Minimizing time risk in on-line bidding: An adaptive information retrieval based approach Anoop Verma a,⇑ , M.K. Tiwari b , Nishikant Mishra c a Department of Industrial Engineering, The University of Iowa, Iowa city, USA b Department of Industrial Engineering and Management, Indian Institute of Technology, Kharagpur, India c School of Management and Business, Aberystwyth University, SY23 3DD, UK article info Keywords: e-Bidding risks Corporate memory Information retrieval Genetic algorithm Nominal group technique abstract Knowledge is of prime importance, particularly for the individuals who are involved in e-business. A lot of energy and time is wasted by the individuals in seeking required knowledge and information. In order to facilitate the individuals with required information, an efficient technique for the proper retrieval of knowledge is must. Almost all online business activities, particularly e-auction based firms are sur- rounded by various risk factors pertaining to time, security, brand etc. The main focus of the present paper is to analyze all such risk factors and further to categorize the same as per their degree of influence. A nominal group technique (NGT) based approach has been utilized to do the same that ranks the risk factors using agreed criteria based approach. Further, the paper proposed an adaptive information retrie- val to resolve the problems related to time risk in online bidding process, while other risk factors has been tried to resolved by using corporate memory based data warehousing. Efficient knowledge retrieval along with the knowledge development and knowledge management became a backbreaking task for any organization. A corporate memory based approach has been utilized to represent the required knowledge stored in memory warehouse for its current and future usage. In underlying retrieval model, adaptiveness is achieved using genetic algorithm based matching function adaptation, where, a total of five matching functions viz. Jaccard’s coefficient, Overlap’s coefficient, Dice coefficient, Inclusion measure, and Cosine measures have been considered to determine the retrieval effectiveness. Later, effectiveness of informa- tion retrieval system is calculated in terms of well known parameters namely precision, recall, fallout and miss. Results of adaptive information retrieval using a weighted combination of matching functions are compared with individual matching functions. Ó 2010 Elsevier Ltd. All rights reserved. 1. Introduction Over the past few years, knowledge has been considered as one of the important entity, particularly for those, who are involved in e-business related activities. Almost all online business communi- ties store and disseminate a large amount of information during their daily conversation. Millions of dollars change hands daily through online auction markets. Online auctions attract thousands, sometimes millions of bidders who compete with each other for the items ranging from modern computer peripherals to antiques (Massad & Tucker, 2000). Internet being the sole and most impor- tant carriers for trading in online transactions such as online bidding process, transaction in e-enabled supply chain etc. Thus, trading partners can be feared of insecure transactions, as identity can be forged, nature of transactions can be altered, or website can be counterfeited. In addition, geographical diversity among the trading partners creates the unprecedented causes of fraud and consumers abuse. Companies such as e-bay, amazon.com have attracted the customers in a big way leading to better customer satisfaction, good reputation etc. However, various risk factors related to time, money, and personal information restrained the customers from the participation in the bidding process, thus, influences the turnover of such companies. To prevent such critical situations, these companies bear a lot of money to enforce sound security policies. The type of such risk factors in such firms arise when a customer registered for the a certain bid, as he may now feared of personal information that can be open for others, further, he may also be concerned about the product he intended to buy etc. Thus, it be- comes crucial for such companies to analyze and provide some effective means to minimize the effects of such risks that a cus- tomer may face while registering to them. In the present paper a 0957-4174/$ - see front matter Ó 2010 Elsevier Ltd. All rights reserved. doi:10.1016/j.eswa.2010.09.025 ⇑ Corresponding author. E-mail addresses: [email protected], [email protected] (A. Verma), [email protected] (M.K. Tiwari), [email protected] (N. Mishra). URLs: http://anoop.nifftian.googlepages.com (A. Verma), http://www.geocities. com/gurukul007 (M.K. Tiwari). Expert Systems with Applications 38 (2011) 3679–3689 Contents lists available at ScienceDirect Expert Systems with Applications journal homepage: www.elsevier.com/locate/eswa

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Expert Systems with Applications 38 (2011) 3679–3689
Contents lists available at ScienceDirect
Expert Systems with Applications
journal homepage: www.elsevier .com/locate /eswa
Minimizing time risk in on-line bidding: An adaptive information retrievalbased approach
Anoop Verma a,⇑, M.K. Tiwari b, Nishikant Mishra c
a Department of Industrial Engineering, The University of Iowa, Iowa city, USAb Department of Industrial Engineering and Management, Indian Institute of Technology, Kharagpur, Indiac School of Management and Business, Aberystwyth University, SY23 3DD, UK
a r t i c l e i n f o a b s t r a c t
Keywords:e-Bidding risksCorporate memoryInformation retrievalGenetic algorithmNominal group technique
0957-4174/$ - see front matter � 2010 Elsevier Ltd. Adoi:10.1016/j.eswa.2010.09.025
⇑ Corresponding author.E-mail addresses: [email protected], verma
[email protected] (M.K. Tiwari), [email protected]: http://anoop.nifftian.googlepages.com (A. V
com/gurukul007 (M.K. Tiwari).
Knowledge is of prime importance, particularly for the individuals who are involved in e-business. A lot ofenergy and time is wasted by the individuals in seeking required knowledge and information. In order tofacilitate the individuals with required information, an efficient technique for the proper retrieval ofknowledge is must. Almost all online business activities, particularly e-auction based firms are sur-rounded by various risk factors pertaining to time, security, brand etc. The main focus of the presentpaper is to analyze all such risk factors and further to categorize the same as per their degree of influence.A nominal group technique (NGT) based approach has been utilized to do the same that ranks the riskfactors using agreed criteria based approach. Further, the paper proposed an adaptive information retrie-val to resolve the problems related to time risk in online bidding process, while other risk factors hasbeen tried to resolved by using corporate memory based data warehousing. Efficient knowledge retrievalalong with the knowledge development and knowledge management became a backbreaking task for anyorganization. A corporate memory based approach has been utilized to represent the required knowledgestored in memory warehouse for its current and future usage. In underlying retrieval model, adaptivenessis achieved using genetic algorithm based matching function adaptation, where, a total of five matchingfunctions viz. Jaccard’s coefficient, Overlap’s coefficient, Dice coefficient, Inclusion measure, and Cosinemeasures have been considered to determine the retrieval effectiveness. Later, effectiveness of informa-tion retrieval system is calculated in terms of well known parameters namely precision, recall, fallout andmiss. Results of adaptive information retrieval using a weighted combination of matching functions arecompared with individual matching functions.
� 2010 Elsevier Ltd. All rights reserved.
