Mining Web content for Enhanced Search Roi Blanco Yahoo! Research

Mining Web content for Enhanced Search
Aug 03, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Mining Web content for Enhanced Search
Roi Blanco
Yahoo! Research

Yahoo! Research Barcelona• Established January, 2006• Led by Ricardo Baeza-Yates• Research areas
• Web Mining • Social Media• Distributed Web retrieval • Semantic Search• NLP/IR
2

Natural Language Retrieval• How to exploit the structure and meaning of
natural language text to improve search• Current search engines perform only limited NLP
(tokenization, stemming)• Automated tools exist for deeper analysis
• Applications to diversity-aware search• Source, Location, Time, Language, Opinion, Ranking…
• Search over semi-structured data, semantic search• Roll-out user experiences that use higher layers of
the NLP stack
3

Agenda
• Intro to current status of Web Search• Semantic Search
– Annotating documents– Entity linking– Entity search– Applications
• Time-aware information access– Motivation– Applications
4

5
WEB SEARCH

Some Challenges
• From user understanding to selecting the right hardware/software architecture– Modeling user behavior– Modeling user engagement/return
• Providing answers, not links– Richer interfaces
• Enriching document structure using semantic annotations– Indexing those annotations– Accessing them in real-time– What are the right annotations? The right level of granularity? Trade-offs?
• Time-aware information access– Changes the game in almost every step of the pipeline
6
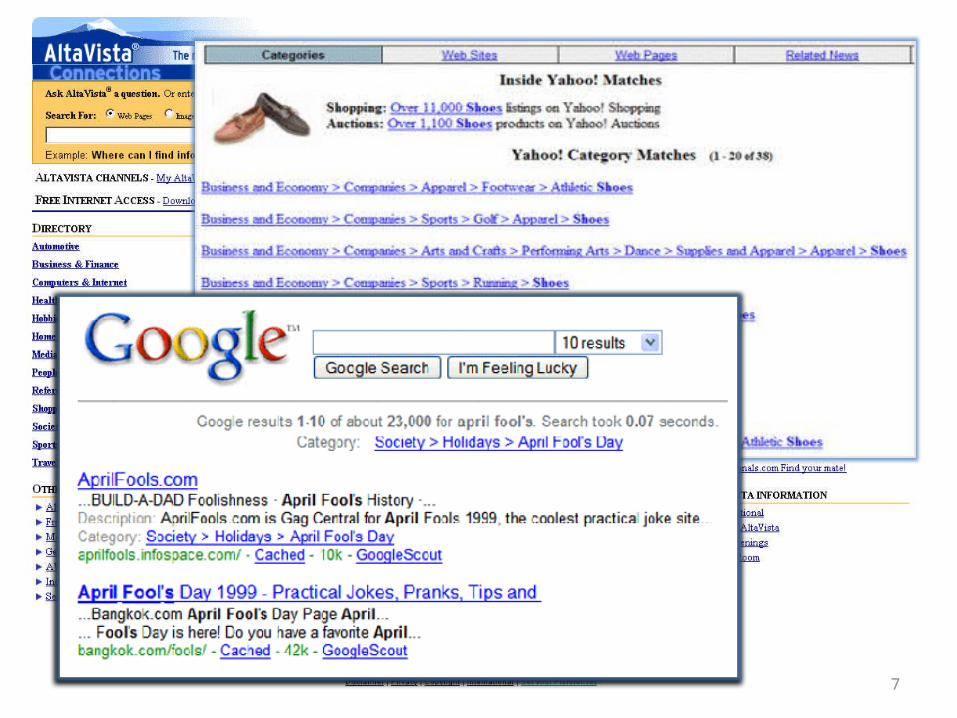
7

8

9

Structured data - Web search
Top-1 entity with structured data
Related entities
Structured dataextracted from HTML
10

New devices
• Different interaction (e.g. voice)• Different capabilities (e.g. display)• More Information (geo-localization)• More personalized
11

12
SEMANTIC SEARCH

Semantic Search
• What different kinds of search and applications beyond string matching or returning 10 blue links?
• Can we have a better understanding of documents and queries?
• New devices open new possibilities, new experiences
• Is current technology in natural language understanding mature enough?
13

Search is really fast, without necessarily being intelligent
14

Why Semantic Search? Part I
• Improvements in IR are harder and harder to come by– Machine learning using hundreds of features
• Text-based features for matching• Graph-based features provide authority
– Heavy investment in computational power, e.g. real-time indexing and instant search
• Remaining challenges are not computational, but in modeling user cognition– Need a deeper understanding of the query, the content
and/or the world at large– Could Watson explain why the answer is Toronto?
15

Semantic Search: a definition
• Semantic search is a retrieval paradigm that– Makes use of the structure of the data or explicit schemas to
understand user intent and the meaning of content– Exploits this understanding at some part of the search process
• Emerging field of research– Exploiting Semantic Annotations in Information Retrieval (2008-
2012) – Semantic Search (SemSearch) workshop series (2008-2011)– Entity-oriented search workshop (2010-2011)– Joint Intl. Workshop on Semantic and Entity-oriented Search (2012)– SIGIR 2012 tracks on Structured Data and Entities
• Related fields:– XML retrieval, Keyword search in databases, NL retrieval
16

What it’s like to be a machine?
Roi Blanco
17

What it’s like to be a machine?
✜Θ♬♬ţğ
✜Θ♬♬ţğ √∞ §®ÇĤĪ✜★♬☐✓✓ţğ★✜
✪✚✜ΔΤΟŨŸÏĞÊϖυτρ℠≠⅛⌫Γ≠=⅚ ©§ ★✓♪ΒΓΕ℠
✖Γ♫⅜±⏎↵⏏☐ģğğğμλκσςτ⏎⌥°¶§ ΥΦΦΦ ✗✕☐
18

Interactive search and task completion
19

Why Semantic Search? Part II• The Semantic Web is here
– Data• Large amounts of RDF data• Heterogeneous schemas• Diverse quality
– End users• Not skilled in writing complex
queries (e.g. SPARQL) • Not familiar with the data
• Novel applications– Complementing document search
• Rich Snippets, related entities, direct answers
– Other novel search tasks
20

Other novel applications
• Aggregation of search results– e.g. price comparison across websites
• Analysis and prediction– e.g. world temperature by 2020
• Semantic profiling– Ontology-based modeling of user interests
• Semantic log analysis– Linking query and navigation logs to ontologies
• Task completion– e.g. booking a vacation using a combination of services
• Conversational search21

list search
related entity finding
entity searchSemSearch 2010/11
list completion
SemSearch 2011
TREC ELC taskTREC REF-LOD task
semantic search
Common tasks in Semantic Search
22

”A child of five would understand this. Send someone to fetch a child of five”.
Groucho Marx
Is NLU that complex?
23

Some examples…• Ambiguous searches
– paris hilton• Multimedia search
– paris hilton sexy• Imprecise or overly precise searches
– jim hendler– pictures of strong adventures people
• Searches for descriptions– 33 year old computer scientist living in barcelona– reliable digital camera under 300 dollars
• Searches that require aggregation– height eiffel tower– harry potter movie review– world temperature 2020
24

Language is Ambiguous
The man saw the girl with the telescope
25

Paraphrases
• ‘This parrot is dead’• ‘This parrot has kicked the bucket’• ‘This parrot has passed away’• ‘This parrot is no more' • 'He's expired and gone to meet his maker,’ • 'His metabolic processes are now history’
26
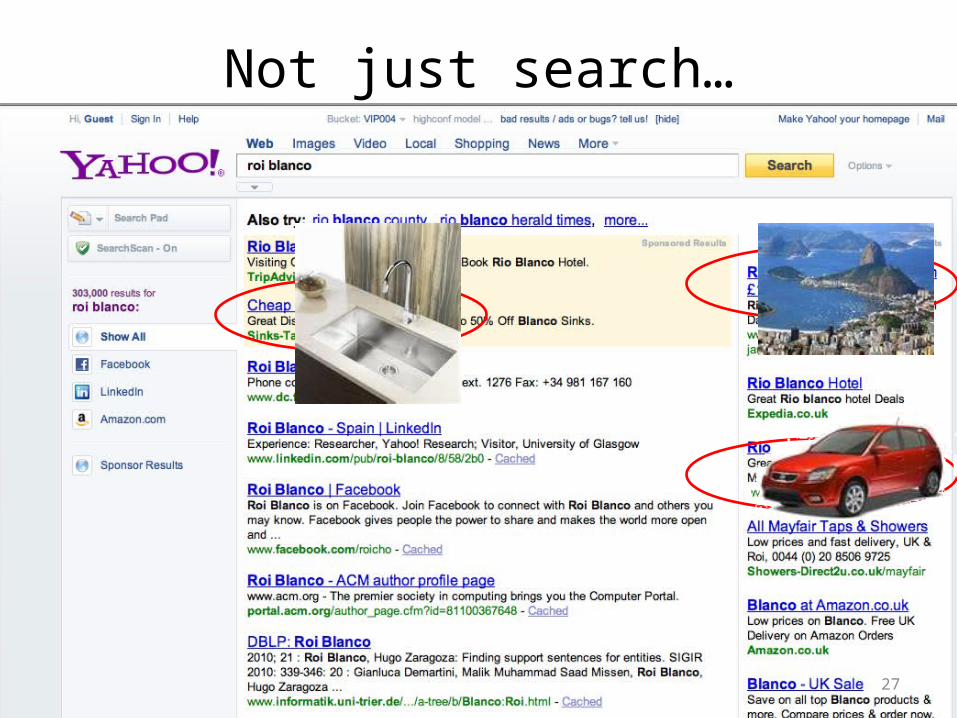
Not just search…
27

