Maximum likelihood: counterexamples, examples, and open problems Jon A. Wellner University of Washington Maximum likelihood: – p. 1/7

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Maximum likelihood:
counterexamples, examples, and open problems
Jon A. Wellner
University of Washington
Maximum likelihood: – p. 1/7

• Talk at University of Idaho ,Department of Mathematics, September 15, 2005
• Email: [email protected]: //www.stat.washington.edu/jaw/jaw.research.html
Maximum likelihood: – p. 2/7

Outline
• Introduction: maximum likelihood estimation
Maximum likelihood: – p. 3/7

Outline
• Introduction: maximum likelihood estimation• Counterexamples
Maximum likelihood: – p. 3/7

Outline
• Introduction: maximum likelihood estimation• Counterexamples• Beyond consistency: rates and distributions
Maximum likelihood: – p. 3/7

Outline
• Introduction: maximum likelihood estimation• Counterexamples• Beyond consistency: rates and distributions• Positive examples
Maximum likelihood: – p. 3/7

Outline
• Introduction: maximum likelihood estimation• Counterexamples• Beyond consistency: rates and distributions• Positive examples• Problems and challenges
Maximum likelihood: – p. 3/7

1. Introduction: maximum likelihood estimation
• Setting 1: dominated families
Maximum likelihood: – p. 4/7

1. Introduction: maximum likelihood estimation
• Setting 1: dominated families• Suppose that X1, . . . ,Xn are i.i.d. with density pθ0 with
respect to some dominating measure µ wherepθ0 ∈ P = {pθ : θ ∈ Θ} for Θ ⊂ Rd.
Maximum likelihood: – p. 4/7

1. Introduction: maximum likelihood estimation
• Setting 1: dominated families• Suppose that X1, . . . ,Xn are i.i.d. with density pθ0 with
respect to some dominating measure µ wherepθ0 ∈ P = {pθ : θ ∈ Θ} for Θ ⊂ Rd.
• The likelihood is
Ln(θ) =n∏
i=1
pθ(Xi) .
Maximum likelihood: – p. 4/7

1. Introduction: maximum likelihood estimation
• Setting 1: dominated families• Suppose that X1, . . . ,Xn are i.i.d. with density pθ0 with
respect to some dominating measure µ wherepθ0 ∈ P = {pθ : θ ∈ Θ} for Θ ⊂ Rd.
• The likelihood is
Ln(θ) =n∏
i=1
pθ(Xi) .
• Definition: A Maximum Likelihood Estimator (or MLE) of θ0 isany value θ̂ ∈ Θ satisfying
Ln(θ̂) = supθ∈Θ
Ln(θ) .
Maximum likelihood: – p. 4/7

• Equivalently, the MLE θ̂ maximizes the log-likelihood
log Ln(θ) =n∑
i=1
log pθ(Xi) .
Maximum likelihood: – p. 5/7

• Example 1. Exponential (θ). X1, . . . ,Xn are i.i.d. pθ0 where
pθ(x) = θ exp(−θx)1[0,∞)(x).
Maximum likelihood: – p. 6/7

• Example 1. Exponential (θ). X1, . . . ,Xn are i.i.d. pθ0 where
pθ(x) = θ exp(−θx)1[0,∞)(x).
• Then the likelihood is
Ln(θ) = θn exp(−θn∑1
Xi),
Maximum likelihood: – p. 6/7

• Example 1. Exponential (θ). X1, . . . ,Xn are i.i.d. pθ0 where
pθ(x) = θ exp(−θx)1[0,∞)(x).
• Then the likelihood is
Ln(θ) = θn exp(−θn∑1
Xi),
• so the log-likelihood is
log Ln(θ) = n log(θ) − θ
n∑1
Xi
Maximum likelihood: – p. 6/7

• Example 1. Exponential (θ). X1, . . . ,Xn are i.i.d. pθ0 where
pθ(x) = θ exp(−θx)1[0,∞)(x).
• Then the likelihood is
Ln(θ) = θn exp(−θn∑1
Xi),
• so the log-likelihood is
log Ln(θ) = n log(θ) − θ
n∑1
Xi
• and θ̂n = 1/Xn.
Maximum likelihood: – p. 6/7
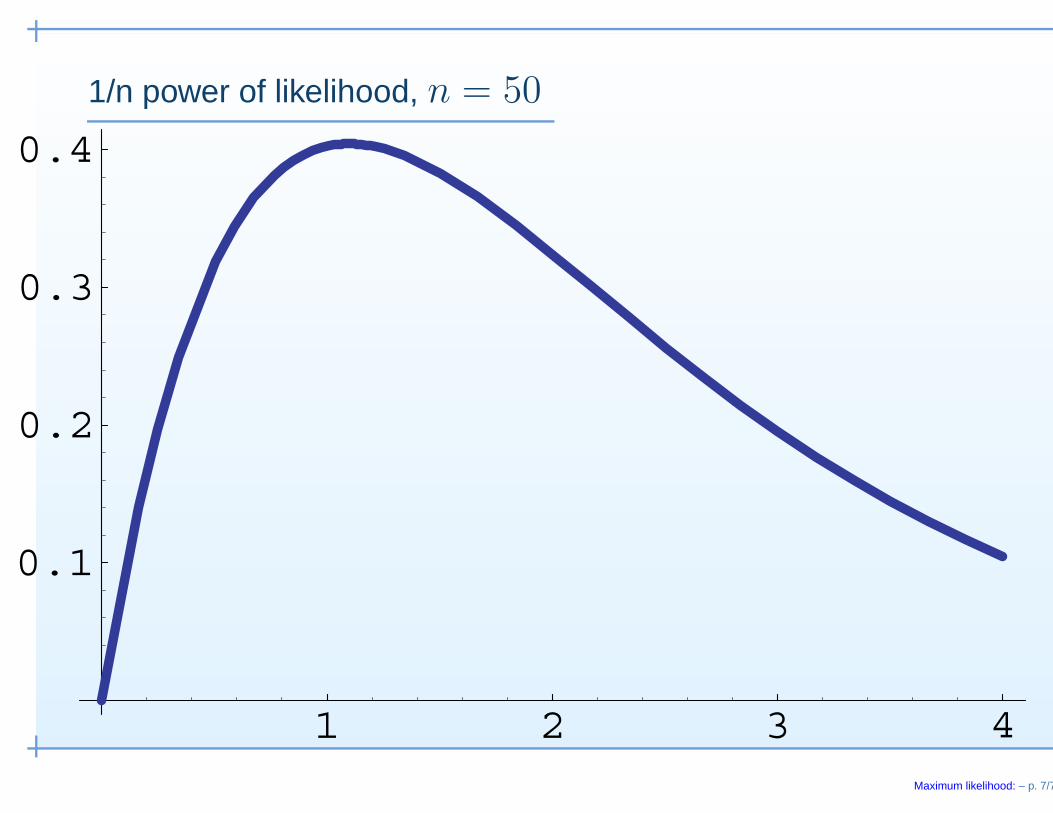
1/n power of likelihood, n = 50
1 2 3 4
0.1
0.2
0.3
0.4
Maximum likelihood: – p. 7/7
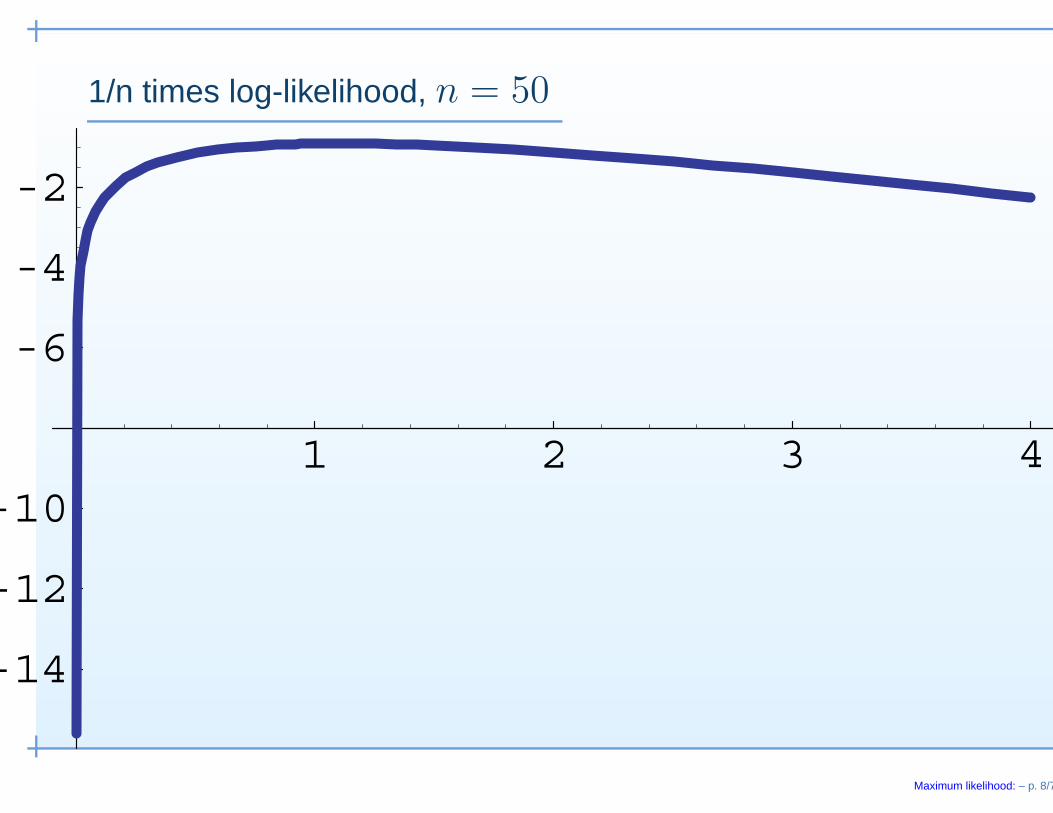
1/n times log-likelihood, n = 50
1 2 3 4
-14
-12
-10
-6
-4
-2
Maximum likelihood: – p. 8/7