1. Introduction
Over the past few years, knowledge has been considered as oneof the important entity, particularly for those, who are involved ine-business related activities. Almost all online business communi-ties store and disseminate a large amount of information duringtheir daily conversation. Millions of dollars change hands dailythrough online auction markets. Online auctions attract thousands,sometimes millions of bidders who compete with each other forthe items ranging from modern computer peripherals to antiques(Massad & Tucker, 2000). Internet being the sole and most impor-tant carriers for trading in online transactions such as onlinebidding process, transaction in e-enabled supply chain etc. Thus,
ll rights reserved.
[email protected] (A. Verma),(N. Mishra).
erma), http://www.geocities.
trading partners can be feared of insecure transactions, as identitycan be forged, nature of transactions can be altered, or website canbe counterfeited. In addition, geographical diversity among thetrading partners creates the unprecedented causes of fraud andconsumers abuse. Companies such as e-bay, amazon.com haveattracted the customers in a big way leading to better customersatisfaction, good reputation etc. However, various risk factorsrelated to time, money, and personal information restrained thecustomers from the participation in the bidding process, thus,influences the turnover of such companies. To prevent such criticalsituations, these companies bear a lot of money to enforce soundsecurity policies.
The type of such risk factors in such firms arise when a customerregistered for the a certain bid, as he may now feared of personalinformation that can be open for others, further, he may also beconcerned about the product he intended to buy etc. Thus, it be-comes crucial for such companies to analyze and provide someeffective means to minimize the effects of such risks that a cus-tomer may face while registering to them. In the present paper a

3680 A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689
Nominal group technique (NGT) based approach has been utilizedto rank the concerned risk factors in online bidding process. In realworld scenario, companies facilitate the users to access huge lumpof information about the products that a certain user is indented tobuy. With the presence of such a vast array of data, it becomes dif-ficult for the users to sort out the information that he actuallyneeds. In such situations it is imperative for companies to improvisesome effective means so that users’ can effectively search their re-quired information without wasting much of their time. In generalusers put their information need in the form of query and furtherinformation retrieval system sort out most similar documents aftermatching the whole document set with the query. The process ofinformation retrieval in the form of documents continues till useris unsatisfied with the retrieved documents. Effective retrieval liesin the ease with which the documents are stored in the company’sdatabase. As, in the system and surrounding data flows in unfor-matted and variegated form, thus, it is imperative for such compa-nies to properly filter and format the data, information, records etc.to make it available for efficient retrieval. In the literature, the term‘‘Corporate memory” has been extensively used by the researchersand analysts to represent the stored knowledge in the formattedform (Ballay & Poitou, 1996; Heijst, Spek, & Kruizinga, 1996; Huang,Tseng, & Kusiak, 2005; Kuhn & Abecker, 1997; Simon & Grandba-stein, 1995). The document formatting in corporate memory is per-formed offline, while the retrieval process (includes queryformatting and matching process) is performed online (Pathak, Gor-don, & Fan, 2000). In information retrieval matching among thedocuments and queries has been performed by using benchmarkmatching functions that explores the similarity between the docu-ments and queries on the basis of criteria such as document length,position of keyterms in the document, frequency of keyterms etc.(Pathak et al., 2000; Saltan & Buckley, 1990). The purpose of thepresent paper is to study the risk factors related to online biddingprocess and further to provide some effective means to minimizethe effect of same. Our main consideration includes the following.
1. Our analysis is based on a generic study of risk factors, whichassumes that� Before implementing some means to minimize the effects of
underlying risk factors, it is worth considering determiningthe critical risk factor among the available alternatives.
� Degree of influence of risk factors in online business commu-nities depend upon the type of user, type of product that anuser is intended to buy, type of bidding process etc.
2. For effective information retrieval, genetic algorithm isemployed in two phase viz. (1) To determine a set of relevantdocuments that meet the user’s need, and (2) To determine aset of possible combination of weights for the benchmarkmatching functions, here, adaption is achieved in secondphase.
3. All possible information retrieval effectiveness parameters viz.precision, fallout, recall, and miss have been considered in orderto realize the performance of information retrieval.
We organize the paper as follows: In Section 2, description of on-line bidding process with the analysis of risk factors is considered,further, a group decision making approach is also performed here.It is followed by the detailed insight of Corporate memory that alsoincludes the different memory management schemes, given in Sec-tion 3. In Section 4, description of basic information retrieval andimplementation steps are given. Next section (i.e. Section 5) is de-voted to the detail the solution methodology vis-a-vis the underly-ing problem. In Section 6, problem generation scheme and furtherthe experimental details of underlying research is elaborated.Lastly, Section 7 concludes the present research with some linesof its future applications.
2. Online bidding process
Auction is an economic incentive mechanism that determinesthe price of an item to buy or sell (Huang, Tseng, & Kusiak,2002). This process requires the involvement of one or more bid-ders who want the item, and an item for sale to the highest bidder.Online auction is done through internet, where, a web page used todisplay information regarding goods or services along with theinformation to sell them.
Traditional auctions have some information deficiencies, asthey last only for a few minutes for each item sold. In this auctiontype, both sellers and bidders may not get what they actually want.With the advancement in the information technology, auction canbe performed via internet, thus, overcoming the difficulties relatedto available information. Trading on the internet has severaladvantages, given as:
� It is independent of the geographic location.� Business settlement will be in shorter time with lower overhead
cost.� It can support a great range of potential bidders.� It provides an infrastructure for executing auctions and bids
more cheaply.
2.1. Analysis of risk factors in online bidding
As stated earlier, trading in online business firms is morespeculative rather comfortable, due to chance of loss of personalinformation, poor quality product etc. Apart from free price infor-mation, online auction is full of several risks associated withbuyers, sellers, auctioneers etc. In the literature, researchers haveidentified several risk factors prevailed in online bidding process,description of which is given as (Massad & Tucker, 2000).
1. Time risk: This risk factor is mainly confined with the bidders orbuyers, since, they requires a lot of information pertaining toproduct which they are intended to buy. This risk type is verycommon in day-to-day activities as buyers are generally una-ware of products and their associated search mechanisms.
2. Security risk: This aspect of bidding risk has influenced much ofthis trade as due to loss of information such as credit card num-bers etc.
3. Vendor’s risk: Another type of risk that reside inside every buy-ers is regarding the authority of auction and the product theyintended to buy.
4. Brand risk: This risk factor is mainly concerned with the authen-ticity of the product obtained by the buyers or bidders. Buyersmay feel cheated by the type of product, which they receivedafter winning the bid.
5. Privacy risk: The risk of loss of personal information such asaddress, email id, personal contacts etc. comes under the pur-view of privacy risk.
6. Price collusion: Contrary to all previously explained risk factors,price collusion affects the sellers. This risk factor is prevalent inopen-bid type of auctions, where, every registered bidder cancontact with the other registered bidders with the help of avail-able information and conspire to deflate the price of the con-cerned product.
