Internet-Scale Data Management 34 Published by the IEEE Computer Society 1089-7801/12/$31.00 © 2012 IEEE IEEE INTERNET COMPUTING T he landscape of large-scale data management has seen a major shift in recent years. For decades, relational database management sys- tems (RDBMSs) dominated the scene. New kinds of applications, however, particularly on the Web, brought RDBMSs to their limits. Popular social media sites (such as YouTube and Flickr), social networks (such as Face- book and LinkedIn), and large retail platforms (such as Amazon) must deal with both large amounts of data and frequent accesses by millions of users. The amount of stored data, high query load, and often globally distributed data centers make distributing or par- titioning the data inevitable. The pressing need for large-scale distributed and highly available stor- age systems has led to the rise of NoSQL systems. NoSQL (short for “not only SQL”) is a rather loose term for describ- ing a new class of storage systems. Most prominent among these are key-value stores, but others, such as document databases and graph databases, are also NoSQLs. So far, no standardization exists for NoSQL systems, making their integra- tion with applications (for example, as an alternative to an RDBMS) a nontrivial task. In general, storage solutions based on NoSQL systems are custom made. To allow high data availability, NoSQL systems sacrifice various functional- ities that are standard in RDBMSs, such as strong data consistency, full access control to data, a standardized query language, and referential integrity con- straints. Most prominently, NoSQL sys- tems have limited query capabilities. Distributed NoSQL systems aim to provide high availability for large volumes of data but lack the inherent support of complex queries often required by overlying applications. Common solutions based on inverted lists for single terms perform poorly in large-scale distributed settings. The authors thus propose a multiterm indexing technique that can store the inverted lists of combinations of terms. A query-driven mechanism adaptively stores popular term combinations derived from the recent query history. Experiments show that this approach reduces the overall bandwidth consumption by half, significantly improving the NoSQL system’s capacity and response time with only marginal overhead in terms of additional, but cheaper, required (storage) resources. Christian von der Weth Digital Enterprise Research Institute Anwitaman Datta Nanyang Technological University Multiterm Keyword Search in NoSQL Systems

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Inte
rnet
-Sca
le D
ata
Man
agem
ent
34 Published by the IEEE Computer Society 1089-7801/12/$31.00 © 2012 IEEE IEEE INTERNET COMPUTING
T he landscape of large-scale data management has seen a major shift in recent years. For decades,
relational database management sys-tems (RDBMSs) dominated the scene. New kinds of applications, however, particularly on the Web, brought RDBMSs to their limits. Popular social media sites (such as YouTube and Flickr), social networks (such as Face-book and LinkedIn), and large retail platforms (such as Amazon) must deal with both large amounts of data and frequent accesses by millions of users. The amount of stored data, high query load, and often globally distributed data centers make distributing or par-titioning the data inevitable.
The pressing need for large-scale distributed and highly available stor-age systems has led to the rise of NoSQL
systems. NoSQL (short for “not only SQL”) is a rather loose term for describ-ing a new class of storage systems. Most promi nent among these are key-value stores, but others, such as document databases and graph databases, are also NoSQLs.
So far, no standardization exists for NoSQL systems, making their integra-tion with applications (for example, as an alternative to an RDBMS) a nontrivial task. In general, storage solutions based on NoSQL systems are custom made. To allow high data availability, NoSQL systems sacrifice various functional-ities that are standard in RDBMSs, such as strong data consistency, full access control to data, a standardized query language, and referential integrity con-straints. Most prominently, NoSQL sys-tems have limited query capabilities.
Distributed NoSQL systems aim to provide high availability for large volumes of
data but lack the inherent support of complex queries often required by overlying
applications. Common solutions based on inverted lists for single terms perform
poorly in large-scale distributed settings. The authors thus propose a multiterm
indexing technique that can store the inverted lists of combinations of terms.
A query-driven mechanism adaptively stores popular term combinations derived
from the recent query history. Experiments show that this approach reduces
the overall bandwidth consumption by half, significantly improving the NoSQL
system’s capacity and response time with only marginal overhead in terms of
additional, but cheaper, required (storage) resources.
Christian von der WethDigital Enterprise Research Institute
Anwitaman DattaNanyang Technological University
Multiterm Keyword Search in NoSQL Systems
IC-16-01-Weth.indd 34 12/13/11 3:00 PM

Multiterm Keyword Search in NoSQL Systems
JANUARY/FEBRUARY 2012 35
This article focuses on key-value stores, which support an efficient evaluation of queries based on data objects’ keys. The information needs of online platforms, however, go beyond key-based queries — that is, queries that can be translated into primary key accesses to data objects.
