© 2018 Arm Limited Memory Centric High Performance Compu=ng Panel Jonathan Beard 11 November 2018

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

© 2018 Arm Limited
Memory Centric High Performance
Compu=ng PanelJonathan Beard
11 November 2018

© 2018 Arm Limited 2
Trends
End of Frequency Scaling
?End of Moore’s Law
Power keeps going up
More cores/socket
data source: hGps://goo.gl/bb6wZW
© 2018 Arm Limited 3
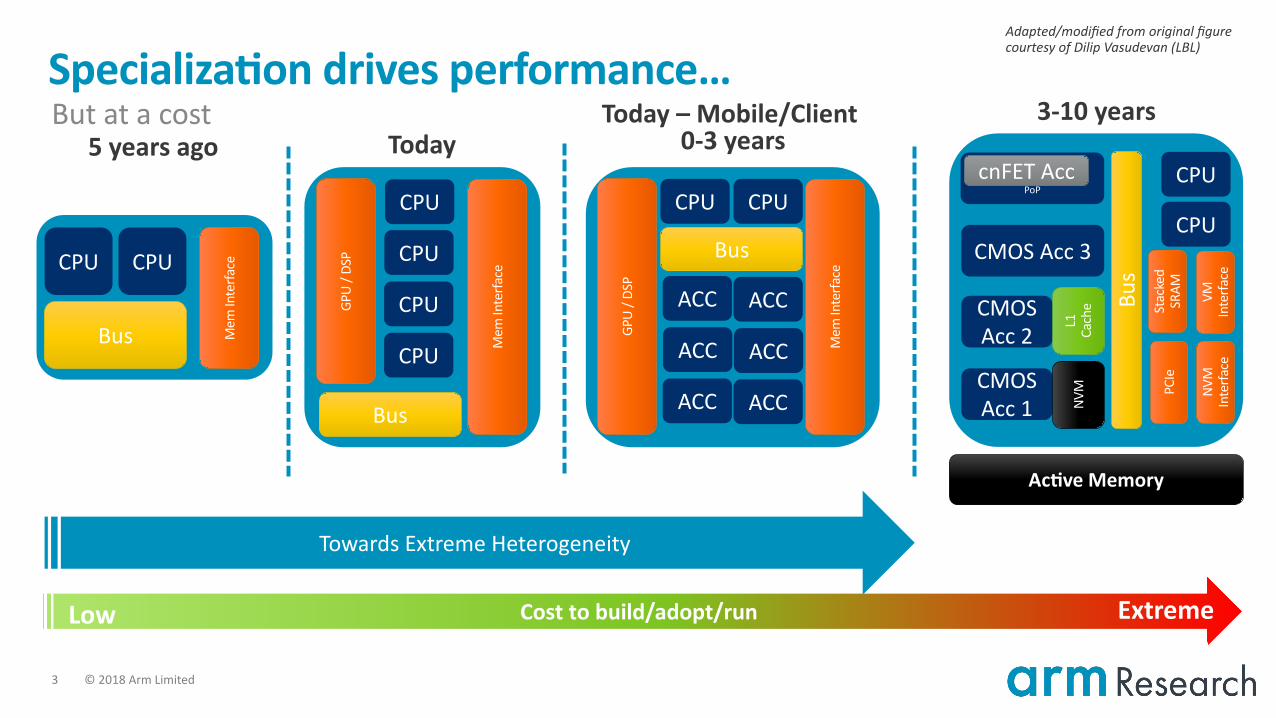
Specializa)on drives performance…But at a cost
Adapted/modified from original figure courtesy of Dilip Vasudevan (LBL)
CPU CPUM
em In
terfa
ce
Bus
CPU
Mem
Inte
rface
Bus
CPU
CPU
CPUGP
U / D
SP
CPU
Mem
Inte
rface
Bus
CPU
ACC
GPU
/ DSP
ACC
ACC
ACC
ACC
ACC
CPU
VM
Inte
rface
Bus
CPU
CMOS Acc 1
CMOS Acc 2
NVM
L1
Cach
e
CMOS Acc 3
PoP
NVM
In
terfa
ce
cnFET Acc
PCIe
Stac
ked
SRAM
Towards Extreme Heterogeneity
Today5 years ago 0-3 years3-10 years
Cost to build/adopt/runLow ExtremeHighLow
Ac)ve Memory
Today – Mobile/Client

