Multi Multi - - Threading for Latency Threading for Latency John P. Shen John P. Shen Microprocessor Research Microprocessor Research Intel Labs Intel Labs (formerly MRL) (formerly MRL) December 1, 2001 December 1, 2001 MTEAC MTEAC - - 5 Keynote 5 Keynote

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

MultiMulti--Threading for LatencyThreading for Latency
John P. ShenJohn P. ShenMicroprocessor ResearchMicroprocessor Research
Intel LabsIntel Labs(formerly MRL)(formerly MRL)
December 1, 2001December 1, 2001MTEACMTEAC--5 Keynote5 Keynote

2J.P. Shen
OutlineOutline
1.1. HyperHyper--Threading TechnologyThreading Technology2.2. Speculative PreSpeculative Pre--computationcomputation
–– Basic and Chaining TriggersBasic and Chaining Triggers–– InIn--Order vs. OutOrder vs. Out--ofof--Order ModelsOrder Models–– SP on HyperSP on Hyper--Threading HardwareThreading Hardware
3.3. Future Research DirectionsFuture Research Directions–– “Pseudo Multi“Pseudo Multi--Threading”Threading”–– “Logically Decoupled Architecture”“Logically Decoupled Architecture”

3J.P. Shen
Microarchitecture in TransitionMicroarchitecture in Transition
1
10
100
1000
10000
100000
1000000
1980 1985 1990 1995 2000 2005 2010
MIP
S Pentium® Pro ArchitectureSpeculative Out of Order
Pentium® 4 ArchitectureTrace Cache
Future Xeon™ ArchitectureMulti-Threaded
Multi-Threaded, Multi-Core
Pentium® ArchitectureSuper Scalar
Era of Era of Instruction Instruction ParallelismParallelism
Era of Era of Thread Thread
ParallelismParallelism

4J.P. Shen
HyperHyper--Threading TechnologyThreading Technology
�� Executes two tasks simultaneouslyExecutes two tasks simultaneously–– Two different applicationsTwo different applications–– Two threads of same applicationTwo threads of same application
�� CPU maintains architecture state for two processorsCPU maintains architecture state for two processors–– Two logical processors per physical processorTwo logical processors per physical processor
�� Demonstrated on prototype Intel® Xeon™ ProcessorDemonstrated on prototype Intel® Xeon™ Processor–– Two logical processors for < 5% additional die areaTwo logical processors for < 5% additional die area–– Power efficient performance gainPower efficient performance gain
Hyper-Threading Technology brings SimultaneousMulti-Threading(SMT) to Intel Architecture
HyperHyper--Threading Technology brings SimultaneousThreading Technology brings SimultaneousMultiMulti--Threading(SMT) to Intel ArchitectureThreading(SMT) to Intel Architecture

