SPARSH MITTAL, ZHAO ZHANG AND YANAN CAO PUBLISHED IN IEEE TRANSACTIONS ON VLSI 2014 MASTER: A Technique for Improving Energy Efficiency of Caches In Multicore Processors

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

SPARSH MITTAL, ZHAO ZHANG AND YANAN CAO
P U B L I S H E D I N I E E E T R A N S A C T I O N S O N V L S I 2 0 1 4
MASTER: A Technique for Improving Energy Efficiency of Caches In Multicore Processors

Presentation Plan
Motivation For Cache Power Management
Existing Techniques And Their Limitations
MASTER: Overall Approach
Cache Coloring and Reconfigurable Cache Emulator
Marginal Gain Computation and Algorithm
Overall Flow-Diagram
Simulation Experiments and Results

Motivation: Power Management Is Crucial
Power issue drives major design decisions.
Modern data centers consume megawatts of peak power: equal to the needs of a city of thousands of people!
An Exascale machine built with technology used in today’s supercomputers will consume gigawatts of power!

Motivation: Increasing Cache Sizes
Size of last level cache is increasing (e.g. 15MB in Intel Core i7-3960X processor)!
Caches consume huge chip area!
Intel’s 32nm Sandy Bridge Core i7-3960X

Motivation: Increasing Leakage Energy
Leakage energy is increasing dramatically with recent CMOS technology generations
Leakage energy has become a major source of energy consumption in last level caches (LLC)
Large power consumption increases cooling cost also
We need effective approaches for saving cache leakage energy!

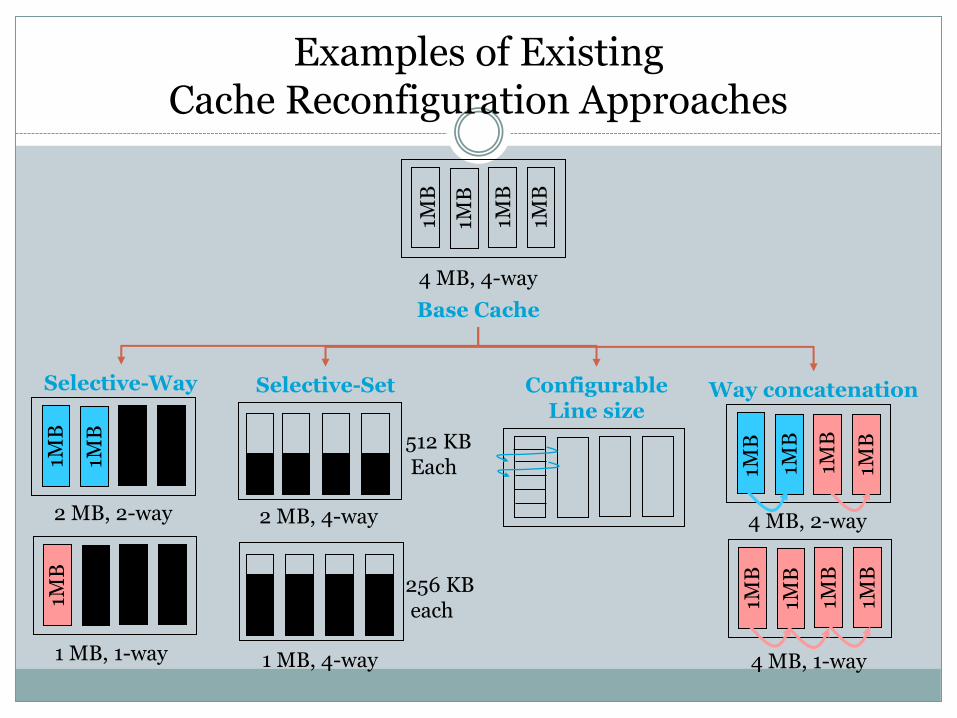
Cache Reconfiguration Approach: Main Idea
There exists inter- and intra-program variation in cache requirement of different programs.
By allocating just right amount of cache to each program, rest of the cache can be turned off.
Leakage saving can be obtained with minimum performance loss.
2 MB, 4-way
1 MB, 4-way
Selective-Set
512 KB Each
256 KB each
1MB
1MB
2K
B
2K
B
2 MB, 2-way
1MB
2K
B
2K
B
2K
B
1 MB, 1-way
Selective-Way
Examples of Existing Cache Reconfiguration Approaches
1MB
4 MB, 4-way
1MB
1MB
1MB
Base Cache
1MB
1MB
1MB
1MB
4 MB, 2-way
1MB
1MB
1MB
1MB
4 MB, 1-way
Way concatenation Configurable Line size