However, existing approaches (see the “Related Work in Key-Value Stores and Search” sidebar) typically assume static documents. In con-trast, we address dynamic document sets, such as in tagging systems, where users can add or
delete tags to or from documents. Because of these dynamic characteristics, computing a meaningful number of multiterm keys to be indexed a priori is impractical. We therefore aim for query-driven optimization techniques, stor-ing only keys that occur frequently in incom-ing queries. To efficiently handle changing data objects, we propose incremental updates. Obvi-ously, there is a trade-off of costs for processing queries and maintaining the index, particularly in the presence of updates. Our results show that
Related Work in Key-Value Stores and Search
Distributed NoSQL systems are largely inspired by distrib-uted hash tables. DHTs were originally designed to pro-
vide an efficient lookup mechanism for large-scale peer-to-peer systems. Popular implementations include Can, Chord, Kadem-lia, Pastry, and Tapestry.1 In the past decade, many researchers have addressed various aspects of DHTs, including support of keyword-based searches — that is, querying the DHT apart from the data object keys.2–5 As a result, straightforward solu-tions such as inverted indexes perform rather poorly in DHTs on a large scale.
Despite their heritage, NoSQL systems and their applied settings distinguish them from DHTs:
• DHTs mainly address systems that operate on a global scale, which isn’t necessarily the case for NoSQL systems. In general, NoSQL systems rely on dedicated resources — that is, nodes in the system. Thus, challenges such as node churn are less pronounced. This lets key-value stores apply single-hop routing protocols (compared to multihop rout-ing in traditional DHTs).
• In large real-world systems, such as Amazon or Facebook, the NoSQL data store resides on top of hybrid architec-tures with centralized components. Such components potentially allow for indexing or caching techniques that aren’t available in DHTs.
• NoSQL systems are more practical and relevant than tradi-tional DHTs. Thus, issues such as scalability to global dimen-sions are secondary to the application of best-practice techniques to meet user demands. In this article, this is the case for support of secondary indexes. Despite scalability issues, a growing number of existing key-value store imple-mentations natively support such indexes.
We study the architectures of several popular online platforms that use a NoSQL key-value store as a storage back end to provide services for the overlying applications. Although such architectures scale well for accessing the data using a data object’s primary key, we focus on the efficient support of queries that refer to several data objects at a time.
Like other work,6,7 we deploy an inverted index to map the relevant characteristics, derived from a service’s information needs, to the data object identifier.
However, for multiterm queries (which form most user queries), this approach doesn’t scale well in large, distributed systems.8 Consequently, researchers have proposed various approaches using multiterm inverted indexes.2,4 Here, given a document with n terms, the number of possible term combina-tions is O(2n). Thus, limiting the set of possible multiterm keys to a meaningful subset is a crucial part of the proposed systems. However, current approaches assume static documents — that is, the set of terms for a document doesn’t change. In practice, most online applications consist of data objects that change over time (for example, new tags are added frequently in a tagging system). So, not only the index’s size but also the bandwidth needed to propagate updates to the index becomes an issue. Thus, the effect of the number of index entries on the overall performance is more pronounced than with static data objects.
References1. K. Lua et al., “A Survey and Comparison of Peer-to-Peer Overlay Network
Schemes,” IEEE Comm. Surveys & Tutorials, vol. 7, nos. 1–4, 2005, pp. 72–93.
2. H. Chen et al., “TSS: Efficient Term Set Search in Large Peer-to-Peer Tex-
tual Collections,” IEEE Trans. Computers, vol. 59, no. 7, 2010, pp. 969–980.
3. Y.-J. Joung, L.-W. Yang, and C.-T. Fang, “Keyword Search in DHTBased
Peer-to-Peer Networks,” Proc. IEEE Int’l Conf. Distributed Computing Systems
(ICDCS), IEEE CS Press, 2005, pp. 339–348.
4. I. Podnar et al., “Scalable Peer-to-Peer Web Retrieval with Highly Discriminative
Keys,” Proc. Int’l Conf. Data Eng. (ICDE 07), IEEE Press, 2007, pp. 1096–1105.
5. F. Zhou et al., “Approximate Object Location and Spam Filtering on Peer-
to-Peer Systems,” Proc. Middleware, Springer, 2003, pp. 1–20.
6. H. Chen et al., “Efficient Multi-Keyword Search Over P2P Web,” Proc. Conf.
World Wide Web (WWW), ACM Press, 2008, pp. 989–998.
7. P. Reynolds and A. Vahdat, “Efficient Peer-to-Peer Keyword Searching,”
Proc. Middleware, Springer, 2003, pp. 21–40.
