索索索索 Platform - DBA - 程程程 Skype:shunzi_bj Email:qingshun@douban .com 2015.04.03

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

1 什么是索引2 Tree3 MySQL 索引结构4 索引原则5 索引优化
OUTLINE

为什么 B+Tree 比 B-Tree 更适合数据库的索引结构? 为什么单调递增字段(如 :AUTO_INCREMENT )比非单
调字段作为 InnoDB 的主键更好? 为什么可选择性高的字段创建索引效率更高? InnoDB 和 MyISAM 的索引结构有什么异同? InnoDB 的主键和辅助索引的关系是什么? InnoDB 中为什么不建议过长的字段作为主键? 索引都有哪些类型?常用的有哪些? 什么是索引的最左前缀和可选择性? 为什么查询要遵循索引的最左前缀原则? 为什么范围查询字段最好放到组合索引的最后? 什么是索引覆盖? …………

什么是索引? 索引是对数据库表中一列或多列的值进行排序的一种结构。
其作用是什么? 使 SQL 语句执行得更快。
1 什么是索引

2 TREE
2.1 查找算法2.2 查找树2.3 B-Tree2.4 B+Tree2.5 索引高度2.6 范围扫描

查找算法:1 、顺序查找;2 、基于排序结果上的查找;3 、基于 hash 值的查找。
2.1 查找算法

动态查找树主要有:二叉查找树( Binary Search Tree )平衡二叉查找树( Balanced Binary Search Tree )红黑树 (Red-Black Tree )B-tree/B+-tree
前三者是典型的二叉查找树结构。其它的都是多叉树。他们的查找时间复杂度 O(logaN) , a 是树的阶,也就是节点的最大出度。 a 越大,树的高度越低!
2.2 查找树
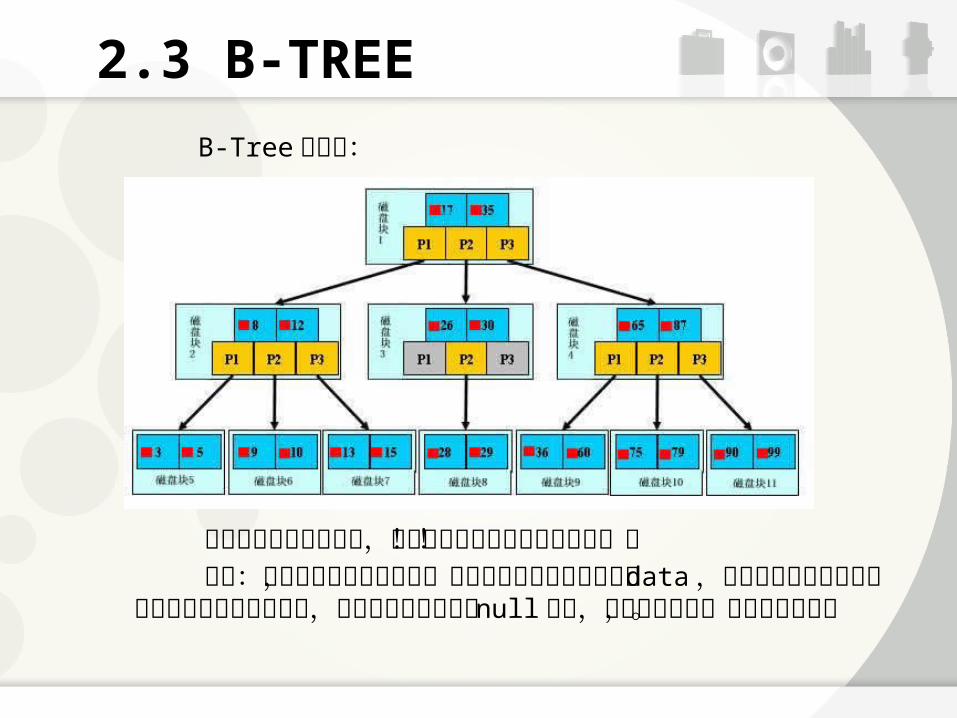
2.3 B-TREE
B-Tree 结构图:
非叶子节点也包含数据,导致叶子节点不包括全部数据!! 查找:从根节点进行二分查找,如果找到则返回对应节点的data ,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到 null 指针,前者查找成功,后者查找失败。

