Natural Language Processing Lecture 17: Earley’s Algorithm and Dependencies

Natural Language Processing Lecture 17: Earley’s Algorithm and Dependencies.
Dec 19, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Natural Language Processing
Lecture 17: Earley’s Algorithm and Dependencies

Survey Feedback
• Expanded office hours– Tuesday evenings– Friday afternoons
• More detail in the lectures• Piazza• Quiz & Midterm policy– You don’t get them back
• Grading policy

Earley’s Algorithm

Grammar for Examples
NP -> NNP -> DT NNP -> NP PPNP -> PNPPP -> P NPS -> NP VPS -> VPVP -> V NPVP -> VP PP
DT -> aDT -> theP -> throughP -> withPNP -> SwabhaPNP -> ChicagoV -> bookV -> booksN -> bookN -> booksN -> flight
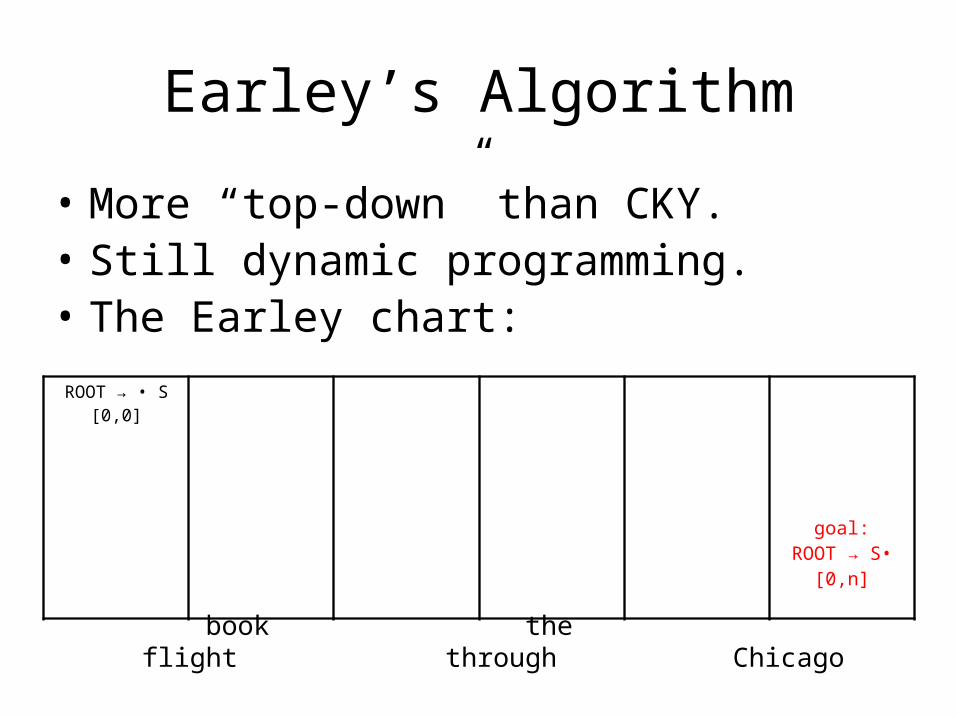
Earley’s Algorithm
• More “top-down” than CKY.• Still dynamic programming.• The Earley chart:ROOT → • S [0,0]
goal:ROOT → S• [0,n]
book the flight through Chicago

Earley’s Algorithm: PREDICT
Given V → α•Xβ [i, j] and the rule X → γ,create X → •γ [j, j]
ROOT → • S [0,0]S → • VP [0,0]S → • NP VP [0,0]...VP → • V NP [0,0]...NP → • DT N [0,0]...
book the flight through Chicago
ROOT → • S [0,0]S→ VPS → VP • [0,0]

Earley’s Algorithm: SCAN
Given V → α•Tβ [i, j] and the rule T → wj+1,create T → wj+1• [j, j+1]
ROOT → • S [0,0]S → • VP [0,0]S → • NP VP [0,0]...VP → • V NP [0,0]...NP → • DT N [0,0]...
V → book• [0, 1]
book the flight through Chicago
VP → • V NP [0,0]V → bookV → book • [0,1]

Earley’s Algorithm: COMPLETE
Given V → α•Xβ [i, j] and X → γ• [j, k],create V → αX•β [i, k]
ROOT → • S [0,0]S → • VP [0,0]S → • NP VP [0,0]...VP → • V NP [0,0]...NP → • DT N [0,0]...
V → book• [0, 1]VP → V • NP [0,1]
book the flight through Chicago
VP → • V NP [0,0]V → book • [0,1]VP → V • NP [0,1]