Semantics at every step of the IR process
bla bla bla?
bla
blabla
q=“bla” * 3
Document processing bla
blabla
blabla
bla
IndexingRanking
“bla”θ(q,d)
Query interpretation
Result presentation
The IR engine The Web
28

Understanding Queries
• Query logs are a big source of information & knowledge
To rank better the results (what you click)
To understand queries betterParis Paris Flights
Paris Paris Hilton
29

“Understand” Documents
NLU is still an open issue
30

NLP for IR
• Full NLU is AI complete, not scalable to the web size (parsing the web is really hard).
• BUT … what about other shallow NLP techniques?
• Hypothesis/Requirements:• Linear extraction/parsing time• Error-prone output (e.g. 60-90%)• Highly redundant information
• Explore new ways of browsing• Support your answers
31

Usability
SometimesWe also fail at using the technology
32

Support your answersErrors happen: choose the right ones!
• Humans need to “verify” unknown facts• Multiple sources of evidence• Common sense vs. Contradictions
• are you sure? is this spam? Interesting!• Tolerance to errors greatly increases if users can verify
things fast• Importance of snippets, image search
• Often the context is as important as the fact• E.g. “S discovered the transistor in X”
• There are different kinds of errors• Ridiculous result (decreases overall confidence in system)• Reasonably wrong result (makes us feel good)
33

34
TOOLS FOR GENERATING ANNOTATIONS

Entity?
• Uniquely identifiable “thing” or “object”– “A thing with a distinct and independent existence”
• Properties:– ID– Name(s)– Type(s)– Attributes (/Descriptions)– Relationships to other entities
• An entity is only one kind of textual annotation!
35

Entity?
36

Named Entity Recognition
• “Named Entity”, IE context of MUC-6 (R. Grishman & Sundheim’1996)
• Recognize information units like names, including PERson, ORGanization, LOCation names, and numeric expressions including time, date, money
[Yahoo!] employee [Roi Blanco] visits [Sapporo] . ORG PER LOC
37

ML methods• Supervised
• HMM• CRF• SVM• …
• Unsupervised• Lexical Resources (e.g WordNet), lexical patterns and
statistics from large non-annotated corpora.• “Semi-supervised” (or “weakly supervised”)
• Mostly “Bootstrapping” from a set of entities
38

Entity Linking
Image taken from Milne and Witten (2008b). Learning to Link with Wikipedia. In CIKM '08.39

NE Linking / NED
• Linking mentions of Named Entities to a Knowledge Base (e.g. Wikipedia, Freebase …)
• Name Variations • Shortened forms• Alternative Spellings
• “New” Entities (not contained in the Knowledge Base)
• As the Knowledge Base grows … everything looks like an Entity (a town named web!?)
40

Entity Ambiguity
• In Wikipedia Michael Jordan may also refer to:– Michael Jordan (mycologist)– Michael Jordan (footballer) – Michael Jordan (Irish politician)– Michael B. Jordan (born 1987), American actor– Michael I. Jordan (born 1957), American researcher– Michael H. Jordan (1936–2010), American executive– Michael-Hakim Jordan (born 1977), basketball player
41

Traditional IE
• Relations: assertions linking two or more concepts– actors-act in-movies– cities-capital of-countries
• Facts: instantiations of relations– leonardo dicaprio-act in-inception– cairo-capital of-egypt
• Attributes: facts capturing quantifiable properties– actors --> awards, birth date, height– movies --> producer, release date, budget
42

43
ENTITY LINKING
http://ejmeij.github.io/entity-linking-and-retrieval-tutorial/

Image taken from Mihalcea and Csomai (2007). Wikify!: linking documents to encyclopedic knowledge. In CIKM '07. 44

45
Bing
46

47
Yahoo!
48

49
Yahoo! Homepage

50
Yahoo! Homepage

51
Yahoo! Homepage

Why do we need entity linking?
• (Automatic) document enrichment– go-read-here– assistance for (Wikipedia) editors– inline (microformats, RDFa)
52

Why do we need entity linking?
• “Use as feature”– to improve
• classification• retrieval• word sense disambiguation• semantic similarity• ...
– dimensionality reduction (as compared to, e.g., term vectors)
53

Why do we need entity linking?
• Enable – semantic search– advanced UI/UX– ontology learning, KB population– ...
54

A bit of history
• Text classification• NER• WSD• NED
– {person name, geo, movie name, ...} disambiguation
– (Cross-document) co-reference resolution• Entity linking
55

Entity linking?
• NE normalization / canonicalization / sense disambiguation
• DB record linkage / schema mapping• Knowledge base population• Entity linking
– D2W– Wikification– Semantic linking
56

Entity Linking: main problem• Linking free text to entities
– Entities (typically) taken from a knowledge base• Wikipedia• Freebase • ...
– Any piece of text• news documents• blog posts• tweets• queries• ...
57

Typical steps
1. Determine “linkable” phrases – mention detection – MD
2. Rank/Select candidate entity links– link generation – LG– may include NILs (null values, i.e., no target in KB)
3. (Use “context” to disambiguate/filter/improve)– disambiguation – DA
58

Preliminaries
• Wikipedia• Wikipedia-based measures
– commonness– relatedness– keyphraseness
59

Wikipedia• Basic element: article (proper)
• But also
– redirect pages– disambiguation pages– category/template pages– admin pages
• Hyperlinks
– use “unique identifiers” (URLs) • [[United States]] or [[United States|American]]• [[United States (TV series)]] or
[[United States (TV series)|TV show]]60

Wikipedia style guidelines
• “the lead contains a quick summary of the topic's most important points, and each major subtopic is detailed in its own section of the article”– “The lead section (also known as the lead,
introduction or intro) of a Wikipedia article is the section before the table of contents and the first heading. The lead serves as an introduction to the article and a summary of its most important aspects.”
See http://en.wikipedia.org/wiki/Wikipedia:Summary_style 61

Some statistics
• WordNet– 80k entity definitions– 115k surface forms– 142k senses (entity - surface form combinations)
• Wikipedia (only)– ~4M entity definitions– ~12M surface forms– ~24M senses
62

Wikipedia-based measures
• keyphraseness(w) [Mihalcea & Csomai 2007]
Collection frequency term w as a link to another Wikipedia article
Collection frequency term w
63

Wikipedia-based measures
• commonness(w,c) [Medelyan et al. 2008]
Number of linkswith target c’ and anchor text w
64

Commonness and keyphraseness
Image taken from Li et al. (2013). TSDW: Two-stage word sense disambiguation using Wikipedia. In JASIST 2013. 65

Wikipedia-based measures
• relatedness(c, c’) [Milne & Witten 2008a]
Image taken from Milne and Witten (2008a). An Effective, Low-Cost Measure of Semantic Relatedness Obtained from Wikipedia Links. In AAAI WikiAI Workshop. 66

Wikipedia-based measures
• relatedness(c, c’) [Milne & Witten 2008a]
Total number of Wikipedia articles
Intersection of inlinks with target c and c’
Number of linkswith target c
67

Recall the steps
1. mention detection – MD2. link generation – LG3. (disambiguation) – DA
68

Wikify![Mihalcea & Csomai 2007]
• MD– tf.idf, Χ2, keyphraseness
• LG1.Overlap between definition (Wikipedia page) and
context (paragraph) [Lesk 1986]2.Naive Bayes [Mihalcea 2007]
• context, POS, entity-specific terms
3.Voting between (1) and (2)
69

Large-Scale Named Entity Disambiguation Based on Wikipedia Data
[Cucerzan 2007]
• Key intuition: leverage context links – '''Texas''' is a [[pop music]] band from [[Glasgow]],
[[Scotland]], [[United Kingdom]]. They were founded by [[Johnny McElhone]] in [[1986 in music|1986]] and had their performing debut in [[March]] [[1988]] at ...
• Prune the candidates, keep only:– appearances in the first paragraph of an article, and– reciprocal links
70

Large-Scale Named Entity Disambiguation Based on Wikipedia Data
[Cucerzan 2007]
• MD– NER; rule-based; co-ref resolution
• LG– Represent entities as vectors
• context, categories
– Same for all candidate entity links– Determine maximally coherent set
71

Topic Indexing with Wikipedia[Medelyan et al. 2008]
• MD– keyphraseness [Mihalcea & Csomai 2007]
• LG• combination of average relatedness &
commonness• LG/DA
• Naive Bayes• TF.IDF, position, length, degree, weighted keyphraseness
72

Learning to Link with Wikipedia[Milne & Witten 2008b]
• Key idea: disambiguation informs detection– compare each possible sense with its relatedness
to the context sense candidates– start with unambiguous senses– So, first LG, then base MD on these results
73
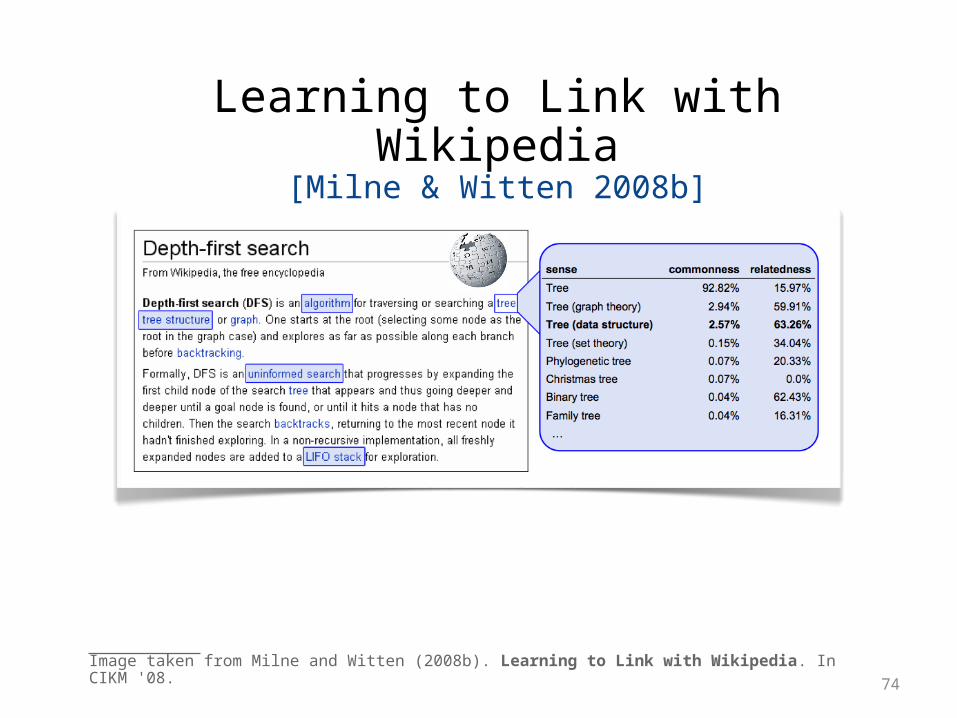
Image taken from Milne and Witten (2008b). Learning to Link with Wikipedia. In CIKM '08.
Learning to Link with Wikipedia[Milne & Witten 2008b]
74

