99],which is a graphical programming environment for parallel systems, was developed bySCAI in cooperation with Genias and Daimler-Benz.
GMD FOKUS as a prime contractor with seven European and a Canadian and a Japanesepartners led the MIAMI (Mobile Intelligent Agents for Managing the InformationInfrastructure) [www25] project. Its key objectives are: creation a unified MIA (MobileIntelligent Agent) framework by refining and enhancing the OMG (Object ManagementGroup) MASIF (Mobile Agent System Interoperability Facilities) specification,developing MIA based solutions for the management of Open EII (European InformationInfrastructure), producing recommendations to infrastructure, terminal and serviceproviders. MASIF is built on the top of CORBA.
EKV++ GmbH has developed a MASIF compliant mobile agent environment calledGrasshopper. It allows building agent-based distributed applications by creatingautonomous agents, migrating them transparently locating agents and sending messagesthem. It provides interoperability with other OMG-MASIF standard compliant agentsystems.
GMD (Sankt Augustin) has developed a Web-based platform called BSCW (BasicSupport for Cooperative Work). It provides support for platform independent cooperationin geographically distributed projects. The basic idea of the system is the autonomouslymanaged Shared Workplace used for task organization and coordination.
An important step for Europe-wide cooperation is the establishment of Euro ToolsDatabase [www11] [www19]. It contains software tools for computational and dataintensive applications sorted by categories. European institutions are more active in theJavaGrande Forum [www20] an association making Java the grand programminglanguage [www18] to support high-end computing applications in science andengineering. A European JavaGrande Forum SIG (Special Interest Group) has beencreated recently.
The ProActive PDC [www18], a Java Library for Parallel, Distributed and ConcurrentComputing and metacomputing by INRIA (France) has the following basic features:active objects, asynchronous calls, automatic future-based synchronizations ("wait-by-necessity") reuse through polymorphism between standard and active objects andmigration. It is only made of standard Java classes and requires no changes to JVM (JavaVirtual Machine).

77
12. Summary and Conclusions
There are a large number and diverse range of emerging distributed systems currentlybeing developed. Therefore it is hard to define the related systems range and the keyissues. In this prospective report we have attempted to describe and discuss many aspectsof heterogeneous distributed processing including the relevant programming models,distributed system implementation support, programming environments and mainarchitectural issues.
We started of by discussing why there is a need for metacomputing systems. Then, wedescribed the progress from parallel supercomputers to clusters and from clusters tometacomputers. We tried to select and describe the most important actual systems andoutlined some of the benefits and experiences learned.
Because the scope of important problems is very broad, some key areas as scheduling andresource scheduling, communication media and protocol system problems as security anddistributed file management were only touched on. Similarly, the ever increasingapplication fields were only demonstrated by a few important cases.
It is very difficult to predict the future since in a field as computing, the technologicaladvances are moving very fast. However, some trends are evident. The first issue to bementioned is heterogeneity. The environment has to support heterogeneous hardware andsoftware platforms including different level and kind of architectures, languages,standards, etc. Applications that run in network-based computing environments, shouldbe able to exploit this heterogeneity to match the computational requirements andcommunication needs.
The second important fact is that widespread distributed processing applicationsnecessitate the availability of high level, easy to use tools. The Globus MetacomputingToolkit is currently the most comprehensive attempt at providing this kind ofenvironment. The Globus team has taken a very pragmatic approach by using existingstandard software components to provide many of its services. This is the road we shouldfollow further to reach the long time predicted situation when distributed processingexperts and users will belong to different “gangs”.
The Java programming language successfully addresses several key issues ofdevelopment of distributed environments. Java, with its related technologies and growingrepositories of tools is having a large impact on the growth and development ofmetacomputing environments. We also believe that the framework incorporatingCORBA services will be very influential on the design of heterogeneous distributedenvironments. Beside the commodity approach, particularly in metacomputing systems,the toolbox approach like Globus will play an important role as long as the executionspeed of higher level commodity systems cannot compete with the efficiency of Globus.Nevertheless, the object-oriented programming model seems to become generallyaccepted in heterogeneous distributed systems. It is obvious in the commodity approach

