European Journal of Operational Research 70 (1993) 289-303 289 North-Holland Minimizing flow time variance in a single machine system using genetic algorithms Mahesh C. Gupta Department of Management, University of Louisville, Louisville, ICY 40292, USA Yash P. Gupta College of Business and Administration, University of Colorado at Denver, Campus Box 165, P.O. Box 173364, Denver, CO 80217-3364, USA Anup Kumar Department of Engineering Mathematics and Computer Science, University of Louisville, Louisville, KY 40292, USA Received January 1992; revised September 1992 Abstract: In this paper, we address an n-job, single machine scheduling problem with an objective to minimize the flow time variance. We propose heuristic procedure based on genetic algorithms with the potential to address more generalized objective function such as weighted flow time variance. The development and implementation of the algorithm is supported with literature review and statistical analysis of the results. Some general guidelines to select the parameter values of the genetic algorithm are also developed using an experimental design approach. Keywords: Single machine system; Scheduling; Flow time variance; Genetic algorithms; Experimental design Introduction In this paper, we consider the problem of scheduling n jobs on a single machine when all jobs are available for processing and the objective is to minimize the squared deviations from the mean completion time or flow time (CTV). 1 Such objective functions are known as non-regular per- formance measures. Past research on scheduling has concentrated mainly on regular performance measures in which the objective function is increasing in terms of job completion times. Some commonly used regular measures include mean flow time and average in-process inventory with the optimal schedule determination for such measures being relatively simple. Yet in certain problem environments nonregular performance criteria, such as the completion times (or waiting times) variance and the sum of earliness/tardiness penalties, are more appropriate. For example, in service or Correspondence to: Dr. Yash P. Gupta, College of Business and Administration, University of Colorado at Denver, Cam- pus Box 165, P.O. Box 173364, Denver, CO 80217-3364, USA. i The terms 'completion time' and 'flow time' are inter- changeably used because all jobs are available for process- ing at time zero, and the flow time is equal to the comple- tion time (Cheng and Gupta, 1989). 0377-2217/93/$06.00 © 1993 - Elsevier Science Publishers B.V. All rights reserved

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

European Journal of Operational Research 70 (1993) 289-303 289 North-Holland
Minimizing flow time variance in a single machine system using genetic algorithms
Mahesh C. Gupta Department of Management, University of Louisville, Louisville, ICY 40292, USA
Y a s h P. G u p t a
College of Business and Administration, University of Colorado at Denver, Campus Box 165, P.O. Box 173364, Denver, CO 80217-3364, USA
A n u p K u m a r
Department of Engineering Mathematics and Computer Science, University of Louisville, Louisville, KY 40292, USA
Received January 1992; revised September 1992
Abstract: In this paper, we address an n-job, single machine scheduling problem with an objective to minimize the flow time variance. We propose heuristic procedure based on genetic algorithms with the potential to address more generalized objective function such as weighted flow time variance. The development and implementation of the algorithm is supported with literature review and statistical analysis of the results. Some general guidelines to select the parameter values of the genetic algorithm are also developed using an experimental design approach.
Keywords: Single machine system; Scheduling; Flow time variance; Genetic algorithms; Experimental design
Introduction
In this paper, we consider the problem of scheduling n jobs on a single machine when all jobs are available for processing and the objective is to minimize the squared deviations from the mean completion time or flow time (CTV). 1 Such objective functions are known as non-regular per- formance measures.
Past research on scheduling has concentrated mainly on regular performance measures in which
the objective function is increasing in terms of job completion times. Some commonly used regular measures include mean flow time and average in-process inventory with the optimal schedule determination for such measures being relatively simple. Yet in certain problem environments nonregular performance criteria, such as the completion times (or waiting times) variance and the sum of earliness/tardiness penalties, are more appropriate. For example, in service or
Correspondence to: Dr. Yash P. Gupta, College of Business and Administration, University of Colorado at Denver, Cam- pus Box 165, P.O. Box 173364, Denver, CO 80217-3364, USA.
i The terms 'completion time' and 'flow time' are inter- changeably used because all jobs are available for process- ing at time zero, and the flow time is equal to the comple- tion time (Cheng and Gupta, 1989).
0377-2217/93/$06.00 © 1993 - Elsevier Science Publishers B.V. All rights reserved

290 M.C. Gupta et al. / Single machine scheduling
manufacturing systems it is desirable that each customer (or job) spends approximately the same amount of time in the system as every other customer, i.e. minimize the variance of response time. In an other situation, it may be important to assign accurate and attainable due date so as to deliver the product just-in-time (see Bagchi et al., 1987, for the interrelationship between these two criteria).
In recent years scheduling research involving non-regular performance measures has received some attention from practitioners as well as re- searchers. On one hand, researchers are stimu- lated to address the theoretical challenge posed by these NP-hard 2 scheduling problems. The practitioners, on the other hand, are motivated by their need to adopt concepts such as just-in-time and zero inventory to respond to the increasing competitive pressures. Cheng and Gupta (1989) and Baker and Scudder (1990) presented a com- prehensive survey of this research.
Merten and Muller (1972) introduced comple- tion time variance (CTV) and waiting time vari- ance (WTV) as two related non-regular perfor- mance measures. Being quadratic in nature, these functions tend to penalize larger deviations at a higher rate. These same measures have been further investigated by a number of researchers: Schrage (1975), Eilon and Chowdhuary (1977), Kanet (1981), Vani and Raghvachari (1987), Bagchi et al. (1987), Bagchi (1989) and Gupta et al. (1990).
Schrage proposed the first optimal algorithm for scheduling up to five jobs, while Eilon and Chowdhuary proved that the optimal sequence to CTV and WTV problems is V-shaped, meaning that the jobs preceding and succeeding the short- est job are in LPT (i.e. longest processing time first) and SPT (i.e. shortest processing time first) orders respectively. Eilon and Chowdhuary pro- vided a theorem a number of heuristic methods for large problems. Kanet developed an elegant heuristic algorithm (JJK) and demonstrated the superiority of its performance against the heuris- tics proposed by Eilon and Chowdhuary. Kanet also showed that the CTV problem is equivalent
2 NP-hard problem means that any algorithm which computes an exact solution of the scheduling problem requires an amount of computation time which is exponential in n, the size of the problem (Garey and Johnson, 1979).
to minimizing the sum of squared differences in job completion times. Vani and Raghvachari used the concept of pooled variance to develop a heuristic algorithm (V& R) and claimed that their heuristic compared favorably with other heuris- tics. In addition, Bagchi et al. suggested mean squared deviation (MSD) of job completion times about the common due-date as another non-regu- lar measure and identified the interrelationships among CTV, WTV and MSD problems The re- searchers proved a number of dominance proper- ties and developed an efficient branching proce- dure to determine the optimal schedule for small problems (n < 20). Bagchi et al. also concluded that for solving large problems good approximate solutions should be found using heuristic meth- ods. Recently, Gupta et al. (1990) provided a comparative analysis of the existing heuristic al- gorithms and proposed a new heuristic (GGB1) to improve a given schedule. Their analysis demonstrated that Kanet's JJK and GGB1 heuristics are by far the most efficient heuristics. Gupta et al. concluded that the best results for the completion time variance problem can be obtained by complementing Kanet's heuristic with GGB1 (i.e. by taking the results of Kanet's
• heuristic as a given schedule and then improve it using GGB1).
Examination of the above literature suggests that although the non-regular performance mea- sures are important in today's highly competitive business environment, the research correspond- ing to this class of combinatorial problems is relatively sparse. Cheng and Cai (1992) proved that the CTV problem is NP-hard and no polyno- mial or pseudo polynomial algorithm exists to find the optimal solution for the completion time variance (CTV) problem. Moreover, because of the difficulty in finding an optimal solution to even the CTV problem, to our knowledge, no one has attempted to address the weighted comple- tion time variance (WCTV) problem where each job has a weight attached to it. Therefore, the purpose of this paper is to develop new and improved procedures to address the CTV and WCTV problems.