© 2018 Arm Limited 4
More cores
●● ● ● ● ●● ● ● ● ●●●● ●●●●●●●●● ●●●●●●●●●●●●●●
●
●
●
●
●
●●●
●
●
●●
●
●
●
●●●●
●●
●●
●
●
●●
●
●
●
●●
●
●
●
●●
●
●
●
●●
1980 1990 2000 2010
1
510
50100
Year
Avg.Co
res/
Socket
The sunk cost• More wiresThe preventable cost• Data movement • Programmer burden
data source: h?ps://goo.gl/bb6wZW
© 2018 Arm Limited 5
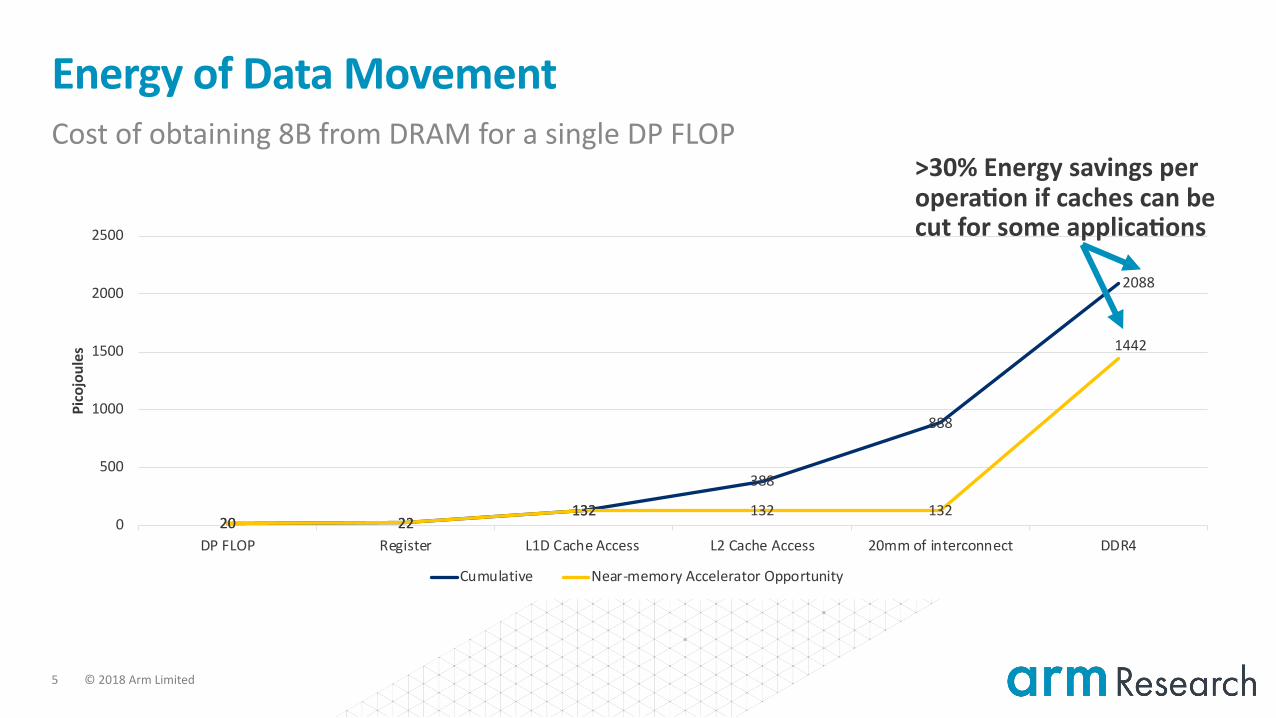
Energy of Data MovementCost of obtaining 8B from DRAM for a single DP FLOP
20 22132
388
888
2088
20 22132 132 132
1442
0
500
1000
1500
2000
2500
DP FLOP Register L1D Cache Access L2 Cache Access 20mm of interconnect DDR4
Pico
joul
es
Cumulative Near-memory Accelerator Opportunity
>30% Energy savings per opera<on if caches can be cut for some applica<ons

© 2018 Arm Limited 6
Rela%vity Locality is, from a certain point of view.
L1
Core
L2
L3 SCM*PE
Data X
Observa%on: Manipula%ng distance by moving processor can expand locality and decrease latency for some workloads
Long distance
Short distance
*Storage Class Memory - NVM

© 2018 Arm Limited 7
Rela%vity
L1
Core
L2
L3 SCM*PE
Data
X
Observa%on: Manipula%ng distance by moving processor can expand locality and decrease latency for some workloads
184 cycles
100 cycles
45% reduc%on in latency if no reuse
*Storage Class Memory - NVM
Locality is, from a certain point of view.

