47 Lossless compression methods Mohammed Chassab Mahdi Assist .Lecturer-Institute of Technical /Kufa Abstract the aim of research is to find compression methods which are more appropriate to compress files with different extensions, and what the effect of changing the size of the file on the compression ratio . In this research have been selected eight most common of file extensions and for each one of these extensions have been selected ten different size files as a samples to compress by using three lossless compression methods(RLE, Huffman ,LZW ) have also been discussed the response of each extension to the three methods. All programs have been written using visual basic language مستخلص ال يهدف البحث إلى إيجاد طرق الضغطكثر اءم مملفات ة لضغط ال ذات ادادات مد ال فة ، مخدل ك ما ي هدف إ لى درا سة جم ير ح دأثير دغ ال ملف على نسبة ال ضغط. Compression Ratio لبحااثذا اااه اا يدنااثااة ث ماادااا باادلضااغطرق ا طااLossless compression methods ة طرياي (RLE ,Huffman ,LZW) خدمهايساد ت ذا فا ضغط مل ل اي فهات مخدلداد د ية ام ت ثمانك ثر ال كه عا شي ضغط ع شرة مل فات دمداد امد بإح جام مخدل فة سدجابةق شة ا ك ما د مت منا ضغط بالطرقلداد ل كه ام د ثة الث. غة الف ج برامج كد بت بل كه ال اه بيسيك.1-Introduction Data compression is a general term used to describe the process of recoding data so that it requires fewer bytes of storage space .Two very important terms used in all however are lossless compression and lossy compression [6]. Lossless data is the ability to shrink a file then reconstitute it to its original form. Lossy compression however, is the ability to eliminate some data during the process (rather than shrink) then reconstitute it. These terms are vital in understanding the differences between the different types. There are many different kinds of ways to perform data compression. Each one is used differently and has its intended purpose. The first kind of compression is dictionary-based compression. In this type compression replaces characters with one individual codeword. This codeword is then directed to a dictionary that is able to find the original structure of the word. It shortens words, sentences, or paragraphs so that the entirety of each do not have to be transported. Another type of compression is statistical compression. During this process the frequencies of characters are manipulated in order to perform the necessary task. Characters that are repeated throughout the file are given bit patterns. In this process letters or individual characters that are repeated many times throughout a piece are

Welcome message from author
This document is posted to help you gain knowledge. Please leave a comment to let me know what you think about it! Share it to your friends and learn new things together.
Transcript

47
Lossless compression methods Mohammed Chassab Mahdi
Assist .Lecturer-Institute of Technical /Kufa
Abstract
the aim of research is to find compression methods which are more appropriate to
compress files with different extensions, and what the effect of changing the size of the
file on the compression ratio .
In this research have been selected eight most common of file extensions and for each
one of these extensions have been selected ten different size files as a samples to
compress by using three lossless compression methods(RLE, Huffman ,LZW ) have
also been discussed the response of each extension to the three methods. All programs
have been written using visual basic language
المستخلص ة لضغط الملفات مالءم األكثرالضغط طرق إيجاد إلىالبحث يهدفً ددادات ذات اال فة ،الم هدف ماكمخدل لىي سة إ جم درا ير ح دأثير دغ
Compression Ratio .ضغطالنسبة علىملف ال
طاارق الضااغط بااد اادا ماا ثالثااة يدنااا ه اااذا البحااثLossless compression methods اي طري ة (RLE ,Huffman ,LZW)يسادخدمها
فات ذا ضغط مل اي ل فه ددادات مخدل ية ام ثرت ثمان كه األك شي عا لكما دمت مناقشة اسدجابة مخدلفة بإحجامامدداد دم ضغط عشرة ملفات اه كه البرامج كدبت بلغة الفج . الثالثةكه امدداد للضغط بالطرق
بيسيك.
1-Introduction
Data compression is a general term used to describe the process of recoding data
so that it requires fewer bytes of storage space .Two very important terms used in all
however are lossless compression and lossy compression [6].
Lossless data is the ability to shrink a file then reconstitute it to its original form. Lossy
compression however, is the ability to eliminate some data during the process (rather
than shrink) then reconstitute it. These terms are vital in understanding the differences
between the different types.
There are many different kinds of ways to perform data compression. Each one is
used differently and has its intended purpose.
The first kind of compression is dictionary-based compression. In this type
compression replaces characters with one individual codeword. This codeword is then
directed to a dictionary that is able to find the original structure of the word. It shortens
words, sentences, or paragraphs so that the entirety of each do not have to be
transported.
Another type of compression is statistical compression. During this process the
frequencies of characters are manipulated in order to perform the necessary task.
Characters that are repeated throughout the file are given bit patterns. In this process
letters or individual characters that are repeated many times throughout a piece are

