~-~.- _I_ - .__i"-?._l_ - _--- +" Please see tfie color piate on page2geZ- J L-"- 11~~1111111 --_- Markerless Monocular Motion Capture Using Image Features and Physical Constraints Yisheng Chen' Jinho Leet Rick Parent$ Raghu Machirajul The Ohio State University MER1 The Ohio State University The Ohio State University ABSTRACT We present a technique to extract motion parameters of a human figure from a single video stream. Our goal is to prototype motion synthesis rapidly for game design and animation applications. For example, our approach is especially useful in situations where mo- tion capture systems are restricted in their usefuhess given the var- ious required instrumentation. Similarly, our approach can be used to synthesize motion from archival footage. By extracting the sil- houette of the foreground figure and using a model-based approach, the problem is re-formulated as a local, optimized search ofthe pose space, The pose space consists of 6 rigid body vansformation para- meters plus the internal joint angles of the figure. The silhouette of the figure from the captured video is compared against the silhou- eite of a synthetic figure using a pixel-bypixel, distancebased cost function to evaluate goodness-of-fit. For for a single video stream, this is not without problems. Occlusion and ambiguities arising from the use of a single view often cause spurious reconstruction of the captured motion. By using temporal coherence, physical con- straints, and knowledge of the anatomy, a viable pose sequence can be reconstructed for many live-action sequences. CR Categories: 1.3.7 [Computer Graphics]: Three-Dimensional Graphics and Realism-Animation- [I.4.4]: Image Processing and Computer Vision-Applications Keywords: computer animation, model-based reconstruction 1 INTRODUCTION Motion Capture (mocap) has become a mainstay of many computer animated productions and is often used to capture human motion. Commercial mocap systems capture motion by fixing on the target figure instrumentation such as optical, magnetic, or mechanical sen- sors, passive optical reflectors or active optical emitters. However, various constraints imposed by the instrumentation tend to limit the usefulness of mocap either by restricting the physical space of the movement, restricting the environment in which motion can be cap- tured, or restricting the movement itself (not to mention restrictions due to cost). While motion hbraries and motion retargetting techniques extend the usefulness of mocap, there is a need to develop algorithms and methods for commodity sensors. For example, there is often a need to synthesize the motian of a figure in a video Cl$ obtained from Ihe Web, or from a surveillance camera. Conversely, one would like to capture human motion with the least m o u n t of equipment possible - using a sin& consumer-grade camera. Additionally, we wish to produce results at rates that would make such a system useful in an interactive environment and therefore suitable for prototyping animated sequences and exploring initial character motions. "e-mail:chenyisFcse.ohio-state.edu 'e-mail:[email protected] te-,ail:parentOcse.ohio-state.edu 0e-mail:mghu @cse.ahio-stats.edu Proceedings of Computer Graphics lnlemational2005 (CG1'05) June 22-24,2005, Stony Brook, NY, USA 0-7803-9330-9/05/$20.00 02005 IEEE However, creating a single-camera, interactive, markerless system to capture human motion is challenging [6]. On the other hand, heremhas been a concerted effort by several researchers to develop methods that will reconstruct motion recorded by either a limited number of camerns or just a single camera. Generally speaking, capturing human motion from video involves extracting features From video sequences and matching those fea- tures to some model or representation of motion to be reconstructed. Data-driven approaches exploit a motion database for reconstruct- ing target motion {e.g., [ 1 I ]). Such strategies can provide real-time albeit limited reconstruction of motion. Maion outside the confines of the database is constructed with lesser fidelity. Other approaches key on a specific type of motion, such as cyclic, sagittally symmet- ric motion, and look for specific indicators of motion phases (e.g., IZ]). Zn a more general vein, motion-templates are used to recognize a variety of motions (e.g., [ 11). More general are systems that use a 3D model of the human figure to recreate a figure's pose for each frame. Rehg and his associates [5], and SmincAisescu II9,21,20] have used both 3D models of humans to emulate and synthesize motion as depicted in a single video stream. Our approach also falls into this last category. We now elaborate on our model-based approach. 1.1 3D Mode[-based Approach Model-based approaches use a 3D articulated model of the human body to estimate the pose and shape such that the model's 2D pro- jection closely fits the captured person in the image. Features such as intensities, edges, silhouettes are widely used. Processing color and texture information is computationally expensive and changes in illumination present significant problems. tt should be noted much of the scene and camera information is unknown. As a re- sult, many of the efforts to track human figures in video, including ours, use silhouettes. Silhouettes are less sensitive to noise than edges but fine details might be lost in its extraction. The use of silhouettes does create problems. Extracting pose from a silhouette can produce multiple candidate solutions. The high dimensionality of the articulated model parameter space requires efficient yet robust search algorithms. A suitable initialization of model parameters is also required by many algorithms for motion tracking. Constraints like joint angle limits on parameters can be used as well as knowledge about physics and the anatomy. By extracting the silhouette of the foreground figure and using a model-based approach, the problem is re-formulated as a local, op- timized search of the pose space. The pose space, in turn, consists of 6 rigid body transformation parameters plus the internal joint angles of the figure. Occlusion and ambiguities arising from the use of a single view of- ten cause spurious reconstruction of the captured motion. There- fore, the reconstruction is successful when either 2D correspon- dence is established for each frame of the sequence manually [SI, or when the motion under scrutiny is limited [19, 211. There is a paucity of methods that aHow for general motion and require little manual intervention. Additionally, these methods should be effi- cient. 36

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

~-~- _I_ - __i-_l_ - _--- +
Please see tfie color piate on page2geZ- J L--- 1 1 ~ ~ 1 1 1 1 1 1 1 --_- Markerless Monocular Motion Capture Using Image Features and Physical
Constraints
Yisheng Chen Jinho Leet Rick Parent$ Raghu Machirajul The Ohio State University M E R 1 The Ohio State University The Ohio State University
ABSTRACT
We present a technique to extract motion parameters of a human figure from a single video stream Our goal is to prototype motion synthesis rapidly for game design and animation applications For example our approach is especially useful in situations where mo- tion capture systems are restricted in their usefuhess given the var- ious required instrumentation Similarly our approach can be used to synthesize motion from archival footage By extracting the sil- houette of the foreground figure and using a model-based approach the problem is re-formulated as a local optimized search ofthe pose space The pose space consists of 6 rigid body vansformation para- meters plus the internal joint angles of the figure The silhouette of the figure from the captured video is compared against the silhou- eite of a synthetic figure using a pixel-bypixel distancebased cost function to evaluate goodness-of-fit For for a single video stream this is not without problems Occlusion and ambiguities arising from the use of a single view often cause spurious reconstruction of the captured motion By using temporal coherence physical con- straints and knowledge of the anatomy a viable pose sequence can be reconstructed for many live-action sequences CR Categories 137 [Computer Graphics] Three-Dimensional Graphics and Realism-Animation- [I44] Image Processing and Computer Vision-Applications Keywords computer animation model-based reconstruction
1 INTRODUCTION
Motion Capture (mocap) has become a mainstay of many computer animated productions and is often used to capture human motion Commercial mocap systems capture motion by fixing on the target figure instrumentation such as optical magnetic or mechanical sen- sors passive optical reflectors or active optical emitters However various constraints imposed by the instrumentation tend to limit the usefulness of mocap either by restricting the physical space of the movement restricting the environment in which motion can be cap- tured or restricting the movement itself (not to mention restrictions due to cost)
While motion hbraries and motion retargetting techniques extend the usefulness of mocap there is a need to develop algorithms and methods for commodity sensors For example there is often a need to synthesize the motian of a figure in a video Cl$ obtained from Ihe Web or from a surveillance camera Conversely one would like to capture human motion with the least m o u n t of equipment possible - using a sinamp consumer-grade camera Additionally we wish to produce results at rates that would make such a system useful in an interactive environment and therefore suitable for prototyping animated sequences and exploring initial character motions
e-mailchenyisFcseohio-stateedu e-mailIeejhmerlcom te-ailparentOcseohio-stateedu 0e-mailmghu cseahio-statsedu
Proceedings of Computer Graphics lnlemational2005 (CG105) June 22-242005 Stony Brook NY USA 0-7803-9330-905$2000 02005 IEEE
However creating a single-camera interactive markerless system to capture human motion is challenging [6] On the other hand heremhas been a concerted effort by several researchers to develop methods that will reconstruct motion recorded by either a limited number of camerns or just a single camera
Generally speaking capturing human motion from video involves extracting features From video sequences and matching those fea- tures to some model or representation of motion to be reconstructed Data-driven approaches exploit a motion database for reconstruct- ing target motion eg [ 1 I ]) Such strategies can provide real-time albeit limited reconstruction of motion Maion outside the confines of the database is constructed with lesser fidelity Other approaches key on a specific type of motion such as cyclic sagittally symmet- ric motion and look for specific indicators of motion phases (eg IZ]) Zn a more general vein motion-templates are used to recognize a variety of motions (eg [ 11) More general are systems that use a 3D model of the human figure to recreate a figures pose for each frame Rehg and his associates [5] and SmincAisescu II92120] have used both 3D models of humans to emulate and synthesize motion as depicted in a single video stream Our approach also falls into this last category We now elaborate on our model-based approach
11 3D Mode[-based Approach
Model-based approaches use a 3D articulated model of the human body to estimate the pose and shape such that the models 2D pro- jection closely fits the captured person in the image Features such as intensities edges silhouettes are widely used Processing color and texture information is computationally expensive and changes in illumination present significant problems tt should be noted much of the scene and camera information is unknown As a re- sult many of the efforts to track human figures in video including ours use silhouettes Silhouettes are less sensitive to noise than edges but fine details might be lost in its extraction
The use of silhouettes does create problems Extracting pose from a silhouette can produce multiple candidate solutions The high dimensionality of the articulated model parameter space requires efficient yet robust search algorithms A suitable initialization of model parameters i s also required by many algorithms for motion tracking Constraints like joint angle limits on parameters can be used as well as knowledge about physics and the anatomy
By extracting the silhouette of the foreground figure and using a model-based approach the problem is re-formulated as a local op- timized search of the pose space The pose space in turn consists of 6 rigid body transformation parameters plus the internal joint angles of the figure
Occlusion and ambiguities arising from the use of a single view of- ten cause spurious reconstruction of the captured motion There- fore the reconstruction i s successful when either 2D correspon- dence is established for each frame of the sequence manually [SI or when the motion under scrutiny is limited [19 211 There is a paucity of methods that aHow for general motion and require little manual intervention Additionally these methods should be effi- cient
36
We describe herein a method to reconstruct arbitraq motion se- quences a at is model-based operates on images and exploits knowledge about the anatomy Consequently our method is simple efficient and requires limited manual intervention Will aur method reconstruct all motion sequences successfully The answer i s no Occlusion of limbs by larger parts of the anatomy cannot always be resolved through the use of image siIhouettes On the other hand we wish to explore the limits of efficient monocular motion recon- struction Our results show that we can reconstruct increasingly complex motion when we include a larger set of anatomical fea- tures and CQnSk3htS and employ robust image comparison metrics We now provide an overview of ow approach
12 Overview of Our Approach
In this paper we explore inverse methods which reconstruct motion from a single camera We examine techniques which use silhouettes and edges rather than texture Since motion is our primary interest and not identification silhouettes and edges provide ample grounds for developing robust methods hverse design methods like ours employ optimization algorithms to minimize an objective function
Resolving occlusion berween various parts of the human body is certainly an ominous challenge given the difficulty of matching an imperfect highly flexible self-occluding model to cluttered image features Viable human models have at least 20 joint parametea subject to highly nonlinear physical constraints Also a significant number of the possible degrees of freedom afforded by the vari- ous joints are not uniquely determined by any given image Thus monocular motion capture is ill-posed and non-linear Methods re- ported in the literature are either complex and expensive for com- puter graphics applications or impose severe restrictions on the type of motion that can be captured
The work described herein is an expIoration of simple yet robust cost functions and incremental search strategies Our focus on sim- pler cost functions will eventually allow for tlle realization of near real-time reconstruction often needed for computer graphics appli- cations while at the same time making few assumptions about the motion being tracked
The starling point of our method is a model of a human actm with multiple quadrics assembled at various joints After an initial pose is established either automatically or with the aid of the user a frame-to-frame tracking procedure ensues in which the solution of the last frame is the initial guess for the next frame In addition to silhouettes and edges our objective function uses anatomical and physical constraints to aid in disambiguating the view
The main contributions of our work include
development of a new core-weighted XOR metric for model localization in an image
robust detection and tracking of body parts such as head arms feet and the V between the legs in the image
inclusion of image features and anatomical constraints to re- duce the size of optimal search space