As compared with traditional in person bidding, the frequencyand impact of these risk factors are more severe in online biddingprocess. It can be justified from the fact that the number of fraud-ulent cases in online bidding are increasing almost exponentiallyas each year passes. In order to represent the severity of risk factorsin online bidding process, a comparative analysis of risk factors hasbeen shown in Fig. 1.
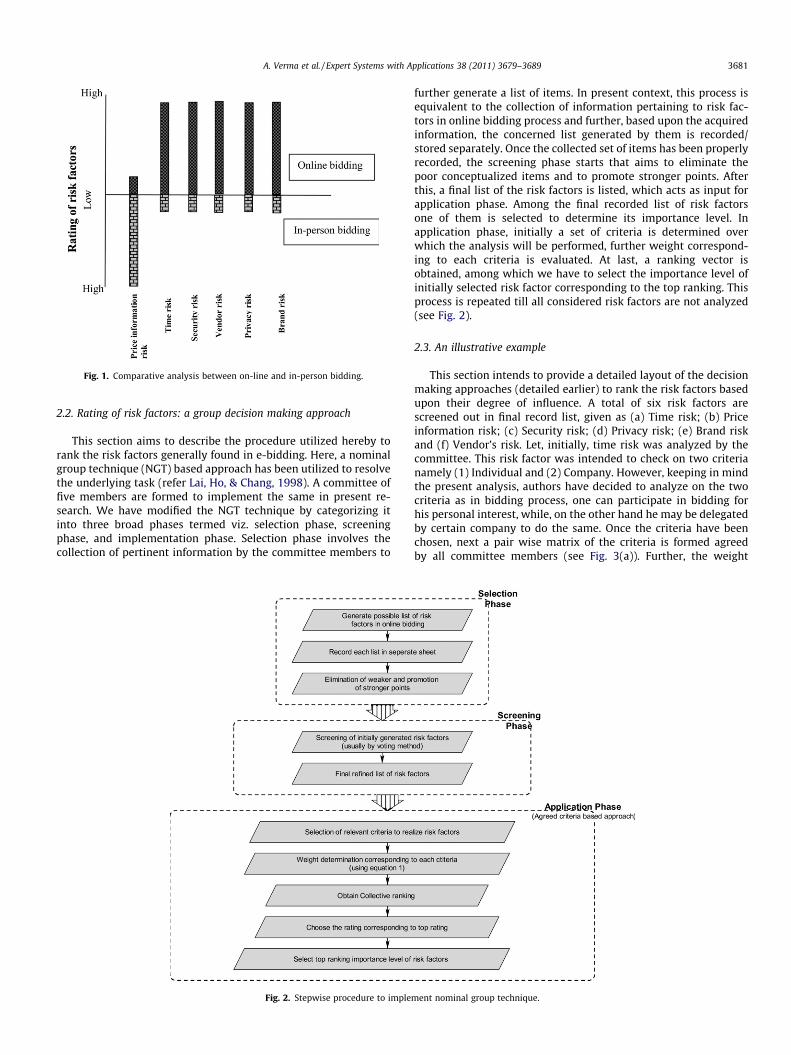
Fig. 1. Comparative analysis between on-line and in-person bidding.
A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689 3681
2.2. Rating of risk factors: a group decision making approach
This section aims to describe the procedure utilized hereby torank the risk factors generally found in e-bidding. Here, a nominalgroup technique (NGT) based approach has been utilized to resolvethe underlying task (refer Lai, Ho, & Chang, 1998). A committee offive members are formed to implement the same in present re-search. We have modified the NGT technique by categorizing itinto three broad phases termed viz. selection phase, screeningphase, and implementation phase. Selection phase involves thecollection of pertinent information by the committee members to
Fig. 2. Stepwise procedure to implem
further generate a list of items. In present context, this process isequivalent to the collection of information pertaining to risk fac-tors in online bidding process and further, based upon the acquiredinformation, the concerned list generated by them is recorded/stored separately. Once the collected set of items has been properlyrecorded, the screening phase starts that aims to eliminate thepoor conceptualized items and to promote stronger points. Afterthis, a final list of the risk factors is listed, which acts as input forapplication phase. Among the final recorded list of risk factorsone of them is selected to determine its importance level. Inapplication phase, initially a set of criteria is determined overwhich the analysis will be performed, further weight correspond-ing to each criteria is evaluated. At last, a ranking vector isobtained, among which we have to select the importance level ofinitially selected risk factor corresponding to the top ranking. Thisprocess is repeated till all considered risk factors are not analyzed(see Fig. 2).
2.3. An illustrative example
This section intends to provide a detailed layout of the decisionmaking approaches (detailed earlier) to rank the risk factors basedupon their degree of influence. A total of six risk factors arescreened out in final record list, given as (a) Time risk; (b) Priceinformation risk; (c) Security risk; (d) Privacy risk; (e) Brand riskand (f) Vendor’s risk. Let, initially, time risk was analyzed by thecommittee. This risk factor was intended to check on two criterianamely (1) Individual and (2) Company. However, keeping in mindthe present analysis, authors have decided to analyze on the twocriteria as in bidding process, one can participate in bidding forhis personal interest, while, on the other hand he may be delegatedby certain company to do the same. Once the criteria have beenchosen, next a pair wise matrix of the criteria is formed agreedby all committee members (see Fig. 3(a)). Further, the weight
ent nominal group technique.
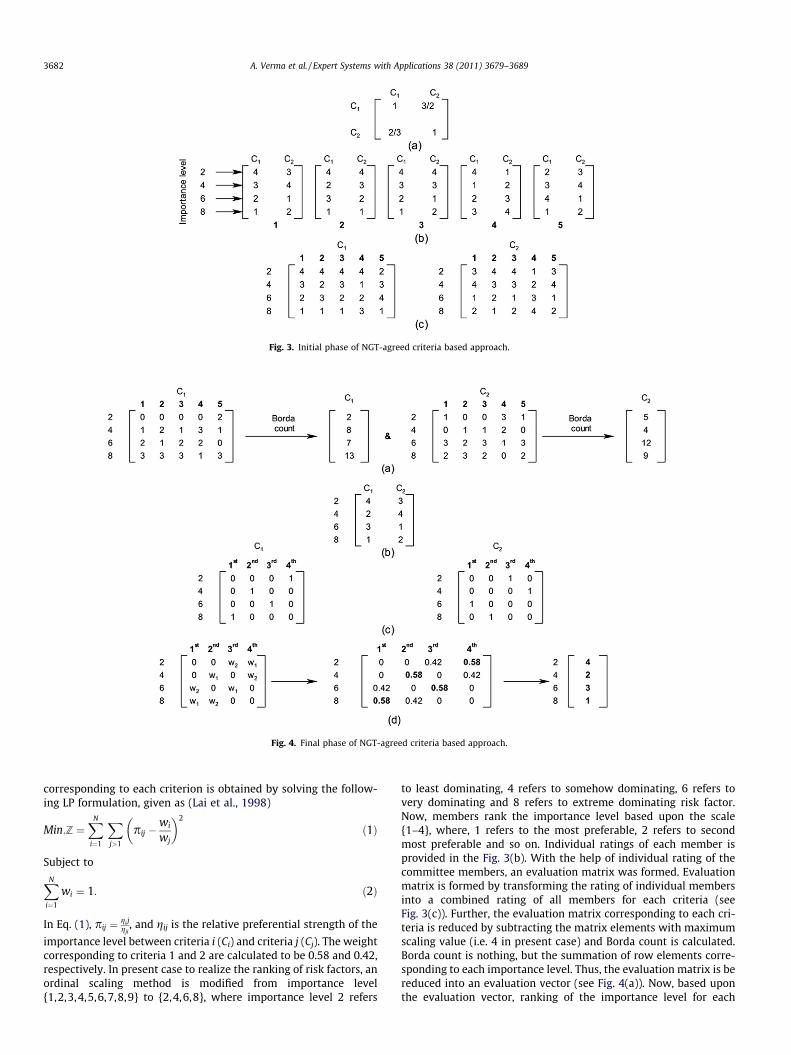
Fig. 3. Initial phase of NGT-agreed criteria based approach.