78
based on Java and CORBA but it also appears as the programming interface of lowerlevel metacomputing systems as shown by the Legion approach.
The third observation is the problem of security. Providing adequate security is a verycomplex issue. A careful balance needs to be maintained between the usability of anenvironment and security mechanisms utilized. Security is a matter of tradeoffs – moreusability vs. more security and better performance vs. more security.
Finally, we should conclude that it is hard estimate and at the same time over-estimate thegeneral effects of these new lines of heterogeneous distributed computing systems. It willhave serious social consequences and is going to have an effect as revolutionary asrailroads had in the American mid-West in the early nineteenth century [FoKe99].According to this analogy, many researchers predict – and we share their view – that atsome stage in the future, our computing needs will be satisfied in the same manner as weuse electricity power grid.

79
13. Used acronyms
ADI Abstract Device InterfaceAM Access ManagerAPI Application Programmer’s InterfaceAFS Andrew File SystemATM Asynchronous Transfer ModeCDDI Copper Distributed Data InterfaceCGI: Common Gateway InterfaceCIS Center Information SystemCOM Common Object ModelCOMA Cache Only Memory ArchitectureCORBA Common Object Broker ArchitectureCRM Center Resource ManagerCSMA/CD Carrier Sense Multiple Access/Collision DetectionDCE Distributed Computing EnvironmentDCOM Distributed Common Object ModelDII Dynamic Invocation InterfaceDIT Directory Information TreeDOE Department Of EnergyDPSS Distributed Parallel Storage SystemDSI Dynamic Skeleton InterfaceFDDI Fiber Distributed Data InterfaceGASS Global Access to Secondary StorageGEM Globus Executable ManagerGIF Graphics Interchange FormatGRAM Globus Resource Allocation ManagerGSI Globus Security InfrastructureHBM Heart Beat MonitorHLL High Level LanguageHPF High Performance FortranHPSS High Performance Storage SystemHTML Hyper-Text Markup LanguageHTTP Hyper-Text Transfer ProtocolIDL Interface Definition LanguageIIOP Internet Inter-ORB ProtocolIP Internet ProtocolIPG Information Power GridISV Independent Software VendorJDBC Java Database ConnectivityJDK Java Development KitJIT Just-In-TimeJPEG Joint Photographers Expert GroupJVM Java Virtual MachineLAN Local Area Network

80
MASIF Mobile Agent System Interoperability FrameworkMDS Metacomputing Directory ServiceMIMD Multiple Instruction Multiple DataMPEG Moving Picture Expert GroupMPI Message Passing InterfaceMPMD Multiple Process Multiple DataMPP Massively Parallel ProcessorNASA National Aeronautics and Space AdministrationNCF Network Computing FrameworkNFS Network File SystemNOW Network of WorkstationsNPACI National Partnership for Advanced Computational InfrastructureNSF National Science FoundationNUMA Non-Uniform Memory AccessOLE Object Linking and EmbeddingOMG Object Management GroupOO Object OrientedORB Object Request BrokerOSF Open Software FoundationPC Personal ComputerPVM Parallel Virtual MachineQM Queue ManagerQoS Quality of ServicesRFS Remote File SystemRMI Remote Method InvocationRPC Remote Procedure CallRSL Resource Specification LanguageRSD Resource and Service DescriptionSIMD Single Instruction Multiple DataSMP Symmetric Multi ProcessorSMS Symmetric Multiprocessor SystemSPMD Single Process Multiple DataSSI Single System ImageSSL Secure Socket LayerTCP Transmission Control ProtocolUCAID University Corporation for Advanced Internet DevelopmentUDP User Datagram ProtocolUMA Uniform Memory AccessURL Uniform Resource LocatorVB Visual BasicVRML Virtual Reality Modeling Language