8. J. Li et al., “On the Feasibility of Peer-to-Peer Web Indexing and Search,”
Proc. Int’l Workshop Peer-To-Peer Systems (IPTPS 03), LNCS 2735, Springer,
2003, pp. 207–215.
IC-16-01-Weth.indd 35 12/13/11 3:00 PM

Internet-Scale Data Management
36 www.computer.org/internet/ IEEE INTERNET COMPUTING
multiterm indexing reduces the overall band-width consumption by roughly 50 percent even under suboptimal conditions. This capacity gain allows for faster query processing, or for downsizing the infrastructure without perfor-mance losses.
Given the work in this area (see the side-bar), this article isn’t so much about a single new idea; rather, it summarizes the current state of NoSQL systems and investigates how several known heuristics can be combined to design a scalable system well-tuned to work-load characteristics.
NoSQL Storage SystemsNoSQL systems implement a key-to-value map in their core, featuring a hash-table-like PUT/ GET/DELETE interface for inserting, accessing, and updating data. The main difference among these systems is their expressiveness in pro-cessing queries, their support of (semi-)struc-tured data, and their application-specific characteristics.
Because of the large number of custom-ized NoSQL systems and the lack of stan-dardization, an exhaustive classification is missing. We therefore adopt the following com-mon classification that covers most popular implement ations.
Basic key-value stores implement the key-to-value map and provide a simple PUT/GET/DELETE API. The keys aren’t interpreted — that is, a key itself features no semantics and is typically derived using a hash value of the stored data object. This simplicity makes NoSQL systems fast and easy to implement and main-tain. Key-value stores have no dedicated nodes, which enables simple replication schemes and re-organization algorithms in case of node churn. Key-value stores are strictly limited to primary key accesses. Popular implementations are Amazon’s Dynamo,1 Facebook’s Cassandra,2 and Voldemort (http://project-voldemort.com).
Column stores keep data in a more struc-tured, table-like manner. A single data entry is called a row and is addressed by its key. Unlike in RDBMSs, rows in column stores can have different sets of columns, aren’t predefined, and can dynamically change over time. Keys in col-umn stores are interpreted — that is, derived from a common attribute of the data objects. Further-more, keys are stored in a sorted fashion, allowing for range queries over the key attribute. Such
a data structure results in an extended API compared to basic key-value stores. Google’s BigTable,3 Yahoo’s PNUTS,4 Hadoop’s Hbase (http://hbase.apache.org), and Hypertable (www. hypertable.org) are some popular column store implementations.
Document stores support the storage of (semi-) structured data. Here, data storage and access are optimized for documents as opposed to rows or records. Documents are typically stored in JavaScript Object Notation (JSON), allowing com-plex data structures (such as arrays or hashes) to be represented within a single database entry and retrieved with one read operation. Docu-ment stores typically provide complex opera-tions, such as adding or deleting elements to or from a document’s array. Popular document stores include CouchDB (http://couchdb.apache.org), MongoDB (www.mongodb.org), and Terra-Store (http://code.google.com/p/terrastore).
Graph databases use nodes and edges as the main storage elements. These systems optimize the performance for associative accesses to sup-port the efficient execution of typical graph algorithms — for example, following or finding paths in a graph. A common feature for accom-plishing this is the ability to store sets of ele-ment references in a single entry’s field value. Existing implementations of graph databases include Neo4j (http://neo4j.org) and Hyper-GraphDB (www.hypergraphdb.org).
This classification merely outlines the major flavors of NoSQL variants. Some NoSQL imple-mentations can be used as both column and document stores. Furthermore, some key-value stores feature interpreted keys, including sorted storage to support range queries.
Evaluating Nonprimary Key QueriesNoSQL systems support only efficient access to data objects based on their keys. Many applica-tions, however also require efficient evaluation of queries that address data objects apart from their keys. In this article, we consider keyword-based searches. This refers to applications in which data objects feature a set of keywords — for example, relevant terms derived from a text document or user-added tags of media objects.
A search query comprises a set of terms. The ideal query result should include all the data objects featuring all of these terms. As an example scenario, consider a social bookmarking platform, such as Delicious, in which users
IC-16-01-Weth.indd 36 12/13/11 3:00 PM

Multiterm Keyword Search in NoSQL Systems
JANUARY/FEBRUARY 2012 37
can manage and share their bookmarked URLs online. Moreover, users can add tags to book-marks and search for bookmarks using keyword- based searches on the tag data.
Basic ApproachesTwo main approaches support queries that aren’t based on data objects’ primary keys.
