MODELS OF PROTEIN EVOLUTION: AN INTRODUCTION TO AMINO ACID EXCHANGE MATRICES Robert Hirt Institute for Cell and Molecular Biosciences, Newcastle University, UK

MODELS OF PROTEIN EVOLUTION: AN INTRODUCTION TO AMINO ACID EXCHANGE MATRICES Robert Hirt Institute for Cell and Molecular Biosciences, Newcastle University,
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

MODELS OF PROTEIN EVOLUTION:
AN INTRODUCTION TO AMINO ACID EXCHANGE MATRICES
Robert HirtInstitute for Cell and Molecular Biosciences,
Newcastle University, UK

Inferring trees is difficult!!!
1. The method problem
Dataset 1
A
B
C
B
C
A
Dataset 1
Method 1
Method 2
?

Dataset 1
A
B
C
B
C
A
2. The dataset problem2. The dataset problem
Dataset 2
Method 1
Method 1?
Inferring trees is difficult!!!

From DNA/protein sequences to trees
Modified from Hillis et al., (1993). Methods in Enzymology 224, 456-487
1
2
3
4
5
Align Sequences
Phylogenetic signal?Patterns—>evolutionary processes?
Test phylogenetic reliability
Distances methods
Choose a method
MB ML
Characters based methods
Single treeOptimality criterion
Calculate or estimate best fit tree
LS ME NJ
Distance calculation(which model?)
Model?
MPWheighting?
(sites, changes)?Model?
Sequence data
**
*
*

Agenda
• Some general considerations– Why protein phylogenetics?
– What are we comparing? Protein sequences - some basic features
– Protein structure/function and its impact on patterns of mutations
• Amino acid exchange matrices: where do they come from and when do we use them?– Database searches (e.g. Blast, FASTA)
– Sequence alignment (e.g. ClustalX)
– Phylogenetics (model based methods: distance, ML & Bayesian)

Why protein phylogenies?Why protein phylogenies?
• For historical reasons - the first sequencesFor historical reasons - the first sequences• Most genes encode proteinsMost genes encode proteins• To study protein structure, function and evolutionTo study protein structure, function and evolution• Comparing DNA and protein based phylogenies can Comparing DNA and protein based phylogenies can
be useful be useful – Different genes - e.g. 18S rRNA versus EF-2 proteinDifferent genes - e.g. 18S rRNA versus EF-2 protein– Protein encoding gene - codons versus amino acidsProtein encoding gene - codons versus amino acids

Proteins were the first molecular sequences to be used for phylogenetic
inference
• Fitch and Margoliash (1967).
Construction of phylogenetic trees.
Science 155, 279-284.

Phylogenies from proteins
• Parsimony• Distance matrices• Maximum likelihood• Bayesian methods

Evolutionary models for amino acid changes
• All methods have explicit or implicit evolutionary models
• Can be in the form of simple formula– Kimura formula to estimate distances
• Most models for amino acid changes typically include – A 20x20 rate matrix (or reduced version of it, 6x6 rate matrix)– Correction for rate heterogeneity among sites (pinv)– Assume stationarity and neutrality - what if there are biases in
composition, or non neutral changes such as selection?

Character states in DNA and protein alignments
• DNA sequences have four states (five): A, C, G, T, (and ± indels)
•Proteins have 20 states (21): A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y (and ± indels)
—> more information in DNA or protein alignments?

DNA->Protein: the code
• 3 nucleotides (a codon) code for one amino acid
(61 codons! 61x61 rate matrices?)
• Degeneracy of the code: most amino acids are
coded by several codons
—> more data/information in DNA?

