Massive Computing at CERN and lessons learnt Bob Jones CERN Bob.Jones <at> CERN.ch

Massive Computing at CERN and lessons learnt Bob Jones CERN Bob.Jones CERN.ch.
Dec 26, 2015
Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

Massive Computing at CERN and lessons learnt
Bob JonesCERN
Bob.Jones <at> CERN.ch

• A distributed computing infrastructure to provide the production and analysis environments for the LHC experiments
• Managed and operated by a worldwide collaboration between the experiments and the participating computer centres
• The resources are distributed – for funding and sociological reasons
• Our task is to make use of the resources available to us – no matter where they are located
Ian Bird, CERN 2
WLCG – what and why?
What is WLCG today?
Service coordinationService coordinationService managementService management Operational securityOperational security
World-wide trust federationfor CA’s and VO’s
World-wide trust federationfor CA’s and VO’s
Complete Policy frameworkComplete Policy framework
FrameworkFramework
Support processes & toolsSupport processes & tools Common toolsCommon tools Monitoring & AccountingMonitoring & Accounting
CollaborationCollaborationCoordination & management & reportingCoordination & management & reporting
Common requirementsCommon requirements
Coordinate resources & fundingCoordinate resources & funding
Memorandum of Understanding
Coordination with service & technology providersCoordination with service & technology providers
Physical resources: CPU, Disk, Tape, NetworksPhysical resources: CPU, Disk, Tape, Networks
Distributed Computing servicesDistributed Computing services

4
WLCG data processing model
Tier-1 (11 centres):•Permanent storage•Re-processing•Analysis
Tier-0 (CERN):•Data recording•Initial data reconstruction•Data distribution
Tier-2 (~130 centres):• Simulation• End-user analysis
Jones
Explain how many physicists are accessing the data

Lyon/CCIN2P3Barcelona/PIC
De-FZK
US-FNAL
Ca-TRIUMF
NDGF
CERNUS-BNL
UK-RAL
Taipei/ASGC
Ian Bird, CERN 526 June 2009
Today we have 49 MoU signatories, representing 34 countries:
Australia, Austria, Belgium, Brazil, Canada, China, Czech Rep, Denmark, Estonia, Finland, France, Germany, Hungary, Italy, India, Israel, Japan, Rep. Korea, Netherlands, Norway, Pakistan, Poland, Portugal, Romania, Russia, Slovenia, Spain, Sweden, Switzerland, Taipei, Turkey, UK, Ukraine, USA.
Today we have 49 MoU signatories, representing 34 countries:
Australia, Austria, Belgium, Brazil, Canada, China, Czech Rep, Denmark, Estonia, Finland, France, Germany, Hungary, Italy, India, Israel, Japan, Rep. Korea, Netherlands, Norway, Pakistan, Poland, Portugal, Romania, Russia, Slovenia, Spain, Sweden, Switzerland, Taipei, Turkey, UK, Ukraine, USA.
WLCG Collaboration StatusTier 0; 11 Tier 1s; 64 Tier 2 federationsWLCG Collaboration StatusTier 0; 11 Tier 1s; 64 Tier 2 federations
Amsterdam/NIKHEF-SARA
Bologna/CNAF

