How MacGyver Learned to Leave Duct Tape Behind and Use Spark Instead April 22, 2015 DC Spark Interactive Meetup | 1

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

How MacGyver Learned to Leave Duct Tape Behind and Use Spark Instead
April 22, 2015
DC Spark Interactive Meetup | 1

Agenda
• MacGyver Who?
• Complex Data Problem
• Current Architecture
• New Tools in MacGyver’s box
● Spark Architecture
● Initial Results
• Q&A
DC Spark Meetup | 2


MacGyver Trivia
● Answer these questions 3:○ What was the name of the actor who
played the role of MacGyver?○ What other series is this actor best known
for?○ Was there another actor who was in both
MacGyver and the other series?○ OR○ What’s MacGyver’s first name?

If MacGyver Were a Coder ….
● Suppose he retired in 1996 from the Phoenix Foundation and became a Software Engineer
● He’s given the assignment in 2004 to build a new ETL platform.
● What would the architecture look like?

ETL circa 2000 - Present
= SQL
=
Oracle DB
SQL Server
MySQL
PostGreSQL
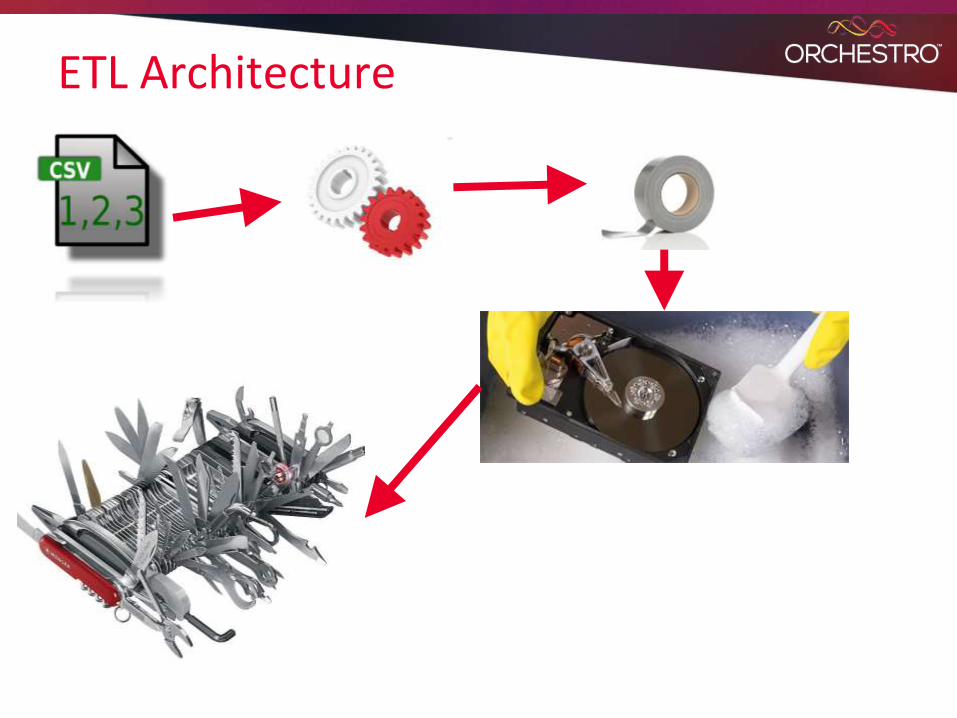
ETL Architecture

MacGyver at Orchestro
● If he worked at Orchestro …. ○ He might find a lot of :
○ But he might find cases where there are problems need additional tools.

Maybe Orchestro doesn’t have a BIG Data Problem
● Currently, our team deals with 15-20TB of data total
● In Matt Asay’s talk at QCon in 2014, ○ 64% of Big Data projects have < 100TB
● So maybe we don’t have a “Big Data” problem, but there’s a good chance we have a complex data problem
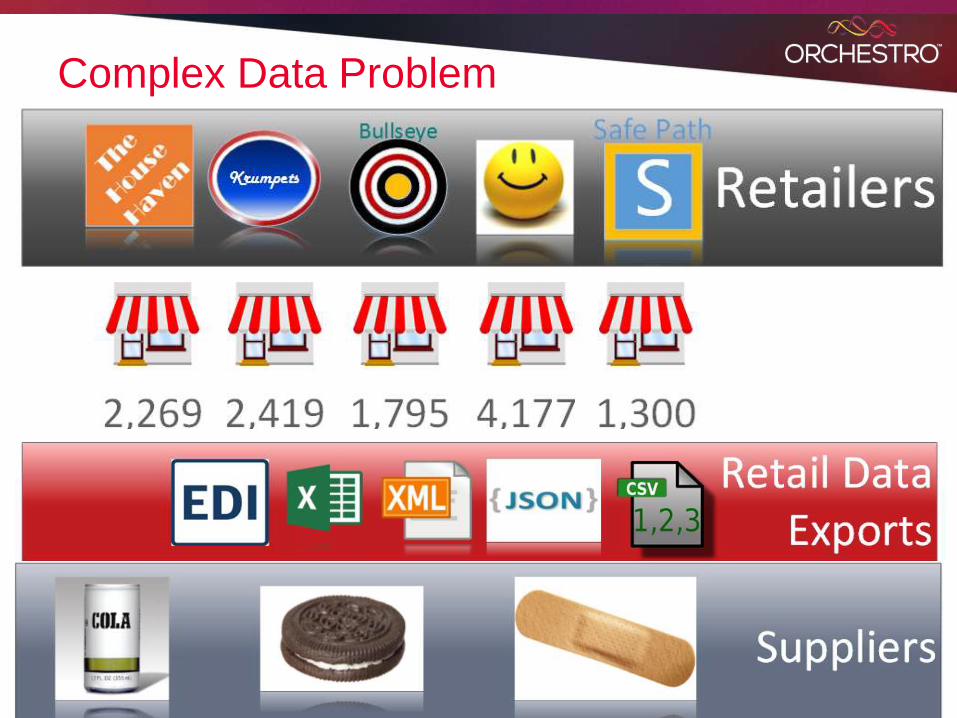
Complex Data Problem