DNA—>Protein
• The code is degenerate:
20 amino acids are encoded by 61 possible codons (3 stop codons)
• Complex patterns of changes among codons:
– Synonymous/non synonymous changes
– Synonymous changes correspond to codon changes not affecting the coded amino acid

Codon degeneracy: protein alignments as a guide for DNA alignments
GAA-GGA-AGC-TCC-TGG-TTA-CTC-CTG-GGA-TCC
GAG-GGT-TCC-AGC-TAT-CTA-TTA-ATT-GGT-AGC
GAC-GGC-AGT-GCA-TGG-TTG-CTT-TTG-GGC-AGT
GAT-GGG-TCA-GCT-TAC-CTC-CTG-GCC-GGG-TCA
GluGlu--GlyGly--SerSer--SerSer--TrpTrp--LeuLeu--LeuLeu--LeuLeu--GlyGly--SerSer
GluGlu--GlyGly--SerSer--SerSer--TyrTyr--LeuLeu--LeuLeu--IleIle--GlyGly--SerSer
AspAsp--GlyGly--SerSer--AlaAla--TrpTrp--LeuLeu--LeuLeu--LeuLeu--GlyGly--SerSer
AspAsp--GlyGly--SerSer--AlaAla--TyrTyr--LeuLeu--LeuLeu--AlaAla--GlyGly--SerSer

DNA->Protein: code usage
• Difference in codon usage can lead to large base
composition bias - in which case one often needs to
remove the 3rd codon, the more bias prone site…
and possibly the 1st
• Comparing protein sequences can reduce the
compositional bias problem
—> more information in DNA or protein?

Models for DNA and Protein evolution
• DNA: 4 x 4 rate matrices– “Easy” to estimate (can be combined with tree search)
• Protein: 20 x 20 matrices– More complex: time and estimation problems (rare changes?) ->
• Empirical models from large datasets are typically used
• One can correct for amino acid frequencies for a given dataset

Proteins and their amino acids
• Proteins determine shape and structure of cells and carry
most catalytic processes - 3D structure
• Proteins are polymers of 20 different amino acids
• Amino acids sequence composition determines the structure
(2ndary, 3ary…) and function of the protein
• Amino acids can be categorized by their side chain
physicochemical properties– Size (small versus large)
– Polarity (hydrophobic versus hydrophilic, +/- charges)

D
R


Amino acid physico-chemical properties
– Major factor in protein folding
– Key to protein functions
——> Major influence in pattern > Major influence in pattern
of amino acid mutationsof amino acid mutationsAs for Ts versus Tv in DNA sequences, some amino acid changes are more common than others: fundamental for sequence comparisons (alignments and phylogenetics!)Small <—> small > small <—> big

Estimation of relative rates of residue replacement (models of evolution)
• Differences/changes in protein alignments can be pooled and patterns of
changes investigate.
• Patterns of changes give insights into the evolutionary processes
underlying protein diversification -> estimation of evolutionary models
• Choice of protein evolutionary models can be important for the sequence
analysis we perform (database searching, sequence alignment, phylogenetics)

Amino acid substitution matrices based on observed substitutions: “empirical models”
• Summarise the substitution pattern from large amount of existing data (‘average’ models)
• Based on a selection of proteins – Globular proteins, membrane proteins?
– Mitochondrial proteins?
• Uses a given counting method and set of recorded changes– tree dependent/independent
– restriction on the sequence divergence

Amino acid physico-chemical properties
– Size
– Polarity• Charges (acidic/basic)
• Hydrophilic (polar)
• Hydrophobic (non polar)