Ian Bird, CERN 6
Fibre cut during 2009:Redundancy meant no interruption

Worldwide resources
7
• >140 sites• ~250k CPU cores• ~100 PB disk
• >140 sites• ~250k CPU cores• ~100 PB disk
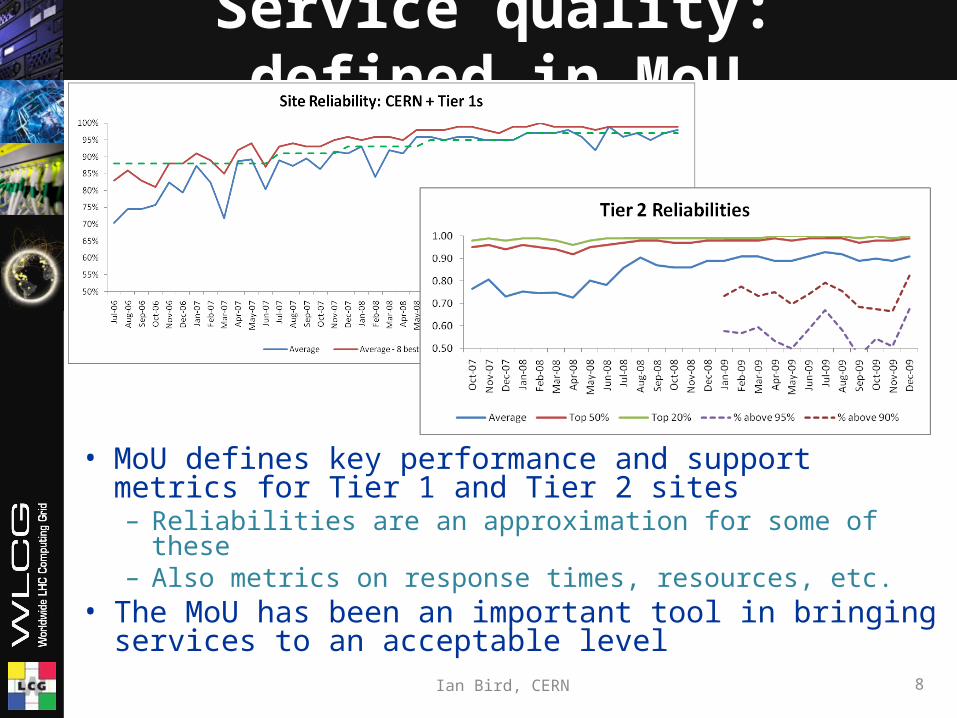
• MoU defines key performance and support metrics for Tier 1 and Tier 2 sites– Reliabilities are an approximation for some of these– Also metrics on response times, resources, etc.
• The MoU has been an important tool in bringing services to an acceptable level
Ian Bird, CERN 8
Service quality: defined in MoU

Ian Bird, CERN 9
From testing to data:Independent Experiment Data ChallengesIndependent Experiment Data Challenges
Service Challenges proposed in 2004To demonstrate service aspects:
-Data transfers for weeks on end-Data management-Scaling of job workloads-Security incidents (“fire drills”)-Interoperability-Support processes
Service Challenges proposed in 2004To demonstrate service aspects:
-Data transfers for weeks on end-Data management-Scaling of job workloads-Security incidents (“fire drills”)-Interoperability-Support processes
2004
2005
2006
2007
2008
2009
2010
SC1 Basic transfer ratesSC1 Basic transfer rates
SC2 Basic transfer ratesSC2 Basic transfer rates
SC3 Sustained rates, data management, service reliabilitySC3 Sustained rates, data management, service reliability
SC4 Nominal LHC rates, disk tape tests, all Tier 1s, some Tier 2sSC4 Nominal LHC rates, disk tape tests, all Tier 1s, some Tier 2s
CCRC’08 Readiness challenge, all experiments, ~full computing models
CCRC’08 Readiness challenge, all experiments, ~full computing models
STEP’09 Scale challenge, all experiments, full computing models, tape recall + analysis
STEP’09 Scale challenge, all experiments, full computing models, tape recall + analysis
• Focus on real and continuous production use of the service over several years (simulations since 2003, cosmic ray data, etc.)• Data and Service challenges to exercise all aspects of the service – not just for data transfers, but workloads, support structures etc.
e.g. DC04 (ALICE, CMS, LHCb)/DC2 (ATLAS) in 2004 saw first full chain of computing models on grids
e.g. DC04 (ALICE, CMS, LHCb)/DC2 (ATLAS) in 2004 saw first full chain of computing models on grids