2.4 B+TREE
B+ 树结构图:
1 、叶子节点包含所有的关键字信息,且有横向链表;2 、所有非叶子节点仅包含其子树跟节点中最大或最小关键字。

2.4 B+TREE
B 树比二叉树的高度更低,也更符合数据库的结构(以页 / 块为单位);
B+ 树又比 B 树的好的地方在于:可以范围查找。
最终, B+ 树更合适作为索引结构!
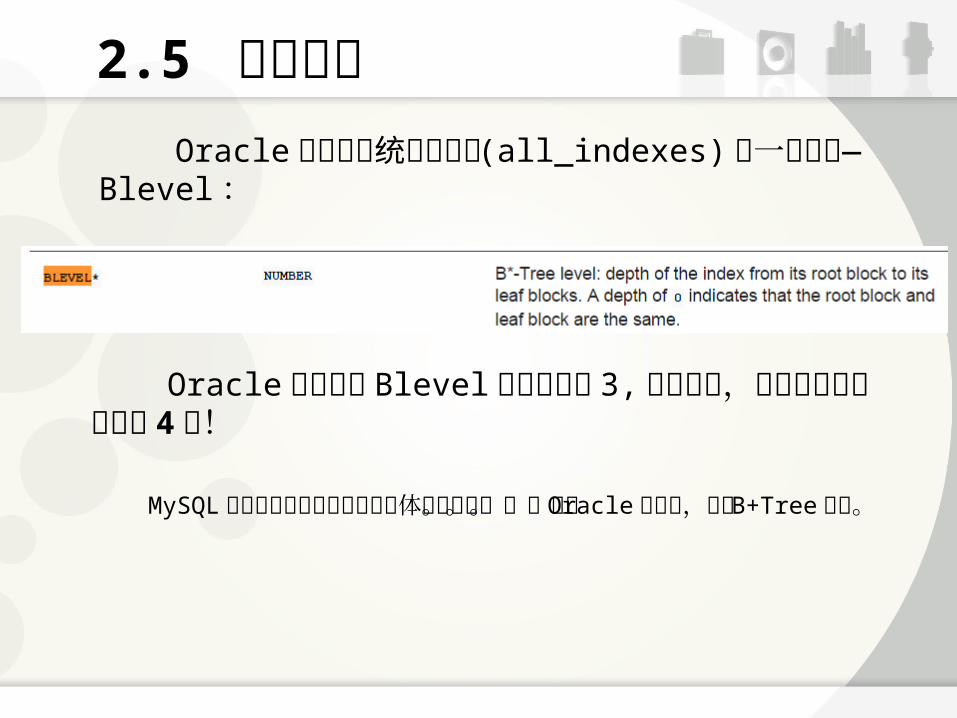
2.5 索引高度 Oracle 里索引的统计信息表 (all_indexes) 有一个字段— Blevel :
Oracle 里见过的 Blevel 最大的就是 3, 也就是说,见过的索引最多只有 4 层!
MySQL 的索引的层次目前不清楚具体怎么算的。。。但和 Oracle 是类似,都是 B+Tree 索引。

2.6 范围扫描 范围扫描( range scan )不就是> 、 >= 、 < 、 <= 、 between…and… 这些吗? Not Only !
除了 primary key 或者 unique index 上的 = 、 in()查找之外,其它都是范围扫描!非唯一索引上的 = 、 in都是范围扫描!(因为不唯一)
是否支持范围扫描是不是很重要。 B+ 树比 B 树的优点也就更明显了。

3 MYSQL 索引结构
3.1 堆表与索引组织表3.2 MyISAM 索引结构3.3 InnoDB 主键结构3.4 InnoDB 辅助索引结构

按照表数据在磁盘上的组织形式区分:堆表、索引组织表; 堆表:在磁盘上数据是按照插入顺序堆积起来的(前面有删除,后面会填补),典型代表有: MySQL的 MyISAM 表、 Oracle 的普通表; 索引组织表:在磁盘上数据是按照主键排序存储的(单个数据块内),典型代表有: MySQL 的 InnoDB表。
3.1 堆表与索引组织表

MyISAM 主键结构:
3.2 MYISAM 索引结构
辅助索引结构与主键一样 ~

InnoDB 主键结构:
聚簇索引:索引即是数据。索引的叶子节点中不仅包括索引字段,而且还包括其它所有字段!数据是以主键顺序在磁盘上存储的(单个数据块内)。
3.3 INNODB 主键结构

InnoDB 辅助索引结构:
辅助索引除了存储索引字段外,还存储了主键值!以辅助索引检索数据,必须先根据辅助索引查找到主键值、再去主键索引里面查找数据!
3.4 INNODB 辅助索引结构
这种结构和 MyISAM 的比有什么优缺点?为什么 InnoDB 的主键字段长度尽量要短?为什么 InnoDB 的主键尽量要用递增类型的?