P
AG
CS-H
CS-SS N
Q
Y
WF
M
I VL
T
Small
Hydrophobic
PolarAliphatic
Tiny
Aromatic
Charged
Taylor’s Venn diagram of amino acids properties
K
RH+
D -E
Taylor (1986). J Theor. Biol. 119: 205-218
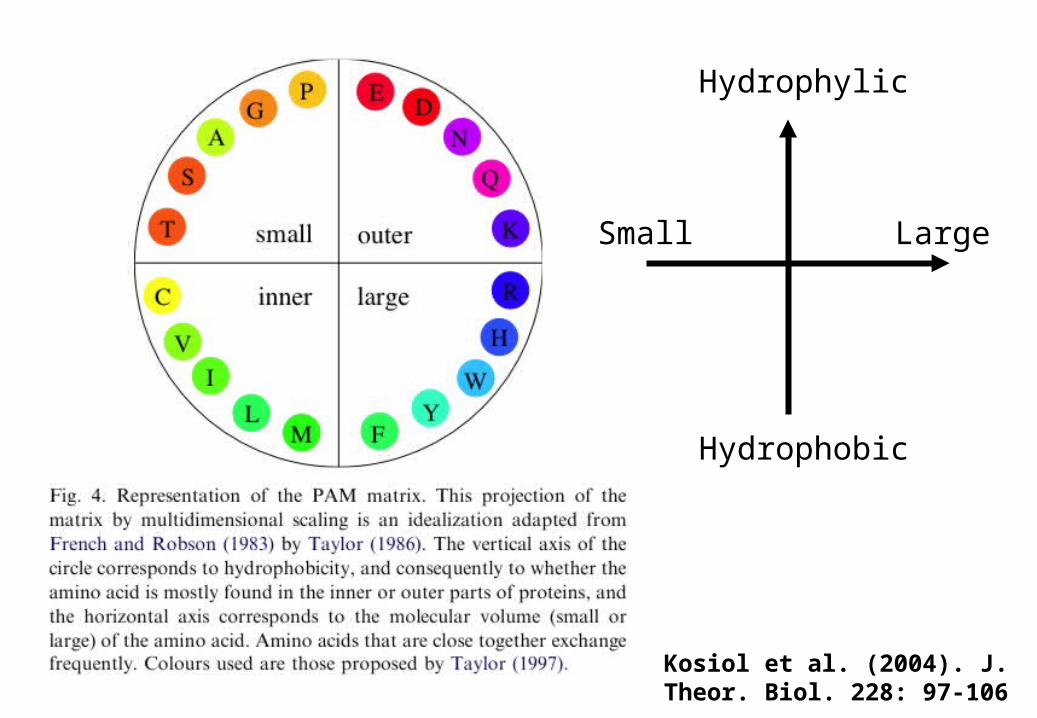
Kosiol et al. (2004). J. Theor. Biol. 228: 97-106
Hydrophobic
Hydrophylic
Small Large

Amino acids categories 1:Doolittle (1985). Sci. Am. 253, 74-85.
–Small polar: S, G, D, N
–Small non-polar: T, A, P, C
–Large polar: E, Q, K, R
–Large non-polar: V, I, L, M, F
–Intermediate polarity: W, Y, H

Amino acids categories 2(PAM matrix)
–Sulfhydryl: C–Small hydrophilic: S, T, A, P, G–Acid, amide: D, E, N, Q–Basic: H, R, K –Small hydrophobic : M, I, L, V–Aromatic: F, Y, W

Amino acids categories 3(implemented in SEAVIEW colour coding)
– Tiny 1, non-polar: C– Tiny 2, non-polar: G– Imino acid: P– Non-polar: M, V, L, I, A, F, W– Acid: D, E– Basic: R, K – Aromatic: Y, H– Uncharged polar: S, T, Q, N

Amino acids categories
Changes within a category are more common then between them• Colour coding of alignments to help visualise their
quality (ClustalX, SEAVIEW)• Differential weighting of cost matrices in parsimony
analyses• Mutational data matrices in model based methods (e.g.
ML and Bayesian framework)• Recoding of the 20 amino acids into bins to focus on
changes between bins (categories) (6x6 matrix)

——> Colour coding of different categories is useful for protein > Colour coding of different categories is useful for protein alignment visual inspectionalignment visual inspection

Phylogenetic trees from protein alignments
• Parsimony based methods - unweighted/weighted
• Distance methods - model for distance estimation
– probability of amino acid changes, site rate heterogeneity
• Maximum likelihood and Bayesian methods- model for ML
calculations
– probability of amino acid changes, site rate heterogeneity