MLE pθ̂(x) and true density pθ0(x)
1 2 3 4 5
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 9/7

• Example 2. Monotone decreasing densities on (0,∞).X1, . . . ,Xn are i.i.d. p0 ∈ P where
P = all nonincreasing densities on (0,∞).
Maximum likelihood: – p. 10/7

• Example 2. Monotone decreasing densities on (0,∞).X1, . . . ,Xn are i.i.d. p0 ∈ P where
P = all nonincreasing densities on (0,∞).
• Then the likelihood is Ln(p) =∏n
i=1 p(Xi);
Maximum likelihood: – p. 10/7

• Example 2. Monotone decreasing densities on (0,∞).X1, . . . ,Xn are i.i.d. p0 ∈ P where
P = all nonincreasing densities on (0,∞).
• Then the likelihood is Ln(p) =∏n
i=1 p(Xi);• Ln(p) is maximized by the Grenander estimator:
p̂n(x) = left derivative at x of the Least Concave Majorant
Cn of Fn
where Fn(x) = n−1∑n
i=1 1{Xi ≤ x}
Maximum likelihood: – p. 10/7
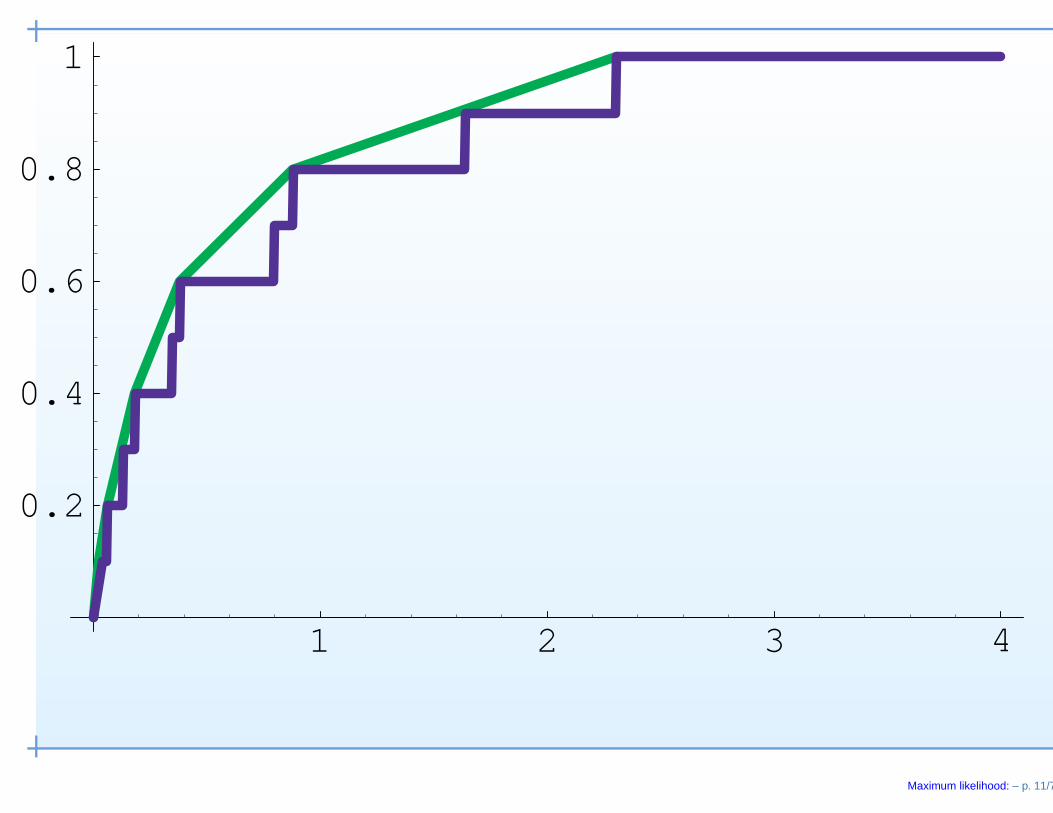
1 2 3 4
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 11/7
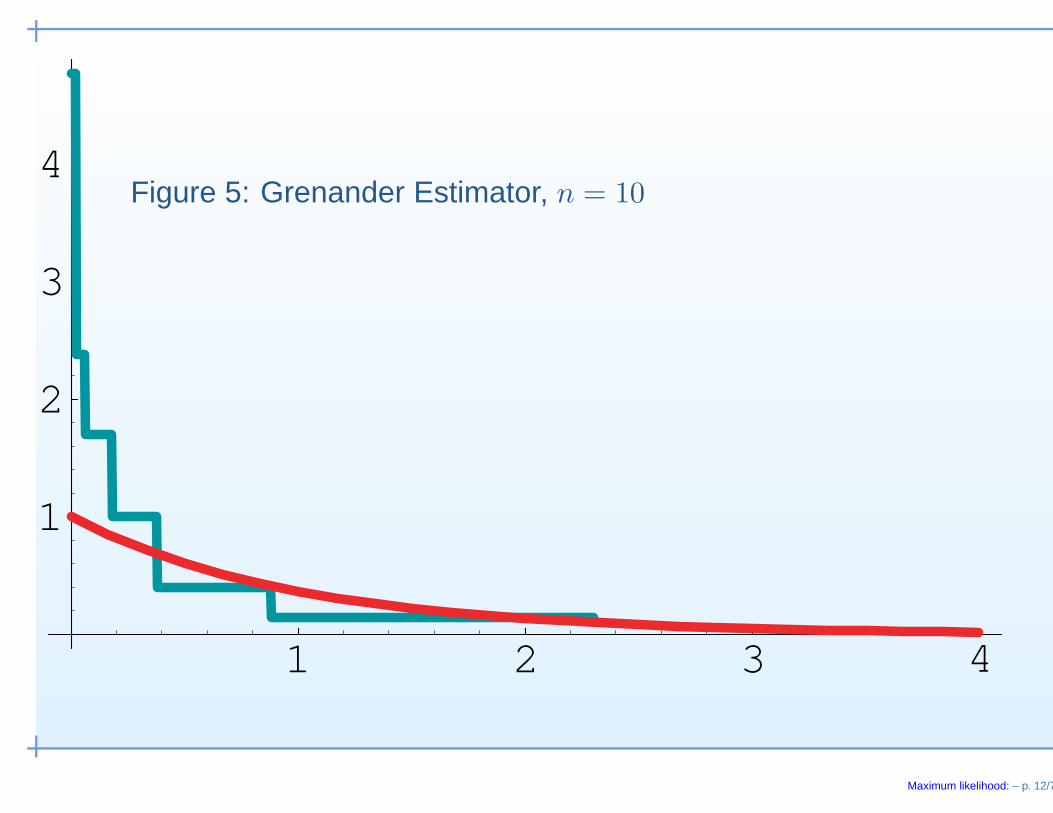
1 2 3 4
1
2
3
4Figure 5: Grenander Estimator, n = 10
Maximum likelihood: – p. 12/7

0.5 1 1.5 2 2.5 3 3.5 4
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 13/7

1 2 3 4
0.5
1
1.5
2
Figure 5: Grenander Estimator, n = 100
Maximum likelihood: – p. 14/7

• Setting 2: non-dominated families
Maximum likelihood: – p. 15/7

• Setting 2: non-dominated families
• Suppose that X1, . . . ,Xn are i.i.d. P0 ∈ P where P is somecollection of probability measures on a measurable space(X ,A).
Maximum likelihood: – p. 15/7

• Setting 2: non-dominated families
• Suppose that X1, . . . ,Xn are i.i.d. P0 ∈ P where P is somecollection of probability measures on a measurable space(X ,A).
• If P{x} denotes the measure under P of the one-point set{x}, the likelihood of X1, . . . ,Xn is defined to be
Ln(P ) =n∏
i=1
P{Xi} .
Maximum likelihood: – p. 15/7

• Setting 2: non-dominated families
• Suppose that X1, . . . ,Xn are i.i.d. P0 ∈ P where P is somecollection of probability measures on a measurable space(X ,A).
• If P{x} denotes the measure under P of the one-point set{x}, the likelihood of X1, . . . ,Xn is defined to be
Ln(P ) =n∏
i=1
P{Xi} .
• Then a Maximum Likelihood Estimator (or MLE) of P0 canbe defined as a measure P̂n ∈ P that maximizes Ln(P );thus
Ln(P̂ ) = supP∈P
Ln(P )
Maximum likelihood: – p. 15/7

• Example 3. (Empirical measure)
Maximum likelihood: – p. 16/7

• Example 3. (Empirical measure)• If P =all probability measures on (X ,A), then
P̂n =1n
n∑i=1
δXi≡ Pn
where δx(A) = 1A(x).
Maximum likelihood: – p. 16/7

• Example 3. (Empirical measure)• If P =all probability measures on (X ,A), then
P̂n =1n
n∑i=1
δXi≡ Pn
where δx(A) = 1A(x).• Thus
P̂n(A) =1n
n∑i=1
δXi(A)
=1n
n∑i=1
1A(Xi) =#{1 ≤ i ≤ n : Xi ∈ A}
n
Maximum likelihood: – p. 16/7