Learning to Link with Wikipedia[Milne & Witten 2008b]
• Filter non-informative, non-ambiguous candidates (e.g., “the”)– based on keyphraseness, i.e., link probability
• Filter non-central candidates– based on average relatedness to all other context senses
• Combine
75

Learning to Link with Wikipedia[Milne & Witten 2008b]
• MD• Machine learning
• link probability, relatedness, confidence of LG, generality, frequency, location, spread
• LG• Machine learning
• keyphraseness, average relatedness, sum of average weights
76
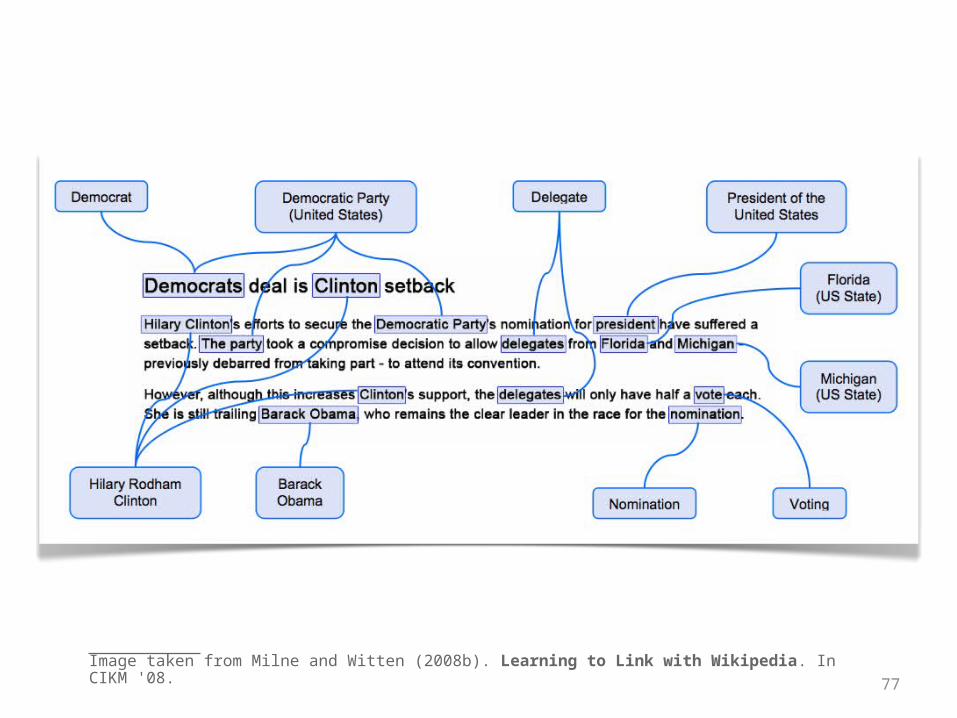
Image taken from Milne and Witten (2008b). Learning to Link with Wikipedia. In CIKM '08.77

Local and Global Algorithms for Disambiguation to Wikipedia
[Ratinov et al. 2011]
• Explicit focus on global versus local algorithms– “Global,” i.e., disambiguation of the candidate graph– NP-hard
• Optimization– reduce the search space to a “disambiguation
context,” e.g.,• all plausible disambiguations [Cucerzan 2007] • unambiguous surface forms [Milne & Witten 2008b]
78

Local and Global Algorithms for Disambiguation to Wikipedia
[Ratinov et al. 2011]
• Main contribution, in steps1.use “local” approach (e.g., commonness) to
generate a disambiguation context2.apply “global” machine learning approach
• relatedness, PMI• {inlinks, outlinks} in various combinations (c and c’)• {avg, max}
• Finally, apply another round of machine learning
79

TAGME: On-the-fly Annotation of Short Text Fragments
[Ferragina & Scaiella 2010]
• MD– keyphraseness [Mihalcea & Csomai 2007]
• LG• use “local” approach to generate a disambiguation
context, similar to [Ratinov et al. 2011] • Heavy pruning
• mentions; candidate links; coherence
• Accessible at http://tagme.di.unipi.it
80

A Graph-based Method for Entity Linking
[Guo et al. 2011]• MD
– rule-based; prefer longer links– generate a disambiguation context
• LG• (weighted interpolation of) in- and outdegree in
disambiguation context to select entity links• edges defined by wikilinks
• Evaluation on TAC KBP
81

Recap
• Essential ingredients– MD
• commonness• keyphraseness
– LG• commonness• machine learning
– DA• relatedness• machine learning
82

83
SEARCH OVER ANNOTATED DOCUMENTS

Annotated documentsBarack Obama visited Tokyo this Monday as part of an extended Asian trip.He is expected to deliver a speech at the ASEAN conference next Tuesday
Barack Obama visited Tokyo this Monday as part of an extended Asian trip.
He is expected to deliver a speech at the ASEAN conference next Tuesday
20 May 2009
28 May 2009
84

85

How does it work?
Monty Python Inverted Index
(sentence/doc level)
Forward Index(entity level)
Flying CircusJohn CleeseBrian
86

Efficient element retrieval
• Goal– Given an ad-hoc query, return a list of documents and
annotations ranked according to their relevance to the query• Simple Solution
– For each document that matches the query, retrieve its annotations and return the ones with the highest counts
• Problems– If there are many documents in the result set this will take too
long - too many disk seeks, too much data to search through– What if counting isn’t the best method for ranking elements?
• Solution– Special compressed data structures designed specifically for
annotation retrieval
87

Forward Index
• Access metadata and document contents – Length, terms, annotations
• Compressed (in memory) forward indexes– Gamma, Delta, Nibble, Zeta codes (power laws)
• Retrieving and scoring annotations– Sort terms by frequency
• Random access using an extra compressed pointer list (Elias-Fano)
88

Parallel Indexes• Standard index contains only tokens• Parallel indices contain annotations on the tokens – the
annotation indices must be aligned with main token index • For example: given the sentence “New York has great
pizza” where New York has been annotated as a LOCATION – Token index has five entries
(“new”, “york”, “has”, “great”, “pizza”)
– The annotation index has five entries (“LOC”, “LOC”, “O”,”O”,”O”)
Can optionally encode BIO format (e.g. LOC-B, LOC-I)• To search for the New York location entity, we search for:
“token:New ^ entity:LOC token:York ^ entity:LOC”
89

Parallel Indices (II)
Doc #5: Hope claims that in 1994 she run to Peter Town.
Peter D3:1, D5:9Town D5:10Hope D5:11994 D5:5…
Doc #3: The last time Peter exercised was in the XXth century.
Possible Queries: “Peter AND run” “Peter AND WNS:N_DATE” “(WSJ:CITY ^ *) AND run” “(WSJ:PERSON ^ Hope) AND run”
WSJ:PERSON D3:1, D5:1WSJ:CITY D5:9WNS:V_DATE D5:5
(Bracketing can also be dealt with)
90

Pipelined Architecture
91
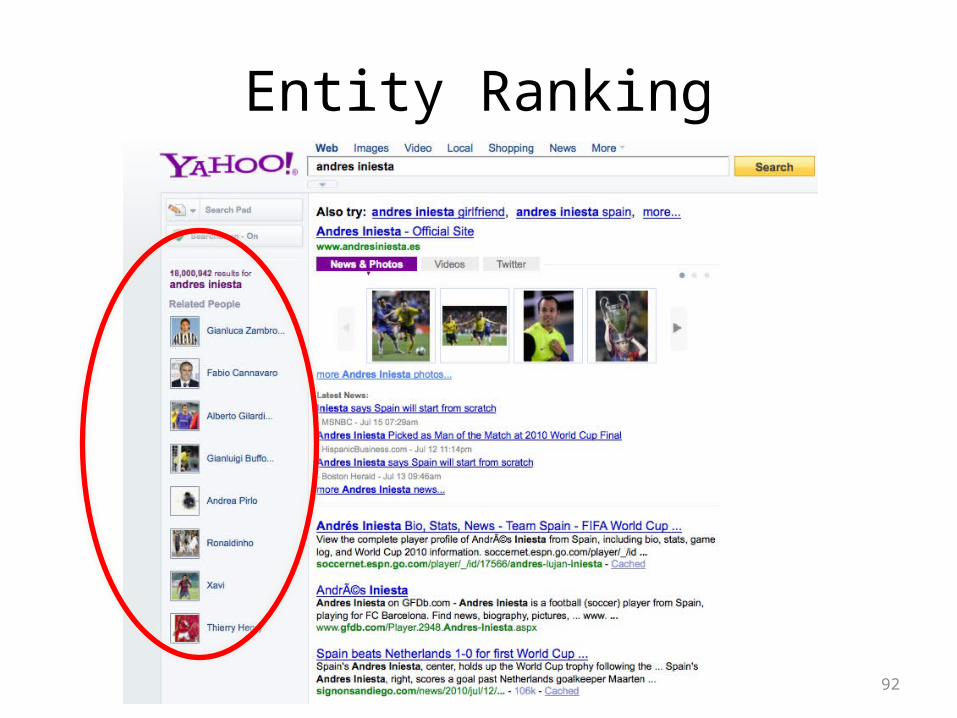
Entity Ranking
92