5J.P. Shen
Intel® Xeon™ Processor MPIntel® Xeon™ Processor MPHyperHyper--Threading Technology PerformanceThreading Technology Performance
1.221.22
Intel® Xeon™ Intel® Xeon™ Processor MPProcessor MP
HyperHyper--ThreadingThreadingDisabledDisabled
1.001.001.181.18
1.231.231.301.30
Microsoft*Microsoft*Active DirectoryActive Directory
Microsoft*Microsoft*ExchangeExchange
Microsoft*Microsoft*SQL ServerSQL Server
Microsoft*Microsoft*IISIIS
Source: Intel Microprocessor Software Labs, Intel Xeon ProcessorSource: Intel Microprocessor Software Labs, Intel Xeon Processor MP (1.6GHz, 1M iL3 cache) platforms are MP (1.6GHz, 1M iL3 cache) platforms are prototype systems in 2prototype systems in 2--way configurations. Applications not tuned or optimized for Hypeway configurations. Applications not tuned or optimized for Hyperr--Threading TechnologyThreading Technology
Preliminary Hyper-Threading Technology performance numberson prototype Intel Xeon processor MP platforms today
Preliminary HyperPreliminary Hyper--Threading Technology performance numbersThreading Technology performance numberson prototype Intel Xeon processor MP platforms todayon prototype Intel Xeon processor MP platforms today
Performance tests and ratings are measured using specific computPerformance tests and ratings are measured using specific computer systems and/or components and reflect the approximate performer systems and/or components and reflect the approximate performance of Intel products as measured by those ance of Intel products as measured by those tests. Any difference in system hardware or software design or ctests. Any difference in system hardware or software design or configuration may affect actual performance. Buyers should consulonfiguration may affect actual performance. Buyers should consult other sources of information to evaluate the t other sources of information to evaluate the performance of systems or components they are considering purchaperformance of systems or components they are considering purchasing. For more information on performance tests and on the perfosing. For more information on performance tests and on the performance of Intel products, reference rmance of Intel products, reference www.www.intelintel.com/.com/procsprocs//perfperf/limits./limits.htmhtm or call (U.S.) 1or call (U.S.) 1--800800--628628--8686 or 18686 or 1--916916--356356--31043104
Intel® Xeon™ Processor MPIntel® Xeon™ Processor MPHyperHyper--Threading EnabledThreading Enabled
*All trademarks and brands are the property of their respective owners
ConcurrentConcurrentLinux buildLinux build
1.181.18
Application Measurements Application Measurements by Intel Microprocessor Software Labsby Intel Microprocessor Software Labs
6J.P. Shen
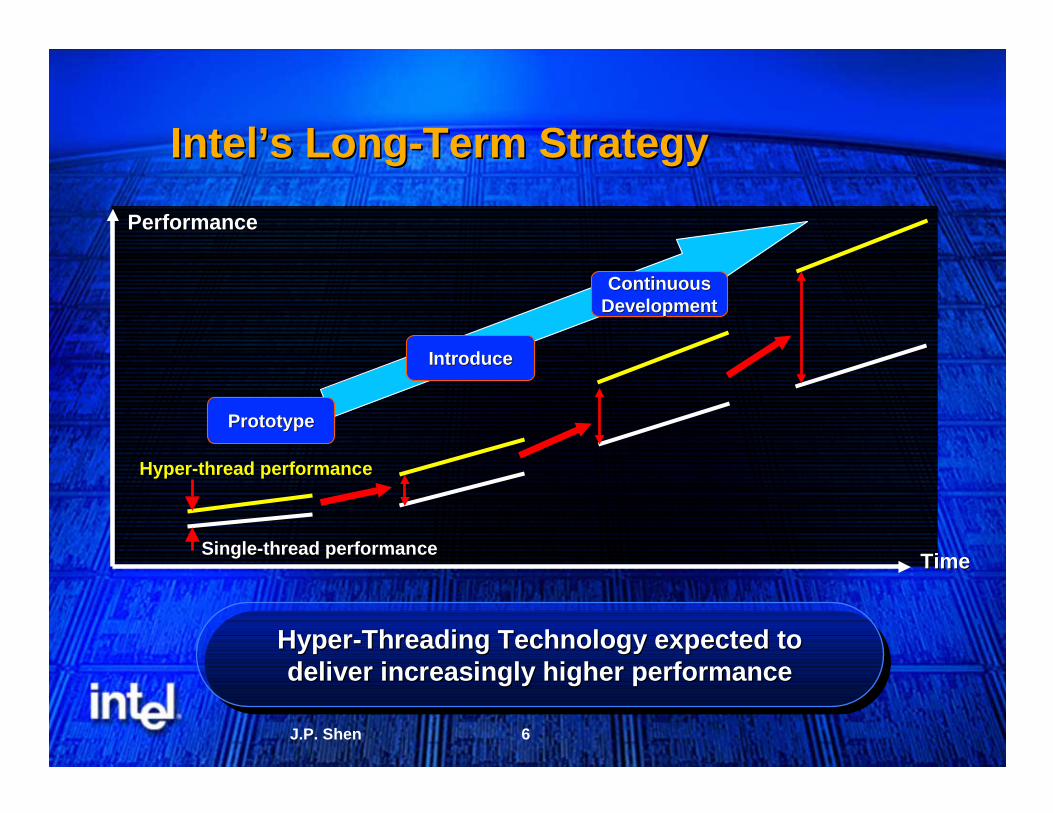
PerformancePerformance
PrototypePrototype
IntroduceIntroduce
ContinuousContinuousDevelopmentDevelopment
TimeTime
Hyper-Threading Technology expected todeliver increasingly higher performance
HyperHyper--Threading Technology expected toThreading Technology expected todeliver increasingly higher performancedeliver increasingly higher performance
Intel’s LongIntel’s Long--Term StrategyTerm Strategy
SingleSingle--thread performancethread performance
HyperHyper--thread performancethread performance

