“Applicazione della conformal prediction alla network anomaly detection” Relatori: Aniello Castiglione Alfredo De Santis Ugo Fiore Francesco Palmieri Partecipanti: Giuseppe Luciano Alessandro Merola Emanuele Pesce Università degli Studi di Salerno Corso di sicurezza

Network Anomaly Detection col Conformal Prediction
Jul 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

“Applicazione della conformal prediction alla network anomaly detection”
Relatori:Aniello CastiglioneAlfredo De SantisUgo FioreFrancesco Palmieri
Partecipanti:Giuseppe LucianoAlessandro MerolaEmanuele Pesce
Università degli Studi di Salerno
Corso di sicurezza

Outline
● Network anomaly detection● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri

Outline
● Network anomaly detection● Introduzione● Tipi di attacchi
● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri

Network anomaly detectionIntroduzione
● L'obiettivo è quello di individuare flussi di rete anomali
● Un flusso è una quintupla formata da:
● Indirizzo IP sorgente
● Indirizzo IP destinazione
● Numero porta della sorgente
● Numero porta della destinazione
● Protocollo

● Un flusso viene detto anomalo se si discosta dal comportamento standard o normale
● Ad esempio quando si è in presenza di attacchi
Network anomaly detectionIntroduzione

Network anomaly detectionTipi di attacchi
● Gli attacchi: DoS, user to root, remote to User, backdoor,
probe (port scan), ecc.● Le contromisure, gli Intrusion Detection System
(IDS): host based network based ibridi
● Come lavora un IDS: Anomaly Detection Misure Detection

Outline● Network anomaly detection● Conformal prediction
● Introduzione● Applicazioni● Descrizione generale● Utilizzo nella soluzione proposta
● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri

Conformal predictionIntroduzione
● Recente tecnica di machine learning ideata da Shafer e Vovk nel 2007
● L'idea è quella di utilizzare l'esperienza passata per effettuare predizioni su nuovi input con precisi intervalli di confidenza

Conformal predictionApplicazioni
● Applicazioni nel campo medico:● Nel 2009, Lambrou e Papadopoulos per la diagnosi del cancro al seno
● Nel 2009, Vovk, Papadopoulos e Gammerman per la diagnosi di dolori addominali acuti

● Sia z una coppia formata da● Feature: caratteristiche dell'esempio● Label: indica la classe di appartenenza
● Sia B, un insieme di elementi z che rappresentano la storia passata.
● Dato un nuovo input x, di cui non si conosce la label, si vuole determinare la rispettiva classe di appartenenza y.
Conformal predictionDescrizione generale

Conformal predictionDescrizione generale
● Requisiti: interscambiabilità dei dati● Richiede:
Misure di non conformità● Distanze
● La scelta della misura di non conformità e della distanza influiscono fortemente sulle performance finali

Misure di non conformità che utilizzano distanze:
● Misura di non conformità: Una funzione a valori reali, A(B,z), che indica quanto è differente z dagli elementi di B.
Average distance Nearest Neighbor Support Vector Machine
● Distanze Squared euclidean distance● Cosine similarity
Conformal predictionDescrizione generale

Average Distance
Calcolo basato sulla distanza di z dalla media degli elementi in B (compreso z) che hanno la stessa classe di zA (B , z )=¿ z̄
B− z∨¿
Conformal predictionDescrizione dell'algoritmo: misure di
non conformità utilizzate
Punti con la stessa classe di z
Punti con la classe diversa da z
Media degli elementi che hanno la stessa classe di z
A(B , z )=∣z̄B−z∣

Nearest Neighbors
Calcolo basato sulla distanza dell'elemento più vicino in B, con la stessa classe.
A(B ,z )=distanza da zall ' elemento più vicino∈Bconla stessa classedistanza daz all ' elemento più vicino∈Bconclasse differente
Conformal predictionDescrizione dell'algoritmo: misure di
non conformità utilizzate
Punti con la stessa classe di z
Punti con la classe diversa da z

