(c) 2015 Independent SAP Technical User Group Annual Conference, 2015 - ISUG TECH 2015 - ISUG TECH 2015 Conference Conference Master Index Rebuilding Master Index Rebuilding Fernando Santos Fernando Santos

Master Index Rebuilding in ASE 15.7
Jul 26, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
- ISUG TECH 2015- ISUG TECH 2015ConferenceConference
Master Index Rebuilding Master Index Rebuilding Fernando Santos Fernando Santos

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
AgendaAgendaWelcome Speaker Introduction Parallelism Concept Types of Parallelism Parallelism Best Usage Partitions and Parallelism : CASE Real World &Q A

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Fernando Santos Fernando Santos
, , , GLOBAL COE at SAP ASE RepServer . IQ Product Specialist Working at
/ SAP Sybase since 1994

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Master Index RebuildingCustomer Scenario
Major Public Bank in Brazil got a problem in his model…
Overflow in a identity column who is the primary key of the bigger tables… ( 1.5 TB) in size
Needed to Rebuild the table and indexes, hole system stopped by 100 hours…
Basic parallelism used with 20 Consumers, but something was wrong
Real World with 50 consumers and producers.

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Parallelism Concept

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Types of Parallelism
(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
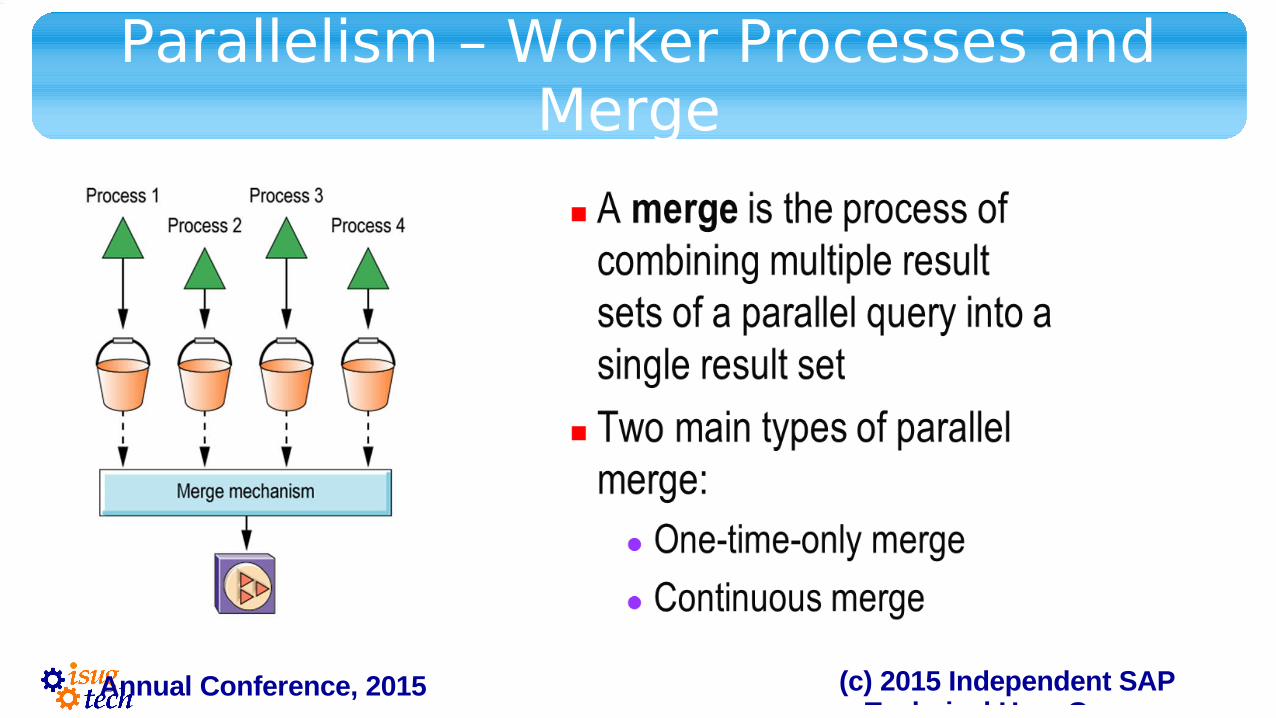
Parallelism – Worker Processes and Merge

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Parallelism – Requirements

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Partitions and Parallelism

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding using Partitions
Each partition must be scanned by a worker process ( producer)
For each producer must to have a consumer
Time to execute will be related to:-Cache-Disk performance (speed)-Worker process memory

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – parallelism formula
To use parallelism during create index operation we must to use consumers… create index … on… with consumers=<tasks>
Those consumers depends on 4 configuration params:
Max parallel degreeMax utility parallel degreeNumber of worker processesMemory per worker processes

