MEDLINE in Oracle XML-DB and Oracle Text Peter Stoehr Head of Database Operations European Bioinformatics Institute (EBI) www.ebi.ac.uk racle Life Sciences, OracleWorld, San Francisco, Sep 10 2003

MEDLINE in Oracle XML-DB and Oracle Text Peter Stoehr Head of Database Operations European Bioinformatics Institute (EBI) Oracle Life Sciences,
Dec 20, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

MEDLINE in Oracle XML-DB and Oracle Text
Peter StoehrHead of Database Operations
European Bioinformatics Institute (EBI)
www.ebi.ac.uk
Oracle Life Sciences, OracleWorld, San Francisco, Sep 10 2003

European Molecular Biology Laboratory (EMBL)
International network of research institutes dedicated to research in molecular biology
Treaty organisation funded by 16 member states
Headquarters established in Heidelberg in 1974- research programmes in cell biology, developmental
biology, instrumentation, gene expression etc
Outstations- Hamburg and Grenoble: structural biology- Monterotondo: mouse genetics- Hinxton, EBI: bioinformatics

European Bioinformatics Institute (EBI)
Mandate
to ensure the growing body of data and information from molecular biology and genome research is placed in the public domain and is accessible freely to all facets of the scientific community in ways that promote scientific progress and global competitiveness
to support academic research as well as biotech, agricultural, chemical and pharmaceutical industries
The EBI builds, develops and publishes databases and information services relevant to molecular biology, as well as conducting research in bioinformatics.

About EBI
Located in Hinxton, Cambridge, England (since 1993)
Non-profit organisation - part of EMBL Started as EMBL Data Library in 1980 Centre for research and services in
bioinformatics Three branches: Services, Research, Industry Funding mainly from EMBL and EU

EBI Resources
Personnel
- 220 people
- ~100 Database developers, software engineers
- DBA - 4
- Systems - 6
Environment
- OS: Tru64 ES45s, Solaris
- Storage: SAN storage, NetApp NFS
- 350-cpu linux compute farm

Major public databases at the EBI DNA sequences - EMBL Nucleotide Sequence Database protein sequences - SWISS-PROT, TrEMBL, Interpro, CluSTr genome annotation - Ensembl protein structures - MSD microarrays - ArrayExpress literature - MEDLINE, patents, fulltext
enzymes - IntEnz protein interactions - IntAct immunogenetics - IMGT, HLA
integration - Integr8, EnsMart
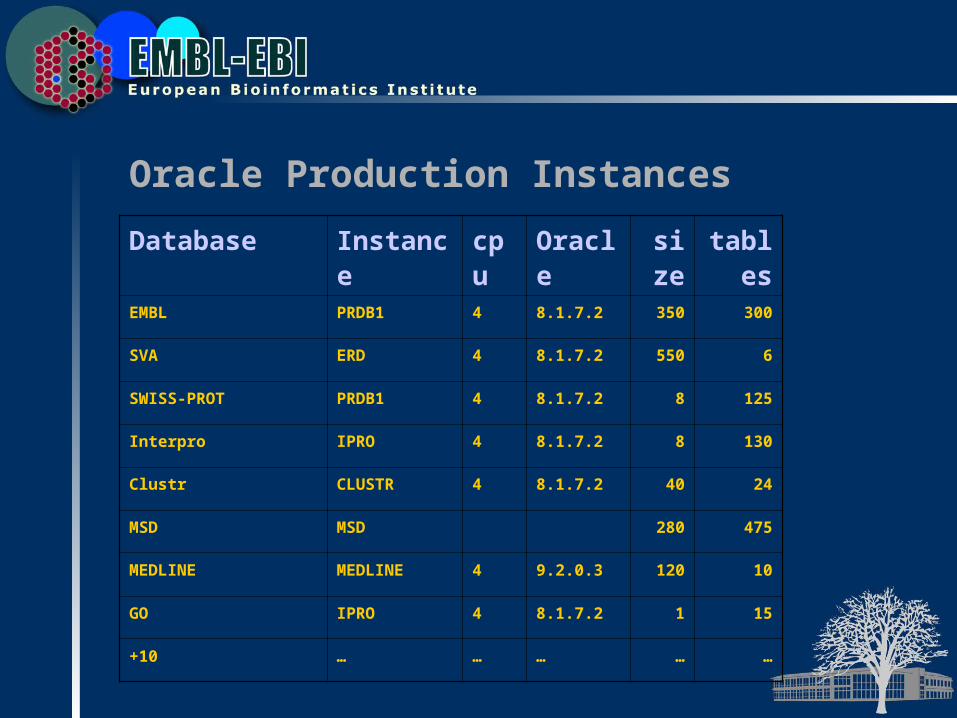
Oracle Production Instances
Database Instance cpu Oracle size tablesEMBL PRDB1 4 8.1.7.2 350 300
SVA ERD 4 8.1.7.2 550 6
SWISS-PROT PRDB1 4 8.1.7.2 8 125
Interpro IPRO 4 8.1.7.2 8 130
Clustr CLUSTR 4 8.1.7.2 40 24
MSD MSD 280 475
MEDLINE MEDLINE 4 9.2.0.3 120 10
GO IPRO 4 8.1.7.2 1 15
+10 … … … … …