Fig. 4. Final phase of NGT-agreed criteria based approach.
3682 A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689
corresponding to each criterion is obtained by solving the follow-ing LP formulation, given as (Lai et al., 1998)
Min:Z ¼XN
i¼1
Xj>1
pij �wi
wj
� �2
ð1Þ
Subject to
XN
i¼1
wi ¼ 1: ð2Þ
In Eq. (1), pij ¼ gi jgji
, and gij is the relative preferential strength of the
importance level between criteria i (Ci) and criteria j (Cj). The weightcorresponding to criteria 1 and 2 are calculated to be 0.58 and 0.42,respectively. In present case to realize the ranking of risk factors, anordinal scaling method is modified from importance level{1,2,3,4,5,6,7,8,9} to {2,4,6,8}, where importance level 2 refers
to least dominating, 4 refers to somehow dominating, 6 refers tovery dominating and 8 refers to extreme dominating risk factor.Now, members rank the importance level based upon the scale{1–4}, where, 1 refers to the most preferable, 2 refers to secondmost preferable and so on. Individual ratings of each member isprovided in the Fig. 3(b). With the help of individual rating of thecommittee members, an evaluation matrix was formed. Evaluationmatrix is formed by transforming the rating of individual membersinto a combined rating of all members for each criteria (seeFig. 3(c)). Further, the evaluation matrix corresponding to each cri-teria is reduced by subtracting the matrix elements with maximumscaling value (i.e. 4 in present case) and Borda count is calculated.Borda count is nothing, but the summation of row elements corre-sponding to each importance level. Thus, the evaluation matrix is bereduced into an evaluation vector (see Fig. 4(a)). Now, based uponthe evaluation vector, ranking of the importance level for each

Table 1Final ranking of the risk factors.
RF Importance level Ranking
Time risk 08 1Security risk 06 2Privacy risk 06 2Brand risk 04 4Vendor risk 04 4Price information risk 02 6
Fig. 5. Corporate memory development process.
Fig. 6. A sample document stored in corporate memory.
A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689 3683
criteria is calculated. Here, top ranking corresponds to the impor-tance level having highest Borda count (see Fig. 4(b)). If more thanone importance level has same Borda count then an average ratingis assigned to each importance level. The importance level rating ofeither criteria is converted into two binary matrix, where 1 is placedto the position given by rating matrix and 0 is placed in otherremaining sites (see Fig. 4(c)). If more than one importance levelhas same rating then its corresponding binary ranking matrix willbe having value 1 more than one places. Further, on the basis ofcontribution of each criteria, a combined agreement matrix is calcu-lated and ranking of importance level is replaced by the weight ofthe criteria (calculated earlier). At last, with the help of combinedagreement matrix, the final ranking vector of each importance levelis evaluated (see Fig. 4(d)).
In a similar fashion, the rating of other risk factors can be calcu-lated. After calculating the importance level of each considered riskfactors, corresponding to their top ranking, the dominance levelwas pointed out (see Table 1). It can be easily perceived from thetable that time risk factor was found to be most dominant amongall considered factors and price information risk was the leastdominant. Now, with the help of aforementioned information, itis easy for the concerned company executives or decision makersto control the influence of such critical risk factors. In the presentpaper, special consideration has been given to minimize time riskby using adaptive information retrieval scheme (detailed in Section4), while other less critical risk factors are taken care using corpo-rate memory based data warehousing, detailed in followingsection.
3. Corporate memory
In the simple language, an explicit, disembodied representationof knowledge is termed as ‘‘Corporate memory.” The characteristicfeatures of corporate memory can be given as (Dieng, Corby,Giboin, & Ribiere, 1999):
� The corporate memory is, by nature, a heterogeneous anddistributed information landscape.� The population of the users of the memory is, by nature,
heterogeneous and distributed in the corporation.
� The tasks, as a whole, to be performed on the corporate memoryare, by nature, distributed and heterogeneous.
Various events, activities acts as a raw source of information todevelop a corporate memory, which further undergoes filtration toseparate the extraneous information. Now, the filtered informationis formatted using XML transformation mechanism to store intocorporate memory based warehouse. A part of this information isfurther disseminates into the surroundings, which again acts as araw source for further upgradation of corporate memory (seeFig. 5). In almost all the cases, it is the formatting mechanism ofinformation that decides the efficiency of any storage media. Re-cently, eXtensible Markup Language (XML) emerged as one of mostcomprehensive way to represent the information essential or crit-ical to certain industry or organization. XML is a data standard thatincreases efficiency of the Web operations by reducing the networktraffic and allowing intelligent search (Huang et al., 2005). Now-a-days XML became an industry standard for exchanging data, and,also it can be used to build the structure of the corporate memory.The key characteristics of XML includes.
� Ability to extract data from a document.� It has no specific tags, therefore, one can define tags and label
according to his choice.� Ability to define data structures and documents to any level of
complexity.
Inspired from the aforementioned characteristics features ofXML, we have incorporated the same to format the filtered infor-mation to store in the corporate memory based warehouse. A sam-ple description of one such document stored in corporate memoryis provided in Fig. 6.
3.1. Role of corporate memory in e-bidding
e-bidding is considered to be one of the important businessactivity that is marked with the generation of huge quantities ofknowledge and information. The generated knowledge can be ofworth importance, if properly stored and managed. The knowledgecan be easily handled by establishing a memory warehouse thatstores the information in an explicit manner, so that every usercan extract the information conveniently. For such online business

Fig. 7. Cyclic representation of corporate memory management (CMM) steps.
