M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 1 Semantic Data Management for Organising Terabyte Data Archives Michael Lautenschlager World Data Center for Climate (M&D/MPIMET, Hamburg) CAS2K3 Workshop Sept. 2003 in Annecy, Fance Home: http://www.mad.zmaw.de/wdcc

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 1
Semantic Data Management forOrganising Terabyte Data Archives
Michael Lautenschlager
World Data Center for Climate(M&D/MPIMET, Hamburg)
CAS2K3 Workshop Sept. 2003 in Annecy, Fance
Home: http://www.mad.zmaw.de/wdcc

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 2
Content:
• General remarks
• DKRZ archive development
• CERA1) concept
• CERA data model and structure
• Automatic fill process
• Database access statistics
1) Climate and Environmental data Retrieval and Archiving

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 3
Semantic data management
• Data consist of numbers and metadata.
• Metadata construct the semantic data context.
• Metadata form a data catalogue which makes data searchable.
• Data are produced, archived and extracted within their semantic context.
Data without explanation are only numbers.
Problems:• Metadata are of different complexity for different data types. • Consistency between numbers and metadata have to be ensured.

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 4
DKRZ Archive Development
Basics observations and assumptions:1) Unix-File archive content end of 2002: 600 TB including
Backup's
2) Observed archive rate (Jan. - May 2003): 40 TB/month
3) System changes: 50% compute power increase in August 2003
4) CERA DB size end of 2002: 12 TB
5) Observed Increase (Jan. - May 2003): 1 TB/month
6) Automatic fill process into CERA DB is going to become operational with 4 TB/month this year and should increase from 10% of the archiving rate to approx. 30% end of 2004
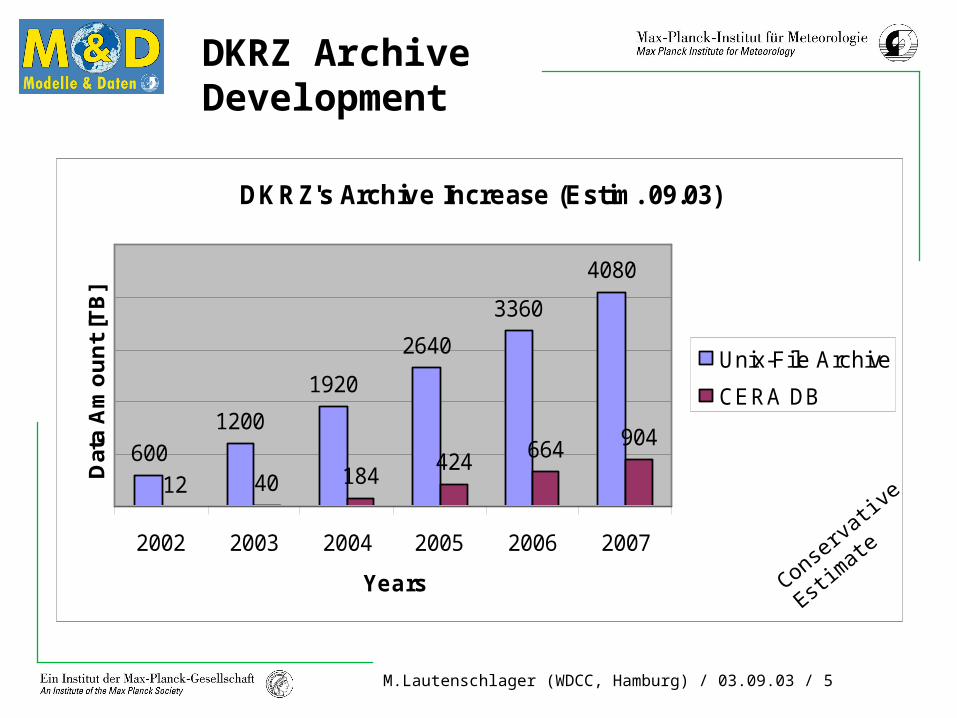
M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 5
DKRZ Archive Development
DKRZ's Archive Increase (Estim. 09.03)
6001200
1920
2640
3360
4080
12 40 184424 664 904
2002 2003 2004 2005 2006 2007
Years
Dat
a A
mo
un
t [T
B]
Unix-File Archive
CERA DB
Conserva
tive
Estimate

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 6
Problems with direct file archive access: Missing Data CatalogueDirectory structure of the Unix file system is not sufficient to organise
millions of files. Data are not stored application-orientedRaw data contain time series of 4D data blocks (3D in space and type of
variable).
Access pattern is time series of 2D fields. Lack of experience with climate model dataProblems in extracting relevant information from climate model raw data
files. Lack of computing facilities at client siteNon-modelling scientists are not equipped to handle large amounts of data
(1/2 TB = 10 years T106 or 50 years T42 in 6 hour storage intervals).
Year 2003 2004 2005 2006 2007
Estimated File Archive Size
1,2 PB 1,9 PB 2,6 PB 3,4 PB 4,1 PB

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 7
Limits of model resolution
ECHAM4(T42)Grid resolution: 2.8°Time step: 40 min
ECHAM4(T106)Grid resolution: 1.1°Time step: 20 min
Noreiks (MPIM), 2001

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 8
(I) Data catalogue and pointer to Unix files Enable search and identification of data Allow for data access as they are
(II) Application-oriented data storage Time series of individual variables are stored as BLOB
entries in DB TablesAllow for fast and selective data access
Storage in standard file-format (GRIB)Allow for application of standard data processing routines
(PINGOs)
CERA Concept:Semantic Data Management

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 9
CERA Database: 7.1 TB (12.2001)* Data Catalogue* Processed Climate Data * Pointer to Raw Data files
Mass Storage Archive:210 TB neglecting Security Copies (12.2001)
CE
RA
Dat
abas
eS
yste
m
Web-Based User InterfaceCatalogue Inspection
Climate Data Retrieval
DK
RZ
Mas
s S
tora
ge A
rch
ive
In
tern
etA
cces
s
Current database size is 20.5074 Terabyte Number of experiments: 298 Number of datasets: 29715 Number of blob within CERA at 03-SEP-03: 1262566234
Typical BLOB sizes: 17 kB and 100 kB
Number of data retrievals:
1500 – 8000 / month
Parts of CERA DB
M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 10
CERA Data: Jan. Temp.