Statistics
26 million nucleotide sequences (25b bases)
1 million protein sequences
200 complete genomes (+viruses, organelles)
28,000 genes in human genome
10,000 protein 3D structures
2500 journals with sequences
12 million MEDLINE citations, 4500 journals
130,000 biotech patent documents
550,000 web hits per day, www.ebi.ac.uk

EBI interest in text resources
• provide links from factual databases to full-text literature (journals, patents…)
• mine for information relevant to factual database annotation.
• most scientific information buried in free text resources
• enable indexing and searching of full-text literature

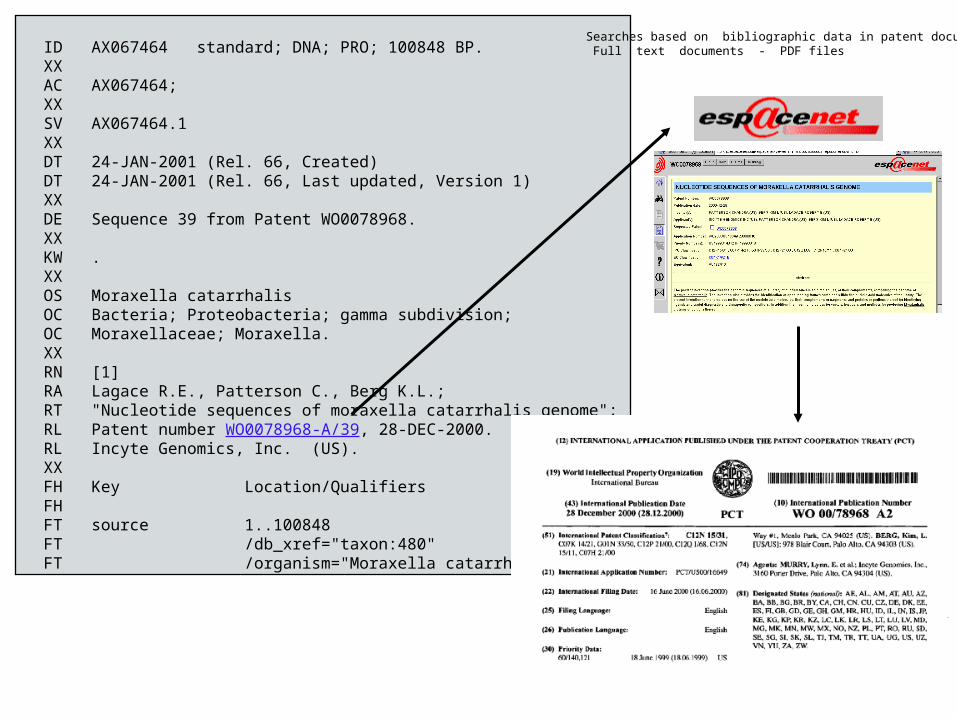
espacenet
ID AX067464 standard; DNA; PRO; 100848 BP.XXAC AX067464;XX SV AX067464.1XXDT 24-JAN-2001 (Rel. 66, Created)DT 24-JAN-2001 (Rel. 66, Last updated, Version 1)XXDE Sequence 39 from Patent WO0078968.XXKW .XXOS Moraxella catarrhalisOC Bacteria; Proteobacteria; gamma subdivision; OC Moraxellaceae; Moraxella.XXRN [1]RA Lagace R.E., Patterson C., Berg K.L.;RT "Nucleotide sequences of moraxella catarrhalis genome";RL Patent number WO0078968-A/39, 28-DEC-2000.RL Incyte Genomics, Inc. (US).XXFH Key Location/QualifiersFHFT source 1..100848FT /db_xref="taxon:480"FT /organism="Moraxella catarrhalis"
Searches based on bibliographic data in patent documents Full text documents - PDF files

EBI interest in text resources
• provide access from factual databases to full-text literature (journals, patents…)
• mine for information relevant to factual database annotation.
• most scientific information buried in free text resources
• enable indexing and intelligent searching of full-text literature


Areas of improvement for public text resources
• improve text retrieval functionality
• improve and add text corpora
• use of thesauri and ontologies (UMLS, SNOMED,GO, GOBO)
• interfaces

Text corpora
• MEDLINE
• Full-text literature
• AGRICOLA
• Biotech patent abstracts
• Biotech patent full-text
• OMIM
• The web
• => public searchable services

Speed of searches
Speed of indexing
Ability to search multiple data sources and formats,MEDLINE in XMLEMBL/SWISS-PROT-type structured fileswebsitesWord, PDF and text, email/jitterbug filesRDBMS (ORACLE and MySQL,
Postgres)
Ability to handle large database/collections
Text query functionsNatural languageBoolean operatorsPhrase searchesProximity searchesUse of synonyms, ontologies, thesauriesp. UMLS/MeSH, GOStemming and wild-carding
Multiple language support (for patent literature)
Document clustering functionality
Search refinenement, set operators
Ranking of results (relevance, date)
Search engine evaluation criteria
Weighting of search
Scaleability of indexing, searching Load balancing on multiple
nodesParallel processing
Incremental and off-line indexing
Ease of use of APIs, documentation
API languages, C/Java/Perl
Interoperabilty with SRS
Market strength of vendor
Availability on multiple unix platformsesp. Tru64, Linux and Solaris
Technical support
Licence costs and flexibility