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – worker processes setup
To use 20 consumers ( expected to have 41 processes related to execute the command )… create index … on… with consumers=<tasks>
Those params must be set as:
Max parallel degree = 41Max utility parallel degree = 41Number of worker processes = 41 (minimum)Memory per worker processes = 65536Number of sort buffers = 10000

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – why?
41 processes will be created for 20 consumersEach partition will be scanned by 1 producer process and 1 consumer will be responsible to sort the read
1 process will be the coordinator (sync)
Number of worker processes must to cover all create index/ update statistics running in parallel for different tables
The real number for “number of worker processes” is max parallel degree X < command sessions in parallel>

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Real World
Big Table create index with 50 consumers
50 first are producers, each one reading own partition of table50 processes as consumers1 sync process
fid spid status cmd1145 529 sleeping WORKER
PROCESS1145 530 sleeping WORKER PROCESS1145 531 sleeping WORKER PROCESS1145 532 sleeping WORKER PROCESS1145 533 sleeping WORKER PROCESS1145 534 sleeping WORKER PROCESS1145 535 sleeping WORKER PROCESS1145 536 sleeping WORKER PROCESS1145 537 sleeping WORKER PROCESS1145 538 sleeping WORKER PROCESS1145 539 sleeping WORKER PROCESS
1145 1145 sync sleep CREATE INDEX

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – ProducersSPID LogicalReads PhysicalReads PartitionName529 271618 401 Partition_1530 280399 227 Partition_2531 280344 248 Partition_3532 279316 394 Partition_4533 283772 201 Partition_5534 282586 390 Partition_6535 284095 296 Partition_7536 279560 459 Partition_8537 277726 372 Partition_9538 277901 336 Partition_10
.........SPID LogicalReads PhysicalReads PartitionName574 282646 379 Partition_46575 286800 469 Partition_47576 268046 970 Partition_48577 277900 301 Partition_49578 282327 174 Partition_50
The snapshot shows a create index with 50 consumers
50 first are producers, each one reading own partition of table
The output can be generated by monProcessObject
In this way all scan will go directly to the cache using 4*pagesize pool ( 16K for 2K…)

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Consumers
Each consumer can be identified in the same output from monProcessObject
All partition names points to Partition_1 ( or first Partition name)
Don’t see physicalReads, because is a sort and write processing
The performance here depends on cache size, number of sort buffers and Disk Speed I/O for writing operations…
SPID LogicalReads PhysicalReads PartitionName579 514391 0 Partition_1580 220928 0 Partition_1581 377781 0 Partition_1582 589584 0 Partition_1583 230281 0 Partition_1584 299273 0 Partition_1585 288716 0 Partition_1586 77644 0 Partition_1587 132840 0 Partition_1

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Customer Results
Caixa Economica Federal – BrazilTable with 1.5 TB Partition by hash – 50 partitionsInitial I/O sub-system = VMAX with SSDFinal I/O sub-system = EMC XTREM I/O

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Customer Resultsexecution #1
First Execution-Consumers = 20-Max parallel degree = 21-Worker processes created 21-Problem: 1 producer 20 consumers
All time waiting to sort the data

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Customer Resultsexecution #2
Second Execution-Consumers = 50-Max parallel degree = 101-Worker processes created 101-Problem: 50 producer (1 for each partition) 50 consumers ( 1 for each producer)
1 sync
Pressure on the I/O subsystem, writing got like 30ms avg svct

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Customer Resultsexecution #3
Third Execution-Consumers = 50-Max parallel degree = 101-Worker processes created 101-Problem: 50 producer (1 for each partition) 50 consumers ( 1 for each producer)
1 sync
Using EMC XTREM I/O – achieved more then 100,000 IOPS with less than 4 ms per
I/O LIMIT !

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Index Rebuilding – Tips and Tricks
•Configure the Default Datacache large pool (16K,64K,128K) for 30%-50% of default pool•Partition the cache as number of engines ( recommended configuration) to be avoid spinlock contention•Setup the I/O sub system, spliting db´s across devices and speed up devices in multiple disks•Adjust max parallel degree, max utility parallel degree, memory per worker processes, number of worker processes and number of sort buffers according your table size and partitions•Use set (sort_resource on and noexec on) at session leve to check the plan of create index before the launch•Setup “max scan parallel degree” for non-partitioned tables using the same formula of “max parallel degree” but take care to do it without production running, could change all plans on the cache… or before adjust “min pages for parallel scan” to a big value… ( never tested yet )

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Questions and Answers Questions and Answers

(c) 2015 Independent SAP Technical User Group
Annual Conference, 2015
Thank You for Attending Thank You for Attending
Please complete your Please complete your session feedback form session feedback form
Related Documents