1 The function of maintenance includes both, omission and insertion.
3684 A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689
activity, corporate memory may serves as an intelligent storagemedia to the users seeking for the bid related information and alsocan process both formal and non-formal knowledge elements in atask oriented way. In the context of e-bidding, a proper co-ordina-tion is required among the concerned entities i.e. bidders, suppliersand auctioneers to effectively operate the underlying process.
3.1.1. Steps to corporate memory managementThe task of corporate memory management is more complex
and time consuming than the storage of knowledge in corporatememory. It involves the maintenance and possible up-gradationof knowledge, while considering the overall capacity of memorywarehouse. The overall management of corporate memory includesfive related steps that should be analyzed in a hierarchy. The keyobjective of corporate memory management (CMM) is to ensurethat right knowledge is available at a right time to expedite the re-trieval process. We consider the corporate memory management asthe cyclic process, in which each key steps are cyclically interlinkedwith each other (see Fig. 7). The description of steps of memorymanagement vis-a-vis the underlying problem is given below:
1. Detection in need of corporate memory: This steps gives an insightof the objective considered in order to develop a corporatememory. The need detection is not an easy task, as there canbe various factors such as user’s type, environment, and knowl-edge type that can influence the detection process. To establisha good relationship between the buyers and sellers, a propercoordination among them is required, here, this factor has beenconsidered as the objective for the need of corporate memory.
2. Construction of corporate memory: Once the need of corporatememory has been find out, the next question arise about theconstruction of corporate memory. Raw materials for the con-struction of corporate memory may include the file documents,human resources, email, events, activities etc. Since, all theseraw-materials are of different styles, therefore in order to storethem, a homogeneous formatting is required that enables theusers to understand the stored knowledge. Moreover, the con-struction of corporate memory depends upon the recognitionof corporate memory as one of existing standard memory type,given as:
(a) Document based corporate memory (Kuhn & Abecker,1997);
(b) Non-computational corporate memory (Simon, 1996);(c) Case-based corporate memory (Simon & Grandbastein,
1995);(d) Knowledge based corporate memory (Ballay & Poitou,
1996);(e) Distributed corporate memory (O’Leary, 1997).
3. Distribution and use of corporate memory: This steps of corporatememory management decides about the personnel or groupswho may be able to use or retrieve required knowledge fromthe memory warehouse. Memory distribution can be done infollowing two ways:(a) Active distribution: If an user itself search for the required
knowledge from the memory warehouse, the distributionwill be termed as an active distribution.
(b) Passive distribution: If a user wants the required knowledgeto be transferred in his personnel account or database, thenthe distribution will be called as passive distribution.
Both type of distributions has its importance, suppose if anyuser is much busy in other work, he will prefer passive typeof memory distribution. On the other hand, if user is not sureabout the type of knowledge required by him, he would liketo search the memory database by self then sort out themost suitable information among the searched information.On the basis of collection and distribution, Heijst et al.(1996) have identified the following key terms:
� Knowledge Attic: Both, collection and distribution of knowl-edge are passive;
� Knowledge Publisher: Passive collection, but, distribution isactive;
� Knowledge Sponge: Active collection and passive diffusion;� Knowledge Pump: Both, collection and distribution of knowl-
edge is active.4. Evaluation of corporate memory: Once the problem regarding the
distribution of corporate memory has been solved, the nextquestion arise is how far the distributed knowledge is able tomeet or match with the users query. In this steps, performanceof corporate memory can be evaluated by receiving feedbackfrom the users.
5. Maintenance1 of corporate memory: It is one of the most criticalfactor of the corporate that deals with the possible up-gradationof corporate memory in order to refrain the database to over-flow, and to include newly generated knowledge. The followingpoints has been considered while upgrading the information inmemory warehouse.� The insertion of new knowledge elements into the active
phase of the corporate memory requires correspondingupdates in the passive corporate memory.
� Task modifications which the corporate memory shall sup-port have to be reflected by adaptations of the relevancedescriptions.
� The corporate memory should be continuously tuned inorder to better match users needs. As already mentioned,the on-line auction is characterized by the transformationof millions of data in its daily conversation. Thus, itbecomes very difficult task for the knowledge manager tomanage and maintain the information. Thus, to avoid thisundesirable situation, compartmentalization of corporatememory has also been done. We have divided the corporatememory into two parts. The function and usage of whichare given as,

Fig. 9. Possible cases of maintenance policies.
A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689 3685
(a) Active corporate memory (ACM): Contains the format-ted and upgrated knowledge, can be called as freshstorage of knowledge.
(b) Passive corporate memory (PCM): Contains the unfor-matted and redundant knowledge from ACM, can becalled as dead storage of knowledge.
The concept of PCM has been generated so as to avoid the deletionof outdated/redundant information that can further be utilized. Asthe information in PCM is stored in unformatted form, thereforeresults no additional cost of maintenance. The aforementioned cor-porate memory type are interlinked with each other in the way it isupgrated (see Fig. 8). According to Holan and Phillips (2004), orga-nizational forgetting is necessary. Keeping their fact in mind, thepassive corporate memory has been conceptualized that reflectsthe forgetting part of organizational memory. In the following sec-tion, a detailed description of the maintenance policies is provided.
3.1.2. Maintenance policiesIn the present paper, two different maintenance policies viz.
time based maintenance and activity based maintenance havebeen used. Time based maintenance corresponds to knowledgeup-gradation in a finite period of time. While, activity based main-tenance is the maintenance of memory warehouse after the com-pletion of certain activity. In the on-line bidding scenario, anactivity corresponds to the bidding process of certain product,and after completion of each bidding process, the company’s cor-porate memory is being up-gradated. If D1 be the end time of anactivity, and D2 be the time slot for the time based maintenancepolicy, then the following three cases will be found, dependingupon the difference between the completion time of either policies,such that D = D1 � D2
D P 0ði:e: D1 > D2Þ; ð3ÞD ¼ 0ði:e: D1 ¼ D2Þ; ð4ÞD 6 0ði:e: D1 < D2Þ: ð5Þ
D1 being constant in nature, while D2 is continuously varied,depending upon the completion time of underlying activity. (Inpresent analysis, equivalent to completion time a bidding process.)The dynamic nature of activity based maintenance accompanieswith higher maintenance cost, as compared with time based main-tenance, also the completion of an activity results in dissemination
Fig. 8. A possible linkage between active and passive corporate memory.
of huge amount of pertinent information that is required to bestored. Thus, while selecting the maintenance scheme to upgradethe corporate memory, both of the afore-mentioned points mustbe considered. The different cases shown above are graphically ci-ted in the Fig. 9.
