Applied Soft Computing 12 (2012) 2654–2674 Contents lists available at SciVerse ScienceDirect Applied Soft Computing j ourna l ho me p age: www.elsevier.com/l ocate/asoc Multi-objective immune algorithm with Baldwinian learning Yutao Qi a,b,∗ , Fang Liu a,b , Meiyun Liu a,b , Maoguo Gong b , Licheng Jiao b a School of Computer Science and Technology, Xidian University, Xi’an, China b Key Laboratory of Intelligent Perception and Image Understanding of Ministry of Education of China, China a r t i c l e i n f o Article history: Received 19 July 2011 Received in revised form 21 March 2012 Accepted 3 April 2012 Available online 19 April 2012 Keywords: Multi-objective optimization problems Immune optimization algorithm Memetic algorithm Baldwinian learning a b s t r a c t By replacing the selection component, a well researched evolutionary algorithm for scalar optimization problems (SOPs) can be directly used to solve multi-objective optimization problems (MOPs). Therefore, in most of existing multi-objective evolutionary algorithms (MOEAs), selection and diversity maintenance have attracted a lot of research effort. However, conventional reproduction operators designed for SOPs might not be suitable for MOPs due to the different optima structures between them. At present, few works have been done to improve the searching efficiency of MOEAs according to the characteristic of MOPs. Based on the regularity of continues MOPs, a Baldwinian learning strategy is designed for improving the nondominated neighbor immune algorithm and a multi-objective immune algorithm with Baldwinian learning (MIAB) is proposed in this study. The Baldwinian learning strategy extracts the evolving environment of current population by building a probability distribution model and generates a predictive improving direction by combining the environment information and the evolving history of the parent individual. Experimental results based on ten representative benchmark problems indicate that, MIAB outperforms the original immune algorithm, it performs better or similarly the other two outstanding approached NSGAII and MOEA/D in solution quality on most of the eight testing MOPs. The efficiency of the proposed Baldwinian learning strategy has also been experimentally investigated in this work. © 2012 Elsevier B.V. All rights reserved. 1. Introduction Many optimization problems in real-life applications have more than one objective in conflict with each others. These optimiza- tion problems are known as multi-objective optimization problems (MOPs) [1]. With the advantage of producing a set of Pareto optimal solutions in a single run, evolutionary algorithms (EAs) have been recognized to be very successful in solving MOPs. Since Schaffer’s pioneer work on evolutionary multi-objective optimization (EMO) [2], a number of multi-objective evolution- ary algorithms (MOEAs) had been developed. According to Coello Coello’s overview of works on EMO [3], MOEAs are categorized into two generations by their characteristics. In the early 1990s, the first generation MOEAs which are characterized by the use of selection mechanisms based on Pareto ranking and fitness sharing to maintain diversity were proposed. The Multi-objective Genetic Algorithm (MOGA) [4], the Niched Pareto Genetic Algorithm (NPGA) [5] and the Non-dominated Sorting Genetic Algorithm (NSGA) [6] are representative ones. Since the end of the 1990s, the second generation MOEAs using the elitism strategy had been presented. The major contributions include the Strength Pareto ∗ Corresponding author at: School of Computer Science and Technology, Xidian University, Xi’an, China. Evolutionary Algorithm (SPEA) [7] and its improved version SPEA2 [8], the Pareto archived evolution strategy (PAES) [9], the Pareto envelope based selection algorithm (PESA) [10] and its revised version PESAII [11], and the improved version of NSGA (NSGAII) [12]. More recently, Zhang et al. [13] combined decomposition meth- ods in mathematics and the optimization paradigm in evolutionary computation and proposed the distinguished MOEA/D. MOEA/D maintains a good diversity by optimizing a set of various scalar sub- problems synchronously and outperforms other compared MOEAs based on Pareto selection in solving MOPs with complicated PS shapes. Gong and Jiao et al. [14] utilized the superiority of the immune inspired clonal selection evolution paradigm in maintain- ing population diversity and proposed a multi-objective immune algorithm with nondominated neighbor-based selection (NNIA) which is an efficient and effective immune inspired multi-objective algorithm for MOPs. As only nondominated solutions have the chance to be proliferated in NNIA, the algorithm may be trapped in local optimal Pareto front if current isolated nondominated anti- bodies selected for proportional cloning are very few. To remedy this, Yang et al. [15] introduced vicinity distances based selec- tion and adaptive ranks clone scheme into NNIA and proposed its enhanced version NNIA2. NNIA2 has made a significant improve- ment in convergence and diversity maintaining, it is could be an efficient and effective algorithm for MOPs. 1568-4946/$ – see front matter © 2012 Elsevier B.V. All rights reserved. http://dx.doi.org/10.1016/j.asoc.2012.04.005

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

M
Ya
b
a
ARRAA
KMIMB
1
tt(sr
oaCitstA((tp
U
1h
Applied Soft Computing 12 (2012) 2654–2674
Contents lists available at SciVerse ScienceDirect
Applied Soft Computing
j ourna l ho me p age: www.elsev ier .com/ l ocate /asoc
ulti-objective immune algorithm with Baldwinian learning
utao Qia,b,∗, Fang Liua,b, Meiyun Liua,b, Maoguo Gongb, Licheng Jiaob
School of Computer Science and Technology, Xidian University, Xi’an, ChinaKey Laboratory of Intelligent Perception and Image Understanding of Ministry of Education of China, China
r t i c l e i n f o
rticle history:eceived 19 July 2011eceived in revised form 21 March 2012ccepted 3 April 2012vailable online 19 April 2012
eywords:ulti-objective optimization problems
mmune optimization algorithmemetic algorithm
aldwinian learning
a b s t r a c t
By replacing the selection component, a well researched evolutionary algorithm for scalar optimizationproblems (SOPs) can be directly used to solve multi-objective optimization problems (MOPs). Therefore,in most of existing multi-objective evolutionary algorithms (MOEAs), selection and diversity maintenancehave attracted a lot of research effort. However, conventional reproduction operators designed for SOPsmight not be suitable for MOPs due to the different optima structures between them. At present, fewworks have been done to improve the searching efficiency of MOEAs according to the characteristicof MOPs. Based on the regularity of continues MOPs, a Baldwinian learning strategy is designed forimproving the nondominated neighbor immune algorithm and a multi-objective immune algorithm withBaldwinian learning (MIAB) is proposed in this study. The Baldwinian learning strategy extracts theevolving environment of current population by building a probability distribution model and generates
a predictive improving direction by combining the environment information and the evolving history ofthe parent individual. Experimental results based on ten representative benchmark problems indicatethat, MIAB outperforms the original immune algorithm, it performs better or similarly the other twooutstanding approached NSGAII and MOEA/D in solution quality on most of the eight testing MOPs. Theefficiency of the proposed Baldwinian learning strategy has also been experimentally investigated in this work.. Introduction
Many optimization problems in real-life applications have morehan one objective in conflict with each others. These optimiza-ion problems are known as multi-objective optimization problemsMOPs) [1]. With the advantage of producing a set of Pareto optimalolutions in a single run, evolutionary algorithms (EAs) have beenecognized to be very successful in solving MOPs.
Since Schaffer’s pioneer work on evolutionary multi-objectiveptimization (EMO) [2], a number of multi-objective evolution-ry algorithms (MOEAs) had been developed. According to Coellooello’s overview of works on EMO [3], MOEAs are categorized
nto two generations by their characteristics. In the early 1990s,he first generation MOEAs which are characterized by the use ofelection mechanisms based on Pareto ranking and fitness sharingo maintain diversity were proposed. The Multi-objective Geneticlgorithm (MOGA) [4], the Niched Pareto Genetic Algorithm
NPGA) [5] and the Non-dominated Sorting Genetic Algorithm
NSGA) [6] are representative ones. Since the end of the 1990s,he second generation MOEAs using the elitism strategy had beenresented. The major contributions include the Strength Pareto∗ Corresponding author at: School of Computer Science and Technology, Xidianniversity, Xi’an, China.
568-4946/$ – see front matter © 2012 Elsevier B.V. All rights reserved.ttp://dx.doi.org/10.1016/j.asoc.2012.04.005
© 2012 Elsevier B.V. All rights reserved.
Evolutionary Algorithm (SPEA) [7] and its improved version SPEA2[8], the Pareto archived evolution strategy (PAES) [9], the Paretoenvelope based selection algorithm (PESA) [10] and its revisedversion PESAII [11], and the improved version of NSGA (NSGAII)[12].
More recently, Zhang et al. [13] combined decomposition meth-ods in mathematics and the optimization paradigm in evolutionarycomputation and proposed the distinguished MOEA/D. MOEA/Dmaintains a good diversity by optimizing a set of various scalar sub-problems synchronously and outperforms other compared MOEAsbased on Pareto selection in solving MOPs with complicated PSshapes. Gong and Jiao et al. [14] utilized the superiority of theimmune inspired clonal selection evolution paradigm in maintain-ing population diversity and proposed a multi-objective immunealgorithm with nondominated neighbor-based selection (NNIA)which is an efficient and effective immune inspired multi-objectivealgorithm for MOPs. As only nondominated solutions have thechance to be proliferated in NNIA, the algorithm may be trappedin local optimal Pareto front if current isolated nondominated anti-bodies selected for proportional cloning are very few. To remedythis, Yang et al. [15] introduced vicinity distances based selec-
tion and adaptive ranks clone scheme into NNIA and proposed itsenhanced version NNIA2. NNIA2 has made a significant improve-ment in convergence and diversity maintaining, it is could be anefficient and effective algorithm for MOPs.
mput
fnnaIPopd(stHetrfTjfneeitIlatta
figroltmomBtifBardTnagoec
ltaovead
Y. Qi et al. / Applied Soft Co
The current MOEA researches overviewed above are mainlyocused on novel designed fitness assignment, diversity mainte-ance and external population. As to the mechanism of reproducingew generations, the traditional crossover and mutation oper-tor for scalar object optimization problems are directly adopt.n contrast to scalar object optimization, the distribution of theareto-optimal solutions of MOPs often shows a high degreef regularity. Considering a continuous m-objective optimizationroblem, it has been observed that under mild smoothness con-itions the PS in the decision space is a piecewise continuousm − 1)-dimensional manifold. Such regularity has been used inome mathematical programming approaches for approximatinghe PF in the object space or the PS in the decision space [16–18].owever, this characteristic of MOPs has not yet been utilized byxisting MOEAs until the works of Zhang’s team [19–23]. Amonghese works, RM-MEDA [22] and the generalized MMEA [23] areepresent ones. RM-MEDA and MMEA assumed that the mani-old of PS is consisted of K linear piecewise continuous manifold.herefore, these algorithms partitioned the population into K dis-oint clusters by the Local PCA algorithm and built a linear modelor each cluster to capture the regularity of the local part. Then,ew generations were reproduced by sampling from these mod-ls. These works indicated that the performance of multi-objectivevolutionary algorithms can be greatly enhanced if the regularityn the distribution of Pareto-optimal solutions is used. However,he clustering number is problem-related and hard to determine.n this work, we design a learning mechanism based on the regu-arity of MOPs to exploit information from the past and current PS,nd provide guidance for reproducing new solution set with bet-er convergence and diversity. The ability of organisms to improveheir fitness by way of reinforced learning and mimicry is knowns the Baldwin effect.
The type of interaction between learning and evolution wasrst proposed by Baldwin [24], therefore, the Baldwin effect is touide the evolution process through learning. Evolutionary algo-ithms (EAs) with Baldwinian learning are often regarded as a typef memetic algorithms (MAs) which is a combination of EAs andocal search [25]. However, Baldwinian learning mechanism trendso learn evolution experience of making progress from environ-
ent rather than to perform local search in the neighborhoodf individuals. The advantage of Baldwinian learning is that it isore unlikely to bring a diversity crisis within the population [26].
ased on the Baldwin effect, Hinton and Nowlan [27] developedhe first computational model with the Baldwin effect for evolv-ng neural networks, and their work has stimulated a number ofurther researches [28,29]. In the work of Ackley and Littman [30],aldwinian learning was used to assist the evolution of adaptivegents that struggle for survival in an artificial ecosystem. Veryecently, Gong and Jiao et al. made the first attempt to intro-uce the Baldwinian learning into artificial immune systems [31].he Baldwinian learning operator simulates the learning mecha-ism in immune system by employing information from within thentibody population to alter the search space. Experimental investi-ations on scalar function optimization and optimal approximationf linear system indicated that the Baldwinian learning guided thevolutionary search for good genotypes and made the algorithmonverge much faster.
The uniqueness of this work is that we design a Baldwinianearning strategy based on the regularity in distribution of the PS inhe decision space of MOPs and propose a multi-objective immunelgorithm with Baldwinian learning (MIAB) under the frameworkf NNIA for continuous multi-objective optimization problems with
ariable linkages. According to the latest discovery by Adriana Larat al. in their work HCS [32], two types of local search are suit-ble for MOPs, one is to move towards the PS along the descentirection which helps to accelerate the algorithm’s convergence,ing 12 (2012) 2654–2674 2655
the other is move along the PS by sidestep which helps to main-tain better diversity. In the proposed Baldwinian learning strategy,not only the descent and sidestep direction are captured from theevolving history, but also the regularity of current PS is take intoconsideration.