7J.P. Shen
MultiMulti--Threaded ProcessorsThreaded Processors
�� Targeting:Targeting:–– Throughput of MultiThroughput of Multi--tasking Workloads tasking Workloads –– Latency of MultiLatency of Multi--threaded Applications threaded Applications
�� Not Targeting:Not Targeting:–– Latency of SingleLatency of Single--threaded Applicationsthreaded Applications
�� Research Challenge:Research Challenge:–– Leverage MultiLeverage Multi--threaded CPU to Improve Latency threaded CPU to Improve Latency
of Singleof Single--threaded Applicationsthreaded Applications

8J.P. Shen
MultiMulti--Threading for LatencyThreading for Latency
MultiMulti--Threaded Threaded ProcessorsProcessors
ThreadThread--BasedBasedMemory PreMemory Pre--fetchingfetching
Memory LatencyMemory LatencyBottleneckBottleneck

9J.P. Shen
ThreadThread--Based Memory PreBased Memory Pre--fetchingfetching
�� Hardware Hardware PrefetchPrefetch::–– Table driven and pattern basedTable driven and pattern based–– Limited by predictable patternsLimited by predictable patterns
�� Software Software PrefetchPrefetch::–– Insert memoryInsert memory prefetchprefetch instructionsinstructions–– Limited by single control flowLimited by single control flow
�� ThreadThread--Based Based PrefetchPrefetch::–– Precompute Precompute addresses for select loadsaddresses for select loads–– Speculative threads for Speculative threads for precomputationprecomputation

10J.P. Shen
Speculative Speculative Precomputation Precomputation (SP)(SP)
�� Target:Target: The Memory BottleneckThe Memory Bottleneck–– PointerPointer--intensive applicationsintensive applications–– PrePre--fetch for “Delinquent loads”fetch for “Delinquent loads”
�� Method:Method: ThreadThread--Based Based PrefetchingPrefetching–– Embed preEmbed pre--fetching SPfetching SP--threads in binarythreads in binary–– Parallel execution of main and SPParallel execution of main and SP--threadsthreads
Eliminate and reduce stall cycles due toPerformance-degrading cache misses
Eliminate and reduce stall cycles due toEliminate and reduce stall cycles due toPerformancePerformance--degrading cache missesdegrading cache misses

11J.P. Shen
Chronicle of SP Research EffortsChronicle of SP Research Efforts
Original SP conceptOriginal SP concept[Intel Labs, UCSD][Intel Labs, UCSD]
Dynamic SP (DSP) Dynamic SP (DSP) [UCSD][UCSD]
Software SP (SSP)Software SP (SSP)[Intel Labs][Intel Labs]
IA64 SSP toolIA64 SSP tool[Intel Labs][Intel Labs]
IA32 SSP tool (HT)IA32 SSP tool (HT)[Intel Labs][Intel Labs]
12J.P. Shen
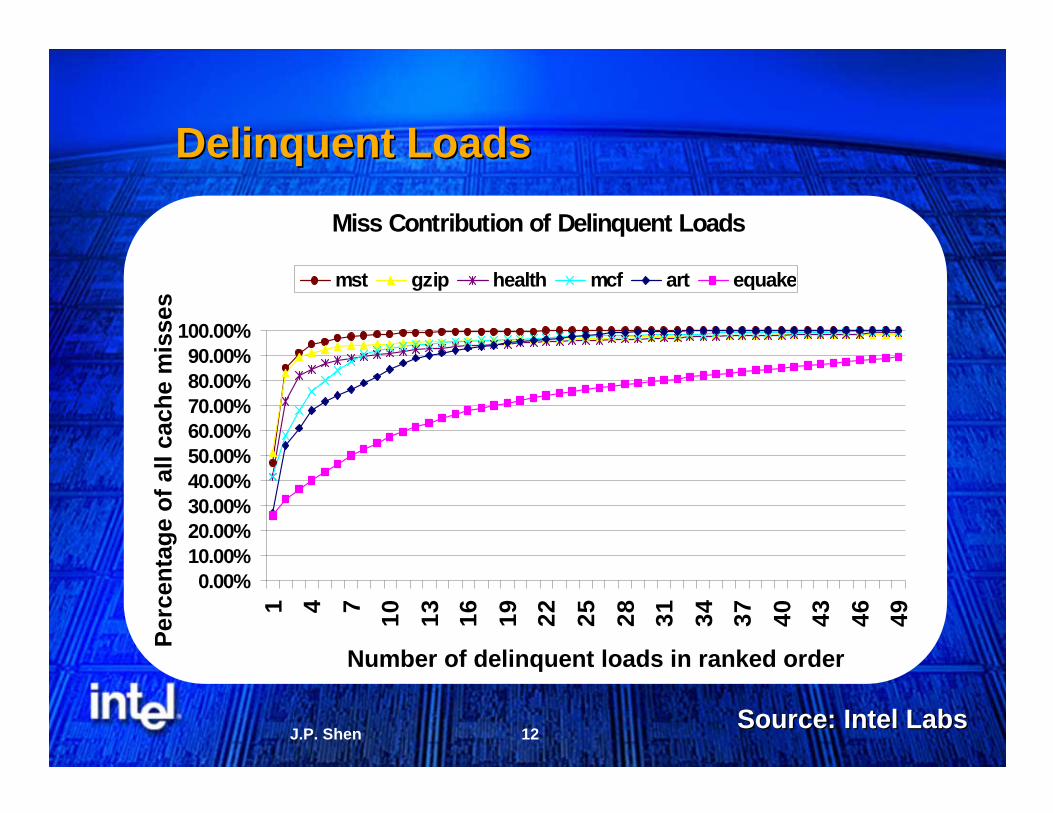
Delinquent LoadsDelinquent Loads
Number of delinquent loads in ranked order
Per
cen
tag
e o
f al
l cac
he
mis
ses
Source: Intel LabsSource: Intel Labs
Miss Contribution of Delinquent Loads
0.00%10.00%20.00%30.00%40.00%50.00%60.00%70.00%80.00%90.00%
100.00%
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49
mst gzip health mcf art equake