Our new method is shown to be capable of reconstructing full a- ticulated body motion efficiently AdditionaIly our results include video sequences of varying length and arbitrary iIlumination and the reconsuuction is quite faithful to the original sequence
The paper is organized as follows In Section 2 we describe perti- nent previous work in motion reconstruction Our human model is briefly discussed in Section 3 We describe in detail our method For motion recansbmction in Section 4 Implementation considerations
are given in Section 5 Section 6 includes results which demon- strate the effectiveness of our technique Concluding remarks and pointers to future work are described in Section 7
2 PREVIOUS WORK
We describe work that is closely related to our own Model based approaches use a 3D articulated model of the human body to esti- mate the pose and shape such that the modelrsquos 2D projection closely fits the captured person in the image Bregler and Malik [2] propose a framework to estimate 3D poses of each body segment in a kine- matic chain using twist representation of a general rigid-body mo- tion However their reconstruction assumes lateral symmetry in the tracked motion Pavlovic et al[16] present asystem to track fronta- parallel motion using a dynamic Bayesian nerwork approach Their work focuses on the dynamics of human behavior as described by bio-mechanical models
Deutscher et al 141 use a human model to build a framework of a kinematic chain using limbs of conical sections for computational simplicity and high-level interpretation of output They use edges and silhouettes for their cost function to estimate pose from multi- ple camera views A condensation algorithm is employed to search the high dimensional space without restrictions Cmanza er a1 [3] use silhouettes from multi-view synchronized video footage to re- construct the motion of a 3D human body model and then re-render the modelrsquos appearance and motion interactively from any novel view point Kakadiaris et al [IO] use a spatio-temporal analysis to track upper body motions from multiple cameras
Monocular markerless motion capture bas been studied by a few re- searchers Sminchisescu and Triggs [20] achieve successful motion synthesis based on the propagation of a mixture of Gaussian den- sity functions each representing probable 3D configurations of the human body over rime Difranco et al [5] pmpose a batch frame- work to reconstruct poses from a single view point based on 2D correspondences subject to a number of constraints Their methods are shown to be successful when deployed on moderately difficult sequences that include athletic and dance movements
Alternative approaches to model based tracking of human bodies have been also used Bobick and Davis [ I ] construct temporal tem- plates from a sequence of silhouette images and present a method to match the temporal template against stored views of the known actions Wren et a1 [22] use 2D blobs for tracking motion in a video image Leventon and Freeman [I41 take a statistical approach and used a set of motion examples to build a probability model for the purpose of recovering 3D joint angles for a new input sequence
Lee et a1 [I 1 1 present a vision-based interface to control avatars in virtual environments They extract visual features from the input silhouette images and search for the best motion matching the vi- sual euroeatures obtained from rendered versions of actions in a motion database Ren et a1 1181 use the AdampiBoost algorithm to select a Few best local features from silhouette images to estimate yaw and body configurations Finaliy a suwey of computer vision-based human motion caprure techniques is presented by Moeslund and Granum ~ 5 1
We reconstmct general 3D motion from the silhouettes extracted from a single view without relying on a motion database As a consequence our work is closest to that of Sminchisescu However we demonstrate the tracking of motions that are more complex than those presented by Sminchisescu and we track at speeds that are equal or faster than those reported
37
3 OUR HUMAN MODEL
Our human model is a combination of spheres and cylinders with anisotropic scale and rigid transformation for an object coordinate system for each part The model is shown in Figure 8 and Figure 9 The parameters that describe our human model consist of two com- ponents - shape and motion parameters We define twelve shape parameters which describe the scale factors to be multiplied to a predefined standard size of each body part Motion parameters are composed of 6 global transformation and total 24 joint angles Each joint has anywhere from one to three degrees-of-freedom Given N frames h m a videa sequence our human body model at a specific frame i is represented by M1) = M ( E ~ P ( ~ ) ) where a = (nl a2 4 r crpn (m = 12) is the shape parameter vector and p() = pL p2 pn 1 (n = 30) is the motion parmeter vector (i) (4 ( i )
4 THE OPTIMIZATION STRATEGY
The use of a single view makes the reconstwction problem ill- posed as stated earlier We now describe our optimization strat- egy to fit the motion parameters to a single stream of silhouette images First we describe how we extract silhouettes from a video sequence Then we present an objective function based on the dif- ference of area between model-generated silhouette and input sil- houette Next we discuss how we improve the performance of our optimization algorithm We achieve this by incorporating edge in- formation along with both physical and anatomical constraints into the objective function FinalIy we discuss a non-linear multidimen- sional optimization algorithm we employ to minimize the proposed objective function
41 Silhouette Extraction
The input to our motion synthesis system is a sequence of silhouette images that describe the g m s s motion of the human body We avoid using coloration or texture information in order to minimize the eeuro- fects of variable viewing conditions In addition to using silhou- ettes we also employ high-contrast edges to further our optimiza- tion strategy as explained below Given a video footage there exist several methods to obtain siIhouette images Although silhouettes are less sensitive to noise than edges fine details of body structure and motion are often lost in their extraction We employed the fol- lowing semi-automatic methods to extract the foreground human figures from the background
First we identify frames wherein the human figure is absent and construct a statistical model of the background The mean and stan- dard deviation at all pixels over all frames (and for every color RGB channel) is computed If a pixel differs too much from the back- ground on any color channel the pixel is treated as a foreground pixel and thus the silhouette is recovered in a pixel-wise manner In case there exists no image with just the background we identify frames that describe motion of figures moving through the scene in a predictable fashion We then compute a median image over the whole sequence followed by building a weighted-meanvariance background model to extract the silhouette out if over time there will more non-motion at apixel than there will be motion 191 0th- envise we select several frames with little overlap of the human figures extract the figures manually and then combine the result- ing images to obtain a composite background image If there exists background ateas that cannot be recovered they are considered as foreground anyway
Once we derive a background model we can subtract the back- ground From all the images in the sequence Often we do not have a perfect background model and therefore the silhouette images may suffer from the presence of noise The silhouette quality can be improved using morphological operations such as dilation and size-based object filtering
42 Core-Weigbted XOR
Our goal is to find the motion parameter set fl that minimizes the total penalty
for a suitable cost function f where SLw and S d e ( 3 ( ) ) are the ifh input silhouette image and a silhouette image generated by M() respectively For the sake of clarity we instead denote S)iiw and Smodel(fl(i)) simply as Sinpur and Smadel respectively
How does one design a viable and robust cost function f as de- scribed in Eq(l) The easiest way to measure the difference of two binary images is the number of on pixels when pixel-wise XOR operation is applied to the two images 1131 In this case
where the double summation iterates over all pixel locations If our goal requires that f = 0 that is if two silhouettes overlap exactly the optimal soIution will be unique in terms of S d e l However if our objective function f cannot be reduced to zero given inherent characreristjcs of the problem it is likely that there are multiple optimal solutions Any preference among those multiple optimal solutions should be incorporated into the cost function
Since limbs are features af particular importance in any articulated figure we do not want to lose track of those features Limbs in a human body are often well characterized by their skeleton or medial axis derived from the silhouette image Therefore whenever ambi- guity occurs it would be better tu choose the direction in parametric shape space such that model-generated silhouette covers the core area of the input silhouette The core area includes the silhouette pixels close to the skeleton This requirement can be incorporated in the cost function by imposing higher penalty if Sdel(fi(i)) does not overlap any region near the core area of the input silhouette $1
rnpur-
Our new cost function replaces c ( i j ) in Eq(2) with
where D(S) is the Euclidean distance transform of binary image S and 3 is the inverse image of S and w is a weighting factor that controls the importance of coverage of core area reIative to the mis- match in the region outside of silhouette area
Note that image d represents a distance map from silhouette contour and can be computed once in a preprocessing step Figure 1 depicts the coremap imaged with w = 50 We call Eq 2 along with Eq 3 core-weighted XOR
3s
Figure 1 (left) An input silhouette image (right) The coremap image used to compute the coreweighted XOR
43 Using Image Features and Physical Constraints
The core-weighted XOR objective function is sufficient in many cases However there are also cases in which it falls short or our performance expectations Simply adjusting the core-weighted XOR parameters is insufficient to increase the generality of this method In particular the problems encountered include ap- pendages are sometimes not extended to completely fill the silhou- ette feet are able ta penetrate the ground plane and joints are aI- lowed to bend backward as well as forward These sub-optimal configurations ax found because they represent local minima of the core-weighted XOR function To remove these spurious local min- ima and improve our performance additional tems are included in the basic objective function
In order to stretch the limbs to cover silhouette edges we augment our objective function with a term that emphasizes matching edges amp(4)
where T is the image after edges have been extracted h m the fore- ground image using a contrast threshold This tenn i s summed over all pixel positions along with the core-weighted XOR function
In addition to the matching edges term semantic features are used for the limbs to fully cover the silhouette We detect the limbs (hands and feet) along the contours of the foreground human body in some frames 1121 Along the contour of the silhouette we cal- culate the curvature of each point on the contour The curvature at those points is compared against a specified threshold and points of high positive curvature are extracted Using an estimate o f the po- sition of hands from several of previous frames unlikely handfoot positions are further eliminated as determined by the human body smctufe
Moreover the outlines of the arms and the V shape between two legs can be detected based on those concave points along edge con- tours the neck and the crotch are usually the concave points along the edge contours and anns begin from the neck and the V shape between the legs is formed by the feet and the crotch However since we are only using a single camera it is hard to distinguish between the left and right limbs Therefore we do not q u i r e the exact matching of the limbs from the model and the silhouettes The handlfaot consmint term only focuses on reducing the distance be- tween the modelrsquos handslfeet and the nearest detected ones
z = -wl J((i - id12 + (jm - (5)
where ( i m j) is the limb position on the articulated model (id j d ) is the detected footlhand position and wi is the weight factor
A r m s and the V shape are treated the same as the edge term which means we try to get a maximum matching between detected armdlegs and those of modelrsquos
where R is the image with armslegs detected This term is summed over all pixel positions along with the core-weighted XOR func- tion We use those two terms to synthesize motions in Figure 8 and Figure 9
It should be noted that sometimes there is no proper candidate (both a hand or a foot) and in those cases we do not require that the handlfoot constraints be satisfied for particular frames Moreover the position of the head can be detected along the contour using the horizontal projection of the silhouette [7] and temporal coherence The head always lies at a local highest position along the silhou- ette outline and near the maximum of horizontal projection of the histogram Similarly a head constraint term can be used in the ob- jective function
Figure 2 Three examples for handsfeet arms legs and head detec- tions along silhouette outlines where head is marked as red body tips are white arms in green and legs in red
To disallow configurations that include ground plane penetration we define a constraint an the limbs of the figure that essentially evaluates to infinity whenever penetration occurs We also define constraints for each joint angle such that C 5 5 C j = 730 and penalize configurations that violate the constraints These con- figuration penalties are added to the objective function These mod- ifications help guide the silhouette-model matching process to a physically meaningful pxameter set with less ambiguity
Despite the application of physical constraints temporal coherence and knowledge of the anatomy the 3D reconstruction is still under- constrained due to self-occlusions and ambiguities
Instead of exploring complex yet not reliable solutions like texture detection we alIow users to specify the keyframes interactively to obtak viable results Similar solutions to this problem are re- ported in [5] Every keyframe has an impact range and for any frame inside this range instead of using the configuration of the last frame as starting body pose one uses the interpolation of the keyframe and the previous frame to start the optimization Enough keyframes can always guarantee a good reconstructionl but speci- fying keyframes is tedious Our suggestion is the foIlowing When body features like feet and bands are not discemable for several consecutive frames during the pre-processing stage it is because occlusions or ambiguities occur Users should add two keyframes one before the occlusions happen and one after the occlusions dis- appear Users do not necessarily specieuroy all the 30 pimrdquoers they specify a subset ofthe parameters usually those describing position
39
of the limba or the twisted torso Figure 3 shows a sequence that requires keyframing to be reconstructed correctly
Figure 3 Keyframes are necessarily to reconstruct this sequence con- taining ambiguities and self-occlusions Figure 10 shows an example where this keyframe technique is employed We specify the left and right pose as the keyframe poses
44 Biased Downhill Simplex Method