Trees from protein alignment:Parsimony methods - cost matrices• All changes weighted equally
• Differential weighting of changes: an attempt to correct for homoplasy!:– Based on the minimal number of amino acid substitutions, the genetic
code matrix (PHYLIP-PROTPARS)
– Weights based on physico-chemical properties of amino acids
– Weights based on observed frequency of amino acid substitutions in alignments

Parsimony: unweighted matrix for amino acid changes
–Ile -> Leu cost = 1
–Trp -> Asp cost = 1
–Ser -> Arg cost = 1
–Lys -> Asp cost = 1

Parsimony: weighted matrix for amino acid changes, the genetic code matrix
–Ile -> Leu cost = 1
–Trp -> Asn cost = 3
–Ser -> Arg cost = 2
–Lys -> Asp cost = 2

Weighting matrix based on minimal amino acid changes PROTPARS inPHYLIP
A C D E F G H I K L M N P Q R 1 2 T V W Y[A] 0 2 1 1 2 1 2 2 2 2 2 2 1 2 2 1 2 1 1 2 2[C] 2 0 2 2 1 1 2 2 2 2 2 2 2 2 1 1 1 2 2 1 1[D] 1 2 0 1 2 1 1 2 2 2 2 1 2 2 2 2 2 2 1 2 1[E] 1 2 1 0 2 1 2 2 1 2 2 2 2 1 2 2 2 2 1 2 2[F] 2 1 2 2 0 2 2 1 2 1 2 2 2 2 2 1 2 2 1 2 1[G] 1 1 1 1 2 0 2 2 2 2 2 2 2 2 1 2 1 2 1 1 2[H] 2 2 1 2 2 2 0 2 2 1 2 1 1 1 1 2 2 2 2 2 1[I] 2 2 2 2 1 2 2 0 1 1 1 1 2 2 1 2 1 1 1 2 2[K] 2 2 2 1 2 2 2 1 0 2 1 1 2 1 1 2 2 1 2 2 2[L] 2 2 2 2 1 2 1 1 2 0 1 2 1 1 1 1 2 2 1 1 2[M] 2 2 2 2 2 2 2 1 1 1 0 2 2 2 1 2 2 1 1 2 3[N] 2 2 1 2 2 2 1 1 1 2 2 0 2 2 2 2 1 1 2 3 1[P] 1 2 2 2 2 2 1 2 2 1 2 2 0 1 1 1 2 1 2 2 2[Q] 2 2 2 1 2 2 1 2 1 1 2 2 1 0 1 2 2 2 2 2 2[R] 2 1 2 2 2 1 1 1 1 1 1 2 1 1 0 2 1 1 2 1 2[1] 1 1 2 2 1 2 2 2 2 1 2 2 1 2 2 0 2 1 2 1 1[2] 2 1 2 2 2 1 2 1 2 2 2 1 2 2 1 2 0 1 2 2 2[T] 1 2 2 2 2 2 2 1 1 2 1 1 1 2 1 1 1 0 2 2 2[V] 1 2 1 1 1 1 2 1 2 1 1 2 2 2 2 2 2 2 0 2 2 [W] 2 1 2 2 2 1 2 2 2 1 2 3 2 2 1 1 2 2 2 0 2 [Y] 2 1 1 2 1 2 1 2 2 2 3 1 2 2 2 1 2 2 2 2 0
W: TGG |||N: AAC AAT
A minimum of 3 changes are needed at the DNA levelfor W<->N

Phylogenetic trees from protein alignments
• Parsimony based methods - unweighted/weighted
• Distance methods - model for distance estimation
– probability of amino acid changes, site rate heterogeneity
• Maximum likelihood and Bayesian methods- model for ML
calculations
– probability of amino acid changes, site rate heterogeneity

A two step approach - two choices!
1) Estimate all pairwise distancesChoose a method (100s) - has an explicit model for sequence
evolution
2) Estimate a tree from the distance matrixChoose a method: with or without an optimality criterion?
Distance methods