Entity Ranking
• Given a topic, find relevant entities• Evaluated in TREC and INEX campaigns • Most well-known: people and expert
search• Many other applications: dates, events,
locations, companies, ...
93
94

Example queries
• Impressionist art Museums in Holland• Countries with the Euro currency• German car manufacturers• Artists related to Pablo Picasso• Actors who played Hamlet• English monarchs who married a French women• Many examples on
http://www.ins.cwi.nl/projects/inex-xer/topics/
95

Entity Ranking
• Topical query Q– Entity (result) type TX– A list of Entity instance Xs
• Systems employ categories, structure, links:– Kaptein et al., CIKM10: Exploits Wikipedia, identifies entity types, anchor text
index for entity search– Bron et al,CIKM10 Entity co occurrence, Entity type filtering, Context ‐
(relation type)
• See http://ilps.science.uva.nl/trec-entity/resources/• Futher: http://ejmeij.github.io/entity-linking-and-
retrieval-tutorial/
96

Element Containment Graph[Zaragoza et al. CIKM 2007]
• Given passage s in S, element e in E, there is a directed edge from s to e if passage s contains element e
• Element containment graph C = S x E where Cij is strength of connection between si and ej
At query time, compute Cq as a subset of the containment graph of the q passages matching the query
Rank entities using HITS, PageRank, passage similarity, element similarity, etc
97

98
SEARCH OVER RDF (TRIPLES) DATA

Resource Description Framework (RDF)
• Each resource (thing, entity) is identified by a URI– Globally unique identifiers– Locators of information
• Data is broken down into individual facts– Triples of (subject, predicate, object)
• A set of triples (an RDF graph) is published together in an RDF document
example:roi
“Roi Blanco”
name
typefoaf:Person
RDF document
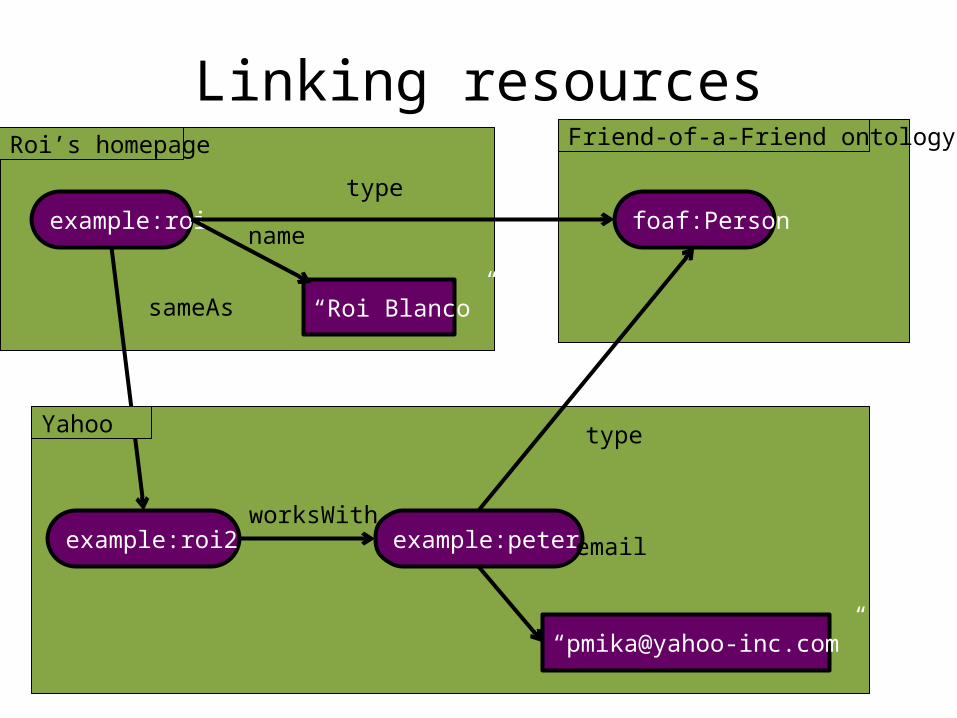
Linking resources
example:roi
“Roi Blanco”
namefoaf:Person
sameAs
example:roi2worksWith
example:peter
type
type
Roi’s homepage
Yahoo
Friend-of-a-Friend ontology

Publishing RDF• Linked Data
– Data published as RDF documents linked to other RDF documents
– Community effort to re-publish large public datasets (e.g. Dbpedia, open government data)
• RDFa– Data embedded inside HTML pages– Recommended for site owners by Yahoo!, Google, Facebook
• SPARQL endpoints– Triple stores (RDF databases) that can be queried through
the web

The state of Linked Data
• Rapidly growing community effort to (re)publish open datasets as Linked Data– In particular, scientific and government datasets– see linkeddata.org
• Less commercial interest, real usage (Haas et al. SIGIR 2011)
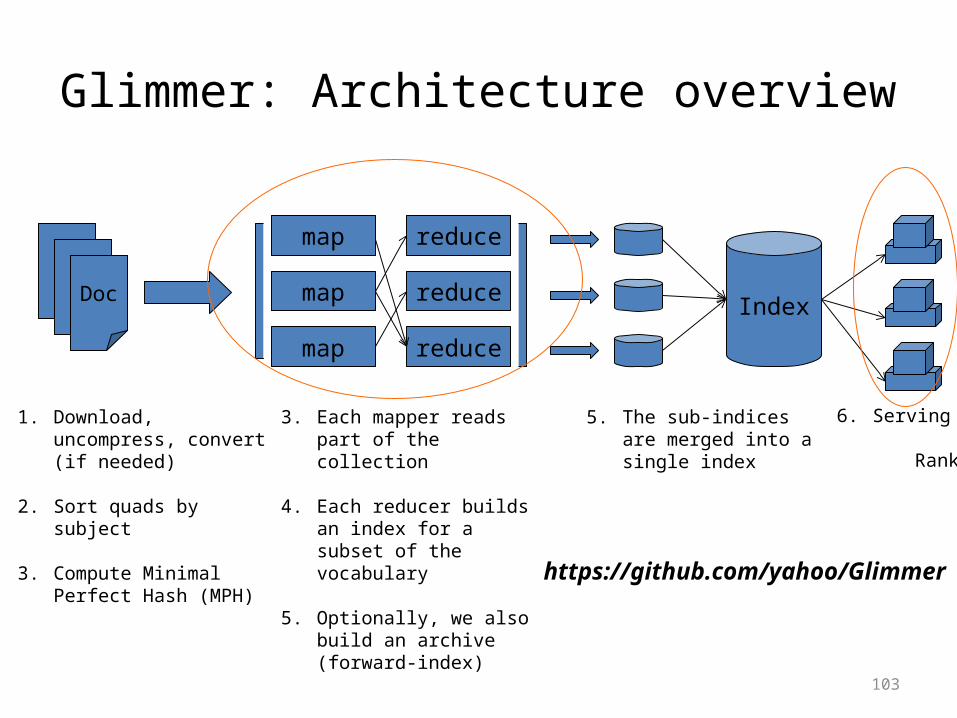
Glimmer: Architecture overview
Doc
1. Download, uncompress, convert (if needed)
2. Sort quads by subject
3. Compute Minimal Perfect Hash (MPH)
map
map
reduce
reduce
map reduce
Index
3. Each mapper reads part of the collection
4. Each reducer builds an index for a subset of the vocabulary
5. Optionally, we also build an archive (forward-index)
5. The sub-indices are merged into a single index
6. Serving and Ranking
103
https://github.com/yahoo/Glimmer

Horizontal index structure
• One field per position– one for object (token), one for predicates (property), optionally one for context
• For each term, store the property on the same position in the property index– Positions are required even without phrase queries
• Query engine needs to support fields and the alignment operator✓ Dictionary is number of unique terms + number of properties✓ Occurrences is number of tokens * 2
104

Vertical index structure
• One field (index) per property• Positions are not required• Query engine needs to support fields✓ Dictionary is number of unique terms✓ Occurrences is number of tokens
✗ Number of fields is a problem for merging, query performance• In experiments we index the N most common properties
105