Extracting pose from a silhouetre can produce multiple candidate solutions The high dimensionality of the articulated model para- meter space requires efficient local and global search algorithms We chose local algorithms given their loweroost A suitable initial- ization of model parameters is also required by many algorithms for motion tracking Constraints like joint angle limits on parameters can be used The movement of the subject can be restricted at the cost of losing generality For example movement symmetric (but out of phase) to the central sagittal plane is often assumed
The object function disallows the computation of analytic deriva- tives in terms of motion parameters Downhill simplex method [17] serves very well to minimize the proposed cost function since it re- quires function evaluation for specific multi-dimensional optimiza- tion parameters
The simplex method can be easily adapted to our multi-dimensional human body model The initial simplex of R dimensions consists of n + 1 vertices Though we use this method for alignment and shape fitting we explain itrsquos workings by only describing reconstruction of the motion Let the coefficients ~ ( i ) = f ~ ~ - rsquo ) pn i i p l ) ) (the solution of the previous frame) be one of the initial points po of the simplex We can choose the other remaining n points to be
p=m+pie i = 1 q
where ejrsquos are n unit vectors and pi are defined by the character- istic length scale of each component of p The movement of this n-dimensional simplex is confined to be within the motion space close enough to the configuration of the current frame and there is no need to perfom exhaustive searches beyond certain ranges of movement between two consecutive frames To further target the most relevant parameter space to search parameter velocity is used to bias the simplex location This bias and the size of the simplex are determined by limits on parmetric acceleration that arise from principles of physics and basic anatomy
Due 10 the inherent hierarchical properties of the human model a hierarchical optimization algorithm is employed The complete 30 configuration parameters are divided into 6 sub-groups as dictated by anatomical considerations Starting from the configuration of the pervious frame the modelrsquos global translation and rotation k s - formations are first computed using the downhill simplex method
Then the torso is appropriately rotated to minimize the error The arm and leg positions are computed last one by one
To avoid accumulative errors another simple technique that is often beneficial is to restart the optimization routine from the solution found in the current optimization stage ln the following section we explore how these strategies are exploited towards finding the correct motion configuration from silhouette image sequences
5 IMPLEMENTATION
Our reconstruction method depends on an optimization process ex- ecuted in a motion parameter space Toward this purpose we first perfom a shape fitting exercise for the very first frame so that our model fully explains the silhouette area fram a specific view The resulting shape parameters are then fixed for the remainder of the motion tracking process It should be noted that we use the same objective function for initial alignment shape fitting and motion tracking
51 Automatic Initialization
As mentioned before the only input we exploiit to reconstruct the 3D motion parameters are silhouette images extracted from a video sequence We use the area-based metric to compute the likelihood of our model for a given input silhouette image Therefore the projected shape of a 3D model needs to be as close as possible to the input silhouette A suitable frame with no self-occlusjons is used to adapt the shape of our model to the actor being observed The optimization procedure is employed for this frame in order to fix the modelrsquos shape parameters and initial the pose of the model Lacking a suitable frame the shape parameters and initial pose of the model can be initially seamp by hand
The optimization parameters we determine in the jnitialhation stage is a subset of the parameter set a Up Let a translation vec-
subset of motion parameters that define the rotation angles around z-axis of upper arms and upper legs respectively We divide the ini- tialization task into two consecutive optimization steps
( 1 ) ( 1 ) U ) ( 1 ) 11) tor r = PI 1 Pz 1 1 and let s = A Pt2 P[res7 ampI be a
1 Alignment find r and 5 such that Eq 1 is minimized
2 Shape adjustment find a and s so that m I is minimized
The middle and right image in Figure 4 depict the result for the two steps described above Note that our coreweighted XOR metric is helpful to align the shape of the initial model at the center of the silhouette image If the initial model was not aligned at the center of the silhouette the subsequent shape fitting process would have failed
given the optimal t 3) found at step 1
52 Motion Tracking
After the initialization described in the previous section acrual mo-
such that it minimizes the objective function as described in Sec-
tion 4 for each frame i The optimal parameter vector pi found at frame i is used as the initial guess for the optimization routine of frame i + 1
To reconstruct only physically meaningful joint angles we assign a constraint for each joint angle as well as the degree of freedom
tion tracking is performed by searching a motion configuration p (i)
(
40
I 50 l a 150 2m ZKI
Figure 4 Automatic initialization step (left) Initial status (middle) Fnrr-ber
After alignment (right) After shape fitting and ready for motion fitting Figure 5 Effectiveness of simple repetition of the same optimization
process
~3 otherwise
where c e 1 and a1 are given by Eq 3 Q 4 Eq 5 and Eq 6 Ck and ($ are the lower and upper bound of a joint angle p k respec- tively Assigning constraints for each joint angle is very beneficial in removing the ambiguity when deciding the next step in searching downhill direction
In using the downhill simplex method restarting the minimization routine always helps to escape the shallow local minima that are proximal to deeper local minima Figure 5 shows how effective this simple repetition is The example sequence consists of four main actions of a total of 250 frames The frame range (0100) depicts the bending of the left arm range (JOO 150) shows the bending of the right arm range (t50200) shows the bending of the left leg and finally the frame range (200250) depicts the same actor bend- ing his right leg The results using no repetition and 2-times rep- etition show relatively high cost values Incorrect results are also obtained Two such incorrect results from the two tracking exper- iment at a specific frame (224) are shown in Figure Tracking with 3-times repetition showed visually correct results for all four action sequences In this case the area with high cost in Figure is mainly caused by the deformation of the shape of the subject We note this by displaying the two frames with corresponding peaks in the graph The sources of error are marked illustratively in Figure 7 The region A D and E is from the deformation of the clothes The region B is caused by the expanded silhouette due to the motion blur effect and C is a region with the inherent difference between model and real silhouette m a
53 Motion Refinement
The final tracking result cannot be perfect because the shape of the articulated model does not match the actor in the video exactly there are occlusions and ambiguities there are many more DOFs for each arliculated joint However our system generates reason- ably good motion data and aIlows the users to refine the generated motion in the post-processing stage The user can also add new constraints to reduce the search space for particular parameters to
Figure 6 First input image Second a correct result (with cost value 1231) Third and forth image shows the 2 incorrect results (with cost value 2167 and 2130 respectively)
get better tracking results In addition given our motion data user can modify the motion with any 3D character animation tool like Poser from Curious Lab
6 RESULTS
We illustrate our method using several full body tracking se- quences AI1 the video clips are sampled at the rate of 30Hz and some of them are from CMU Graphics Lab Motion Capture Data- base [e] Despite that we are using only one camera and do not em- ploy any marker we still obtain desirable results Figure 8 Figure 9 and Figure 10 are examples of tracking artists and athletes The first dance sequence (Figure 8) is relatively straightforward to track be- cause there are no occlusions and motion is mainly planar Our tracker manages to track the fmnto parallel motions The second badminton sequence (Figure 9) is more complex because of multi- ple occlusions occurring during the action However we can recon- struct the motion when we assume that both legs move with con- stant velocity In addition we capture the in-depth (out-of-plane) motions of the player successfully The previous sequences could all be tracked without user intervention The last sequence (Fig- ure IO) contains many more challenges given the complex torso ro- tations and arm swings After introducing keyframing our tracker estimates the uncertain positions of arms and torso and recov- ers the motions of the arms even though they are totally occtuded in the silhouettes For this sequence six keyframes were used More reconstruction results can be found at httpwwwcseohio- stateedukhenyisresearchmotionindexhtm
The time expended for analysis is about 3 sec per frame for sim- ple sequences and about 5 sec per frame for difficult ones when executed on a Pentium Iv PC with a 2 GHz CPU and 512MB of memory It should be noted that 131 reported times of 7 to 12 sec per
41
REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43

We describe herein a method to reconstruct arbitraq motion se- quences a at is model-based operates on images and exploits knowledge about the anatomy Consequently our method is simple efficient and requires limited manual intervention Will aur method reconstruct all motion sequences successfully The answer i s no Occlusion of limbs by larger parts of the anatomy cannot always be resolved through the use of image siIhouettes On the other hand we wish to explore the limits of efficient monocular motion recon- struction Our results show that we can reconstruct increasingly complex motion when we include a larger set of anatomical fea- tures and CQnSk3htS and employ robust image comparison metrics We now provide an overview of ow approach
12 Overview of Our Approach
In this paper we explore inverse methods which reconstruct motion from a single camera We examine techniques which use silhouettes and edges rather than texture Since motion is our primary interest and not identification silhouettes and edges provide ample grounds for developing robust methods hverse design methods like ours employ optimization algorithms to minimize an objective function
Resolving occlusion berween various parts of the human body is certainly an ominous challenge given the difficulty of matching an imperfect highly flexible self-occluding model to cluttered image features Viable human models have at least 20 joint parametea subject to highly nonlinear physical constraints Also a significant number of the possible degrees of freedom afforded by the vari- ous joints are not uniquely determined by any given image Thus monocular motion capture is ill-posed and non-linear Methods re- ported in the literature are either complex and expensive for com- puter graphics applications or impose severe restrictions on the type of motion that can be captured
The work described herein is an expIoration of simple yet robust cost functions and incremental search strategies Our focus on sim- pler cost functions will eventually allow for tlle realization of near real-time reconstruction often needed for computer graphics appli- cations while at the same time making few assumptions about the motion being tracked
The starling point of our method is a model of a human actm with multiple quadrics assembled at various joints After an initial pose is established either automatically or with the aid of the user a frame-to-frame tracking procedure ensues in which the solution of the last frame is the initial guess for the next frame In addition to silhouettes and edges our objective function uses anatomical and physical constraints to aid in disambiguating the view
The main contributions of our work include
development of a new core-weighted XOR metric for model localization in an image
robust detection and tracking of body parts such as head arms feet and the V between the legs in the image
inclusion of image features and anatomical constraints to re- duce the size of optimal search space
Our new method is shown to be capable of reconstructing full a- ticulated body motion efficiently AdditionaIly our results include video sequences of varying length and arbitrary iIlumination and the reconsuuction is quite faithful to the original sequence
The paper is organized as follows In Section 2 we describe perti- nent previous work in motion reconstruction Our human model is briefly discussed in Section 3 We describe in detail our method For motion recansbmction in Section 4 Implementation considerations
are given in Section 5 Section 6 includes results which demon- strate the effectiveness of our technique Concluding remarks and pointers to future work are described in Section 7
2 PREVIOUS WORK
We describe work that is closely related to our own Model based approaches use a 3D articulated model of the human body to esti- mate the pose and shape such that the modelrsquos 2D projection closely fits the captured person in the image Bregler and Malik [2] propose a framework to estimate 3D poses of each body segment in a kine- matic chain using twist representation of a general rigid-body mo- tion However their reconstruction assumes lateral symmetry in the tracked motion Pavlovic et al[16] present asystem to track fronta- parallel motion using a dynamic Bayesian nerwork approach Their work focuses on the dynamics of human behavior as described by bio-mechanical models
Deutscher et al 141 use a human model to build a framework of a kinematic chain using limbs of conical sections for computational simplicity and high-level interpretation of output They use edges and silhouettes for their cost function to estimate pose from multi- ple camera views A condensation algorithm is employed to search the high dimensional space without restrictions Cmanza er a1 [3] use silhouettes from multi-view synchronized video footage to re- construct the motion of a 3D human body model and then re-render the modelrsquos appearance and motion interactively from any novel view point Kakadiaris et al [IO] use a spatio-temporal analysis to track upper body motions from multiple cameras
Monocular markerless motion capture bas been studied by a few re- searchers Sminchisescu and Triggs [20] achieve successful motion synthesis based on the propagation of a mixture of Gaussian den- sity functions each representing probable 3D configurations of the human body over rime Difranco et al [5] pmpose a batch frame- work to reconstruct poses from a single view point based on 2D correspondences subject to a number of constraints Their methods are shown to be successful when deployed on moderately difficult sequences that include athletic and dance movements
Alternative approaches to model based tracking of human bodies have been also used Bobick and Davis [ I ] construct temporal tem- plates from a sequence of silhouette images and present a method to match the temporal template against stored views of the known actions Wren et a1 [22] use 2D blobs for tracking motion in a video image Leventon and Freeman [I41 take a statistical approach and used a set of motion examples to build a probability model for the purpose of recovering 3D joint angles for a new input sequence
Lee et a1 [I 1 1 present a vision-based interface to control avatars in virtual environments They extract visual features from the input silhouette images and search for the best motion matching the vi- sual euroeatures obtained from rendered versions of actions in a motion database Ren et a1 1181 use the AdampiBoost algorithm to select a Few best local features from silhouette images to estimate yaw and body configurations Finaliy a suwey of computer vision-based human motion caprure techniques is presented by Moeslund and Granum ~ 5 1
