MACHİNE LEARNİNG 10 Decision Trees

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

MACHİNE LEARNİNG10 Decision Trees

Motivation
Parametric Estimation Assume model for class probability or
regression Estimate parameters from all data
Non-Parametric Find “similar”/”close” data points Fit local model using these points Costly computation of distance from all
training dataBased on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
2

Motivation
Pre-split training data into region using small number of simple rules organized in hierarchical manner
Decision Trees Internal decision nodes have splitting rule Terminal leaves have class labels for
classification problem or values for regression problem
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
3

Tree Uses Nodes, and Leaves
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
4

Decision Trees
Start from univariate decision trees Each node looks only at single input feature
Want smaller decision trees Less memory for representation Less computation for a new instance
Want smaller generalization error
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
5

Decision and Leaf Node
Implement simple test function fm(x) Output: labels of branches fm(x) discriminant in d-dimensional space Complex discriminant is broken down
into hierarchy of simple decisions Leaf node describes a region in d-
dimensional space with same value Classification label Regression value
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
6

Classification Trees What is the good split function? Use Impurity measure Assume Nm training samples reach node m
Node m is pure if for all classes either 0 or 1 Need values in between
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
7

Entropy
Measure amount of uncertainty on a scale from 0 to 1
Example: 2 events If p1=p2=0.5, entropy is 1 which is
maximum uncertainty If p1=1=1-p0, entropy is 0 , which is no
uncertainty
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
8

Entropy
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
9

Best Split
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
10
Node is impure, need to split more Have several split criteria
(coordinates), have to choose optimal Minimize impurity (uncertainty) after
split Stop when impurity is small enough
Zero stop impurity=>complex tree with large variance
Larger stop impurity=>small tress but large bias

Best Split
Impurity after split: Nmj of Nm take branch j. Ni
mj belong to Ci
Find the variable and split that min impurity among all variables split positions for numeric variables
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
11
K
i
imj
imj
n
j m
mjm pp
N
N
12
1
logI'
mj
imji
mji N
Npj,m,CP̂ x|

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)12
ID3 algorithmforClassification and Regression Trees(CART)

Regression Trees
Value not a label in a leaf nodes Need other impurity measure Use Average Error
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
13
t
tm
t
ttm
mt
mt mt
mm
mm
b
rbgbgr
NE
m:b
x
xx
xxx
1
otherwise0
node reaches if 1
2
X

Regression Trees
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
14
After splitting:
2
1 if : reaches node and branch
0 otherwise
1'
mjmj
t tmjtt t
m mj mj mjj t tm mjt
m jb
b rE r g b g
N b
x xx
xx
x
X

Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)15
Example

Pruning Trees
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
16
Number of data instances reach a node is small Less then 5% of training data Don’t want to split further regardless of impurity
Remove subtrees for better generalization Prepruning: Early stopping Postpruning: Grow the whole tree then prune
subtrees Set aside pruning set Make sure pruning does not significantly increase error

Decision Trees and Feature Extraction
Univariate Tree uses only certain variable Some variables might not get used Features closer to the root have greater
importance
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
17

Interpretability
Conditions that are simple to understand Path from the root =>one conjunction of test All paths can be defined using set of IF_THEN
rules Form a rule base
Percentage of training data covered by the rule Rule support
Tool for a Knowledge Extraction Can be verified by experts
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
18

Rule Extraction from Trees
Lecture Notes for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
19
C4.5Rules (Quinlan, 1993)

Rule induction
Learn rules directly from data Decision-tree is a breadth-first rule construction Rule induction: depth-first construction
Start Learn rules one by one Rule is a conjunction of conditions Add condition one by one by certain criteria
Entropy Remove samples covered by rule from training
data
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
20

Ripper algorithm Assume two classes K=2, positive and
negative examples Add rules to explain positive examples, all
other examples are classified as negative Foil algorithm: add condition to a rule to
maximize information gain
Based on E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
21
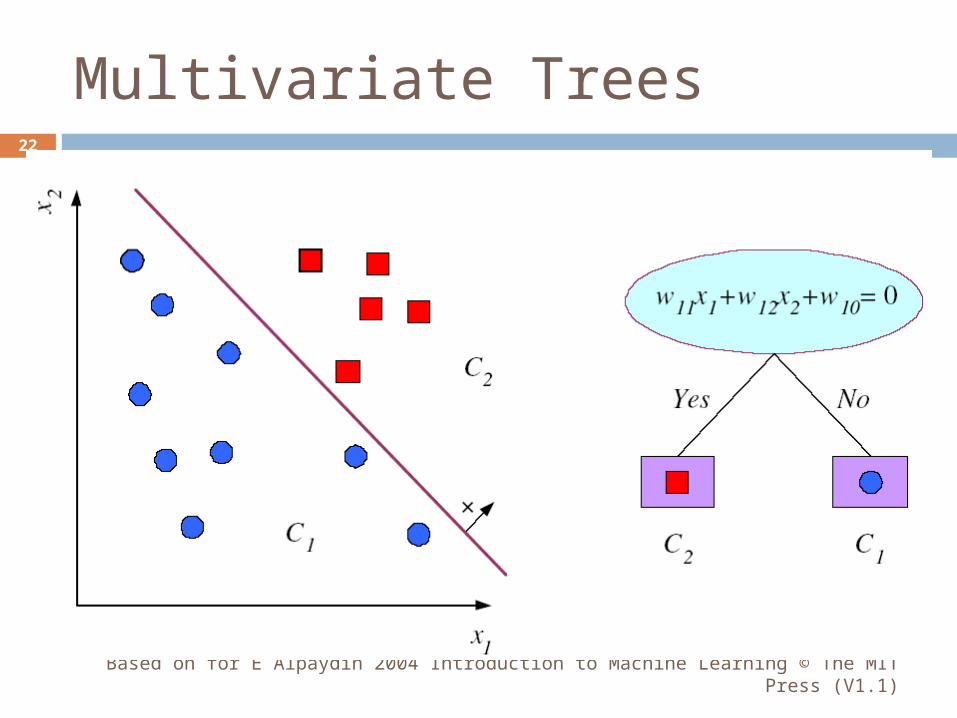
Multivariate Trees
Based on for E Alpaydın 2004 Introduction to Machine Learning © The MIT Press (V1.1)
22
Related Documents