The remainder of this paper is organized as follows. Section 2introduces some backgrounds about the continuous MOPs, immuneinspired optimization algorithms, and some related terms. Section3 presents the motivation and the details of the proposed Bald-winian learning strategy and algorithm. Section 4 briefly presentsand analyzes the experimental results to validate our proposedapproach and the efficiency of the special Baldwinian learning.Section 5 concludes this paper and outlines future research work.
2. Related background
2.1. Definitions and notations of multi-objective optimization
In this paper, the following continuous multi-objective opti-mization problems (continuous MOPs) are considered:
Minimize F(x) = (f1(x), f2(x), . . . , fm(x))Subject to x ∈ ˝
(1)
In which ∈ Rn is the feasible region of the decision space, andx = {x1, x2, . . . , xn} ∈ is the decision variable vector. The targetfunction F(x) : x → Rm consists of m real-valued continuous objec-tive functions f1(x), f2(x), . . . , fm(x) and Rm is the objective space.
Different from scalar object optimization problems (SOPs), notall solutions in MOPs are comparable based on two or more objec-tive functions. Rather than finding a unique optimal solution, thetask of multi-objective optimization algorithm is to find a set ofoptimal tradeoff decision variable vectors known as the Pareto-optimal solutions. The set of all the optimal tradeoffs in the decisionspace and the objective space are known as the Pareto set (PS) andthe Pareto front (PF) respectively. Since it is impossible to find thewhole PS of continuous MOPs, we aim at finding a finite set of Paretooptimal vectors which are uniformly scattered along the true PF,and thus good representatives of the entire PF.
2.2. Regularity of continuous MOPs
For MOPs, the distribution of the PS in decision space exhibitshigh simplicity and regularity. Under certain smoothness assump-tions, it can be induced from the Karush–Kuhn–Tucker conditionthat the PS of a continuous multi-objective optimization problemdefines a piecewise continuous (m − 1)-dimensional manifold inthe decision space [16,18]. Specifically, the PS of a continuous bi-objective optimization problem is a piecewise continuous curve inRn, while the PS of a continuous tri-objective optimization problemis a piecewise continuous surface.
Such regularity of MOPs was first employed to enhance the per-formance of MOEAs by Q. Zhang’s team. Jin et al. firstly used thisregularity to investigate the reasons behind the success of localsearch in MOEAs [19]. They found that if connectedness holds, alocal search technique can find Pareto optimal solutions withoutexploring the dominated regions when one Pareto optimal solutionhas been found. Based on this work, Zhou et al. utilized a probabilitymodel to capture the regularity of the distribution of Pareto opti-mal solutions and proposed a model-based EA for MOPs [20,21].RM-MEDA [22] and the generalized MMEA [23] by Zhang et al.are generalizing works of utilizing the regularity of MOPs. These
two algorithms were designed under the paradigm of estimationof distribution algorithms (EDAs), several linear models were builtto approximate the PS manifold piecewise, and new generationswere sampled from the models thus built.
2656 Y. Qi et al. / Applied Soft Comput
mmiibn
�
risK(ti
ccmuwv
b
a
b
td
˚
m
�
�
Fig. 1. Illustration of the piecewise linear probability model in RM-MEDA.
RM-MEDA builds the following piecewise linear probabilityodel for modeling current PS manifold. For an m-objective opti-ization problem, the PS of current population can be envisaged as
ndependent observations of a probability model �, whose centroids an (m − 1)-dimensional piecewise continuous manifold notedy �. � can be described by equation (2), where � ∈ Rn and ε an-dimensional zero-mean noise vector.
= � + ε (2)
Fitting the model (2) to the points in current population is highlyelated to principal curve or surface analysis, which aims at find-ng a central curve or surface of a set of points in Rn. For sake ofimplicity, RM-MEDA assumes that the centroid of � consists of
manifolds � = � 1 + � 2 + · · · + � K , each � j(j = 1, 2, . . . , K) is anm − 1)-dimensional line segment or hyper-plane. Particularly, inhe case of two objectives, each � j is a line segment in Rn, as shownn Fig. 1.
RM-MEDA first divides current population into K disjointlusters S1, S2, . . . , SK by the (m − 1)-dimensional local principalomponent analysis algorithm and then build the piecewise linearodel � j to approximate the centroid of each Sj. Given the subpop-
lation Sj, let xj be its mean and Uji
be its i-th principal componenthich is a unity eigenvector associated with the i-th largest eigen-
alue of the covariance matrix of the points in Sj. Compute aji
andjiby Eqs. (3) and (4) respectively.
ji= min
x ∈ Sj(x − xj)
TUj
i(3)
ji= max
x ∈ Sj(x − xj)
TUj
i(4)
Note ˚j as the smallest line segment or hyper-plane containinghe projections of all the points of Sj in the affine (m − 1)-imensional principal subspace of Sj, then:
j ={
x ∈ Rn∣∣x = xj +
m−1∑i=1
˛iUji, aj
i≤ ˛i ≤ bj
i, i = 1, . . . , m − 1
}(5)
The probability model � j extends ˚j by 50% along each of the − 1 principal component directions Uj
1, Uj2, . . . , Uj
m−1, therefore,j is set as:
j ={
x ∈ Rn|x = xj +m−1∑i=1
˛iUji, ai
j − 0.25(bij − ai
j) ≤ ˛i ≤ bij
+ 0.25(bij − ai
j), i = 1, . . . , m − 1
}(6)
ing 12 (2012) 2654–2674
Fig. 1 takes two objectives problem for example to illustrationthe idea of the probability model and the relationships between Sj,˚j and � j . In this illustrative example, the number of clusters K is 3,˚1, ˚2 and ˚3 are the smallest line segments which are local linearapproximations to the 1-dimensional manifold of current Paretoset. � 1, � 2 and � 3 are their extensions which can provide a betterapproximation.
Q. Zhang’s works provide a useful tool to analysis the distribu-tion of points in current Pareto set. With the help this modelingmethod, we utilize regularity of MOPs to promote the efficiency ofour previous work NNIA. Unlike Q. Zhang’s EDA approaches, themain contribution of this paper is to design a Baldwinian learningstrategy to grasp the global distribution of current Pareto set andconsider the Pareto set as a whole rather than a set of indepen-dent individuals. Through the proposed learning, both the historydescent direction and the regularity of current population are cap-tured and used as guidance for further evolution.
2.3. Immune algorithms for multi-object optimization
Artificial immune system (AIS) is a new computational intelli-gence method inspired by theoretical immunology and observedimmune functions, principles and models, which are applied todeal with science and engineering problems [33]. More and moreresearches indicate that, comparing with evolutionary algorithms,artificial immune algorithms can maintain better population diver-sity and thus not easy to fall in to local optimal.
Recently, artificial immune algorithms have been graduallyapplied to multi-objective optimization. Yoo and Hajela [34]first introduced an immune based fitness modification into theirgenetic multi-objective algorithm. Coello Coello [35,36] proposedthe first real meaning of multi-objective immune system algo-rithm (MISA) based on the immune clonal selection principle.Luh and Chueh [37] proposed a novel multi-objective immunealgorithm (MOIA) by simulating the antibody-antigen relation-ships in terms of specificity, germinal center, and the memorycharacteristics of adaptive immune responses. Under the frame-work of the artificial immune network algorithm, Freschi andRepetto [38] proposed a Vector Artificial Immune System (VAIS)for solving MOPs. Cutello et al. [39] proposed a modified versionof Pareto archived evolution strategy (I-PAES) algorithms by usingtwo immune inspired operators: cloning and hyper-mutation, andapplied it to solve the protein structure prediction problem. Basedon the immune clonal selection principle, Jiao and Gong et al.carried out thorough researches on immune mechanism for opti-mization and proposed several immune multi-object optimizationalgorithms [14,15,40,41]. The multi-objective immune algorithmwith nondominated neighbor-based selection (NNIA), which con-sists of a novel non-dominated neighbor-based selection strategy,crowding-distance based proportional cloning, simulated binarycrossover and static hypermutation operator, is the most repre-sentative work.
2.4. Searching paradigm of immune clonal selection basedoptimization
The immune clonal selection principle [42] proposed by Burnetin 1958 is a widely accepted model for how the immune sys-tem search for antibodies which match the antigen best and thusresponds to infection. Based on this principle, Castro pioneeredthe Clonal Selection Algorithm (CSA) [43] for the optimizationproblem. This work established the framework of the searching
paradigm based on immune clonal selection and affinity matura-tion by hyper-mutation. Fig. 2 is the searching paradigm of clonalselection based immune optimization algorithm. It illustrates aninstance antibody among the antibody population changes from
Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2657
ction
oaott
cotpwtaasm
2
mttrvicm
{{ttc
A
C
wibt
B
D
erated by the reproducing phase can be divided into threecategories: evolved offsprings which dominate their parent solu-tions, degraded offsprings which are dominated by their parentsolutions and non-dominated offsprings which neither dominate
Fig. 2. Searching paradigm of clonal sele
ne individual to a better one in one iteration. Considering anntibody as the coding of a solution for MOPs, we can solve theptimization problem by simulating the immunological recogni-ion procedure which finds out the best matched antibody withinhe antibody space to recognize a certain antigen.
In this iteration flow, there are three important operations: thelone operation, the immune genetic operation and the selectionperation. The clone operation will decide how many offspringshe operated antibody proliferates. The clone size is usually pro-ortional to the antibody’s affinity. The immune genetic operationhich is consist of mutation and recombination will determine how
he antibody population evolve and maturate. This operation usu-lly special designed according to the target problem and currentntibody population. The selection operation will decide which off-pring antibody will survive. Usually the antibody with high affinityore likely to be retained.
.5. Coding and affinity assignment of NNIA
Coding and affinity assignment determine the optimizationodel of immune optimization algorithms. The neighborhood rela-
ionship between solutions depends on the coding strategy andhe landscape of the searching space lies on affinity assignment. Asegard to MOPs, we want to find uniformly scattered Pareto optimalectors, thus the algorithm should spend more computing times onndividuals in the sparse part of current PF. The same as NNIA, therowing-distance [12] of the antibody is adopted in this work toeasure whether it is in the sparse part or not.For any antibody A in the antibody population P, A =
a1, a2, . . . , an} is the coding of the decision variable x =x1, x2, . . . , xn}. In this work, we adopt real-valued presentation,hat is, ai = xi, i = 1, 2, . . . , n. So, A = {a1, a2, . . . , an} must be inhe feasible region ˝. The affinity of antibody A is defined as itsrowding-distance in the population P:
ffinity(A|P) = CD(A, P) (7)
And the crowding-distance of A ∈ P can be defined as:
D(A, P) =m∑
i=1
�i(A, P)
f maxi
− f mini
(8)
here f maxi
and f mini
are the maximum and minimum value of the-th objective. Denote boundary antibody set of the i-th objectivey Bdi, the antibodies belong to or not belong to Bdi are differentlyreated.
d = {A|A ∈ P, ∀A′ ∈ P : f (A) = min{f (A′)} or max{f (A′)}} (9)
i i i iiA = min{fi(A′) − fi(A
′′)|A, A′, A′′ ∈ P, A /∈ Bdi : fi(A′′) < fi(A) < fi(A
′)}(10)
based immune optimization algorithm.
�i(A, P) ={
2 × max{DiA′ }, if A, A′ ∈ P, A ∈ Bdi, A′ /∈ Bdi
DiA, otherwise
(11)
Based on the crowding-distance CD(A, P), we can estimate thedensity of antibodies surrounding A in the population P. Antibodywith larger crowding-distance also has higher affinity and will bemore likely to survive and proliferate. Here, the boundary antibod-ies are assigned with extremely higher affinities. Such design makesthe boundary antibodies occupy more computing time which maylead to a wider Pareto front.
3. Algorithm
3.1. Basic idea
As has been described in Section 2.2, RM-MEAD divided currentpopulation into K disjoint clusters and built distribution model withlinear centroid for each cluster to approximate a part of the PS mani-fold. Fig. 3 takes bi-objective problems for example to illustrate thebasic idea of the proposed Baldwinian learning. The parent solu-tions in Fig. 3 are in the same subpopulation Sj and the centroid ofthe distribution mode � j is a line segment in the decision space. Thepopulation of solutions evolves towards the ideal Pareto Set fromone distribution model to another. Therefore, how to maintain andutilize the trend of evolution by investigating the changing of thedeveloping distribution model is the main motivation of this work.
At each iteration of the evolution loop, new offsprings gen-
Fig. 3. Basic idea of Baldwinian learning.