Text search/extraction systemsAltavista
Verity
Inktomi
ASPseek
Autonomy
Thunderstone
Excalibur
Fulcrum
SPSS/LexiQuest
Stratify/”Purple Yogi”
Dolphinsearch
Quiver
Oracle Text
X-Mine - “Opus”
Diogene
incellico - “Cell Entity Browser”
Collexis
Alma
PharmDM
Linguamatics
Inxight
ClearForest
APRSmartLogik
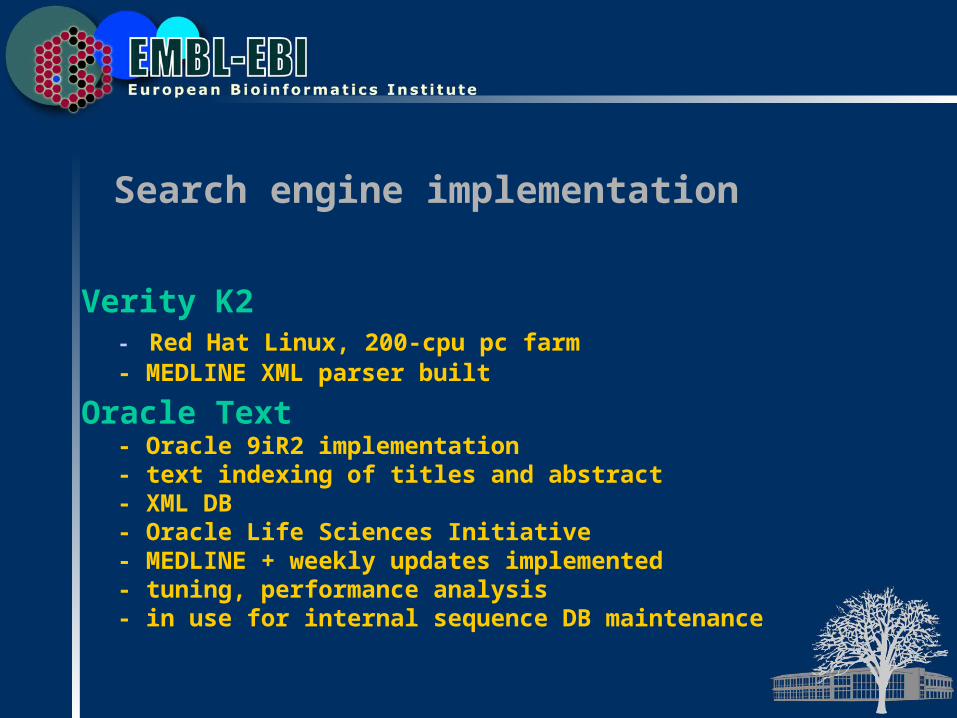
Search engine implementation
Verity K2- Red Hat Linux, 200-cpu pc farm- MEDLINE XML parser built
Oracle Text- Oracle 9iR2 implementation- text indexing of titles and abstract- XML DB- Oracle Life Sciences Initiative- MEDLINE + weekly updates implemented- tuning, performance analysis- in use for internal sequence DB maintenance

MEDLINE
• National Library of Medicine (NLM) Bethesda
• 530 XML files, following NLM DTD
• ~ 12 million citations published in over 4500 biomedical journals
• Daily updates

MEDLINE record view in SRS
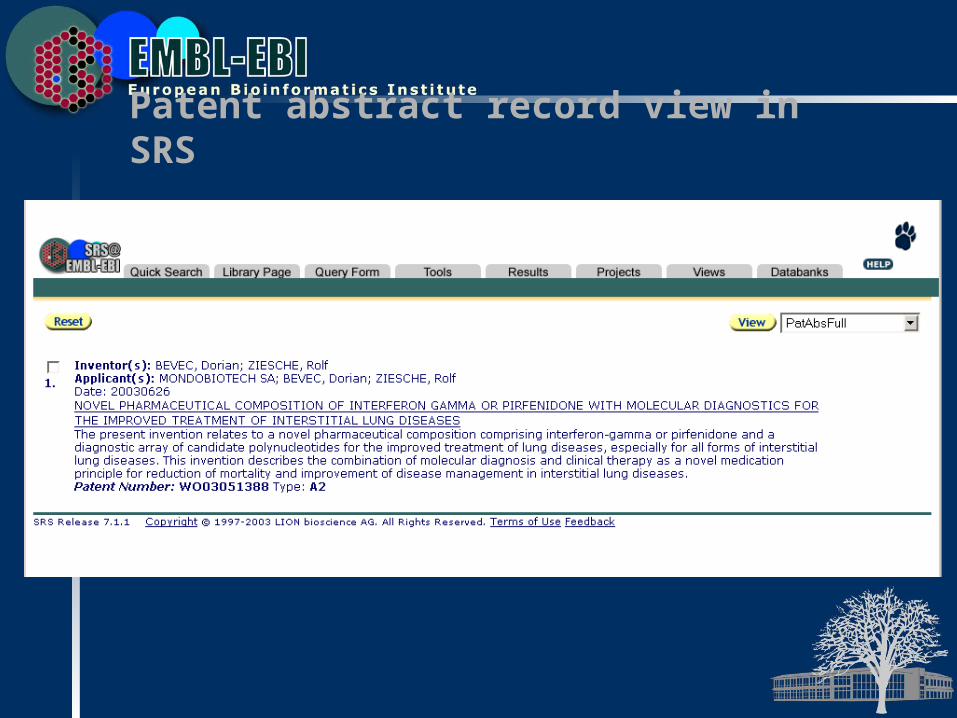
Patent abstract record view in SRS