Estimation of protein pairwise distances
1. Simple formula2. More complex models
• 20 x 20 matrices (evolutionary model):– Identity matrix– Genetic code matrix– Mutational data matrices (MDMs)
• Correction for rate heterogeneity between sites (pInv)

The Kimura formula: correction for multiple hits
dij = -Ln (1 - Dij - (Dij2/5))
- Dij the observed dissimilarity between i and j (0-1).
- Can give good estimate of dij for 0.75 > Dij > 0
- It can approximates the PAM matrix well
- If Dij ≥ 0.8541, dij = infinite.
- Implemented in ClustalX1.83 and PHYLIP3.62
- Does not take into account which amino acid are changing
-> Importance of mutational matrices, MDM!

Amino acid substitution matrices (MDMs)
• Sequence alignments based matrices
PAM, JTT, BLOSUM, WAG...
• Structure alignments based matrices
STR (for highly divergent sequences)

Protein distance measurements with MDM
20 x 20 matrices:• PAM, BLOSUM, WAG…matrices• Maximum likelihood calculation which
takes into account:– All sites in the alignment
– All pairwise rates in the matrix
– Branch length
dij = ML [P(), Xij, (pinv)] (dodgy notation!)
dij = -Ln (1 - Dij - (Dij2/5))= F(Dij)

How is an MDM inferred?
Observed raw changes are corrected for:Observed raw changes are corrected for:- The amino acid relative mutabilityThe amino acid relative mutability- The amino acid normalised frequencyThe amino acid normalised frequency
Differences between MDM come from:Differences between MDM come from:- Choice of proteins used Choice of proteins used (membrane, globular)(membrane, globular) - Range of sequence similarities usedRange of sequence similarities used- Counting methodsCounting methods
- On a tree [MP, ML]On a tree [MP, ML]- Pairwise comparison from an alignmentPairwise comparison from an alignment
-> empirical models from large datasets are typically used

How is an MDM inferred?
seq.1 AIDESLIIASIATATI |*||*||*||*||*||seq.2 AGDEALILASAATSTI
The raw data: observed changes in pairwise comparisons in an alignment or on a tree

A S T G I L E DA 3 S 2 1T 0 0 1G 0 0 0 0I 1 0 0 1 2L 0 0 0 0 1 1E 0 0 0 0 0 0 1D 0 0 0 0 0 0 1 0
seq.1 AIDESLIIASIATATI |*||*||*||*||*||seq.2 AGEEALILASAATSTI
Raw matrixSymmetrical!
-> The larger the dataset the better the estimates!

Amino Acid exchange matrices
- s1,2 s1,3 … s1,20s1,2 - s2,3 … s2,20
s1,3 s2,3 - … s3,20 … … … … … s1,20 s2,20 s3,20 … -
X diag(π1, …, π20) = Q matrix
Q Rate matrixQij Instantaneous rates of change of amino acidssij Exchangeabilities of amino acid pairs ij sij = sij Time reversibilityπi Stationarity of amino acid frequencies (typically the observed proportion of residues in the dataset)

Amino Acid exchange matrices
R
Q
P RFRaw matrixObserved changes (counted on a MP tree or in pairwise comparisons)
Relatedness odd matrixUsed for scoring alignments (BlastP, ClustalX)
Rate matrix(with composition, not branch length)
Relative rate matrix(no composition, no branch length)
Probability matrix(composition +branch length)Can be estimated using ML on a tree Modified from Peter Foster

The PAM and JTT matrices
• PAM - Dayhoff et al. 1968
– Nuclear encoded genes, ~100 proteins
• JTT - Jones et al. 1992
– 59,190 accepted point mutations for 16,300
proteinsJones, Taylor & Thornton (1992). CABIOS 8, 275-282

