Ashwin Shankar Nezih Yigitbasi Productionizing Spark on Yarn for ETL

Netflix - Productionizing Spark On Yarn For ETL At Petabyte Scale
Apr 16, 2017
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Ashwin ShankarNezih Yigitbasi
Productionizing Spark on Yarn for ETL



Scale

81+ millionmembers
Global 1000+ devicessupported
125 millionhours / day
Netflix Key Business Metrics

40 PB DW Read 3PB Write 300TB700B Events
Netflix Key Platform Metrics

Outline
● Big Data Platform Architecture
● Technical Challenges
● ETL

Big Data Platform Architecture

Cloudapps
Kafka Ursula
CassandraAegisthus
Dimension Data
Event Data
~ 1 min
Daily
S3
SSTables
Data Pipeline

Storage
Compute
Service
Tools
Big Data APIBig Data Portal
S3 Parquet
Transport VisualizationQuality Pig Workflow Vis Job/Cluster Vis
Interface
Execution Metadata
Notebooks

• 3000 EC2 nodes on two clusters (d2.4xlarge)• Multiple Spark versions• Share the same infrastructure with MapReduce jobs
S M
S M
S M
M
…16 vcores
120 GB
M
S
MapReduceS
S M
S M
S M
MSSpark
S M
S M
S M
MS
S M
S M
S M
MS
Spark on YARN at Netflix

Technical Challenges

YARN
ResourceManager
NodeManager
SparkAM
RDD

Custom Coalescer Support [SPARK-14042]
• coalesce() can only “merge” using the given number of partitions– how to merge by size?
• CombineFileInputFormat with Hive
• Support custom partition coalescing strategies

• Parent RDD partitions are listed sequentially
• Slow for tables with lots of partitions
• Parallelize listing of parent RDD partitions
UnionRDD Parallel Listing [SPARK-9926]

YARN
ResourceManager
S3FilesystemRDD
NodeManager
SparkAM

• Unnecessary getFileStatus() call
• SPARK-9926 and HADOOP-12810 yield faster startup
• ~20x speedup in input split calculation
Optimize S3 Listing Performance [HADOOP-12810]

Output Committers
Hadoop Output Committer• Write to a temp directory and rename to destination on success
• S3 rename => copy + delete• S3 is eventually consistent
S3 Output Committer• Write to local disk and upload to S3 on success
• avoid redundant S3 copy• avoid eventual consistency

YARN
ResourceManager
Dyn
amic
A
lloca
tion S3
FilesystemRDD
NodeManager
SparkAM

• Broadcast joins/variables• Replicas can be removed with dynamic allocation
Poor Broadcast Read Performance [SPARK-13328]
...16/02/13 01:02:27 WARN BlockManager: Failed to fetch remote block broadcast_18_piece0 (failed attempt 70)...16/02/13 01:02:27 INFO TorrentBroadcast: Reading broadcast variable 18 took 1051049 ms
• Refresh replica locations from the driver on multiple failures

• Cancel & resend pending container requests• if the locality preference is no longer needed• if no locality preference is set
• No locality information with S3
• Do not cancel requests without locality preference
Incorrect Locality Optimization [SPARK-13779]

YARN
ResourceManager
Parquet R/WD
ynam
ic
Allo
catio
n S3FilesystemRDD
NodeManager
SparkAM
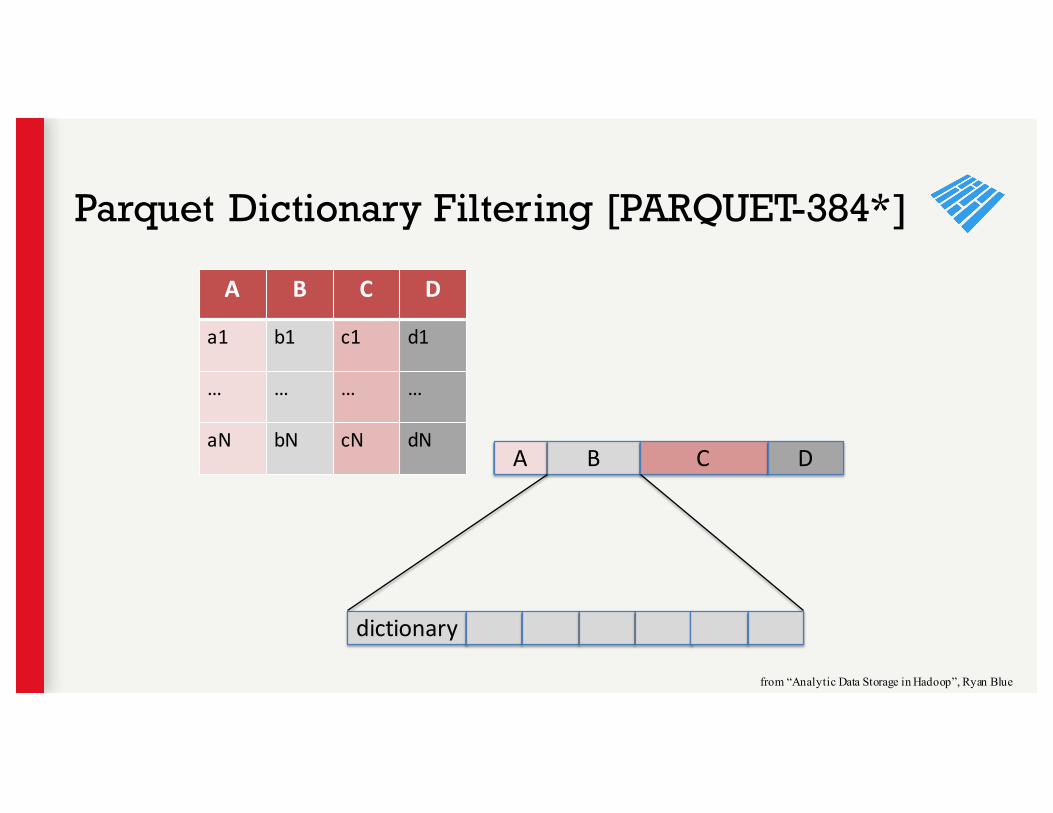
A B C D
a1 b1 c1 d1
… … … …
aN bN cN dNA B C D
dictionary
from “Analytic Data Storage in Hadoop”, Ryan Blue
Parquet Dictionary Filtering [PARQUET-384*]