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 11

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 12
Metadata EntryThis is the central CERA Block,providing information on• the entry's title• type and relation to other entries• the project the data belong to• a summary of the entry• a list of general keywords related to data• creation and review dates of the metadata
Additionally: Modules and Local Extensions
Module DATA_ORGANIZATION (grid structure)Module DATA_ACCESS (physical storage)Local extension for specific information on (e.g.)• data usage• data access and data administration
CoverageInformation on the volume of space-time
covered by the dataReference
Any publication related to the data togehter with the publication form
StatusStatus information like data quality, processing steps, etc.
DistributionDistribution information including access restrictions, data format and fees if necessary
Contact
Data related to contact persons and institutes like distributor, investigator, and owner of copyright
ParameterBlock describes data topic,
variable and unit
Spatial Reference
Information on the coordinatesystem used
CERA-2 Data Model Blocks

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 13
The CERA2 data model …allows for data search according to discipline, keyword, variable,
project, author, geographical region and time interval and for data retrieval.
allows for specification of data processing (aggregation and selection) without attaching the primary data.
is flexible with respect to local adaptations and storage of different types of geo-referenced data.
is open for cooperation and interchange with other database systems.
Data Model Functions

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 14
Level 1 - Interface:Metadata entries(XML, ASCII)
Level 2 – Interf.:Separate filescontaining BLOBtable data
Experiment Description
Pointer toUnix-Files
Dataset 1Description
Dataset nDescription
BLOB DataTable
BLOB DataTable
Data Structure in CERA DB

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 15
Creation of application-orienteddata storage must beautomatic because of large archive rates !!!
Automatic Fill Process (AFP)

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 16
Archive Data Flow per month
ComputeServer
CommonFile
System
MassStorageArchive
CERADB
System
60 TB/month
2003: 4 TB/month2004: 12 TB/month2005+: 20 TB/month
Unix-Files
Application OrientedData Hierarchy
Application OrientedData Hierarchy
Unix-Files
MetadataInitialisation
Important:Automatic fill processhas to be performedbefore correspondingfiles migrate to massstorage archive.

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 17
Automatic Fill Process (AFP)Steps and Relations
DB-Server:
1. Initialisation of CERA DBMetadata and BLOB data tables are created
Compute Server:
1. Climate model calculation starts with 1. month
2. Next model month starts and primary data processing of previous monthBLOB table input is produced and stored in the dynamic DB fill cache
3. Step 2 repeated until end of model experiment
DB Server:
1. BLOB data table input accessed from DB fill cache
2. BLOB table injection and update of metadata
3. Step 2 repeated until table partition is filled (BLOB table fill cache)
4. Close partition, write corresponding DB files to HSM archive, open new partition and continue with 2)
5. Close entire table and update metadata after end of model experiment

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 18
AFP Disk Cache Sizes
Dynamic DB fill cache (BLOB table input time series)
• In order to guarantee stable operation the fill cache should buffer data from approximately 10 days production.
• Cache size is determined by the automatic data fill rate of up to 1/3 of the archive increase.
Year AFP [TB/month] DB Fill Cache [TB]
2003 4 1.5
2004 12 4
2005 - 2007 20 7

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 19
AFP DISK Cache Sizes
BLOB table fill cache (open BLOB table partitions)depends on
• BLOB table partition = Table Space = DB-File: 10 GB (adapted to UniTree environment and data are in GRIB format)
• 10 GB/Table-Partition result in 5 TB/Fill-Stream for standard set of variables (approx. 500 2D global fields) of current climate model.
• Number of parallel fill streams (climate model calculations): 8
• Additional 25% is needed for HSM-transfer of closed partitions and error tracking
• BLOB table partition cache results as (8 Streams * 5 TB/Stream) * 1.25 = 50 TB

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 20
CERA Access Statistic
Month Number of downloads
Volume (GB)
Average Transfersize (MB)
June 2003 3426 78 23 May 2003 5803 117 21 APRIL 2003 5343 66 16 MARCH 2003 3611 109 31 FEBRUARY 2003 8058 168 21 JANARY 2003 2312 204 90 DECEMBER 2002 1985 200 103 NOVEMBER 2002 2813 134 49 OCTOBER 2002 4270 225 54 SEPTEMBER 2002 4054 264 67 AUGUST 2002 5475 216 40 JULY 2002 2888 196 70 JUNE 2002 1835 219 122 MAY 2002 2317 150 66 APRIL 2002 1284 170 136 MARCH 2002 1682 88 54 FEBRUARY 2002 2258 105 47 JANUARY 2002 420 35 85
Summary:
The system is used,mainly from externals.
Application dependent datastorage allows for precisedata access and reducesdata transfer volume by a factor of 100 compared todirect file transfer.
But presently data accessvia CERA DB is only a few percent of DKRZ'sdata download.

M.Lautenschlager (WDCC, Hamburg) / 03.09.03 / 21
CERA DB using countries
URL: http://cera-www.dkrz.de/CERA/index.html
Related Documents