We reconstmct general 3D motion from the silhouettes extracted from a single view without relying on a motion database As a consequence our work is closest to that of Sminchisescu However we demonstrate the tracking of motions that are more complex than those presented by Sminchisescu and we track at speeds that are equal or faster than those reported
37
3 OUR HUMAN MODEL
Our human model is a combination of spheres and cylinders with anisotropic scale and rigid transformation for an object coordinate system for each part The model is shown in Figure 8 and Figure 9 The parameters that describe our human model consist of two com- ponents - shape and motion parameters We define twelve shape parameters which describe the scale factors to be multiplied to a predefined standard size of each body part Motion parameters are composed of 6 global transformation and total 24 joint angles Each joint has anywhere from one to three degrees-of-freedom Given N frames h m a videa sequence our human body model at a specific frame i is represented by M1) = M ( E ~ P ( ~ ) ) where a = (nl a2 4 r crpn (m = 12) is the shape parameter vector and p() = pL p2 pn 1 (n = 30) is the motion parmeter vector (i) (4 ( i )
4 THE OPTIMIZATION STRATEGY
The use of a single view makes the reconstwction problem ill- posed as stated earlier We now describe our optimization strat- egy to fit the motion parameters to a single stream of silhouette images First we describe how we extract silhouettes from a video sequence Then we present an objective function based on the dif- ference of area between model-generated silhouette and input sil- houette Next we discuss how we improve the performance of our optimization algorithm We achieve this by incorporating edge in- formation along with both physical and anatomical constraints into the objective function FinalIy we discuss a non-linear multidimen- sional optimization algorithm we employ to minimize the proposed objective function
41 Silhouette Extraction
The input to our motion synthesis system is a sequence of silhouette images that describe the g m s s motion of the human body We avoid using coloration or texture information in order to minimize the eeuro- fects of variable viewing conditions In addition to using silhou- ettes we also employ high-contrast edges to further our optimiza- tion strategy as explained below Given a video footage there exist several methods to obtain siIhouette images Although silhouettes are less sensitive to noise than edges fine details of body structure and motion are often lost in their extraction We employed the fol- lowing semi-automatic methods to extract the foreground human figures from the background
First we identify frames wherein the human figure is absent and construct a statistical model of the background The mean and stan- dard deviation at all pixels over all frames (and for every color RGB channel) is computed If a pixel differs too much from the back- ground on any color channel the pixel is treated as a foreground pixel and thus the silhouette is recovered in a pixel-wise manner In case there exists no image with just the background we identify frames that describe motion of figures moving through the scene in a predictable fashion We then compute a median image over the whole sequence followed by building a weighted-meanvariance background model to extract the silhouette out if over time there will more non-motion at apixel than there will be motion 191 0th- envise we select several frames with little overlap of the human figures extract the figures manually and then combine the result- ing images to obtain a composite background image If there exists background ateas that cannot be recovered they are considered as foreground anyway
Once we derive a background model we can subtract the back- ground From all the images in the sequence Often we do not have a perfect background model and therefore the silhouette images may suffer from the presence of noise The silhouette quality can be improved using morphological operations such as dilation and size-based object filtering
42 Core-Weigbted XOR
Our goal is to find the motion parameter set fl that minimizes the total penalty
for a suitable cost function f where SLw and S d e ( 3 ( ) ) are the ifh input silhouette image and a silhouette image generated by M() respectively For the sake of clarity we instead denote S)iiw and Smodel(fl(i)) simply as Sinpur and Smadel respectively
How does one design a viable and robust cost function f as de- scribed in Eq(l) The easiest way to measure the difference of two binary images is the number of on pixels when pixel-wise XOR operation is applied to the two images 1131 In this case
where the double summation iterates over all pixel locations If our goal requires that f = 0 that is if two silhouettes overlap exactly the optimal soIution will be unique in terms of S d e l However if our objective function f cannot be reduced to zero given inherent characreristjcs of the problem it is likely that there are multiple optimal solutions Any preference among those multiple optimal solutions should be incorporated into the cost function
Since limbs are features af particular importance in any articulated figure we do not want to lose track of those features Limbs in a human body are often well characterized by their skeleton or medial axis derived from the silhouette image Therefore whenever ambi- guity occurs it would be better tu choose the direction in parametric shape space such that model-generated silhouette covers the core area of the input silhouette The core area includes the silhouette pixels close to the skeleton This requirement can be incorporated in the cost function by imposing higher penalty if Sdel(fi(i)) does not overlap any region near the core area of the input silhouette $1
rnpur-
Our new cost function replaces c ( i j ) in Eq(2) with
where D(S) is the Euclidean distance transform of binary image S and 3 is the inverse image of S and w is a weighting factor that controls the importance of coverage of core area reIative to the mis- match in the region outside of silhouette area
Note that image d represents a distance map from silhouette contour and can be computed once in a preprocessing step Figure 1 depicts the coremap imaged with w = 50 We call Eq 2 along with Eq 3 core-weighted XOR
3s
Figure 1 (left) An input silhouette image (right) The coremap image used to compute the coreweighted XOR
43 Using Image Features and Physical Constraints
The core-weighted XOR objective function is sufficient in many cases However there are also cases in which it falls short or our performance expectations Simply adjusting the core-weighted XOR parameters is insufficient to increase the generality of this method In particular the problems encountered include ap- pendages are sometimes not extended to completely fill the silhou- ette feet are able ta penetrate the ground plane and joints are aI- lowed to bend backward as well as forward These sub-optimal configurations ax found because they represent local minima of the core-weighted XOR function To remove these spurious local min- ima and improve our performance additional tems are included in the basic objective function
In order to stretch the limbs to cover silhouette edges we augment our objective function with a term that emphasizes matching edges amp(4)
where T is the image after edges have been extracted h m the fore- ground image using a contrast threshold This tenn i s summed over all pixel positions along with the core-weighted XOR function
In addition to the matching edges term semantic features are used for the limbs to fully cover the silhouette We detect the limbs (hands and feet) along the contours of the foreground human body in some frames 1121 Along the contour of the silhouette we cal- culate the curvature of each point on the contour The curvature at those points is compared against a specified threshold and points of high positive curvature are extracted Using an estimate o f the po- sition of hands from several of previous frames unlikely handfoot positions are further eliminated as determined by the human body smctufe
Moreover the outlines of the arms and the V shape between two legs can be detected based on those concave points along edge con- tours the neck and the crotch are usually the concave points along the edge contours and anns begin from the neck and the V shape between the legs is formed by the feet and the crotch However since we are only using a single camera it is hard to distinguish between the left and right limbs Therefore we do not q u i r e the exact matching of the limbs from the model and the silhouettes The handlfaot consmint term only focuses on reducing the distance be- tween the modelrsquos handslfeet and the nearest detected ones
z = -wl J((i - id12 + (jm - (5)
where ( i m j) is the limb position on the articulated model (id j d ) is the detected footlhand position and wi is the weight factor
A r m s and the V shape are treated the same as the edge term which means we try to get a maximum matching between detected armdlegs and those of modelrsquos
where R is the image with armslegs detected This term is summed over all pixel positions along with the core-weighted XOR func- tion We use those two terms to synthesize motions in Figure 8 and Figure 9
It should be noted that sometimes there is no proper candidate (both a hand or a foot) and in those cases we do not require that the handlfoot constraints be satisfied for particular frames Moreover the position of the head can be detected along the contour using the horizontal projection of the silhouette [7] and temporal coherence The head always lies at a local highest position along the silhou- ette outline and near the maximum of horizontal projection of the histogram Similarly a head constraint term can be used in the ob- jective function
Figure 2 Three examples for handsfeet arms legs and head detec- tions along silhouette outlines where head is marked as red body tips are white arms in green and legs in red
To disallow configurations that include ground plane penetration we define a constraint an the limbs of the figure that essentially evaluates to infinity whenever penetration occurs We also define constraints for each joint angle such that C 5 5 C j = 730 and penalize configurations that violate the constraints These con- figuration penalties are added to the objective function These mod- ifications help guide the silhouette-model matching process to a physically meaningful pxameter set with less ambiguity
Despite the application of physical constraints temporal coherence and knowledge of the anatomy the 3D reconstruction is still under- constrained due to self-occlusions and ambiguities
Instead of exploring complex yet not reliable solutions like texture detection we alIow users to specify the keyframes interactively to obtak viable results Similar solutions to this problem are re- ported in [5] Every keyframe has an impact range and for any frame inside this range instead of using the configuration of the last frame as starting body pose one uses the interpolation of the keyframe and the previous frame to start the optimization Enough keyframes can always guarantee a good reconstructionl but speci- fying keyframes is tedious Our suggestion is the foIlowing When body features like feet and bands are not discemable for several consecutive frames during the pre-processing stage it is because occlusions or ambiguities occur Users should add two keyframes one before the occlusions happen and one after the occlusions dis- appear Users do not necessarily specieuroy all the 30 pimrdquoers they specify a subset ofthe parameters usually those describing position
39
of the limba or the twisted torso Figure 3 shows a sequence that requires keyframing to be reconstructed correctly
Figure 3 Keyframes are necessarily to reconstruct this sequence con- taining ambiguities and self-occlusions Figure 10 shows an example where this keyframe technique is employed We specify the left and right pose as the keyframe poses
44 Biased Downhill Simplex Method
Extracting pose from a silhouetre can produce multiple candidate solutions The high dimensionality of the articulated model para- meter space requires efficient local and global search algorithms We chose local algorithms given their loweroost A suitable initial- ization of model parameters is also required by many algorithms for motion tracking Constraints like joint angle limits on parameters can be used The movement of the subject can be restricted at the cost of losing generality For example movement symmetric (but out of phase) to the central sagittal plane is often assumed
The object function disallows the computation of analytic deriva- tives in terms of motion parameters Downhill simplex method [17] serves very well to minimize the proposed cost function since it re- quires function evaluation for specific multi-dimensional optimiza- tion parameters
The simplex method can be easily adapted to our multi-dimensional human body model The initial simplex of R dimensions consists of n + 1 vertices Though we use this method for alignment and shape fitting we explain itrsquos workings by only describing reconstruction of the motion Let the coefficients ~ ( i ) = f ~ ~ - rsquo ) pn i i p l ) ) (the solution of the previous frame) be one of the initial points po of the simplex We can choose the other remaining n points to be
p=m+pie i = 1 q
where ejrsquos are n unit vectors and pi are defined by the character- istic length scale of each component of p The movement of this n-dimensional simplex is confined to be within the motion space close enough to the configuration of the current frame and there is no need to perfom exhaustive searches beyond certain ranges of movement between two consecutive frames To further target the most relevant parameter space to search parameter velocity is used to bias the simplex location This bias and the size of the simplex are determined by limits on parmetric acceleration that arise from principles of physics and basic anatomy
Due 10 the inherent hierarchical properties of the human model a hierarchical optimization algorithm is employed The complete 30 configuration parameters are divided into 6 sub-groups as dictated by anatomical considerations Starting from the configuration of the pervious frame the modelrsquos global translation and rotation k s - formations are first computed using the downhill simplex method
Then the torso is appropriately rotated to minimize the error The arm and leg positions are computed last one by one
To avoid accumulative errors another simple technique that is often beneficial is to restart the optimization routine from the solution found in the current optimization stage ln the following section we explore how these strategies are exploited towards finding the correct motion configuration from silhouette image sequences
5 IMPLEMENTATION
Our reconstruction method depends on an optimization process ex- ecuted in a motion parameter space Toward this purpose we first perfom a shape fitting exercise for the very first frame so that our model fully explains the silhouette area fram a specific view The resulting shape parameters are then fixed for the remainder of the motion tracking process It should be noted that we use the same objective function for initial alignment shape fitting and motion tracking
51 Automatic Initialization
As mentioned before the only input we exploiit to reconstruct the 3D motion parameters are silhouette images extracted from a video sequence We use the area-based metric to compute the likelihood of our model for a given input silhouette image Therefore the projected shape of a 3D model needs to be as close as possible to the input silhouette A suitable frame with no self-occlusjons is used to adapt the shape of our model to the actor being observed The optimization procedure is employed for this frame in order to fix the modelrsquos shape parameters and initial the pose of the model Lacking a suitable frame the shape parameters and initial pose of the model can be initially seamp by hand