Divide and conquer. Simply put, this approach ignores the underlying key-to-value map in the sense that the initiating node sends a query to all nodes in the network. Each node, then, evaluates the query on its locally stored data and sends the result back to the initiating node. Finally, this node combines all partial results to produce the final result. The most popular imple-mentation of the divide and conquer approach is the MapReduce framework, used in column stores such as BigTable and Hbase, or document stores such as CouchDB and MongoDB.
Broadcasting a query to each node in the net-work doesn’t require storing and maintaining additional data that references relevant data to answer the query. Furthermore, in principle, this approach inherently supports arbitrary complex conditions — for example, exact-match or range conditions and logical combinations of condi-tions (in practice, to guarantee high performance, query formulation is typically limited to simple conditions). Because in this approach the system typically contacts many nodes, and the nodes locally process a query in parallel, the overall response time is good. However, because of each node’s involvement in each query, the induced overhead in terms of resources and bandwidth is high. Thus, such an approach is more suitable for batch and preprocessing.
Secondary indexes. Stored as additional infor-mation in the database, secondary indexes ref-erence the location to data objects depending on nonprimary key attributes. The index informa-tion is stored in the same manner as the user data — that is, as key-value pairs. In general, the values of indexed attributes become the keys and contain the information, and therefore the location, about the relevant data to answer a query. This avoids the need to broadcast a query to all nodes. The indexes, however, lead to additional overheads in terms of additional storage as well as maintenance costs in case of updates.
We distinguish between two variants of sec-ondary indexes. The most straightforward are inverted indexes or inverted lists, popular con-cepts from information retrieval. The keys are derived from the indexed attributes’ values. The stored value is a list of primary keys of the data objects that feature that specific attribute value. To give an example from our social bookmark-ing scenario, we can create an inverted index for all tags. The index entry “blog”→ {url1, url2, url3} points out all URLs that are tagged with “blog.” Inverted indexes are easy to implement and maintain. If the underlying NoSQL system doesn’t interpret keys, as in basic key-value stores, inverted indexes only allow for exact-match queries on the indexed attribute. Column stores, in which keys are interpreted, also sup-port range queries.
The second class of secondary indexes repre-sents more sophisticated data structures, such as Distributed B-Trees5 or Prefix Hash Tries.6 Here, key-value pairs are stored in the system such that they form a logical tree that eventually points to the data objects. These types of data structures let the systems evaluate range queries over the indexed attribute even in the case of noninter-preted keys, but at the cost of high maintenance overhead to keep the index current.
The NoSQL community has acknowledged the importance of secondary indexes, and an increasing number of implementations natively support them (for example, BigTable, Cassandra, and MongoDB). This makes the maintenance of secondary indexes transparent for programmers but rules out customized optimizations. With tailored implementations of secondary indexes — that is, by adding, deleting, and updating index information at the application level — pro-grammers can consider application-specific characteristics to optimize such additional indexes.
Combining Multiple Search CriteriaKeyword-based searches typically contain que-ries with more than one term. Various stud-ies analyzing the query logs of different online platforms reveal an average of two to four query terms.7,8 For divide and conquer approaches such as MapReduce, only the load for comput-ing the query locally on each node increases. Using secondary indexes, however, evaluating a query with k search terms results in k subqueries for each term. The combination of all k partial
IC-16-01-Weth.indd 37 12/13/11 3:00 PM
Internet-Scale Data Management
38 www.computer.org/internet/ IEEE INTERNET COMPUTING
results then yields the final query result. Most online platforms combine search terms via a logical AND. Thus, for the final results, the sys-tem must compute the intersection of the partial results, or the union of the results when terms are combined via logical OR. Either way, partial results must be transferred within the network, which could cause high bandwidth consumption.