© 2018 Arm Limited 8
Rela%vity Applica3on examples where reuse doesn’t ma<er
2 threads
Host MB/s NUCD MB/s
025005000 0 2500 5000
Benchmark
Linked-list
B-Tree
Hash Table
Degree Centrality
Near-HBM (MB/s)Host (MB/s)
4 threads
1 thread
Big out-of-order
coresL1 L2
CoherentNetwork
L3
MC DDR3
HBM
Tiny Cores 1-4
Memory Controllers
xbar
Gem5 Simula3on Configura3on
Bandwidth Scaling

© 2018 Arm Limited 9
Memory Access LatencyProcessor to Memory speed (clock cycles) ra<o
Parallelism to maintain the same 3me to solu3on
Latency rela3ve to core
Parallelism

© 2018 Arm Limited 10
Scalable parallelism
CMOS Acc 1
NVM
CMOS Acc 2
Cach
e
Code
⚙⚙⚙
CPU
Thousands of mini-threads
Bus
Tens of mini-
threads

© 2018 Arm Limited 11
There’s no such thing as processing in memoryChallenge: breaking the seman@c barrier
Biggest problem with processing in memory is that we call it processing in memory.
These are just accelerators….

© 2018 Arm Limited 12
Interface standardsExplosion of interfaces…can we make them boring?
Bus
CMOS Acc 3
CMOS Acc 1M
RAM
CMOS Acc 2
L1
Cach
e
FuncIon Common Interface
All Accelerators
Code
⚙⚙⚙
CPU
Unlock innova2on on both sides of interface! – Minimize so:ware disrup2on, maximize innova2on pace
Challenge• Make it easy to build accelerators
while making it easy to program / debug them

© 2018 Arm Limited 13
Interface standards
BusCode ⚙⚙⚙ CPU
Challenge• Locality-based targe>ng
Data never rests
L1 L2
L3
Memory Interface
SCM
Time to offload
How long will the data stay put

© 2018 Arm Limited 14
Lost in transla+onWe need virtualiza7on!
Bus
CMOS Acc 3
CMOS Acc 1M
RAM
CMOS Acc 2
L1
Cach
e
IOMMUVirtually addressed
Task
This works for a few course grained accelerators
Imagine your processor of 64 cores sharing only a few of these
IOMMU is effec+vely shared TLB across many high throughput cores. Is this a problem?Challenge• Increase transla7on reach for all cores• Give all cores access to robust
virtualiza7on infrastructure
© 2018 Arm Limited 15
L1
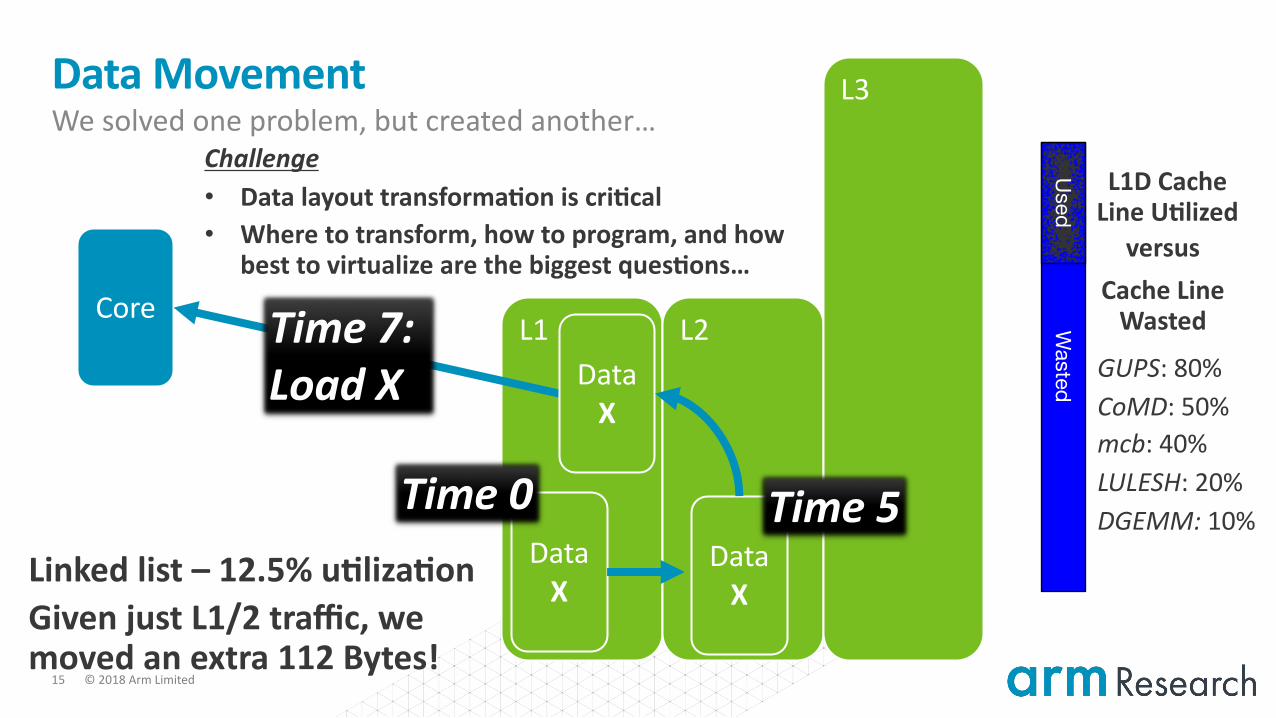
Data Movement We solved one problem, but created another…
Core
Data X
Time 7: Load X
L2
L3
Data X
Data X
Time 0 Time 5
Wasted
Used
GUPS: 80%CoMD: 50%mcb: 40%LULESH: 20%DGEMM: 10%
L1D Cache Line U3lized
Cache Line Wasted
versus
Linked list – 12.5% u3liza3onGiven just L1/2 traffic, we moved an extra 112 Bytes!
Challenge• Data layout transforma3on is cri3cal• Where to transform, how to program, and how
best to virtualize are the biggest ques3ons…