Efficiency improvements
• r-vertical (reduced-vertical) index– One field per weight vs. one field per property– More efficient for keyword queries but loses the ability to restrict per
field– Example: three weight levels
• Pre-computation of alignments– Additional term-to-field index– Used to quickly determine which fields contain a term (in any document)
106
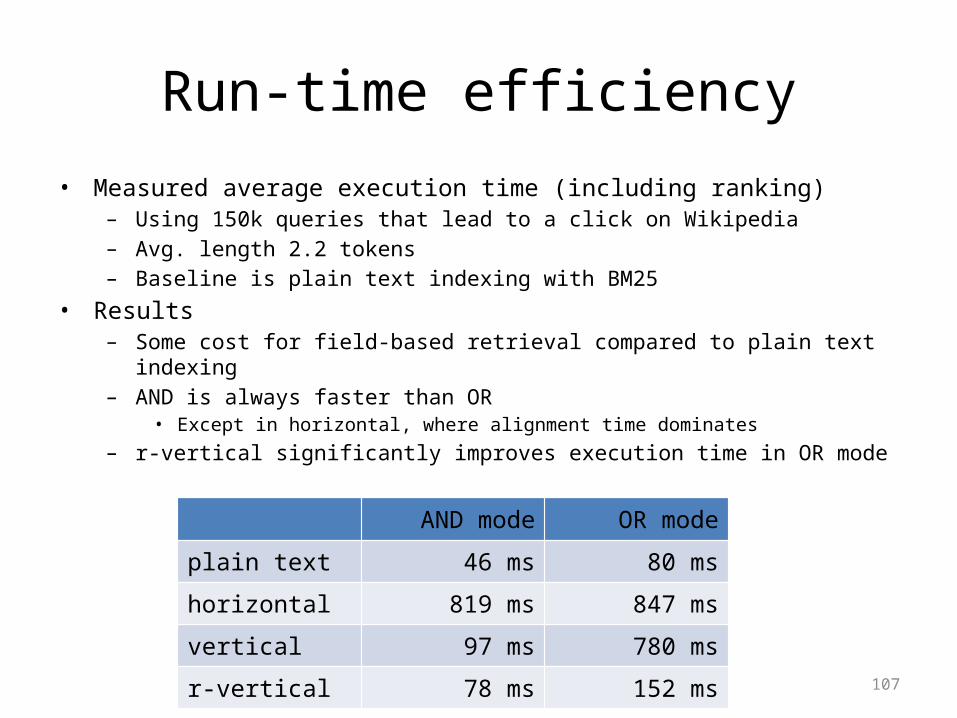
Run-time efficiency
• Measured average execution time (including ranking)– Using 150k queries that lead to a click on Wikipedia– Avg. length 2.2 tokens– Baseline is plain text indexing with BM25
• Results– Some cost for field-based retrieval compared to plain text indexing – AND is always faster than OR
• Except in horizontal, where alignment time dominates– r-vertical significantly improves execution time in OR mode
AND mode OR mode
plain text 46 ms 80 ms
horizontal 819 ms 847 ms
vertical 97 ms 780 ms
r-vertical 78 ms 152 ms107

BM25F Ranking
BM25(F) uses a term-frequency (tf) that accounts for the decreasing marginal contribution of terms
where vs is the weight of the field
tfsi is the frequency of term i in field s
Bs is the document length normalization factor:ls is the length of field s
avls is the average length of s bs is a tunable parameter
108

BM25F ranking (II)• Final term score is a combination of tf and idf
wherek1 is a tunable parameter
wIDF is the inverse-document frequency:
• Finally, the score of a document D is the sum of the scores of query terms q
109

Effectiveness evaluation
• Semantic Search Challenge 2010– Data, queries, assessments available online
• Billion Triples Challenge 2009 dataset• 92 entity queries from web search
– Queries where the user is looking for a single entity– Sampled randomly from Microsoft and Yahoo! query logs
• Assessed using Amazon’s Mechanical Turk– Halpin et al. Evaluating Ad-Hoc Object Retrieval, IWEST 2010– Blanco et al. Repeatable and Reliable Search System
Evaluation using Crowd-Sourcing, SIGIR2011
110
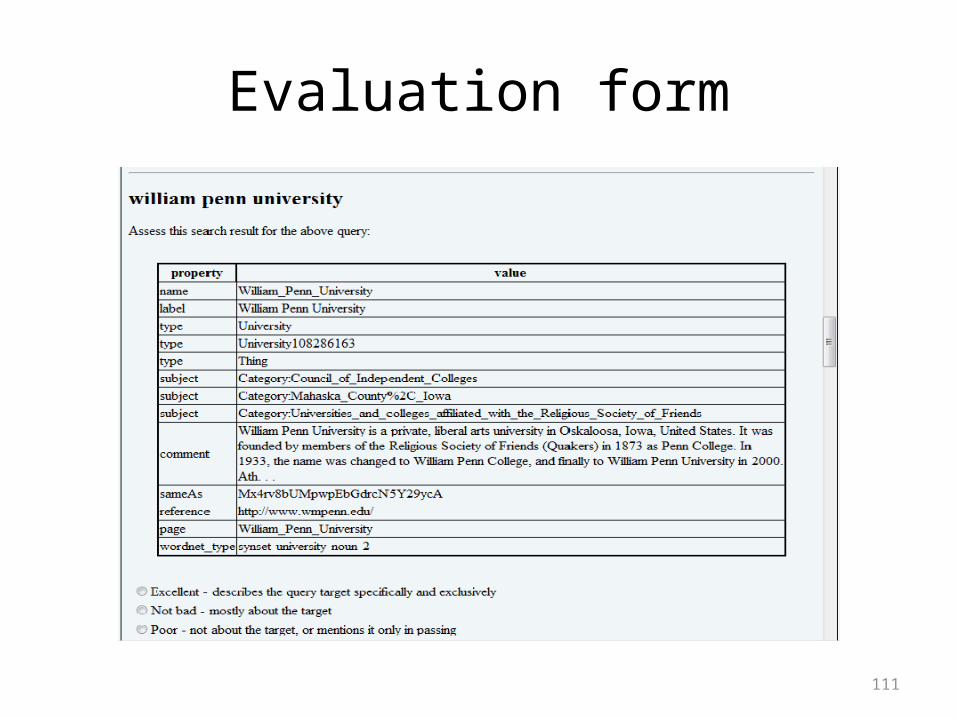
Evaluation form
111

Effectiveness results• Individual features
– Positive, stat. significant improvement from each feature– Even a manual classification of properties and domains helps
• Combination– Positive stat. significant marginal improvement from each additional feature– Total improvement of 53% over the baseline– Different signals of relevance
112

Conclusions
• Indexing and ranking RDF data– Novel index structures– Ranking method based on BM25F
• Future work– Ranking documents with metadata
• e.g. microdata/RDFa
– Exploiting more semantics• e.g. sameAs
– Ranking triples for display – Question-answering
113

Entity Ranking Conclusions• Entity ranking provides a richer user
experience for search-triggered applications
• Ranking entities can be done effectively/efficiently using simple frequency-based models
• Explaining things is as important as retrieving them (Blanco and Zaragoza SIGIR 2010)
– Support sentences: several features based on scores of sentences and entities
– The role of the context boosts performance 114

Related entity ranking in web
search

Spark: related entity recommendations in web
search• A search assistance tool for exploration
• Recommend related entities given the user’s current query– Cf. Entity Search at SemSearch, TREC Entity Track
• Ranking explicit relations in a Knowledge Base– Cf. TREC Related Entity Finding in LOD (REF-LOD) task
• A previous version of the system live since 2010• van Zwol et al.: Faceted exploration of image search results. WWW 2010: 961-970
– The current version (described here) at • Blanco et al: Entity recommendations in Web Search, ISWC 2013
116

Motivation
• Some users are short on time – Need for direct answers– Query expansion, question-answering,
information boxes, rich results…
• Other users have time at their hand– Long term interests such as sports, celebrities,
movies and music– Long running tasks such as travel planning
117