Consistency of the MLE:
• Wald (1949)
Maximum likelihood: – p. 17/7

Consistency of the MLE:
• Wald (1949)• Kiefer and Wolfowitz (1956)
Maximum likelihood: – p. 17/7

Consistency of the MLE:
• Wald (1949)• Kiefer and Wolfowitz (1956)• Huber (1967)
Maximum likelihood: – p. 17/7

Consistency of the MLE:
• Wald (1949)• Kiefer and Wolfowitz (1956)• Huber (1967)• Perlman (1972)
Maximum likelihood: – p. 17/7

Consistency of the MLE:
• Wald (1949)• Kiefer and Wolfowitz (1956)• Huber (1967)• Perlman (1972)• Wang (1985)
Maximum likelihood: – p. 17/7

Consistency of the MLE:
• Wald (1949)• Kiefer and Wolfowitz (1956)• Huber (1967)• Perlman (1972)• Wang (1985)• van de Geer (1993)
Maximum likelihood: – p. 17/7

Counterexamples:
• Neyman and Scott (1948)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)• LeCam (1975), (1990)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)• LeCam (1975), (1990)• Barlow, Bartholomew, Bremner, and Brunk (4B’s) (1972)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)• LeCam (1975), (1990)• Barlow, Bartholomew, Bremner, and Brunk (4B’s) (1972)• Boyles, Marshall, and Proschan (1985)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)• LeCam (1975), (1990)• Barlow, Bartholomew, Bremner, and Brunk (4B’s) (1972)• Boyles, Marshall, and Proschan (1985)• bivariate right censoring
Tsai, van der Laan, Pruitt
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)• LeCam (1975), (1990)• Barlow, Bartholomew, Bremner, and Brunk (4B’s) (1972)• Boyles, Marshall, and Proschan (1985)• bivariate right censoring
Tsai, van der Laan, Pruitt• left truncation and interval censoring
Chappell and Pan (1999)
Maximum likelihood: – p. 18/7

Counterexamples:
• Neyman and Scott (1948)• Bahadur (1958)• Ferguson (1982)• LeCam (1975), (1990)• Barlow, Bartholomew, Bremner, and Brunk (4B’s) (1972)• Boyles, Marshall, and Proschan (1985)• bivariate right censoring
Tsai, van der Laan, Pruitt• left truncation and interval censoring
Chappell and Pan (1999)• Maathuis and Wellner (2005)
Maximum likelihood: – p. 18/7

2. Counterexamples: MLE’s are not always consistent
• Counterexample 1. (Ferguson, 1982).Suppose that X1, . . . ,Xn are i.i.d. with density fθ0 where
fθ(x) = (1 − θ)1
δ(θ)f0
(x − θ
δ(θ)
)+ θf1(x)
for θ ∈ [0, 1] where
f1(x) =121[−1,1](x) Uniform[−1, 1],
f0(x) = (1 − |x|)1[−1,1](x) Triangular[−1, 1]
and δ(θ) satisfies:• δ(0) = 1• 0 < δ(θ) ≤ 1 − θ• δ(θ) → 0 as θ → 1.
Maximum likelihood: – p. 19/7
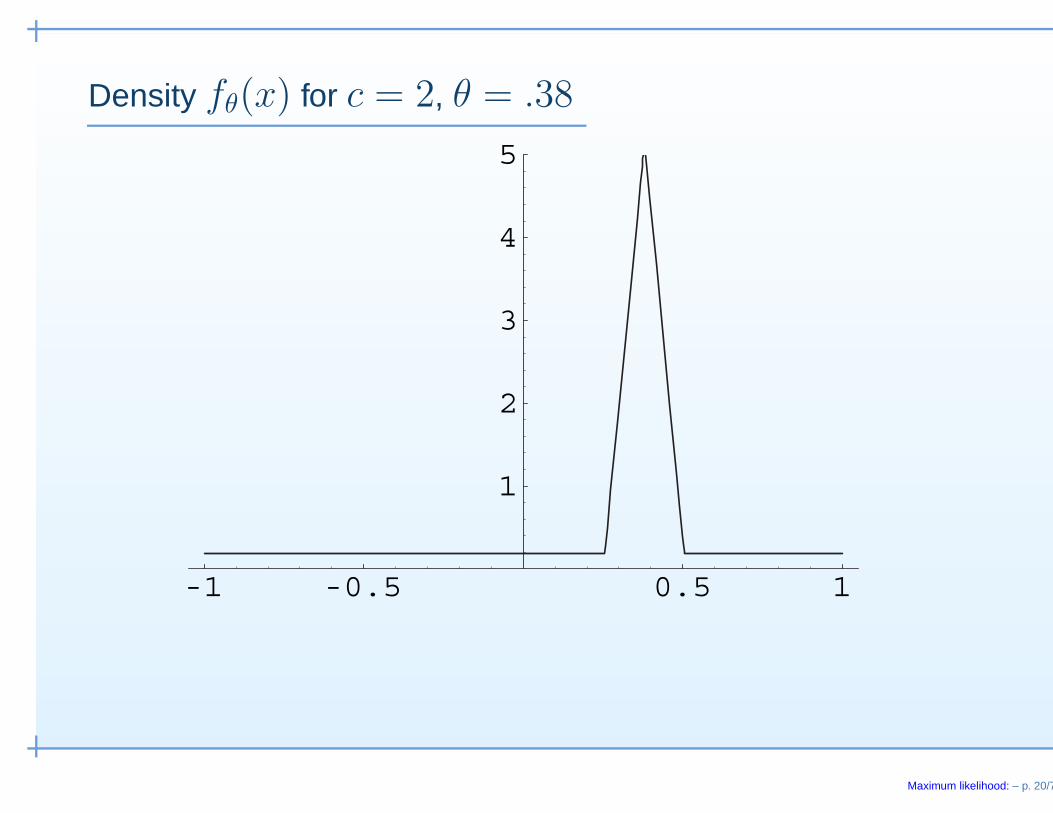
Density fθ(x) for c = 2, θ = .38
-1 -0.5 0.5 1
1
2
3
4
5
Maximum likelihood: – p. 20/7

Fθ(x) for c = 2, θ = .38
-1 -0.5 0.5 1
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 21/7

• Ferguson (1982) shows that θ̂n →a.s. 1no matter what θ0 is true if δ(θ) → 0 “fast enough”.
Maximum likelihood: – p. 22/7

• Ferguson (1982) shows that θ̂n →a.s. 1no matter what θ0 is true if δ(θ) → 0 “fast enough”.
• In fact, the assertion is true if
δ(θ) = (1 − θ) exp(−(1 − θ)−c + 1)
with c > 2. (Ferguson shows that c = 4 works.)
Maximum likelihood: – p. 22/7

• Ferguson (1982) shows that θ̂n →a.s. 1no matter what θ0 is true if δ(θ) → 0 “fast enough”.
• In fact, the assertion is true if
δ(θ) = (1 − θ) exp(−(1 − θ)−c + 1)
with c > 2. (Ferguson shows that c = 4 works.)• If c = 2, Ferguson’s argument shows that
sup0≤θ≤1
n−1 log Ln(θ)
≥ n − 1n
log(Mn/2) +1n
log1 − Mn
δ(Mn)→d D
Maximum likelihood: – p. 22/7

• where
P (D ≤ y) = exp(− 1
2(y − log 2)
), y ≥ log(2) .
That is, with E an Exponential(1) random variable
Dd= log 2 +
12E
.
Maximum likelihood: – p. 23/7

0.2 0.4 0.6 0.8 1
-1.25
-1
-0.75
-0.5
-0.25
0.25
Maximum likelihood: – p. 24/7

• Counterexample 2. (4 B’s, 1972). A distribution F on [0, b) isstar-shaped if F (x)/x is non-decreasing on [0, b). Thus if Fhas a density f which is increasing on [0, b) then F isstar-shaped.
Maximum likelihood: – p. 25/7

• Counterexample 2. (4 B’s, 1972). A distribution F on [0, b) isstar-shaped if F (x)/x is non-decreasing on [0, b). Thus if Fhas a density f which is increasing on [0, b) then F isstar-shaped.
• Let Fstar be the class of all star-shaped distributions on[0, b) for some b.
Maximum likelihood: – p. 25/7

• Counterexample 2. (4 B’s, 1972). A distribution F on [0, b) isstar-shaped if F (x)/x is non-decreasing on [0, b). Thus if Fhas a density f which is increasing on [0, b) then F isstar-shaped.
• Let Fstar be the class of all star-shaped distributions on[0, b) for some b.
• Suppose that X1, . . . ,Xn are i.i.d. F ∈ Fstar.
Maximum likelihood: – p. 25/7

• Counterexample 2. (4 B’s, 1972). A distribution F on [0, b) isstar-shaped if F (x)/x is non-decreasing on [0, b). Thus if Fhas a density f which is increasing on [0, b) then F isstar-shaped.
• Let Fstar be the class of all star-shaped distributions on[0, b) for some b.
• Suppose that X1, . . . ,Xn are i.i.d. F ∈ Fstar.• Barlow, Bartholomew, Bremner, and Brunk (1972) show that
the MLE of a star-shaped distribution function F is
F̂n(x) =
0, x < X(1)ix
nX(n), X(i) ≤ x < X(i+1), i = 1, . . . , n − 1,
1, x ≥ X(n) .
Maximum likelihood: – p. 25/7