13J.P. Shen
SPSP--Threads StatisticsThreads Statistics
4.74.7262688mstmst
5.35.39.19.188healthhealth
2.52.55.85.866mcfmcf
6.06.09.59.599gzipgzip
4.54.512.512.588equakeequake
3.53.54422artart
Avg. # of LiveAvg. # of Live--InsIns
Avg. Thread Avg. Thread LengthLength
# of SP Threads# of SP ThreadsBenchmarkBenchmarkStatistics on SP-Threads for top 10 Delinquent Loads
Source: Intel LabsSource: Intel Labs
14J.P. Shen
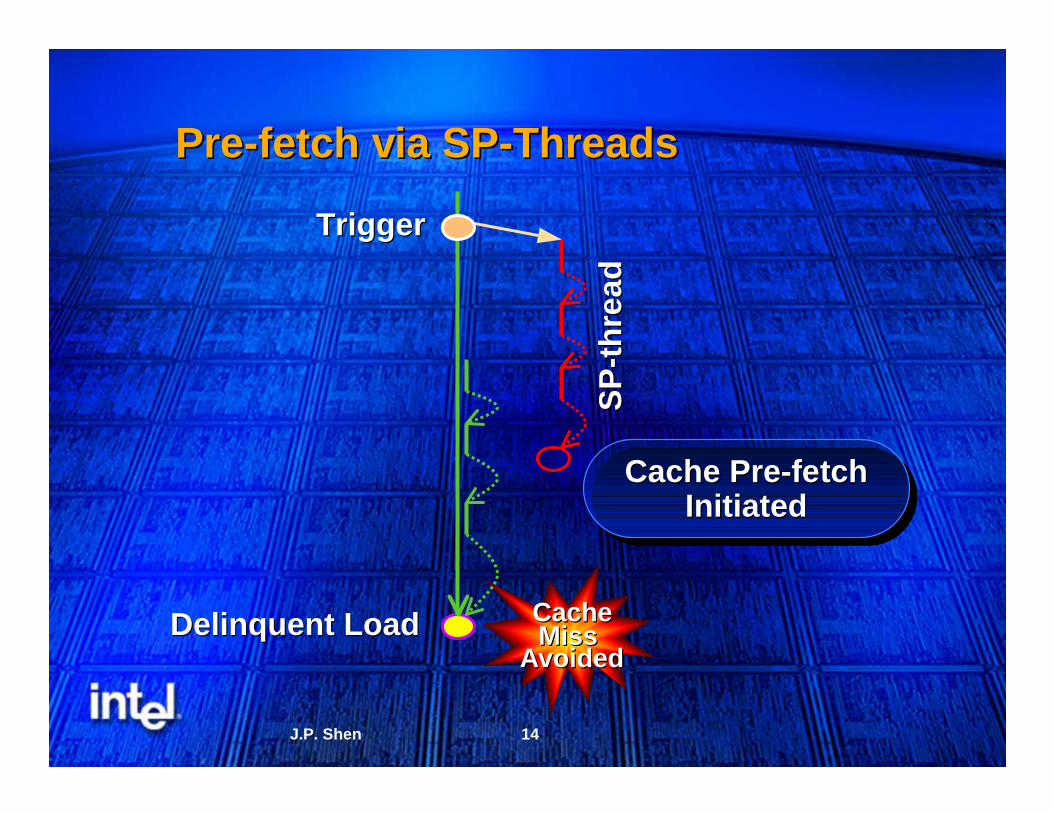
PrePre--fetch via SPfetch via SP--ThreadsThreads
Delinquent LoadDelinquent Load CacheCacheMissMiss
AvoidedAvoided
Cache Pre-fetchInitiated
Cache PreCache Pre--fetchfetchInitiatedInitiated
TriggerTrigger
SP
SP
-- th
read
thre
ad