Patent abstract in XML

Medline in XML
<!DOCTYPE MedlineCitationSetPUBLIC "-//NLM//DTD NLM Medline, 1st November 2002//EN” "http://www.nlm.nih.gov/databases/dtd/nlmmedline_021101.dtd><MedlineCitationSet><MedlineCitation Owner="NLM” Status="Completed"><MedlineID>94033980</MedlineID><PMID>8219565</PMID>…...<Journal><ISSN>1051-0443</ISSN><JournalIssue><Volume>4</Volume><Issue>5</Issue><PubDate><MedlineDate>1993 Sep-Oct</MedlineDate></PubDate></JournalIssue></Journal>…</MedlineCitation>…………..<MedlineCitationSet>

Possible Approaches
Fast, efficient,Domain standardLack of text query functions
Fast, efficient for simple queryPre-processing required, hard to maintain,lack of text query functions, requesting multiple joins for more info
Efficient,support text queryReturn data as XML, post-processing required
Efficient text query, scaleable, industry standard Return data as XML, post-processing required
Oracle XML-DB
Oracle Text
Verity K2
Normalised relational tables
SRS
MEDLINE/Patent XML

Why Oracle XML DB for Medline ?
Oracle 9iR2 embedded XML features with DBMS
• XMLType datatypeLOB storage
- maintains original XML byte for byte- can use an Oracle text index, support Xpath queries- flexible when schemas change
object-relational storage- better performance, index specific fields- access to SQL features (constraints, indices etc)
- DOM fidelity (ordering, namespaces, inhertitance…)- piecewise XML element update
• XMLSchema support

Why Oracle Text for Medline ?
Oracle 9i embedded Text features with DBMS
• Powerful and extensive text functions- wildcards, boolean, stemming, proximity searches, NLP linguistic features, pattern matching, ‘soundex’
• XML specific operators, HASPATH, INPATH etc, to supportXPATH like expressions
• Relevance ranking• Multi-lingual features• Extensions to SQL*Plus• Management of thesauri• Classification (CTXRULE indextype)• Unsupervised document Clustering• Documentation pretty good

Oracle RDBMS, XML DB and Text
One product range
- Cost (already purchased and used RDBMS)
- lower complexity – common administration, training, backup, replication, RAC etc
- lower latency of development/deployment
- no incompatible product updates, gateways etc
- greater performance for mixed queries

Prepare XMLSchema from DTD
• NLM MEDLINE DTD
• XML-Spy
• To use Oracle CLOB type:<xs:schema xmlns:xs=http://www.w3.org/2001/XMLSchemaxmlns:xdb=http://xmlns.oracle.com/xdb elementFormDefault="qualified" xdb:storeVarrayAsTable="true"><xs:element name="Abstract" xdb:SQLType="CLOB"/>
• => XMLSchema
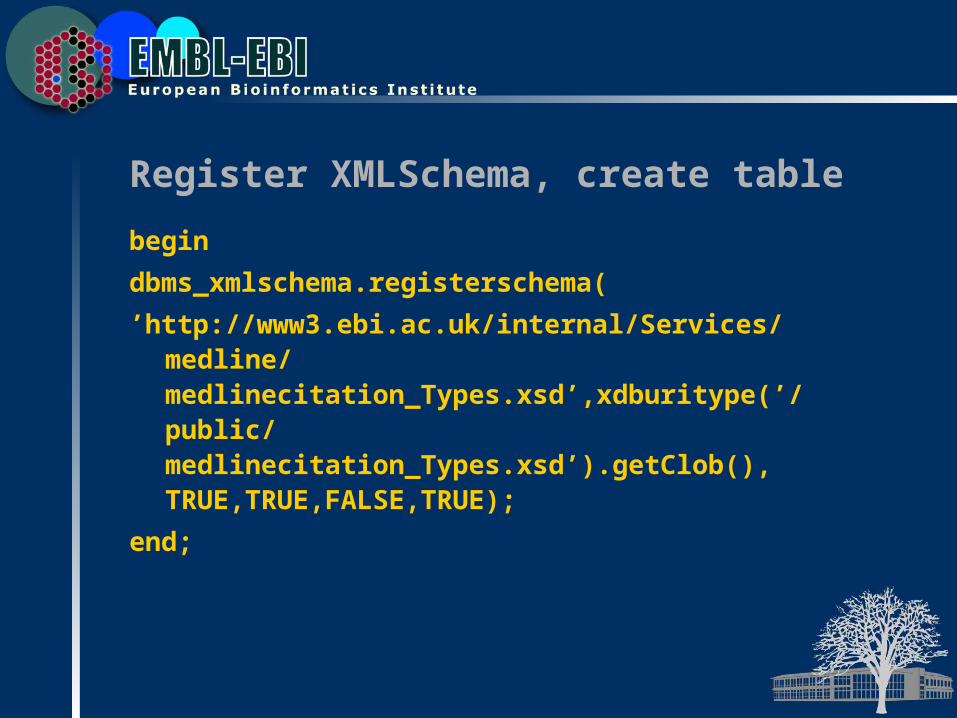
Register XMLSchema, create table
begin
dbms_xmlschema.registerschema(
’http://www3.ebi.ac.uk/internal/Services/medline/medlinecitation_Types.xsd’,xdburitype(’/public/medlinecitation_Types.xsd’).getClob(), TRUE,TRUE,FALSE,TRUE);
end;