In recent years, a growing body of literature suggests the use of heuristic search procedures for combinatorial optimization problems. Glover and Greenberg (1989) reviewed five search proce- dures: genetic search, neural networks, simulated

M.C. Gupta et aL / Single machine scheduling 291
Table 1 Some examples of GA applications
Problem type References
Job Shop Scheduling
Traveling Salesman
Bin Packing Problem
Aarts et al., 1991 Baker, 1985 Biegel and Davern, 1990 Cleveland and Smith, 1989 Dorndorf and Pesch, 1992 Davis, 1985 Fox and McMahon, 1990 Liepins and Hilliard, 1989 Nakano and Yamada, 1991 Syswerda, 1991 Whitley et al., 1989 Goldberg and Lingle, 1985 Grefenstette et al., 1985 Jog et al., 1989 Johnson, 1990 Liepins and Hilliard, 1989 Oliver et al., 1982 Suh and Van Gucht, 1987 Ulder et al., 1991 Whitley et al., 1989 Smith, 1985
annealing, tabu search, and target analysis and concluded that these methods have great poten- tial to address optimization problems and that these techniques should be further investigated to draw some generalizations. Consequently, over the past few years, a number of successful at- tempts have been made to demonstrate the appli- cability of one of these methods; i.e., genetic algorithm (GAs) to combinatorial optimization problems such as traveling salesman problem and job-shop scheduling problems (see Table ). In this paper, we develop a GA based algorithm to ad- dress the CTV and WCTV problems. The rest of the paper is divided into the following sections.
In Section 1, we briefly review some defini- tions and formulate a problem involving a non- regular performance measure. In Section 2, we describe the basic concepts of genetic algorithms and discuss the design issues of GAs for combina- torial problems; we then develop a GA for find- ing an efficient schedule that minimizes the flow time variance for the CTV and WCTV problems. The performance of the algorithm is then com- pared with that of other existing heuristics. Be- cause GAs have many control parameters which affect the quality of the solution obtained, in Section 3, we describe the experimental design to address the importance of control parameters
and discuss the results obtained through the sta- tistical analysis of the design in order to develop some guidelines for the selection measure (i.e. weighted completion times variance) and demon- strate the versatility of GAs by solving a set of problems. In the conclusion, we identify a num- ber of problems which should be addressed in the future and demonstrate the usefulness of the GA approach to address such problems.
Problem formulation
We are concerned with non-preemptive single machine scheduling problems with n jobs where all jobs are available for processing at time t = 0. Associated with each job j, where j - 1, . . . , n, is a processing time pj and weight w i. We define the following measures:
1 2 1 c v=- ( c ; - c ) ,
R j = I
2. WCTV = Weighted Completion Time Variance
n
1 Ewj(C, C) 2, (2) n j = l
where Cj = Completion time or flow time of job j, and
i f = 1 ~ C,. (3) n j = l
For the above problems (1) and (2), it can easily be shown that the machine idle time is unproductive. The only scheduling decision in- volves the order in which the jobs are to be completed which enables us to denote any sched- ule by a permutation of job indices and to find a permutation which minimizes the objective func- tion.
Genetic algorithms
In simple GAs, a candidate solution (a point in the search space) is represented by a sequence of binary numbers, also known as a chromosome a.
a In this paper, a chromosome represents a sequence of n jobs.

292 M.C. Gupta et al. / Single machine scheduling
A chromosome's potential as a solution is deter- mined by its fitness function, which evaluates a chromosome with respect to the objective func- tion of the optimization problem at hand. A judiciously selected set of chromosomes is called a population and the population at a given time is a generation. The population size remains fixed from generation to generation and has a signifi- cant impact on the performance of the GA. The fundamental underlying mechanism of GAS oper- ates on a generation and generally, consists of three main operations: (i) reproduction (selection of copies of chromosomes according to their fit- ness value), (ii) crossover (an exchange of a por- tion of the chromosomes), and (iii) mutation (a random modification of the chromosome). The chromosomes resulting from these three opera- tions, often known as offsprings or children, form the next generation's population. The process is then iterates for a desired number of times (usu- ally up to the point where the system ceases to improve or the population has converged to a few well performing sequences).
Genetic algorithms are search techniques for global optimization in a complex search space. As the name suggests, they employ the concepts of natural selection and genetics. Using past infor- mation they direct the search with expected im- proved performance and achieve fairly consistent and reliable results (De Jong, 1975; Whitley et al., 1989). The traditional methods of optimiza- tion and search do not fare well over a broad spectrum of problem domains. Some are limited in their scope because they employ local search techniques (e.g. calculus based methods). Others, like enumerative schemes, are not efficient when practical search space is too large. In other words, they structurally rigid.
Genetic Algorithms have been shown to be an efficient global search method capable of robust combinatorial optimization of real valued func- tions (De Jong, 1980). However, there are a large class of problems which cannot be encoded as a bit string (with no ordering dependencies). The examples of such optimization problems include the traveling salesman problem (TSP), bin pack- ing problem, and job shop scheduling problems (see Table 1). Consequently, a number of alterna- tive approaches have been suggested to recombi- nation operators, like partially matched crossover (PMX) and cycle crossover (for example, see
Whitley et al., 1989; Fox and McMahon, 1990); basic GAs have also further been augmented with other operations, such as divergence and replace- ment policies, (for example, see Liepins and Hilliard, 1989; Grefenstette, 1987).
Design issues for a genetic algorithm for the CTV problem
In this subsection, we discuss the major obsta- cles in the design of GAs for combinatorial opti- mization problems and describe the approach used in the development of the proposed GA which we call FVM (i.e., flow time variance mini- mization) algorithm for the CTV problem. THe discussion is divided into five subsections, each corresponding to the essential components of GA.
(i) Representation. Choosing an appropriate representation is the first step in applying GAs to any optimization problem. A number of represen- tations like adjacency representation (Grefens- tette et al., 1985), permutation representation (Goldberg and Lingle, 1985), ordinal representa- tion (Grefenstette et al. 1985), and precedence matrix representation (Fox and McMahon, 1990) are being explored for combinatorial problems such as TSP. The FVM algorithm developed for CTV problem uses a permutation representation in which the chromosome represents a permuta- tion of the problem size, n, and the search space is a space of all the permutations, n!.
(ii) Initialization. The next important step in GAs is to initialize the population, that is, create an initial population. As noted by Davis and Steenstrup (1987), the initialization process can be executed with either a randomly-created popu- lation or a well-adapted (seeded) population 4. For the TSP, Grefenstette (1987) and Liepins et al. (1982) suggested that in spite of faster conver- gence the use of seeded populations provides little advantage. In the FVM algorithm, we gen- erated an initial population of desired size using a recursive procedure which can list all possible
4 For many combinatorial problems, it is relatively easy to formulate reasonably good initial population structure. For example, a population consisting of only V-shaped se- quences can be used as a seed population for the flow time variance minimization problem because past research has shown that the optimal sequence is V-shaped (discussed earlier).

M.C. Gupta et al. / Single machine scheduling 293
permutations randomly and provides the flexibil- ity in changing the initial population size.
(iii) Evaluation function. There are a number of characteristics of the evaluation function that enhance or hinder a GA's performance (Davis and Steenstrup, 1987). We discuss two character- istics which have direct implications for a CTV problem and, therefore, have been incorporated in the FVM algorithm. First, since the perfor- mance of a GA is highly sensitive to the objective function 5 value, it is very important to scale the fitness values so as to diversify the population. Further, Goldberg (1989) suggested that fitness scaling helps in differentiating the chromosomes with average fitness values and the best fitness values. In the FVM algorithm, we use the linear scaling as proposed by Goldberg and the linear relationship between the raw fitness f and the scaled fitness f ' is f ' = af+ b, where a and b are constants.