15J.P. Shen
SP Speedup (Basic Triggers)SP Speedup (Basic Triggers)
Realistic Speedup from Speculative Precomputation Using Basic Triggers
00.20.40.60.8
11.21.4
art equake gzip mcf health mst Average
No Spawn Cost Pipe flush Pipe flush+8 cycles Pipe flush+16 cycles
Sp
eed
up
Benchmarks
Source: Intel LabsSource: Intel Labs

16J.P. Shen
SP with Chaining TriggersSP with Chaining Triggers
Delinquent LoadDelinquent Load CacheCacheMissMiss
AvoidedAvoided
TriggerTrigger
SP
SP
-- th
read
thre
ad
SP
SP
-- th
read
thre
ad
SP
SP
-- th
read
thre
ad

17J.P. Shen
SP Speedup (Chaining Triggers)SP Speedup (Chaining Triggers)
Realistic Speedup from Speculative Precomputation Using Chaining Triggers
0.81
1.21.41.61.8
22.22.42.62.8
art equake gzip mcf health mst Average
2 Total Thread Contexts 4 Total Thread Contexts 8 Total Thread Contexts
Sp
eed
up
Benchmarks
Source: Intel LabsSource: Intel Labs

18J.P. Shen
Chaining Trigger AdvantagesChaining Trigger Advantages
�� LowLow--cost thread spawning:cost thread spawning:–– Chaining triggers initiate SPChaining triggers initiate SP--threads without threads without
impacting main thread performanceimpacting main thread performance
�� LongLong--range range prefetchingprefetching::–– Can target delinquent loads far ahead of the main Can target delinquent loads far ahead of the main
threadthread–– Speculative threads make progress independent Speculative threads make progress independent
of main thread’s lack of progressof main thread’s lack of progress
Basic triggers initiate precomputation Chaining triggers sustain precomputationBasic triggers initiate Basic triggers initiate precomputation precomputation
Chaining triggers sustain Chaining triggers sustain precomputationprecomputation

19J.P. Shen
Does SP Work For All Benchmarks?Does SP Work For All Benchmarks?Cycle Accounting
0%
20%
40%
60%
80%
100%
gap
gzipparse
rAve (C
I)equake
health mcfAve (M
I)
Benchmark
Norm
aliz
ed C
ycle
sL3 L2 L1 CacheExecute Execute Other
Source: Intel LabsSource: Intel Labs

20J.P. Shen
Does SP Work For OOO Machines?Does SP Work For OOO Machines?
Performance improvement over in-order Itanium model
0.6
1
1.4
1.8
2.2
2.6
3
gap
gzip
parse
rAve
(CI)
equa
kehe
alth
mcfAve
(MI)
benchmark
spee
dup
IO+SP OOO OOO+SP
Source: Intel LabsSource: Intel Labs