01020304050607080
DFdisabled DFenabled64MBsplit
DFenabled1Gsplit
DFdisabled
DFenabled64MBsplit
DFenabled1Gsplit
~8x ~18x
Parquet Dictionary Filtering [PARQUET-384*]Avg.Com
pletionTime[m
]
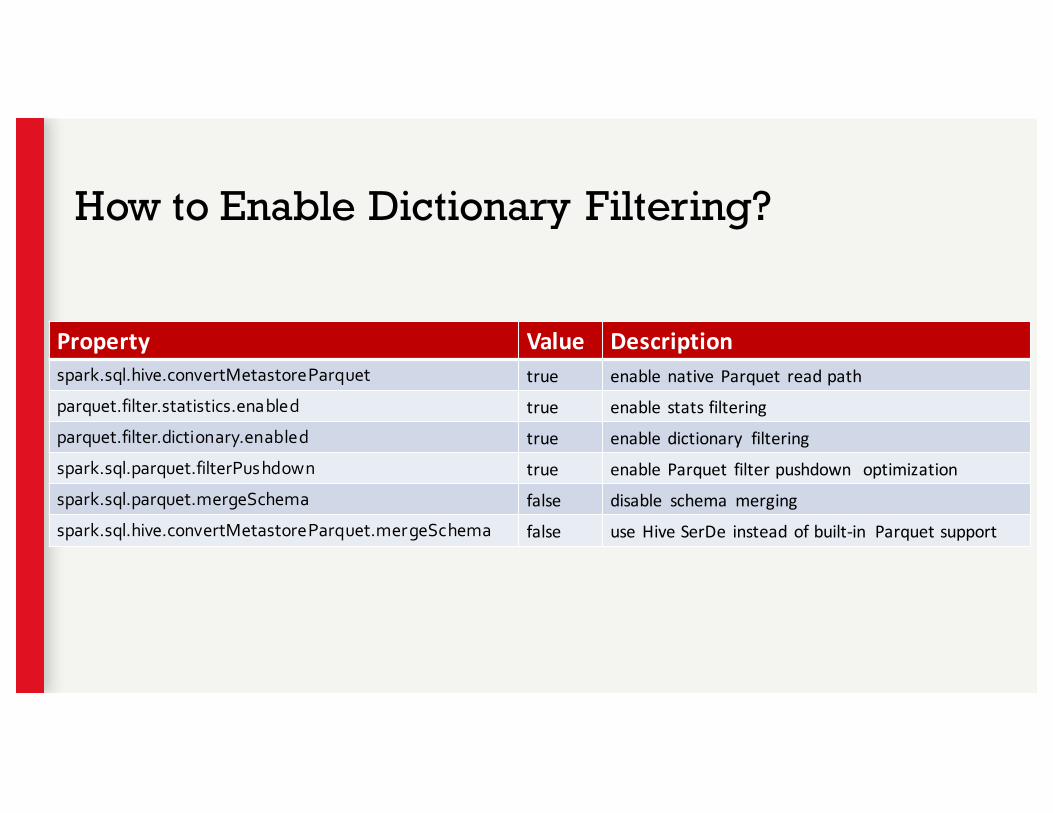
Property Value Descriptionspark.sql.hive.convertMetastoreParquet true enable native Parquet readpathparquet.filter.statistics.enabled true enable statsfilteringparquet.filter.dictionary.enabled true enable dictionary filteringspark.sql.parquet.filterPushdown true enable Parquet filterpushdown optimizationspark.sql.parquet.mergeSchema false disable schema mergingspark.sql.hive.convertMetastoreParquet.mergeSchema false useHiveSerDe insteadofbuilt-in Parquetsupport
How to Enable Dictionary Filtering?