The second important property corresponds to mapping the natural objective function to a fit- ness function. Goldberg suggested a number of ways to handle this process. In the FVM algo- rithm, since we use a minimization objective func- tion, the following transformation is applied:
f( x) = ( Cmax-g(x) whenotherwise.g(x)<Cmax,
(4)
g(x) is the objective function value and Cm~x is chosen as the largest g-value observed in the last k generations. This transformation is also known as winnowing.
(iv) Recombination operators. A number of re- combination operators that combine features of inversion and crossover (e.g. partially matched crossover (PMX), order crossover, cycle crossover, union and intersection crossover) have been in- vestigated (Goldberg and Lingle, 1985) and found to be more suitable for ordering or permutation problems (for example, see Fox and McMahon, 1990). Accordingly, in the FVM algorithm, we use a PMX operator for crossover (for details see Goldberg, 1989). During the crossover operation,
some potentially useful sequences might be lost. Consequently, mutation 6 is introduced to over- come this problem. When mutation is applied to a sequence it chooses one bit and changes it (Baker, 1985). In the FVM algorithm we use the SWAP operator 7. This operator introduces the smallest possible change in an ordering problem (Oliver et al., 1982).
(v) Parameter values. A variety of parameters (crossover rate (PCRS), mutation rate (PMUT), population size (PPSZ), and number of genera- tions (XGEN)) and policies (placement and di- vergence) play a crucial role for the successful implementation of GA. The settings of these parameter values significantly affects the perfor- mance of GA. The problem of setting the param- eter values has been studied extensively for bit string representation (for example, see De Jong, 1975, and Grefenstette, 1986).
Very little work has been reported for other types of representations. Therefore, in this paper, we performed an extensive computational experi- ments with the parameters. An experimental de- sign is developed with these parameters (i.e. PBSZ, PPSZ, PCRS, PMUT and XGEN) at dif- ferent levels and conclusions are drawn with re- spect to their statistical significance for permuta- tional chromosomal representation. Some guide- lines are developed for addressing the combinato- rial problems similar to the CTV problem.
(vi) Replacement strategy. Several replace- ment strategies such as crowding strategy and elitist strategy have been suggested in the litera- ture (see Liepins and Hilliard, 1989, for details). In the FVM algorithm, we used a combination of crowding and elitist strategies. By using the re- combination operators (i.e. crossover and muta- tion), a pool of offspring is generated to create a new population. If all of the offspring outperform every existing chromosome in the old population, then all the offspring replace the existing chro- mosomes in the new population. If some of them fare better, they replace an equal number of existing chromosomes that are lowest in the order of performance in the old population. For the remaining offspring, an offspring is selected from
5 The objective function values are the proport ions of the respective sequences in the population which are calculated from the objective function values are used to choose 'parents ' for crossover.
6 Mutat ion is an occasional random alteration process with a small probability.
7 SWAP operator randomly selects two jobs and exchanges their positions in the sequence.

294 M.C. Gupta et al. / Single machine scheduling
the old population using a specified probability value. This replacement strategy ensures that the best performing chromosomes (or sequences) of the previous generation are stored in the current population.
(vii) Convergence policy. An ideal GA should maintain a high degree of diversity within the population as it iterates from one generation to the next. Otherwise, the population may converge prematurely before the desired solution is found (Grefenstette, 1987). A number of measures have been developed to prevent premature conver- gence and improve the search capabilities of GAs.
We adapted Grefenstette's (1987) entropic measure H i in the FVM algorithm: For each job i, we computed a measure of the entropy H i in the current population using the formula
~'~ (niJ2PPSZ) * Log(nij/2PPSZ )
Hi = j = l
tl
H = i=1 / I
Log n (5)
(6)
where ni/is the number of edges connecting job i and j in the population, n is the number of jobs, and PPSZ is the population size.
As the population converges, H approaches 0. In the FVM algorithm, the divergence (entropy) is calculated and monitored after each genera- tion. If the diversity is below a predetermined acceptable level, we performed mutation opera- tion until the diversity is at the desired level. The acceptable level should be selected after examin- ing several runs of the GA since a high value will force GAs to perform excessive mutation opera- tion and a low value will result in a homogeneous population.
The FVM Genetic Algorithm The GA for a CTV problem is developed incor- porating the design issues discussed above. These steps are now discussed in detail.
Step 1. (Initialization) Select the initial param- eters and create an initial diversified population.
(i) Set the values of PPSZ, PBSZ, PCRS, PMUT and XGEN;
(ii) read the processing times of PBSZ num- ber of jobs;
(iii) create an initial population of size PPSZ and call it oldpop;
(iv) calculate the objective function values us- ing (1) or (2);
(v) sort the population in increasing order of objective function value;
(v) check to see if the diversity of oldpop is at an acceptable level; Otherwise, execute Step 4 (i.e. perform diversification); and
(vi) set GEN -- 1; (i.e. current generation = 1). Step 2. (Recombination) Apply recombination
operator to oldpop to form a selection pool. (i) The PMX crossover operator is executed
with a specified probability PCRS. Under this process, two chromosomes are chosen randomly to form new chromosomes; this is done repeat- edly until the size of selection pool equals PPSZ;
(ii) the mutation process is executed with a specified probability PMUT. Under this process, two chromosomes are chosen randomly to form new chromosomes;
(iii) calculate the objective function and fit- ness values for every new sequence;
(iv) sort the selection pool in increasing order of objective function values;
Step 3. (Replacement) Compare the chromo- somes of sorted oldpop and selection pool for their fitness value, and create a newpop using the replacement policy (see previous section for de- tails).
(i) If all the offspring out-perform every ex- isting chromosome in the old population, then all the offspring replace all the existing chromo- somes in the new population.
(ii) If only some offspring fare better than the existing population, they replace an equal num- ber of existing chromosomes which are lowest in the order of performance in the old population.
(iii) For the remaining offspring, a selection is made with a specified probability ft.
Step 4. (Diversification) Apply the mutation process to diversify the population (see previous section for details).
(i) Calculate the diversity parameter H for the current population using (5) and (6).
(ii) Compare the diversity with the given ac- ceptable level (given parameter). If the diversity is below an acceptable level, execute mutation process repeatedly with p = PMUT until the di- versity of the population is equal to an acceptable level.

M.C. Gupta et al. / Single machine scheduling 295
Table 2 Problem Set 1 (source: Eilon and Chowduary, 1977)
No. Jobs Processing times Optimal values
1 6 2 6 9 12 19 21 218.47 2 7 2 3 6 9 2 1 6 5 8 2 918.28 3 8 2 4 6 7 8 91016 187.23 4 8 1 2 8 9 1 0 1 2 1 3 1 6 254.48 5 10 1 2 5 8 9 1 0 1 3 1 6 1 8 19 486.40 6 10 2 3 6 9 2 1 2 3 3 4 6 5 8 2 92 3584.00 7 10 5 7 8 9 10 13 21 25 41 100 1336.00
Step 5. (New generation) Evaluate the current generation number to determine the next step.
(i) If GEN <XGEN, then GEN is incre- mented by one and the current population be- comes oldpop. GO TO Step 2.
(ii) If GEN > = XGEN, then STOP. The best sequence would be the sequence in the current population with highest fitness value.
Computational analysis
In the following section, we present the com- putational results of the GAs for a flow time
8 The FVM algorithm is a modified verSion of genetic algo- rithm developed by Goldberg (1989) and a copy of the program is available from the authors upon request.
Table 3 Parameter values for GA
Parameters Values
Population size (PPSZ) 100 Generations (XGEN) 100 Crossover probability (PCRS) 0.90 Mutation probability (PMUT) 0.10
variance problem (FVM). The GAs are imple- mented using TURBO PASCAL on the IBM PS/2 model 55SX with the mathematical copro- cessor 8. We applied the FVM algorithm to two sets of problems adapted from published articles in this research area.