Limitations of Existing Cache Energy Saving Techniques
Provide coarse-grain allocation granularity.
Require offline analysis, difficult to scale.
Cannot take components other than cache into account
In multicore systems
Option space becomes huge!
Locality of memory access stream is reduced and hence locality based techniques don’t work well.

MASTER: A Microarchitectural Cache Leakage Energy Saving Technique
Using Dynamic Cache Reconfiguration

Transition Unused Blocks to Low-Power State.
Options State-preserving State-destroying
technique (Gated Vdd
Technique)
Collect Profiling Info. Compute Marginal Gain Use Energy Saving
Algorithm to Decide Cache Quota of Each Application
Use Cache Coloring to Enforce Quotas
Cache Partitioning and
Cache Quota Enforcement
Cache Turn-off for
Saving Leakage Energy
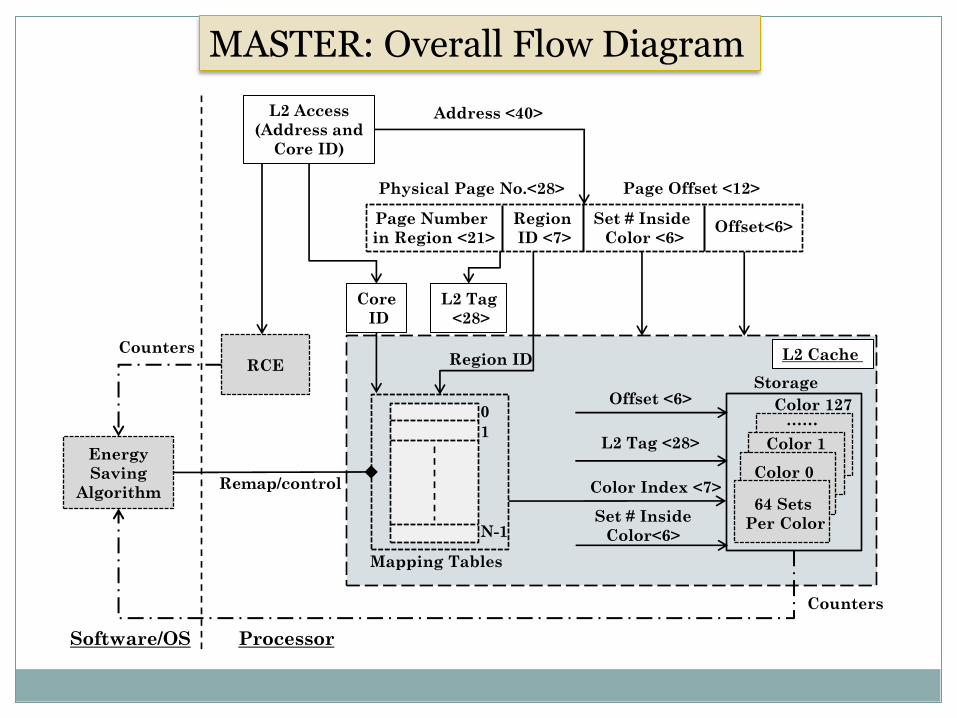
MASTER: Overall Approach