The BLOSUM matrices
• BLOcks SUbstitution Matrices– The matrix values are based on 2000 conserved amino acid
patterns (blocks) - pairwise comparisons
—> more efficient for distantly related proteins
—> more agreement with 3D structure data
BLOSUM62 - 62% minimum sequence identity (BlastP default)
BLOSUM50 - 50% minimum sequence identity
BLOSUM42 - 42% minimum sequence identity (BlastP)
Henikoff & Henikoff (1992). Proc Natl Acad Sci USA 89, 10915-9

The WAG matrix
• Globular protein sequences
– 3,905 sequences from 182 protein families
• Produced a phylogenetic trees for every family and used maximum
likelihood to estimate the relative rate values in the rate matrix
(overall lnL over 182 different trees)– Better fit of the model with most data (significant improvement of the tree lnL when compared to PAM
or JTT matrices)
– Might not be the best option in some cases such as for mitochondria encoded proteins or other membrane proteins…
Whelan and Goldman (2001) Mol. Biol. Evol. 18, 691-699

Comparisons of MDMs: (sij) amino acid exchangeability
Whelan and Goldman (2001) Mol. Biol. Evol. 18, 691-699
S<->A
V<->I
D<->E
JTT
WAG*
PAM
WAG

Log-odds matrices
MDMij = 10 log10 Rij
The MDMij values are rounded to the nearest integer
MDMMDMijij < 0 freq. less than chance < 0 freq. less than chance
MDMMDMijij = 0 freq. expected by chance = 0 freq. expected by chance
MDMMDMijij > 0 freq. greater then chance > 0 freq. greater then chance
The Log-odds matrices can be used The Log-odds matrices can be used
for scoring alignments (Blast and Clustalx)for scoring alignments (Blast and Clustalx)

PAM250 Amino Acid Substitution Matrix
C S T P A G N D E Q H R K M I L V F Y WC 12 C sulfhydryl (1)S 0 2 ST -2 1 3 TP -3 1 0 6 P smallA -2 1 1 1 2 A hydrophilic (2)G -3 1 0 0 1 5 GN -4 1 0 0 0 0 2 ND -5 0 0 -1 0 1 2 4 D acid, acid-amide E -5 0 0 -1 0 0 1 3 4 E and hydrophilic (3)Q -5 -1 -1 -1 0 -1 1 2 2 4 QH -3 -1 -1 0 -1 -2 2 1 1 3 6 H R -4 -0 -2 0 -2 -3 0 -1 -1 1 2 6 R basic (4)K -5 0 0 -1 -1 -2 1 0 0 1 0 3 5 KM -5 -1 -1 -2 -1 -3 -2 -3 -2 -1 -2 0 0 6 MI -2 -1 0 -2 -1 -3 -2 -2 -2 -2 -2 -2 -2 2 5 I smallL -6 -3 -2 -3 -2 -4 -3 -4 -3 -2 -2 -3 -3 4 2 6 L hydrophobic (5)V -2 -1 0 -1 0 -1 -2 -2 -2 -2 -2 -2 -2 2 4 2 4 V F -4 -3 -3 -5 -3 -5 -3 -6 -5 -5 -2 -4 -5 0 1 2 -1 9 FY 0 -3 -3 -5 -3 -5 -2 -4 -4 -4 0 -4 -4 -2 -1 -1 -2 7 10 Y aromatic (6)W -8 -2 -5 -6 -6 -7 -4 -7 -7 -5 -3 2 -3 -4 -5 -2 -6 0 0 17 W C S T P A G N D E Q H R K M I L V F Y W
MDMMDMijij < 0 freq. less than chance < 0 freq. less than chance
MDMMDMijij = 0 freq. expected by chance = 0 freq. expected by chance
MDMMDMijij > 0 freq. greater then chance > 0 freq. greater then chance