The first problem set was provided by Eilon and Chowdhuary (1988) and consists of seven problems with sizes ranging from six to ten jobs (Table 2). This set was subsequently used by Kanet (1981), Vani and Raghvachari (1987), and Gupta et al. (1990) for testing their heuristic algorithms (JJK, V&R, GGB(1 and 2) respec- tively), Gupta et al. (1990) concluded that while JJK and V& R provided optimal solutions for five and three problems respectively, where GGB1 found the optimal solutions for all seven prob- lems. We applied the FVM algorithm to this problem set with the parameter values given in Table 3. The FVM algorithm provided the opti- mum sequences for all seven problems.
Table 4. Comparison of results
S. No. Parameter values FVM Optimal Percentage (PBSZ, PPSZ, XGEN, PCRS, PMUT) values values a deviations
1 (10, 100, 100, 0.90, 0.10) 7027.96 7027.96 0.000 2 (10, 100, 100, 0.90, 0.10) 12269.76 12269.76 0,000 3 (10, 100, 100, 0.90, 0.10) 20903.36 20903.36 0.000 4 (10, 100, 100, 0.90, 0.10) 14094.01 14094.01 0.000 5 (10, 100, 100, 0.90, 0.10) 18884.80 18884.80 0.000 6 (15, 75, 400, 0.90, 0.15) 16052.91 16052.19 0.004 7 (15, 100, 400, 0.75, 0.15) 27083.58 27802.80 0.003 8 (15, 100, 400, 0.75, 0.10) 29807.20 29805.40 0.006 9 (15, 75, 400, 0.60, 0.10) 57715.20 57713.76 0.002
10 (15, 75, 400, 0.90, 0.15) 36005.39 36005.18 0.001 11 (20, 75, 400, 0.75, 0.15) 70971.34 70843.39 0.181 12 (20, 75, 400, 0.60, 0.15) 76076.00 76054.66 0.033 13 (20, 75,400, 0.60, 0.10) 59952.00 58912.59 0.067 14 (20, 100, 400, 0.75, 0.10) 54696.75 54589.11 0.197 15 (20, 75,400, 0.75 0.15) 50069.80 50015.15 0.109
a The optimal objective function values are listed here from Gupta et al. (1990); the optimal sequences are not duplicated in this paper.

296 M.C. Gupta et al. / Single machine scheduling
The second problem set was given by Gupta et al. (1990) and consists of 15 problems with sizes ranging from ten to twenty jobs (Table 4). This set was used by Gupta et al. for comparing their results of heuristic algorithms (GGB1 and GGB2) where they concluded that GGB1 provided opti- mal solutions for eleven problems and it outper- formed all other algorithms (except in one case where the JJK solution was slightly better).
We applied the FVM algorithm to this prob- lem set. Table 4 compares the performance of the FVM with the optimal solution. The main pur- pose of this table is to demonstrate the capability of FVM to identify the most efficient solution when an appropriate parameter wetting is used. Table 4 also shows the computations for percent- age deviations from optimal solutions and demonstrates that the error is less than or equal to 0.1% for thirteen out of fifteen problems, and it is less than 0.2% for all problems in this set. Table 4 also lists a specific set of parameter values for each of the problems. Each set consists of five parameters: PBSZ, PPSZ, XGEN, PCRS, PMUT. The further analysis of the above results suggests that the best value reported in the table is clearly better than the average value (especially for the large problem size) which suggests that multiple runs may be a good strategy for this type of scheduling problem. The results obtained are consistent with Syswerda (1991).
Parameter settings for FVM algorithm: Experimen- tal design approach
The most difficult and time-intensive issue in the successful implementation of GAs is to find good parameter settings, one of the most popular subject of current research in GAs. Recently, a number of approaches have been suggested to derive robust parameter settings for traditional GAs, including carrying out brute force search, using GAs et meta-level, and using adaptive op- erator fitness technique (Davis, 1991). In one of the most extensive study of determining the opti- mal parameter values, Schaffer et al. (1989) con- cluded that the optimal parameter settings vary from problem to problem. It should also be noted that most of the work in this direction has been done for the traditional GAs and very little work has been reported for the combinatorial prob- lems. In this paper, we design an experiment to
discuss the significance of the parameter values and develop some guidelines for the selection of these values.
The experimental design is concerned with (i) selecting a set of variables (i.e. factors) to be investigated and (ii) setting the levels of selected factors. For example, one may be interested in evaluating the performance of FVM algorithm over a number of crossover operators (e.g. order crossover, cycle crossover, and edge combination crossover), replacement strategies (e.g. crowding and elitist strategies) along with other parameters such as population size, mutation rate, crossover rate and number of generations. It should be noted that as the number of factors and their subsequent levels increase, the number of combi- nations of factor levels increases exponentially. Further, Kelton (1988) suggested that the levels of the factors should be chosen carefully so that they represent extreme values.
In this study, we investigated performance of the FVM algorithm for a set of four most com- monly studied parameters listed in Table 5 using PMX crossover. After an extensive preliminary analysis of the FVM algorithm, we chose three levels for each parameter which represented the low, medium and high levels of these parameter values. Specifically, we examined the effects of variations in main factors (i.e. PPSZ, PBSZ, PCRS, PMUT, XGEN) and the various interac- tion effects between the factors (e.g. what is the effect of increasing the population size, while lowering the crossover rate?).
Based on De Jong's and Grefenstette's work, we defined a particular GA design by indicating the respective values for the parameters. For example, GA 1 = (10, 100, 200, 0.90, 0.05) implies that in this design of the FVM algorithm we considered a problem in which the number of jobs is 10, the population size is 100, the number of generation is 200, the crossover rate is 90% and the mutation rate is 5%. Since in this experi- mental design, we considered five parameters each with three values, the Cartesian product of five variables defines a space of 35 design points. In addition, we considered five replications for each design by solving five different problems for each size. Thus, we had 1215 5*35 ) observations in our database where each observation repre- sented the percentage deviation from the optimal solution (for example, see Table 4). The statistical
M.C. Gupta et al. / Single machine scheduling 297
Table 5 Experimental design factors
Parameters (factors) Levels
1. Number of generat ions (XZEN 50 75
100 100 200 400
0.60 0.75 0.90 0.05 0.10 0.15
10 15 20
2. Size of population (PPSZ)
3. Probability of crossover (PCRS)
4. Probability of mutat ion (PMUT)
5. Size of problems (PBSZ)
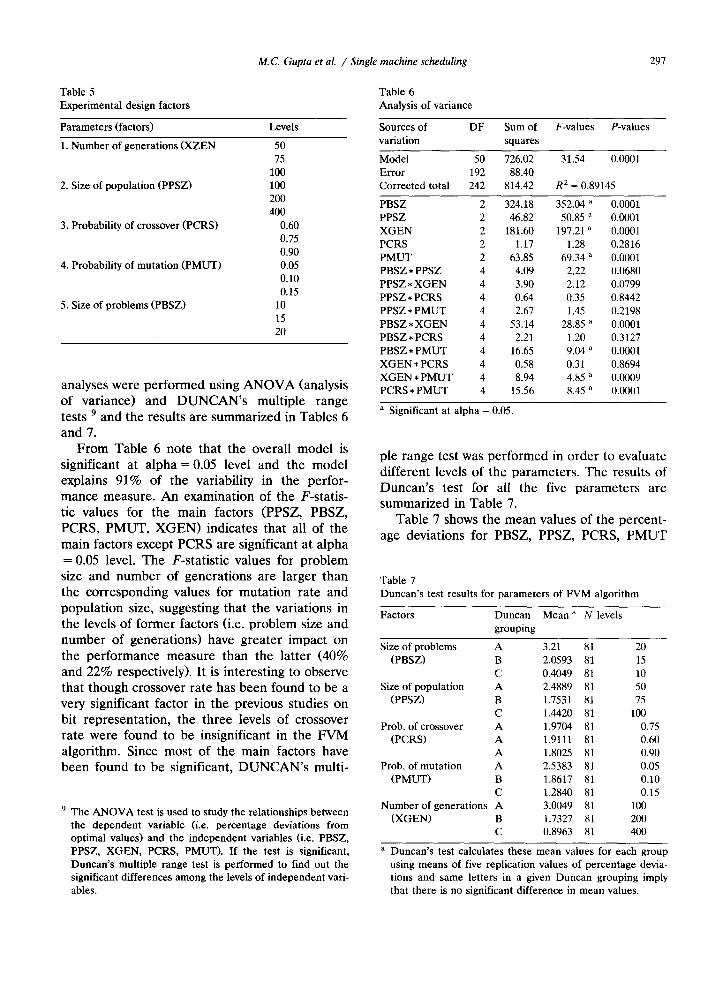
analyses were performed using ANOVA (analysis of variance) and DUNCAN's multiple range tests 9 and the results are summarized in Tables 6 and 7.