2 omput
nsiudPtotoos
3
t
AAAAABDC
A
I
O
S
S
S
S
ttllatp
ts
658 Y. Qi et al. / Applied Soft C
or are dominated by their parent solutions. After the Paretoelection process, evolved and degraded offsprings which containmplicit information about the improving trends of current pop-lation have the chance to survive. According to the changingirections of surviving individuals and the distribution of currentS, a candidate improvement field can be estimated by projectinghe improvement directions on the normal plane of the centroidf the distribution model, as illustrated by Fig. 3. In such a way,he evolution trend can be obtained based on both the distributionf the population and the collective improving information of anffsprings set, rather than by investigating the improvement of aingle individual like hill climbing methods.
.2. Algorithm framework
In the proposed MIAB, each antibody Ab in the population main-ains four data elements which are described as follows:
b.code: antibody codeb.Fvalue: target function valuesb.dir: history searching directionb.affinity: affinity of antibodyt each iteration t, the algorithm maintains:t: Antibody populationt: Nondominanted populationt: Clone population
lgorithm 1. The main Framework of the proposed MIAB
nput: A stopping criterionnD: Maximum size of non-dominated populationnA: Maximum size of active populationcs: Clone sizePBL: Baldwinian learning probabilityK: Number of subpopulations
utput: Dt+1 as the resulting approximate Pareto-optimal setStep1 Initialization
Step1.1: Set the iteration time t = 0;Step1.2: Generate initial antibody population Bt = (Ab1, . . . , AbnD )
with size nD at random. For each initial antibody Abi ,i = 1, 2, . . . , nD ,Abi. dir is initialized to an unit vector with random direction;
Step1.3: Create the initial non-dominated population Dt={} and theinitial clone population Ct={}, where the symbol {} stands for the emptyset.
tep2: Update Non-dominated Population: Identify dominant antibodiesin Bt , copy all the dominant antibodies to form the temporarynon-dominated population DTt . If the size of DTt is not greater than nD ,let Dt = DTt; Otherwise, calculate the crowding-distance values of allindividuals in DTt , sort them in descending order of crowding-distance,and choose the first nD individuals to form Dt .
tep3 Termination: If the stopping criteria is met, stop and output Dt asthe as the resulting approximate Pareto-optimal set; Otherwise,continue.
tep4 ProliferationIf Rand(0, 1) < PBL , then
Apply the Baldwinian learning operator on Dt giving rise to theoffspring population Ct: Ct = BL(Dt, cs, K)Otherwise:
Apply the clone proliferating operator on Dt with clone size cs andmaximum active population size nA , giving rise to Ct:Ct = CLONE(Dt, cs, nA)
tep5 Get the antibody population Bt by combining the Ct and Dt , lett = t + 1, and go to Step2.
In the proposed MIAB, the Baldwinian learning is applied onhe non-dominated population Dt with probability PBL . Underhe background of global search performed by the clone pro-iferating operator, the Baldwinian learning operator builds theinear distribution models of current non-dominated population topproximate the PS manifold and consider the individuals withinhe same distribution model as a whole rather than independent
oints.For a clearer illustration of how MIAB works, Fig. 4 showshe population evolution of the proposed algorithm and demon-trates the relationship between the main framework and the two
ing 12 (2012) 2654–2674
sub-algorithms. The Baldwinian learning operator obtains knowl-edge from the whole population and apply it on individuals as anevolving guide. The following Algorithms 2 and 3 are details ofthe clone proliferating operator and the novel designed Baldwinianlearning operator.
3.3. The clone proliferating operator
It has been proved that, the immune clonal selection basedoptimization algorithms have a good capability of maintain diver-sity and not easy to fall into the local convergence. Therefore, theimmune clonal selection based searching paradigm is employed inthe proposed MIAB as the main evolving strategy to perform globalsearch and keep population variety. The clone proliferating opera-tor applied on Dt with clone size cs and maximum active populationsize nA works as follows:
Algorithm 2. Clone proliferating operator: Ct = CLONE(Dt, cs, nA)
Input: Dt ,cs,nA
Output: Ct
Step1 Activation: Clear the active population AP. Calculate the affinity ofeach antibody in Dt according to equations (7)-(11), choose the nA bestantibodies base on the affinity measure and add them to the activepopulation AP.
Step2 Proportional Cloning: Get the clone population C by applying theproportional cloning to AP. The clone size of the ith antibody Ai in AP isproportional to its affinity and can be calculated by the following Eq.(12), in which i = 1, 2, . . . , nA and nA is the size of population of AP.
qi =
⌈cs × Affinity (Ai
∣Dt )∑nA
j=1Affinity
(Aj
∣Dt
)⌉
(12)
Step3 Immune genetic operation: Apply recombination and mutationoperators on C giving rise to the offspring C’. Initialize C’ with an emptyset, for each antibody A in the temporary population C:
Step3.1 Recombination: Apply the simulated binary crossover (SBX)operator [44] between antibody A and another antibody which israndom selected from the active population AP and different from A,giving rise to the offspring antibody A′ by selecting one of the tworecombination offspring at random.Step3.2 Mutation: Apply the polynomial mutation operator [44] to A′
and set A′′ to the mutation offspring.Step3.3 Record History: Set A′′.dir = A′′.code − A.code, add A′′ to C ′ .
Step4 Output result: Let Ct = C ′ , output Ct , Stop.
In the clone proliferating operator, active antibody with higheraffinity has larger clone size. According to the definition of affinityin Eqs. (7)–(11), the affinity of an active antibody is defined as itscrowding distance in population Dt. Therefore, the proposed algo-rithm obtains better diversity by spending more computing timeon dealing with less crowded parts of the current PS.
Fig. 5 is an illustration of how the clone proliferating operatorworks. According to the biological immune clonal selection theory,antibodies with higher affinity are more likely to survive and pro-liferate. Therefore, in the clone proliferating operator, the activepopulation is determined by affinity sorting and the clone size ofeach active antibody is also proportional to its affinity.
In the recombination and mutation step, the common usedSBX operator which searches between two parent antibodies andpolynomial mutation operator which searches around a single anti-body are employed to perform global random search. At last, thechanging direction of each offspring antibody which could be animprovement direction is recorded.
3.4. The proposed Baldwinian learning operator
By using the probability model which has been described inSection 2.2, the Baldwinian learning operator is designed to main-tain useful information about the evolving environment and useit as guidance for further evolution. The basic idea of the proposed

Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2659
n evo
Bi
A
lrbte
Fig. 4. Populatio
aldwinian learning operator has been discussed in Section 3.1, andt works as follows:
lgorithm 3. Baldwinian learning operator: Ct = BL (Dt, cs, K)
Input: Dt , cs, KOutput: Ct
Step1 Modeling: Divide Dt into K disjoint clusters S1, S2, · · ·, SK , build the
probability model (2) and get the centroid set{
� 1, � 2, · · ·, � K}
for all
clusters, note Uj1, Uj
2, · · ·, Ujm−1 as the m − 1 principal component
directions of the covariance matrix of the points in Sj , j = 1, 2, · · ·, K;Step2 Baldwinian evolving: Apply the Baldwinian evolving operator on Dt
as following, giving rise to the offspring population C1. For each antibodyA in population Dt , assume that A ∈ Sj ,j = 1, 2, · · ·, K , note A′ as theevolving offspring of A:Step2.1 Generate descent direction: Select another antibody A in Sj atrandom, set the candidate descent direction asdir = ˛A.dir + (1 − ˛) A.dir, where is a random real number between 0and 1.
Step2.2 Orthogonalization: Note Span{
Uj1, Uj
2, · · ·, Ujm−1
}as the
(m − 1)-dimensional subspace spanned by Uj1, Uj
2, · · ·, Ujm−1, find an
orthonormal basis of the subspace{
�j1, �j
2, · · ·, �jm−1
}by the following
Gram-Schmidt orthogonalization procedure:
ˇ1 = Uj1, �j
1 = ˇ1⁄∥∥ˇ1
∥∥ˇ2 = Uj
2 −⟨
Uj2, �j
1
⟩�j
1, �j2 = ˇ2⁄
∥∥ˇ2
∥∥ˇ3 = Uj
3 −⟨
Uj3, �j
1
⟩�j
1 −⟨
Uj3, �j
2
⟩�j
2, �j3 = ˇ3⁄
∥∥ˇ3
∥∥...
ˇm−1 = Ujm−1 −
m−2∑i=1
⟨Uj
m−1, �ji
⟩�j
i, �j
m−1 = ˇm−1⁄∥∥ˇm−1
∥∥(13)
Step2.3 Refine searching direction: Refine dir and get a new searchingdirection dir ′ by the following equation:
dir ′ = dir −m−1∑i=1
⟨dir, �j
i
⟩�j
i(14)
Step2.4 Reproduction: Find A′ from A along dir ′:A′.code = A.code + � dir ′, 0 ≤ � ≤ 1 (15)
Step 2.5 Record History: Set A′.dir = A′.code − A.code, add A′ to C1;Step3 clone proliferating: apply the clone proliferating operator on Dt
with clone size cs − nD , giving rise to the offspring C2.Step4 Output result: Let Ct = C1 ∪ C2, output Ct , Stop.
It can be seen from the workflow of the proposed Baldwinianearning operator, antibody learn from its environment in two
espects. First, in Step 2.1, a candidate descent direction dir for anti-ody A is prepared by combining its own evolving history A.dir andhat of another random selected antibody A which shares the samenvironment Sj with A. Second, the candidate descent direction dirlution of MIAB.
is refined by projecting it onto the normal panel of the model cen-troid � j which is a linear fitting of the points in Sj. According tothe basic idea of the proposed Baldwinian learning operator whichis shown in Fig. 3, if antibodies A and A are divided in to the samedisjoint cluster, they may share the same evolving environment.Therefore, the history searching directions of antibody A and A,which must be an improvement direction as these two antibod-ies survived at the latest iteration, may point to the same parts ofthe searching field toward the target PS. In order to maintain a bet-ter population diversity, A is randomly selected from the clusterof A and a candidate descent direction is obtained by combing thehistory searching directions of A and A. In the proposed Baldwinianlearning operator, antibodies in the same cluster are viewed as aunified whole. Their distribution can provide some useful infor-mation about the evolving environment, which is an importantguidance for further evolution.
4. Experimental study
In this section, we will compare the proposed MIAB with threeother outstanding evolutionary multi-objective optimization algo-rithms NSGAII [12], MOEA/D [13] and NNIA [14] in solving 8well-known multi-objective test instances. Among these comparedalgorithms, NSGAII is a fast and elitist evolutionary multi-objectivealgorithm, MOEA/D is a decomposing based evolutionary multi-objective algorithm which is a recent proposal and has shown aremarkable performance when dealing with complicate MOPs, ourprevious work NNIA is an immune clonal selection based multi-objective optimization algorithm. In a sense, the proposed MIAB canbe comprehended as an improved NNIA with Baldwinian learning.The simulating software of the compared approaches are devel-oped by VC++6.0 and run on a personal computer with Inter Core21.86 GHz CPU and 2 GB RAM.
4.1. Test instances
In the experimental study, we select 8 representative test func-tions to validate the effectiveness of the propose approach. The firstfive 30-dimensional ZDT problems ZDT1, ZDT2, ZDT3, ZDT4 and
ZDT6 were propose by Zitzler et al. [46]. The next three DTLZ prob-lems DTLZ1, DTLZ3 and DTLZ6 were developed by Deb, Thiele, et al.[45]. These testing functions have been cited in a number of sig-nificant works in multi-objective optimization field. All these test
2660 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
clone
iT
4
ivttaWb
4
td
I
wstD
4
oMiepwoh
n
4
o
runs of compared algorithms on each test instance. Figs. 7 and 8show in the objective space, the distribution of the final non-dominated fronts with the lowest IGD values found by MIAB,NSGAII and MOEA/D in solving bi-objective ZDT problems and
Fig. 5. Illustration of the
nstances are minimization of the objectives and listed in detail inable 1.
.2. Performance metric
In the experimental studies of this work, the common usednverted generational distance (IGD) metric [47] and the hyper-olume metric [7] are employed to evaluate the performances ofhe compared algorithms. These tow types of performance indica-ors are comprehensive index of convergence and diversity, theyre regarded as rather fair measures and have favorable properties.hen using the IGD metric, true Pareto set of the target MOPs must
e given, but the hypervolume metric do not need.
.2.1. IGD metricLet P* be a set of uniformly distributed Pareto-optimal points in
he true PF. Let P be an approximation to the PF. The IGD metric isefined as follows:
GD(P∗, P) =∑
v ∈ P∗ d(v, P)
|P∗| (16)
here d(v, P) is the minimum Euclidian distance in the objectivepace between v and the points in P, |P*| is the cardinality of P*. Inhis work, the size of P* is set as 500 for ZDT functions and 2500 forTLZ functions.
.2.2. Hypervolume metricLet P = (p1, . . . , ps) be an approximation to the PF in the positive
rthant Rm≥0 of the m-dimensional objective space. For minimization
OPs, the hypervolume metric is a measure of the region whichs simultaneously dominated by P and bounded above by a ref-rence point rp ∈ Rm
≥0 such that rp ≥ (maxpp1, . . . , maxppm) where = (p1, . . . , pm) ∈ P ⊂ Rm
≥0 and the relation ≥ applies component-ise. As illustrated in the following Fig. 6, this region consists of an
rthogonal polytope, and may be seen as the union of s axis-alignedyper-rectangles with one common vertex rp.