4. Information retrieval system
The contribution in the field of information retrieval domain ismainly categorized on the basis of solution methodologies em-ployed to achieve certain objectives. Solution methodologies thatare prevalent is information retrieval are:
� Probabilistic information retrieval (Fuhr & Buckley, 1991; Gor-don, 1988).� Knowledge based information retrieval (Chen & Dhar, 1991).� Learning based information retrieval (Chen, 1995; Yang & Kor-
fhage, 1993).
A detailed description of afore-mentioned information retrievalparadigms can be found in Pathak et al. (2000). As stated earlier, angenetic algorithm based search technique is employed in the pres-ent research, thus our work fits well in learning systems basedinformation retrieval. In the following subsection, a descriptionof basic information retrieval is provided.
4.1. Basic information retrieval system
Information retrieval refers to the process by which one can re-trieved the desired information after assigning certain query. Ingeneral, any information retrieval system comprises of threeessential elements viz. document representation, query represen-tation and a matching function. Document representation refersto the format in which the documents are stored in the company’sdatabase. Document formatting is very crucial part of any retrievalprocess, since in system and surroundings, documents are gener-ally found in variegated and unformatted form as images, notepadsetc. Thus document representation aims to transform the diversedocuments into homogeneous and standard format. Owing to largepile up of documents, the process of document representation isgenerally performed offline, same procedure is utilized for thequery representation, except the difference that query formatting

Fig. 10. Basic information retrieval system.
Fig. 11. Platform for information retrieval process.
3686 A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689
is performed offline. A matching function acts as a nexus betweenthe documents and query, which on the basis of some criteriamatch the query content with the stored set of documents. Ininformation retrieval system, matching function is applied to re-trieve a set of most similar documents on the basis of score gainedby the documents. Further, based upon the user’s feedback, eitherthe query is further modified or user will be satisfied with the cur-rently retrieved document set. The afore-mentioned concepts isshown in the information retrieval framework (see Fig. 10).
4.2. Inside details of information retrieval system
In this section, we describe the overall procedure utilized hereto perform various retrieval tasks. For the present case, we haveadopted a binary representation model where each query/docu-ment is stored in the form of string containing value 0 or 1. Instring 1 corresponds to the case, if certain keyterm is found inquery/document, 0 otherwise. A platform to execute present retrie-val task is given in Fig. 11. Fig. 11(a) shows the total set of conceptsconsidered here for the retrieval process, which forms as a basis torepresent the documents/queries, a description of set of queriesformed from the total key terms are provided in Fig. 11(b). Searchprocess cannot be started unless some mechanism to match thequery with document is provided. Matching function plays a vitalrole in deciding the retrieval efficiency. For the present case, a total
of five matching functions have been considered to analyze the re-trieval process, detailed as:
– Jaccard’s coefficient: This matching function measures thedegree of overlap between the two documents or one docu-ments and a query as a ratio of their overlap from the whole.Let X and Y be two documents require for matching, thusaccording to Jaccard’s coefficient their matching function willbe � X\Y
X[Y
� �. More generally, similarity among documents in a Jac-
card matching function can be defined as:
SimJaccardðD;QÞ ¼jD� Q j
jDj þ jQ j � jD� Q j : ð6Þ
– Dice’s coefficient: This coefficient measures the degree of overlapbetween document and query by estimating their average size,defined as:
SimdiceðD;QÞ ¼jD� Q j
1=2ðjDþ Q jÞ : ð7Þ
– Overlap coefficient: This function simply determines the degreeof overlap between the concerned documents (i.e. documentand a query), defined as:
SimoverlapðD;QÞ ¼jD� Q j
min:ðjDj; jQ jÞ : ð8Þ
– Cosine measure: According to this matching function, the degreeof overlap between two documents can be defined geometri-cally as the cosine of angle between document and a query,defined as:
SimcosineðD;QÞ ¼jD� Q jffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffijDj
ffiffiffiffiffiffiffijQ j
pq : ð9Þ
– Inclusion measure: As the name suggest, inclusion measuredetermines the degree in which one document is covered byother. It measures the proportion of commonality betweentwo documents with the initial one, can be represented as:
SiminclusionðD;QÞ ¼jD� Q jjDj : ð10Þ
With the help of aforementioned matching functions, an overallobjective has been calculated that is the weighted combinationof individual matching functions. Weight corresponding to eachmatching function shows the relative importance of the match-ing functions. Higher weight corresponding to a matching func-tion is equal to greater preference and vice versa. In the presentcase, a genetic algorithm based solution methodology has been

X ¼
A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689 3687
utilized to decide the weight corresponding to each matchingfunction. The overall weighted function can be calculated as:
ðx1 � JaccardÞ þ ðx2 � OverlapÞ þ ðx1 � DiceÞ þ ðx4 � InclusionÞ þ ðx5 � CosineÞx1 þx2 þx3 þx4 þx5
: ð11Þ
In Eq. (11), X is the overall weighted score, and xi (i = 1–5) cor-responds to the weight associated with individual matchingfunctions.
In real world scenario, it is almost impossible to get all retrieveddocuments that can be considered as totally relevant, means a frac-tion of retrieved documents does not seem to be relevant to theusers. Also, on the other hand it is also impossible to retrieve allset of documents that can be relevant for the users. Thus, depend-ing upon the relevancy and precision required by the users, param-eters such as precision, recall has been widely used in the literature(Pathak et al., 2000). The following set of notations are required todescribe the terms mentioned above.
retD: Set of retrieved documents;�retD: Set of non-retrieved documents;relD: Set of relevant documents;�relD: Set of non-relevant documents.
Precision is defined as ratio of retrieved documents that are rele-vant to the total retrieved documents, as:
P ¼ retD \ relDj jjretDj
: ð12Þ
Recall is defined as ratio of retrieved documents that are relevant tothe total relevant documents, as:
R ¼ retD \ relDj jjrelDj
: ð13Þ
Another two related parameters that can be also utilize to analyzethe retrieval efficiency are fallout and miss, which are defined as:
Fig. 12. The stepwise procedure of geneti
Fallout is the ratio of retrieved documents that are non-relevantto the total non-relevant documents, as:
F ¼ retD \ �relDj jj � relDj
: ð14Þ
Miss is the ratio of relevant documents that are not retrieved to thetotal not retrieved documents, as:
M ¼ �retD \ relDj jj � retDj
: ð15Þ
The ideal condition of retrieval with precision ðPÞ and Recall ðRÞ va-lue equal to unity, whereas, fallout ðFÞ and miss ðMÞ value equal tozero. It is worth mentioning that our model will work only when re-trieved documents are available with the users. However, the num-ber of retrieved and relevant documents are users definedparameters, where, number of retrieved documents are decidedon the basis of document cut off values (DCV).
In the following section, a detailed description of underlyingsolution methodology is provided.