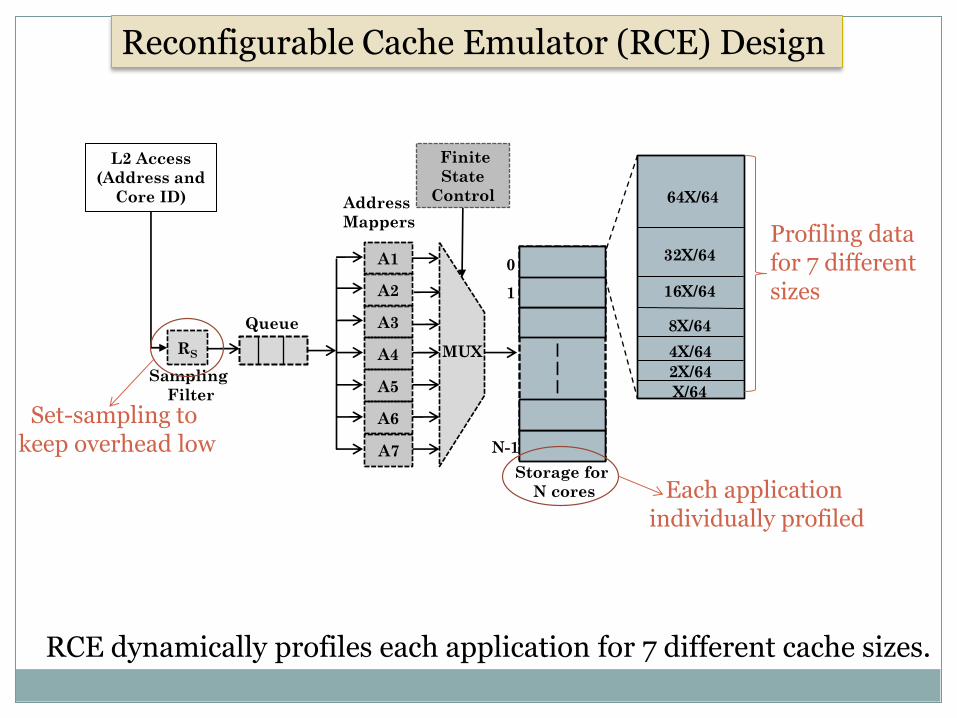
Collecting Profiling Information
For each application, we want to find its miss-rate for different cache sizes
So we use auxiliary tags, called profiling unit.
One profiling unit for each size and each core
Overhead is low since
We store only tags and not data
We use set-sampling (sampling ratio = 64 or more)
We call the structure RCE (Reconfigurable Cache Emulator).
L2 Access
(Address and
Core ID)
Queue
Storage for
N cores
A1
A2
A3
A4
A5
A6
MUX
Address
Mappers
RS
Sampling
Filter
A7
Finite
State
Control
0
N-1
1
64X/64
32X/64
16X/64
8X/64
4X/64
2X/64
X/64
Reconfigurable Cache Emulator (RCE) Design
Set-sampling to keep overhead low
Profiling data for 7 different sizes
RCE dynamically profiles each application for 7 different cache sizes.
Each application individually profiled

L2 Cache 8MB, 8-way, 64B block size
Number of L2 Sets 16384
Sampling Ratio 64
Number of Sets In Profiling Unit =16384/64= 256
Tag size (bits) 24
Profiling Unit Size (Bytes) =(256*8*24)/8 = 6144
Profiling Unit Size (KB) 6
Profiling Unit Overhead

Storage for
N cores
0
N-1
1
64X/64
32X/64
16X/64
8X/64
4X/64
2X/64
X/64
Reconfigurable Cache Emulator (RCE) Overhead
Assume an L2 cache of 8MB size
Even For 4 Cores: Size and Energy overhead of RCE: < 0.8% of L2 cache
Region L2 Size Profiled
Profiling Unit Size
64X/64 8MB 6KB
32X/64 4MB 3KB
16X/64 2MB 1.5KB
8X/64 1MB 768B
4X/64 512KB 384B
2X/64 256KB 192B
X/64 128KB 96B