Examples
118

Spark in use
119

How does it work?
120
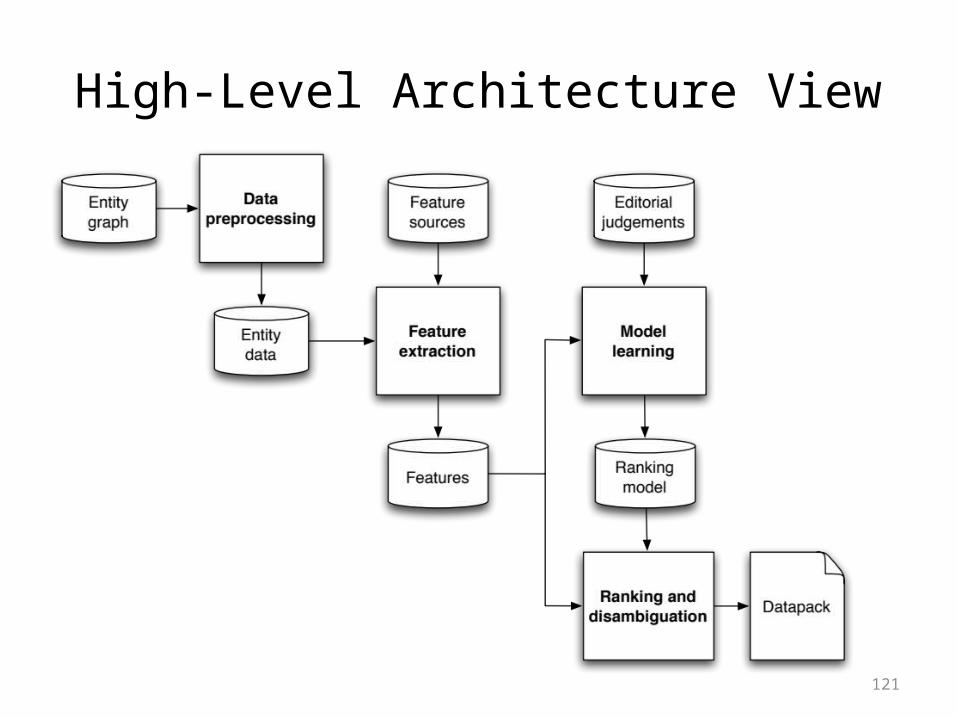
High-Level Architecture View
121
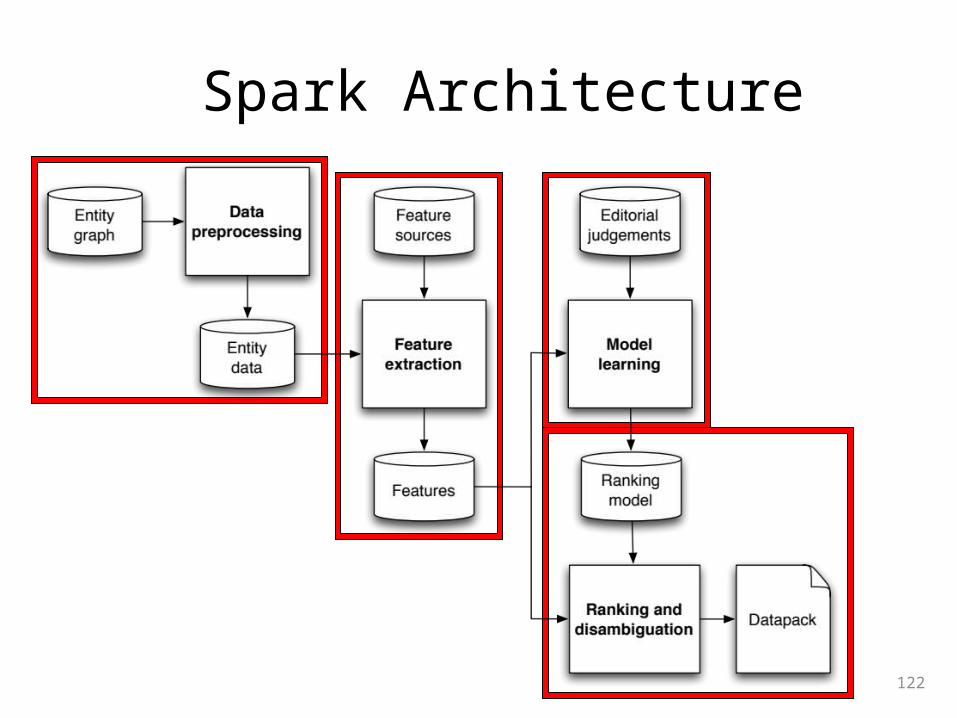
Spark Architecture
122
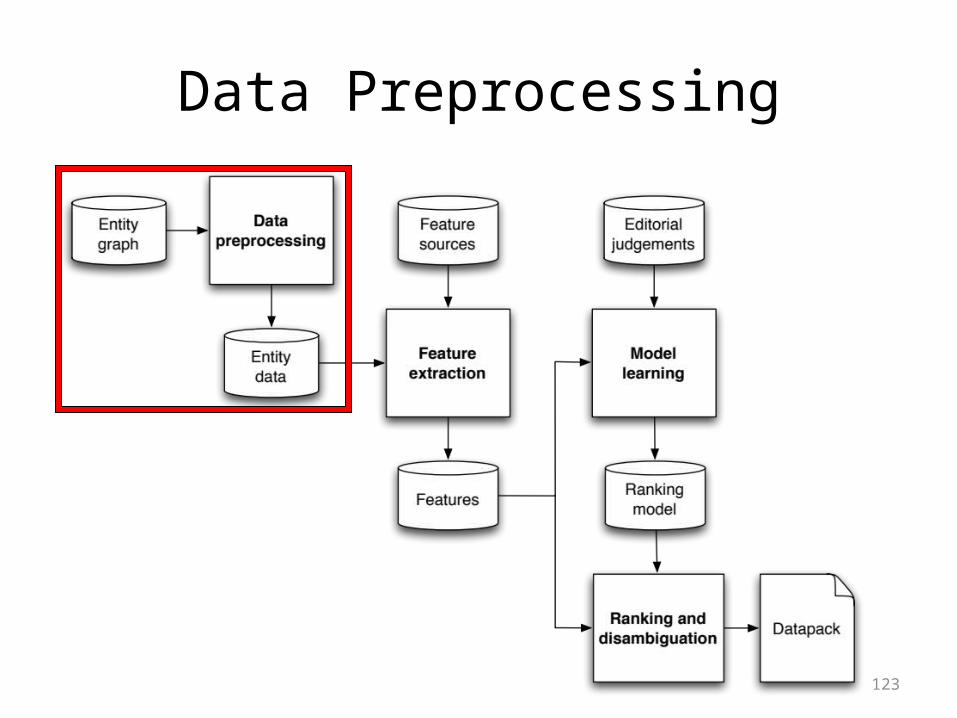
Data Preprocessing
123

Entity graph• 3.4 million entities, 160 million relations
• Locations: Internet Locality, Wikipedia, Yahoo! Travel• Athletes, teams: Yahoo! Sports• People, characters, movies, TV shows, albums: Dbpedia
• Example entities• Dbpedia Brad_Pitt Brad Pitt Movie_Actor• Dbpedia Brad_Pitt Brad Pitt Movie_Producer• Dbpedia Brad_Pitt Brad Pitt Person• Dbpedia Brad_Pitt Brad Pitt TV_Actor• Dbpedia Brad_Pitt_(boxer) Brad Pitt Person
• Example relations• Dbpedia Dbpedia Brad_Pitt Angelina_Jolie Person_IsPartnerOf_Person• Dbpedia Dbpedia Brad_Pitt Angelina_Jolie MovieActor_CoCastsWith_MovieActor• Dbpedia Dbpedia Brad_Pitt Angelina_Jolie MovieProducer_ProducesMovieCastedBy_MovieActor
124

Entity graph challenges• Coverage of the query volume
– New entities and entity types– Additional inference– International data– Aliases, e.g. jlo, big apple, thomas cruise mapother iv
• Freshness– People query for a movie long before it’s released
• Irrelevant entity and relation types– E.g. voice actors who co-acted in a movie, cities in a continent
• Data quality– Andy Lau has never acted in Iron Man 3
125

Feature Extraction
126

Feature extraction from text
• Text sources– Query terms– Query sessions– Flickr tags– Tweets
• Common representationInput tweet: Brad Pitt married to Angelina Jolie in Las VegasOutput event: Brad Pitt + Angelina JolieBrad Pitt + Las VegasAngelina Jolie + Las Vegas
127

Features
• Unary– Popularity features from text: probability, entropy, wiki id
popularity …– Graph features: PageRank on the entity graph, Wikipedia,
web graph– Type features: entity type
• Binary– Co-occurrence features from text: conditional probability,
joint probability …– Graph features: common neighbors …– Type features: relation type
128

Feature extraction challenges
• Efficiency of text tagging– Hadoop Map/Reduce
• More features are not always better– Can lead to over-fitting without sufficient training
data
129
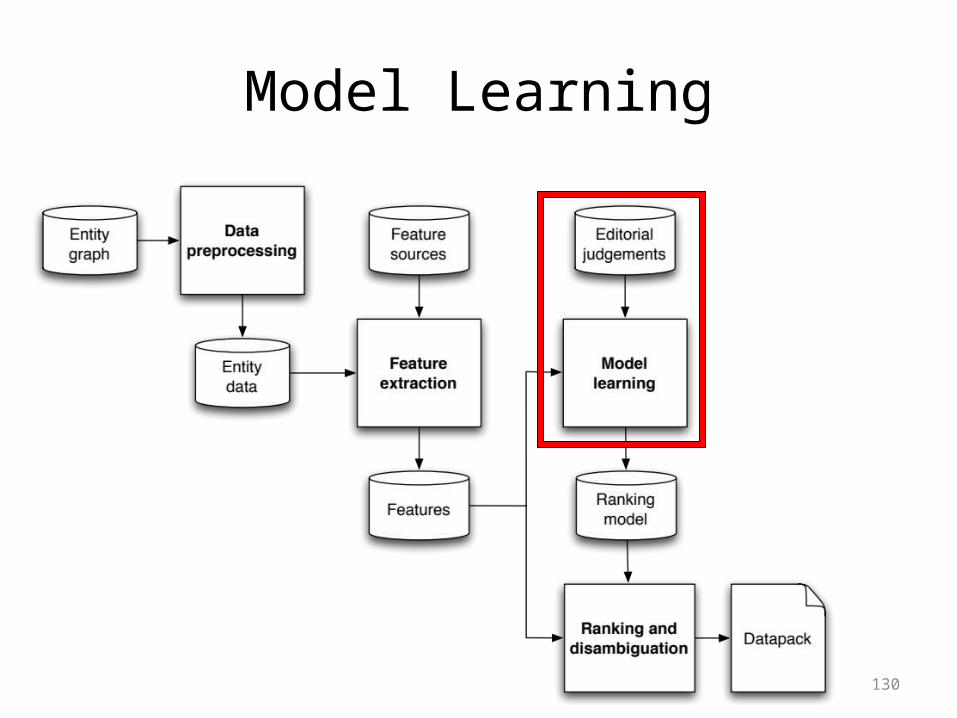
Model Learning
130
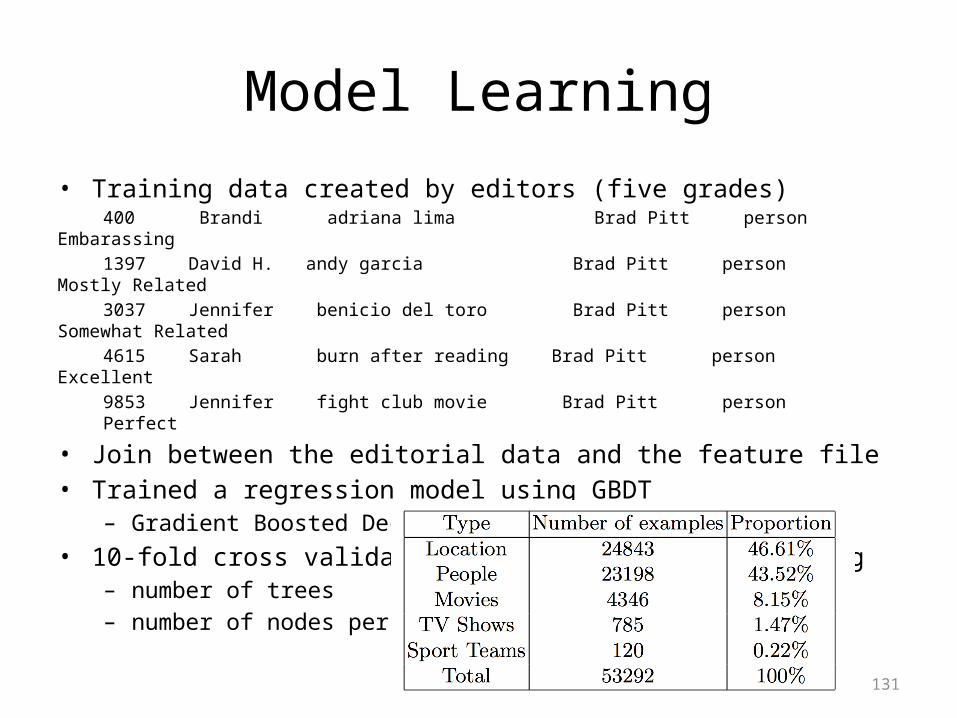
Model Learning
• Training data created by editors (five grades)400 Brandi adriana lima Brad Pitt person Embarassing1397 David H. andy garcia Brad Pitt person Mostly Related3037 Jennifer benicio del toro Brad Pitt person Somewhat Related4615 Sarah burn after reading Brad Pitt person Excellent
9853 Jennifer fight club movie Brad Pitt person Perfect
• Join between the editorial data and the feature file• Trained a regression model using GBDT
– Gradient Boosted Decision Trees• 10-fold cross validation optimizing NDCG and tuning
– number of trees– number of nodes per tree
131