From Table 6 note that the overall model is significant at alpha = 0.05 level and the model explains 91% of the variability in the perfor- mance measure. An examination of the F-statis- tic values for the main factors (PPSZ, PBSZ, PCRS, PMUT, XGEN) indicates that all of the main factors except PCRS are significant at alpha = 0.05 level. The F-statistic values for problem size and number of generations are larger than the corresponding values for mutation rate and population size, suggesting that the variations in the levels of former factors (i.e. problem size and number of generations) have greater impact on the performance measure than the latter (40% and 22% respectively). It is interesting to observe that though crossover rate has been found to be a very significant factor in the previous studies on bit representation, the three levels of crossover rate were found to be insignificant in the FVM algorithm. Since most of the main factors have been found to be significant, DUNCAN's multi-
9 The A N O V A test is used to study the relationships between the dependent variable (i.e. percentage deviations from optimal values) and the independent variables (i.e. PBSZ, PPSZ, XGEN, PCRS, PMUT). If the test is significant, Duncan ' s multiple range test is performed to find out the significant differences among the levels of independent vari- ables.
Table 6 Analysis of variance
Sources of DF Sum of F-values P-values variation squares
Model 50 726.02 31.54 0.0001 Error 192 88.40 Corrected total 242 814.42 R z = 0.89145
PBSZ 2 324.18 352.04 a 0.0001 PPSZ 2 46.82 50.85 a 0.0001 X G E N 2 181.60 197.21 a 0.0001 PCRS 2 1.17 1.28 0.2816 P M U T 2 63.85 69.34 ~ 0.0001 PBSZ * PPSZ 4 4.09 2.22 0.0680 PPSZ * X G E N 4 3.90 2.12 0.0799 PPSZ * PCRS 4 0.64 0.35 0.8442 PPSZ* P M U T 4 2.67 1.45 0.2198 PBSZ * X G E N 4 53.14 28.85 ~ 0.0001 PBSZ* PCRS 4 2.21 1.20 0.3127 PBSZ* P M U T 4 16.65 9.04 a 0.0001 X G E N * PCRS 4 0.58 0.31 0.8694 X G E N * P M U T 4 8.94 4.85 a 0.0009 PCRS * P M U T 4 15.56 8.45 a 0.0001
a Significant at alpha = 0,05.
pie range test was performed in order to evaluate different levels of the parameters. The results of Duncan's test for all the five parameters are summarized in Table 7.
Table 7 shows the mean values of the percent- age deviations for PBSZ, PPSZ, PCRS, PMUT
Table 7 Duncan ' s test results for parameters of FVM algorithm
Factors Duncan Mean a N levels grouping
Size of problems A 3.21 81 20 (PBSZ) B 2.0593 81 15
C 0.4049 81 10 Size of population A 2.4889 81 50
(PPSZ) B 1.7531 81 75 C 1.4420 81 100
Prob. of crossover A 1.9704 81 0.75 (PCRS) A 1.9111 81 0.60
A 1.8025 81 0.90 Prob. of mutat ion A 2.5383 81 0.05
(PMUT) B 1.8617 81 0.10 C 1.2840 81 0.15
Number of generat ions A 3.0049 81 100 (XGEN) B 1.7327 81 200
C 0.8963 81 400
a Duncan ' s test calculates these mean values for each group using means of five replication values of percentage devia- tions and same letters in a given Duncan grouping imply that there is no significant difference in mean values.
298 M.C. Gupta et a L / Single machine scheduling
and XGEN respectively. The three levels of prob- lem size (20, 15, 10) are significantly different from each other, and for smaller problem sizes the FVM algorithm produces the best results. Similarly, the three levels of population size (50, 75, 100), three levels of mutation rate (0.05, 0.10, 0.15), and the three levels of genera- tion number (100, 200, 400) are significantly dif- ferent from each other. The best results are also found for PPSZ = 100, PMUT --- 0.15 and XGEN = 400. Note that there is no significant difference in the mean values obtained using three different levels of crossover rate and that PCRS = 0.90 produces the least mean value.
Next, we examine the interaction effects. The F-statistics (Table 6) and post hoc analysis of these interactions show that:
(i) There is a significant interaction (alpha = 0.05) between PBSZ and PPSZ. The post hoc analysis shows that for a given problem size, an increase in population size improves the perfor- mance of the FVM algorithm. This, it confirms the findings of the basic GA.
(ii) There is a significant interaction (alpha = 0.05) between PBSZ and PMUT, revealing that better performance can be obtained for a given problem size by increasing the mutation rate.
(iii) It should be noted that although the main effect PCRS is not significant, there is a signifi- cant interaction (alpha = 0.05) between PCRS and PMUT, indicating that a higher mutation rate for a given crossover rate tends to give better perfor- mance value for the FVM algorithm.
(iv) There is significant interaction between XGEN and PMUT. With an increase in number of generations, the mutation rate should also be increased to achieve better performance. Further, if an increase in the number of generations fol- lows an increase in the mutation rate, perfor- mance of the FVM algorithm can be improved significantly.
Among these significant interactions, the inter- action between PBSZ and XGEN is the most significant as it comparatively explains more change in the mean value of the performance measure. In general, the implication of these significant interaction terms is that they produce a unique impact on the performance measure unrelated to the individual main effects.
General guidelines for parameter settings
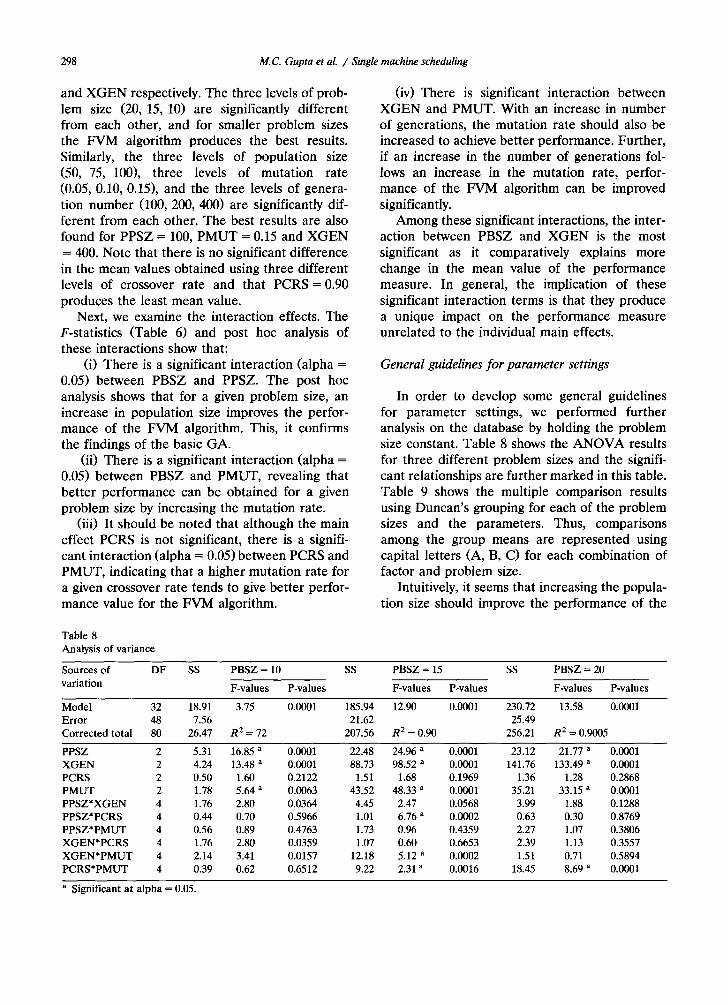
In order to develop some general guidelines for parameter settings, we performed further analysis on the database by holding the problem size constant. Table 8 shows the ANOVA results for three different problem sizes and the signifi- cant relationships are further marked in this table. Table 9 shows the multiple comparison results using Duncan's grouping for each of the problem sizes and the parameters. Thus, comparisons among the group means are represented using capital letters (A, B, C) for each combination of factor and problem size.