Block offset
Physical Page Number Page Offset
Block offset
Physical Page Number Page Offset
Memory
Region ID
Set Index
Physical
Address
Physical
Address
Conventional Set-decoding
Cache Coloring
Cache
Color
Set #
Inside Color
Set Index
Mapping
Table

Full
Half
Quarter
Eighth
1/128 of total
size
Selective-sets Approach Cache Coloring Approach
L2 Cache L2 Cache

Core 0
Core 1
Turned Off
0
33
95
127
Core 0
Core 1
Turned Off
0
23
110
127
Core 1
Core 0
40
78
Core 0
Core 1 127
119
0
Examples of Different Possible Configurations

Marginal Gain Computation
Marginal gain shows reduction in cache miss on increasing unit cache color
Insight
Large marginal gain: Program needs more cache => allocating cache can improve performance and hence energy efficiency.
Small marginal gain: Program’s cache needs are small => turning off cache can save energy.
Colors Misses
16 14561
8 20786
Marginal Gain=(20786−14561)
(16−8)=778.1

C11
C12
C13
C14
Core
Step1: Select 4 color
values for each core
Step 3: Form 4-core
configurations
Step 4: Find most energy
efficient configuration
Answer
Here Cij shows jth color value for ith core
C21
C22
C23
C24
C31
C32
C33
C34
C01
C02
C03
C04
1 2 3 0
Step 2: Choose 2 energy efficient
color value for each core
1. C01 C11 C22 C33
2. C01 C11 C22 C34
3. C01 C11 C23 C33
………..
16. C03 C13 C23 C34
MASTER: Energy Saving Algorithm
1. C01 C11 C22 C33
2. C01 C11 C22 C34
3. C01 C11 C23 C33
………..
16. C03 C13 C23 C34
C11
C12
C13
C14
C21
C22
C23
C24
C31
C32
C33
C34
C01
C02
C03
C04
1 2 3 0
Core
ID
Color 127
Color 1
Color 0
……
Offset<6>
RCE
Software/OS Processor
Counters
Storage
Remap/control
0
1
N-1
Mapping Tables
Set # Inside
Color <6>
Physical Page No.<28>
L2 Access
(Address and
Core ID)
Energy
Saving
Algorithm
Address <40>
L2 Tag
<28>
Region
ID <7>
Page Number
in Region <21>
Region ID
64 Sets
Per Color Set # Inside
Color<6>
Color Index <7>
Offset <6>
L2 Tag <28>
Counters L2 Cache
Page Offset <12>
MASTER: Overall Flow Diagram

Salient Features of MASTER
Software-based approach, with light hardware support
Overhead of RCE and mapping tables <1% of L2.
RCE does not affect L2 operation and does not lie on critical path
No offline profiling required. Fine-grain cache allocation
Can take components other than cache into account.

Experiments
Sniper x86-64 simulator (based on Pin)
2 core with 4MB, 8-way L2
4 core with 8MB, 8-way L2
Baseline: Shared cache with no reconfiguration
We measure energy of L2 cache, DRAM and algorithm.
500M instruction each core. Interval size = 5M cycles
Comparison with
Decay cache technique (DCT) [1]
Way-adaptable cache technique (WAC) [2]