Example
4,177 Stores
~600 products sold at 4,177 Stores~ 2.4 million new sales recs / day
But supplier is a Category Captain, > 70 million new sales recs to analyze (including competitor data)
And that’s just for Smiley Mart!
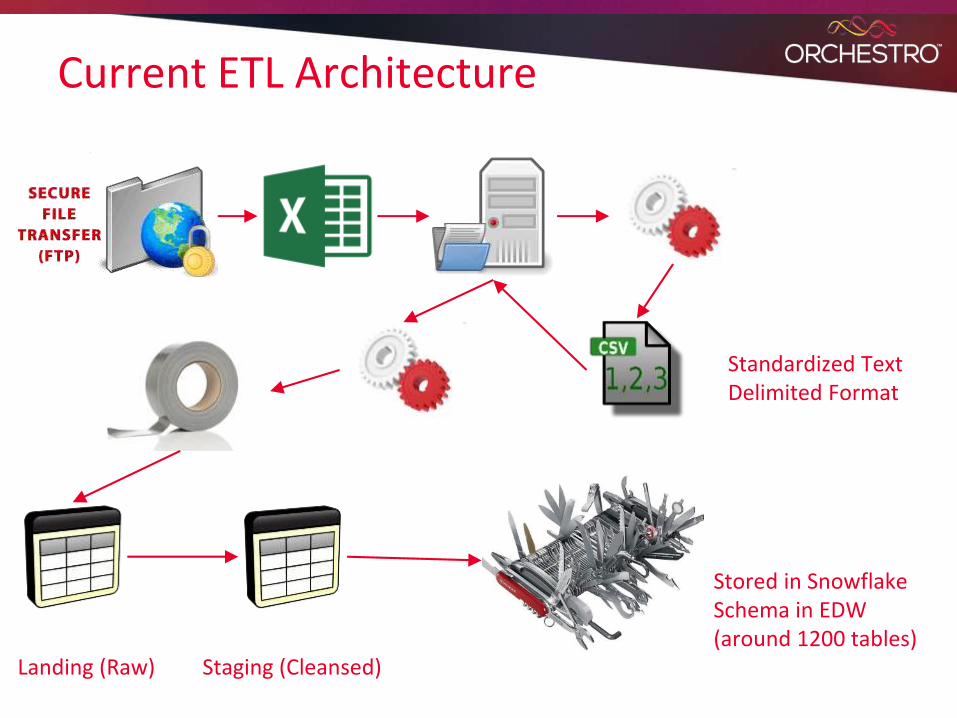
Current ETL Architecture
Standardized Text Delimited Format
Landing (Raw) Staging (Cleansed)
Stored in Snowflake Schema in EDW(around 1200 tables)

Drivers for Change(in no particular order)
● Cost○ SQL Server License = $$$
● ~$6k core○ DB Servers = $$$
● 64 Cores, 256GB RAM○ DSAN = $$$
● Scalability○ This model relies on vertical scaling

Drivers for Change (cont.)
● Performance○ Cleansing, Loading, Analytics,
Reports only getting more complex● Which increases time to
complete each

New Tools in MacGyver’s Toolbox
“ A paperclip can be a
wonderous thing.
More times than I can
remember, one of
these has gotten me
out of a tight spot.”
15

Enter Spark
Why Spark?● Performance
○ 100 TB unsorted data○ Previous Record achieved
● 2100 Node Hadoop cluster at Yahoo!● Completed in 73 min, 1.42 TB/min
○ Spark● 206 Nodes● 23 min, 4.27 TB/min● 1 PB, 190 Nodes, 234 min, 4.27 TB/min - previously
unattainable○ https://databricks.com/blog/2014/10/10/spark-petabyte-
sort.html○ Fairly easy to tune (will show later)

Enter Spark
Why Spark (cont.)?● Operating Cost
○ Open Source (Apache Licensed)○ Gets more done with fewer nodes○ Memory less expensive nowadays○ Runs on commodity hardware○ Predictable projection for growth
● Hardware costs grow with customer base● Add memory to node● When memory maxed out, add node to cluster