Several optimization techniques address these traffic costs. Most prominently, Patrick Reynolds and Amin Vahdat apply Bloom fil-ters to compute the partial results’ intersection, reducing the absolute data size of the trans-ferred partial results.9 In the same work, they introduce incremental fetching, in which they transfer successive subsets of the partial results and compute the intersection. They continue
until the final result is “good” enough — that is, a minimum number of responses satisfying the query are found; otherwise, they continue to the complete result. This would be necessary, for example, for ranked query results where users only consider the top hits. Although such optimization techniques reduce traffic costs, studies show that the combination of partial results for single terms doesn’t scale well in dis-tributed systems.8
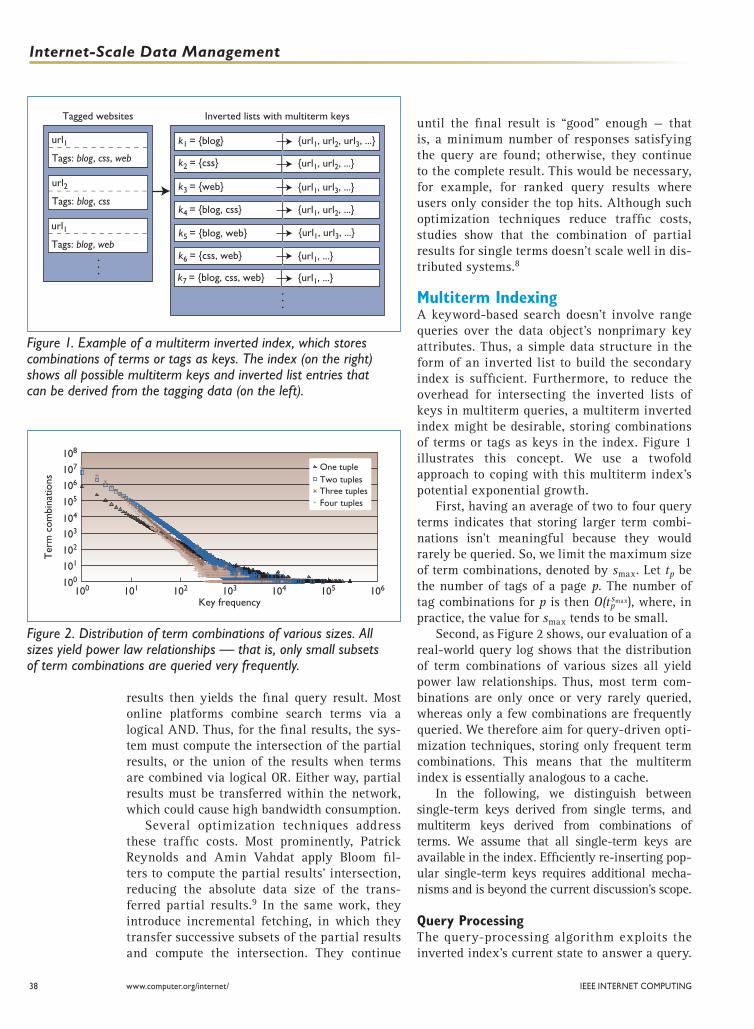
Multiterm IndexingA keyword-based search doesn’t involve range queries over the data object’s nonprimary key attributes. Thus, a simple data structure in the form of an inverted list to build the secondary index is sufficient. Furthermore, to reduce the overhead for intersecting the inverted lists of keys in multiterm queries, a multiterm inverted index might be desirable, storing combinations of terms or tags as keys in the index. Figure 1 illustrates this concept. We use a twofold approach to coping with this multiterm index’s potential exponential growth.
First, having an average of two to four query terms indicates that storing larger term combi-nations isn’t meaningful because they would rarely be queried. So, we limit the maximum size of term combinations, denoted by smax. Let tp be the number of tags of a page p. The number of tag combinations for p is then O(tpsmax), where, in practice, the value for smax tends to be small.
Second, as Figure 2 shows, our evaluation of a real-world query log shows that the distribution of term combinations of various sizes all yield power law relationships. Thus, most term com-binations are only once or very rarely queried, whereas only a few combinations are frequently queried. We therefore aim for query-driven opti-mization techniques, storing only frequent term combinations. This means that the multiterm index is essentially analogous to a cache.
In the following, we distinguish between single-term keys derived from single terms, and multiterm keys derived from combinations of terms. We assume that all single-term keys are available in the index. Efficiently re-inserting pop-ular single-term keys requires additional mecha-nisms and is beyond the current discussion’s scope.
Query ProcessingThe query-processing algorithm exploits the inverted index’s current state to answer a query.
Figure 1. Example of a multiterm inverted index, which stores combinations of terms or tags as keys. The index (on the right) shows all possible multiterm keys and inverted list entries that can be derived from the tagging data (on the left).
k1 = {blog} {url1, url2, url3, ...}
{url1, url2, ...}
{url1, url3, ...}
{url1, url2, ...}
{url1, url3, ...}
{url1, ...}
{url1, ...}
k2 = {css}
k3 = {web}
k4 = {blog, css}
k5 = {blog, web}
k6 = {css, web}
k7 = {blog, css, web}
url1
Tags: blog, css, web
url2
Tags: blog, css
url1
Tags: blog, web
Tagged websites Inverted lists with multiterm keys
...
...
Figure 2. Distribution of term combinations of various sizes. All sizes yield power law relationships — that is, only small subsets of term combinations are queried very frequently.