© 2018 Arm Limited 16
Keeping dark bandwidth coherent Hmmm….maybe there’s a be9er way.
Bus
CMOS Acc 3
CMOS Acc 1N
VM
CMOS Acc 2
L1
Cach
e
CPU
CPU
CPU
CPU
request broadcast / ack / send / ack / complete
• Dark Bandwidth blows up transfers, moving one cache line actually moves far more than that!
• With every move comes coherence traffic, oRen lots.
• SynchronizaTon also takes Tme…
CMOS Acc 3
CMOS Acc 1N
VM
CMOS Acc 2
L1
Cach
e
CPU
CPU
CPU
CPU
Bus
Queueing Accelerator
pushstash/pop
Challenge• Improve performance / transparency
of communica<ons between all processing elements.
• Do we really need coherence? (likely not always)

© 2018 Arm Limited 17
System ArchitectureHow to make boring
CMOS Acc 3
CMOS Acc 1N
VM
CMOS Acc 2
L1
Cach
e
Bus
Queueing Accelerator
Accelerated asynchronous dataflow communica5ons
stash/pop
Code
⚙⚙⚙
CPU
Thousands of mini-threads
Task Queue /
Scheduler Accelerators virtualized, near-bare metal performance.
Easy programming using both dataflow and standard procedural styles within the same system.
Programmable Gather / ScaUer

© 2018 Arm Limited 18
CPU
VM
Inte
rface
Bus
CPU
CMOS Acc 1
CMOS Acc 2
NVM
L1
Cach
e
CMOS Acc 3
PoP
NVM
In
terfa
ce
Non-CMOS Acc
PCIe
Stac
ked
SRAM
Ac#ve Memory
CPU
BusCMOS Acc 3
CMOS Acc 1 NV
M
CMOS Acc 2
L1
Cach
e
1: Efficiency of data movement, logic is cheap, movement is expensive – future systems must capitalize on both data with reuse and streaming data, Dark Bandwidth must be avoided
2: Mul#ple drivers / compilers / soDware stacks are mul#-million-dollar efforts for each vendor – will developers even adopt? –Reducing cost is a huge disruptor!
3: Communica#ons / scalability of cores is not good with current coherence methods – but specializa#on and more cores are the future, Post-Moore.
4: Virtualiza#on and transla#on for accelerators is an aDerthought at the moment, extending the virtual memory model eases programming – but can we do more?
Grand Challenges

1919
Thank You!Danke!Merci!��!�����!Gracias!Kiitos!
© 2018 Arm Limited
Related Documents





![Wearable)Compu=ng)cpoellab/teaching/cse40816_fall11/Lecture8.pdf · Whatis)Wearable)Compu=ng?) Seven)aributes)of)wearable)compu=ng)[Steve)Mann,)1998]:)) 1. Unmonopolizing)of)the)user’s)aen=on.)User)can)aend)to)other)events.)](https://static.cupdf.com/doc/110x72/5f343667514155141c2d75f4/wearablecompung-cpoellabteachingcse40816fall11-whatiswearablecompung.jpg)