In this work, the reference point rp is set by maximum values ofon-dominated solutions obtained by the compared algorithms.
.3. Experimental setup
In NSGAII, MOEA/D and NNIA, the simulated binary crossoverperator and polynomial mutation are adopted for generating
proliferating operator.
offsprings. In the proposed MIAB, SBX operator and polynomialmutation are also used in the clone proliferating operator. Forthe fairness, the SBX operators and the polynomial mutations inall compared algorithms have the same parameter setting. Thecrossover probability of SBX is set as 0.8, and the distribution indexfor SBX is set as 15. The mutation probability of the polynomialmutation is set as 1/n, where n is the number of variables of testedMOPs. The distribution index for polynomial mutation is set as 20.The other parameters of the proposed MIAB are set as follows: theBaldwinian learning probability PBL is set as 0.2 and the number ofsubpopulations K is set as 5.
For the proposed MIAB and NNIA, the maximum size of the non-dominated population nD is 100, the maximum size of the activepopulation is 20 and the clone size cs is 100. For NSGAII, the popula-tion size is 100 and an external population size is 100. For MOEA/D,the number of the sub-problems is 100 and the number of theweight vectors in the neighborhood of each weight vector is 10. Thepopulation in each algorithm is initialized uniformly and randomlyin the decision space. For the sake of fairness, all the compared algo-rithms have the same stop criteria, each simulation continues untilthe total number of function evaluations reaches its upper limit.
4.4. Experimental results of MIAB and comparisons
In the following experiments, we performed 30 independent
Fig. 6. Illustration of the hypervolume metric in the two-objective case with s = 3.
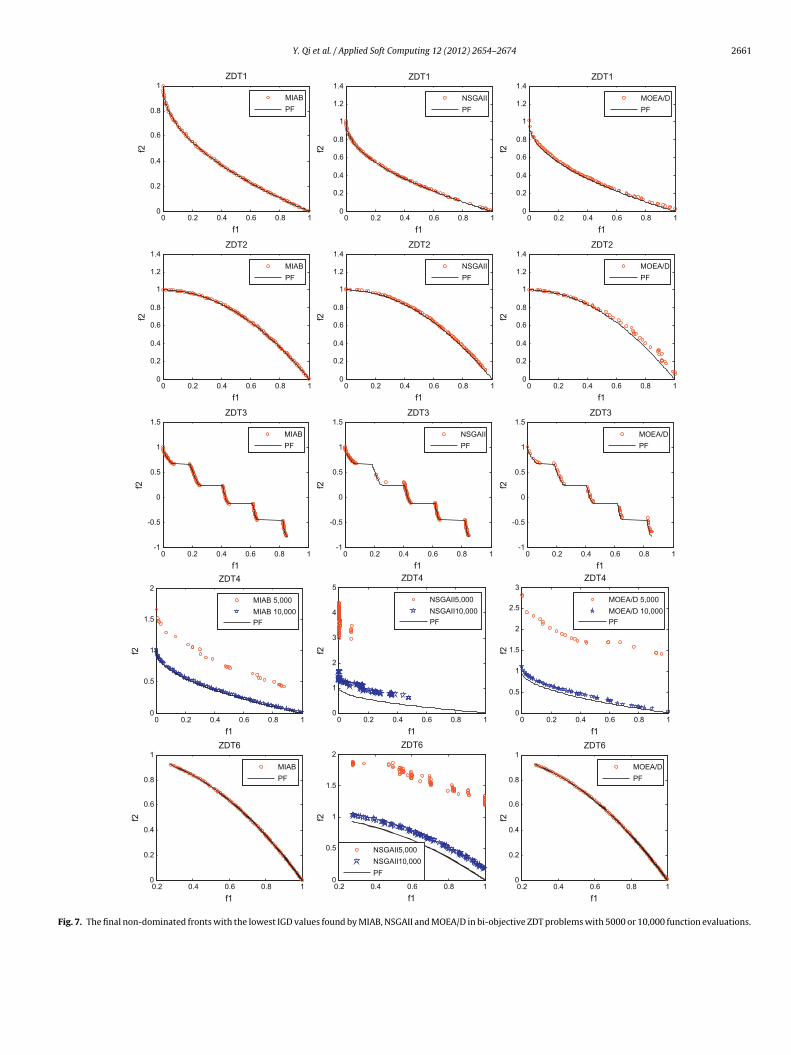
Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2661
0 0.2 0.4 0. 6 0. 8 10
0.2
0.4
0.6
0.8
1
f1
f2
ZDT1
MIAB
PF
0 0. 2 0. 4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
f1
f2
ZDT1
NSGAII
PF
0 0. 2 0. 4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
f1
f2
ZDT1
MOEA/D
PF
0 0.2 0.4 0. 6 0. 8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
f1
f2
ZDT2
MIAB
PF
0 0. 2 0. 4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
f1
f2
ZDT2
NSGAII
PF
0 0. 2 0. 4 0. 6 0. 8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
f1
f2
ZDT2
MOEA/D
PF
0 0.2 0. 4 0. 6 0.8 1-1
-0.5
0
0.5
1
1.5
f1
f2
ZDT3
MIAB
PF
0 0. 2 0. 4 0. 6 0. 8 1-1
-0.5
0
0.5
1
1.5
f1
f2
ZDT3
NSGAII
PF
0 0. 2 0. 4 0. 6 0. 8 1-1
-0.5
0
0.5
1
1.5
f1
f2
ZDT3
MOEA/D
PF
0 0. 2 0. 4 0. 6 0. 8 10
0.5
1
1.5
2
f1
f2
ZDT4
MIAB 5,000
MIAB 10,000
PF
0 0. 2 0. 4 0.6 0.8 10
1
2
3
4
5
f1
f2
ZDT4
NSGAII5,000
NSGAII10,000
PF
0 0.2 0.4 0. 6 0. 8 10
0.5
1
1.5
2
2.5
3
f1
f2
ZDT4
MOEA/D 5,000
MOEA/D 10,000
PF
0.2 0.4 0.6 0. 8 10
0.2
0.4
0.6
0.8
1
f1
f2
ZDT6
MIAB
PF
0.2 0.4 0. 6 0.8 10
0.5
1
1.5
2
f1
f2
ZDT6
NSGAII5,000
NSGAII10,000
PF
0.2 0.4 0. 6 0.8 10
0.2
0.4
0.6
0.8
1
f1
f2
ZDT6
MOEA/D
PF
Fig. 7. The final non-dominated fronts with the lowest IGD values found by MIAB, NSGAII and MOEA/D in bi-objective ZDT problems with 5000 or 10,000 function evaluations.

2662 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
Table 1Test instances.
Problems Variable Dimension Objective functions (minimized)
ZDT1 [0, 1] 30f1(x) = x1 f2(x) = g(x)
[1 −
√x1/g(x)
]g(x) = 1 + 9
(∑n
i=2xi
)/(n − 1)
ZDT2 [0, 1] 30f1(x) = x1 f2(x) = g(x)[1 − (x1/g(x))2]
g(x) = 1 + 9(∑n
i=2xi
)/(n − 1)
ZDT3 [0, 1] 30f1(x) = x1 f2(x) = g(x)
[1 −
√x1/g(x) − x1
g(x)sin(10�x1)
]g(x) = 1 + 9
(∑n
i=2xi
)/(n − 1)
ZDT4x1 ∈ [0, 1]xi ∈ [−5, 5]i = 2, . . . , n
30f1(x) = x1 f2(x) = g(x)
[1 −
√x1/g(x)
]g(x) = 1 + 10(n − 1) +
∑n
i=2[x2
i− 10 cos(4�xi)]
ZDT6 [0, 1] 30f1(x) = 1 − e(−4x1)×[sin(6�x1)]6 f2(x) = g(x)[1 − (f1(x)/g(x))2]
g(x) = 1 + 9[(∑n
i=2xi
)/(n − 1)
]0.25
DTLZ1 [0, 1] k + |xk | − 1
f1(x) = 12
x1x2· · ·xk−1(1 + g(xk))
f2(x) = 12
x1x2· · ·(1 − xk−1)(1 + g(xk))
.
.
.
fk−1(x) = 12
x1(1 − x2)(1 + g(xk))
fk(x) = 12
(1 − x1)(1 + g(xk))
where g(xk) = 100
[|xk | +
∑xi ∈ xk
((xi − 0.5)2 − cos(20�(xi − 0.5)))
]
DTLZ3 [0, 1] k + |xk | − 1
f1(x) = (1 + g(xk)) cos(x1�/2) cos(x2�/2)· · · cos(xk−2�/2) cos(xk−1�/2)f2(x) = (1 + g(xk)) cos(x1�/2) cos(x2�/2)· · · cos(xk−2�/2) sin(xk−1�/2)...fk−1(x) = (1 + g(xk)) cos(x1�/2) sin(x2�/2)fk(x) = (1 + g(xk)) sin(x1�/2)
where g(xk) = 100
[|xk | +
∑xi ∈ xk
((xi − 0.5)2 − cos(20�(xi − 0.5)))
]
DTLZ6 [0, 1] k + |xk | − 1
f1(x) = x1
f2(x) = x2
.
.
.fk−1(x) = xk−1
fk(x) = (1 + g(xk))h(f1, f2, . . . , fk−1, g)
where g(xk) = 1 + 9|xk|
∑xi ∈ xk
xi,
k∑[ ]
toastttf
hfiuthtetntb
ri-objective DTLZ problems respectively. The maximum numbersf function evaluations are set as 5000 for bi-objective problemsnd 20,000 for tri-objective problems. For some difficult problems,uch as ZDT4 and ZDT6 in Fig. 4, the Pareto fronts obtained byhe algorithms with 10,000 function evaluations are also given. Inhese figures, the algorithm name followed by 5000 or 10,000 meanhe Pareto fronts obtained by the algorithm with 5000 or 10,000unction evaluations.
As shown in Fig. 7, for ZDT1, ZDT2 and ZDT3 problems whichave convex, non-convex and discontinuous PF respectively, thenal non-dominated fronts obtained by MIAB are more diverse andniform than those found by NSGAII and with better approximationo the target PF than those found by MOEA/D. As for ZDT4 whichas many local PFs, MIAB and MOEA/D obtained better diversityhan NSGAII during the evolution procedure. After 10,000 functionvaluations, the final non-dominated front found by MIAB has bet-
er approximation quality than that obtained by MOEA/D. For theon-uniform function ZDT6 which has low density of solutions nearhe Pareto front, MIAB performs very similar to MOEA/D and muchetter than NSGAII in terms of both approximation and uniformity.h(f1, f2, . . . , fk−1, g) = k −i=1
fi1 + g
(1 + sin(3�fi))
Fig. 8 illustrates the non-dominated fronts found by each algo-rithm on tri-objective problems DTLZ1, DTLZ3 and DTLZ6 whichhave linear, concave and discontinuous PF respectively. From thisfigure, we can come to the similar conclusion as in Fig. 4. MIABperforms similar or better than NSGAII and MOEA/D in both approx-imation and uniformity with 20,000 function evaluations.
Among the eight representative testing problems, ZDT3 andDTLZ6 are respectively bi-objective and tri-objective optimizationproblems whose ideal Pareto sets are not connected (piecewisecontinuous) manifolds. Experimental results on these two prob-lems in Figs. 7 and 8 indicate that, the proposed MIAB outperformsthe other two outstanding evolutionary multi-objective optimiza-tion algorithms NSGAII and MOEA/D. In other words, the noveldesigned Baldwinian learning operator also works when solvingmulti-objective optimization algorithms with discontinuous man-ifolds of PS.
Fig. 9 illustrates the box plots of comparisons between theproposed MIAB and other two compared algorithms with 5000function evaluations for bi-objective problems and 20,000 func-tion evaluations for tri-objective problems based on the IGD metric.

Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2663
0
0.5
1
0
0.5
1
0
0.5
1
f1
DTLZ1
f2
f3
MIAB
00.5
11.5
0
0.5
1
1.5
0
0.5
1
1.5
f1
DTLZ1
f2
f3
NSGAII
00.5
11.5
0
0.5
1
1.5
0
0.5
1
f1
DTLZ1
f2
f3
MOEA/D
0
5
10
0
5
10
0
5
10
f1
DTLZ3
f2
f3
MIAB
0
50
100
0
5
10
0
2
4
6
f1
DTLZ3
f2
f3
NSGAII
0
2
4
0
2
4
0
2
4
f1
DTLZ3
f2
f3
MOEA/D
0
0.5
0
0.5
2
4
6
8
DTLZ6
f3
MIAB
0
0.5
1
0
0.5
1
2
4
6
8
DTLZ6
f3
NSGAII
0
0.5
0
0.5
2
4
6
DTLZ6
f3
MOEA/D
F GAII an
BirbrPrb
sAbpNtNcadamb
o
11 f1f2 f2
ig. 8. The final non-dominated fronts with the lowest IGD values found by MIAB, NS
ox plots are used to illustrate the distribution of results over 30ndependent runs. In a notched-box plot, the notches represent aobust estimate of the uncertainty about the medians for box-to-ox comparison. Symbol “+” denotes outliers. As the IGD metricepresents the statistical distance between the set of approximateareto-optimal solutions and the ideal Pareto-optimal fronts, algo-ithm which obtains lower IGD values has superior performance inoth convergence and diversity.