21J.P. Shen
Where Do the Speedups Come From?Where Do the Speedups Come From?
Cycle accounting of memory tolerance approaches
0%
20%
40%
60%
80%
100%
IO+S
P
OO
O
OO
O+S
P
IO+S
P
OO
O
OO
O+S
P
IO+S
P
OO
O
OO
O+S
P
IO+S
P
OO
O
OO
O+S
P
IO+S
P
OO
O
OO
O+S
P
IO+S
P
OO
O
OO
O+S
P
gap gzip parser equake health mcf
benchmark
No
rmal
ized
cyc
les
to in
-ord
er m
od
el
Other
Execute
CacheExecute
L1
L2
L3
Source: Intel LabsSource: Intel Labs

22J.P. Shen
OutOut--ofof--Order vs. Spec. Order vs. Spec. PrecomputationPrecomputation
�� OutOut--ofof--OrderOrder–– Effective on L1 missesEffective on L1 misses–– Benefit most programsBenefit most programs–– Effective on delinquent loads in loop bodyEffective on delinquent loads in loop body
�� Speculative Speculative PrecomputationPrecomputation–– Effective on L2 and L3 missesEffective on L2 and L3 misses–– Benefit pointerBenefit pointer--intensive programsintensive programs–– Effective on delinquent loads in loop controlEffective on delinquent loads in loop control
23J.P. Shen
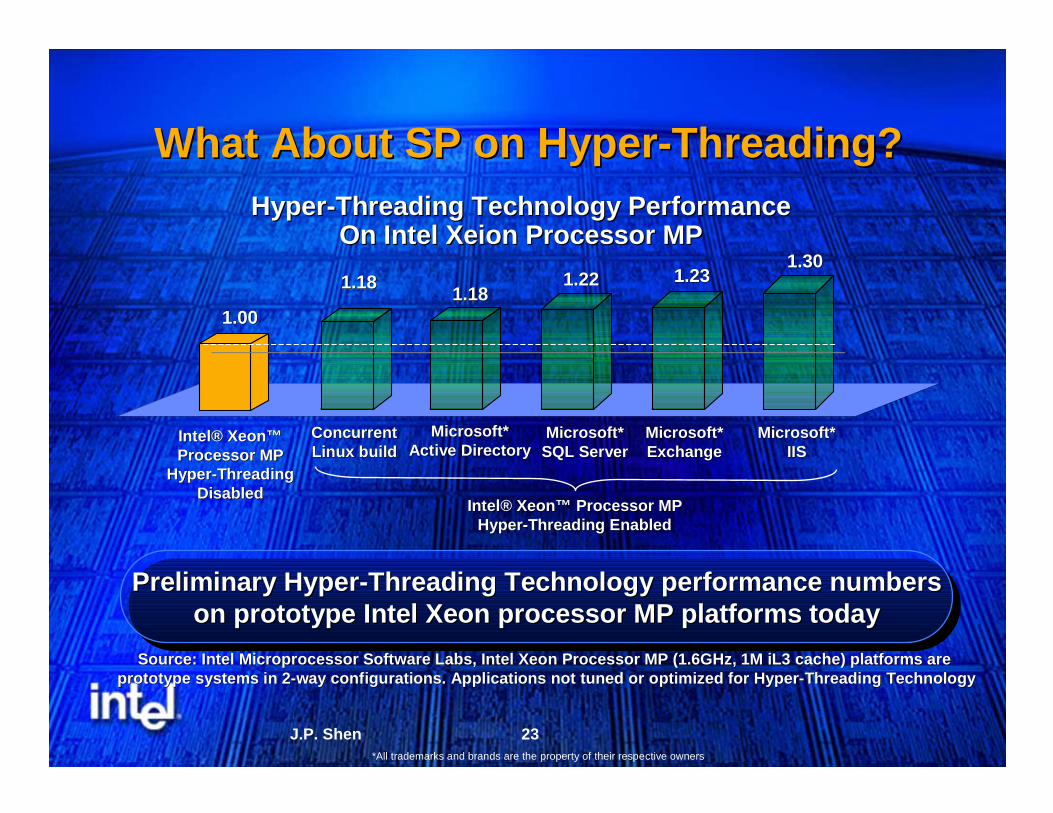
What About SP on HyperWhat About SP on Hyper--Threading?Threading?
1.221.22
Intel® Xeon™ Intel® Xeon™ Processor MPProcessor MP
HyperHyper--ThreadingThreadingDisabledDisabled
1.001.001.181.18
1.231.231.301.30
Microsoft*Microsoft*Active DirectoryActive Directory
Microsoft*Microsoft*ExchangeExchange
Microsoft*Microsoft*SQL ServerSQL Server
Microsoft*Microsoft*IISIIS
Source: Intel Microprocessor Software Labs, Intel Xeon ProcessorSource: Intel Microprocessor Software Labs, Intel Xeon Processor MP (1.6GHz, 1M iL3 cache) platforms are MP (1.6GHz, 1M iL3 cache) platforms are prototype systems in 2prototype systems in 2--way configurations. Applications not tuned or optimized for Hypeway configurations. Applications not tuned or optimized for Hyperr--Threading TechnologyThreading Technology