48
recoded. This type of compression makes it possible for a file to be very small during
transportation then in full text when it is recoded at the end [1,8].
Additionally there is spatial compression . In this file the redundant data
contained in a file is taken advantage. Data that is constantly repeated within a file is
replaced with a message that can accurately describe its contents. This is often used in
the compression of image files. For example, run-length encoding is commonly used to
compress redundant color pixels.
Finally, but no less important there is temporal compression. This is most
commonly used in the compression of video or audio files. This process excludes
redundant information in video and audio samples. It stores only the information
necessary and eliminates all other “useless” information. During cuts, wipes, dissolves,
and transitions the only thing transferred is the “key frame.” The key frame is the
information common in all the original data. That way unnecessary information does
not have to be transferred in all the transfers [5].
1-1-The Need For Compression
In the past, storing documents were stored on paper and kept in filing cabinets
have been very inefficient in terms of storage space and also the time taken to locate and
retrieve information when required. This traditional method of storing documents is
now being replaced by storing and accessing documents electronically through
computers.
This has enabled us to manage things more efficiently and effectively, so that
items can be located and information extracted without undue expense or inconvenience.
In terms of storage, the capacity of a storage device can be effectively increased with a
method that compresses a body of data on its way to a storage device and decompresses
it when it is retrieved [4].
In terms of communications, the bandwidth of a digital communication link can be
effectively increased by compressing data at the sending end and decompressing data at
the receiving end [7].
At any given time, the ability of the Internet to transfer data is fixed. Thus, if data
can effectively be compressed wherever possible, significant improvements of data
throughput can be achieved. Many files can be combined into one compressed document
making sending easier. In computer graphics, we are interested in reducing the size of a
block of graphics data so we can fit more information in a given physical storage space.
1-2-Data compression classification
Data compression can be divided into two main types [2,10]:
A-Lossless data compression:-
The data which have been compressed by the lossless compression methods can
be returned to the original form exactly. Lossless compression methods used for task

49
data such as texts, some kinds of pictures, signals from earthquakes and volcanoes, and
medical tomography images.
B-Lossy data compression:-
Lossy compression methods cause the loss of some information (non-task),
which normally can not be retrieved or restructure but it can get higher compression
ratio than those we get using lossless compression methods[9]. In many applications, the
shortfall when restructuring unimportant, for example when storing a talk, the exact
value of each sample of the talk is not necessary[3].
2-System design
Three algorithms (RLE , Huffman , LZW) has been used to write three
programs using visual basic language and then develop a system includes three
programs. This system can be load the different files in order to compression by one of
each method (Huffman ,LZW , RLE) and then saved.
Also it can be load the compression files in order to decompression and then saved . The
system also allow to present file content before and after compression or decompression
2-1Selected file extensions
In this research have been selected eight file extensions which is common used .
These selected file extensions listed below :-
1- txt. (Text file)
2- doc. (Text file)
3- bmp. (Image file)
4- jpg. (Image file)
5- mp3. (Audio file)
6- mpeg. (Video file)
7- ppt . ( Data file)
8-html. (Web file)
2-2Experimental results
For each file extension have been selected ten different size files and compressed
these files by using three methods (Huffman, LZW, RLE) and have been calculated the
compression ratio .Compression ratio is the ratio of the size of the original data to the
size of the compressed data.
Compression Ratio (CR) =size of original file / size of compressed file.