As can be seen from Fig. 9 that MIAB performances stable anduperior to NSGAII and MOEA/D in solving ZDT1, ZDT2 and ZDT3.s for the more complex problems ZDT4 and ZDT6, MIAB is slightlyetter than MOEA/D but much superior to NSGAII. For tri-objectiveroblem DTLZ1, MIAB performs as well as MOEA/D but better thanSGAII. For DTLZ3, MIAB is more stable than MOEA/D and superior
o NSGAII. For DTLZ6, MIAB is stable and superior to MOEA/D andSGAII. From these experimental results we can come to the con-lusion that, when dealing with MOPs with discontinuous PF, suchs ZDT3 and DTLZ 6, MIAB performs better than MOEA/D. Whenealing with complex MOPs like ZDT4 and ZDT6, MIAB and MOEA/Dre much better than NSGAII. The major reason may lie in that MIAB
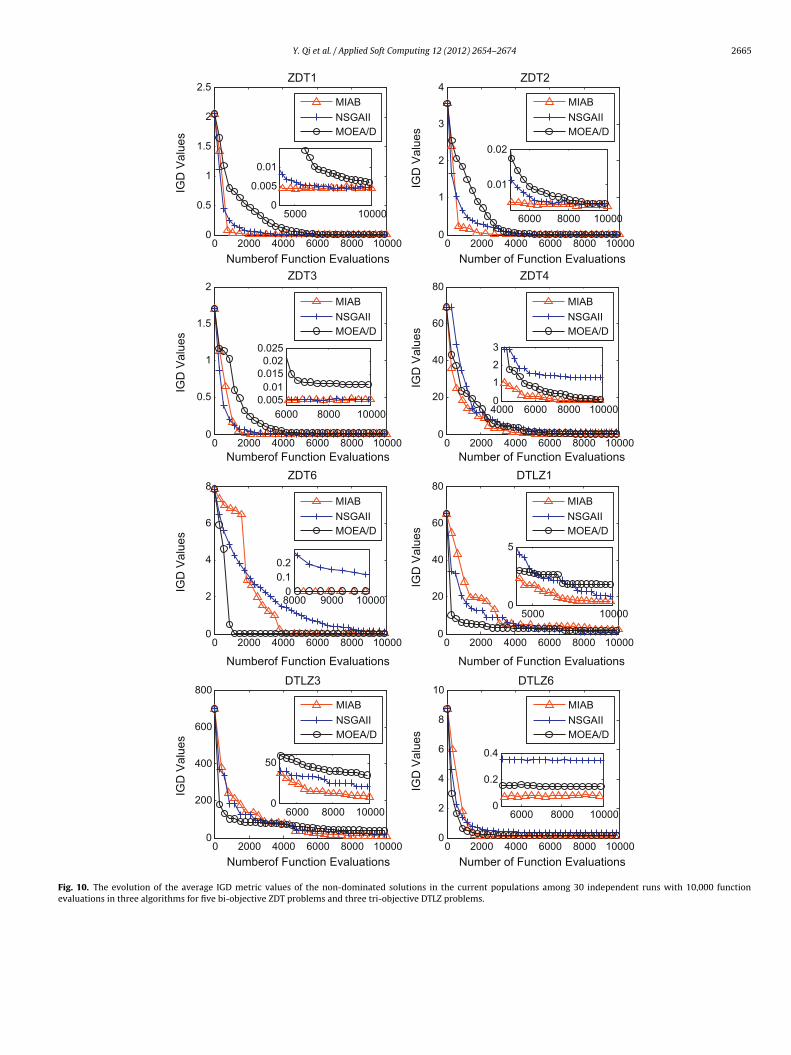
aintains as good population diversity as MOEA/D which can alsoe conformed by the distribution of non-dominated fronts in Fig. 8.Fig. 10 shows the evolution of the average IGD metric values
f the non-dominated fronts in the current populations among 30
f1 11 f1f2
d MOEA/D in solving tri-objective DTLZ problems with 20,000 function evaluations.
independent runs with 10,000 function evaluations. From this fig-ure we can find out that MIAB converges much faster and maintainsbetter Pareto solution sets than NSGAII and MOEA/D in solvingZDT1 and ZDT2. For ZDT3, MIAB and NSGAII converge faster thanMOEA/D and maintain better Pareto solution sets. For complexproblems ZDT4 and ZDT6, MIAB and MOEA/D converge faster andperform better than NSGAII. For tri-objective problems DTLZ1,DTLZ3 and DTLZ6, NSGAII and MOEA/D converge faster than MIABbut MIAB maintains better Pareto solution sets.
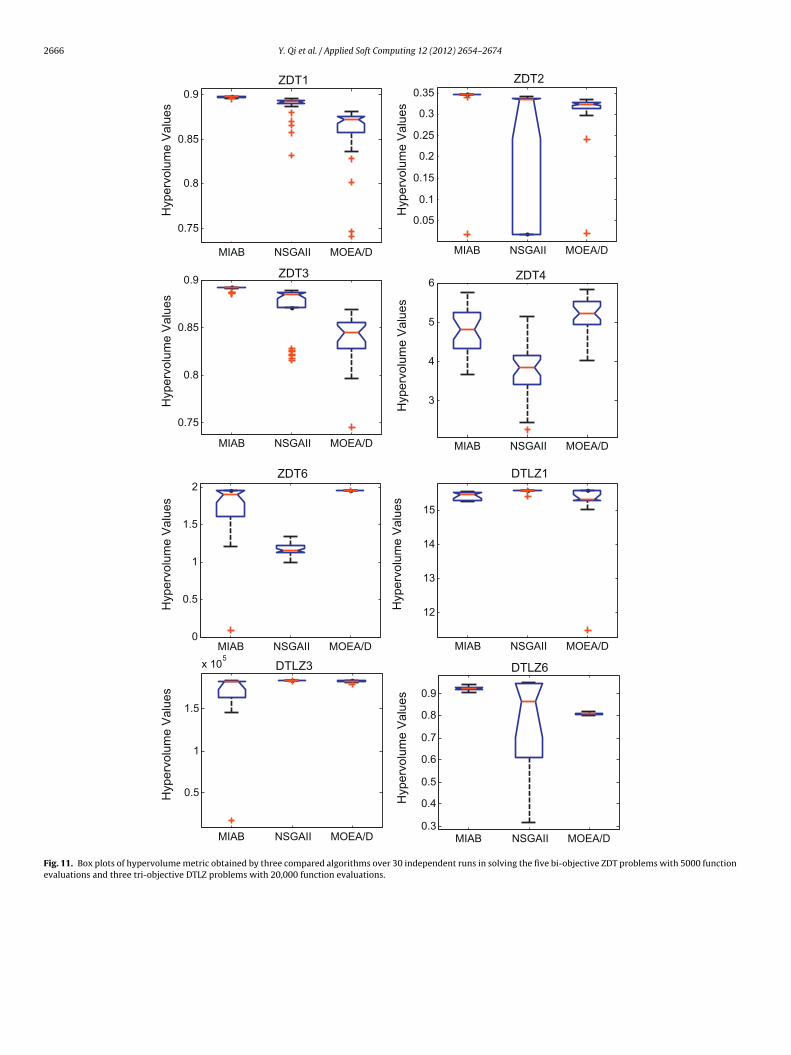
Fig. 11 shows the box plots of the hypervolume metric obtainedby the proposed MIAB and other two compared algorithms over30 independent runs in solving the five bi-objective ZDT problemswith 5000 function evaluations and three tri-objective DTLZ prob-lems with 20,000 function evaluations. According to the definitionof the hypervolume metric, the algorithm with higher hypervol-ume values performs better. From experimental results in Fig. 11,we can come to the similar conclusions as that from Fig. 9 which isbased on the IGD metric.
According to the experimental results in Figs. 7–11, we can cometo the conclusion that MIAB maintains better population diver-
sity than NSGAII. MIAB converges faster than NSGAII in solving allthe bi-objective and most tri-objective problems. Comparing withMOEA/D, MIAB converges faster in dealing with most of the bi-objective problems except for the non-convex and non-uniform
2664 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
MIAB NSGAII MOEA/D0
0.05
0.1
0.15
IGD
Valu
es
ZDT1
MIAB NSGAII MOEA/D
0
0.1
0.2
0.3
0.4
0.5
0.6
IGD
Valu
es
ZDT2
MIAB MOEA/D
0.004
0.006
0.008
0.01
0.012
0.014
0.016
0.018
0.02
0.022
0.024
MIAB NSGAII MOEA/D
0.01
0.02
0.03
0.04
0.05
0.06
0.07
IGD
Va
lue
s
ZDT3
MIAB NSGAII4.5
5
5.5
6
6.5
x 10-3
MIAB NSGAII MOEA/D
0
1
2
3
4
IGD
Va
lue
s
ZDT4
MIAB NSGAII MOEA/D
0
0.5
1
IGD
Va
lue
s
ZDT6
MIAB MOEA/D
2.4
2.6
2.8
3
3.2
3.4
x 10-3
MIAB NSGAII MOEA/D0
1
2
3
4
5
6
IGD
Va
lue
s
DTLZ1
MIAB NSGAII MOEA/D
20
40
60
80
IGD
Va
lue
s
DTLZ3
MIAB NSGAII MOEA/D
0.2
0.4
0.6
0.8
1
1.2
1.4
IGD
Va
lue
s
DTLZ6
Fig. 9. Box plots of IGD metric obtained by three compared algorithms over 30 independent runs in solving the five bi-objective ZDT problems with 5000 function evaluationsand three tri-objective DTLZ problems with 20,000 function evaluations.
Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2665
0 2000 4000 6000 8000 100000
200
400
600
800DTLZ3
Numberof Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
6000 8000 100000
50
0 2000 4000 600 0 800 0 1000 00
2
4
6
8
10DTLZ6
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
6000 8000 100000
0.2
0.4
0 2000 4000 6000 8000 1000 00
0.5
1
1.5
2
2.5ZDT1
Numberof Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
5000 100000
0.005
0.01
0 2000 4000 600 0 800 0 1000 00
1
2
3
4ZDT2
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
6000 8000 10000
0.01
0.02
0 2000 4000 6000 8000 1000 00
0.5
1
1.5
2ZDT3
Numberof Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
6000 8000 10000
0.005
0.01
0.015
0.02
0.025
0 2000 4000 600 0 800 0 1000 00
20
40
60
80ZDT4
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
4000 600 0 8000 100000
1
2
3
0 2000 4000 6000 8000 1000 00
2
4
6
8ZDT6
Numberof Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
8000 9000 100000
0.1
0.2
0 2000 4000 600 0 800 0 1000 00
20
40
60
80DTLZ1
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NSGAII
MOEA/D
5000 100000
5
Fig. 10. The evolution of the average IGD metric values of the non-dominated solutions in the current populations among 30 independent runs with 10,000 functionevaluations in three algorithms for five bi-objective ZDT problems and three tri-objective DTLZ problems.
2666 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
MIAB NSGAII MOEA/D
0.75
0.8
0.85
0.9
Hyp
erv
olu
me
Va
lue
s
ZDT1
MIAB NSGAII MOEA/D
0.05
0.1
0.15
0.2
0.25
0.3
0.35
Hyp
erv
olu
me
Va
lue
s
ZDT2
MIAB NSGAII MOEA/D
0.75
0.8
0.85
0.9
Hyp
erv
olu
me
Va
lue
s
ZDT3
MIAB NSGAII MOEA/D
3
4
5
6
Hyp
erv
olu
me
Va
lue
s
ZDT4
MIAB NSGAII MOEA/D0
0.5
1
1.5
2
Hyp
erv
olu
me
Va
lue
s
ZDT6
MIAB NSGAII MOEA/D
12
13
14
15
Hyp
erv
olu
me
Va
lue
s
DTLZ1
MIAB NSGAII MOEA/D
0.5
1
1.5
x 105
Hyp
erv
olu
me
Va
lue
s
DTLZ3
MIAB NSGAII MOEA/D0.3
0.4
0.5
0.6
0.7
0.8
0.9
Hyp
erv
olu
me
Va
lue
s
DTLZ6
Fig. 11. Box plots of hypervolume metric obtained by three compared algorithms over 30 independent runs in solving the five bi-objective ZDT problems with 5000 functionevaluations and three tri-objective DTLZ problems with 20,000 function evaluations.
Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2667
0 2000 4000 6000 8000 100000
0.5
1
1.5
2
2.5ZDT1
Number of F uncti on Eval uations
IGD
Va
lue
s
MIAB
NNIA
6000 8000 10000
0.02
0.04
0 2000 4000 6000 8000 100000
1
2
3
4ZDT2
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
7000 8000 9000 100000
0.05
0.1
0 2000 4000 6000 8000 100000
0.5
1
1.5
2ZDT3
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
6000 8000 10000
0.01
0.02
0 2000 4000 6000 8000 100000
20
40
60
80ZDT4
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
6000 8000 100000
1
2
0 2000 4000 6000 8000 100000
2
4
6
8ZDT6
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
0 2000 4000 6000 8000 100000
20
40
60
80DTLZ1
Numberof Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
6000 8000 100000
5
0 2000 4000 6000 8000 100000
200
400
600
800DTLZ3
Numberof Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
0 2000 4000 6000 8000 100000
2
4
6
8
10DTLZ6
Number of Function Evaluations
IGD
Va
lue
s
MIAB
NNIA
6000 8000 100000
0.2
0.4
Fig. 12. The evolution of the average IGD metric values of the non-dominated solutions in the current populations among 30 independent runs with 10,000 functionevaluations in MIAB and NNIA for five bi-objective ZDT problems and three tri-objective DTLZ problems.
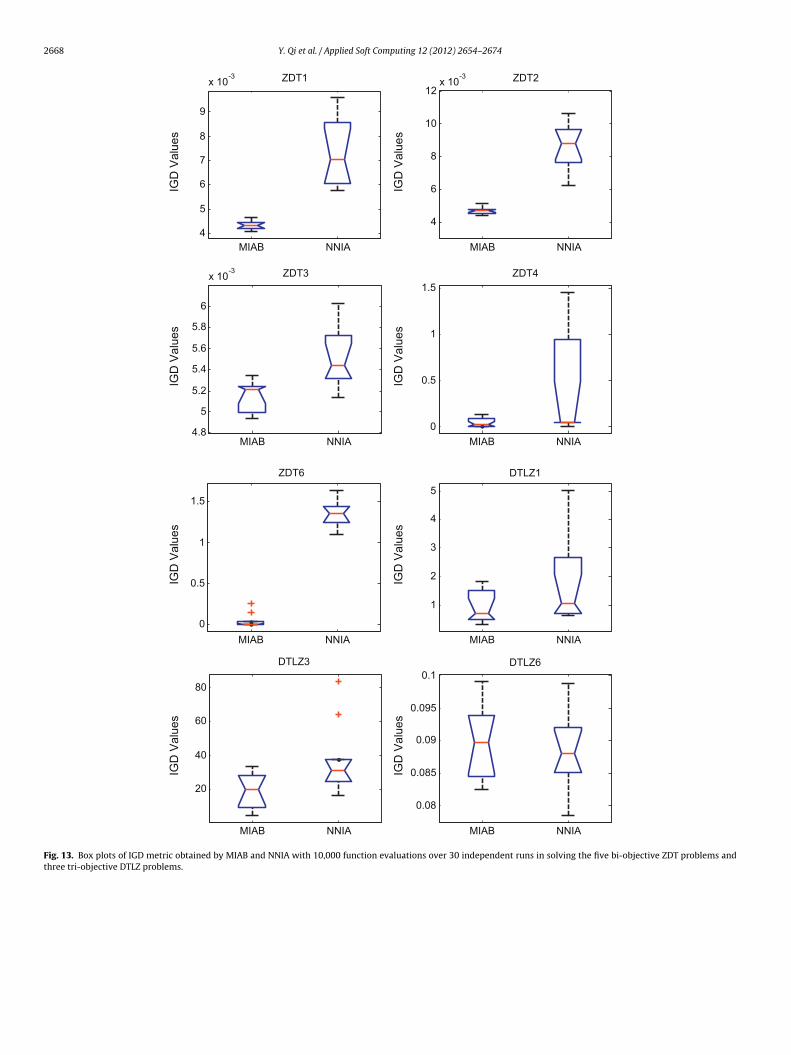
2668 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
MIAB NNIA
4
5
6
7
8
9
x 10-3
IGD
Va
lue
s
ZDT1
MIAB NNIA
4
6
8
10
12x 10
-3
IGD
Va
lue
s
ZDT2
MIAB NNIA4.8
5
5.2
5.4
5.6
5.8
6
x 10-3
IGD
Va
lue
s
ZDT3
MIAB NNIA
0
0.5
1
1.5
IGD
Va
lue
s
ZDT4
MIAB NNIA
0
0.5
1
1.5
IGD
Va
lue
s
ZDT6
MIAB NNIA
1
2
3
4
5
IGD
Va
lue
s
DTLZ1
MIAB NNIA
20
40
60
80
IGD
Va
lue
s
DTLZ3
MIAB NNIA
0.08
0.085
0.09
0.095
0.1
IGD
Va
lue
s
DTLZ6
Fig. 13. Box plots of IGD metric obtained by MIAB and NNIA with 10,000 function evaluations over 30 independent runs in solving the five bi-objective ZDT problems andthree tri-objective DTLZ problems.
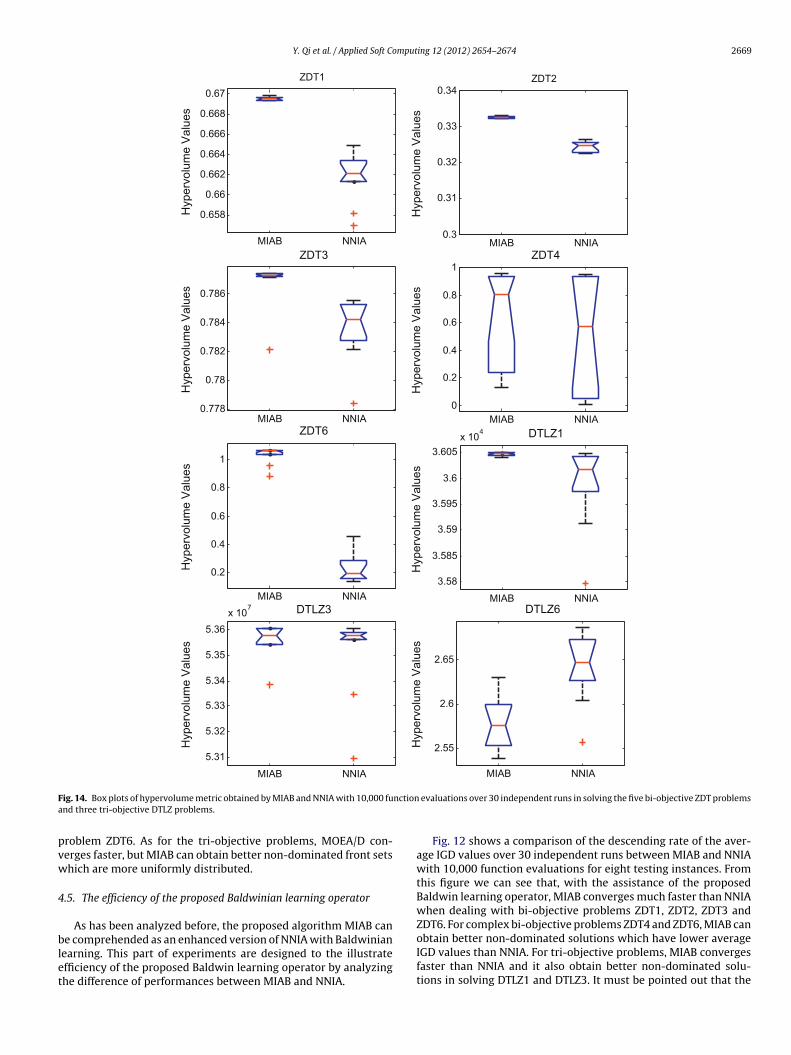
Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2669
MIAB NNIA
0.658
0.66
0.662
0.664
0.666
0.668
0.67
Hyp
erv
olu
me
Va
lue
s
ZDT1
MIAB NNIA0.3
0.31
0.32
0.33
0.34
Hyp
erv
olu
me
Va
lue
s
ZDT2
MIAB NNIA0.778
0.78
0.782
0.784
0.786
Hyp
erv
olu
me
Va
lue
s
ZDT3
MIAB NNIA
0
0.2
0.4
0.6
0.8
1
Hyp
erv
olu
me
Va
lue
s
ZDT4
MIAB NNIA
0.2
0.4
0.6
0.8
1
Hyp
erv
olu
me
Va
lue
s
ZDT6
MIAB NNIA
3.58
3.585
3.59
3.595
3.6
3.605
x 104
Hyp
erv
olu
me
Va
lue
s
DTLZ1
MIAB NNIA
5.31
5.32
5.33
5.34
5.35
5.36
x 107
Hyp
erv
olu
me
Va
lue
s
DTLZ3
MIAB NNIA
2.55
2.6
2.65
Hyp
erv
olu
me
Va
lue
s
DTLZ6
F nctiona
pvw
4
blet
ig. 14. Box plots of hypervolume metric obtained by MIAB and NNIA with 10,000 fund three tri-objective DTLZ problems.
roblem ZDT6. As for the tri-objective problems, MOEA/D con-erges faster, but MIAB can obtain better non-dominated front setshich are more uniformly distributed.
.5. The efficiency of the proposed Baldwinian learning operator
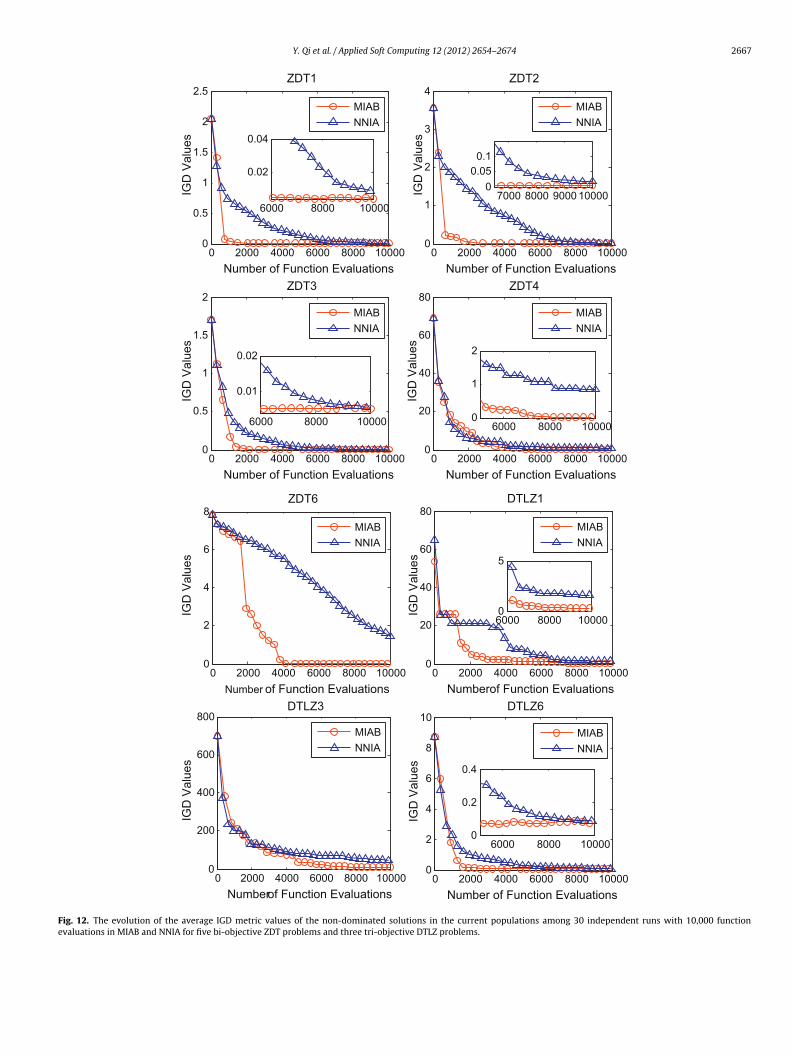
As has been analyzed before, the proposed algorithm MIAB can
e comprehended as an enhanced version of NNIA with Baldwinianearning. This part of experiments are designed to the illustratefficiency of the proposed Baldwin learning operator by analyzinghe difference of performances between MIAB and NNIA.
evaluations over 30 independent runs in solving the five bi-objective ZDT problems
Fig. 12 shows a comparison of the descending rate of the aver-age IGD values over 30 independent runs between MIAB and NNIAwith 10,000 function evaluations for eight testing instances. Fromthis figure we can see that, with the assistance of the proposedBaldwin learning operator, MIAB converges much faster than NNIAwhen dealing with bi-objective problems ZDT1, ZDT2, ZDT3 andZDT6. For complex bi-objective problems ZDT4 and ZDT6, MIAB can
obtain better non-dominated solutions which have lower averageIGD values than NNIA. For tri-objective problems, MIAB convergesfaster than NNIA and it also obtain better non-dominated solu-tions in solving DTLZ1 and DTLZ3. It must be pointed out that the
2670 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
0 ind
pa
NpFw
ot
Fig. 15. Box plots of IGD values versus the subpopulation number K over 3
roposed Baldwin learning operator also works when solving ZDT3nd DTLZ6 problems whose ideal Pareto sets are not connected.