Intuitively, it seems that increasing the popula- tion size should improve the performance of the
Table 8 Analysis of variance
Sources of DF SS PBSZ = 10 SS PBSZ = 15 SS PBSZ = 20
variation F-values P-values F-values P-values F-values P-values
Model 32 18.91 3.75 0.0001 185.94 12.90 0.0001 230.72 13.58 0.0001 Error 48 7.56 21.62 25.49 Corrected total 80 26.47 R 2 = 72 207.56 R 2 = 0.90 256.21 R 2 = 0.9005
PPSZ 2 5.31 16.85 a 0.0001 22.48 24.96 a 0.0001 23.12 21.77 a 0.0001 X G E N 2 4.24 13.48 a 0.0001 88.73 98.52 a 0.0001 141.76 133.49 a 0.0001 PCRS 2 0.50 1.60 0.2122 1.51 1.68 0.1969 1.36 1.28 0.2868 PMUT 2 1.78 5.64 a 0.0063 43.52 48.33 ~ 0.0001 35.21 33.15 a 0.0001 PPSZ*XGEN 4 1.76 2.80 0.0364 4.45 2.47 0.0568 3.99 1.88 0.1288 PPSZ*PCRS 4 0.44 0.70 0.5966 1.01 6.76 a 0.0002 0.63 0.30 0.8769
PPSZ*PMUT 4 0.56 0.89 0.4763 1.73 0.96 0.4359 2.27 1.07 0.3806 XGEN*PCRS 4 1.76 2.80 0.0359 1.07 0.60 0.6653 2.39 1.13 0.3557 X G E N * P M U T 4 2.14 3.41 0.0157 12.18 5.12 a 0.0002 1.51 0.71 0.5894 PCRS*PMUT 4 0.39 0.62 0.6512 9.22 2.31 a 0.0016 18.45 8.69 a 0.0001
a Significant at alpha = 0.05,
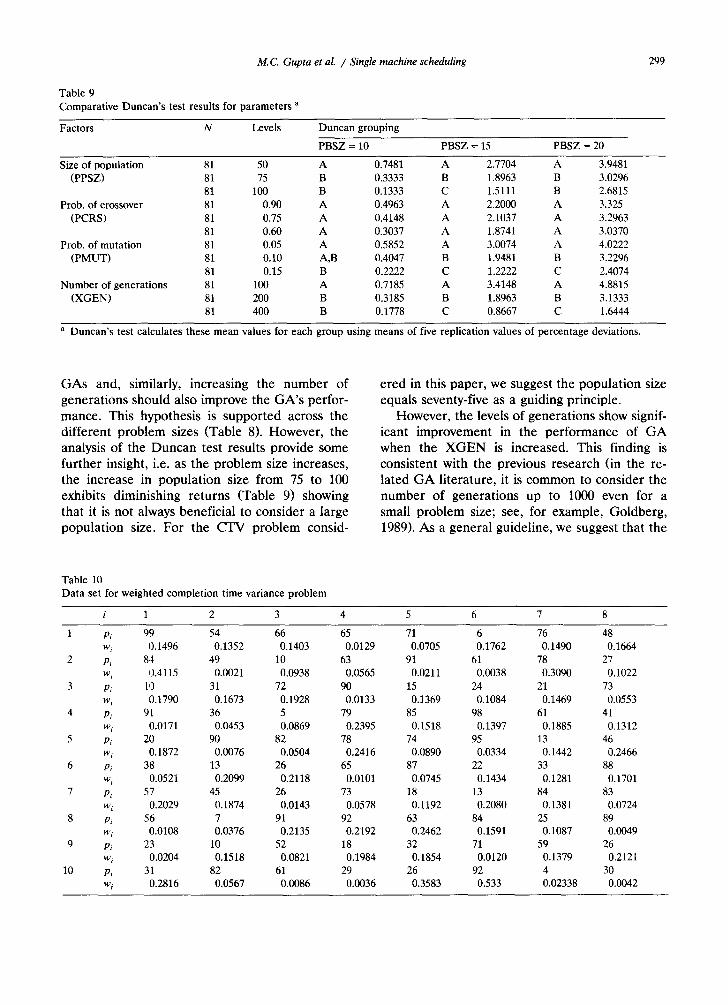
M . C . Gupta et al . / S i n g l e machine scheduling 299
Table 9 Comparative Duncan's test results for parameters a
Factors N Levels Duncan grouping
PBSZ = 10 PBSZ = 15 PBSZ = 20
Size of population 81 50 A 0.7481 A 2.7704 A 3.9481 (PPSZ) 81 75 B 0.3333 B 1.8963 B 3.0296
81 100 B 0.1333 C 1.5111 B 2.6815 Prob. of crossover 81 0.90 A 0.4963 A 2.2000 A 3.325
(PCRS) 81 0.75 A 0.4148 A 2.1037 A 3.2963 81 0.60 A 0.3037 A 1.8741 A 3.0370
Prob. of mutation 81 0.05 A 0.5852 A 3.0074 A 4.0222 (PMUT) 81 0.10 A,B 0.4047 B 1.9481 B 3.2296
81 0.15 B 0.2222 C 1.2222 C 2.4074 Number of generations 81 100 A 0.7185 A 3.4148 A 4.8815
(XGEN) 81 200 B 0.3185 B 1.8963 B 3.1333 81 400 B 0.1778 C 0.8667 C 1.6444
a Duncan's test calculates these mean values for each group using means of five replication values of percentage deviations.
GAs and, similarly, increasing the number of generations should also improve the GA's perfor- mance. This hypothesis is supported across the different problem sizes (Table 8). However, the analysis of the Duncan test results provide some further insight, i.e. as the problem size increases, the increase in population size from 75 to 100 exhibits diminishing returns (Table 9) showing that it is not always beneficial to consider a large population size. For the CTV problem consid-
ered in this paper, we suggest the population size equals seventy-five as a guiding principle.
However, the levels of generations show signif- icant improvement in the performance of GA when the XGEN is increased. This finding is consistent with the previous research (in the re- lated GA literature, it is common to consider the number of generations up to 1000 even for a small problem size; see, for example, Goldberg, 1989). As a general guideline, we suggest that the
Table 10 Data set for weighted completion time variance problem
i 1 2 3 4 5 6 7 8
1 Pi 99 54 66 65 71 6 76 w i I).1496 0.1352 0.1403 0.0129 0.0705 0.1762 0.1490
2 Pi 84 49 10 63 91 61 78 w i I).4115 0.0021 0.0938 0.0565 0.0211 0.0038 0.3090
3 pi 10 31 72 90 15 24 21 w i 0.1790 0.1673 0.1928 0.0133 0.1369 0.1084 0.1469
4 p~ 91 36 5 79 85 98 61 w i 0.0171 0.0453 0.0869 0.2395 0.1518 0.1397 0.1885
5 Pi 20 90 82 78 74 95 13 w i 0.1872 0.0076 0.0504 0.2416 0.0890 0.0334 0.1442
6 P i 38 13 26 65 87 22 33 w i 0.0521 0.2099 0.2118 0.0101 0.0745 0.1434 0.1281
7 Pi 57 45 26 73 18 13 84 w i 0.2029 0.1874 0.0143 0.0578 0.1192 0.2080 0.1381
8 p~ 56 7 91 92 63 84 25 w i 0.0108 0.0376 0.2135 0.2192 0.2462 0.1591 0.1087
9 p~ 23 10 52 18 32 71 59 w i 0.0204 0.1518 0.0821 0.1984 0.1854 0.0120 0.1379
10 Pi 31 82 61 29 26 92 4 w i 0.2816 0.0567 0.0086 0.0036 0.3583 0.533 0.02338
48 0.1664
27 0.1022
73 0.0553
41 0.1312
46 0.2466
88 0.1701
83 0.0724
89 0.0049
26 0.2121
30 0.0042

300 M.C. Gupta et al. / Single machine scheduling
Table 11 Experimental design factors for WCTV problem
Factors Levels
1. Number of generations (XGEN) 50 75
2. Size of population (PPSZ) 100 200
3. Probability of crossover (PCRS) 0.60 0.75
4. Probability of Mutation (PMUT) 0.05 0.10
largest possible number of generations in CTV problem equals 400.