Support Vector MachineCalcolo basato sulla distanza di z dall' iperpiano separatore ottimo
Conformal predictionDescrizione dell'algoritmo: misure di
non conformità utilizzate
Iperpiano separatore
Rosso e verde indicano le classi

Errori del Support Vector Machine Troppo rumore nei dati Dati non linearmente separabili
Conformal predictionDescrizione dell'algoritmo: misure di
non conformità utilizzate
Iperpiano separatore
Rosso e verde indicano le classi

Squared euclidean distance:
● Cosine similarity:
d ( p ,q)=√∑i=1
n
(q i−pi)2
similarity ( p ,q)=p⋅q
∥p∥⋅∥q∥
Conformal predictionDescrizione dell'algoritmo: distanze
utilizzate
p
q

Conformal predictionAlgoritmo generale
Sia: una sequenza di esempi, dove è l'i-esimo esempio con
Avendo la sequenza di esempi osservata (x1,y1), (x2,y2), ..., (xn-1,yn-1) e xn, si vuole prevedere y fornendo una regione di predizione
Tale regione denota l’insieme di tutti i possibili valori che la predizione y può assumere, dove ogni valore è corretto con una probabilità di almeno 1 - .
Γε (z1, z2,. .., zn−1 , xn)
B={z1, z2, ... , zn−1}
z i=(x i , y i) 1⩽i⩽n−1
ε

Conformal predictionAlgoritmo generale

Conformal predictionAdattamento dell'algoritmo
all'anomaly detection● ConformalPrediction(A,B, xn, y) è la funzione
che data xn e y restituisce la probabilità che xn abbia quella label, cioè appartenga a quella classe.
● Le classi sono due:● Flusso normale;● Flusso anomalo.
● Una feature del flusso viene passata all'algoritmo prima con un label poi con un'altra.
● La label a cui viene associata la probabilità maggiore è quella di appartenenza della feature.

Conformal predictionAlgoritmo adattato
Dove py indica la probabilità che xn appartenga alla classe y

Outline● Network anomaly detectioni● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri

Il Framework di analisi dei dati
● Approccio basato sul machine learning:● Raccolta dati● Pre-processing● Feature selection● Addestramento supervisionato

Il Framework di analisi dei dati Raccolta dati
Dataset● Synflood01: dati artificiali creati con Zenmap (un port scanner). Cattura di pacchetti contenenti anomalie e dati normali.
● Mawi02*: dataset disponibile online.
*Measurement and Analysis on the WIDE Internet (MAWI) è una raccolta di dataset contenente traffico di dati.

Il Framework di analisi dei datiPre-processing
Analizzati dei pacchetti con BRO (un IDS) che ci ha restituito flussi dei dati.
● I flussi hanno queste feature:● Ip e porta di origine e destinazione
● Protocollo
● Byte spediti e ricevuti
● Durata servizio
● Stato connessione
● Altri...

Il Framework di analisi dei dati Feature selection
● Individuazione del sottoinsieme di feature più significative per la discriminazione
● Le feature selezionate: durata della connessione numero di byte ricevuti flag tcp/udp attivi numero di porta della connessione numero di pacchetti del flusso

Il Framework di analisi dei dati Addestramento supervisionato
● Suddivisione dei dataset:
● Traning set: 60%. Dati utilizzati per addestrare il modello discriminatorio.
● Test set: 40%. Dati utilizzati per valutare le prestazioni del modello addestrato.

Outline● Network anomaly detection● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri

Esperimenti e risultati:Metodologia
● Prima fase: testing su dati artificiali Dataset Synflood01
Test set formato da 1513 flussi● Seconda fase: testing su dati reali
Dataset Mawi02 Test set formato da 4398 flussi
Valutazione performance in base ad indici prestazionali
Error rate: è la percentuale di misclassificazione

Esperimenti e risultati:Configurazioni testate
Misura di non conformità
Distanza
Nearest Neighbor Euclidean
Nearest Neighbor Cosine Similarity
Average Distance Euclidean
Average Distance Cosine Similarity
Support Vector Machine
Euclidean