Fig. 13 shows the box plots of IGD metric obtained by MIAB andNIA after 10,000 function evaluations. It can be seen that MIABerforms better than NNIA in solving seven of the eight problems.or the DTLZ6 problem with discontinuous PF, MIAB performs as
ell as NNIA.Fig. 14 illustrates the box plots of the hypervolume metricbtained by MIAB and NNIA after 10,000 function evaluations. Fromhese experimental results we can see that MIAB obtains higher
ependent runs of MIAB with the Baldwinian learning probability PBL = 0.2.
hypervolume values than NNIA in solving seven of the eight prob-lems except DTLZ6, which is consist with the experimental resultsshown in Fig. 13 based on the IGD metric.
From experimental results shown in Figs. 12–14, we candraw the conclusion that the proposed Baldwin learning operatorimproves the performance of NNIA in terms of both convergence
rate and solution quality. The main reason of this enhancementmay lies in that the hill climbing directions are utilized by theproposed Baldwin learning operator to accelerate the convergencespeed, which is absent in NNIA. It is well known that hill climbing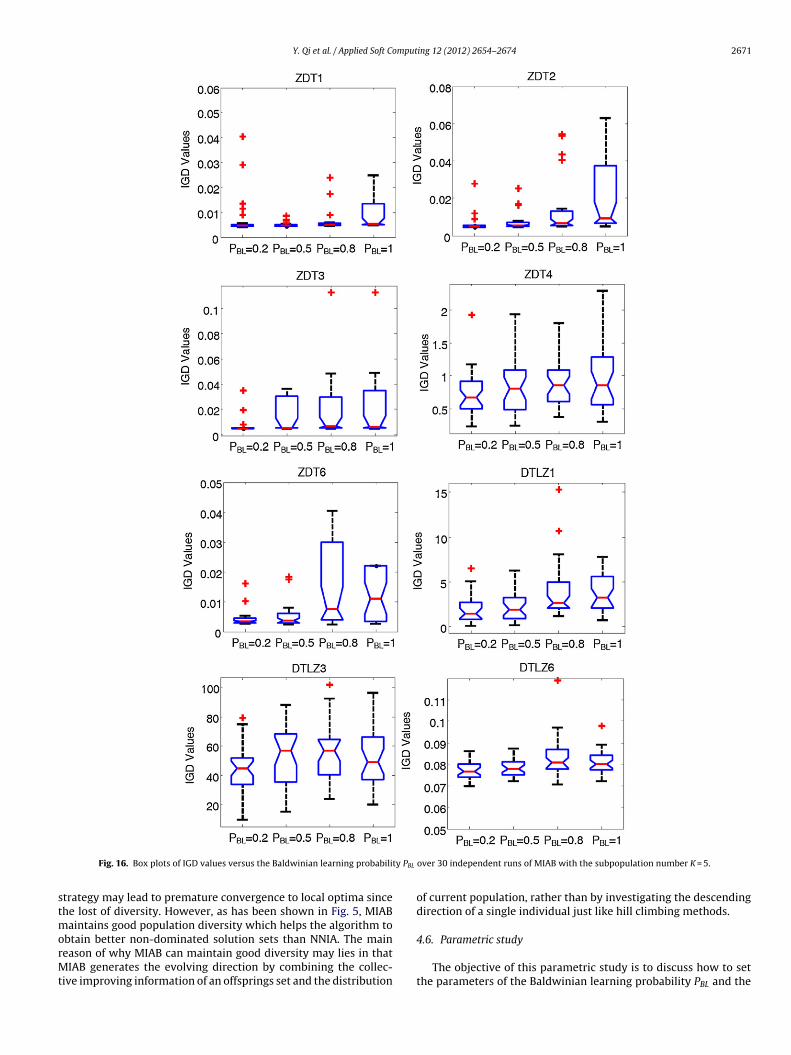
Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674 2671
ty PBL
stmorMt
Fig. 16. Box plots of IGD values versus the Baldwinian learning probabili
trategy may lead to premature convergence to local optima sincehe lost of diversity. However, as has been shown in Fig. 5, MIAB
aintains good population diversity which helps the algorithm to
btain better non-dominated solution sets than NNIA. The maineason of why MIAB can maintain good diversity may lies in thatIAB generates the evolving direction by combining the collec-ive improving information of an offsprings set and the distribution
over 30 independent runs of MIAB with the subpopulation number K = 5.
of current population, rather than by investigating the descendingdirection of a single individual just like hill climbing methods.
4.6. Parametric study
The objective of this parametric study is to discuss how to setthe parameters of the Baldwinian learning probability PBL and the
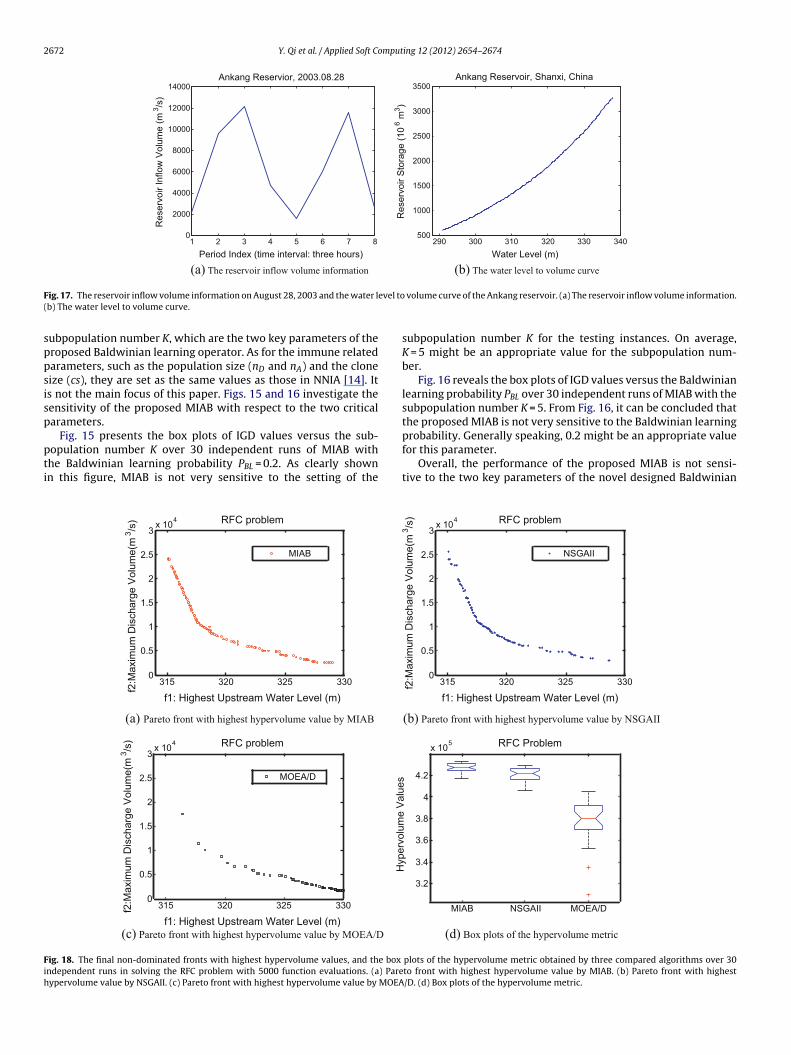
2672 Y. Qi et al. / Applied Soft Computing 12 (2012) 2654–2674
1 2 3 4 5 6 7 80
2000
4000
6000
8000
10000
12000
14000
Period Index (time interval: three hours)
Re
se
rvo
ir In
flo
w V
olu
me
(m
3/s
)
Ankang Reservior, 2003.08.28
290 300 310 320 330 340500
1000
1500
2000
2500
3000
3500
Water Level (m)
Re
se
rvo
ir S
tora
ge
(1
06
m3)
Ankang Reservoir, Shanxi, China
(a) The reservoir inflow volume information (b) The water level to volume curve
F evel to(
sppsisp
pti
Fih
ig. 17. The reservoir inflow volume information on August 28, 2003 and the water lb) The water level to volume curve.
ubpopulation number K, which are the two key parameters of theroposed Baldwinian learning operator. As for the immune relatedarameters, such as the population size (nD and nA) and the cloneize (cs), they are set as the same values as those in NNIA [14]. Its not the main focus of this paper. Figs. 15 and 16 investigate theensitivity of the proposed MIAB with respect to the two criticalarameters.
Fig. 15 presents the box plots of IGD values versus the sub-
opulation number K over 30 independent runs of MIAB withhe Baldwinian learning probability PBL = 0.2. As clearly shownn this figure, MIAB is not very sensitive to the setting of the315 320 325 3300
0.5
1
1.5
2
2.5
3x 10
4
f1: Highest Upstream Water Level (m)
f2:M
axim
um
Dis
ch
arg
e V
olu
me
(m3/s
) RFC problem
MIAB
(a) Pareto front with highest hypervolume value by MIAB
315 320 325 3300
0.5
1
1.5
2
2.5
3x 10
4
f1: Highest Upstream Water Level (m)
f2:M
axim
um
Dis
ch
arg
e V
olu
me
(m3/s
) RFC problem
MOEA/D
(c) Pareto front with highest hypervolume value by MOEA/D
ig. 18. The final non-dominated fronts with highest hypervolume values, and the box
ndependent runs in solving the RFC problem with 5000 function evaluations. (a) Pareypervolume value by NSGAII. (c) Pareto front with highest hypervolume value by MOEA
volume curve of the Ankang reservoir. (a) The reservoir inflow volume information.
subpopulation number K for the testing instances. On average,K = 5 might be an appropriate value for the subpopulation num-ber.
Fig. 16 reveals the box plots of IGD values versus the Baldwinianlearning probability PBL over 30 independent runs of MIAB with thesubpopulation number K = 5. From Fig. 16, it can be concluded thatthe proposed MIAB is not very sensitive to the Baldwinian learningprobability. Generally speaking, 0.2 might be an appropriate value
for this parameter.Overall, the performance of the proposed MIAB is not sensi-tive to the two key parameters of the novel designed Baldwinian
315 320 325 3300
0.5
1
1.5
2
2.5
3x 10
4
f1: Highest Upstream Water Level (m)
f2:M
axim
um
Dis
ch
arg
e V
olu
me
(m3/s
) RFC problem
NSGAII
(b) Pareto front with highest hypervolume value by NSGAII
MIAB NSGAII MOEA/D
3.2
3.4
3.6
3.8
4
4.2
x 105
Hyp
erv
olu
me
Va
lue
s
RFC Problem
(d) Box plots of the hypervolume metric
plots of the hypervolume metric obtained by three compared algorithms over 30to front with highest hypervolume value by MIAB. (b) Pareto front with highest/D. (d) Box plots of the hypervolume metric.

mput
la
4
iFtritLm
wwtumwov
taiv
tTdio
aTestuti
5
toctotae
oop
Y. Qi et al. / Applied Soft Co
earning operator. We should point out that the range of appropri-te subpopulation number in MIAB is still problem-dependent.
.7. Experimental results on real-world problem
In this part, a real world problem of flood control for reservoirs investigated to show the superiority of the proposed approach.lood disaster is one of the most damaging natural disasters, dueo its high frequency and enormous destruction strength, thuseservoir flood control (RFC) is an important problem worthy ofntensive research. RFC is a complex multi-objective optimiza-ion problem with constraints, and it can be modeled as follows.et Q = (Q1, Q2, . . . , QT ) be the decision variable vector, then theulti-objective optimization problem is:
min F(Q ) = (f1(Q ), f2(Q ))f1(Q ) = min{max(Zt)}f2(Q ) = min{max(Qt)}subject to : Zmin ≤ Zt ≤ Zmax
0 ≤ Qt ≤ Qmax
Vt = Vt−1 + It − Qt
t = 1, 2, . . . , T
(17)
here T is the total number of scheduling periods, Zt is the upstreamater level of the t-th period, Qt is the discharge volume of the t-
h period. Zmin and Zmax are the minimum and maximum limit ofpstream water level of the t-th period respectively. Qmax is theaximal discharge volume of all periods. Vt = Vt−1 + It − Qt is theater balance equation, in which Vt and Vt−1 the reservoir storages
f the t-th and the (t − 1)-th period, and It is the reservoir inflowolume of the t-th period.
In this paper, we use discharge volume as the decision variableo encode the individuals. Every individual vector can be expresseds a series of discharge volumes during T scheduling periods, thats Q = (Q1, Q2, . . . , QT ) where Qt(t = 1, 2, . . . , T) is the dischargeolume of the individual in the t-th period.
The three compared algorithms are applied to deal with theypical flood of the Ankang reservoir in Shanxi province of China.he parameter setups of the compared algorithms are the same asescribed in Section 4.3. Fig. 17 shows the reservoir inflow volume
nformation on August 28, 2003 and the water level to volume curvef the Ankang reservoir.