Preliminary Hyper-Threading Technology performance numberson prototype Intel Xeon processor MP platforms today
Preliminary HyperPreliminary Hyper--Threading Technology performance numbersThreading Technology performance numberson prototype Intel Xeon processor MP platforms todayon prototype Intel Xeon processor MP platforms today
Intel® Xeon™ Processor MPIntel® Xeon™ Processor MPHyperHyper--Threading EnabledThreading Enabled
*All trademarks and brands are the property of their respective owners
ConcurrentConcurrentLinux buildLinux build
1.181.18
HyperHyper--Threading Technology PerformanceThreading Technology PerformanceOn Intel On Intel Xeion Xeion Processor MPProcessor MP
24J.P. Shen
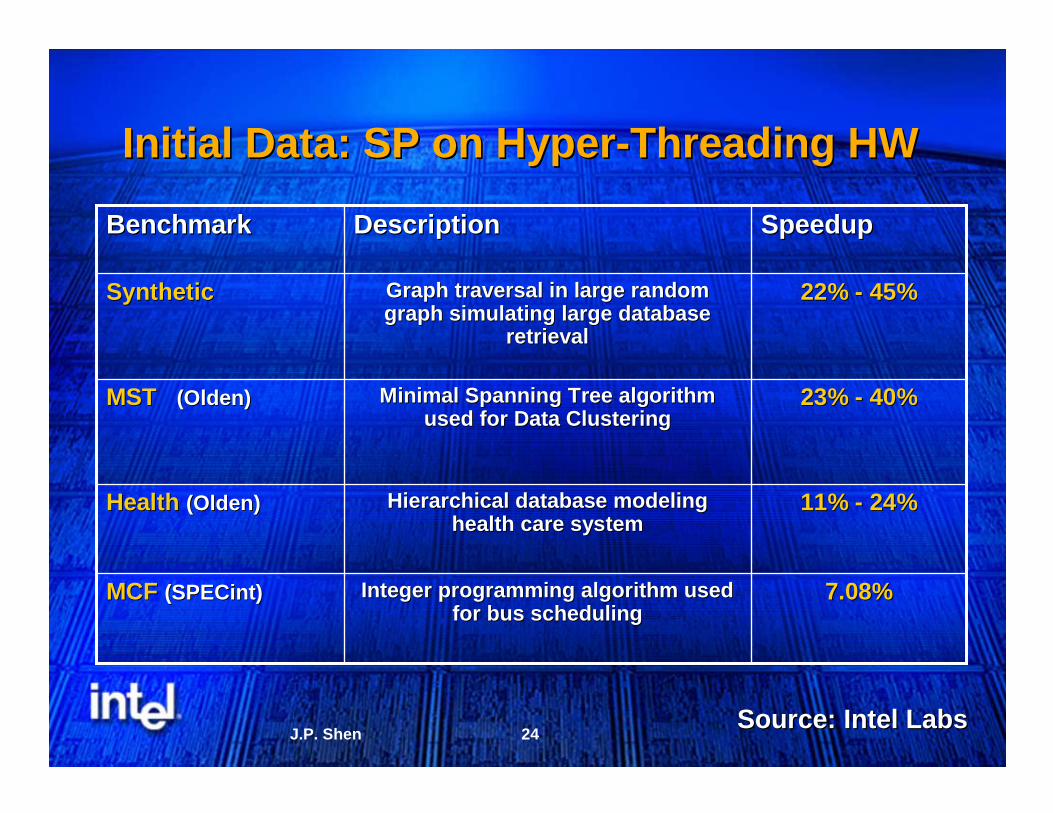
Initial Data: SP on HyperInitial Data: SP on Hyper--Threading HWThreading HW
7.08%7.08%Integer programming algorithm used Integer programming algorithm used for bus schedulingfor bus scheduling
MCFMCF ((SPECintSPECint))
11% 11% -- 24%24%Hierarchical database modeling Hierarchical database modeling health care system health care system
HealthHealth (Olden)(Olden)
23% 23% -- 40%40%Minimal Spanning Tree algorithm Minimal Spanning Tree algorithm used for Data Clusteringused for Data Clustering
MSTMST (Olden)(Olden)
22% 22% -- 45%45%Graph traversal in large random Graph traversal in large random graph simulating large database graph simulating large database
retrievalretrieval
SyntheticSynthetic
SpeedupSpeedupDescriptionDescriptionBenchmarkBenchmark
Source: Intel LabsSource: Intel Labs