50
Results of compression using three methods for each ten files from the same
extension has been put in the table also contains the compression ratios calculated.
The scheme was designed to clarify the relationship between file size and the
compression ratio for each compression method.
Table(1) txt files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffman
1.0024 1.9594 1.564586 46076 23571 29519 46185 Txt1
1.0114 1.97607 1.524984 103050 52742 68343 104222 Txt2
0.9999 2.10342 1.610484 167544 79646 104024 167529 Txt3
0.9999 2.06291 1.62187 207899 100774 128178 207888 Txt4
1.0002 2.12644 1.621255 255069 119977 157362 255124 Txt5
1.0002 2.05488 1.620862 315180 153414 194494 315248 Txt6
1.0002 2.06669 1.623715 382058 184893 235335 382117 Txt7
1.0002 2.09032 1.615578 412503 197374 255373 412575 Txt8
1.0007 1.84023 1.482511 471943 256626 318548 472251 Txt9
1.0054 2.45268 1.608797 519803 213070 324834 522592 Txt10
Fig(1) txt files curves
51
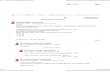
Table(2) doc files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffman
1.6019 1.47488 1.603497 30683 33326 30653 49152 Doc1
1.3912 2.45552 1.800769 94586 53587 73071 131584 Doc2
1.4071 2.70128 1.891521 138268 72025 102859 194560 Doc3
1.472 2.27969 1.94604 188746 121876 142772 277840 Doc4
1.3921 2.22338 1.725003 276393 173053 223050 384762 Doc5
1.2798 2.22409 1.616443 363667 209258 287921 465408 Doc6
1.2683 2.31147 1.630573 450120 246981 350115 570888 Doc7
1.25 2.32253 1.57236 560726 301795 445781 700928 Doc8
1.2399 2.20516 1.565969 621477 349435 492066 770560 Doc9
1.2417 2.255 1.572892 699729 385305 552399 868864 Doc10
Fig(2) doc files curves

52
Table(3) bmp files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffman
1.00008 0.97229 1.183345 36915 37970 31198 36918 Bmp1
0.99981 0.94307 1.033767 102794 108978 99417 102774 Bmp2
1.01933 1.68259 1.04319 244393 148056 238804 249118 Bmp3
0.99996 0.91756 1.017805 332996 362901 327157 332982 Bmp4
0.99971 1.12376 1.111846 411372 365964 369884 411254 Bmp5
1.07708 1.03523 1.051168 512801 533535 525444 552330 Bmp6
1.00024 1.32035 1.374772 677888 513540 493212 678054 Bmp7
1.0012 1.86793 1.14966 714914 383189 622593 715770 Bmp8
1.01838 1.25657 1.046276 831488 673875 809322 846774 Bmp9
1.03518 2.00549 1.295362 890334 459566 711503 921654 Bmp10
Fig(3) bmp files curves

53
Table(4) jpg files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffman
1.00839 0.71413 0.9853 12629 17833 12925 12735 Jpg1
1.00072 0.65822 0.993771 104590 159012 105321 104665 Jpg2
1.00045 0.68117 1.001412 226802 333108 226584 226904 Jpg3
1.08069 0.66781 1.00061 308195 498742 332860 333063 Jpg4
1.00006 0.65719 0.999104 473850 721065 474303 473878 Jpg5
1.00011 0.66605 1.002589 555678 834383 554302 555737 Jpg6
1.0178 0.66387 0.999898 609447 934364 620356 620293 Jpg7
1.00003 0.69727 1.015257 716434 1027511 705690 716457 Jpg8
1.00548 0.65252 1.000228 830602 1279887 834960 835150 Jpg9
1.00485 0.65527 1.000065 935151 1434038 939625 939686 Jpg10
Fig(4) jpg files curves