The optimization parameters we determine in the jnitialhation stage is a subset of the parameter set a Up Let a translation vec-
subset of motion parameters that define the rotation angles around z-axis of upper arms and upper legs respectively We divide the ini- tialization task into two consecutive optimization steps
( 1 ) ( 1 ) U ) ( 1 ) 11) tor r = PI 1 Pz 1 1 and let s = A Pt2 P[res7 ampI be a
1 Alignment find r and 5 such that Eq 1 is minimized
2 Shape adjustment find a and s so that m I is minimized
The middle and right image in Figure 4 depict the result for the two steps described above Note that our coreweighted XOR metric is helpful to align the shape of the initial model at the center of the silhouette image If the initial model was not aligned at the center of the silhouette the subsequent shape fitting process would have failed
given the optimal t 3) found at step 1
52 Motion Tracking
After the initialization described in the previous section acrual mo-
such that it minimizes the objective function as described in Sec-
tion 4 for each frame i The optimal parameter vector pi found at frame i is used as the initial guess for the optimization routine of frame i + 1
To reconstruct only physically meaningful joint angles we assign a constraint for each joint angle as well as the degree of freedom
tion tracking is performed by searching a motion configuration p (i)
(
40
I 50 l a 150 2m ZKI
Figure 4 Automatic initialization step (left) Initial status (middle) Fnrr-ber
After alignment (right) After shape fitting and ready for motion fitting Figure 5 Effectiveness of simple repetition of the same optimization
process
~3 otherwise
where c e 1 and a1 are given by Eq 3 Q 4 Eq 5 and Eq 6 Ck and ($ are the lower and upper bound of a joint angle p k respec- tively Assigning constraints for each joint angle is very beneficial in removing the ambiguity when deciding the next step in searching downhill direction
In using the downhill simplex method restarting the minimization routine always helps to escape the shallow local minima that are proximal to deeper local minima Figure 5 shows how effective this simple repetition is The example sequence consists of four main actions of a total of 250 frames The frame range (0100) depicts the bending of the left arm range (JOO 150) shows the bending of the right arm range (t50200) shows the bending of the left leg and finally the frame range (200250) depicts the same actor bend- ing his right leg The results using no repetition and 2-times rep- etition show relatively high cost values Incorrect results are also obtained Two such incorrect results from the two tracking exper- iment at a specific frame (224) are shown in Figure Tracking with 3-times repetition showed visually correct results for all four action sequences In this case the area with high cost in Figure is mainly caused by the deformation of the shape of the subject We note this by displaying the two frames with corresponding peaks in the graph The sources of error are marked illustratively in Figure 7 The region A D and E is from the deformation of the clothes The region B is caused by the expanded silhouette due to the motion blur effect and C is a region with the inherent difference between model and real silhouette m a
53 Motion Refinement
The final tracking result cannot be perfect because the shape of the articulated model does not match the actor in the video exactly there are occlusions and ambiguities there are many more DOFs for each arliculated joint However our system generates reason- ably good motion data and aIlows the users to refine the generated motion in the post-processing stage The user can also add new constraints to reduce the search space for particular parameters to
Figure 6 First input image Second a correct result (with cost value 1231) Third and forth image shows the 2 incorrect results (with cost value 2167 and 2130 respectively)
get better tracking results In addition given our motion data user can modify the motion with any 3D character animation tool like Poser from Curious Lab
6 RESULTS
We illustrate our method using several full body tracking se- quences AI1 the video clips are sampled at the rate of 30Hz and some of them are from CMU Graphics Lab Motion Capture Data- base [e] Despite that we are using only one camera and do not em- ploy any marker we still obtain desirable results Figure 8 Figure 9 and Figure 10 are examples of tracking artists and athletes The first dance sequence (Figure 8) is relatively straightforward to track be- cause there are no occlusions and motion is mainly planar Our tracker manages to track the fmnto parallel motions The second badminton sequence (Figure 9) is more complex because of multi- ple occlusions occurring during the action However we can recon- struct the motion when we assume that both legs move with con- stant velocity In addition we capture the in-depth (out-of-plane) motions of the player successfully The previous sequences could all be tracked without user intervention The last sequence (Fig- ure IO) contains many more challenges given the complex torso ro- tations and arm swings After introducing keyframing our tracker estimates the uncertain positions of arms and torso and recov- ers the motions of the arms even though they are totally occtuded in the silhouettes For this sequence six keyframes were used More reconstruction results can be found at httpwwwcseohio- stateedukhenyisresearchmotionindexhtm
The time expended for analysis is about 3 sec per frame for sim- ple sequences and about 5 sec per frame for difficult ones when executed on a Pentium Iv PC with a 2 GHz CPU and 512MB of memory It should be noted that 131 reported times of 7 to 12 sec per
41
REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43

3 OUR HUMAN MODEL
Our human model is a combination of spheres and cylinders with anisotropic scale and rigid transformation for an object coordinate system for each part The model is shown in Figure 8 and Figure 9 The parameters that describe our human model consist of two com- ponents - shape and motion parameters We define twelve shape parameters which describe the scale factors to be multiplied to a predefined standard size of each body part Motion parameters are composed of 6 global transformation and total 24 joint angles Each joint has anywhere from one to three degrees-of-freedom Given N frames h m a videa sequence our human body model at a specific frame i is represented by M1) = M ( E ~ P ( ~ ) ) where a = (nl a2 4 r crpn (m = 12) is the shape parameter vector and p() = pL p2 pn 1 (n = 30) is the motion parmeter vector (i) (4 ( i )
4 THE OPTIMIZATION STRATEGY
The use of a single view makes the reconstwction problem ill- posed as stated earlier We now describe our optimization strat- egy to fit the motion parameters to a single stream of silhouette images First we describe how we extract silhouettes from a video sequence Then we present an objective function based on the dif- ference of area between model-generated silhouette and input sil- houette Next we discuss how we improve the performance of our optimization algorithm We achieve this by incorporating edge in- formation along with both physical and anatomical constraints into the objective function FinalIy we discuss a non-linear multidimen- sional optimization algorithm we employ to minimize the proposed objective function
41 Silhouette Extraction
The input to our motion synthesis system is a sequence of silhouette images that describe the g m s s motion of the human body We avoid using coloration or texture information in order to minimize the eeuro- fects of variable viewing conditions In addition to using silhou- ettes we also employ high-contrast edges to further our optimiza- tion strategy as explained below Given a video footage there exist several methods to obtain siIhouette images Although silhouettes are less sensitive to noise than edges fine details of body structure and motion are often lost in their extraction We employed the fol- lowing semi-automatic methods to extract the foreground human figures from the background
First we identify frames wherein the human figure is absent and construct a statistical model of the background The mean and stan- dard deviation at all pixels over all frames (and for every color RGB channel) is computed If a pixel differs too much from the back- ground on any color channel the pixel is treated as a foreground pixel and thus the silhouette is recovered in a pixel-wise manner In case there exists no image with just the background we identify frames that describe motion of figures moving through the scene in a predictable fashion We then compute a median image over the whole sequence followed by building a weighted-meanvariance background model to extract the silhouette out if over time there will more non-motion at apixel than there will be motion 191 0th- envise we select several frames with little overlap of the human figures extract the figures manually and then combine the result- ing images to obtain a composite background image If there exists background ateas that cannot be recovered they are considered as foreground anyway
Once we derive a background model we can subtract the back- ground From all the images in the sequence Often we do not have a perfect background model and therefore the silhouette images may suffer from the presence of noise The silhouette quality can be improved using morphological operations such as dilation and size-based object filtering
42 Core-Weigbted XOR
Our goal is to find the motion parameter set fl that minimizes the total penalty
for a suitable cost function f where SLw and S d e ( 3 ( ) ) are the ifh input silhouette image and a silhouette image generated by M() respectively For the sake of clarity we instead denote S)iiw and Smodel(fl(i)) simply as Sinpur and Smadel respectively
How does one design a viable and robust cost function f as de- scribed in Eq(l) The easiest way to measure the difference of two binary images is the number of on pixels when pixel-wise XOR operation is applied to the two images 1131 In this case
where the double summation iterates over all pixel locations If our goal requires that f = 0 that is if two silhouettes overlap exactly the optimal soIution will be unique in terms of S d e l However if our objective function f cannot be reduced to zero given inherent characreristjcs of the problem it is likely that there are multiple optimal solutions Any preference among those multiple optimal solutions should be incorporated into the cost function
Since limbs are features af particular importance in any articulated figure we do not want to lose track of those features Limbs in a human body are often well characterized by their skeleton or medial axis derived from the silhouette image Therefore whenever ambi- guity occurs it would be better tu choose the direction in parametric shape space such that model-generated silhouette covers the core area of the input silhouette The core area includes the silhouette pixels close to the skeleton This requirement can be incorporated in the cost function by imposing higher penalty if Sdel(fi(i)) does not overlap any region near the core area of the input silhouette $1
rnpur-
Our new cost function replaces c ( i j ) in Eq(2) with
where D(S) is the Euclidean distance transform of binary image S and 3 is the inverse image of S and w is a weighting factor that controls the importance of coverage of core area reIative to the mis- match in the region outside of silhouette area
Note that image d represents a distance map from silhouette contour and can be computed once in a preprocessing step Figure 1 depicts the coremap imaged with w = 50 We call Eq 2 along with Eq 3 core-weighted XOR
3s
Figure 1 (left) An input silhouette image (right) The coremap image used to compute the coreweighted XOR
43 Using Image Features and Physical Constraints
The core-weighted XOR objective function is sufficient in many cases However there are also cases in which it falls short or our performance expectations Simply adjusting the core-weighted XOR parameters is insufficient to increase the generality of this method In particular the problems encountered include ap- pendages are sometimes not extended to completely fill the silhou- ette feet are able ta penetrate the ground plane and joints are aI- lowed to bend backward as well as forward These sub-optimal configurations ax found because they represent local minima of the core-weighted XOR function To remove these spurious local min- ima and improve our performance additional tems are included in the basic objective function
In order to stretch the limbs to cover silhouette edges we augment our objective function with a term that emphasizes matching edges amp(4)
where T is the image after edges have been extracted h m the fore- ground image using a contrast threshold This tenn i s summed over all pixel positions along with the core-weighted XOR function
In addition to the matching edges term semantic features are used for the limbs to fully cover the silhouette We detect the limbs (hands and feet) along the contours of the foreground human body in some frames 1121 Along the contour of the silhouette we cal- culate the curvature of each point on the contour The curvature at those points is compared against a specified threshold and points of high positive curvature are extracted Using an estimate o f the po- sition of hands from several of previous frames unlikely handfoot positions are further eliminated as determined by the human body smctufe
Moreover the outlines of the arms and the V shape between two legs can be detected based on those concave points along edge con- tours the neck and the crotch are usually the concave points along the edge contours and anns begin from the neck and the V shape between the legs is formed by the feet and the crotch However since we are only using a single camera it is hard to distinguish between the left and right limbs Therefore we do not q u i r e the exact matching of the limbs from the model and the silhouettes The handlfaot consmint term only focuses on reducing the distance be- tween the modelrsquos handslfeet and the nearest detected ones
z = -wl J((i - id12 + (jm - (5)
where ( i m j) is the limb position on the articulated model (id j d ) is the detected footlhand position and wi is the weight factor
A r m s and the V shape are treated the same as the edge term which means we try to get a maximum matching between detected armdlegs and those of modelrsquos
where R is the image with armslegs detected This term is summed over all pixel positions along with the core-weighted XOR func- tion We use those two terms to synthesize motions in Figure 8 and Figure 9
It should be noted that sometimes there is no proper candidate (both a hand or a foot) and in those cases we do not require that the handlfoot constraints be satisfied for particular frames Moreover the position of the head can be detected along the contour using the horizontal projection of the silhouette [7] and temporal coherence The head always lies at a local highest position along the silhou- ette outline and near the maximum of horizontal projection of the histogram Similarly a head constraint term can be used in the ob- jective function
Figure 2 Three examples for handsfeet arms legs and head detec- tions along silhouette outlines where head is marked as red body tips are white arms in green and legs in red
To disallow configurations that include ground plane penetration we define a constraint an the limbs of the figure that essentially evaluates to infinity whenever penetration occurs We also define constraints for each joint angle such that C 5 5 C j = 730 and penalize configurations that violate the constraints These con- figuration penalties are added to the objective function These mod- ifications help guide the silhouette-model matching process to a physically meaningful pxameter set with less ambiguity