100
100 101 102 103 104 105 106
101
102
103
104
105
106
107
108
Ter
m c
ombi
natio
ns
Key frequency
One tupleTwo tuplesThree tuplesFour tuples
IC-16-01-Weth.indd 38 12/13/11 3:00 PM

Multiterm Keyword Search in NoSQL Systems
JANUARY/FEBRUARY 2012 39
If a query comprises two or more terms, in gen-eral, not all possible keys are available, nor are all available keys required. To find the optimal subset of keys and the order in which they access the index would require complete knowledge, particularly about the expected size of the inter-section of two or more partial results. This would require maintaining statistics over the data in the inverted index, which are typically unavail-able in distributed settings. We therefore favor a heuristic to determine the set and order of keys to access the index, as Figure 3 shows.
Given a query q, the initiating node per-forms three steps:
1. computes all relevant keys (derived from all possible term combinations up to size smax) for q;
2. accesses the index to get the size of each available key’s inverted list; and
3. generates the list of keys L to access the index. Starting with the key having the shortest inverted list, the node iteratively adds keys to L that maximize L’s coverage of q until L covers all of q’s query terms. If several keys maximize the coverage, the node selects the key with the shortest inverted list.
Once the initiator has computed list L, it can access the index to retrieve the query result, as Figure 4 shows. For this, L is sent successively
to all nodes responsible for a key in L. Each node then incorporates the inverted list of the corresponding key into the intermediate result. The last node to do so sends the final result back to the initiating node. This basic mechanism is identical for both the multiterm and single-term approaches.
2 {blog, web, ajax}
{blog, css} {blog, web} {blog, ajax} {web, ajax}
{blog} {css} {web} {ajax}
{blog, css, web} {blog, css, ajax} {blog, web, ajax} {css, web, ajax}
{blog, css} {css, web} {blog, web} {blog, ajax} {css, ajax} {web, ajax}
{blog} {css} {web} {ajax}
1
600
12080
400
40
5
800 200
50
Derive from q all possible keys between size 1 and smax(here smax = 3)
Get length of inverted list for each key from index⇒ response for each key:
• length of inverted list or
• info: key not available
Identify list of keys according to the following optimization criteria:
• minimize number of required keys to cover all query terms
• favor keys with short inverted lists
3
{{blog, web, ajax}, {blog, css}}5 80
Input: query q = {blog, css, web, ajax}
Figure 3. Computation of the list of keys L to access the secondary index. The number in the black square above a key indicates the size of the key’s inverted list.
Figure 4. An initiating node accessing the index and retrieving the query result for the computed key access list L from Figure 3. The receivers of list L in a successive order are the nodes storing the inverted list for the keys in L. Each node updates the result by computing the intersection between the previous result and the inverted list of the corresponding key. The last node then sends the result back to the initiating node.
k1 = {blog, web, ajax}k2 = {blog, css}
k1 → {url1, url2, ..., url5}
k2 → {url4, url2, ..., url83}
Queryinitiator
L = {k2}result = {url1, url2, ..., url5}
Result = {url4, url5}23
L = {k1, k2}result = θ
1
IC-16-01-Weth.indd 39 12/13/11 3:00 PM

Internet-Scale Data Management
40 www.computer.org/internet/ IEEE INTERNET COMPUTING
Index MaintenanceThe maintenance of the inverted index com-prises two major tasks: suspending and resum-ing keys depending on their popularity, and handling tag data updates.
Suspending and resuming keys. To quantify popularity, we provide each key k with a bit vector Bk of length l. Every time k is requested, we shift Bk one bit to the right and append a 1. To implement the timely decay of a key k’s popularity, we periodically shift Bk one bit to the right and append a 0, as Figure 5 shows. With that, the number of set bits in Bk repre-sents the popularity of a key k. If the number of set bits in Bk falls below a system-specific threshold bsusp, we suspend k. That is, we delete k’s inverted list from the index. If the number of set bits exceeds bres (with bres > bsusp), we resume k. Resuming a key k involves retrieving its cor-responding inverted list, which translates to performing a query for k and storing the result as k’s inverted list. Resuming keys adds to the
workload for processing user queries. However, depending on the parameter settings, we expect resuming keys to be much more infrequent than evaluating user queries.