25J.P. Shen
Future Research DirectionsFuture Research Directions
�� Code Adaptation ToolsCode Adaptation Tools–– Automated Source Level ToolAutomated Source Level Tool–– Automated Binary Level ToolAutomated Binary Level Tool
�� RunRun--Time Support OptimizationTime Support Optimization–– LightLight--Weight Thread SpawningWeight Thread Spawning–– ISA Extension and ISA Extension and Microcode Microcode SupportSupport
�� “Pseudo Multi“Pseudo Multi--Threading”Threading”
�� “Logically Decoupled Architecture”“Logically Decoupled Architecture”

26J.P. Shen
“Pseudo Multi“Pseudo Multi--Threading”Threading”
Traditional MultiTraditional Multi--threading
threading
Pseudo
Pseudo
MultiMulti--Threading
Threading

27J.P. Shen
“Pseudo Multi“Pseudo Multi--Threading”Threading”
�� Traditional MultiTraditional Multi--Threading CompilerThreading Compiler–– Partition single thread into multiple threadsPartition single thread into multiple threads–– Must ensure semantic correctnessMust ensure semantic correctness–– Achieve performance by parallel executionAchieve performance by parallel execution
�� Pseudo MultiPseudo Multi--Threading CompilerThreading Compiler–– Attach assist threads to original single threadAttach assist threads to original single thread–– Leverage side effect of assist threadsLeverage side effect of assist threads–– Achieve performance by concurrent Achieve performance by concurrent prefetchingprefetching

28J.P. Shen
“Logically Decoupled Architecture”“Logically Decoupled Architecture”
MemoryMemory
MemoryMemory
ExecuteExecuteEngineEngine
AccessAccessEngineEngine
Access ThreadAccess Thread
Execute ThreadExecute Thread
Physically Decoupled ArchitecturePhysically Decoupled Architecture
Logically Decoupled ArchitectureLogically Decoupled Architecture

29J.P. Shen
“Logically Decoupled Architecture”“Logically Decoupled Architecture”
�� Logical Form of AccessLogical Form of Access--Execute DecouplingExecute Decoupling–– Attach special “Access” threads to original codeAttach special “Access” threads to original code–– SMT execution of “Access” and “Execute” threadsSMT execution of “Access” and “Execute” threads–– Overlapping (“pipelining”) of Access and ExecuteOverlapping (“pipelining”) of Access and Execute
�� Best Use of SMT Resources?Best Use of SMT Resources?–– ThroughputThroughput: many threads simultaneously: many threads simultaneously–– LatencyLatency: one thread with assist threads: one thread with assist threads–– Leverage TLP to achieve MLP and ILPLeverage TLP to achieve MLP and ILP–– Amplification of assist thread effectiveness?Amplification of assist thread effectiveness?

30J.P. Shen
ConclusionConclusion
�� MultiMulti--Threading Is InevitableThreading Is Inevitable–– Transition from ILP to TLP performanceTransition from ILP to TLP performance–– Power and complexity efficiencyPower and complexity efficiency
�� Challenges With MultiChallenges With Multi--ThreadingThreading–– Additional validation overheadAdditional validation overhead–– Operating systems supportOperating systems support–– Enabling development of MT applicationsEnabling development of MT applications
�� Interesting Research AreasInteresting Research Areas–– Alternate and best use of SMT resourcesAlternate and best use of SMT resources–– Tradeoffs between SMT and CMPTradeoffs between SMT and CMP–– Software development and compilation toolsSoftware development and compilation tools
Related Documents