Despite the application of physical constraints temporal coherence and knowledge of the anatomy the 3D reconstruction is still under- constrained due to self-occlusions and ambiguities
Instead of exploring complex yet not reliable solutions like texture detection we alIow users to specify the keyframes interactively to obtak viable results Similar solutions to this problem are re- ported in [5] Every keyframe has an impact range and for any frame inside this range instead of using the configuration of the last frame as starting body pose one uses the interpolation of the keyframe and the previous frame to start the optimization Enough keyframes can always guarantee a good reconstructionl but speci- fying keyframes is tedious Our suggestion is the foIlowing When body features like feet and bands are not discemable for several consecutive frames during the pre-processing stage it is because occlusions or ambiguities occur Users should add two keyframes one before the occlusions happen and one after the occlusions dis- appear Users do not necessarily specieuroy all the 30 pimrdquoers they specify a subset ofthe parameters usually those describing position
39
of the limba or the twisted torso Figure 3 shows a sequence that requires keyframing to be reconstructed correctly
Figure 3 Keyframes are necessarily to reconstruct this sequence con- taining ambiguities and self-occlusions Figure 10 shows an example where this keyframe technique is employed We specify the left and right pose as the keyframe poses
44 Biased Downhill Simplex Method
Extracting pose from a silhouetre can produce multiple candidate solutions The high dimensionality of the articulated model para- meter space requires efficient local and global search algorithms We chose local algorithms given their loweroost A suitable initial- ization of model parameters is also required by many algorithms for motion tracking Constraints like joint angle limits on parameters can be used The movement of the subject can be restricted at the cost of losing generality For example movement symmetric (but out of phase) to the central sagittal plane is often assumed
The object function disallows the computation of analytic deriva- tives in terms of motion parameters Downhill simplex method [17] serves very well to minimize the proposed cost function since it re- quires function evaluation for specific multi-dimensional optimiza- tion parameters
The simplex method can be easily adapted to our multi-dimensional human body model The initial simplex of R dimensions consists of n + 1 vertices Though we use this method for alignment and shape fitting we explain itrsquos workings by only describing reconstruction of the motion Let the coefficients ~ ( i ) = f ~ ~ - rsquo ) pn i i p l ) ) (the solution of the previous frame) be one of the initial points po of the simplex We can choose the other remaining n points to be
p=m+pie i = 1 q
where ejrsquos are n unit vectors and pi are defined by the character- istic length scale of each component of p The movement of this n-dimensional simplex is confined to be within the motion space close enough to the configuration of the current frame and there is no need to perfom exhaustive searches beyond certain ranges of movement between two consecutive frames To further target the most relevant parameter space to search parameter velocity is used to bias the simplex location This bias and the size of the simplex are determined by limits on parmetric acceleration that arise from principles of physics and basic anatomy
Due 10 the inherent hierarchical properties of the human model a hierarchical optimization algorithm is employed The complete 30 configuration parameters are divided into 6 sub-groups as dictated by anatomical considerations Starting from the configuration of the pervious frame the modelrsquos global translation and rotation k s - formations are first computed using the downhill simplex method
Then the torso is appropriately rotated to minimize the error The arm and leg positions are computed last one by one
To avoid accumulative errors another simple technique that is often beneficial is to restart the optimization routine from the solution found in the current optimization stage ln the following section we explore how these strategies are exploited towards finding the correct motion configuration from silhouette image sequences
5 IMPLEMENTATION
Our reconstruction method depends on an optimization process ex- ecuted in a motion parameter space Toward this purpose we first perfom a shape fitting exercise for the very first frame so that our model fully explains the silhouette area fram a specific view The resulting shape parameters are then fixed for the remainder of the motion tracking process It should be noted that we use the same objective function for initial alignment shape fitting and motion tracking
51 Automatic Initialization
As mentioned before the only input we exploiit to reconstruct the 3D motion parameters are silhouette images extracted from a video sequence We use the area-based metric to compute the likelihood of our model for a given input silhouette image Therefore the projected shape of a 3D model needs to be as close as possible to the input silhouette A suitable frame with no self-occlusjons is used to adapt the shape of our model to the actor being observed The optimization procedure is employed for this frame in order to fix the modelrsquos shape parameters and initial the pose of the model Lacking a suitable frame the shape parameters and initial pose of the model can be initially seamp by hand
The optimization parameters we determine in the jnitialhation stage is a subset of the parameter set a Up Let a translation vec-
subset of motion parameters that define the rotation angles around z-axis of upper arms and upper legs respectively We divide the ini- tialization task into two consecutive optimization steps
( 1 ) ( 1 ) U ) ( 1 ) 11) tor r = PI 1 Pz 1 1 and let s = A Pt2 P[res7 ampI be a
1 Alignment find r and 5 such that Eq 1 is minimized
2 Shape adjustment find a and s so that m I is minimized
The middle and right image in Figure 4 depict the result for the two steps described above Note that our coreweighted XOR metric is helpful to align the shape of the initial model at the center of the silhouette image If the initial model was not aligned at the center of the silhouette the subsequent shape fitting process would have failed
given the optimal t 3) found at step 1
52 Motion Tracking
After the initialization described in the previous section acrual mo-
such that it minimizes the objective function as described in Sec-
tion 4 for each frame i The optimal parameter vector pi found at frame i is used as the initial guess for the optimization routine of frame i + 1
To reconstruct only physically meaningful joint angles we assign a constraint for each joint angle as well as the degree of freedom
tion tracking is performed by searching a motion configuration p (i)
(
40
I 50 l a 150 2m ZKI
Figure 4 Automatic initialization step (left) Initial status (middle) Fnrr-ber
After alignment (right) After shape fitting and ready for motion fitting Figure 5 Effectiveness of simple repetition of the same optimization
process
~3 otherwise
where c e 1 and a1 are given by Eq 3 Q 4 Eq 5 and Eq 6 Ck and ($ are the lower and upper bound of a joint angle p k respec- tively Assigning constraints for each joint angle is very beneficial in removing the ambiguity when deciding the next step in searching downhill direction
In using the downhill simplex method restarting the minimization routine always helps to escape the shallow local minima that are proximal to deeper local minima Figure 5 shows how effective this simple repetition is The example sequence consists of four main actions of a total of 250 frames The frame range (0100) depicts the bending of the left arm range (JOO 150) shows the bending of the right arm range (t50200) shows the bending of the left leg and finally the frame range (200250) depicts the same actor bend- ing his right leg The results using no repetition and 2-times rep- etition show relatively high cost values Incorrect results are also obtained Two such incorrect results from the two tracking exper- iment at a specific frame (224) are shown in Figure Tracking with 3-times repetition showed visually correct results for all four action sequences In this case the area with high cost in Figure is mainly caused by the deformation of the shape of the subject We note this by displaying the two frames with corresponding peaks in the graph The sources of error are marked illustratively in Figure 7 The region A D and E is from the deformation of the clothes The region B is caused by the expanded silhouette due to the motion blur effect and C is a region with the inherent difference between model and real silhouette m a
53 Motion Refinement
The final tracking result cannot be perfect because the shape of the articulated model does not match the actor in the video exactly there are occlusions and ambiguities there are many more DOFs for each arliculated joint However our system generates reason- ably good motion data and aIlows the users to refine the generated motion in the post-processing stage The user can also add new constraints to reduce the search space for particular parameters to
Figure 6 First input image Second a correct result (with cost value 1231) Third and forth image shows the 2 incorrect results (with cost value 2167 and 2130 respectively)
get better tracking results In addition given our motion data user can modify the motion with any 3D character animation tool like Poser from Curious Lab
6 RESULTS
We illustrate our method using several full body tracking se- quences AI1 the video clips are sampled at the rate of 30Hz and some of them are from CMU Graphics Lab Motion Capture Data- base [e] Despite that we are using only one camera and do not em- ploy any marker we still obtain desirable results Figure 8 Figure 9 and Figure 10 are examples of tracking artists and athletes The first dance sequence (Figure 8) is relatively straightforward to track be- cause there are no occlusions and motion is mainly planar Our tracker manages to track the fmnto parallel motions The second badminton sequence (Figure 9) is more complex because of multi- ple occlusions occurring during the action However we can recon- struct the motion when we assume that both legs move with con- stant velocity In addition we capture the in-depth (out-of-plane) motions of the player successfully The previous sequences could all be tracked without user intervention The last sequence (Fig- ure IO) contains many more challenges given the complex torso ro- tations and arm swings After introducing keyframing our tracker estimates the uncertain positions of arms and torso and recov- ers the motions of the arms even though they are totally occtuded in the silhouettes For this sequence six keyframes were used More reconstruction results can be found at httpwwwcseohio- stateedukhenyisresearchmotionindexhtm
The time expended for analysis is about 3 sec per frame for sim- ple sequences and about 5 sec per frame for difficult ones when executed on a Pentium Iv PC with a 2 GHz CPU and 512MB of memory It should be noted that 131 reported times of 7 to 12 sec per
41
REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43

Figure 1 (left) An input silhouette image (right) The coremap image used to compute the coreweighted XOR
43 Using Image Features and Physical Constraints
The core-weighted XOR objective function is sufficient in many cases However there are also cases in which it falls short or our performance expectations Simply adjusting the core-weighted XOR parameters is insufficient to increase the generality of this method In particular the problems encountered include ap- pendages are sometimes not extended to completely fill the silhou- ette feet are able ta penetrate the ground plane and joints are aI- lowed to bend backward as well as forward These sub-optimal configurations ax found because they represent local minima of the core-weighted XOR function To remove these spurious local min- ima and improve our performance additional tems are included in the basic objective function
In order to stretch the limbs to cover silhouette edges we augment our objective function with a term that emphasizes matching edges amp(4)
where T is the image after edges have been extracted h m the fore- ground image using a contrast threshold This tenn i s summed over all pixel positions along with the core-weighted XOR function
In addition to the matching edges term semantic features are used for the limbs to fully cover the silhouette We detect the limbs (hands and feet) along the contours of the foreground human body in some frames 1121 Along the contour of the silhouette we cal- culate the curvature of each point on the contour The curvature at those points is compared against a specified threshold and points of high positive curvature are extracted Using an estimate o f the po- sition of hands from several of previous frames unlikely handfoot positions are further eliminated as determined by the human body smctufe
Moreover the outlines of the arms and the V shape between two legs can be detected based on those concave points along edge con- tours the neck and the crotch are usually the concave points along the edge contours and anns begin from the neck and the V shape between the legs is formed by the feet and the crotch However since we are only using a single camera it is hard to distinguish between the left and right limbs Therefore we do not q u i r e the exact matching of the limbs from the model and the silhouettes The handlfaot consmint term only focuses on reducing the distance be- tween the modelrsquos handslfeet and the nearest detected ones
z = -wl J((i - id12 + (jm - (5)
where ( i m j) is the limb position on the articulated model (id j d ) is the detected footlhand position and wi is the weight factor
A r m s and the V shape are treated the same as the edge term which means we try to get a maximum matching between detected armdlegs and those of modelrsquos
where R is the image with armslegs detected This term is summed over all pixel positions along with the core-weighted XOR func- tion We use those two terms to synthesize motions in Figure 8 and Figure 9
It should be noted that sometimes there is no proper candidate (both a hand or a foot) and in those cases we do not require that the handlfoot constraints be satisfied for particular frames Moreover the position of the head can be detected along the contour using the horizontal projection of the silhouette [7] and temporal coherence The head always lies at a local highest position along the silhou- ette outline and near the maximum of horizontal projection of the histogram Similarly a head constraint term can be used in the ob- jective function
Figure 2 Three examples for handsfeet arms legs and head detec- tions along silhouette outlines where head is marked as red body tips are white arms in green and legs in red
To disallow configurations that include ground plane penetration we define a constraint an the limbs of the figure that essentially evaluates to infinity whenever penetration occurs We also define constraints for each joint angle such that C 5 5 C j = 730 and penalize configurations that violate the constraints These con- figuration penalties are added to the objective function These mod- ifications help guide the silhouette-model matching process to a physically meaningful pxameter set with less ambiguity
Despite the application of physical constraints temporal coherence and knowledge of the anatomy the 3D reconstruction is still under- constrained due to self-occlusions and ambiguities