Enter Spark
Why Spark (cont.)?● Multi-Faceted, Simplified API
○ Map/Reduce can often be completed as a one liner
○ Functional, immutable API● Easy to keep concepts in your head
● Tranformations - abstract● Actions - concrete
○ ETL generally only needs Map and Filter○ Multi-language APIs
● Scala, Java, Python

Another Tool
=
+ =

Enter Clojure
Why Clojure?● We started out with Python
○ Good cultural fit● Dynamic language● Cross paradigm - OO, Functional
○ But…● Lags behind Scala and Java Spark releases● Only worked in YARN client mode

Enter Clojure
Why Clojure?● Clojure is:
○ Dynamic Language○ Built on JVM
● Can use just about any Java API you want● Can optionally compile a Clojure app into a
Java Archive○ (Only) Functional
● Comes with map,reduce,filter baked in● Fns are first class objects● Immutable data structures● No generics
○ Great concurrency support

Clojure Syntax
● Maps: {}○ {:weapon “chewing gum”
:outcome “boom”}● Sequences/Lists: ()
○ (1 “Mullet ” “ please”)● Vectors: []
○ [“Got ” “duct tape?”]● Functions: (fname arg0 arg1)
○ (catch-bad-guy-with “Paper Clip”)

Developing in Spark and Clojure
● Clojure comes with a shell called the REPL (Read Eval Print Loop)

Developing in Spark and Clojure
● We currently use the SparklingAPI (https://gorillalabs.github.io/sparkling/)○ Idiomatic wrapper around Spark
Java API● May use Flambo in the future:
○ https://github.com/yieldbot/flambo

Developing in Spark and Clojure
● Best editor for Clojure is Emacs○ Cider plugin
● Integrated REPL● Code completion
● In Clojure, Java, and REPL● Easier to read errors
● Great article on how to set up Cider http://www.braveclojure.com/using-emacs-with-clojure/

Developing in Spark and Clojure
● Build with Leiningen (or lein)○ Project file written in Clojure○ Provides integration with Maven and
Clojars repos○ Runs unit tests○ Generates uberjar
● Looking into potential use of Gradle○ Better fit for continuous
integration/deployment
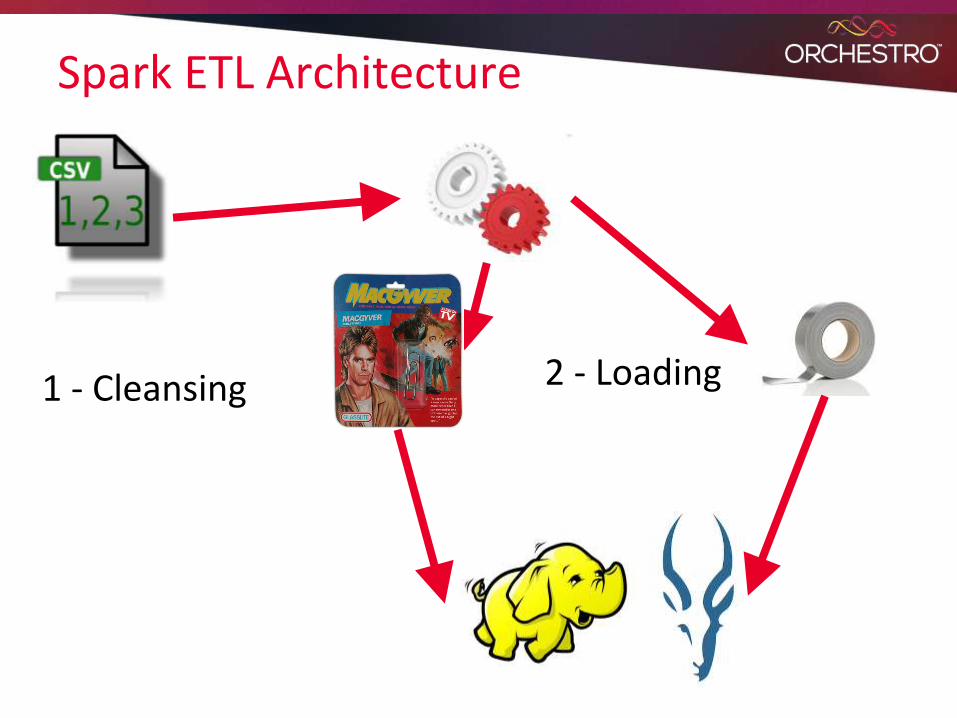
Spark ETL Architecture
1 - Cleansing 2 - Loading

Spark ETL Architecture
● Advantages○ Lower risk
● Fits into existing process○ Single Responsibility:
● Do cleansing, and do it well○ Huge potential to improve performance
● Next Steps○ Build out loading capability in Spark

Initial Results
● 70 m record Point of Sale data set○ Prod Cleansing Time:
1h 29m○ Spark Cleansing Time:
1m 36s○ How?
● Keys○ Yarn Cluster mode○ Num Executors

Related Documents