High(H)
astar(As), bzip2(Bz), calculix(Ca), dealII(Dl), gcc(Gc), gemsFDTD(Gm), gromacs(Gr), lbm(Lb), leslie3d(Ls), omnetpp(Om), soplex(So), sphinx(Sp), xalancbmk(Xa), zeusmp(Ze)
Low(L)
bwaves(Bw), cactusADM(Cd), gamess(Ga), gobmk(Gk), h264ref(H2), hmmer(Hm), libquantum(Lq), mcf(Mc), milc(Mi), namd(Nd), perlbench(Pe), povray(Po), sjeng(Sj), tonto(To), wrf(Wr)
H2L0 T1(AsDl), T2(GcLs), T3(GmGr), T4(LbXa), T5(BzLs)
H1L1 T6(SoMi), T7(ZeCd), T8(CaTo), T9(SpMc), T10(OmLq)
H0L2 T11(SjWr), T12(BwNd), T13(HmGa), T14(GkH2), T15(PePo)
H4L0 F1(SoGrZeLb), F2(OmSpGmGc), F3(BzGrLsGm)
H3L1 F4(LsZeOmLq), F5(GmCaLbCd), F6(CaAsXaMc)
H2L2 F7(BzDlGaMc), F8(SpGcLqHm), F9(XaLbMiGk)
H1L3 F10(SoNdMiBw), F11(DlCdGkGa), F12(AsPeToWr)
H0L4 F13(BwPoNdH2), F14(HmSjPoH2), F15(SjToWrPe)
SPEC2006 Benchmark Classification
2-Core Workloads
4-Core Workloads
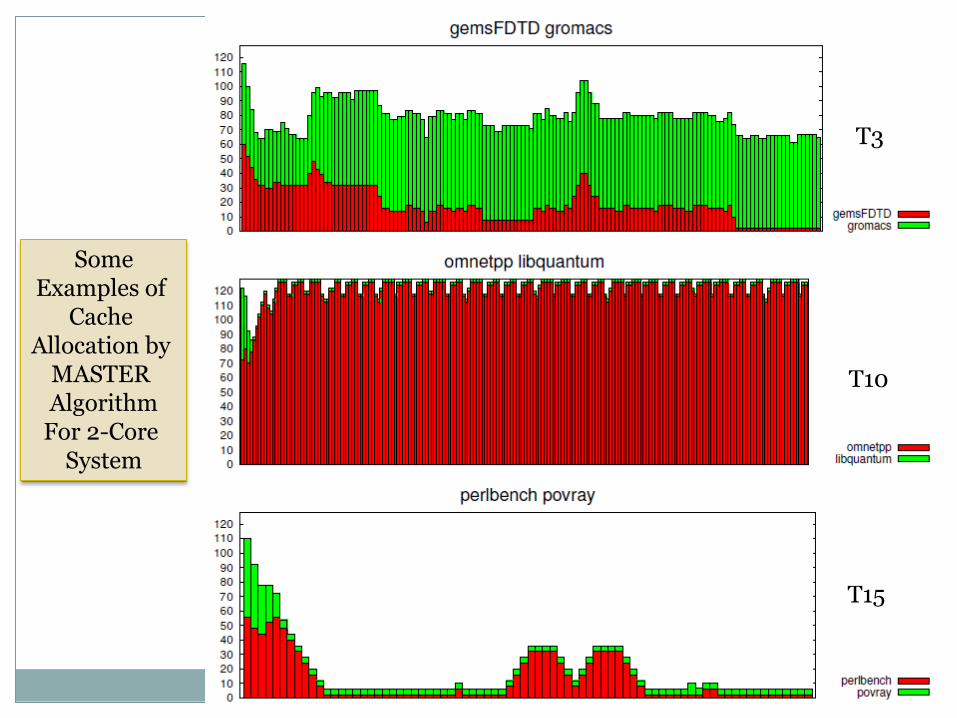
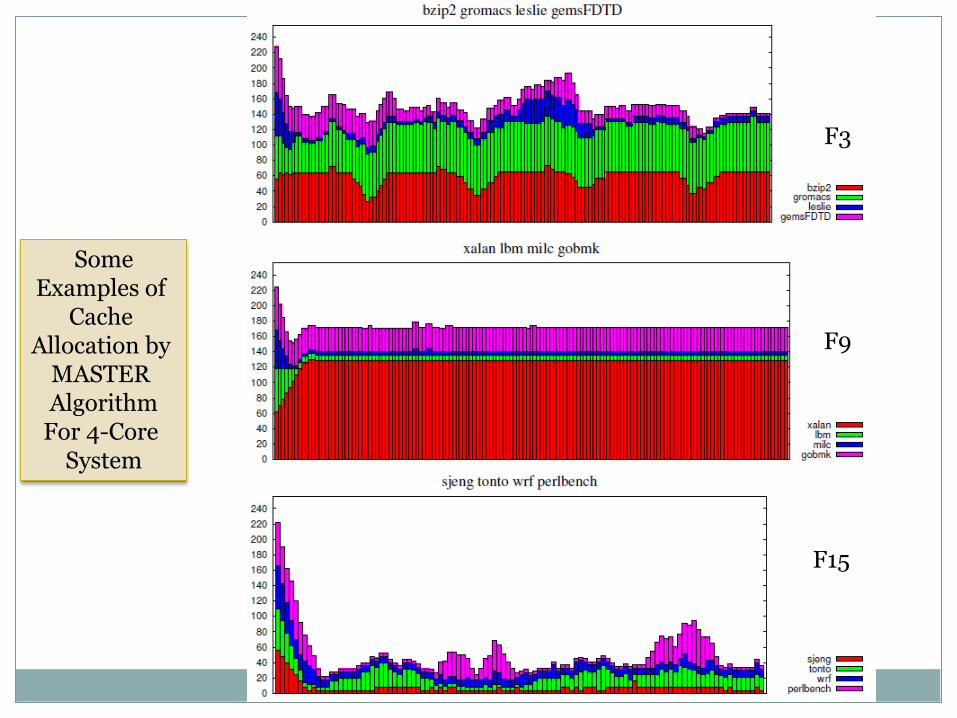
Some Examples of
Cache Allocation by
MASTER Algorithm
For 2-Core System
T3
T10
T15