Load data
• SQL*Loader
• We use a Java application, JDBC- need to control updates, deletions.
• synchronize context indexexec ctx_ddl.sync_index(‘title_ind’,’40M’);
• Complete MEDLINE:- 1 day to load, 1 day for context indexing
• Updates- 10 mins

Actual MEDLINE instances @EBI
• 9iR2 in Production- MEDLINE + patent abstracts- updated twice per week- used for in-house reference- CLOB storage of XMLType field- partitioned (by date) context index of XMLType
• 9iR2 in development- using structured object-relational storage- indexing fields, inc. context indextype for titles, abstracts- no partioning

MED production schema
Control vocabularies
Auxiliary tables
converted to
comply with
includes
consists of(0..n)
describes
controlled by
MedlineCitationSet
MedlineCitation
DeleteCitationDeleteCitation_Id
#PMID numberUndeleted char(1)
MedlineCitationSetFrame
Heading varchr2(256)Start_tag varchar2(50)MedlineCitation XMLType nullDeleteCitation XMLType nullEnd_tag varchr2(50)
DTD#Name varchar2(56)NLMURL varchar2 (150)InternalLocation varchar2(150)Doc clob
XMLSchema#Name varchar2 (56)URL varchar2 (150)Doc clob
MedlineCitation#PMID numberMedlineID number
PubYear number
Mesh_Tree_CV
#Mesh_Id varchar2 (40)Parent_Id varchar2 (40)Descriptor varchar2 (300)Rank number (2)
Qualifier_CV
#Qualifier_id varchar2 (15) Qualifier varchar2 (40) Qualifier_Abbr varchar2 (5)
PubMed_Journal_CV
#JrId number,JournalTitle varchar2(500),MedAbbr varchar2(255),ISSN varchar2(9),ESSN varchar2(9),IsoAbbr varchar2(255),NlmId varchar2(25));
Entrez_Journal_CV
#JrId number,JournalTitle varchar2(500),MedAbbr varchar2(255),ISSN varchar2(9),ESSN varchar2(9),IsoAbbr varchar2(255),NlmId varchar2(25));
included in
Language_CV
#Abbr varchar2 (3) Name varchar2 (255)
Legend:#-- primary key
MedlineCitation XMLType
registeredwith
PublicationType_CV
#ID numberName varchar2 (255)
CitationSubSet_CV
#ID varchar2 (3) Name varchar2 (255)
UpdateCitation_Info
PMID numberTimeUpdated timestamp(0)TimeDeleted timestamp(0)
refereed to

Main Table: MedlineCitation
MedlineCitation
#PMID numberMedlineID number
PubYear numberdummy clob
MedlineCitation XMLType
Table is partitioned into 8
XMLtype Column is registered with XMLSchema, locally context type indexed