Earley’s Algorithm: COMPLETE
Given V → α•Xβ [i, j] and X → γ• [j, k],create V → αX•β [i, k]
ROOT → • S [0,0]S → • VP [0,0]S → • NP VP [0,0]...VP → • V NP [0,0]...NP → • DT N [0,0]...
V → book• [0, 1]VP → V • NP [0,1]
book the flight through Chicago
VP → • V NP [0,0]V → book • [0,1]VP → V • NP [0,1]

Thought Questions
• Runtime?– O(n3)
• Memory?– O(n2)
• Weighted version?• Recovering trees?

Parsing as Search

Implementing Recognizers as Search
Agenda = { state0 }while(Agenda not empty)
s = pop a state from Agendaif s is a success-state return s // valid parse treeelse if s is not a failure-state:
generate new states from spush new states onto Agenda
return nil // no parse!

Agenda-Based Probabilistic Parsing
Agenda = { (item, value) : initial updates from equations }// items take the form [X, i, j]; values are realswhile(Agenda not empty)
u = pop an update from Agendaif u.item is goal return u.value // valid parse treeelse if u.value > Chart[u.item]
store Chart[u.item] ← u.valueif u.item combines with other Chart items:
generate new updates from u and items stored in Chart
push new updates onto Agendareturn nil // no parse!

Catalog of CF Parsing Algorithms
• Recognition/Boolean vs. parsing/probabilistic• Chomsky normal form/CKY vs.
general/Earley’s• Exhaustive vs. agenda

Dependency Parsing

Treebank Tree
The luxury auto maker last year sold 1,214 cars in the U.S.
DT NN NN NN JJ NN VBD CD NNS IN DT NNP
NP NP NP NP
PP
VP
S

Headed Tree
The luxury auto maker last year sold 1,214 cars in the U.S.
DT NN NN NN JJ NN VBD CD NNS IN DT NNP
NP NP NP NP
PP
VP
S

Lexicalized Tree
The luxury auto maker last year sold 1,214 cars in the U.S.
DT NN NN NN JJ NN VBD CD NNS IN DT NNP
NPmaker NPyear NPcars NPU.S.
PPin
VPsold
Ssold

Dependency Tree

Methods for Dependency Parsing
• Parse with a phrase-structure parser with headed / lexicalized rules– Reuse algorithms we know– Leverage improvements in phrase structure parsing
• Maximum spanning tree algorithms– Words are nodes, edges are possible links– MSTParser
• Shift-reduce parsing– Read words in one at a time, decide to “shift” or
“reduce” to incrementally build tree structures– MaltParser, Stanford NN Dependency Parser

Maximum Spanning Tree
• Each dependency is an edge• Assign each edge a goodness score (ML problem)• Dependencies must form a tree• Find the highest scoring tree (Chu-Liu-Edmonds algorithm)
Figure: Graham Neubig

Shift-Reduce Parsing
• Two data structures– Buffer: words that are being read in– Stack: partially built dependency trees
• At each point choose– Shift: move word from stack to queue– Reduce-left: combine top two items in stack by making the top word the head of the tree
– Reduce-right: combine top two items in stack by maing the second word the head of the tree
• Parsing as classification: classifier says “shift” or “reduce-left” or “reduce-right”

Shift-Reduce Parsing
Figure: Graham Neubig
Stack Buffer Stack Buffer

Parsing as Classification
• Given a state:
• What action is best?
• Better classification -> better parsing
Stack Buffer

Shift-Reduce Algorithm
• ShiftReduce(queue)– make list heads– stack = [ (0, “ROOT”, “ROOT”) ]– while |buffer| > 0 or |stack| > 1:
• feats = MakeFeats(stack, buffer)• action = Predict(feats, weights)• if action = shift:
– stack.push(buffer.read())
• elif action = reduce_left:– heads[stack[-2]] = stack[-1]– stack.remove(-2)
• else: # action = reduce_right– heads[scack[-1]] = stack[-2]– stack.remove(-1)
Related Documents


![arXiv:1612.02526v5 [cs.LG] 28 Jun 2018 ing/prediction algorithm, … · 2018-06-29 · consistently learning long-range dependencies, in settings such as natural language, remains](https://static.cupdf.com/doc/110x72/5ec544addb528449974152c8/arxiv161202526v5-cslg-28-jun-2018-ingprediction-algorithm-2018-06-29-consistently.jpg)