5. Algorithmic details
A Genetic Algorithm is an ‘intelligent’ probabilistic search algo-rithm that simulates the process of evolution by taking a popula-tion of solutions and applying genetic operators in eachreproduction. Each solution in the population is evaluated accord-ing to some fitness measure. Fitter solutions in the population areused for reproduction. New offspring’ solutions are generated andunfit solutions in the population are replaced. The cycle of evalua-tion–selection–reproduction is continued until a satisfactory solu-tion is found Goldberg (1989) and Michalewicz (1994). Holland(1975) introduced genetic algorithms which, later on, were appliedto a wide variety of problems.
c algorithm for information retrieval.
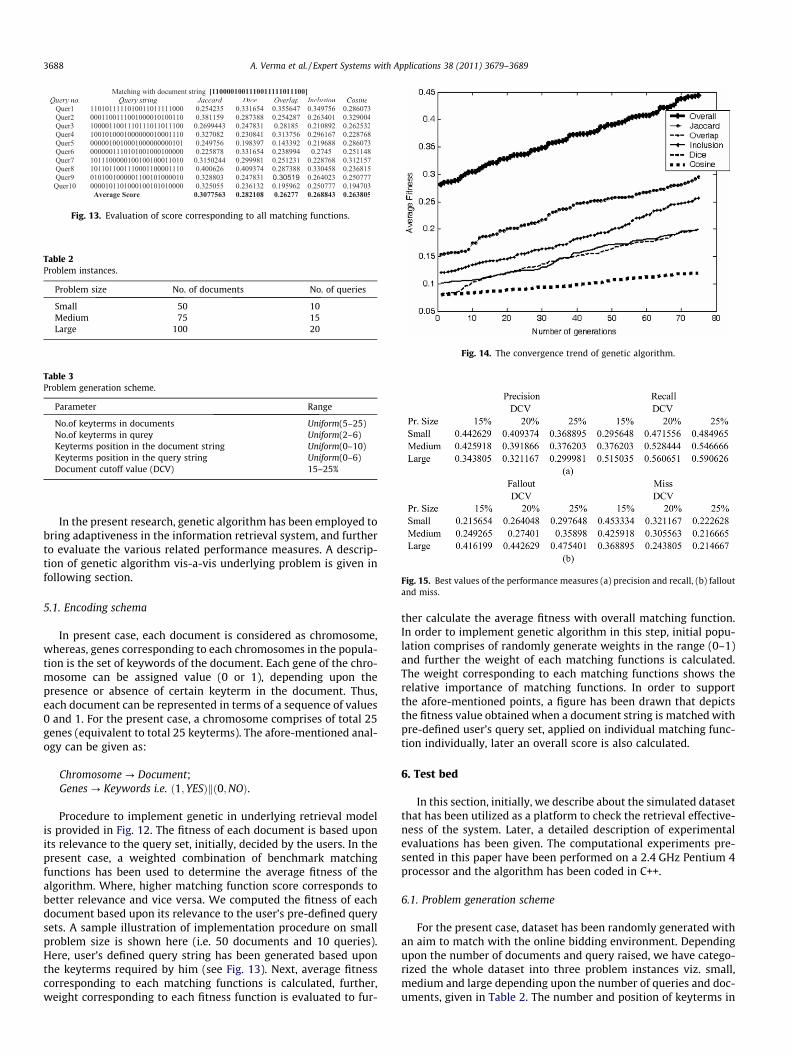
Fig. 13. Evaluation of score corresponding to all matching functions.
Table 2Problem instances.
Problem size No. of documents No. of queries
Small 50 10Medium 75 15Large 100 20
Table 3Problem generation scheme.
Parameter Range
No.of keyterms in documents Uniform(5–25)No.of keyterms in qurey Uniform(2–6)Keyterms position in the document string Uniform(0–10)Keyterms position in the query string Uniform(0–6)Document cutoff value (DCV) 15–25%
Fig. 14. The convergence trend of genetic algorithm.
Fig. 15. Best values of the performance measures (a) precision and recall, (b) falloutand miss.
3688 A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689
In the present research, genetic algorithm has been employed tobring adaptiveness in the information retrieval system, and furtherto evaluate the various related performance measures. A descrip-tion of genetic algorithm vis-a-vis underlying problem is given infollowing section.
5.1. Encoding schema
In present case, each document is considered as chromosome,whereas, genes corresponding to each chromosomes in the popula-tion is the set of keywords of the document. Each gene of the chro-mosome can be assigned value (0 or 1), depending upon thepresence or absence of certain keyterm in the document. Thus,each document can be represented in terms of a sequence of values0 and 1. For the present case, a chromosome comprises of total 25genes (equivalent to total 25 keyterms). The afore-mentioned anal-ogy can be given as:
Chromosome ? Document;Genes ? Keywords i.e. ð1;YESÞkð0;NOÞ.
Procedure to implement genetic in underlying retrieval modelis provided in Fig. 12. The fitness of each document is based uponits relevance to the query set, initially, decided by the users. In thepresent case, a weighted combination of benchmark matchingfunctions has been used to determine the average fitness of thealgorithm. Where, higher matching function score corresponds tobetter relevance and vice versa. We computed the fitness of eachdocument based upon its relevance to the user’s pre-defined querysets. A sample illustration of implementation procedure on smallproblem size is shown here (i.e. 50 documents and 10 queries).Here, user’s defined query string has been generated based uponthe keyterms required by him (see Fig. 13). Next, average fitnesscorresponding to each matching functions is calculated, further,weight corresponding to each fitness function is evaluated to fur-
ther calculate the average fitness with overall matching function.In order to implement genetic algorithm in this step, initial popu-lation comprises of randomly generate weights in the range (0–1)and further the weight of each matching functions is calculated.The weight corresponding to each matching functions shows therelative importance of matching functions. In order to supportthe afore-mentioned points, a figure has been drawn that depictsthe fitness value obtained when a document string is matched withpre-defined user’s query set, applied on individual matching func-tion individually, later an overall score is also calculated.
6. Test bed
In this section, initially, we describe about the simulated datasetthat has been utilized as a platform to check the retrieval effective-ness of the system. Later, a detailed description of experimentalevaluations has been given. The computational experiments pre-sented in this paper have been performed on a 2.4 GHz Pentium 4processor and the algorithm has been coded in C++.
6.1. Problem generation scheme
For the present case, dataset has been randomly generated withan aim to match with the online bidding environment. Dependingupon the number of documents and query raised, we have catego-rized the whole dataset into three problem instances viz. small,medium and large depending upon the number of queries and doc-uments, given in Table 2. The number and position of keyterms in

A. Verma et al. / Expert Systems with Applications 38 (2011) 3679–3689 3689
the documents are selected using an uniform distribution. A tabledescribing the scheme utilized to generate the relevant dataset isgiven in Table 3.