聚簇和非聚簇表对比图:
3.4 INNODB 辅助索引结构

4 索引原则
4.1 索引类型4.2 索引优点4.3 最左前缀4.4 索引可选择性4.5 覆盖索引
4.1 索引类型索引类型:
B-Tree 、 Hash 、全文;主键、唯一索引、非唯一索引;单列索引、多列索引(组合索引);函数索引、位图索引、反转索引; (MySQL
无 )分区索引、全局索引 (MySQL无 );…………

1 、大大减少了服务器需要扫描的数据量; -- 普通索引2 、可以帮助服务器避免排序和临时表; -- 索引包含 by 字段3 、可以将随机 I/O变成顺序 I/O 。 -- 索引覆盖
4.2 索引优点

最左前缀原则:从索引的最左边字段开始组合。举例:索引( A , B , C )
为什么索引要符合最左前缀:索引扫描需要先在叶子节点中确定一个起点和终点!
4.3 最左前缀

( A 、 B 、 C 三列的组合索引,从左到右排好序的叶子节点)
4.3 最左前缀
看看where a=2 and b=3 的数据都有哪些?
再看看where b=3 的数据有有哪些?

看看where a=2 and c=3 的数据都有哪些?
只能用到第一个字段,然后扫描索引的范围就变成了:
同理,你是否理解了这句话呢:组合索引中,范围查询字段后面的其它字段,都用不到索引。假如索引( A , B , C )Select ……Where A=1 and B>=2 and B<=3 and C=3;索引只能用两个字段( A , B )。
4.3 最左前缀
索引的可选择性:不重复的索引值(基数,cardinality )和表总行数的比值。
为什么可选择性高的字段创建索引效率更高?最直观的理解:选择性高的字段具有更高的筛选性。
4.4 索引可选择性

索引覆盖:索引数据包括了需要查找的、筛选的所有字段。只扫描索引不回表!
辅助索引( A 、 B 、 C ):select B,C from table_name order by A,B;主键: id ;辅助索引( A , B ):Select id from table_name order by A,B;
优点:减小访问量;随机 IO 基本变为顺序 IO ; InnoDB避免了对主键的二次查询。
4.5 索引覆盖

使用独立的列;(索引列上不要有计算或函数)考虑索引的最左前缀和可选择性;尽量用多列索引来满足不同查询条件;(一当多
用)选择合适的索引顺序; (视业务而定)利用索引覆盖;使用索引扫描来做排序;避免多个范围条件的查询;(知道为什么了吧)范围查询的列放到索引最后。
5 索引优化

其它的需要注意的点:少用 select * ,请明确写出需要查找的列; jion 中、 group
by 中、有 text 和 BLOB 字段的表中,禁用 select * ;禁用 UNION ,如必要,用 UNION ALL 代替; 不需要排序的,请不要用 order by ;分组后不需要排序的,请用 order by null;
关联表的数量尽量少;少用 or ;尽量用 jion 代替子查询;避免类型转换; Where 中不直接对字段进行函数转换、计算等!避免用 like '%abc';
5 索引优化
left join 后面的限制条件只能用于限制 left join 后面的表,对 left jion 前面的表无效!
避免在 sql 中用 hint ;(如: force key() ) 数据库中尽量少存日志类型的数据;如必须,尽量定期归档; 不要增加不必要的列;(有人喜欢备用列:
ext1 、 ext2 、 ... ) 索引字段,尽量用 NOT NULL ;避免不必要的索引;尽量少用 TEXT 、 BLOB 类型; DISTINCT,UNION,MINUS,INTERSECT,ORDER
BY 、 GROUP BY ,都会引起排序操作,需慎用; 对 count 、 sum 、 max 外加 group by 的操作,尽量少做,
可增加外部缓存来减少在数据库层的操作。(如:排行榜)拒绝: big SQL 、 big Transaction 、 big Batch ;
5 索引优化

Thanks!
Related Documents