54
Table(5) mp3 files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffma
n
1.00825 0.66628 0.99493 53701 81263 54420 54144 Mp3 1
1.03652 0.67626 1.0343 112746 172809 112989 116864 Mp3 2
1.02023 0.66857 1.02073 208392 318003 208291 212608 Mp3 3
1.01351 0.65739 1.01295 304243 469056 304409 308352 Mp3 4
1.03571 0.67684 1.01704 405982 621242 413434 420480 Mp3 5
1.01292 0.66722 1.01529 510143 774465 508955 516736 Mp3 6
1.00708 0.65758 1.00849 624441 956337 623568 628864 Mp3 7
1.02169 0.67005 0.96506 709727 1082195 751373 725120 Mp3 8
1.06563 0.69517 1.02249 817498 1253151 851987 871152 Mp3 9
1.00645 0.66662 1.01212 927016 1399593 921817 932992 Mp3 10
Fig(5) mp3 files curves
55
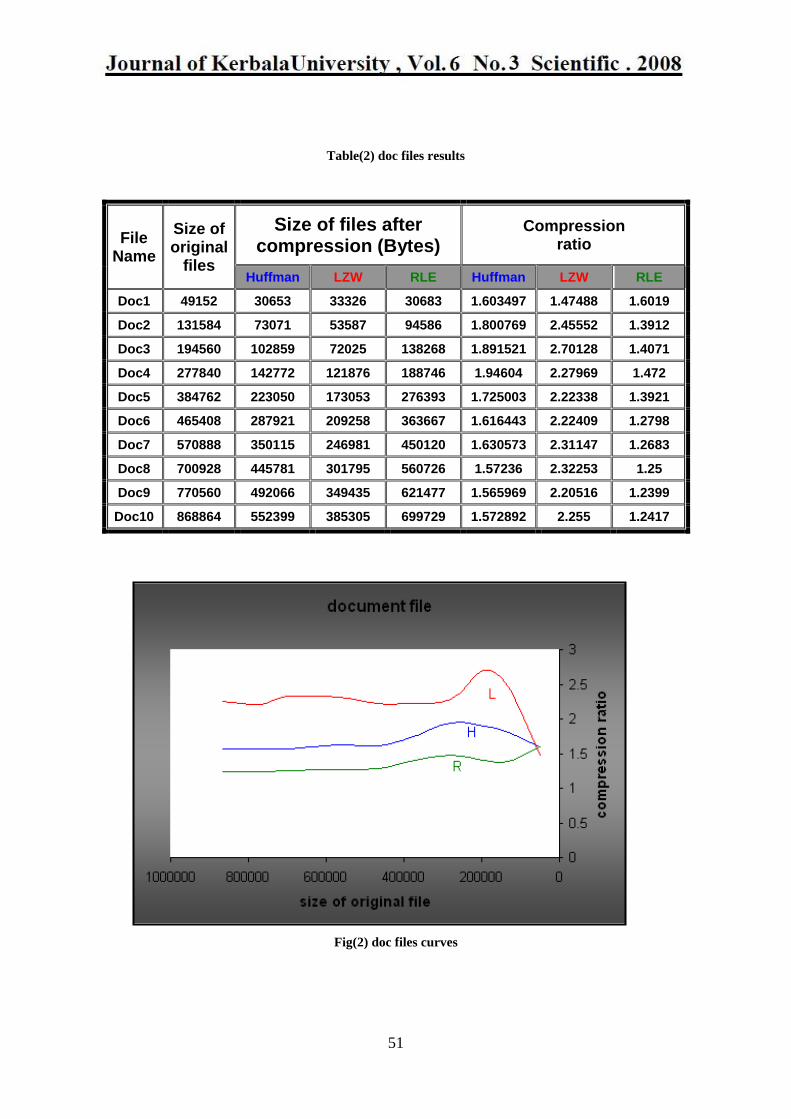
Table(6) mpeg files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffm
an
1.22377 0.85374 1.08046 18412 26392 20854 22532 Mpeg1
1.04126 0.71247 1.01493 118015 172477 121076 122884 Mpeg2
1.02509 0.70395 1.01236 197793 288026 200280 202756 Mpeg3
1.01728 0.71252 1.02234 348288 497258 346567 354308 Mpeg4
1.00961 0.70198 1.0177 411791 592253 408516 415748 Mpeg5