select m.MedlineCitation.getClobVal() AS MedXML from Medlinecitation m where pmid=8219565;
--return a full XML document:<MedlineCitation Owner="NLM” Status="Completed"><MedlineID>94033980</MedlineID><PMID>8219565</PMID>…...<Article><Journal><ISSN>1051-0443</ISSN><JournalIssue><Volume>4</Volume><Issue>5</Issue><PubDate><MedlineDate>1993 Sep-Oct</MedlineDate></PubDate></JournalIssue></Journal><ArticleTitle>Transcatheter manipulation of asymmetrically opened titanium Green field filters.</ArticleTitle><Pagination><MedlinePgn>687-90</MedlinePgn></Pagination>……<Article> …</MedlineCitation>
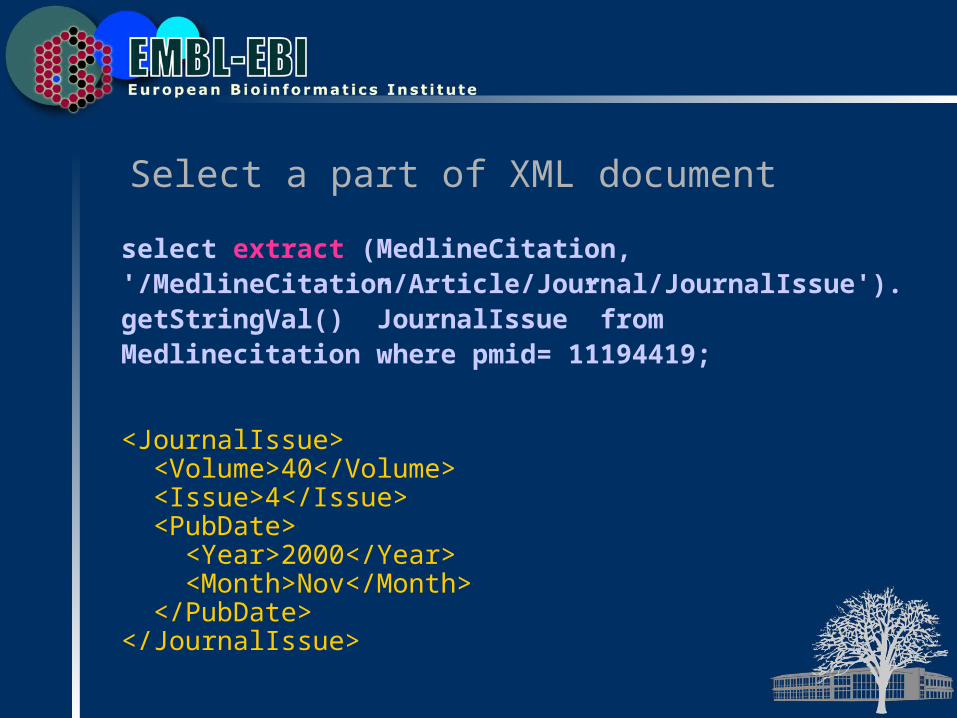
Select a part of XML document
select extract (MedlineCitation, '/MedlineCitation/Article/Journal/JournalIssue').getStringVal() ”JournalIssue” from Medlinecitation where pmid= 11194419;
<JournalIssue> <Volume>40</Volume> <Issue>4</Issue> <PubDate> <Year>2000</Year> <Month>Nov</Month> </PubDate></JournalIssue>
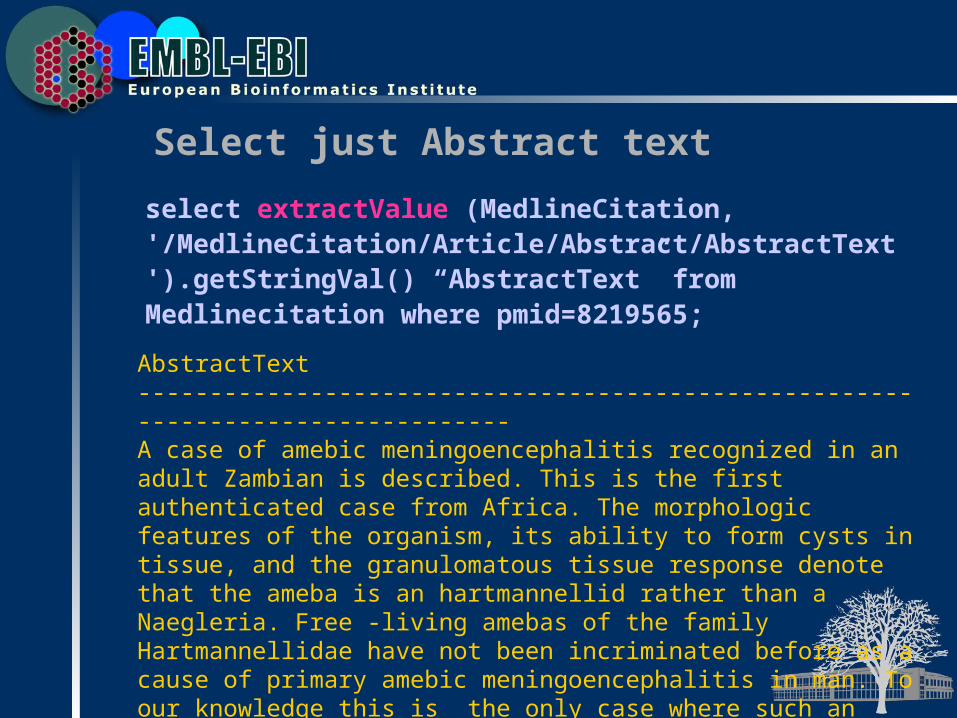
Select just Abstract text
select extractValue (MedlineCitation, '/MedlineCitation/Article/Abstract/AbstractText').getStringVal() “AbstractText” from Medlinecitation where pmid=8219565;
AbstractText--------------------------------------------------------------------------------A case of amebic meningoencephalitis recognized in an adult Zambian is described. This is the first authenticated case from Africa. The morphologic features of the organism, its ability to form cysts in tissue, and the granulomatous tissue response denote that the ameba is an hartmannellid rather than a Naegleria. Free -living amebas of the family Hartmannellidae have not been incriminated before as a cause of primary amebic meningoencephalitis in man. To our knowledge this is the only case where such an ameba was responsible for fulminating meningoencephalitis. The presence of the amebas in a cellulocutaneous abdominal lesion sugges ts hematogenous dissemination.