Energy Saving with 2-core System MASTER DCT WAC
14.7% 9.4% 10.2%
ActiveRatio = Fraction of active cache lines averaged over entire simulation
Some Examples of
Cache Allocation by
MASTER Algorithm
For 4-Core System
F3
F9
F15

Energy Saving with 4-core System MASTER DCT WAC
11.2% 4.9% 6.5%

Result Analysis
MASTER provides fair speedup (~1.0)
On average, DRAM traffic increase is small or even negative.
MASTER also outperforms statically equally-partitioned baseline cache (results omitted).

MASTER Parameter Sensitivity Results
% Energy Saved Weighted Speedup
DRAM Access Increase (per kilo
instruction)
N=2 N=4 N=2 N=4 N=2 N=4
Default 14.7 11.2 0.99 0.99 -0.51 0.17
Interval=10M 14 11.6 1 1 -0.68 -0.17
Sampling Ratio =128 12.9 10.3 0.99 0.99 0.04 0.61
Assoc =16 15.8 13.9 0.99 0.99 -0.51 0.23
FIFO policy 12.9 12.8 0.99 1 -0.54 -0.18
PLRU policy 14.3 12 0.99 0.99 -0.45 0.14
Clearly, MASTER works well for: Different interval sizes Different sampling ratios Different cache associativities Different cache replacement policies

Contributions and Applications
Our techniques can be easily extended to:
Single-tasking and multi-tasking systems
Soft real-time systems
Hardly few cache leakage energy saving techniques exist for multicore processors
Saving energy gives headroom for performance scaling and also reduces cooling cost.
Our techniques directly optimize energy and hence can optimize for system energy.
No offline profiling: suitable for product systems.
Thanks a lot!
Questions and Comments are Welcome!

Extra Slides

L2 Size 8MB, 8-way, 64B block size
Number of L2 Sets 16384
Sampling Ratio 64
Number of Sets In Profiling Unit =16384/64= 256
Tag size (bits) 24
Profiling Unit Size (Bytes) =(256*8*24)/8 = 6144
Profiling Unit Size (KB) 6

MASTER: Energy Saving Algorithm
1. Choose 4 color values for each core using marginal gain from cache allocation.
2. Select 2 with minimum energy.
3. Using these, form N core configurations.
4. Select 1 with minimum energy.
5. Choose it for next interval.
Related Documents