BLOSUM62 Amino Acid Substitution Matrix
C S T P A G N D E Q H R K M I L V F Y WC 9 C sulfhydryl (1)S -1 4 ST -1 1 5 TP -3 -1 -1 7 P smallA 0 1 0 -1 4 A hydrophilic (2)G -3 0 -2 -2 0 6 GN -3 1 0 -2 -2 0 6 ND -3 0 -1 -1 -2 -1 1 6 D acid, acid-amide E -4 0 -1 -1 -1 -2 0 2 5 E and hydrophilic (3)Q -3 0 -1 -1 -1 -2 0 0 2 5 QH -3 -1 -2 -2 -2 -2 1 -1 0 0 8 H R -3 -1 -1 -2 -1 -2 0 -2 0 1 0 5 R basic (4)K -3 0 -1 -1 -1 -2 0 -1 1 1 -1 2 5 KM -1 -1 -1 -2 -1 -3 -2 -3 -2 0 -2 -1 -1 5 MI -1 -2 -1 -3 -1 -4 -3 -3 -3 -3 -3 -3 -3 1 4 I smallL -1 -2 -1 -3 -1 -4 -3 -4 -3 -2 -3 -2 -2 2 2 4 L hydrophobic (5)V -1 -2 0 -2 0 -3 -3 -3 -2 -2 -3 -3 -2 1 3 1 4 V F -2 -2 -2 -4 -2 -3 -3 -3 -3 -3 -1 -3 -3 0 0 0 -1 6 FY -2 -2 -2 -3 -2 -3 -2 -3 -2 -1 2 -2 -2 -1 -1 -1 -1 3 7 Y aromatic (6)W -2 -3 -2 -4 -3 -2 -4 -4 -3 -2 -2 -3 -3 -1 -3 -2 -3 1 2 11 W C S T P A G N D E Q H R K M I L V F Y W
MDMMDMijij < 0 freq. less than chance < 0 freq. less than chance
MDMMDMijij = 0 freq. expected by chance = 0 freq. expected by chance
MDMMDMijij > 0 freq. greater then chance > 0 freq. greater then chance

Log-odds matrices
MDMij = 10 log10 Rij
The MDMij values are rounded to the nearest integer
MDMMDMijij < 0 freq. less than chance < 0 freq. less than chance
MDMMDMijij = 0 freq. expected by chance = 0 freq. expected by chance
MDMMDMijij > 0 freq. greater then chance > 0 freq. greater then chance
I <---> M Log-odds = +2 (in PAM250):I <---> M Log-odds = +2 (in PAM250): 2 corresponds to an actual value of 0.22 corresponds to an actual value of 0.2
LogLog1010 = 0.20412, hence 10 = 0.20412, hence 100.20.2 = 1.6 = 1.6
Meaning L<--->M changes between two sequences are occurring Meaning L<--->M changes between two sequences are occurring
1.6 times more often then random1.6 times more often then random

Summary 1• Many amino acid rate matrices (MDM) exist and one needs to choose one for
protein comparisons (alignment, phylogenetics...) – do not hesitate to experiment!
• One should make a rational choice (as much as possible): – How was the rate matrix produced?– What are the structural features of the sequences of the sequences that you are comparing?
Globular/membrane protein? – What is the level of sequence identity of the compared sequences?– Does one MDM fit my data better then the others: You can use ModelGenerator or ProtTest to compare models
• Always try to correct for rate heterogeneity between sites in phylogenetics!

Summary 2• In practice MDM are obtained by averaging the observed changes and amino
acid frequencies between numerous proteins (e.g. JTT, BLOSUM) and are used for your specific dataset– With some software you can correct an MDM for the πi values of your data (amino acid
frequencies -F option)
• Specific matrices have been calculated to reflect particular composition biases– the mitochondrial proteins matrix: mtREV24
– Transmembrane domains: PHAT
• Using recoding of amino acids one can generate dataset specific models (specific GTR type model)

And…• Other developments:
– What about context-dependent MDM: alpha helices versus beta sheets, surface accessibility?
– Heterogeneous models between sites or taxa (branches)
– Protein LodDet? For long alignments only…
– Modeltest-like software that allow to choose protein models analytically:
• Modelgenerator: http://bioinf.may.ie/software/ • ProtTest: http://darwin.uvigo.es
Related Documents