81
14. References
[Adve95] V. Adve, J.-C. Wang, J. Mellor-Crummey, D. Reed, M. Anderson, and K.Kennedy: An integrated compilation and performance analysis environmentfor data parallel programs. In Proc. Supercomputing’95, 1995
[AhBa99] D. Ahr and A. Baeker: Project Workspaces for Parallel Computing – TheTRAPPER Approach, EuroPar’99 Conf., 1999
[Baek97] Bäcker, A. et al.: WINPAR, Windows-Based Parallel Computing, in Proc.of the ParCo'97 Conference, Bonn, 1997
[Bara96] R. Baraglia et al.: Experiences with a Wide Area Network metacomputingmanagement Tool Using IBM SP-2 Parallel Systems, Concurrency: Practiceand Experience, Vol. 8., 1996
[Berm99] F. Berman: High-Performance Schedulers, in [FoKe99], pp. 279-310
[Bert98] M. Bertozzi, et al.: DISCO Report on the state-of-the-art of PC ClusterComputing, Technical Report, DISI-TR-98-09, 1998, pp. 55
[Bohr99] K.A. Bohrer: Architecture of the San Francisco framework, IBM SystemsJournal, Vol. 37(1998), No. 2.
[Boud92] J.Y. Le Boudec: The Asynchronous Transfer Mode: A Tutorial, ComputerNetworks and ISDN Systems, Vol. 24(1992), May.
[Brun98] M. Brune et al.: Specifying Resources and Services in metacomputingEnvironments, Parallel Computing, Vol. 24, 1998, pp. 1751-1776
[BuCL99] I. Busse, S. Covaci and A. Leichsenring: Autonomy and Decentralization inActive Networks: A Case Study for Mobile Agents, Proc. of the First Int.Conf. on Active Networks, 1999, pp. 165-179
[CaDo98] H. Casanova and J. Dongarra: Using Agent-based Software for ScientificComputing in the NetSolve System, Parallel Computing, Vol. 24, 1998, pp.1777-1790
[Chat98] J. Chattratichat, et al.: An Architecture for Distributed Enterprise DataMining, In: High Performance Computing and Networking (eds. P. Slot, M.Bubak, A Hoekstra, B. Hertsberger), Springer 1999, pp. 573-582.
[Dcom96] DCOM Technical Overview, Microsoft Corporation, 1996.

82
[Eick98] Th. Eickermann, et al.: Metacomputing in gigabit environments: Networks,tools, and applications, Parallel Computing, Vol. 24, 1998, pp. 1847-1872
[Entr98] Enterprise JavaBeans to CORBA Mapping Sun Microsystems, Inc. 1998.
[FoFu99] G.C. Fox and W. Furmanski: High-Performance Commodity Computing, in[FoKe99], pp. 237-256
[FoKe99] I. Foster and C. Kesselman (editors): The GRID Blueprint for a NewComputing Infrastructure, Morgan Kaufmann, 1999, pp. 677
[FoKe99b] I. Foster and C. Kesselman: The Globus Toolkit, in [FoKe99], pp. 259-278
[GaGr99] D. Gannon and A. Grimshaw: Object-Based Approaches, in [FoKe99], pp.205-236
[GEIS94] A. Geist, A. Beguelin, J. Dongarra, W. Jiang, R. Mancher, V.S. Sunderam:Parallel Virtual Machine – A User’s Guide and Tutorial for NetworkedParallel Computing. MIT Press, London, 1994.
[GeKP96] G.A. Geist, J.A. Kohl and P.M. Papadopoulos: PVM and MPI: aComparison of Features, xx, 1996
[Gott99] E. Gottschalk: Technical overview of IBM’s Java initiatives, IBM SystemsJournal, Vol. 37(1998), No. 3.
[GrLS94] W. Gropp, E. Lusk, A. Skjellum: Using MPI: Portable ParallelProgramming with the Message-Passing Interface. MIT Press, London,1994.
[HeEt91] M.T.Heath and J.A.Etheridge, Visualizing the Performance of ParallelPrograms, IEEE Software, 8(5), 1991, pp. 29-39
[Held97] G. Held: Virtual LANs Constructions, Implementation, and Management, J.Wiley & Sons, Inc., 1997
[Hoar85] C.A.R. Hoare: Communicating Sequential Processes, Prentice Hall, 1985,pp. 256
[HPFF93] High Performance Fortran Forum. High Performance Fortran languagespecification. Specific Programming, 2(1-2):1-170, 1993.
[Inmo88] Inmos Ltd.: occam 2 Reference Manual, Prentice Hall, 1988, pp. 133
[Intr97] Introduction to the Open Blueprint: A Guide to Distributed Computing. IBMG326-0395-03, 1997