• Moreover, BBBB (1972) show that if F (x) = x for 0 ≤ x ≤ 1,then
F̂n(x) →a.s. x2 �= x
for 0 ≤ x ≤ 1.
Maximum likelihood: – p. 26/7

MLE n = 5 and true d.f.
0.2 0.4 0.6 0.8 1
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 27/7

MLE n = 100 and true d.f.
0.2 0.4 0.6 0.8 1
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 28/7

MLE n = 100 and limit
0.2 0.4 0.6 0.8 1
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 29/7

• Note 1. Since X(i)d= Sj/Sn+1 where Si =
∑ij=1 Ej with Ej
i.i.d. Exponential(1) rv’s, the total mass at order statisticsequals
1nX(n)
n∑i=1
X(i)d=
n∑i=1
Si
nSn=
n
Sn
1n
n∑j=1
(1 − j − 1
n
)Ej
→p 1 ·∫ 1
0(1 − t)dt = 1/2 .
Maximum likelihood: – p. 30/7

• Note 1. Since X(i)d= Sj/Sn+1 where Si =
∑ij=1 Ej with Ej
i.i.d. Exponential(1) rv’s, the total mass at order statisticsequals
1nX(n)
n∑i=1
X(i)d=
n∑i=1
Si
nSn=
n
Sn
1n
n∑j=1
(1 − j − 1
n
)Ej
→p 1 ·∫ 1
0(1 − t)dt = 1/2 .
• Note 2. BBBB (1972) present consistent estimators of Fstar-shaped via isotonization due to Barlow and Scheurer(1971) and van Zwet.
Maximum likelihood: – p. 30/7

• Counterexample 3. (Boyles, Marshall, Proschan (1985). Adistribution F on [0,∞) is Increasing Failure Rate Average if
1x{− log(1 − F (x))} ≡ 1
xΛ(x)
is non-decreasing; that is, if Λ is star-shaped.
Maximum likelihood: – p. 31/7

• Counterexample 3. (Boyles, Marshall, Proschan (1985). Adistribution F on [0,∞) is Increasing Failure Rate Average if
1x{− log(1 − F (x))} ≡ 1
xΛ(x)
is non-decreasing; that is, if Λ is star-shaped.• Let FIFRA be the class of all IFRA- distributions on [0,∞).
Maximum likelihood: – p. 31/7

• Suppose that X1, . . . ,Xn are i.i.d. F ∈ FIFRA. Boyles,Marshall, and Proschan (1985) showed that the MLE F̂n ofa IFRA-distribution function F is given by
− log(1 − F̂n(x)) =
λ̂j , X(j) ≤ x < X(j+1),
j = 0, . . . , n − 1∞, x > X(n)
where
λ̂j =j∑
i=1
X−1(i) log
( ∑nk=i X(k)∑n
k=i+1 X(k)
).
Maximum likelihood: – p. 32/7

• Moreover, BMP (1985) show that if F is exponential(1), then
1 − F̂n(x) →a.s. (1 + x)−x �= exp(−x), so1x
Λ̂n(x) →a.s. log(1 + x) �= 1 .
Maximum likelihood: – p. 33/7

MLE n = 100 and true d.f. 1 − exp(−x)
1 2 3 4
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 34/7

MLE n = 100 and limit d.f.(1 + x)−x
1 2 3 4
0.2
0.4
0.6
0.8
1
Maximum likelihood: – p. 35/7

More counterexamples:
• bivariate right censoring: Tsai, van der Laan, Pruitt
Maximum likelihood: – p. 36/7

More counterexamples:
• bivariate right censoring: Tsai, van der Laan, Pruitt• left truncation and interval censoring:
Chappell and Pan (1999)
Maximum likelihood: – p. 36/7

More counterexamples:
• bivariate right censoring: Tsai, van der Laan, Pruitt• left truncation and interval censoring:
Chappell and Pan (1999)• bivariate interval censoring with a continuous mark:
Hudgens, Maathuis, and Gilbert (2005)Maathuis and Wellner (2005)
Maximum likelihood: – p. 36/7

3. Beyond consistency: rates and distributions
• Le Cam (1973); Birgé (1983):optimal rate of convergence rn = ropt
n determined by
nr−2n = log N[ ](1/rn,P) (1)
• If
log N[ ](ε,P) K
ε1/γ(2)
(1) leads to the optimal rate of convergence
roptn = nγ/(2γ+1) .
Maximum likelihood: – p. 37/7

• On the other hand, bounds (from Birgé and Massart(1993)), yield achieved rates of convergence for maximumlikelihood estimators (and other minimum contrastestimators) rn = rach
n determined by
√nr−2
n =∫ r−1
n
cr−2n
√log N[ ](ε,P)dε
• If (2) holds, this leads to the rate{nγ/(2γ+1) if γ > 1/2nγ/2 if γ < 1/2 .
• Thus there is the possibility that maximum likelihood is not(rate-)optimal when γ < 1/2.
Maximum likelihood: – p. 38/7

• Typically1γ
=d
α
where d is the dimension of the underlying sample spaceand α is a measure of the “smoothness” of the functions inP.
Maximum likelihood: – p. 39/7

• Typically1γ
=d
α
where d is the dimension of the underlying sample spaceand α is a measure of the “smoothness” of the functions inP.
• Hence
α <d
2
leads to γ < 1/2.
Maximum likelihood: – p. 39/7

• Typically1γ
=d
α
where d is the dimension of the underlying sample spaceand α is a measure of the “smoothness” of the functions inP.
• Hence
α <d
2
leads to γ < 1/2.
• But there are many examples/problem with γ > 1/2!
Maximum likelihood: – p. 39/7
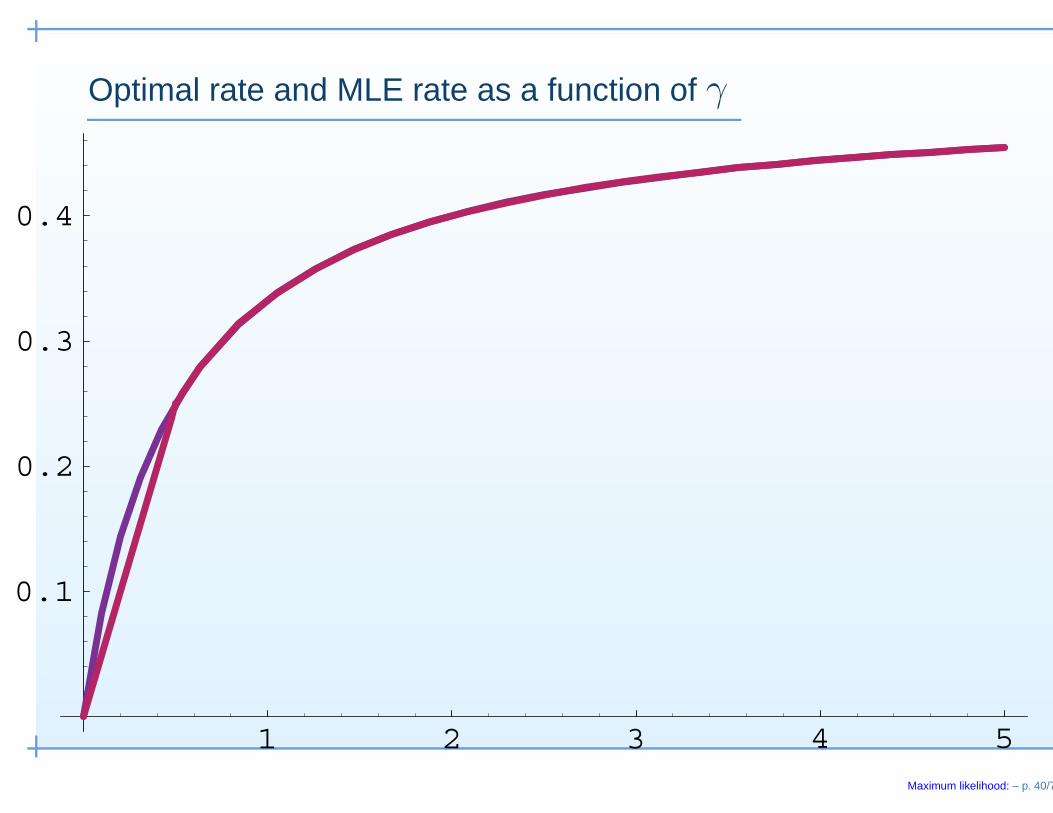
Optimal rate and MLE rate as a function of γ
1 2 3 4 5
0.1
0.2
0.3
0.4
Maximum likelihood: – p. 40/7
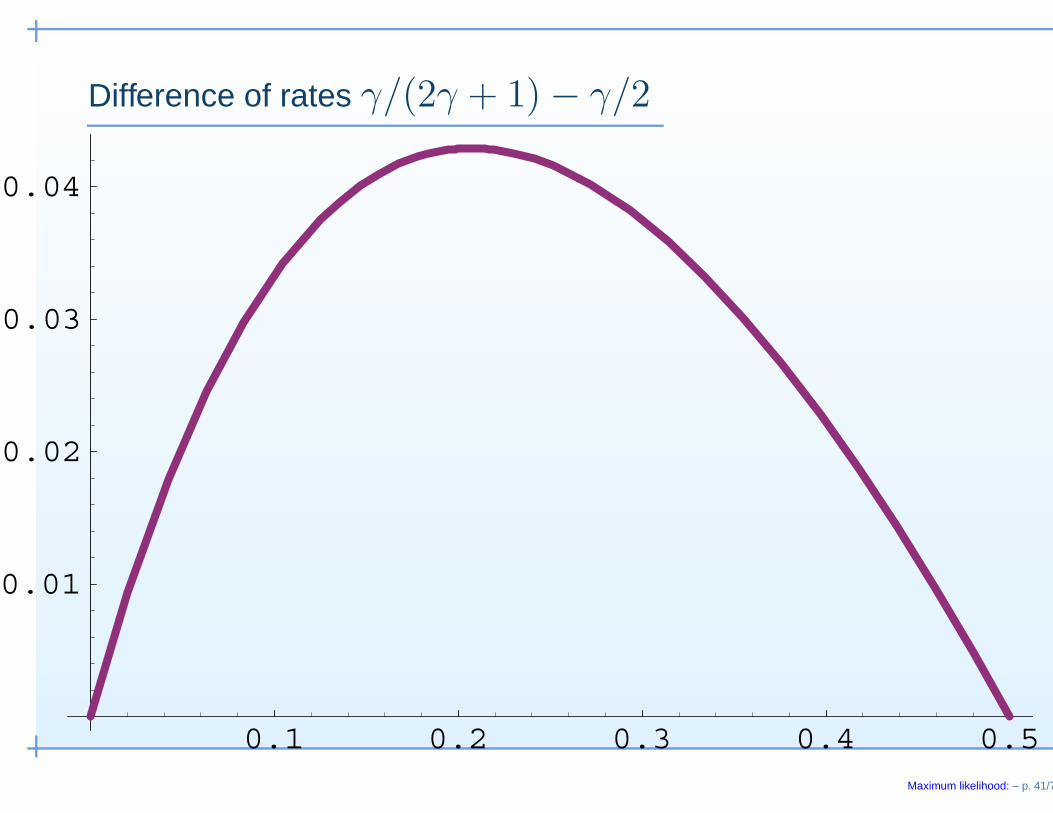
Difference of rates γ/(2γ + 1) − γ/2
0.1 0.2 0.3 0.4 0.5
0.01
0.02
0.03
0.04
Maximum likelihood: – p. 41/7