1.00792 0.69263 1.01293 627861 913670 624759 632836 Mpeg6
1.00794 0.69257 1.01301 692824 1008310 689356 698327 Mpeg7
1.00977 0.69393 1.01354 720008 1047717 717329 727044 Mpeg8
1.00859 0.69307 1.01343 800043 1164261 796224 806916 Mpeg9
1.00788 0.69618 1.01519 910334 1317925 903776 917508 Mpeg10
Fig(6) mpeg files curves
56
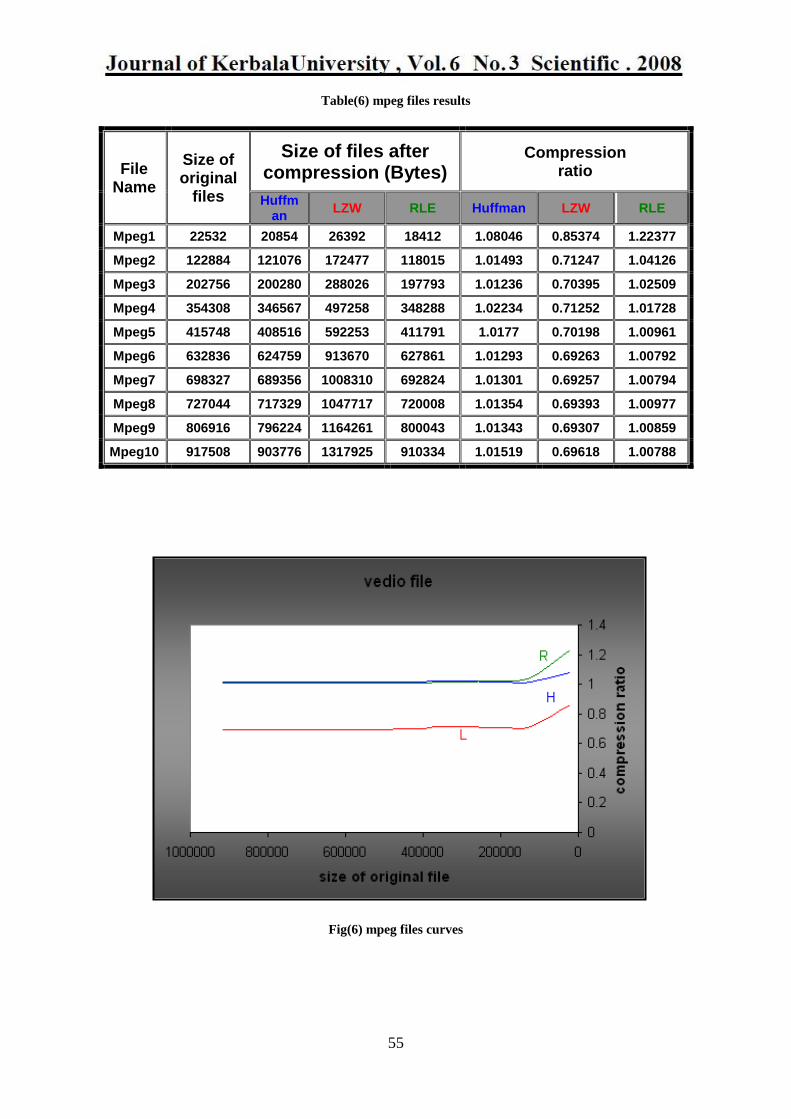
Table(7) ppt files results
Compression ratio
Size of files after compression (Bytes)
Size of original
Files
File Name
RLE LZW Huffman RLE LZW Huffman
1.40637 2.19636 1.977122 19295 12355 13725 27136 Ppt1
1.32314 1.41355 1.552881 47983 44914 40884 63488 Ppt2
1.32715 1.42735 1.343308 93361 86807 92238 123904 Ppt3
1.13517 1.24904 1.31108 166432 151258 144101 188928 Ppt4
1.12393 1.42655 1.121005 257839 203142 258511 289792 Ppt5
1.05784 0.8734 1.083528 335900 406832 327936 355328 Ppt6
1.04319 0.83137 1.060261 430925 540715 423986 449536 Ppt7
1.08336 0.98012 1.148319 516556 570969 487335 559616 Ppt8
1.06075 1.07727 1.207403 583076 574135 512253 618496 Ppt9
1.04702 0.82773 1.069384 676296 855469 662153 708096 Ppt10
Fig(7) ppt files curves