Instead of exploring complex yet not reliable solutions like texture detection we alIow users to specify the keyframes interactively to obtak viable results Similar solutions to this problem are re- ported in [5] Every keyframe has an impact range and for any frame inside this range instead of using the configuration of the last frame as starting body pose one uses the interpolation of the keyframe and the previous frame to start the optimization Enough keyframes can always guarantee a good reconstructionl but speci- fying keyframes is tedious Our suggestion is the foIlowing When body features like feet and bands are not discemable for several consecutive frames during the pre-processing stage it is because occlusions or ambiguities occur Users should add two keyframes one before the occlusions happen and one after the occlusions dis- appear Users do not necessarily specieuroy all the 30 pimrdquoers they specify a subset ofthe parameters usually those describing position
39
of the limba or the twisted torso Figure 3 shows a sequence that requires keyframing to be reconstructed correctly
Figure 3 Keyframes are necessarily to reconstruct this sequence con- taining ambiguities and self-occlusions Figure 10 shows an example where this keyframe technique is employed We specify the left and right pose as the keyframe poses
44 Biased Downhill Simplex Method
Extracting pose from a silhouetre can produce multiple candidate solutions The high dimensionality of the articulated model para- meter space requires efficient local and global search algorithms We chose local algorithms given their loweroost A suitable initial- ization of model parameters is also required by many algorithms for motion tracking Constraints like joint angle limits on parameters can be used The movement of the subject can be restricted at the cost of losing generality For example movement symmetric (but out of phase) to the central sagittal plane is often assumed
The object function disallows the computation of analytic deriva- tives in terms of motion parameters Downhill simplex method [17] serves very well to minimize the proposed cost function since it re- quires function evaluation for specific multi-dimensional optimiza- tion parameters
The simplex method can be easily adapted to our multi-dimensional human body model The initial simplex of R dimensions consists of n + 1 vertices Though we use this method for alignment and shape fitting we explain itrsquos workings by only describing reconstruction of the motion Let the coefficients ~ ( i ) = f ~ ~ - rsquo ) pn i i p l ) ) (the solution of the previous frame) be one of the initial points po of the simplex We can choose the other remaining n points to be
p=m+pie i = 1 q
where ejrsquos are n unit vectors and pi are defined by the character- istic length scale of each component of p The movement of this n-dimensional simplex is confined to be within the motion space close enough to the configuration of the current frame and there is no need to perfom exhaustive searches beyond certain ranges of movement between two consecutive frames To further target the most relevant parameter space to search parameter velocity is used to bias the simplex location This bias and the size of the simplex are determined by limits on parmetric acceleration that arise from principles of physics and basic anatomy
Due 10 the inherent hierarchical properties of the human model a hierarchical optimization algorithm is employed The complete 30 configuration parameters are divided into 6 sub-groups as dictated by anatomical considerations Starting from the configuration of the pervious frame the modelrsquos global translation and rotation k s - formations are first computed using the downhill simplex method
Then the torso is appropriately rotated to minimize the error The arm and leg positions are computed last one by one
To avoid accumulative errors another simple technique that is often beneficial is to restart the optimization routine from the solution found in the current optimization stage ln the following section we explore how these strategies are exploited towards finding the correct motion configuration from silhouette image sequences
5 IMPLEMENTATION
Our reconstruction method depends on an optimization process ex- ecuted in a motion parameter space Toward this purpose we first perfom a shape fitting exercise for the very first frame so that our model fully explains the silhouette area fram a specific view The resulting shape parameters are then fixed for the remainder of the motion tracking process It should be noted that we use the same objective function for initial alignment shape fitting and motion tracking
51 Automatic Initialization
As mentioned before the only input we exploiit to reconstruct the 3D motion parameters are silhouette images extracted from a video sequence We use the area-based metric to compute the likelihood of our model for a given input silhouette image Therefore the projected shape of a 3D model needs to be as close as possible to the input silhouette A suitable frame with no self-occlusjons is used to adapt the shape of our model to the actor being observed The optimization procedure is employed for this frame in order to fix the modelrsquos shape parameters and initial the pose of the model Lacking a suitable frame the shape parameters and initial pose of the model can be initially seamp by hand
The optimization parameters we determine in the jnitialhation stage is a subset of the parameter set a Up Let a translation vec-
subset of motion parameters that define the rotation angles around z-axis of upper arms and upper legs respectively We divide the ini- tialization task into two consecutive optimization steps
( 1 ) ( 1 ) U ) ( 1 ) 11) tor r = PI 1 Pz 1 1 and let s = A Pt2 P[res7 ampI be a
1 Alignment find r and 5 such that Eq 1 is minimized
2 Shape adjustment find a and s so that m I is minimized
The middle and right image in Figure 4 depict the result for the two steps described above Note that our coreweighted XOR metric is helpful to align the shape of the initial model at the center of the silhouette image If the initial model was not aligned at the center of the silhouette the subsequent shape fitting process would have failed
given the optimal t 3) found at step 1
52 Motion Tracking
After the initialization described in the previous section acrual mo-
such that it minimizes the objective function as described in Sec-
tion 4 for each frame i The optimal parameter vector pi found at frame i is used as the initial guess for the optimization routine of frame i + 1
To reconstruct only physically meaningful joint angles we assign a constraint for each joint angle as well as the degree of freedom
tion tracking is performed by searching a motion configuration p (i)
(
40
I 50 l a 150 2m ZKI
Figure 4 Automatic initialization step (left) Initial status (middle) Fnrr-ber
After alignment (right) After shape fitting and ready for motion fitting Figure 5 Effectiveness of simple repetition of the same optimization
process
~3 otherwise
where c e 1 and a1 are given by Eq 3 Q 4 Eq 5 and Eq 6 Ck and ($ are the lower and upper bound of a joint angle p k respec- tively Assigning constraints for each joint angle is very beneficial in removing the ambiguity when deciding the next step in searching downhill direction
In using the downhill simplex method restarting the minimization routine always helps to escape the shallow local minima that are proximal to deeper local minima Figure 5 shows how effective this simple repetition is The example sequence consists of four main actions of a total of 250 frames The frame range (0100) depicts the bending of the left arm range (JOO 150) shows the bending of the right arm range (t50200) shows the bending of the left leg and finally the frame range (200250) depicts the same actor bend- ing his right leg The results using no repetition and 2-times rep- etition show relatively high cost values Incorrect results are also obtained Two such incorrect results from the two tracking exper- iment at a specific frame (224) are shown in Figure Tracking with 3-times repetition showed visually correct results for all four action sequences In this case the area with high cost in Figure is mainly caused by the deformation of the shape of the subject We note this by displaying the two frames with corresponding peaks in the graph The sources of error are marked illustratively in Figure 7 The region A D and E is from the deformation of the clothes The region B is caused by the expanded silhouette due to the motion blur effect and C is a region with the inherent difference between model and real silhouette m a
53 Motion Refinement
The final tracking result cannot be perfect because the shape of the articulated model does not match the actor in the video exactly there are occlusions and ambiguities there are many more DOFs for each arliculated joint However our system generates reason- ably good motion data and aIlows the users to refine the generated motion in the post-processing stage The user can also add new constraints to reduce the search space for particular parameters to
Figure 6 First input image Second a correct result (with cost value 1231) Third and forth image shows the 2 incorrect results (with cost value 2167 and 2130 respectively)
get better tracking results In addition given our motion data user can modify the motion with any 3D character animation tool like Poser from Curious Lab
6 RESULTS
We illustrate our method using several full body tracking se- quences AI1 the video clips are sampled at the rate of 30Hz and some of them are from CMU Graphics Lab Motion Capture Data- base [e] Despite that we are using only one camera and do not em- ploy any marker we still obtain desirable results Figure 8 Figure 9 and Figure 10 are examples of tracking artists and athletes The first dance sequence (Figure 8) is relatively straightforward to track be- cause there are no occlusions and motion is mainly planar Our tracker manages to track the fmnto parallel motions The second badminton sequence (Figure 9) is more complex because of multi- ple occlusions occurring during the action However we can recon- struct the motion when we assume that both legs move with con- stant velocity In addition we capture the in-depth (out-of-plane) motions of the player successfully The previous sequences could all be tracked without user intervention The last sequence (Fig- ure IO) contains many more challenges given the complex torso ro- tations and arm swings After introducing keyframing our tracker estimates the uncertain positions of arms and torso and recov- ers the motions of the arms even though they are totally occtuded in the silhouettes For this sequence six keyframes were used More reconstruction results can be found at httpwwwcseohio- stateedukhenyisresearchmotionindexhtm
The time expended for analysis is about 3 sec per frame for sim- ple sequences and about 5 sec per frame for difficult ones when executed on a Pentium Iv PC with a 2 GHz CPU and 512MB of memory It should be noted that 131 reported times of 7 to 12 sec per
41
REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43

of the limba or the twisted torso Figure 3 shows a sequence that requires keyframing to be reconstructed correctly
Figure 3 Keyframes are necessarily to reconstruct this sequence con- taining ambiguities and self-occlusions Figure 10 shows an example where this keyframe technique is employed We specify the left and right pose as the keyframe poses
44 Biased Downhill Simplex Method
Extracting pose from a silhouetre can produce multiple candidate solutions The high dimensionality of the articulated model para- meter space requires efficient local and global search algorithms We chose local algorithms given their loweroost A suitable initial- ization of model parameters is also required by many algorithms for motion tracking Constraints like joint angle limits on parameters can be used The movement of the subject can be restricted at the cost of losing generality For example movement symmetric (but out of phase) to the central sagittal plane is often assumed
The object function disallows the computation of analytic deriva- tives in terms of motion parameters Downhill simplex method [17] serves very well to minimize the proposed cost function since it re- quires function evaluation for specific multi-dimensional optimiza- tion parameters
The simplex method can be easily adapted to our multi-dimensional human body model The initial simplex of R dimensions consists of n + 1 vertices Though we use this method for alignment and shape fitting we explain itrsquos workings by only describing reconstruction of the motion Let the coefficients ~ ( i ) = f ~ ~ - rsquo ) pn i i p l ) ) (the solution of the previous frame) be one of the initial points po of the simplex We can choose the other remaining n points to be
p=m+pie i = 1 q
where ejrsquos are n unit vectors and pi are defined by the character- istic length scale of each component of p The movement of this n-dimensional simplex is confined to be within the motion space close enough to the configuration of the current frame and there is no need to perfom exhaustive searches beyond certain ranges of movement between two consecutive frames To further target the most relevant parameter space to search parameter velocity is used to bias the simplex location This bias and the size of the simplex are determined by limits on parmetric acceleration that arise from principles of physics and basic anatomy
Due 10 the inherent hierarchical properties of the human model a hierarchical optimization algorithm is employed The complete 30 configuration parameters are divided into 6 sub-groups as dictated by anatomical considerations Starting from the configuration of the pervious frame the modelrsquos global translation and rotation k s - formations are first computed using the downhill simplex method
Then the torso is appropriately rotated to minimize the error The arm and leg positions are computed last one by one
To avoid accumulative errors another simple technique that is often beneficial is to restart the optimization routine from the solution found in the current optimization stage ln the following section we explore how these strategies are exploited towards finding the correct motion configuration from silhouette image sequences
5 IMPLEMENTATION
Our reconstruction method depends on an optimization process ex- ecuted in a motion parameter space Toward this purpose we first perfom a shape fitting exercise for the very first frame so that our model fully explains the silhouette area fram a specific view The resulting shape parameters are then fixed for the remainder of the motion tracking process It should be noted that we use the same objective function for initial alignment shape fitting and motion tracking
51 Automatic Initialization
As mentioned before the only input we exploiit to reconstruct the 3D motion parameters are silhouette images extracted from a video sequence We use the area-based metric to compute the likelihood of our model for a given input silhouette image Therefore the projected shape of a 3D model needs to be as close as possible to the input silhouette A suitable frame with no self-occlusjons is used to adapt the shape of our model to the actor being observed The optimization procedure is employed for this frame in order to fix the modelrsquos shape parameters and initial the pose of the model Lacking a suitable frame the shape parameters and initial pose of the model can be initially seamp by hand
The optimization parameters we determine in the jnitialhation stage is a subset of the parameter set a Up Let a translation vec-
subset of motion parameters that define the rotation angles around z-axis of upper arms and upper legs respectively We divide the ini- tialization task into two consecutive optimization steps
( 1 ) ( 1 ) U ) ( 1 ) 11) tor r = PI 1 Pz 1 1 and let s = A Pt2 P[res7 ampI be a
1 Alignment find r and 5 such that Eq 1 is minimized
2 Shape adjustment find a and s so that m I is minimized
The middle and right image in Figure 4 depict the result for the two steps described above Note that our coreweighted XOR metric is helpful to align the shape of the initial model at the center of the silhouette image If the initial model was not aligned at the center of the silhouette the subsequent shape fitting process would have failed