4. Positive Examples (some still in progress!)
• Interval censoring (Groeneboom)case 1, current status datacase 2 (Groeneboom)
Maximum likelihood: – p. 42/7

4. Positive Examples (some still in progress!)
• Interval censoring (Groeneboom)case 1, current status datacase 2 (Groeneboom)
• panel count data(Wellner and Zhang, 2000)
Maximum likelihood: – p. 42/7

4. Positive Examples (some still in progress!)
• Interval censoring (Groeneboom)case 1, current status datacase 2 (Groeneboom)
• panel count data(Wellner and Zhang, 2000)
• k−monotone densities(Balabdaoui and Wellner, 2004)
Maximum likelihood: – p. 42/7

4. Positive Examples (some still in progress!)
• Interval censoring (Groeneboom)case 1, current status datacase 2 (Groeneboom)
• panel count data(Wellner and Zhang, 2000)
• k−monotone densities(Balabdaoui and Wellner, 2004)
• competing risks current status data(Jewell and van der Laan; Maathuis)
Maximum likelihood: – p. 42/7

• Example 1. (interval censoring, case 1)
Maximum likelihood: – p. 43/7

• Example 1. (interval censoring, case 1)◦ X ∼ F , Y ∼ G independent
Observe (1{X ≤ Y }, Y ) ≡ (∆, Y ).Goal: estimate F . MLE F̂n exists
Maximum likelihood: – p. 43/7

• Example 1. (interval censoring, case 1)◦ X ∼ F , Y ∼ G independent
Observe (1{X ≤ Y }, Y ) ≡ (∆, Y ).Goal: estimate F . MLE F̂n exists
◦ Global rate: d = 1, α = 1, γ = α/d = 1.γ/(2γ + 1) = 1/3, so rn = n1/3:
n1/3h(pF̂n, p0) = Op(1)
and this yields
n1/3
∫|F̂n − F0|dG = Op(1) .
Maximum likelihood: – p. 43/7

• Interval censoring case 1, continued:
Maximum likelihood: – p. 44/7

• Interval censoring case 1, continued:◦ Local rate: (Groeneboom, 1987)
n1/3(F̂n(t0) − F (t0))
→d
{F (t0)(1 − F (t0))f0(t0)
2g(t0)
}1/3
2Z
where Z = argmin{W (t) + t2}
Maximum likelihood: – p. 44/7

• Example 2. (interval censoring, case 2)
Maximum likelihood: – p. 45/7

• Example 2. (interval censoring, case 2)◦ X ∼ F , (U, V ) ∼ H, U ≤ V independent of X
Observe i.i.d. copies of (∆, U, V ) where
∆ = (∆1,∆2,∆3)= (1{X ≤ U}, 1{U < X ≤ V }, 1{V < X})
Maximum likelihood: – p. 45/7

• Example 2. (interval censoring, case 2)◦ X ∼ F , (U, V ) ∼ H, U ≤ V independent of X
Observe i.i.d. copies of (∆, U, V ) where
∆ = (∆1,∆2,∆3)= (1{X ≤ U}, 1{U < X ≤ V }, 1{V < X})
◦ Goal: estimate F . MLE F̂n exists.
Maximum likelihood: – p. 45/7

• (interval censoring, case 2, continued)
Maximum likelihood: – p. 46/7

• (interval censoring, case 2, continued)◦ Global rate (separated case): If P (V − U ≥ ε) = 1,
d = 1, α = 1, γ = α/d = 1γ/(2γ + 1) = 1/3, so rn = n1/3
n1/3h(pF̂n, p0) = Op(1)
and this yields
n1/3
∫|F̂n − F0|dµ = Op(1)
where
µ(A) = P (U ∈ A) + P (V ∈ A), A ∈ B1
Maximum likelihood: – p. 46/7

• (interval censoring, case 2, continued)
Maximum likelihood: – p. 47/7

• (interval censoring, case 2, continued)◦ Global rate (nonseparated case): (van de Geer, 1993).
n1/3
(log n)1/6h(pF̂n
, p0) = Op(1) .
Although this looks “worse” in terms of the rate, it isactually better because the Hellinger metric is muchstronger in this case.
Maximum likelihood: – p. 47/7

• (interval censoring, case 2, continued)◦ Global rate (nonseparated case): (van de Geer, 1993).
n1/3
(log n)1/6h(pF̂n
, p0) = Op(1) .
Although this looks “worse” in terms of the rate, it isactually better because the Hellinger metric is muchstronger in this case.
Maximum likelihood: – p. 47/7

(interval censoring, case 2, continued)
• Local rate (separated case): (Groeneboom, 1996)
n1/3(F̂n(t0) − F0(t0)) →d
{f0(t0)2a(t0)
}1/3
2Z
where Z = argmin{W (t) + t2} and
a(t0) =h1(t0)F0(t0)
+ k1(t0) + k2(t0) +h2(t0)
1 − F0(t0)
k1(u) =∫ M
u
h(u, v)F0(v) − F0(u)
dv
k2(v) =∫ v
0
h(u, v)F0(v) − F0(u)
du
Maximum likelihood: – p. 48/7

(interval censoring, case 2, continued)
• Local rate (non-separated case): (conjectured, G&W, 1992)
(n log n)1/3(F̂n(t0) − F0(t0)) →d
{34
f0(t0)2
h(t0, t0)
}1/3
2Z
where Z = argmin{W (t) + t2}
Maximum likelihood: – p. 49/7

(interval censoring, case 2, continued)
• Local rate (non-separated case): (conjectured, G&W, 1992)
(n log n)1/3(F̂n(t0) − F0(t0)) →d
{34
f0(t0)2
h(t0, t0)
}1/3
2Z
where Z = argmin{W (t) + t2}• Monte-Carlo evidence in support:
Groeneboom and Ketelaars (2005)
Maximum likelihood: – p. 49/7
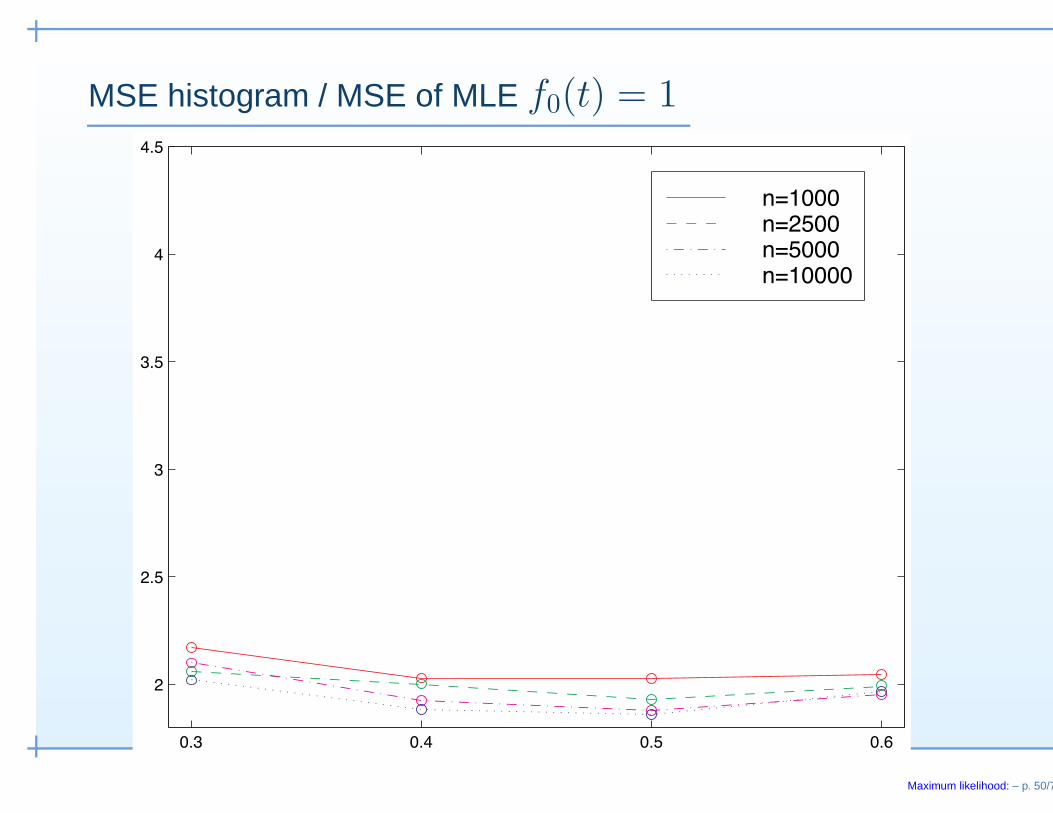
MSE histogram / MSE of MLE f0(t) = 1
0.3 0.4 0.5 0.6
2
2.5
3
3.5
4
4.5
n=1000n=2500n=5000n=10000
Maximum likelihood: – p. 50/7