Efficient Dynamic Partition Inserts [SPARK-15420*]
• Parquet buffers row group data for each file during writes
• Spark already sorts before writes, but has some limitations
• Detect if the data is already sorted
• Expose the ability to repartition data before write

YARN
ResourceManager
Parquet R/WD
ynam
ic
Allo
catio
n
Spar
kH
isto
rySe
rver
S3FilesystemRDD
NodeManager
SparkAM

Spark History Server – Where is My Job?

• A large application can prevent new applications from showing up• not uncommon to see event logs of GBs
• SPARK-13988 makes the processing multi-threaded
• GC tuning helps further• move from CMS to G1 GC• allocate more space to young generation
Spark History Server – Where is My Job?

ExtractTransformLoad

group
foreach
join
foreach + filter + store
joinforeach foreach
join
join
join
load + filter load + filter load + filter load + filter load + filter load + filter
Pig vs. Spark
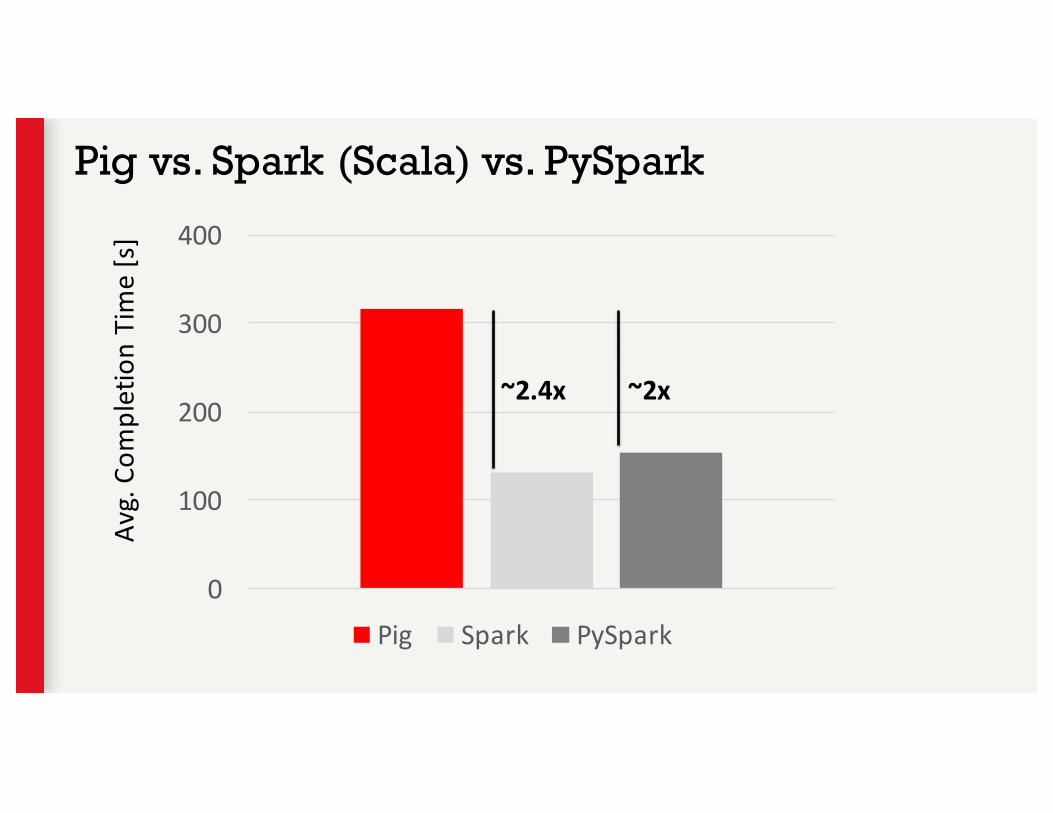
0
100
200
300
400
Pig Spark PySpark
~2.4x ~2x
Avg.Com
pletionTime[s]
Pig vs. Spark (Scala) vs. PySpark

Prototype DeployBuild Run
S3
Production Workflow

• A rapid innovation platform for targeting algorithms
• 5 hours (vs. 10s of hours) to compute similarity for all Netflix profiles for 30-day window of new arrival titles
• 10 minutes to score 4M profiles for 14-day window of newarrival titles
Production Spark Application #1: Yogen

• Personalized ordering of rows of titles
• Enrich page/row/title features with play history
• 14 stages, ~10Ks of tasks, several TBs
Production Spark Application #2: ARO

What’s Next?
• Improved Parquet support
• Better visibility
• Explore new use cases

Questions?
Related Documents