given the optimal t 3) found at step 1
52 Motion Tracking
After the initialization described in the previous section acrual mo-
such that it minimizes the objective function as described in Sec-
tion 4 for each frame i The optimal parameter vector pi found at frame i is used as the initial guess for the optimization routine of frame i + 1
To reconstruct only physically meaningful joint angles we assign a constraint for each joint angle as well as the degree of freedom
tion tracking is performed by searching a motion configuration p (i)
(
40
I 50 l a 150 2m ZKI
Figure 4 Automatic initialization step (left) Initial status (middle) Fnrr-ber
After alignment (right) After shape fitting and ready for motion fitting Figure 5 Effectiveness of simple repetition of the same optimization
process
~3 otherwise
where c e 1 and a1 are given by Eq 3 Q 4 Eq 5 and Eq 6 Ck and ($ are the lower and upper bound of a joint angle p k respec- tively Assigning constraints for each joint angle is very beneficial in removing the ambiguity when deciding the next step in searching downhill direction
In using the downhill simplex method restarting the minimization routine always helps to escape the shallow local minima that are proximal to deeper local minima Figure 5 shows how effective this simple repetition is The example sequence consists of four main actions of a total of 250 frames The frame range (0100) depicts the bending of the left arm range (JOO 150) shows the bending of the right arm range (t50200) shows the bending of the left leg and finally the frame range (200250) depicts the same actor bend- ing his right leg The results using no repetition and 2-times rep- etition show relatively high cost values Incorrect results are also obtained Two such incorrect results from the two tracking exper- iment at a specific frame (224) are shown in Figure Tracking with 3-times repetition showed visually correct results for all four action sequences In this case the area with high cost in Figure is mainly caused by the deformation of the shape of the subject We note this by displaying the two frames with corresponding peaks in the graph The sources of error are marked illustratively in Figure 7 The region A D and E is from the deformation of the clothes The region B is caused by the expanded silhouette due to the motion blur effect and C is a region with the inherent difference between model and real silhouette m a
53 Motion Refinement
The final tracking result cannot be perfect because the shape of the articulated model does not match the actor in the video exactly there are occlusions and ambiguities there are many more DOFs for each arliculated joint However our system generates reason- ably good motion data and aIlows the users to refine the generated motion in the post-processing stage The user can also add new constraints to reduce the search space for particular parameters to
Figure 6 First input image Second a correct result (with cost value 1231) Third and forth image shows the 2 incorrect results (with cost value 2167 and 2130 respectively)
get better tracking results In addition given our motion data user can modify the motion with any 3D character animation tool like Poser from Curious Lab
6 RESULTS
We illustrate our method using several full body tracking se- quences AI1 the video clips are sampled at the rate of 30Hz and some of them are from CMU Graphics Lab Motion Capture Data- base [e] Despite that we are using only one camera and do not em- ploy any marker we still obtain desirable results Figure 8 Figure 9 and Figure 10 are examples of tracking artists and athletes The first dance sequence (Figure 8) is relatively straightforward to track be- cause there are no occlusions and motion is mainly planar Our tracker manages to track the fmnto parallel motions The second badminton sequence (Figure 9) is more complex because of multi- ple occlusions occurring during the action However we can recon- struct the motion when we assume that both legs move with con- stant velocity In addition we capture the in-depth (out-of-plane) motions of the player successfully The previous sequences could all be tracked without user intervention The last sequence (Fig- ure IO) contains many more challenges given the complex torso ro- tations and arm swings After introducing keyframing our tracker estimates the uncertain positions of arms and torso and recov- ers the motions of the arms even though they are totally occtuded in the silhouettes For this sequence six keyframes were used More reconstruction results can be found at httpwwwcseohio- stateedukhenyisresearchmotionindexhtm
The time expended for analysis is about 3 sec per frame for sim- ple sequences and about 5 sec per frame for difficult ones when executed on a Pentium Iv PC with a 2 GHz CPU and 512MB of memory It should be noted that 131 reported times of 7 to 12 sec per
41
REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43
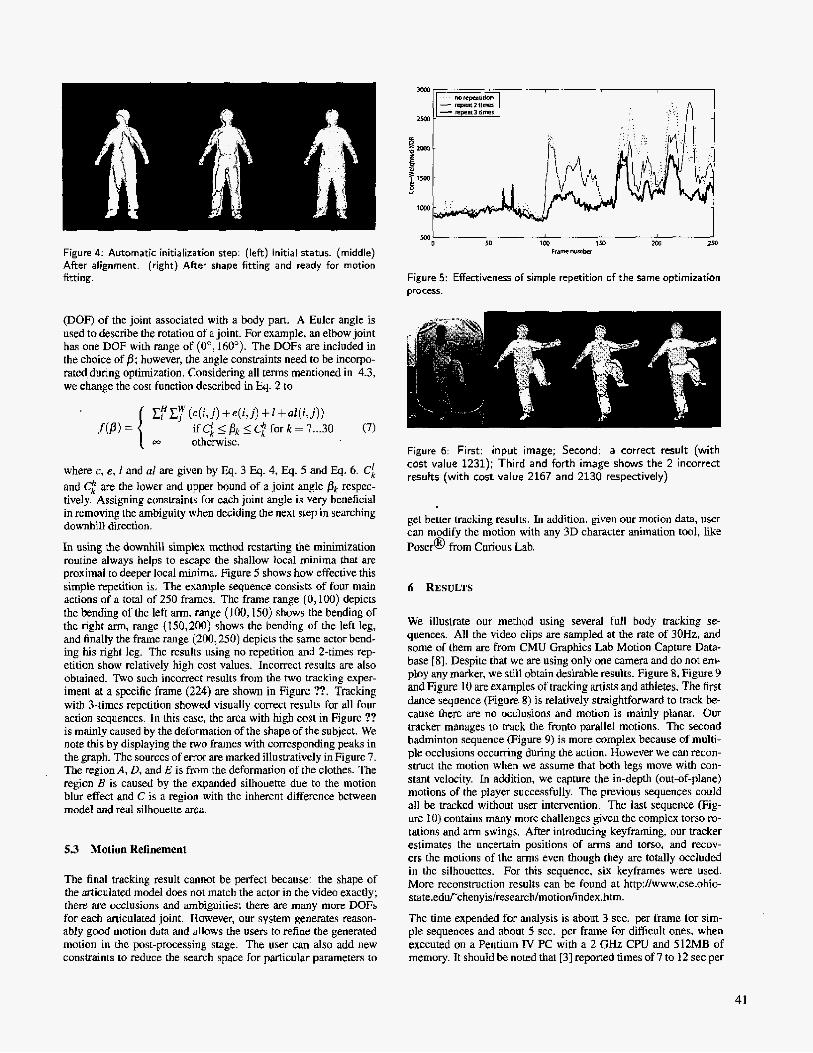
I 50 l a 150 2m ZKI
Figure 4 Automatic initialization step (left) Initial status (middle) Fnrr-ber
After alignment (right) After shape fitting and ready for motion fitting Figure 5 Effectiveness of simple repetition of the same optimization
process
~3 otherwise
where c e 1 and a1 are given by Eq 3 Q 4 Eq 5 and Eq 6 Ck and ($ are the lower and upper bound of a joint angle p k respec- tively Assigning constraints for each joint angle is very beneficial in removing the ambiguity when deciding the next step in searching downhill direction
In using the downhill simplex method restarting the minimization routine always helps to escape the shallow local minima that are proximal to deeper local minima Figure 5 shows how effective this simple repetition is The example sequence consists of four main actions of a total of 250 frames The frame range (0100) depicts the bending of the left arm range (JOO 150) shows the bending of the right arm range (t50200) shows the bending of the left leg and finally the frame range (200250) depicts the same actor bend- ing his right leg The results using no repetition and 2-times rep- etition show relatively high cost values Incorrect results are also obtained Two such incorrect results from the two tracking exper- iment at a specific frame (224) are shown in Figure Tracking with 3-times repetition showed visually correct results for all four action sequences In this case the area with high cost in Figure is mainly caused by the deformation of the shape of the subject We note this by displaying the two frames with corresponding peaks in the graph The sources of error are marked illustratively in Figure 7 The region A D and E is from the deformation of the clothes The region B is caused by the expanded silhouette due to the motion blur effect and C is a region with the inherent difference between model and real silhouette m a
53 Motion Refinement
The final tracking result cannot be perfect because the shape of the articulated model does not match the actor in the video exactly there are occlusions and ambiguities there are many more DOFs for each arliculated joint However our system generates reason- ably good motion data and aIlows the users to refine the generated motion in the post-processing stage The user can also add new constraints to reduce the search space for particular parameters to
Figure 6 First input image Second a correct result (with cost value 1231) Third and forth image shows the 2 incorrect results (with cost value 2167 and 2130 respectively)
get better tracking results In addition given our motion data user can modify the motion with any 3D character animation tool like Poser from Curious Lab
6 RESULTS
We illustrate our method using several full body tracking se- quences AI1 the video clips are sampled at the rate of 30Hz and some of them are from CMU Graphics Lab Motion Capture Data- base [e] Despite that we are using only one camera and do not em- ploy any marker we still obtain desirable results Figure 8 Figure 9 and Figure 10 are examples of tracking artists and athletes The first dance sequence (Figure 8) is relatively straightforward to track be- cause there are no occlusions and motion is mainly planar Our tracker manages to track the fmnto parallel motions The second badminton sequence (Figure 9) is more complex because of multi- ple occlusions occurring during the action However we can recon- struct the motion when we assume that both legs move with con- stant velocity In addition we capture the in-depth (out-of-plane) motions of the player successfully The previous sequences could all be tracked without user intervention The last sequence (Fig- ure IO) contains many more challenges given the complex torso ro- tations and arm swings After introducing keyframing our tracker estimates the uncertain positions of arms and torso and recov- ers the motions of the arms even though they are totally occtuded in the silhouettes For this sequence six keyframes were used More reconstruction results can be found at httpwwwcseohio- stateedukhenyisresearchmotionindexhtm
The time expended for analysis is about 3 sec per frame for sim- ple sequences and about 5 sec per frame for difficult ones when executed on a Pentium Iv PC with a 2 GHz CPU and 512MB of memory It should be noted that 131 reported times of 7 to 12 sec per
41
REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43

REFERENCES
Figure 7 Analyzing the source of error appeared a t two peaks in the third plot of Figure AD and E are from deformation of clothes B is from motion blur effect and C is from the inherent difference between model and real image
frame for similar operations We use w = 1 O from Eq 3 w e = 20 from Eq 4 wf = 20 from Eq 5 and w ~ = 20 from Eq 6 for the cost function for all motion synthesis
7 CONCLUSION AND FUTURE WORK
We presented a simple and robust technique to reconswct 3D mo- tion parameters of a human model using image silhouettes A novel cost metric called core-weighted XOR was introduced and consis- tently used for the automatic alignment shape fitting and motion tracking The computation time of the cost function is directiy re- lated to the overall performance of our method Currently our im- plementation does not exploit any hardware acceleration In the fu- ture we intend to accelerate the weighted-XOR computation using features of a modern graphics hardware Our work is closest to that of Sminchisescu [20] and that of DiFranco [ 5 ] We compare favor- ably in terms of generality to the results they report By detecting mare human features like head arms hands legs and feet we can further improve the correctness of registering our model with the all the images and recovering the 3d poses
One of the biggest challenges in 3D motion reconstruction from a single silhouette image is the inherent ambiguity caused by self- occlusion of different body parts Usually internal edge information can be used to solve the ambiguity at certain degree However spurious edges caused by shadows andor mostly by the patterns of clothes can result in incorrect reconstruction Finally we would like to study how we can exploit various spatial and temporal features of silhouette image sequence to infer the correct motion of self- occluded part in future work
ACKNOWLEDGEMENTS
The authors would like to thank the Advanced Computing Cen- ter for Art and Design at Ohia State University for their support specifically for the use of their motion capture lab and software en- vironment The authors would also like to thank the folks at CMU for making available their motion captured database The database was created with funding from NSF EIA-0196217 This work was supported in part by US National Science Foundation Grant ITR- US-0428249 and by the Secure Knowledge Management Program Air Force Research Laboratory Information Directorate Wright- Patterson AFB
[ 11 AE Bobick and JW Davis The Representation and Recognition of Action using Temporal Templates In IEEE Transactions un Potrem Analysis and Machine Intelligence volume 23 No3 pages 257-267 2001
[2] C Bregler and J Malik Tracking People with Twists and Exponential Maps In Proceedings 0fIEEE CVPR pages 8-151998
[31 J Carranza C Thaobalt M Magnor andH-P Seidel Free-Viewpoint Video of Human Actors In Pmceedings of SIGGRAPHZCO3 volume 22 No3 pages 5494772003
[4] 5 Deutscher A Blake and I Reid Articulated Body Motion Cap- ture by Annealed Particle Filtering In Pmceedings of IEEE CVPR volume 2 pages 126-1332000
[5] DE DiFtanco T Cham and JM Rehg Reconsmction of 3-D Fig- ure Motion from 2-D Correspondences In Proc Conf Computer W- sion and Parrern Recognition pages 307-3142001
[6j M Gleicher and N Ferrier Evaluating Wdeo-Based Motion Capture In Proceedings of Computer Animation pages 75-802002
171 I Haritaoglu D Hanuood and L Davis Ghost A Human Body Part Labeling System Using Silhouettes In lnremational Con on Panern Recognirion volume I pages 77-82 1998
[8] JK Hodgins Camegie Mellon University Graphics Lab Motion Cap- ture Database httpmocapcscmuedd
[91 T Horprasert D Hamood and LS Davis A statistical approach for real-time robust background subtraction and shadow detection In IEEE Frame-Rote Workshop 1999
[lo] I Kakadiaris and D Metaxas Model-Based Estimation of 3D Hu- man Motion In IEEE Transactions on Panem Analysis and Machine Inrelligence volume 22 December 2000
[11] J Lee J Chai PSA Reitsma JK Hodgins and NS Pollard In- teractive Conuol of Avatars Animated with Human Motion Data In Pmceedings of SIGGRAPH 2002 Computer Graphrcs Proceedings Annual Conference Series pages 49 1-500 ACM ACM Press I ACM SIGGRAPH 2002
121 MW Lee I Cohen and SK Jung Particle Filter with Analytical Inference for Human Body Tracking In IEEE Workshop on Morion and Vdeu Computing 2002
131 HPA Lensch W Heidrich and H Seidel Automated Texture Regis- tration and Stitching for Real World Models In Proceedings of Pacific Graphics ZOOO 2000
141 M Leventon and W Freeman Bayesian estimation of 3-d h u m motion from an image sequence In Tcchniccrl Repon TR-9--06 Mir- subishi Elecmric Research Lubomoty Cambridge M 1998
151 TB Moeslund and E Granum A Survey of Computer Vision-Based Human Motion Capture In Compurer Ksion and Image Understand- ing 81(3) pages 231-2682001
161 V Pavlovic JM Rehg T Cham and KP Murphy A Dynamic Bayesian Network Approach to Figure Tracking Using Learned Dy- namic Models In h d Con$ on Computer Vision pages 94-1011999
171 WH Press BP Hannery SA Teukolosky and WT Vetterling Nu- merical Recipes in Cr The Art of Scientific Computing Cambridge Universiry Press New York 1988
181 L Ren G Shakbnamvich I Hodgins H Pfister and P Viola Learn- ing Silhouette Features for Control of Human Motion In Proceedings of rhe SlGGRAPH 2004 Conference OR Sketches amp Applications Au-
[19] C Sminchisescu Consistency and Coupling in Human Model Like- lihoods In IEEE Inrernational Conference on Auromutic Face and Gessure Recognirion pages 27-32 2002
Kinematic Jump Processes For Monocular 3D Human Tracking In Pmc Con$ Computer W o n and Parrem Recognition pages 69-162003
[21] Cristian Sminchisescu and Bill E g g s Estimating Articulated Human Motion with Covariance Scaled Sampling Internoflonu1 Jouml of Robotics Research 2003
I221 CR Wren A Azarbayejani T Darell and AP Pentland Pfinder Real-lime Tracking of the Human Body In Transmiions on Panern Analysis and Machine intelligence 19(7) 1997
gust 2004
[20] C Smiochisescu and B Triggs
42
Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43

Figure 8 Tracking a dancer displaying representative frames The top row shows the footage the middle row is the matching between silhouette (white ares) and our model (colored area) and the bottom row i5 the animation after rendering The limb stretching term is used here
Figure 9 Tracking a badminton player displaying representative frames The limb stretching term for legs is used here
figure 10 Tracking an actor dispbaying representative frames We employ the keyframe technique on the arms t o reconstruct this sequence
43
Related Documents