MSE histogram / MSE of MLE f0(t) = 4(1 − t)3
0.3 0.4 0.5 0.6
2
2.5
3
3.5
4
4.5
n=1000n=2500n=5000n=10000
Maximum likelihood: – p. 51/7

MSE histogram / MSE of MLE f0(t) = 1
0.3 0.4 0.5 0.62
3
4
5
6
7
8
9
n=1000n=2500n=5000n=10000
Maximum likelihood: – p. 52/7
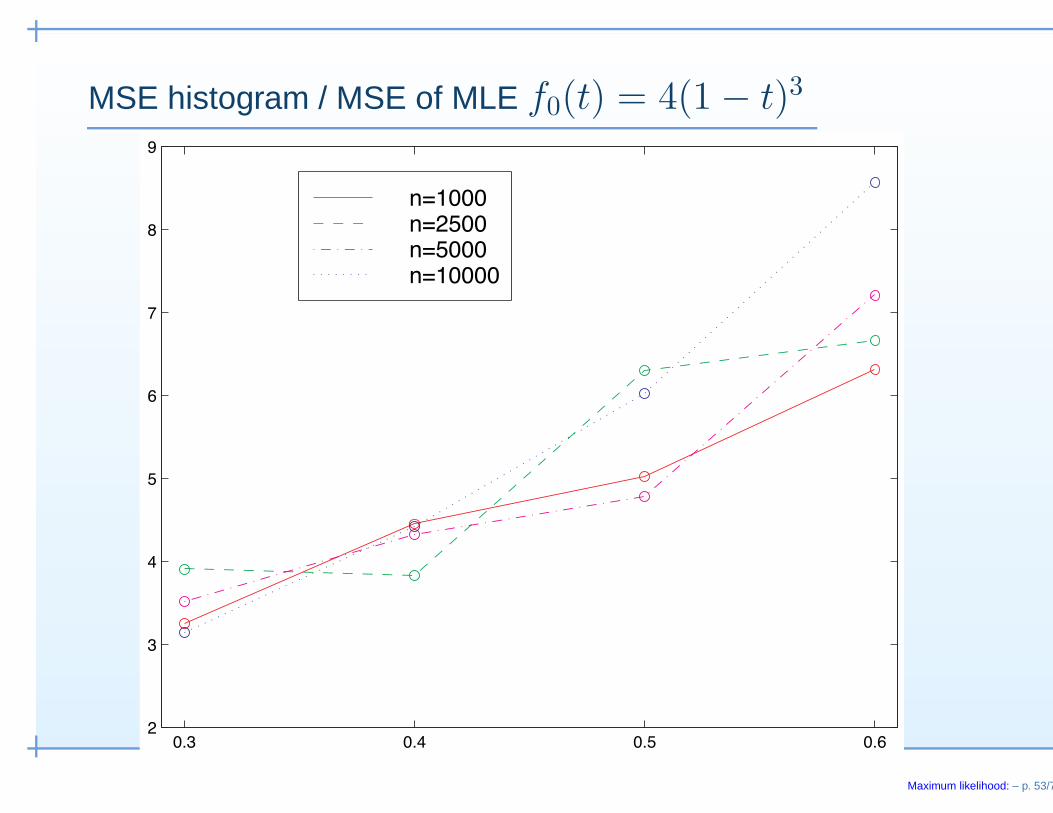
MSE histogram / MSE of MLE f0(t) = 4(1 − t)3
0.3 0.4 0.5 0.62
3
4
5
6
7
8
9
n=1000n=2500n=5000n=10000
Maximum likelihood: – p. 53/7

• Example 3. (k-monotone densities)
Maximum likelihood: – p. 54/7

• Example 3. (k-monotone densities)◦ A density p on (0,∞) is k−monontone (p ∈ Dk) if it is
non-negative and nonincreasing when k = 1; and if(−1)jp(j)(x) ≥ 0 for j = 0, . . . , k − 2 and (−1)k−2p(k−2) isconvex for k ≥ 2.
Maximum likelihood: – p. 54/7

• Example 3. (k-monotone densities)◦ A density p on (0,∞) is k−monontone (p ∈ Dk) if it is
non-negative and nonincreasing when k = 1; and if(−1)jp(j)(x) ≥ 0 for j = 0, . . . , k − 2 and (−1)k−2p(k−2) isconvex for k ≥ 2.
◦ Mixture representation: p ∈ Dk iff
p(x) =∫ ∞
0
k
yk(y − x)k−1
+ dF (y)
for some distribution function F on (0,∞).� k = 1: monotone decreasing densities on R+
� k = 2: convex decreasing densities on R+
� k ≥ 3: . . .� k = ∞: completely monotone densities
= scale mixtures of exponentialMaximum likelihood: – p. 54/7

(k-monotone densities, continued)
• The MLE p̂n of p0 ∈ Dk exists and is characterized by
∫ ∞
0
k
yk
(y − x)k+
p̂n(x)dPn(x)
{≤ 1, for all y ≥ 0= 1, if (−1)kp̂
(k−1)n (y−) > p̂
(k−1)n (y+)
Maximum likelihood: – p. 55/7

(k-monotone densities, continued)
• The MLE p̂n of p0 ∈ Dk exists and is characterized by
∫ ∞
0
k
yk
(y − x)k+
p̂n(x)dPn(x)
{≤ 1, for all y ≥ 0= 1, if (−1)kp̂
(k−1)n (y−) > p̂
(k−1)n (y+)
• k = 1 Grenander estimator: rn = n1/3
Maximum likelihood: – p. 55/7

(k-monotone densities, continued)
• The MLE p̂n of p0 ∈ Dk exists and is characterized by
∫ ∞
0
k
yk
(y − x)k+
p̂n(x)dPn(x)
{≤ 1, for all y ≥ 0= 1, if (−1)kp̂
(k−1)n (y−) > p̂
(k−1)n (y+)
• k = 1 Grenander estimator: rn = n1/3
◦ Global rates and finite n minimax bounds: Birgé (1986),(1987), (1989)
Maximum likelihood: – p. 55/7

(k-monotone densities, continued)
• The MLE p̂n of p0 ∈ Dk exists and is characterized by
∫ ∞
0
k
yk
(y − x)k+
p̂n(x)dPn(x)
{≤ 1, for all y ≥ 0= 1, if (−1)kp̂
(k−1)n (y−) > p̂
(k−1)n (y+)
• k = 1 Grenander estimator: rn = n1/3
◦ Global rates and finite n minimax bounds: Birgé (1986),(1987), (1989)
◦ Local rates: Prakasa Rao (1969), Groeneboom (1985),(1989)
Kim and Pollard (1990)
n1/3(p̂n(t0) − p0(t0)) →d
{p0(t0)|p′0(t0)|
2
}1/3
2Z
Maximum likelihood: – p. 55/7

(k-monotone densities, continued)
• k = 2; convex decreasing densityd = 1, α = 2, γ = 2, γ/(2γ + 1) = 2/5, so rn = n2/5
(forward problem)� Global rates: nothing yet� Local rates and distributions:
Groeneboom, Jongbloed, Wellner (2001)
Maximum likelihood: – p. 56/7

(k-monotone densities, continued)
• k = 2; convex decreasing densityd = 1, α = 2, γ = 2, γ/(2γ + 1) = 2/5, so rn = n2/5
(forward problem)� Global rates: nothing yet� Local rates and distributions:
Groeneboom, Jongbloed, Wellner (2001)• k ≥ 3; k - monotone density
d = 1, α = k, γ = k, γ/(2γ + 1) = k/(2k + 1), sorn = nk/(2k+1) (forward problem)?� Global rates: nothing yet� Local rates: should be rn = nk/(2k+1)
progress: Balabdaoui and Wellner (2004)local rate is true if a certain conjectureabout Hermite interpolation holds
Maximum likelihood: – p. 56/7