Handling tag updates. To limit the bandwidth consumption required for updates, we propose a mechanism that sacrifices strong data con-sistency for high availability, which is in line with NoSQL systems’ basic characteristic. In a nutshell, we update only the corresponding single-term key in the inverted index. Thus, in principle, the single-term and multiterm approaches might yield different results for the same query. We update available multiterm keys periodically via incremental updates, in which we compute the set of list entries to be added or removed from a multiterm key’s cur-rent inverted list. To accomplish this, we assign a time stamp to each entry in the inverted list of single-term keys, indicating when it was added or marked as removed. Next, we assign a time stamp to each multiterm key, indicating the time of its last update. Thus, for a multiterm key km, we can identify the latest changes in the inverted lists of all corresponding single-term keys — that is, all entries that have been added or removed after the last update of km. An incre-mental update now successively incorporates the latest changes in the inverted list of all km’s corresponding single-term keys to update km. Figure 6 gives an illustrative example.
We can delete a marked-as-removed entry from a single-term key’s inverted list after a maximum interval for updating multiterm keys has passed.
ResultsOur results underline the effectiveness of our multiterm indexing approach.
Used datasets. To get meaningful results, we used publicly available real-world datasets. For the stored data, we used tagging informa-tion from the social bookmarking site Delicious obtained in 2006, which included an average of 4.19 tags per bookmark and 67 user actions per minute. Privacy concerns make acquiring query logs challenging. We therefore use the AOL query log,10 which is, to the best of our knowl-edge, the only real-world query log of reason-able size and containing mainly English queries. The log contains approximately 28.8 million
Bk = 0 1 1 0 0 0 1 1
Bk = 1 0 1 1 0 0 0 1
Bk = 0 0 1 1 0 0 0 1
Request for key k
Periodic shifting
Figure 5. Example of a bit vector Bk of size | Bk | = 8 bits, and the modifi cation of Bk both after a request for k and after a periodic shifting.
k1 = {blog}k2 = {css}
k251 → {url 10
1 , url 252 , ..., url 15
5 }
k232 → {url 5
4 , url 52 , ..., url 23 }
added = θremoved = {url2}
1
2
k203 → {url1, url2} updateKey(k3)
added = {url3}removed = {url2}
3
add (k3, {url3})remove (k3, {url2})
4
k2 = {blog,css}
Figure 6. Example of the incremental update of a two-term key at time t = 30. The superscript at each inverted list entry represents the time when the entry was added to or removed from the inverted list. A key’s time stamp indicates when it was last updated. Crossed-out entries are marked as removed. After the update, k30
3 → {id1, id3}.
IC-16-01-Weth.indd 40 12/13/11 3:00 PM

Multiterm Keyword Search in NoSQL Systems
JANUARY/FEBRUARY 2012 41
queries, and was collected between March and May 2006.
Assumptions and evaluation method. We assume a distributed key-value store for managing the inverted index. We ignore node failures. Fur-thermore, single-term keys are always available. Because we don’t consider locality-preserving data-placement strategies, we assume the worst case: that there are a sufficiently large number of nodes in the system, so all relevant keys for processing a query or propagating an update reside on different nodes. In our experiments, we measure the bandwidth consumption, rep-resented by the number of inverted list entries that are transferred during query processing, or while resuming and updating keys. With these parameters and assumptions, our results are independent of the actual number of nodes in the systems. We evaluate our approach using multi-term keys with respect to a naïve approach based solely on single-term keys. Because single-term query processing is identical in the single-term and multiterm approaches, we use only queries with more than one term.
Experiment settings and results. We simulate 150 user actions per minute, which is more than twice the number we derived from the Delicious data-set. We update multiterm keys frequently enough to guarantee an average overlap of 99 percent between the query results for the multiterm and single-term approaches. We run several simula-tions in which we modify the time between the periodic shifting of the keys’ bit vector, which essentially affects the index size — that is, the number of additionally stored multiterm keys. Figure 7 shows the reduction in bandwidth.
The results indicate the trade-off between the query processing performance and the load for maintaining the index in the presence of updates with respect to the number of available multiterm keys in the index. A larger number of multiterm keys speeds up query evaluation but causes high maintenance costs, and vice versa. Although the multiterm approach involves increasing costs for index maintenance, improvements in overall bandwidth consumption significantly outweigh the maintenance costs.
Despite our worst-case assumptions for the parameter settings, our multiterm approach re duc es the bandwidth to approximately 50 percent compared to the single-term approach. We expect
even better results in real-world systems. Table 1 shows the relative increase in storage require-ments. Even for extended periods between shift-ing the bit vectors, the additional storage needed to store the multiterm keys is reasonably low. Thus, we can significantly reduce the bandwidth consumption by only slightly increasing the required storage.
F rom an economic perspective, our multiterm indexing technique increases the infrastruc-
ture’s capacity and allows for downsizing the deployed resources without sacrificing perfor-mance, thus saving money in terms of instal-lation and operation costs, or improving the scalability of the existing infrastructure.