It is observed that the PCRS factor is insignifi- cant whereas PMUT is statistically significant for all three problem sizes. However, with an in- crease in the problem size, the interaction effect of PCRS with PMUT is significant. It suggests that the solution performance can be increased by carefully selecting the combination of PMUT and PCRS. The analysis of Duncan's test suggests some guiding values (i.e. PMUT = 0.15 should be used with PCRS = 0.60) since the crossover rate of 0.60 has been suggested as a guiding value for the conventional GA (see Goldberg, 1989).
Weighted completion time variance (WCTV) problem
In this section, we demonstrate the versatility of the GAs to address more difficult problems. The FVM algorithm is applied to the weighted
completion time variance problem for which no known heuristic algorithm exists.
A set of ten problems is generated by ran- domly choosing the processing times between 1 and 99 for each problem. The job priorities (or weights) are also randomly chosen in such a way that they add up to one for each problem. The problem size is eight, and it kept at this level to obtain the optimal solution for each problem combinatorial. The problem data are provided in Table 10.
The FVM algorithm is used to address the weighted completion time variance problem with- out any significant change. The only modification made is in Step l(iv) and Step 2(iii) of the algo- rithm in calculating the objective function value. The FVM algorithm is implemented for a 2 facto- rial experimental design (Table 11) where each of the four parameters (XGEN, PPSZ, PCRS and PMUT) is at two levels. Thus, the data set con- sists of sixteen design points for each of the ten problems. By evaluating each of these points, we manually selected one specific set which provided the minimum objective function value. (A tie is broken arbitrarily.) The results are shown in Table 12.
The optimal sequences are also given in Table 12 along with the optimal objective function val- ues. The table also shows a specific set of param- eter values used in the FVM algorithms to solve the weighted completion time variance problem. The FVM algorithm provides the optimal solu- tions to all the problems. The results in Table 12 are verified by solving the problem set combina- torial.
Table 12 Optimal sequences and objective function values
No. 1 2 3 4 5 6 7 8 Optimal Parameter values values (XGEN, PPSZ, PCRS, PMUT)
1 4 1 7 8 6 2 3 5 1095.04 (50, 100, 0.60, 0.05) 2 2 5 7 1 3 8 4 6 418.46 (50, 100, 0.60, 0.05) 3 4 3 2 7 1 5 6 8 247.88 (50, 200, 0.60, 0.05) 4 1 6 4 7 3 8 5 2 1096.94 (75, 200, 0.60, 0.05) 5 6 3 4 8 7 1 5 2 527.83 (50, 100, 0.60, 0.05) 6 5 8 6 3 2 7 1 4 378.06 (75, 200, 0.75, 0.05) 7 8 7 1 5 6 2 4 3 614.85 (50, 200, 0.60, 0.05) 8 8 3 4 5 2 7 6 1 1042.35 (75, 100, 0.75, 0.05) 9 6 7 5 8 2 4 3 1 208.09 (50, 200, 0.60, 0.05)
10 4 6 8 1 5 7 2 3 170.78 (75, 100, 0.60, 0.05)

M.C. Gupta et al. / Single machine scheduling 301
Conclusions and future directions
In this paper, GAs are developed for a n job single machine scheduling problem, along with a non-regular performance measure (i:e. comple- tion time variance). The basic design issues for the development of such algorithms are discussed in detail in the context of the current findings in this relatively new area. Specifically, the para- mount concepts of representation, initialization, evaluation function, recombination operators, pa- rameter values, replacement strategy and conver- gence policy, are briefly discussed and their adop- tion to develop the FVM algorithm is justified.
The successful implementation of the FVM algorithm is demonstrated by addressing two problem sets available in the published literature on the completion time variance problem. The algorithm produced optimal schedules for all the problems in problem set 1 and near optimal schedules for most of the problems in the set 2 with an error of less than 0.2% of the optimal solutions for the worst schedules.
Since the successful implementation of GAs depends upon the careful selection of parameter values, rigorous statistical tests are conducted to investigate the impact of these parameters. We found that the various levels of the parameters (population size PPSZ), number of generations (XGEN), problem size (PBSZ), and mutation rate probability (PMUT)) have significant impact on the performance of the FVM genetic algorithm for the CTV problem. Specifically, PBSZ and XGEN have a greater impact than the other parameters, and the crossover rate was found to be insignificant in our study. Further, the interac- tions among these parameters were also signifi- cant, which implied that a specific set of these parameters should be selected carefully for effi- cient implementation of the GAs.
The algorithm developed in this article pro- vides a foundation for additional research on job shop scheduling using nonregular measure of per- formance. The current work still leaves open sev- eral interesting and important issues. For exam- ple, there are cases: (i) where the specific jobs have different weights (penalties), (ii) where the penalties for earliness and tardiness are not the same, and (iii) where the jobs can be processed on any one of the parallel machines. These gen- eral cases, of course, are more difficult to address
in terms of identifying optimal schedules (Bagchi et al., 1987).
In this paper, we successfully demonstrated the application of a GA based approach to a weighted completion time variance problem. We created a data set of ten problems and found optimal solutions for all of them using the GA with a very simple modification. Thus, the most important change required in the algorithm is the computation of the objective function value. Therefore, it may be a worthwhile effort to ex- plore the other cases for which Baker and Scud- der (1990) and Cheng and Gupta (1989) have provided an extensive review.
As discussed earlier, in this paper we use PMX crossover and simple diversification strategy, while a number of alternatives are available in the literature. It would be an interesting study to investigate the performance of other alternative crossovers and diversification strategies for the CTV problem.
GAs are evolutionary in nature; their search procedures and formulation practices are contin- ually changing. These changes may provide im- proved approaches to the problems being consid- ered and hopefully reduce the limitations faced at present. Currently, a great number of ideas has been suggested to improve the speed and accu- racy of the GAs in a variety of fields (Johnson, 1990; Grefenstette, 1987; Yamada and Nakano, 1992; Dorndorf and Pesch, 1992; Ulder et al., 1991). For example, it would be interesting to use GA as a meta-strategy to improve the perfor- mance of local search techniques or problem specific heuristics.
Future research in this area should also in- clude a comparative performance of GAs with other search procedures such as neural networks, tabu search, and simulated annealing when ap- plied in solving CTV problems. Computational times needed by each procedure and the quality of the solution will guide us towards selecting the most appropriate procedure for this class of prob- lems.
Acknowledgements
We acknowledge the constructive comments made by three reviewers and the guest editor on the earlier versions of this paper.

302 M.C. Gupta et al. / Single machine scheduling
References
Aarts, E.H.L., Van Laarhoven, P.J.M., and Uider, N.L.I., (1991) "Local-search-based algorithms for job shop scheduling", Working Paper, University of Eindhoven.
Bagchi, U. (1989) "Simultaneous minimization of mean and variation of flow time and waiting time in single machine systems", Operations Research 37, 118-125.