Direct and Inverse estimators k = 3, n = 100
0 1 2 3 4 5
0.0
0.4
0.8
1.2
(1a) - LSE, k=3, n=100 (direct problem)
0 1 2 3 4 5
0.0
0.4
0.8
1.2
(1b) - MLE, k=3, n=100 (direct problem)
0 5 10 15
0.0
0.4
0.8
(2a) - LSE, k=3, n=100 (inverse problem)
0 5 10 15
0.0
0.4
0.8
(2b) - MLE, k=3, n=100 (inverse problem)
Maximum likelihood: – p. 57/7
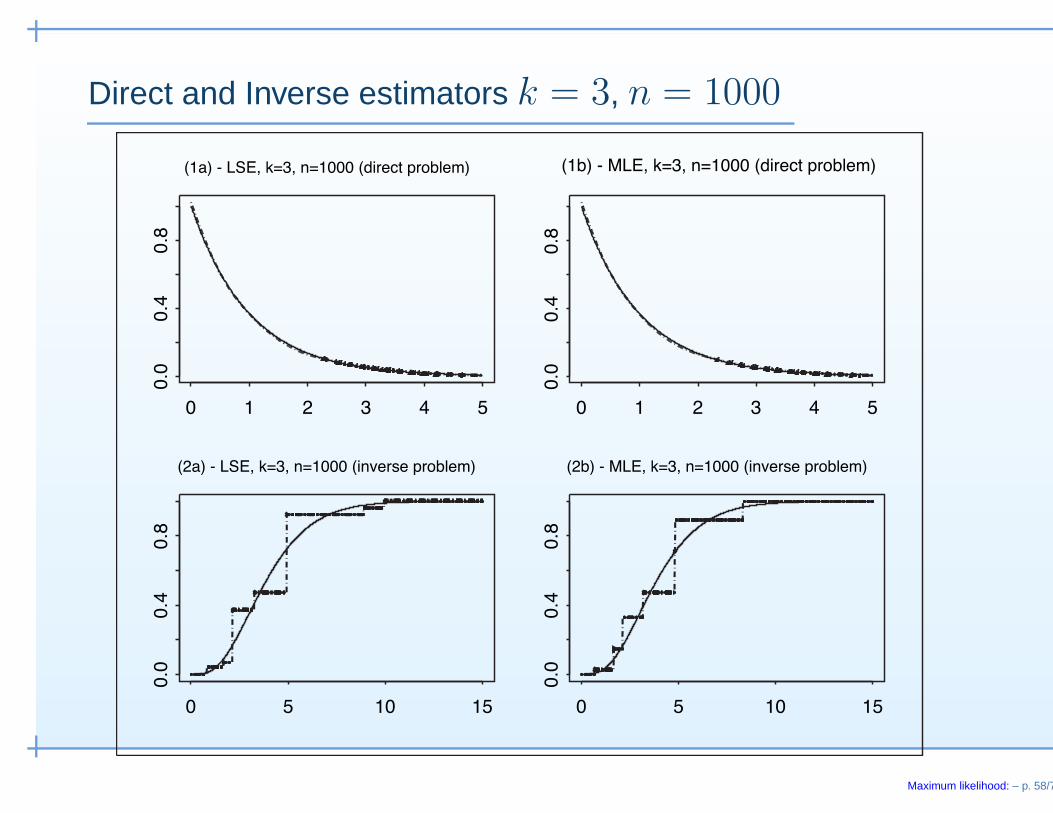
Direct and Inverse estimators k = 3, n = 1000
0 1 2 3 4 5
0.0
0.4
0.8
(1a) - LSE, k=3, n=1000 (direct problem)
0 1 2 3 4 5
0.0
0.4
0.8
(1b) - MLE, k=3, n=1000 (direct problem)
0 5 10 15
0.0
0.4
0.8
(2a) - LSE, k=3, n=1000 (inverse problem)
0 5 10 15
0.0
0.4
0.8
(2b) - MLE, k=3, n=1000 (inverse problem)
Maximum likelihood: – p. 58/7
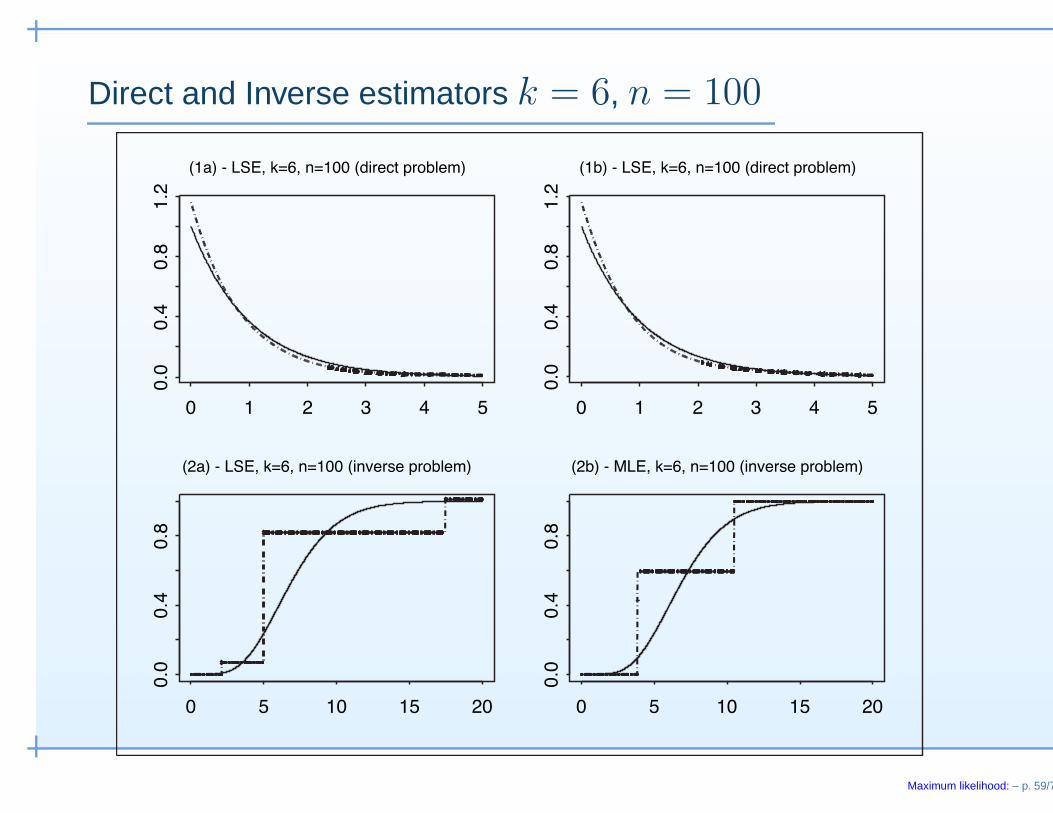
Direct and Inverse estimators k = 6, n = 100
0 1 2 3 4 5
0.0
0.4
0.8
1.2
(1a) - LSE, k=6, n=100 (direct problem)
0 1 2 3 4 5
0.0
0.4
0.8
1.2
(1b) - LSE, k=6, n=100 (direct problem)
0 5 10 15 20
0.0
0.4
0.8
(2a) - LSE, k=6, n=100 (inverse problem)
0 5 10 15 20
0.0
0.4
0.8
(2b) - MLE, k=6, n=100 (inverse problem)
Maximum likelihood: – p. 59/7

Direct and Inverse estimators k = 6, n = 1000
0 1 2 3 4 5
0.0
0.4
0.8
(1a) - LSE, k=6, n=1000 (direct problem)
0 1 2 3 4 5
0.0
0.4
0.8
(1b) - MLE, k=6, n=1000 (direct problem)
0 5 10 15 20
0.0
0.4
0.8
(2a) - LSE, k=6, n=1000 (inverse problem)
0 5 10 15 20
0.0
0.4
0.8
(2b) - MLE, k=6, n=1000 (inverse problem)
Maximum likelihood: – p. 60/7

• Example 4. (Competing risks with current status data)
Maximum likelihood: – p. 61/7

• Example 4. (Competing risks with current status data)◦ Variables of interest (X,Y );
X = failure time; Y = failure causeX ∈ R+, Y ∈ {1, . . . ,K}T = an observation time, independent of (X,Y )
Maximum likelihood: – p. 61/7

• Example 4. (Competing risks with current status data)◦ Variables of interest (X,Y );
X = failure time; Y = failure causeX ∈ R+, Y ∈ {1, . . . ,K}T = an observation time, independent of (X,Y )
◦ Observe: (∆, T ), ∆ = (∆1, . . . ,∆K ,∆K+1) where
∆j = 1{X ≤ T, Y = j}, j = 1, . . . ,K
∆K+1 = 1{X > T} .
Maximum likelihood: – p. 61/7

• Example 4. (Competing risks with current status data)◦ Variables of interest (X,Y );
X = failure time; Y = failure causeX ∈ R+, Y ∈ {1, . . . ,K}T = an observation time, independent of (X,Y )
◦ Observe: (∆, T ), ∆ = (∆1, . . . ,∆K ,∆K+1) where
∆j = 1{X ≤ T, Y = j}, j = 1, . . . ,K
∆K+1 = 1{X > T} .
◦ Goal: estimate Fj(t) = P (X ≤ t, Y = j) for j = 1, . . . ,K
Maximum likelihood: – p. 61/7

• Example 4. (Competing risks with current status data)◦ Variables of interest (X,Y );
X = failure time; Y = failure causeX ∈ R+, Y ∈ {1, . . . ,K}T = an observation time, independent of (X,Y )
◦ Observe: (∆, T ), ∆ = (∆1, . . . ,∆K ,∆K+1) where
∆j = 1{X ≤ T, Y = j}, j = 1, . . . ,K
∆K+1 = 1{X > T} .
◦ Goal: estimate Fj(t) = P (X ≤ t, Y = j) for j = 1, . . . ,K
◦ MLE F̂n = (F̂n,1, . . . , F̂n,K) exists!
Characterization of F̂n involves an interacting system ofslopes of convex minorants
Maximum likelihood: – p. 61/7