Improvements - can create additional relational tables
Citation
PMID number primary key,MedlineID number,ArticleTitle VARCHAR2(1500),Volume VARCHAR2(55),Issue VARCHAR2(55),StartPage VARCHAR2(55),EndPage VARCHAR2(55),MedlinePgn VARCHAR2(100),PubYear number,ISSN VARCHAR2(9),NlmUniqueId VARCHAR2(25),AuthorListCompleteYN
VARCHAR2(1)
Author
PMID number foreign key,
LastName VARCHAR2(255),
Initials VARCHAR2(255),
Suffix VARCHAR2(25),
CollectiveName VARCHAR2(1000),
Affiliation VARCHAR2(1000),
Rank number
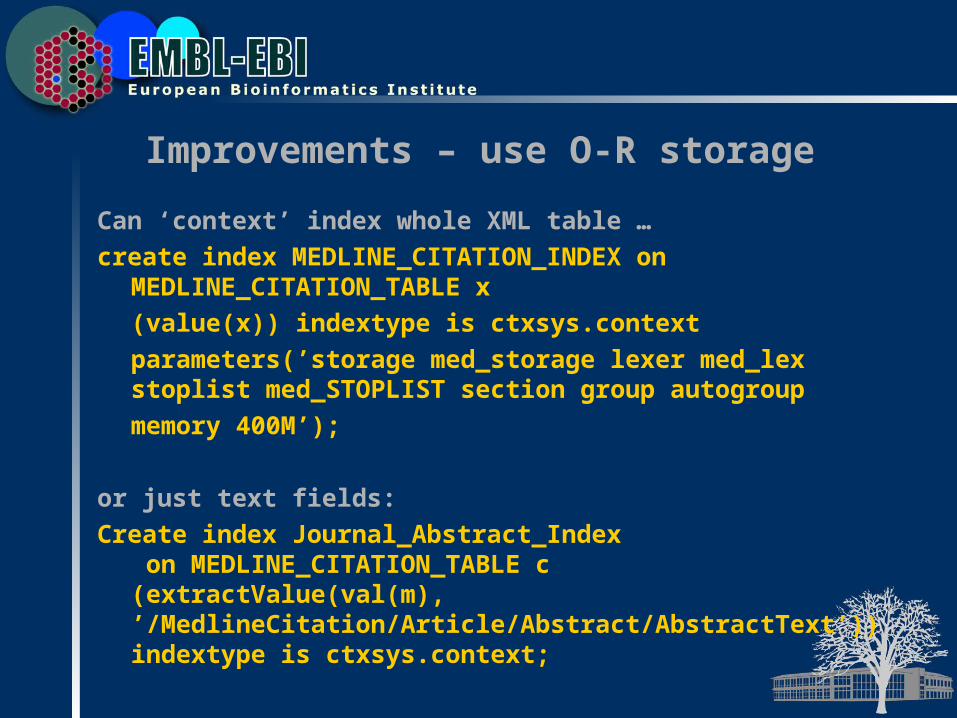
Improvements – use O-R storage
Can ‘context’ index whole XML table …
create index MEDLINE_CITATION_INDEX on MEDLINE_CITATION_TABLE x(value(x)) indextype is ctxsys.contextparameters(’storage med_storage lexer med_lexstoplist med_STOPLIST section group autogroupmemory 400M’);
or just text fields:
Create index Journal_Abstract_Index on MEDLINE_CITATION_TABLE c(extractValue(val(m),’/MedlineCitation/Article/Abstract/AbstractText’))indextype is ctxsys.context;