Impact of training data
Number of training instances (judged relations)132

Model Learning challenges
• Editorial preferences not necessarily coincide with usage– Users click a lot more on people than expected– Image bias?
• Alternative: optimize for usage data– Clicks turned into labels or preferences– Size of the data is not a concern– Gains are computed from normalized CTR/COEC
– See van Zwol et al. Ranking Entity Facets Based on User Click Feedback. ICSC 2010: 192-199.
133

Ranking and Disambiguation
134

Ranking and Disambiguation
• We apply the ranking function offline to the data• Disambiguation
– How many times a given wiki id was retrieved for queries containing the entity name?
Brad Pitt Brad_Pitt 21158Brad Pitt Brad_Pitt_(boxer) 247
XXX XXX_(movie) 1775XXX XXX_(Asia_album) 89XXX XXX_(ZZ_Top_album) 87
XXX XXX_(Danny_Brown_album) 67
– PageRank for disambiguating locations (wiki ids are not available)
• Expansion to query patterns– Entity name + context, e.g. brad pitt actor
135

Ranking and Disambiguation challenges
• Disambiguation cases that are too close to call– Fargo Fargo_(film) 3969– Fargo Fargo,_North_Dakota 4578
• Disambiguation across Wikipedia and other sources
136

Evaluation #2: Side-by-side testing
• Comparing two systems– A/B comparison, e.g. current system under development and production system– Scale: A is better, B is better
• Separate tests for relevance and image quality– Image quality can significantly influence user perceptions– Images can violate safe search rules
• Classification of errors– Results: missing important results/contains irrelevant results, too few results, entities
are not fresh, more/less diverse, should not have triggered– Images: bad photo choice, blurry, group shots, nude/racy etc.
• Notes– Borderline, set one entities relate to the movie Psy but the query is most likely about
Gangnam style – Blondie and Mickey Gilley are 70’s performers and do not belong on a list of 60’s
musicians. – There is absolutely no relation between Finland and California.
137

Evaluation #3: Bucket testing
• Also called online evaluation– Comparing against baseline version of the system – Baseline does not change during the test
• Small % of search traffic redirected to test system, another small % to the baseline system
• Data collection over at least a week, looking for stat. significant differences that are also stable over time
• Metrics in web search– Coverage and Click-through Rate (CTR)– Searches per browser-cookie (SPBC)– Other key metrics should not impacted negatively, e.g. Abandonment
and retry rate, Daily Active Users (DAU), Revenue Per Search (RPS), etc.
138
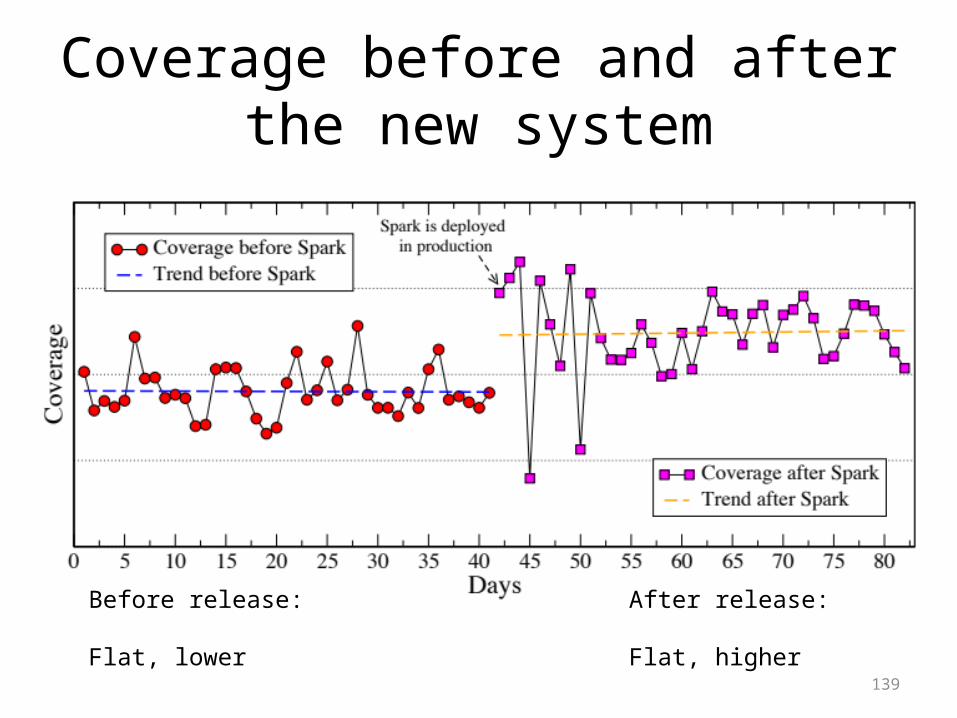
Coverage before and after the new system
Before release:
Flat, lower
After release:
Flat, higher139
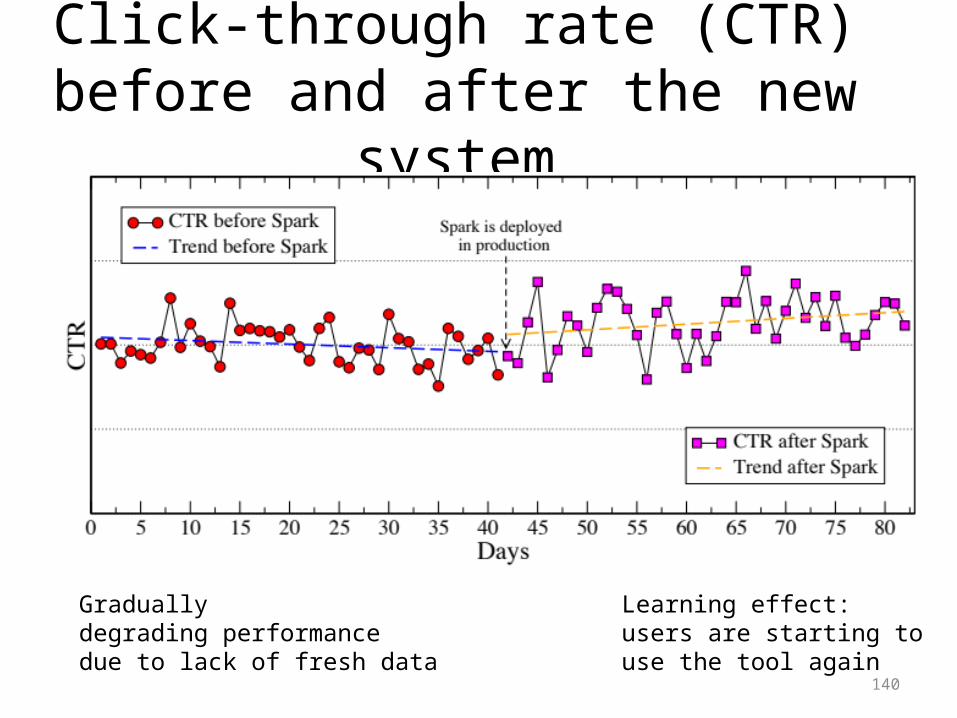
Click-through rate (CTR) before and after the new system
Before release:
Gradually degrading performance due to lack of fresh data
After release:
Learning effect:users are starting to use the tool again
140

Summary
• Spark– System for related entity recommendations
• Knowledge base • Extraction of signals from query logs and other user-
generated content• Machine learned ranking• Evaluation
• Other applications– Recommendations on topic-entity pages
141

Future work
• New query types– Queries with multiple entities
• adele skyfall
– Question-answering on keyword queries• brad pitt movies • brad pitt movies 2010
• Extending coverage– Spark now live in CA, UK, AU, NZ, TW, HK, ES
• Even fresher data– Stream processing of query log data
• Data quality improvements• Online ranking with post-retrieval features
142

TIME AND SEARCH
143

Web Search and time
• Information freshness adds constraints/tensions in every layer of WSEs
• Architecture • Crawling• Indexing• Distribution• Caching• Serving system
• Modeling• Time-dependent user intent• UI (how to let the user take control)
144