57
Table(8) html files results
Compression ratio
Size of files after compression (Bytes)
Size of original
files
File Name
RLE LZW Huffman RLE LZW Huffman
1.05545 0.9064 1.115152 523 609 495 552 html1
1.01027 1.53753 1.400998 9448 6208 6813 9545 html2
1.13826 2.68568 1.527689 26393 11186 19665 30042 html3
1.00078 2.30099 1.420273 52279 22738 36838 52320 html4
1.04082 2.23278 1.471803 70260 32752 49686 73128 html5
1.02106 1.95386 1.361606 94897 49592 71163 96896 html6
1.0641 2.08627 1.421844 112111 57182 83903 119297 html7
1.00144 2.3192 1.317899 144182 62258 109560 144389 html8
1.00855 1.87637 1.336452 170530 91660 128690 171988 html9
0.99998 3.63339 1.476389 193630 53291 131149 193627 html10
Fig(8) html files curves

58
Table(9)
The best compression method for each extension of files
web files
data files
video files
audio files
files image files text
html ppt mpeg mp3 jpg bmp doc txt type of files
LZW Huffma
n RLE RLE RLE LZW LZW LZW
best compressio
n method
Table(10)
Total sizes of files
total size of all original
files (Bytes)
total size of all compression files(Bytes)
total size of all files
compression by the best
method(Bytes)
total size of all files
compression by WinRAR
(Bytes) Huffman LZW RLE
30840347 27319941 31994898 29820060 24019640 18806048
Results discussion
1- Compression results of the text files for the type (txt)and (doc) showed that these files
responded to the compression by LZW method more than the other methods.
2- When RLE compression method is used the compression ratio of the image files of
type (bmp) equal to one. It means that above files neither responds to the
compression nor bigger size at the same time. These files responded slightly to the
compression using Huffman method while, the compression ratio to LZW method is
the biggest, but this ratio varied greatly.
3- The image files of type (jpg) maintained on their sizes using Huffman method, That
means the sizes of these files did not increase or decrease When LZW method is
used, the compression ratio is less than one this means that the sizes of these files
were increased .These files slightly responded to compression using RLE method.
4- The audio files of type (mp3) maintained their sizes when Huffman and RLE methods
were used, but the sizes of these files increased when LZW method was used. This
means that these files do not respond to all lossless compression methods.

59
5- The video Files of type (mpeg) responded slightly to the compression when Huffman
and RLE methods were used while sizes increased when these files compressed by
LZW method.
6- The data files of type (ppt) responded to all compression methods, but these files have
responded more to compression when Huffman method was used.
7- The web files of type (html ) responded more to the compression by using the method
of LZW, but they responded less by using the Huffman method , while, maintained
their sizes using RLE method .
8- The web files html 3 and html 10 responded to compression by using LZW method
more than the rest of the files of the same extension because these files contain texts
more than pictures .
9- The image files Bmp 3, Bmp8 and Bmp10 responded to the compression by using
LZW method more than the rest of files of the same extension because of contain
these images on large similar tracts .
3-Conclusions
It could be concluded from the results that :-
1- The change in file size does not affect the compression ratio when using all methods
which were studied. 2- Results showed that LZW was the best method to compress the files with the
extensions of ( txt.doc.bmp.html) while, RLE was the best method to compress the
files with the extensions of (jpg.mp3.mpeg). Huffman was the best method to
compress files with the extension(ppt).
3-Possible future work to complete the program , which was practically implemented in
this research so as to adopt practical results recommended in the table (9) where the
program will choose the best compression method depending on the file extension
required to compress .
4-It is possible in the future to change in the program, which was implemented in this
research to compress file using three methods at the same time, and then compared
sizes of files resulted from the compression of these methods in the selection of the
smallest and adopt it as a result of the compression

60
References
[1] David Salomon “Data Compression: The Complete Reference” Springer, New
York, Berlin, Heidelberg, U.S.A, Germany, 2nd
edition,2000.
[2] Gilbert Held “ Data Compression ”John Wiley and Sons Ltd (December 7, 1983).
[3] Gilbert Held and Thomas Marshall "Data compression : techniques and plications:
hardware and software considerations ": Chichester [West Sussex] New York :
Wiley, c1987.
[4] James A. Storer “Data Compression Methods and Theory”(Principles of
Computer Science Series, Vol 13) Computer Science Pr; Reissue edition(April
1988) .
[5] Jerry D. Gibson, Toby Berger, Tom Lookabaugh Rich Baker, David Lindbergh
“Digital Compression for Multimedia :Principles &Standards (Morgan Kaufmann
Series in Multimedia Information and Systems) ” Morgan Kaufmann; 1st
edition(January 1, 1998)
[6] Khalid Sayood “Introduction to Data Compression” Morgan Kaufmann
Publishers, Burlington, United States of America, Third edition, 2005.
[7] Leonard Laub “Data Compression: Applications in Communications, Storage,
Imaging, Audio, Video and Multimedia” Thomson Executive Pr (December 1996)
[8] Mark Nelson and Jean-loup Gailly “The Data Compression Book” M&T Books,
New York, United States of America, 2nd edition,,1995.
[9] R. Krichevsky “Universal Compression and Retrieval (Mathematics and Its
Applications) ” Springer; 1 edition (February 28, 1994)
[10] Wright, Scott Brian. “An overview of data compression techniques” Thesis
(M.S.E.E.)--University of Washington, 1989.
Related Documents