6.2. Experimental evaluation
In this subsection, detailed description of the various results,obtained under different cases are provided. As stated earlier, inthe present paper we have utilized GA in two phases to impartadaptiveness in the retrieval process. In order to check the adap-tiveness of solution methodology, the average fitness obtained byoverall matching function combinations is compared with the indi-vidual matching function (see Fig. 14), the results are compared inlarge problem instance. It can be seen from the figure that a fastconvergence is obtained with overall matching function combina-tion, right from the initial generation, it has average fitness muchgreater as compared to individual matching functions. Amongthe individual matching functions, only Jaccard’s matching func-tion has shown some good performance, while remaining match-ing functions has shown almost similar convergence rate (seeFig. 14).
The performance of genetic algorithm based information retrie-val is also tested on the well known retrieval performance mea-sures viz. precision, fallout, recall and miss values. Here, thevalues corresponding to all performance measures is shown onall problem instances using all considered DCVs (see Fig. 15). Itcan be seen from the figure that increase in problem size accompa-nied by decrease in the precision values, whereas, under same sit-uation recall values have been increased.
7. Conclusion and future scope
Online business communities are continuously improving theircustomer satisfaction level by reducing the influence of risk factors.Over the past few year, numerous decision making approacheshelped a lot to the researchers and analysts in determining the crit-ical factor influencing the concerned approaches. Here, a groupdecision making approach viz. NGT agreed criteria based approachhas been utilized to determine the most dominating risk factorinfluencing the online business communities viz. e-bidding etc.Based upon the results of decision making approach, the mostinfluencing risk factor has been resolved by utilizing the adaptiveinformation retrieval scheme. In information retrieval, adaptive-ness has been brought by searching a proper combination ofweights corresponding to benchmark matching functions. Effec-tiveness of the information retrieval has been analyzed on theparameters based upon the precision, recall, fallout and miss val-ues. Whereas, average matching score has been considered as thecriteria, whose value is to be maximized. A genetic algorithm basedsolution methodology was utilized to analyze the performance ofinformation retrieval scheme. Numerous experimental investiga-tions were performed to explore the effectiveness of retrieval sys-tem. Other risk factors such as privacy risk, security risk etc. wereresolved by incorporating a corporate memory based data ware-housing and management scheme.
Present research includes various empirical and experimentalanalysis on one of the most active research area pertaining tothe online business community i.e. e-bidding. However, the
scope of present research is not limited to the online biddingprocess. Application of proposed research in e-manufacturingsystems, web enabled supply chain are the topics of future con-cerns. Here, we have utilized only genetic algorithm basedmatching function adaption, it would be more interesting tocompare the performance of GA with other evolutionary searchtechnique. Due to limited scope of present research a simulateddata set have been used as platform to analyze the retrievaleffectiveness, thus, the application of proposed research onbenchmark dataset such as cranfield, 20 newsgroup etc. arethe topics of future scope.
References
Ballay, J. F., & Poitou, J. P. (1996). Knowledge management: Organization,competence, and methodology. In Proceeding of the fourth internationalsymposium on the management of industrial and corporate knowledge(ISMICK096) (Vol. 1, pp. 265–285).
Chen, H. (1995). Machine learning for information retrieval: Neural networks,symbolic learning, and genetic algorithms. Journal of the American Society forInformation Science, 46(3), 194–216.
Chen, H., & Dhar, V. (1991). Cognitive process as a basis for intelligent retrievalsystems design. Information Processing and Management, 27, 405–432.
Dieng, R., Corby, O., Giboin, A., & Ribiere, M. (1999). Methods and tools for corporateknowledge management. International Journal of Human–Computer Studies, 51,567–598.
Fuhr, N., & Buckley, C. (1991). A probabilistic learning approach for documentindexing. ACM Transactions on Information Systems, 9, 223–248.
Goldberg, D. E. (1989). Genetic algorithms-in search, optimization and machinelearning. Addison-Wesley Publishing Company.
Gordon, M. D. (1988). Probabilistic and genetic algorithms for document retrieval.Communications of the ACM, 31(10), 1208–1218.
Heijst, G. V., Spek, R. V. D., & Kruizinga, E. (1996). Organization corporate memories.In Proceedings of the 10th workshop on knowledge acquisition for knowledge basedsystems, Ban, Canada (pp. 01–18).
Holan, P. M. D., & Phillips, N. (2004). Remembrance of things past the dynamics oforganizational forgetting. Management Science, 50(11), 1603–1613.
Holland, H. H. (1975). Adaptation in natural and artificial systems. Detroit, MI:University of Michigen Press.
Huang, C., Tseng, T., & Kusiak, A. (2002). A practical english auction with simplerevocation. IEICE Transactions on Fundamentals, E85-A(5).
Huang, C., Tseng, T., & Kusiak, A. (2005). XML-based modeling of corporate memory.IEEE Transactions on System Man and Cybernatics – Part A: Systems and Humans,35(5), 629–640.
Kuhn, O., & Abecker, A. (1997). Corporate memories for knowledge management inindustrial practice: Prospects and challenges. Journal of Universal ComputerScience, 3, 929–954.
Lai, Y. J., Ho, E. S. S. A., & Chang, S. I. (1998). Identifying customer preferences in qualityfunction deployment using group decision making techniques. Integrated productand process development. John Wiley and Sons, Inc..
Massad, V. J., & Tucker, J. M. (2000). Comparing bidding and pricing between in-person and on-line auctions. Journal of Product and Brand Management, 9(5),325–332.
Michalewicz, Z. (1994). Genetic algorithm + data structure = evolution programs. NewYork: Springer Verlag.
O’Leary, D. E. (1997). The internet, intranets and the AI renaissance. Computer, 30,71–78.
Pathak, P., Gordon, M., & Fan, W. (2000). Effective information retrieval usinggenetic algorithm based matching function adaptation. In Proceedings of 33rdHawaii international conference on system sciences-2000 (pp. 1–8).
Saltan, G., & Buckley, C. (1990). Improving retrieval performance by relevancefeedback. Journal of the American Society for Information Science, 41(4), 288–297.
Simon, G. (1996). Knowledge acquisition and modeling for corporate memory:Lessons learnt from experience. In B. Gaines & M. Musen (Eds.), Proceedings ofKAW096 (pp. 41-1–41-18). Ban, Canada. Available from http://ksi.cpsc.ucalgary.ca/KAW/KAW96/KAW96Proc.html.
Simon, G., & Grandbastein, M. (1995). Corporate knowledge: A case study in thedetection of metallurgical flaws. In Proceedings of ISMICK’95 (pp. 43–52).
Yang, J., & Korfhage, R. R. (1993). Query optimization in information retrieval usinggenetic algorithms. In Proceedings of the fifth international conference on geneticalgorithms (pp. 603–613).
Related Documents