Bagchi, U., Sullivan, R.S., and Chang, Y.C. (1987), "Minimiz- ing mean squared deviation of completion times about a common due-date", 33, 894-906.
Baker, J.E., (1985) "Adaptive selection methods for genetic algorithms", in: Proc. of 1st International Conference on Genetic Algorithms and Their Applications.
Baker, K.R., and Scudder, G.D. (1990), "Sequencing with earliness and tardiness penalties: A review", Operations Research 38, 22-36.
Biegel, J.E., and Davern, J.J. (1990), "Genetic algorithms and job shop scheduling", Computers and Industrial Engineer- ing 19, 81-91.
Cheng, T.C.E., and Cai, X. (1990), "On the complexity of completion time variance minimization problem", Work- ing Paper, University of Western Australia, Nedlands.
Cheng, T.C.E., and Gupta, M.C. (1989), "Survey of schedul- ing research involving due-date determination decisions", European Journal of Operational Research 38, 156-166.
Cleveland, G.A., and Smith, S.F. (1989), "Using genetic algo- rithms to schedule flow shop releases", in: J.D. Schaffer (ed.), Proc. 3rd Int. Conf. Genetic Algorithms, 160-169.
Davis, L. (1985), "Job shop scheduling with genetic algo- rithms", in: Proc. 1st International Conference on Genetic Algorithms and Their Applications.
Davis, L. (ed.) (1991), Handbook of Genetic Algorithms, Van Nostrand Reinhold, New York.
Davis, L., and Steenstrup, M. (1987), "Genetic algorithms and simulated annealing: An overview", in: L. Davis (ed.), Genetic Algorithms and Simulated Annealing, Los Altos, CA.
De Jong, K.A. (1975), "An analysis of the behavior of a class of genetic adaptive systems", Doctoral Dissertation, Uni- versity of Michigan, Dissertation Abstract International, 36(10), 5140B, (University Microfilms No. 76-9381).
De Jong, K.A. (1980), "Adaptive system design: A genetic approach", IEEE Transactions on Systems, Man, and Cy- bernetics 10 9, 556-574.
Dorndorf, U., and Pesch, E. (1992), "Evolution based learning in a job shop scheduling environment", Working Paper, University of Limburg.
Eilon, S., and Chowdhuary, I.C. (1977), "Minimizing the waiting time variance in the single machine problem", Management Science 567-575.
Fox, B.R., and McMahon, M.B. (1990), "Genetic operators for sequencing problems", Working Paper, Planning and Scheduling Group, McDonnell Douglas Space Systems Co.
Garey, M.R., and Johr~son, D.S. (1979), Computers and In- tractability, Freeman, San Francisco, CA.
Glover, F., and Greenberg, H.J. (1989), "New approaches for heuristic search: A bilateral linkage with Artificial Intelli- gence", European Journal of Operational Research 39, 119-130.
Goldberg, D.E. (1989) Genetic Algorithms in Search, Optimiza- tion, and Machine Learning, Addison-Wesley, Reading MA.
Goldberg, D.E., and Lingle, R. (1985), "Alleles, loci and the Traveling Salesman Problem", in Proc. 1st International Conference on Genetic Algorithms and Their Applications.
Grefenstette, J.J. (1986), "Optimization of control parame- ters for genetic algorithms", IEEE Transactions on Sys- tems, Man, and Cybernetics 16 1, 122-128.
Grefenstette, J.J., "Incorporating problem specific knowledge into genetic algorithms", in: L. Davis (ed.), Genetic Algo- rithms and Simulated Annealing, Los Altos, CA.
Grefenstette, J., Gopal, R., Rosmaita, B., and Van Gucht, D. (1985), "Genetic algorithms for the Traveling Salesman Problem", in: Proc. 1st International Conference on Genetic Algorithm and Their Applications.
Gupta, M.C., Gupta, Y.P., and Bettor, C.R. (1990), "Minimiz- ing the flow time variance in single machine systems", Journal of the Operational Research Society 41, 767-779.
Jog, P., Suh, J.Y., and Van Gucht, D. (1989), "The effects of population size, heuristic crossover and local improvement on a genetic algorithm for the Traveling Salesman Prob- lem", in: J.D. Schaffer (ed.), Proc. 3rd Int. Conf. Genetic Algorithms, 110-115.
Johnson, D.S. (1990), "Local optimization and the Traveling Salesman Problem", in: Proc. 17th Colloq. Automata, Lan- guages, and Programming, 446-461.
Kanet J.J. (1981), "Minimizing variation of flow times in single machine systems", Management Science 37, 1453- 1459.
Kelton, W.D. (1988), "Designing computer simulation experi- ments", in: Proc. of the 1988 Winter Simulation Conference, 15-18.
Liepins, G.E., and Hilliard, M.R. (1989), "Genetic algorithms: Foundations and applications", Annals of Operations Re- search 21, 31-58.
Liepins, G.E., Hilliard, M.R., Palmer, M., and Morrow, M. (1982), "Greedy genetics", in: Proc. 2nd International Con- ference on Genetic Algorithms and Their Applications.
Muhlenbein, H., Gorges-Schleuter, M., and Kramer, O. (1988), "Evolution algorithms in combinatorial Optimization", Parallel Computing 7, 65-85.
Merten, A.G., and Muller, M.E. (1972), "Variance minimiza- tion in single machine sequencing problem", Management Science 18, 518-528.
Nakano, R., and Yamada, T. (1991), "Conventional genetic algorithms for job shop problems", in: Proc. 4th Interna- tional Conf. on Genetic Algorithms and Their Applications, 474-479.
Oliver, L.M., Smith, D.J., and Holland, J.R.C. (1982), "A study of permutation crossover operators on the Traveling Salesman Problem", in: Proc. 2nd International Conference on Genetic Algorithm and Their Applications.
Schaffer, J.D., Caruana, R.A., Eshelman, L.J., and Das, R. (1989), "A study of control parameters affecting online performance of genetic algorithms for function optimiza- tion", in: J.D. Schaffer (ed.), Proc. of the 3rd International Conference on Genetic Algorithms.
Schrage, L. (1975), "Minimizing the time-in-system variance for a finite job set", Management Science 31, 540-543.

M.C. Gupta et al. / Single machine scheduling 303
Smith, D., "Bin packing with adaptive search", in: Proc. 1st International Conference on Genetic Algorithms and Their Applications.
Suh, O.Y., and Van Gucht, D. (1987), "Incorporating heuris- tic information into genetic search", in: Proc. 4th Int. Conf. on Genetic Algorithms and Their Applications, 100- 107.
Syswerda, G. (1991), "Schedule optimization using genetic algorithms", in: (ed), Handbook of Genetic Algorithms, Van Nostrand Reinhold, New York.
Ulder, N.L.J., Aarts, E.H.L., Bandelt, H.-J., Van Laarhoven, P.J.M., and Pesch, E. (1991), "Genetic local search algo- rithms for the Traveling Salesman Problem", in: Proc. 1st.
Int. Workshop on Parallel Problem Solving from Nature, 109-116.
Vani, V., and Raghvachari, M. (1987), "Deterministic and random single machine sequencing with variance mini- mization", Operations Research 35, 111-120.
Whitley, D., Starkweather, T., and Fuquay, D'Ann (1989), "Scheduling problems and traveling salesmen: The genetic edge recombination operator", in: Proc. 3rd International Conference on Genetic Algorithms and Their Applications.
Yamada, T., and Nakano, R. (1992), "A genetic algorithm applicable to large-scale job-shop problems", Working Pa- per, NTT Communication Science Labs, Kyoto.
Related Documents







![Estimation of genetic variation and SNP- heritability … · [Visscheret al. 2010, Twin Research and Human Genetics] 13 Checking for population structure. Genetic variance associated](https://static.cupdf.com/doc/110x72/5b9512b709d3f2de4a8b8428/estimation-of-genetic-variation-and-snp-heritability-visscheret-al-2010.jpg)