High-level Architecture of WSEs
Parser/Tokenizer
Indexterms
Cache QueryEngine
queries
Indexing pipeline
Runtime system
results
WWW WWW
145

Adding the time dimension
• Some solutions don’t scale up anymore• Review your architecture• Review your algorithms• Add more machines (~$$$)
• Some solutions don’t apply anymore• Caching
146

Evolution• 1999
• Index updated ~once per month• Disk-based updates/indexing
• 2001• In-memory indexes• Changes the whole-game!
• 2007• Indexing time < 1 minute• Accept updates while serving
• Now• Focused crawling, delayed transactions, etc.• Batch Updates -> Incremental processing
147

Some landmarks
• Reliable distributed storage• Some models/processes require millions of accesses
• Massive parallelization• Map/Reduce – Hadoop• Storm/S4 – Streaming• Hadoop 2.0 - YARN!
• Semi-structured storage systems• Asynchronous item updates
148
What’s going on “right now”?
149

Query temporal profiles
• Modeling• Time-dependent user intent• Implicitly time-qualified search queries
• SIGIR
• Dream theater barcelona
• Barcelona vs Madrid
• ….
• Interested in these tasks?• Joho et al. A survey of temporal Web experience, WWW 2013• Keep an eye on NTCIR next year!
150

Caching for Real-Time Indexes• Queries are redundant (heavy-tail) and bursty• Caching search results saves up executing ~30/60% of the queries
• Tens of machines do the work of 1000s
• Dilemma: Freshness versus Computation• Extreme #1: do not cache at all – evaluate all queries
• 100% fresh results, lots of redundant evaluations• Extreme #2: never invalidate the cache
• A majority of stale results – results refreshed only due to cache replacement, no redundant work
• Middle ground: invalidate periodically (TTL)• A time-to-live parameter is applied to each cached entry
151Blanco et al. SIGIR 2010

•Problem:•In fast crawling, cache not always up-to-date (stale)
•Solution: • Cache Invalidator Predictor - looks into new documents and invalidates queries accordingly
152
• Using synopsis reduces the number of refreshes up to 30% compared to a time-to-live baseline
CACHING FOR INCREMENTAL INDEXES

Time Aware ER
• In some cases the time dimension is available– News collections– Blog postings
• News stories evolve over time– Entities appear/disappear– Analyze and exploit relevance evolution
• An Entity Search system can exploit the past to find relevant entities
– De Martini et al. TAER: Time Aware Entity Retrieval. CIKM 2010,
153

Ranking Entities Over Time
Barack ObamaNaoto KanYokohamaBarack Obama
Takao SatoMichiko SatoKamakura
Barack ObamaUnited States
154

155
TIME EXPLORER

Time(ly) opportunities
Can we create new user experiences based on a deeper analysis and exploration of the time dimension?
• Goals:– Build an application that helps users to explore,
interact and ultimately understand existing information about the past and the future.
– Help the user cope with the information overload and eventually find/learn about what she’s looking for.
156

Original Idea• R. Baeza-Yates, Searching the Future, MF/IR 2005
– On December 1st 2003, on Google News, there were more than 100K references to 2004 and beyond.
– E.g. 2034: • The ownership of Dolphin Square in London must revert to an insurance company.• Voyager 2 should run out of fuel.• Long-term care facilities may have to house 2.1 million people in the USA.• A human base in the moon would be in operation.
157

Time Explorer
• Public demo since August 2010• Winner of HCIR NYT Challenge
• Goal: explore news through time and into the future
• Using a customized Web crawl from news and blog feeds
http://fbmya01.barcelonamedia.org:8080/future/
158
Matthews et al. HCIR 2010

Time Explorer
159

Time Explorer - Motivation Time is important to search Recency, particularly in news is highly related
to relevancy But, what about evolution over time?
How has a topic evolved over time? How did the entities (people, place, etc) evolve with respect to the topic over
time? How will this topic continue to evolve over the future? How does bias and sentiment in blogs and news change over time?
Google Trends, Yahoo! Clues, RecordedFuture …
Great research playground Open source!
160

161
Time Explorer

Analysis Pipeline Tokenization, Sentence Splitting, Part-of-
speech tagging, chunking with OpenNLP Entity extraction with SuperSense tagger Time expressions extracted with TimeML
Explicit dates (August 23rd, 2008) Relative dates (Next year, resolved with Pub Date)
Sentiment Analysis with LivingKnowledge Ontology matching with Yago Image Analysis – sentiment and face detection
162

Indexing/Search
• Lucene/Solr search platform to index and search– Sentence level– Document level
• Facets for annotations (multiple fields for faster entity-type access)
• Index publication date and content date –extracted dates if they exists or publication date
• Solr Faceting allows aggregation over query entity ranking and for aggregating counts over time
• Content date enables search into the future163
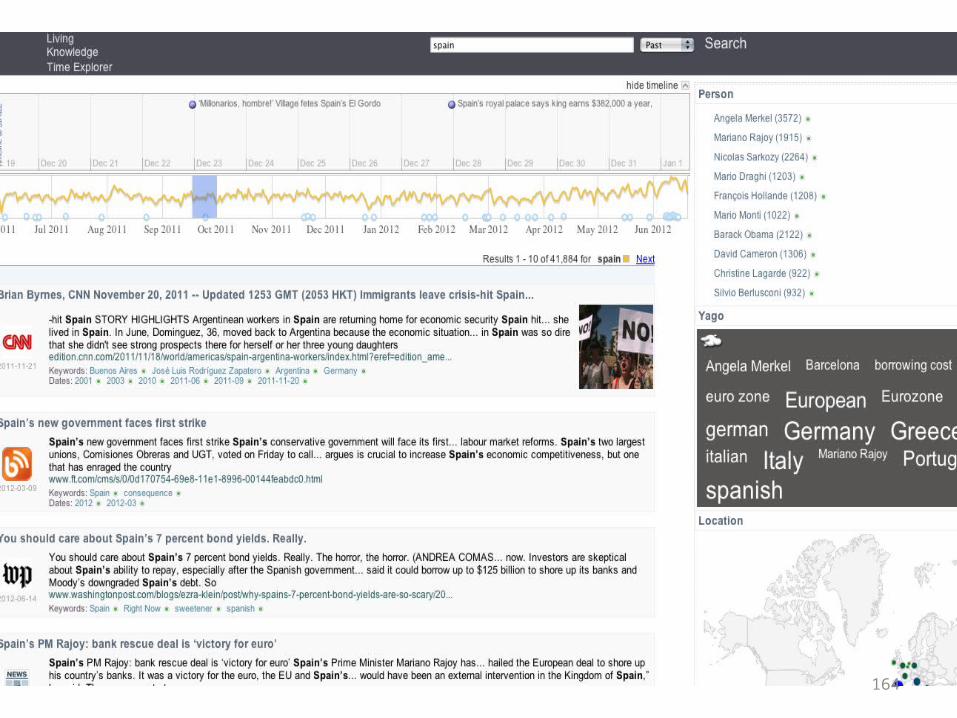
164

Timeline
165
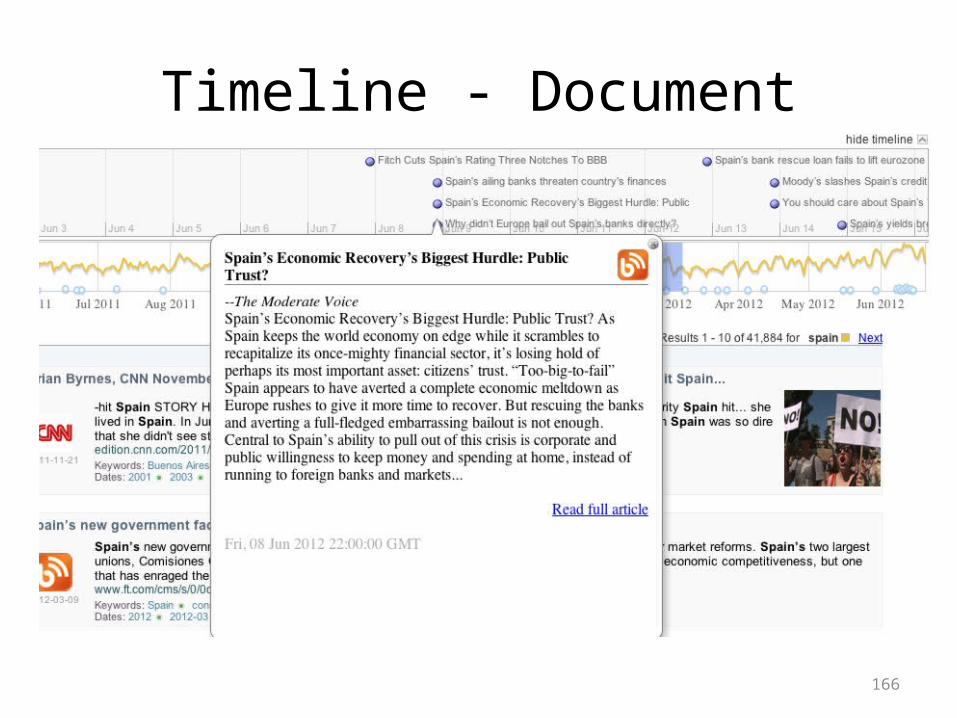
Timeline - Document
166

Entities (Facets)
167

Timeline – Entity Trend
168

Timeline – Future
169

Opinions
170

Quotes
171

Other challenges– Large scale processing
• Distributed computing• Shift from batch (Hadoop) to online (Storm)
– Efficient extraction/retrieval, algorithmic/data structures
• Critical for interactive exploration
– Connection with the user experience• Measures! User engagement?
– Personalization– Integration with Knowledge Bases (Semantic Web)– Multilingual
172
Related Documents