Esperimenti e risultati:Risultati su Synflood01
NN-Euclidean NN-Cosine AVG-Euclidean AVG-Cosine SVM0
5
10
15
20
25
30E
rro
r R
ate
(in
%)
NN: nearest neighbours - AVG: average distance - SVM: support vector machine
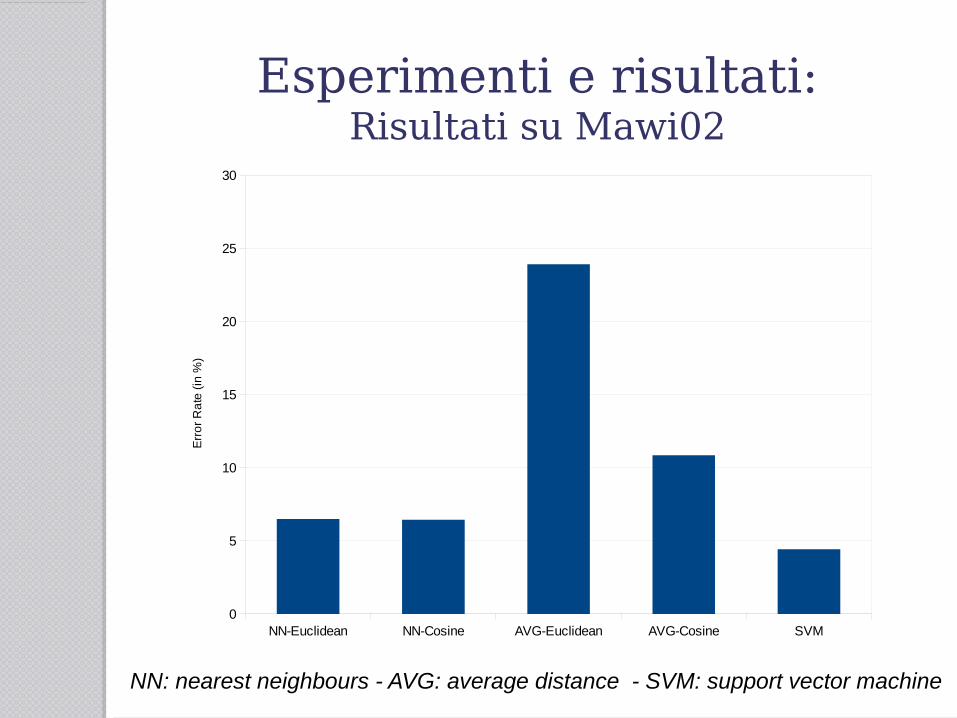
Esperimenti e risultati:Risultati su Mawi02
NN-Euclidean NN-Cosine AVG-Euclidean AVG-Cosine SVM0
5
10
15
20
25
30
Err
or
Ra
te (
in %
)
NN: nearest neighbours - AVG: average distance - SVM: support vector machine

Esperimenti e risultati:Risultati su Mawi02
● SVM ha dato il 4.43% di errore nel rilevamento:● 15 falso positivi ● 180 falso negativi
● Mentre ha dato:● 64 vero positivi● 4141 vero negativi
Per “positivo” si intende un flusso che è anomalo e “negativo” un flusso che non lo è.

Esperimenti e risultati:Cause degli errori
● SVMNatura dei dati, che non si presentano perfettamente separabili
● Average distancePoca robustezza della media, sulla quale questo criterio si basa. Anche un singolo outlier può influenzare di molto le prestazioni finali
● Nearest NeighborNon separabilità dei dati e poca omogeneità di dispersione.

Outline● Network anomaly detection● Conformal prediction● Il Framework di analisi dei dati● Esperimenti e risultati● Conclusioni e sviluppi futuri

Conclusioni
● L'algoritmo di conformal prediction si presta ad essere utilizzato nella network anomaly detection utilizzando SVM come classificatore, ma per ottenere risultati migliori si dovrebbero usare più features.
● Ranking performance misure di non conformità:
1)SVM
2)Nearest neighbor
3)Average distance

Sviluppi futuri
● Possibile variante dell'algoritmo:
Sliding window: usare solo il passato più recente al fine di migliorare i tempi computazionali

Grazie per l’attenzione
Related Documents