• LHC, the experiments, & computing have taken ~20 years to build and commission
• They will run for at least 20 years• We must be able to rely on long term
infrastructures– Global networking– Strong and stable NGIs (or their evolution)
• That should be eventually self-sustaining
– Long term sustainability - must come out of the current short term project funding cycles
Ian Bird, CERN 10
Large scale = long times

• CERN and the HEP community have been involved with grids from the beginning
• Recognised as a key technology for implementing the LHC computing model
• HEP work with EC-funded EDG/EGEE in Europe, iVDGL/Grid3/OSG etc. in US has been of clear mutual benefit– Infrastructure development driven by HEP needs– Robustness needed by
WLCG is benefitting other communities
– Transfer of technology fromHEP
• Ganga, AMGA, etc used by many communities now
Ian Bird, CERN 11
Grids & HEP: Common history

www.egi.euEGI-InSPIRE RI-261323 www.egi.euEGI-InSPIRE RI-261323
European Grid Infrastructure
• European Data Grid (EDG)– Explore concepts in a testbed
• Enabling Grid for E-sciencE (EGEE)– Moving from prototype to production
• European Grid Infrastructure (EGI)– Routine usage of a sustainable e-
infrastructure
12

www.egi.euEGI-InSPIRE RI-261323
European Grid Infrastructure(Status April 2011 – yearly increase)
• 13319 end-users (+9%)• 186 VOs (+6%)• ~30 active VOs: constant• Logical CPUs (cores)
– 207,200 EGI (+8%)– 308,500 All
• 90 MPI sites• 101 PB disk• 80 PB tape• 25.7 million jobs/month
– 933,000 jobs/day (+91%)• 320 sites (1.4%)• 58 countries (+11.5%)
EGI - The First Year 13
ArcheologyAstronomyAstrophysicsCivil ProtectionComp. ChemistryEarth SciencesFinanceFusionGeophysicsHigh Energy PhysicsLife SciencesMultimediaMaterial Sciences…
Non-HEP users ~ 3.3M jobs / month

Grids, clouds, supercomputers, etc.
14
Grids• Collaborative environment• Distributed resources (political/sociological)• Commodity hardware• (HEP) data management• Complex interfaces (bug not feature)• Communities expected to contribute resources
Supercomputers• Scarce• Low latency interconnects• Applications peer reviewed• Parallel/coupled applications• Also SC grids (DEISA/PRACE, Teragrid/XD)
Clouds• Proprietary (implementation)• Economies of scale in management• Commodity hardware• Pay-as-you-go usage model• Details of physical resources hidden• Simple interfaces
Volunteer computing• Simple mechanism to access millions CPUs• Difficult if (much) data involved• Control of environment check • Community building – people involved in Science• Potential for huge amounts of real work

CERN IT Department
CH-1211 Genève 23
Switzerlandwww.cern.ch/it
• Philosophy: promote web-based citizen participation in science projects as an appropriate low cost technology for scientists in the developing world.
• Partners: CERN, UN Institute for Training and Research, University of Geneva • Sponsors: IBM, HP Labs, Shuttleworth Foundation • Technology: open source platforms for internet-based distributed collaboration• Projects:
– Computing for Clean Water optimizing nanotube based water filters by large scale simulation on volunteer PCs
– AfricaMap volunteer thinking to generate maps of regions of Africa from satellite images, with UNOSAT
– LHC@home new volunteer project for public participation in LHC collision simulations, using VM technology
• Plans: Training workshops in 2011 in India, China, Brazil and South Africa
Collaboration with the General Public:Citizen Cyberscience Centre
Frédéric Hemmer 15

Some more questions to be answered• Computing model
– How many computing models exist in the community and can they all use the same computing infrastructure?
• Continuous load or periodic campaigns?– How intensely and frequently will the community use the computing
infrastructure?
• Manpower– Do you have enough geeks to port the code and support it?
• How committed is the community?– Are you prepared to contribute and share computing resources?
Bob Jones – May 2011 16
Related Documents