AcknowledgmentsThis work was partly supported by AcRF Tier 1 Grant RG
29/09 for the CrowdStore project. The work was performed
at NTU Singapore when Christian von der Weth was there
as a research fellow.
References1. G. DeCandia et al., “Dynamo: Amazon’s Highly Avail-
able Key-Value Store,” Proc. ACM SIGOPS Symp. Oper-
ating Systems Principles (SOSP 07), vol. 41, ACM Press,
2007, pp. 205–220.
2. A. Lakshman and P. Malik, “Cassandra: Structured
Storage System on a P2P Network,” Proc. Symp. Prin-
ciples of Distributed Computing (PODC 09), ACM Press,
2009, p. 5.
Figure 7. Multiterm versus single-term query processing with and without updates. With an increasing time between periodic shiftings of the bit vectors, the number of additionally stored multiterm keys increases. This in turn results in a better performance for executing queries but also in an increasing overhead for handling updates.
0
20
40
60
80
100
120
140
400 seconds 20 minutes 1 hour 3 hours 9 hours
Red
uctio
n of
ban
dwid
thco
nsum
ptio
n (p
erce
nt)
Time between periodic shifting of bit vectors
Without updatesWith updates
IC-16-01-Weth.indd 41 12/13/11 3:00 PM

Internet-Scale Data Management
42 www.computer.org/internet/ IEEE INTERNET COMPUTING
3. F. Chang et al., “BigTable: A Distributed Storage Sys-
tem for Structured Data,” Proc. Symp. Operating Sys-
tems Design and Implementation (OSDI 06), Usenix
Assoc., 2006, pp. 205–218.
4. B.F. Cooper et al., “PNUTS: Yahoo!’s Hosted Data Serv-
ing Platform,” Proc. VLDB Endowment (PVLDB 08),
vol. 1, no. 2, 2008, pp. 1277–1288.
5. M.K. Aguilera, W.M. Golab, and M.A. Shah, “A Practi-
cal Scalable Distributed B-Tree,” Proc. VLDB Endow-
ment (PVLDB 08), vol. 1, no. 1, 2008, pp. 598–609.
6. S. Ramabhadran et al., “Brief Announcement: Prefix
Hash Tree,” Proc. Symp. Principles of Distributed Com-
puting (PODC 04), ACM Press, 2004, p. 368.
7. H. Chen et al., “TSS: Efficient Term Set Search in Large
Peer-to-Peer Textual Collections,” IEEE Trans. Computers,
vol. 59, no. 7, 2010, pp. 969–980.
8. J. Li et al., “On the Feasibility of Peer-to-Peer Web Index-
ing and Search,” Proc. Int’l Workshop Peer-To-Peer Sys-
tems (IPTPS 03), LNCS 2735, Springer, 2003, pp. 207–215.
9. P. Reynolds and A. Vahdat, “Efficient Peer-to-Peer Keyword
Searching,” Proc. Middleware, Springer, 2003, pp. 21–40.
10. G. Pass, A. Chowdhury, and C. Torgeson, “A Picture of
Search,” Proc. Int’l Conf. Scalable Information Systems
(InfoScale), ACM Press, 2006, pp. 1–7.
Christian von der Weth is a postdoctoral researcher at the
Digital Enterprise Research Institute (DERI), National
University of Ireland, Galway. His research interests
include distributed information systems with a focus on
query processing and information retrieval, trust man-
agement and reputation systems, and social network
analysis. Von der Weth has a PhD in computer science
from the Karlsruhe Institute of Technology, Germany.
Contact him at [email protected].
Anwitaman Datta is an assistant professor in the School of
Computer Engineering at Nanyang Technological Univer-
sity (NTU), Singapore, where he also leads the self-* and
algorithmic aspects of the Networked Distributed Systems
(SANDS) research group. His research interests include
large-scale networked distributed information systems
and social collaboration networks, self-organization and
algorithmic issues of these systems and networks, and
their scalability, resilience, and performance. Datta has a
PhD in computer and communication sciences from EPFL
Switzerland. Contact him at [email protected].
Selected CS articles and columns are also available for free at http://ComputingNow.computer.org.
Table 1. Relative increase in index size for storing multiterm keys at different shifting periods.
Time between shifting 400 seconds 20 minutes 1 hour 3 hours 9 hours
Relative increase of index (%)
0.06 0.2 1.7 3.9 4.2
Let us bring technology news to you.
Subscribe to our daily newsfeed
http://computingnow.computer.org
IC-16-01-Weth.indd 42 12/13/11 3:00 PM
Related Documents