83
[Intr98] Introduction to Data Mining and Knowledge Discovery, Two CrowsCorporation, 1998
[Java98] JavaSpaces Specification Sun Microsystems, Inc. 1998
[John99] W.E. Johnston: Realtime Widely Distributed Implementation Systems, in[FoKe99], pp. 75-104
[Kacs99] P. Kacsuk: Systematic Debugging of Parallel Programs Based on CollectiveBreakpoints, Proc. of Int. Symp. On Software Engineering for Parallel andDistributed Systems, 1999, pp. 83-96
[KaDF98] P. Kacsuk, G. Dózsa, F. Fadgyas: Designing parallel programs by thegraphical language GRAPNEL, Microprocessing and Microcomputing, Vol.41, 1996, pp. 625-643.
[KDFL98] P. Kacsuk, G. Dózsa, F. Fadgyas, R. Lovas: GRADE: A GraphicalProgramming Environment for Multicomputers. Computers and ArtificialIntelligence, Vol. 17, 1998, No. 5, pp. 417-427.
[LiLM88] M. Litzkov, M. Livny, M.W. Mutka: Condor – a hunter of idle workstation.In Proc. Eights Int. Conf. of Distributed Computing Systems, pp. 104-111,1998.
[LiRa99] M. Livny and R. Raman: High-Throughput Resource Management, in[FoKe99], pp. 311-338
[LoGa99] P.T.L. Loyd and G.M. Galambos: Technical reference architectures,IBM Systems Journal, Vol. 38(1999), No. 1
[Mail95] Maillet, E.: Issues in Performance Tracing with Tape/PVM, in Proc. ofEuroPVM’95, Lyon, 1995, 143-148
[Main96] A. Mainwaring: Active message application programming interface andcommunication subsystem organization, Technical Report, Department ofComputer Science, UC Berkeley, Berkeley, CA, 1996.
[MaTW94] M.D. May, P.W. Thompson and P.H.Welch (editors): Networks, Routersand Transputers: Function, Performance, and Application, IOS Press, 1994,pp. 210
[Orfa96] R. Orfali et al.: The Essential Client/Server Survival Guide, Wiley, 1996.

84
[PaLC95] S. Pakin, M. Lauria, A. Chien: High performance messaging onworkstations: Illionis Fast Messages (FM) for Myrinet, in: Proc. ofSupercomputing’95, IEEE Computer Society Press, 1996.
[Pfis95] G.F. Pfister: In Search of Clusters, Prentice Hall, 1995, pp. 414
[ScYa98] U. Schwiegelshohn and R. Yahyapour: Resource Allocation and Schedulingin Metasystems, In: High Performance Computing and Networking (eds. P.Slot, M. Bubak, A Hoekstra, B. Hertsberger), Springer 1999, pp. 851-860.
[SiFK97] D.Sima, T.Fountain, P.Kacsuk: Advanced Parallel Computer Architectures,Addison-Wesley, Harlow, p. 750, 1997.
[Sing99] H. Singh: Progressing to Distributed Multiprocessing, Prentice Hall, 1999
[Turc96] L.H. Turcotte, Cluster Computing, in Parallel and Distributed ComputingHandbook (ed.: A.Y. Zomaya), McGraw-Hill, 1996, pp. 762-779
[Vajd98] F. Vajda: The Pros and Cons of Web Programming. Proc. of the 24th
EUROMICRO Conference, IEEE Computer Society, 1998, pp. 984-988
[Wald98] J. Waldo: Jini Architecture Overview, Sun Microsystems, Inc. 1998
[WhFP96] G.B. White, E.A. Fish and U.W. Pooch: Computer System and NetworkSecurity, CRC Press, 1996
[Zhan98] L. Zhang: A Scalable Resource Management Framework for DifferentiatedServices, Proc. of the First Internet2 Application/Engineering QoSWorkshop (May 21-22, 1998, Santa Clara, California), UniversityCorporation, 1998, pp. 37-39.
[www1] Overview of CORBAhttp://www.cs.wustl.edu/~schmidt/corba-overview.htm
[www2] National Computational Science Alliancehttp://www.ncsa.uiuc.edu./alliance
[www3] Java Servlet APIhttp://java.sun.com/products/servle
[www4] Requirements for OO + Web Integrationhttp://www.obj.com/survey/Rqmts.htm
[www5] Metacomputing Linkshttp://www.sis.port.ac.uk/~mab/Metacomputing