Fig. 18 illustrates the experimental results of the three comparedlgorithms in solving the RFC problem over 30 independent runs.he three compared algorithms stop when the numbers of functionvaluations exceed the threshold of 5000. From this figure, it can beeen that the proposed MIAB obtains a better Pareto optimal solu-ion set than NSGAII and MOEA/D in terms of both convergence andniformity. The box plots of the hypervolume metric also indicatehat MIAB performs better than the other two compared algorithmn solving the real world reservoir flood control problem.
. Conclusions and future work
How to reproduce new generations with better quality thanheir parents is the central driver to the population evolutionf MOEAs. However, in most of current MOEAs, the traditionalrossover and mutation operator which perform random search inhe decision space and were originally developed for scalar objectptimization problems are directly employed. Without the heuris-ic information of MOPs, the searching procedures of most MOEAsppear to be of excessive randomness which prevents them fromfficient evolution.
In this paper, a Baldwinian learning strategy is designed basedn the regularity property of continuous MOPs and a multi-bjective immune algorithm with Baldwinian learning (MIAB) isroposed under the framework of NNIA for continuous MOPs with
[
ing 12 (2012) 2654–2674 2673
variable linkages. MIAB consider the Pareto set as a whole ratherthan a set of independent individuals. The Baldwinian learningoperator builds a piecewise linear probability model for model-ing current found PS manifold, and produce a new generation bychanging the operated antibody along the descent direction whichis a combination of the evolving history of the parent individ-ual and the environment information provided by the probabilitymodel. Experimental results have indicated that with the help ofthe proposed Baldwin learning operator MIAB outperforms NNIAin terms of both convergence rate and solution quality. Comparingwith the outstanding evolutionary multi-objective optimizationalgorithm NSGAII, MIAB can maintain better population diversityand converge faster in solving all the bi-objective and most tri-objective problems among eight testing problems. Comparing withthe decomposition based evolutionary multi-objective optimiza-tion algorithm MOEA/D, MIAB converges faster in solving most ofthe bi-objective problems and obtains better non-dominated frontsets which are more uniformly distributed. Experimental resultson the real world reservoir flood control problem also illustrate thesuperiority of the proposed algorithm. Overall, MIAB makes a goodbalance between diversity and convergence.
The future research topics may focus on the following: (1)Develop a simple method with lower computing complexity todescribe the distribution of current PS, for example, the interpo-lation approximation methods. (2) Use of information about theevolving environment for finding better searching directions. (3)Extension of the proposed MIAB to constrained and dynamic MOPs.
Acknowledgments
This work was supported by the National Research Founda-tion for the Doctoral Program of Higher Education of China underGrant Nos. 20090203120016 and 20100203120008, the China Post-doctoral Science Foundation Special funded project under GrantNos. 20090461283, 20090451369, 200801426, 20080431228 and201104658, the Provincial Natural Science Foundation of Shaanxi ofChina under Grant Nos. 2011JQ8010 and 2009JQ8015, the NationalNatural Science Foundation of China under Grant Nos. 61072139and 61001202, and the Fundamental Research Funds for the CentralUniversities under Grant No. JY10000903007.
References
[1] K. Deb, Multi-Objective Optimization Using Evolutionary Algorithms, Wiley,New York, 2001.
[2] J.D. Schaffer, Multiple objective optimization with vector evaluated geneticalgorithms, in: Proceedings of the First International Conference on GeneticAlgorithms, 1985, pp. 93–100.
[3] C.A. Coello Coello, Evolutionary multi-objective optimization: a historical viewof the field, IEEE Computational Intelligence Magazine 1 (1) (2006) 28–36.
[4] F.M. Carlos, J.F. Peter, Genetic algorithms for multi-objective optimization:formulation, discussion and generalization, in: Proceedings of the Fifth Inter-national Conference on Genetic Algorithms, San Mateo, CA, 1993, pp. 416–423.
[5] H. Jeffrey, N. Nicholas, E.G. David, A niched Pareto genetic algorithm formulti-objective optimization, in: Proceedings of the First IEEE Conference onEvolutionary Computation, IEEE World Congress on Computational Intelli-gence, vol. 1, Piscataway, NJ, June, 1994, pp. 82–87.
[6] N. Srinivas, K. Deb, Multi-objective optimization using nondominated sortingin genetic algorithms, Evolutionary Computation 1 (1994) 221–248.
[7] E. Zitzler, L. Thiele, Multi-objective evolutionary algorithms: a comparative casestudy and the strength Pareto approach, IEEE Transactions on EvolutionaryComputation 3 (4) (1999) 257–271.
[8] E. Zitzler, M., Laumanns, L., Thiele, SPEA2. Improving the strength Pareto evo-lutionary algorithm for multi-objective optimization, Evolutionary Methodsfor Design, Optimisation and Control with Application to Industrial Problems,Athens, Greece, 2002, pp. 95–100.
[9] J.D. Knowles, D.W. Corne, Approximating the nondominated front using the
Pareto archived evolution strategy, Evolutionary Computation 8 (2) (2000)149–172.10] D.W. Corne, J.D. Knowles, M.J. Oates, The Pareto envelope-based selection algo-rithm for multi-objective optimization, in: Proceedings of the Parallel ProblemSolving from Nature VI Conference, 2000, pp. 839–848.

2 omput
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
[
674 Y. Qi et al. / Applied Soft C
11] D.W. Corne, N.R. Jerram, J.D. Knowles, M.J. Oates, Region-based selection inevolutionary multiobjective optimization: PESA-II, in: Proceedings of Geneticand Evolutionary Computation, Morgan Kaufmann, San Mateo, CA, 2001, pp.283–290.
12] K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multi-objectivegenetic algorithm: NSGA-II, IEEE Transactions on Evolutionary Computation 6(2002) 182–197.
13] Q.F. Zhang, H. Li, A multi-objective evolutionary algorithm based on decom-position: MOEA/D, IEEE Transactions on Evolutionary Computation 11 (2007)712–731.
14] M.G. Gong, L.C. Jiao, H.F. Du, L.F. Bo, Multi-objective immune algorithm withnondominated neighbor-based selection: NNIA, Evolutionary Computation 16(2008) 225–255.
15] D.D. Yang, L.C. Jiao, M.G. Gong, J. Feng, Adaptive ranks and K-nearest neighbourlist based multiobjective immune algorithm, Computational Intelligence 26(2010) 359–385.
16] K. Miettinen, Nonlinear multiobjective optimization, in: Kluwer’s InternationalSeries in Operations Research & Management Science, vol. 12, Norwell, 1999.
17] M. Ehrgott, Multicriteria Optimization, Lecture Notes in Economics and Math-ematical Systems, vol. 491, New York, 2005.
18] O. Schütze, S. Mostaghim, M. Dellnitz, J. Teich, Covering Pareto sets by multi-level evolutionary subdivision techniques, in: Proceedings of the secondInternational Conference on Evolutionary Multi-Criterion Optimization, vol.2632, Faro, Portugal, 2003, pp. 118–132.
19] Y.C. Jin, B. Sendhoff, Connectedness, regularity and the success of local search inevolutionary multi-objective optimization, in: Congress on Evolutionary Com-putation, 2003, pp. 1910–1917.
20] A.M. Zhou, Q.F. Zhang, Y.C. Jin, E. Tsang, T. Okabe, A model-based evolution-ary algorithm for bi-objective optimization, in: Proceedings of Congress onEvolutionary Computation, Edinburgh, UK, 2005, pp. 2568–2575.
21] A.M. Zhou, Y.C. Jin, Q.F. Zhang, B. Sendhoff, E. Tsang, Combining model-basedand genetics-based offspring generation for multi-objective optimization usinga convergence criterion, in: Proceedings of Congress on Evolutionary Compu-tation (CEC 2006), Vancouver, BC, Canada, 2006, pp. 3234–3241.
22] Q.F. Zhang, A.M. Zhou, Y.C. Jin, A regularity model-based multiobjective estima-tion of distribution algorithm: RM-MEDA, IEEE Transactions on EvolutionaryComputation 12 (2008) 41–63.
23] A.M. Zhou, Q.F. Zhang, Y.C. Jin, Approximating the set of Pareto-optimalsolutions in both the decision and objective spaces by an estimation of dis-tribution algorithm, IEEE Transactions on Evolutionary Computation 13 (2009)1167–1189.
24] J.M. Baldwin, A new factor in evolution, The American Naturalist 30 (1896)441–451.
25] W.E. Hart, N. Krasnogor, J.E. Smith, Recent Advances in Memetic Algorithms,in: chapter Memetic Evolutionary Algorithms, Springer, 2004, pp. 3–30.
26] D. Whitley, V.S. Gordon, K. Mathias, Lamarckian evolution, the Baldwin effectand function optimization, in: Proceedings of Parallel Problem Solving fromNature, Springer-Verlag, 1994, pp. 6–15.
27] G.E. Hinton, S.J. Nowlan, How learning can guide evolution, Complex Systems1 (1987) 495–502.
28] J.A. Bullinaria, Exploring the Baldwin effect in evolving adaptable control sys-tems, in: R.F. French, J.P. Sougne (Eds.), Connectionist Models of Learning,Development and Evolution, Springer, London, 2001, pp. 231–242.
[
ing 12 (2012) 2654–2674
29] J. Huang, H. Wechsler, Visual routines for eye location using learning and evo-lution, IEEE Transactions on Evolutionary Computation 4 (2000) 73–82.
30] D.H. Ackley, M.L. Littman, Interactions between learning and evolution, in: C.G.Langton, C. Taylor, J.D. Farmer, S. Rasmussen (Eds.), Artificial Life 2, Addison-Wesley, Redwood City, CA, 1992, pp. 487–509.
31] M.G. Gong, L.C. Jiao, L.N. Zhang, Baldwinian learning in clonal selection algo-rithm for optimization, Information Sciences 180 (2010) 1218–1236.
32] A. Lara, G. Sanchez, C.A. Coello Coello, O. Schütze, A new local search strategyfor memetic multiobjective evolutionary algorithms: HCS, IEEE Transactionson Evolutionary Computation 14 (2010) 112–132.
33] L.D. Castro, J. Timmis, Artificial Immune Systems: A New Computational Intel-ligence Approach, Springer, Germany, Heidelberg, 2002.
34] J. Yoo, P. Hajela, Immune network simulations in multicriterion design, Struc-tural Optimization 18 (1999) 85–94.
35] C.A. Coello Coello, N.C. Cortes, An approach to solve multiobjective optimizationproblems based on an artificial immune system, in: Proceedings of the FirstInternational Conference on Artificial Immune Systems, University of Kent atCanterbury, UK, 2002, pp. 212–221.
36] C.A. Coello Coello, N.C. Cortes, Solving multiobjective optimization prob-lems using an artificial immune system, Genetic Programming and EvolvableMachines 6 (2005) 163–190.
37] G.C. Luh, C.H. Chueh, W.W. Liu, Multi-objective immune algorithm: MOIA, Engi-neering Optimization 35 (2003) 143–164.
38] F. Freschi, M. Repetto, Multiobjective optimization by a modified artificialimmune system algorithm, in: Proceedings of the Fourth International Con-ference on Artificial Immune Systems, vol. 3627, 2005, pp. 248–261.
39] V. Cutello, G. Narzisi, G. Nicosia, A class of Pareto archived evolution strat-egy algorithms using immune inspired operators for ab-initio protein structureprediction, in: Applications of Evolutionary Computing, Lecture Notes in Com-puter Science, vol. 3449, Lausanne, Switzerland, March 30–April 1, 2005, pp.54–63.
40] L.C. Jiao, M.G. Gong, R.H. Shang, H.F. Du, B. Lu, Clonal selection with immunedominance and anergy based multi-objective optimization, in: Proceedings ofThird International Conference, Lecture Notes in Computer Science vol. 3410,Guanajuato, México, March, 2005, pp. 474–489.
41] D.D. Yang, L.C. Jiao, M.G. Gong, Adaptive multi-objective optimization based onnondominated solutions, Computational Intelligence 25 (2009) 84–108.
42] F.M. Burnet, The Clonal Selection Theory of Acquired Immunity, CambridgeUniversity Press, Cambridge, UK, 1959.
43] L.N.D. Castro, F.J.V. Zuben, Learning and optimization using the clonal selectionprinciple, IEEE Transactions on Evolutionary Computation 6 (2002) 239–251.
44] K. Deb, H.G. Beyer, Self-adaptive genetic algorithms with simulated binarycrossover, Evolutionary Computation 9 (2001) 197–221.
45] K. Deb, L. Thiele, M. Laumanns, E. Zitzler, Scalable multi-objective optimizationtest problems, in: Proceedings of Congress on Evolutionary Computation, 2002,pp. 825–830.
46] E. Zitzler, Evolutionary algorithms for multiobjective optimisation: methodsand applications, PhD thesis, Swiss Federal Institute of Technology (ETH),
Zurich, Switzerland, 1999.47] A.M. Zhou, Y.C. Jin, Q.F. Zhang, B. Sendhoff, E. Tsang, Combining model-basedand genetics-based offspring generation for multi-objective optimization usinga convergence criterion, in: Proceedings of Congress on Evolutionary Compu-tation, 2001, pp. 3234–3241.
Related Documents