(competing risks with current status data, continued)
• Global rates. Easy with present methods.
n1/3K∑
k=1
∫|F̂n,k(t) − F0,k(t)|dG(t) = Op(1)
Maximum likelihood: – p. 62/7

(competing risks with current status data, continued)
• Global rates. Easy with present methods.
n1/3K∑
k=1
∫|F̂n,k(t) − F0,k(t)|dG(t) = Op(1)
• Local rates? Conjecture rn = n1/3. New methods needed.Tricky. Maathuis (2006)?
Maximum likelihood: – p. 62/7

(competing risks with current status data, continued)
• Global rates. Easy with present methods.
n1/3K∑
k=1
∫|F̂n,k(t) − F0,k(t)|dG(t) = Op(1)
• Local rates? Conjecture rn = n1/3. New methods needed.Tricky. Maathuis (2006)?
• Limit distribution theory: will involve slopes of an interactingsystem of greatest convex minorants defined in terms of avector of dependent two-sided Brownian motions
Maximum likelihood: – p. 62/7

n2/3× MSE of MLE and naive estimators of F1
0.0 0.5 1.0 1.5
0.00
0.05
0.10
0.15
0.20
0.25
n=25
t
MLENESNETNE
n23 M
SE
0.0 0.5 1.0 1.5
0.00
0.05
0.10
0.15
0.20
0.25
n=250
t
MLENESNETNE
n23 M
SE
0.0 0.5 1.0 1.5
0.00
0.05
0.10
0.15
0.20
0.25
n=2500
t
MLENESNETNE
n23 M
SE
0.0 0.5 1.0 1.5
0.00
0.05
0.10
0.15
0.20
0.25
n=25000
t
MLENESNETNE
n23 M
SE
Maximum likelihood: – p. 63/7

n2/3× MSE of MLE and naive estimators of F2
0.0 0.5 1.0 1.5
0.0
0.1
0.2
0.3
0.4
n=25
t
MLENESNETNE
n23 M
SE
0.0 0.5 1.0 1.5
0.0
0.1
0.2
0.3
0.4
n=250
t
MLENESNETNE
n23 M
SE
0.0 0.5 1.0 1.5
0.0
0.1
0.2
0.3
0.4
n=2500
t
MLENESNETNE
n23 M
SE
0.0 0.5 1.0 1.5
0.0
0.1
0.2
0.3
0.4
n=25000
t
MLENESNETNE
n23 M
SE
Maximum likelihood: – p. 64/7
• Example 5. (Monotone densities in Rd)
Maximum likelihood: – p. 65/7

• Example 5. (Monotone densities in Rd)◦ Entropy bounds? Natural conjectures:
α = 1, d, γ = 1/d, so γ/(2γ + 1) = 1/(d + 2)
Maximum likelihood: – p. 65/7

• Example 5. (Monotone densities in Rd)◦ Entropy bounds? Natural conjectures:
α = 1, d, γ = 1/d, so γ/(2γ + 1) = 1/(d + 2)◦ Biau and Devroye (2003) show via Assouad’s lemma
and direct calculations:
roptn = n1/(d+2)
Maximum likelihood: – p. 65/7

• Example 5. (Monotone densities in Rd)◦ Entropy bounds? Natural conjectures:
α = 1, d, γ = 1/d, so γ/(2γ + 1) = 1/(d + 2)◦ Biau and Devroye (2003) show via Assouad’s lemma
and direct calculations:
roptn = n1/(d+2)
◦ Rate achieved by the MLE:Natural conjecture:
rachn = n1/2d, d > 2
Maximum likelihood: – p. 65/7

• Example 5. (Monotone densities in Rd)◦ Entropy bounds? Natural conjectures:
α = 1, d, γ = 1/d, so γ/(2γ + 1) = 1/(d + 2)◦ Biau and Devroye (2003) show via Assouad’s lemma
and direct calculations:
roptn = n1/(d+2)
◦ Rate achieved by the MLE:Natural conjecture:
rachn = n1/2d, d > 2
◦ Biau and Devroye (2003) construct generalizations ofBirgé’s (1987) histogram estimators that achieve theoptimal rate for all d ≥ 2.
Maximum likelihood: – p. 65/7

5. Problems and Challenges
• More tools for local rates and distribution theory?
Maximum likelihood: – p. 66/7

5. Problems and Challenges
• More tools for local rates and distribution theory?• Under what additional hypotheses are MLE’s globally rate
optimal in the case γ > 1/2?
Maximum likelihood: – p. 66/7

5. Problems and Challenges
• More tools for local rates and distribution theory?• Under what additional hypotheses are MLE’s globally rate
optimal in the case γ > 1/2?• More counterexamples to clarify when MLE’s do not work?
Maximum likelihood: – p. 66/7

5. Problems and Challenges
• More tools for local rates and distribution theory?• Under what additional hypotheses are MLE’s globally rate
optimal in the case γ > 1/2?• More counterexamples to clarify when MLE’s do not work?• What is the limit distribution for interval censoring, case 2?
(Does the G&W (1992) conjecture hold?)
Maximum likelihood: – p. 66/7

5. Problems and Challenges
• More tools for local rates and distribution theory?• Under what additional hypotheses are MLE’s globally rate
optimal in the case γ > 1/2?• More counterexamples to clarify when MLE’s do not work?• What is the limit distribution for interval censoring, case 2?
(Does the G&W (1992) conjecture hold?)• When the MLE is not rate optimal, is it still preferable from
some other perspectives? For example, does the MLEprovide efficient estimators of smooth functionals (whilealternative rate -optimal estimators fail to have thisproperty)? Compare with Bickel and Ritov (2003).
Maximum likelihood: – p. 66/7

Problems and challenges, continued
• More rate and optimality theory for Maximum LikelihoodEstimators of mixing distributions in mixture models withsmooth kernels: e.g. completely monotone densities (scalemixtures of exponential), normal location mixtures(deconvolution problems)
Maximum likelihood: – p. 67/7

Problems and challenges, continued
• More rate and optimality theory for Maximum LikelihoodEstimators of mixing distributions in mixture models withsmooth kernels: e.g. completely monotone densities (scalemixtures of exponential), normal location mixtures(deconvolution problems)
• Stable and efficient algorithms for computing MLE’s inmodels where they exist (e.g. mixture models, missingdata).
Maximum likelihood: – p. 67/7

Problems and challenges, continued
• More rate and optimality theory for Maximum LikelihoodEstimators of mixing distributions in mixture models withsmooth kernels: e.g. completely monotone densities (scalemixtures of exponential), normal location mixtures(deconvolution problems)
• Stable and efficient algorithms for computing MLE’s inmodels where they exist (e.g. mixture models, missingdata).
• Results for monotone densities in Rd?
Maximum likelihood: – p. 67/7

Selected References
• Bahadur, R. R. (1958). Examples of inconsistency ofmaximum likelihood estimates. Sankhya, Ser. A 20, 207 - 210.
• Barlow, R. E., Bartholomew, D. J., Bremner, J. M., andBrunk, H. D. (1972). Statistical Inference under Order Restrictions.Wiley, New York.
• Barlow, R. E. and Scheurer, E. M (1971). Estimation fromaccelerated life tests. Technometrics 13, 145 - 159.
• Biau, G. and Devroye, L. (2003). On the risk of estimates forblock decreasing densities. J. Mult. Anal. 86, 143 - 165.
• Bickel, P. J. and Ritov, Y. (2003). Nonparametric estimatorswhich can be “plugged-in”. Ann. Statist. 31, 1033 - 1053.
• Birgé, L. (1987). On the risk of histograms for estimatingdecreasing densities. Ann. Statist. 15, 1013 - 1022.
Maximum likelihood: – p. 68/7

• Birgé, L. (1989). The Grenander estimator: anonasymptotic approach. Ann. Statist. 17, 1532-1549.
• Birgé, L. and Massart, P. (1993). Rates of convergence forminimum contrast estimators. Probab. Theory Relat. Fields 97,113 - 150.
• Boyles, R. A., Marshall, A. W., Proschan, F. (1985).Inconsistency of the maximum likelihood estimator of adistribution having increasing failure rate average. Ann.Statist. 13, 413-417.
• Ferguson, T. S. (1982). An inconsistent maximum likelihoodestimate. J. Amer. Statist. Assoc. 77, 831–834.
• Ghosh, M. (1995). Inconsistent maximum likelihoodestimators for the Rasch model. Statist. Probab. Lett. 23,165-170.
Maximum likelihood: – p. 69/7

• Hudgens, M., Maathuis, M., and Gilbert, P. (2005).Nonparametric estimation of the joint distribution of asurvival time subject to interval censoring and a continuousmark variable. Submitted to Biometrics.
• Le Cam, L. (1990). Maximum likelihood: an introduction.Internat. Statist. Rev. 58, 153 - 171.
• Maathuis, M. and Wellner, J. A. (2005). Inconsistency of theMLE for the joint distribution of interval censored survivaltimes and continuous marks. Submitted to Biometrika.
• Pan, W. and Chappell, R. (1999). A note on inconsistencyof NPMLE of the distribution function from left truncated andcase I interval censored data. Lifetime Data Anal. 5, 281-291.
Maximum likelihood: – p. 70/7
Related Documents