85
[www6] Abilene Project Summaryhttp://www.ucaid.edu/abilene/html/project_summary.htm
[www7] Introducing Java Beanhttp://www.ens.fr/~castagna/JAVAtutorial/beans/whatis/index.htm
[www8] RMI Documentationhttp://java.sun.com/products/jdk.1.1/docs/guide/rmi/index.htm
[www9] VM Spec Structure of the Java Virtual Machinehttp://idefix-4.cskuleuven.ac.be/~bartvh/java/vmspec/Overview.doc.htm
[www10] Internet2http://www.Internet2.edu/html
[www11] Parallel Computing Projectshttp://www.hlrs.de/structure.organisation/par/projects
[www12] Codine – technical descriptionhttp://www.geniasoft.com/products/codine/tech_desc.htm
[www13] Vampir – Pallas productshttp://www.pallas.de/pages/vampir.htm
[www14] COVISE, Organisation – Visualisation, HLRShttp://www.hrls.de/structure/organisation/vis/covise/
[www15] G WAAThttp://www.hrls.de/people/resch/PROJECTS/GWAAT.htm
[www16] METODIShttp://www.hrls.de.structure/organisation/par/projects/metodis/#Block
[www17] PACX-MPI Projecthttp://www.hrls.de/structure/organisation/par/projects/pacx-mpi/index.htm
[www18] ProActive PDC – Java parallel and Distributed Concurrent ComputingPortable Libraryhttp://www-sop.inria.fr/sloop/javall/home.htm
[www19] EuroTools Databasehttp://www.irisa.fr/EuroTools/
[www20] JavaGrandehttp://www.javagrande.org

86
[www21] Site Map for GMD’s BSCW Web Sitehttp://bscw.gmd.de/sitemap.htm
[www22] Software Engineering Tools for Parallel Programming – SCAIhttp://www.gmd.de/SCAI/area-tools.htm
[www23] GMD – German National Research Center for Information Technologyhttp://www.gms.de/Welcome.en.htm
[www24] Metacomputing and Networking – SCAIhttp://ftp.gmd.de/SCAI/area-popcorn.htm
[www25] MIAMI projecthttp://www.ee.ucl.ac.uk/~dgriffin/miami/
[www26] Trapper – A Graphical Programming Environment for Parallel Systemshttp://www.geniasoft.com/products/trapper/trap_index.htm
[www27] Tele-Immersion – The Killer Application for High Performance Networkshttp://wwwdoctest.nesa.uiuc.edu/People/pls/recent-talks/vanguard/index.htm
[www28] Tele-Manufacturing Facility Projecthttp://www.sdsc.edu/tmf/Whitepaper/whitepaper.html
[www29] Introduction of Virtual Laboratoryhttp://vlab.ee.nus.edu.sg/vlab/intr.html#purpos
[www30] Data Mining Research: Opportunities and Challengeshttp://www.ncdm.uic.edu/dmr-v8-4-52.htm
[www31] G.E. Fagg and J.J. Dongarra: PVMPI: An Integration of the PVM and MPISystems, http://www.netlib.org/utk/papers/pvmpi/paper.html
[www32] LAM / MPI Parallel Computinghttp://www.mpi.nd.edu/lam
[www33] IMPI, Interoperable MPI, National Institute of Standards and Technologyhttp://impi.nist.gov/IMPI/Impi.htm
Related Documents