Improvements S-R storage - index specific fields
create unique index MEDLINE_PMID_INDEX on MEDLINE_CITATION_TABLE m
(extractValue(value(m),'/MedlineCitation/PMID'))
create index AUTHOR_LASTNAME_INDEX on ARTICLE_AUTHOR_TABLE a
(a."LastName")
create index JOURNAL_ISSN_INDEX on MEDLINE_CITATION_TABLE c
( extractValue(value(c),'/MedlineCitation/Article/Journal/ISSN') )
create index JOURNAL_VOLUME_INDEX on MEDLINE_CITATION_TABLE c
(extractValue(value(c),'/MedlineCitation/Article/Journal/JournalIssue/Volume'),
extractValue(value(c),'/MedlineCitation/Article/Journal/JournalIssue/Issue'))
create index PAGINATION_INDEX on MEDLINE_CITATION_TABLE c
( extractValue(value(c),'/MedlineCitation/Article/Pagination/MedlinePgn'))
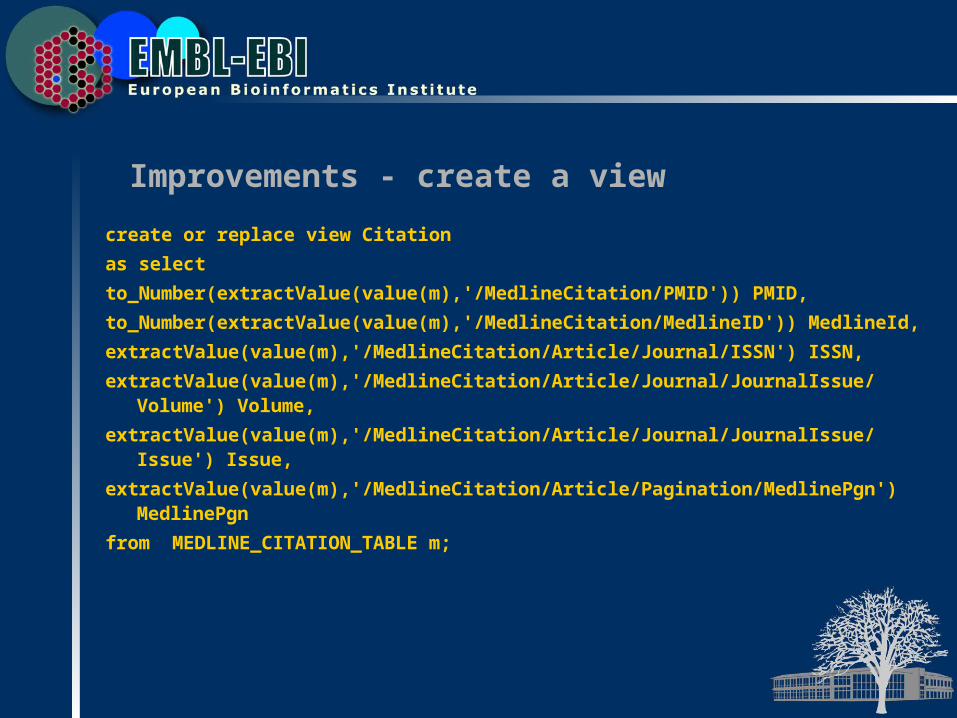
Improvements - create a view
create or replace view Citation
as select
to_Number(extractValue(value(m),'/MedlineCitation/PMID')) PMID,
to_Number(extractValue(value(m),'/MedlineCitation/MedlineID')) MedlineId,
extractValue(value(m),'/MedlineCitation/Article/Journal/ISSN') ISSN,
extractValue(value(m),'/MedlineCitation/Article/Journal/JournalIssue/Volume') Volume,
extractValue(value(m),'/MedlineCitation/Article/Journal/JournalIssue/Issue') Issue,
extractValue(value(m),'/MedlineCitation/Article/Pagination/MedlinePgn') MedlinePgn
from MEDLINE_CITATION_TABLE m;
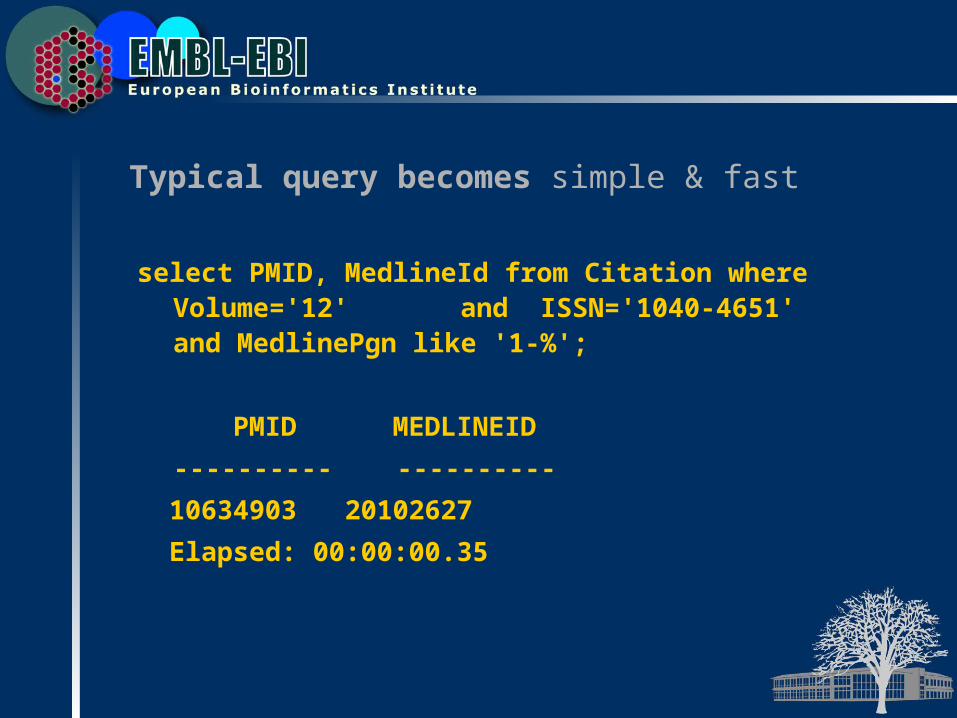
Typical query becomes simple & fast
select PMID, MedlineId from Citation where Volume='12' and ISSN='1040-4651' and MedlinePgn like '1-%';
PMID MEDLINEID
---------- ----------
10634903 20102627
Elapsed: 00:00:00.35

Text query examples
SELECT score, pmid, title FROM citationWHERE CONTAINS(abstract,’gene NEAR expression’,1) >0ORDER BY score(1) DESC;
SELECT pmid, title FROM citationWHERE CONTAINS(abstract,’DrosophilaAND ABOUT(adh)’)>0;

Next steps
• lexical functionality of Oracle Text
• thesauri (UMLS, GO, SNOMED)
• scaleability (linux RAC ?)
• concept extraction, classification, clustering
• application to database curation
• interfaces: web services, GUI

Acknowledgements
Leader: Peter Stoehr, Weimin Zhu
DBA: Muruli Rao, Olalekan Oyewole
Developer: Lichun Wang
Oracle Support: Mark Drake (XML)
Roger Ford (Text)
Related Documents











